







 百度提出统一特征表示优化(UFO)技术,应对大模型落地难题。UFO包括All in One和One for All两部分:All in One通过多任务协同训练,免去下游任务fine-tuning,提升模型效果;One for All利用超网络实现不同任务、硬件的灵活部署,解决大模型推理性能问题。该技术已在智慧城市多任务中取得SOTA效果,并将开放源代码。
百度提出统一特征表示优化(UFO)技术,应对大模型落地难题。UFO包括All in One和One for All两部分:All in One通过多任务协同训练,免去下游任务fine-tuning,提升模型效果;One for All利用超网络实现不同任务、硬件的灵活部署,解决大模型推理性能问题。该技术已在智慧城市多任务中取得SOTA效果,并将开放源代码。
从深度学习技术被提出以来,一直践行着“think big”的理念。特别是当预训练技术被广泛应用之后,更多的数据结合更大的模型参数量会持续带来模型性能的提升,这条定律不断被近期发布的各种大模型所验证。在刚刚过去的2021年,百度文心大模型中的ERNIE3.0、微软和英伟达联合推出的MT-NLP以及谷歌的Switch Transformer等等,参数量可达千亿甚至万亿。
在获得高性能大模型后,如何将大模型与业务结合实现落地变得尤为重要。当前预训练模型的落地流程可被归纳为:针对只有少量标注数据的特定任务,使用任务数据fine-tune预训练模型并部署上线。然而,当预训练模型参数量不断增大后,该流程面临两个无法回避的问题。首先,随着模型参数量的急剧增加,大模型fine-tuning所需要的计算资源将变得非常巨大,普通开发者通常无法负担。其次,随着AIOT的发展,越来越多AI应用从云端往边缘设备、端设备迁移,而大模型却无法直接部署在这些存储和算力都极其有限的硬件上。
针对预训练大模型落地所面临的问题,百度提出统一特征表示优化技术(UFO:Unified Feature Optimization),在充分利用大数据和大模型的同时,兼顾大模型落地成本及部署效率。UFO技术方案的主要内容包括:1. All in One:设计视觉表示多任务协同训练方案,免去了下游任务fine-tuning的过程,实现单模型在智慧城市多个核心任务效果全面领先2. One for All:首创针对视觉多任务的超网络与训练方案,支持各类任务、各类硬件的灵活部署,解决大模型推理性能差的问题。
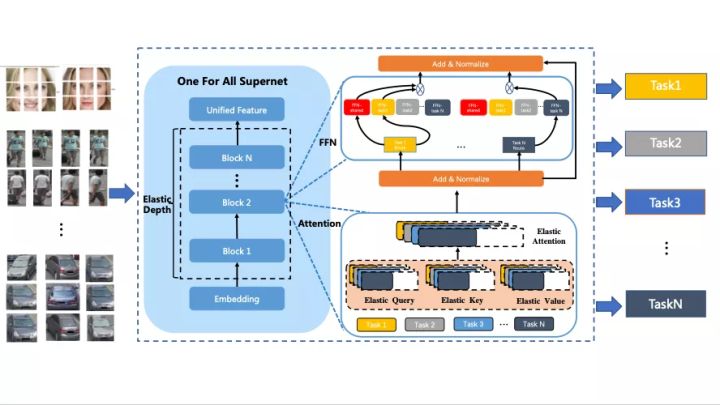
All in One:
功能更强大、更通用的视觉模型
之前主流的视觉模型生产流程,通常采用单任务“Train from scratch”方案。每个任务都从零开始训练,各个任务之间也无法相互借鉴。由于单任务数据不足带来偏置问题,实际效果过分依赖任务数据分布,场景泛化效果往往不佳。
近两年蓬勃发展的大数据预训练技术,通过使用大量数据学到更多的通用知识,然后迁移到下游任务当中,本质上是不同任务之间相互借鉴了各自学到的知识。基于海量数据获得的预训练模型具有较好的知识完备性,在下游任务中基于少量数据fine-tuning依然可以获得较好的效果。不过基于预训
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2682
2682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









