







多模态理解大模型是能处理多种数据形式(如图像、文本、视频等)的人工智能模型。通过深度学习技术,它能实现跨模态的信息理解、关联和生成。与单模态模型相比,它能更全面地捕捉与分析复杂场景,实用性和普适性更强。常见应用有图文理解、视觉问答、文档理解以及场景描述等。随着技术发展,这类模型在准确性、鲁棒性和通用性方面提升,为人工智能发展开辟新方向。
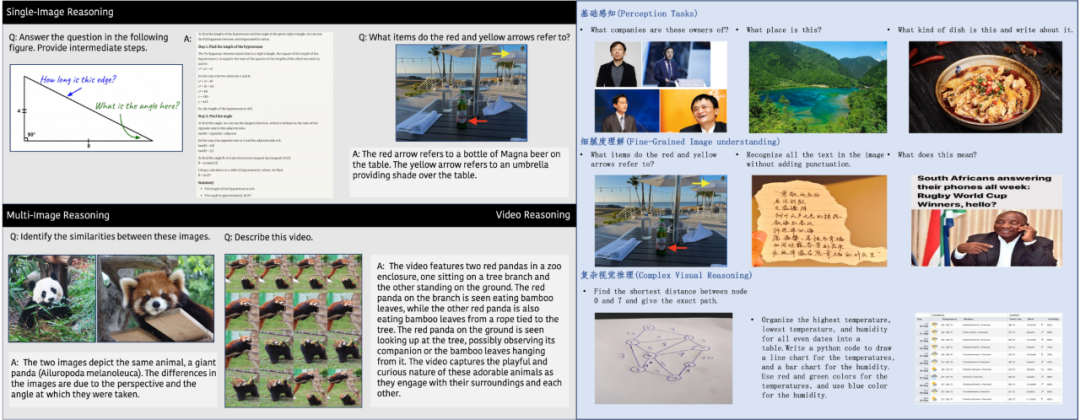
多模态理解效果示例
在本篇文章中,我们将结合 PaddleMIX 来实现三个有趣的多模态理解应用。具体而言,我们将利用 Qwen2.5-VL 多模态理解能力,以及 DeepSeek-R1 强大的推理和中文表达能力,打造一个集图像理解、文学创作、命理分析和繁体文献研究于一体的多模态创意平台。
Qwen2.5-VL 在视觉理解基准测试中表现强大,不仅能识别常见物体,还能深入分析图像文本、图表,甚至初步具备使用电脑和手机的能力。它还能理解超 1 小时的视频内容,精准捕捉事件,进行视觉定位,并支持对发票等数据进行结构化输出。DeepSeek-R1 则是一款国产开源大语言模型,依托强化学习驱动的推理机制,具备强大的逻辑推演能力和复杂任务处理能力。
