






函数式自动微分
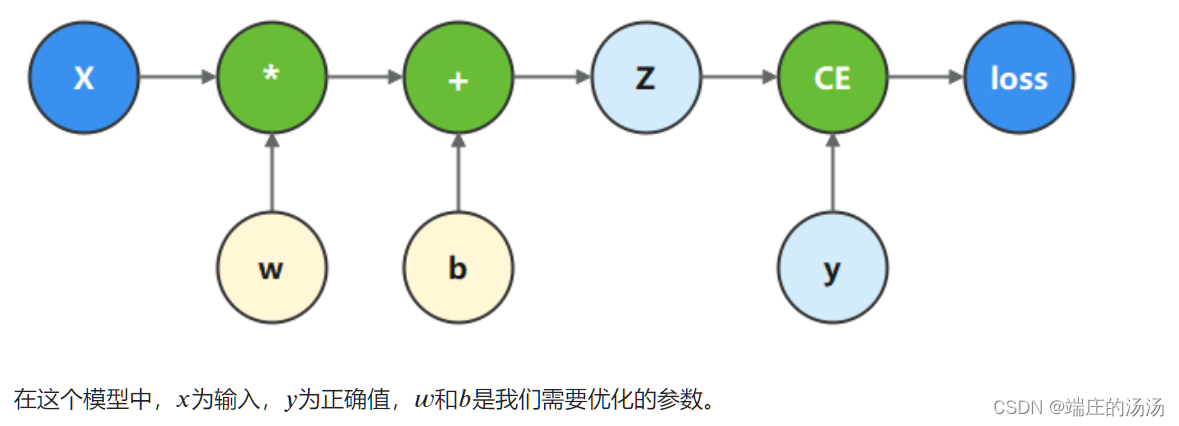
反向传播算法是深度学习蓬勃发展的基石之一,因此掌握程序怎么执行反向传播是非常重要的。MindSpore使用函数式自动微分的设计理念,提供自动微分函数接口grad和value_and_grad。grad基于计算图计算参数的梯度,需要自己实现计算图function。如下图,输入x经过一层线性层直接输出结果z,然后和labels y计算二值交叉熵损失。
如下图代码所示,首先定义一个假设的输入输出,然后对于要求导的参数定义为Parameter类方便求导。
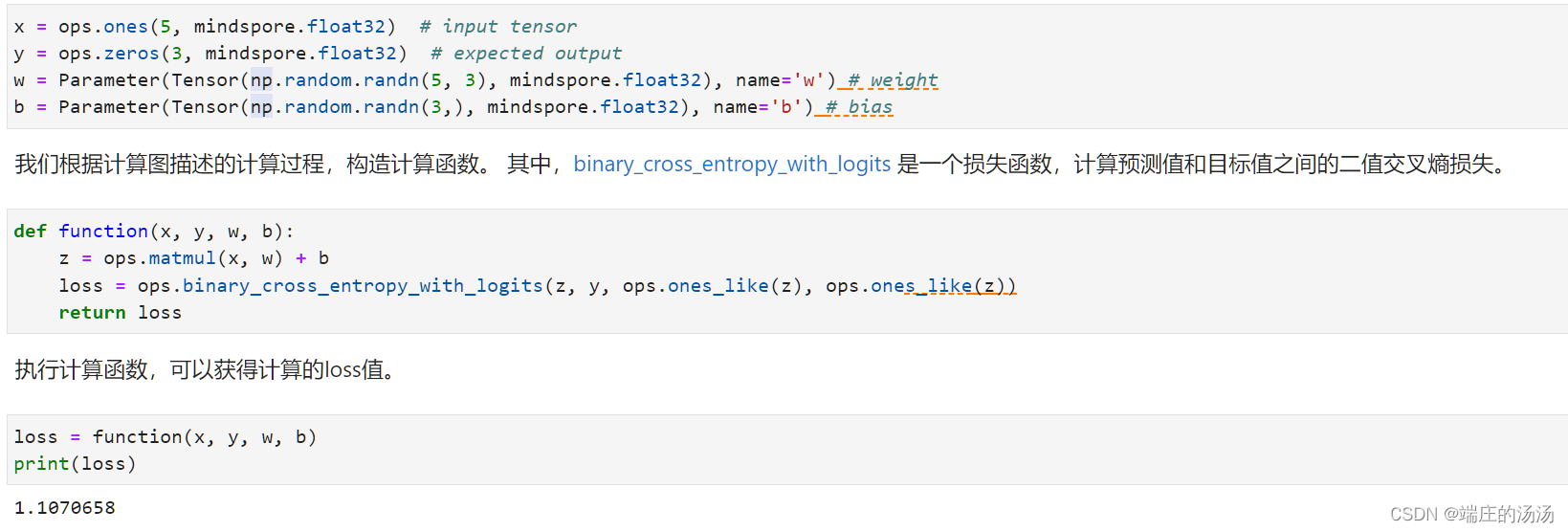
对于定义好的变量,执行矩阵操作,然后计算二值交叉熵损失,值得注意的是,计算二值交叉熵损失时,label和pred的输入形式是一一对应的,z和y的shape是一致的,这和计算交叉熵的函数是不一样的。
