







 本文深入浅出地介绍了MADDPG算法,从多智能体环境到算法拆解,再到环境复现。作者通过解析PARL框架下的MADDPG,展示了如何应用该算法解决‘老鹰捉小鸡’问题,强调了MADDPG在多智能体协同和竞争环境中的核心思想。
本文深入浅出地介绍了MADDPG算法,从多智能体环境到算法拆解,再到环境复现。作者通过解析PARL框架下的MADDPG,展示了如何应用该算法解决‘老鹰捉小鸡’问题,强调了MADDPG在多智能体协同和竞争环境中的核心思想。
点击左上方蓝字关注我们

【飞桨开发者说】郑博培:北京联合大学机器人学院2018级自动化专业本科生,深圳市柴火创客空间认证会员,百度大脑智能对话训练师,百度强化学习7日营学员

MADDPG算法是强化学习的进阶算法,在读对应论文Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments的过程中,往往会遇到很多不是很好理解的数学公式,这篇文章旨在帮助读者翻过数学这座大山,并从PARL(PARL是百度提供的一个高性能、灵活的强化学习框架)的代码理解MADDPG算法。本文目录如下:
1.把MADDPG拆分成多个算法
2.什么是多智能体?有哪些环境?
3.从PARL的代码解读MADDPG
4.复现“老鹰捉小鸡”的游戏环境
5.回归论文
把MADDPG拆分成多个算法
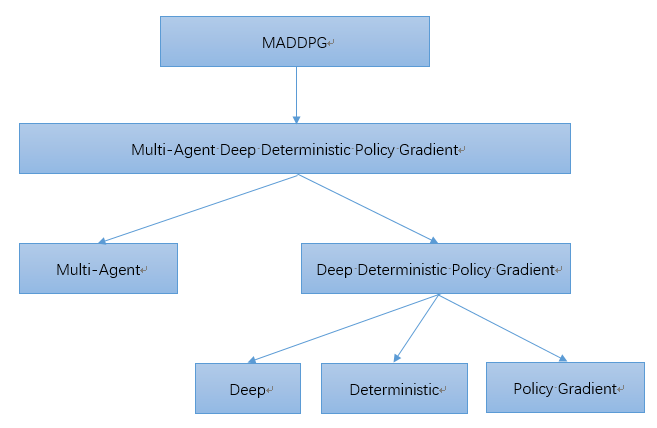
MADDPG的全称是Multi-Agent Deep Deterministic Policy Gradient。我们可以把它拆开去理解:
-
Multi-Agent:多智能体
-
Deep:与DQN类似,使用目标网络+经验回放
-
Deterministic:直接输出确定性的动作
-
Policy Gradient: 基于策略Policy来做梯度下降从而优化模型
我们可以把思路理一下,MADDPG其实是在DDPG的基础上做的修改,而DDPG可以看作在DPG的基础之上修改而来,DPG是确定性输出的Policy Gradient;也可以把DDPG理解为让DQN可以扩展到连续控制动作空间的算法。
那下面我们就来把这些算法一一回顾一下:
Q-learning算法。Q-learning算法最主要的就是Q表格,里面存着每个状态的动作价值。然后用Q表格来指导每一步的动作。并且每走一步,就更新一次Q表格,也就是说用下一个状态的Q值去更新当前状态的Q值。
DQN算法。DQN的本质其实是Q-learning算法,最主要的区别是把Q表格换成了神经网络,向神经网络输入状态state,就能输出所有状态对应的动作action。
在讲PG算法前,我们需要知道的是,在强化学习中,有两大类方法,一种基于值(Value-based),一种基于策略(Policy-based)。Value-based的算法的典型代表为Q-learning和SARSA,将Q函数优化到最优,再根据Q函数取最优策略;Policy-based的算法的典型代表为Policy Gradient,直接优化策略函数。
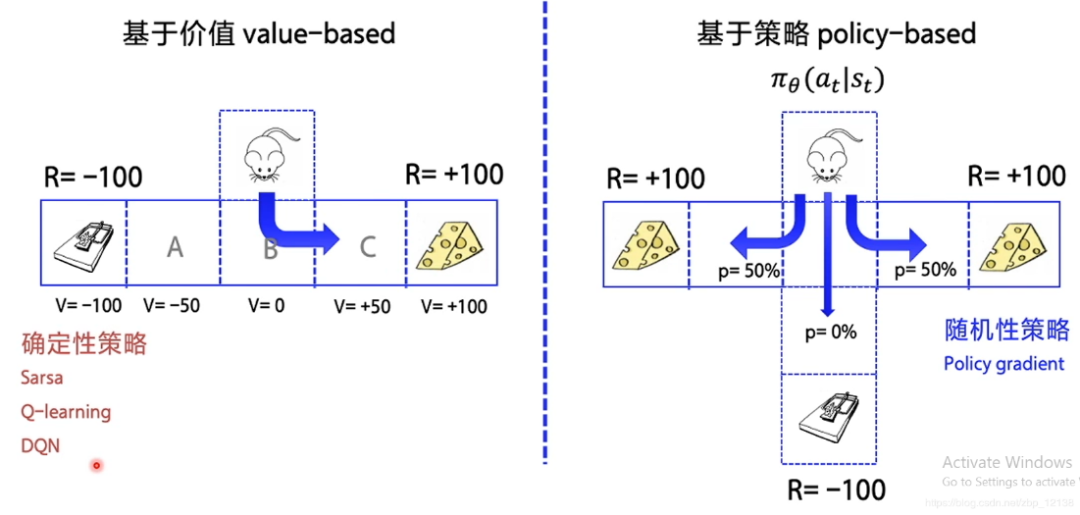