通过调用grad函数接口,传入编写的函数和要求导的参数再计算图中的位置,即可实现自动求导。

向得到的自动计算微分的函数传入输入,label和要求导的参数即可得到参数的梯度。
通常情况下,求导时会求loss对参数的导数,因此函数的输出只有loss一项。当我们希望函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。
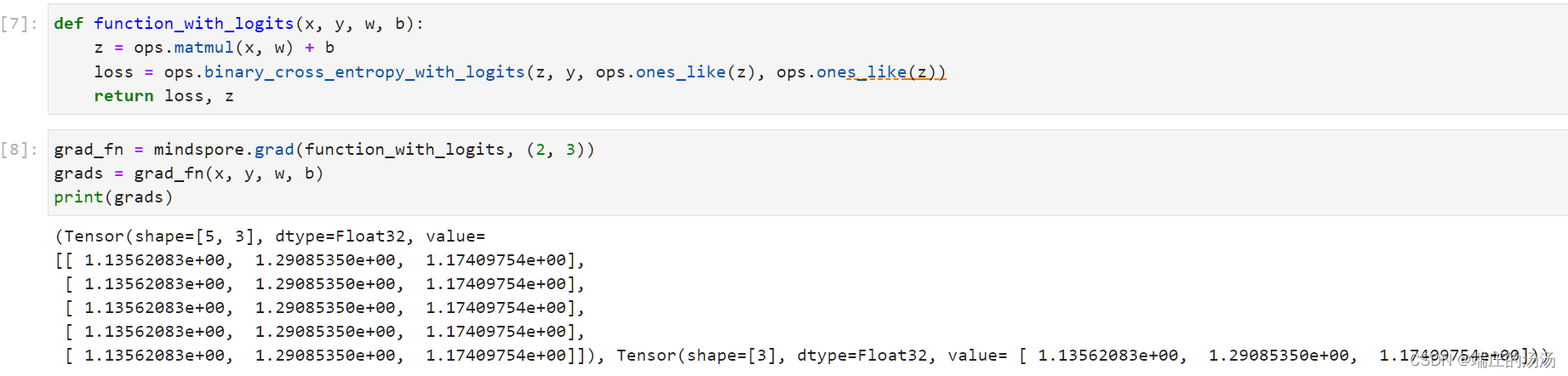
如上图所示,函数返回了loss和z,对于w和b的求导只需要loss一条路求导,如果同时返回z就相当于2条路对w和b求导,显然重复了,导致w和b的梯度变大。

如上图所示,在返回z时,声明z这条路不需要求导即可。同理,一个函数也许有多个输出,不只需要返回一个结果,可能还有其他的中间变量方便可视化。对此另一种方法更实用,将has_aux参数设为True,可以看到和上边是一样的效果。

上边是说的grad,对自己构建的计算图求导,但是一个完整的深度学习程序是基于OO设计的。MindSpore中的神经网络构造是继承自nn.Cell。此时梯度的计算就需要value_and_grad函数。如下图所示,构建一个前向传播并进行loss计算的常用程序。
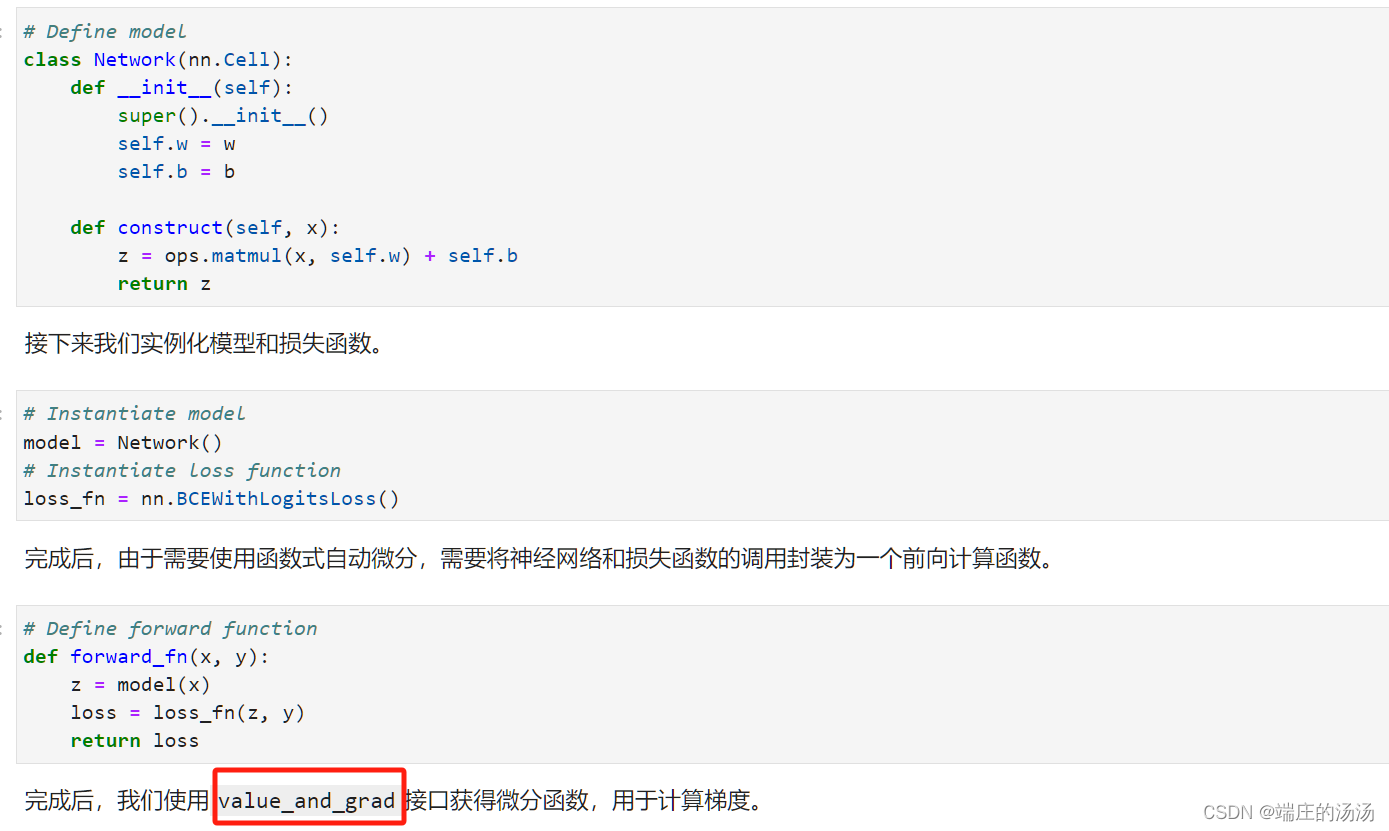
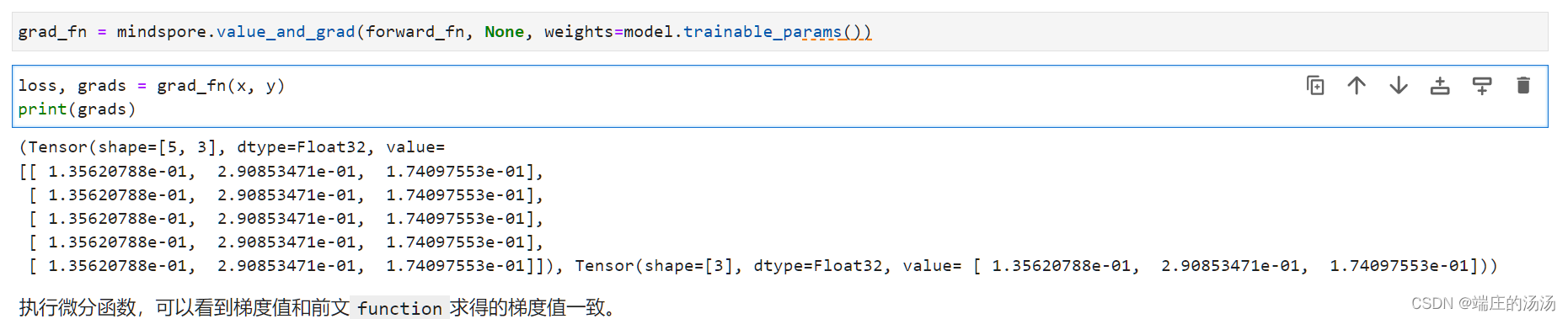
使用面向对象继承的方式非常的方便,不需要自己构建计算图,不需要将参数进行包装。对于参数,在设置属性的时候,父类会自行将需要训练的参数使用mindspore.Parameter进行包装,非常的方便。如果需要查看模型中参数的梯度,不再需要传入参数在计算图中的位置,只需要调用model.trainable_params()方法从Cell中取出可以求导的参数即可。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