Policy Gradient算法。可以通过类比监督学习的方式来理解Policy Gradient的梯度下降。向神经网络输入状态state,输出的是每个动作的概率,然后选择概率最高的动作作为输出。训练时,要不断地优化神经网络,借助后续动作轨迹的收益计算梯度,使输出的概率更好地逼近收益较高的动作。
DPG算法。DPG算法可以理解为PG+DQN,它是首次能处理确定性的连续动作空间问题的算法,可以理解为在PG的基础上直接输出确定值而不是概率分布。为了解决探索不足的问题,引入了off-policy的Actor-Critic结构。
Actor的前生是Policy Gradient,可以在连续动作空间内选择合适的动作action;Critic的前生是DQN或者其他的以值为基础的算法,可以进行单步更新,效率更高。Actor基于概率分布选择行为,Critic基于Actor生成的行为评判得分,Actor再根据Critic的评分修改选行为的概率。DPG可以通俗地理解为在Actor-Critic结构上,让Actor输出的action是确定值而不是概率分布。
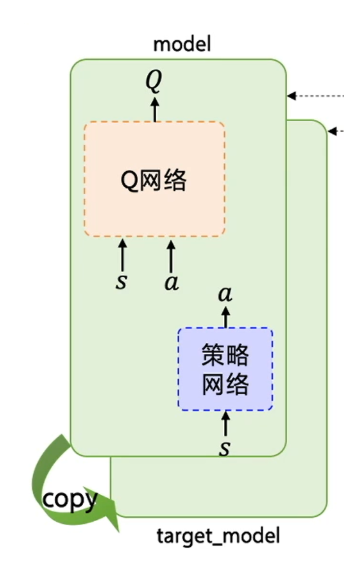
DDPG算法。DDPG算法可以理解为DPG+DQN。因为Q网络的参数在频繁更新梯度的同时,又用于计算Q网络和策略网络的梯度,所以Q网络的更新是不稳定的,所以为了稳定Q网络的更新,DDPG分别给策略网络和Q网络都搭建了一个目标网络,专门用来稳定Q网络的更新:
简单来看,MADDPG其实就是改造DDPG去解决一个环境里存在多个智能体的问题。像Q-Learning或者policy gradient都不适用于多智能体环境。主要的问题是,在训练过程中,每个智能体的策略都在变化,因此从每个智能体的角度来看,环境变得十分不稳定,其他智能体的行动带来环境变化。
对DQN算法来说,经验回放的方法变的不再适用,因为如果不知道其他智能体的状态,那么不同情况下自身的状态转移会不同;对PG算法来说,环境的不断变化导致了学习的方差进一步增大。
PG算法介绍
什么是多智能体?有哪些环境?
在单智能体强化学习中,智能体所在的环境是稳定不变的,但是在多智能体强化学习中,环境是复杂的、动态的,因此给学习过程带来很大的困难。我理解的多智能体环境是一个环境下存在多个智能体,并且每个智能体都要互相学习,合作或者竞争。
下面我们看一下都有哪些多智能体环境。(摘自https://www.zhihu.com/question/332942236/answer/1159244275)
比较有意思的环境是OpenAI的捉迷藏环境,主要讲的是两队开心的小朋友agents在玩捉迷藏游戏中经过训练逐渐学到的各种策略:
这个环境是基于mujoco的, mujoco是付费的,这里有一个简化版的类似捉迷藏的环境,也是OpenAI的:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2807
2807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