此外,基于 PaddleMIX 的多模态理解应用远不止于此,飞桨星河社区的开发者也借助这一强大框架实现了诸如智能作业检查、AI 试题生成等多样化应用,进一步拓展了多模态技术在教育等领域的实践边界,展现了 PaddleMIX 在多模态应用开发领域的无限潜力和活力。
智能作业检查:
https://aistudio.baidu.com/projectdetail/8663715?channelType=0&channel=0
AI 试题生成:
https://aistudio.baidu.com/projectdetail/8802580?channelType=0&channel=0
更多项目开发教程请移步:
https://github.com/PaddlePaddle/PaddleMIX/blob/develop/paddlemix_applications.md
将这两款模型(Qwen2.5-VL 和 DeepSeek-R1)结合在一起,就能在多模态场景中玩出更多创新玩法,开辟出更广阔的可能性。本文会按照以下三个步骤展开:
引言:先介绍应用的思路及目标,包括整体的构建思路。
应用构建:详细讲解如何在PaddleMIX中使用Qwen2.5-VL和DeepSeek-R1构建应用。
应用部署:分享 AIStudio 中的部署流程与注意事项,帮助大家快速上手。
希望通过这篇文章,大家不仅能理解多模态大模型的强大之处,也能动手构建并部署自己的多模态应用,一起感受新技术的魅力~

引言
本文将手把手带大家构建用一张V100 32G显卡构建基于Qwen2.5-VL 3B模型 + DeepSeek-R1(API调用)的三个趣味应用,提示:要求更好效果可以选用7B模型(V100 32G 或A100 40G)。
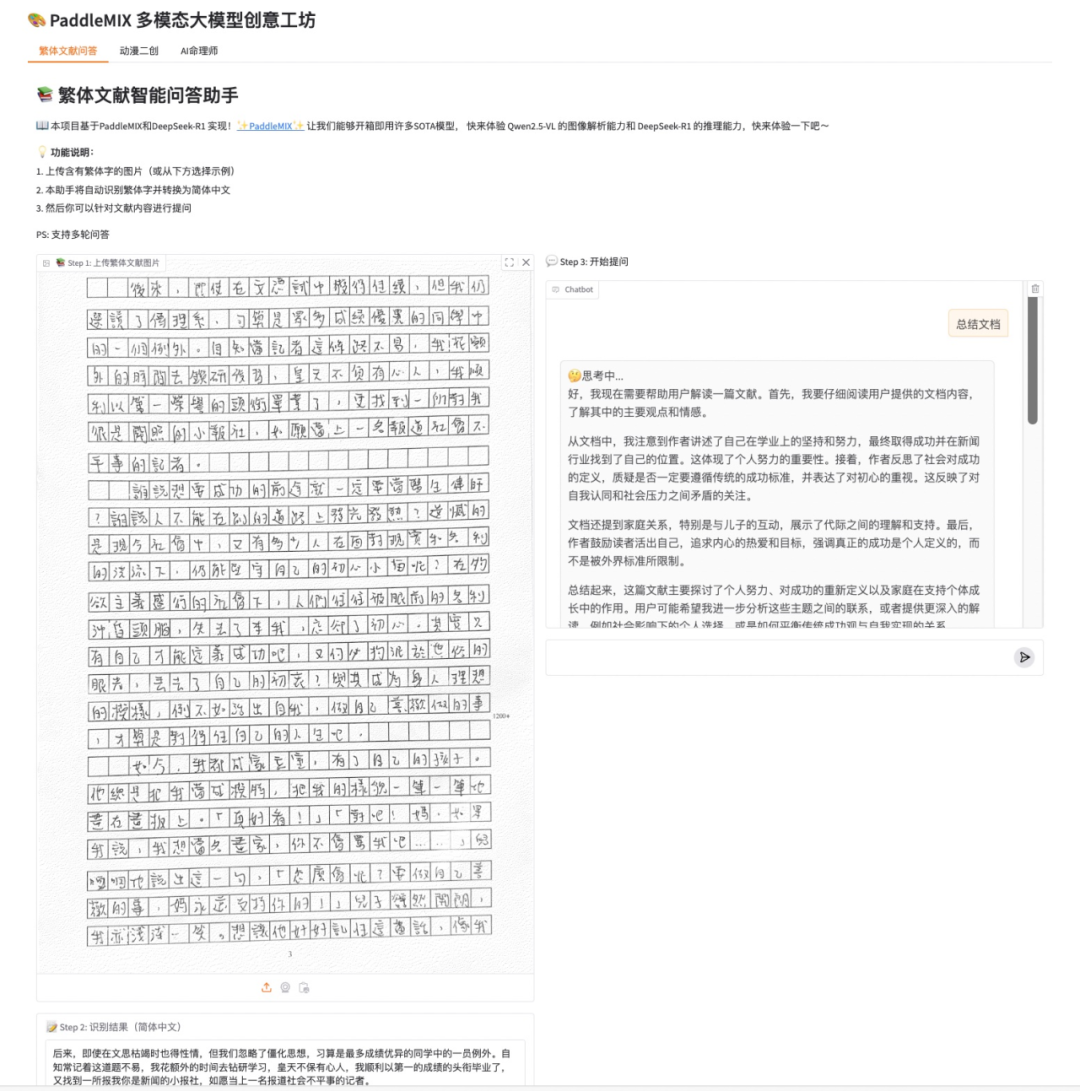
📚 繁体文献智能问答助手:利用 Qwen2.5-VL 的图像识别能力和 DeepSeek-R1 的文本理解能力,打造一款能够识别、解读古籍繁体文献的智能助手,帮助用户快速理解繁体字内容并进行深度问答交流。
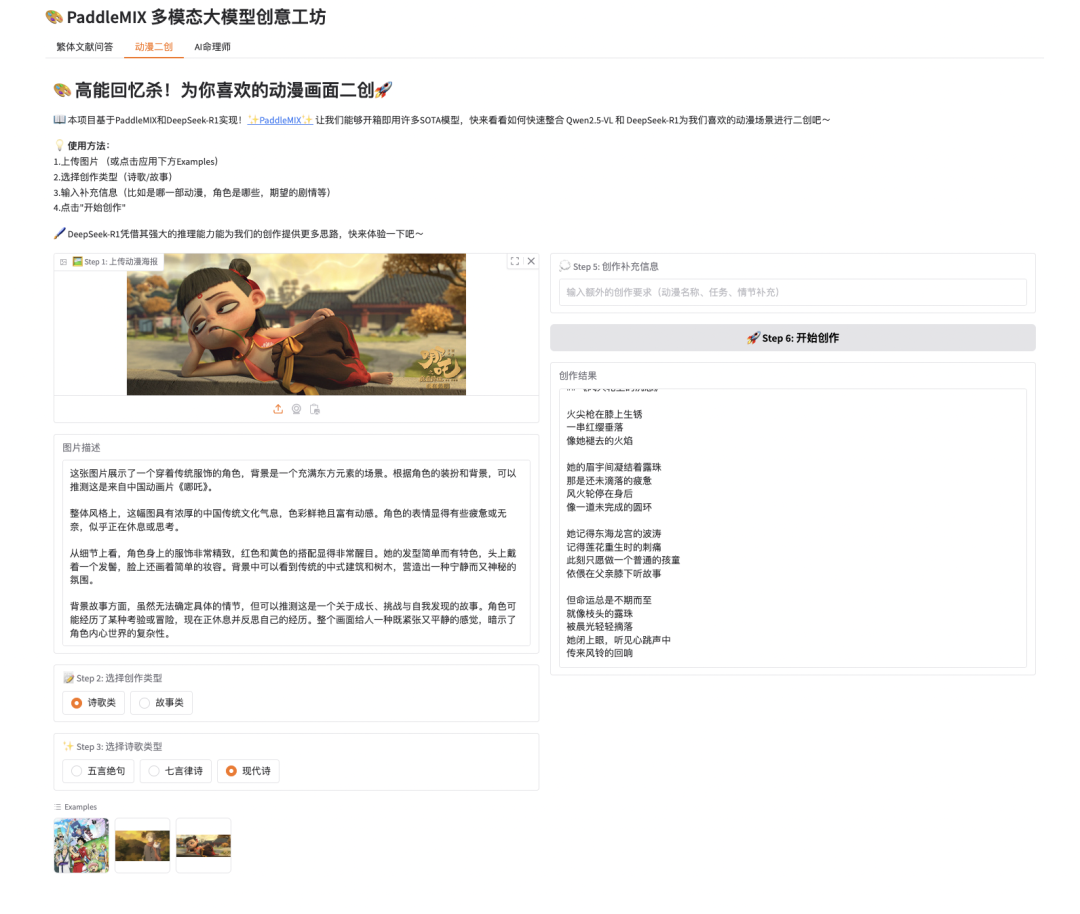
🎨 高能回忆杀!为你喜欢的动漫画面二创🚀:结合 Qwen2.5-VL 的图像理解与 DeepSeek-R1 的创意写作能力,将用户上传的动漫场景转化为富有情感和创意的故事或诗歌,让经典画面焕发新生。
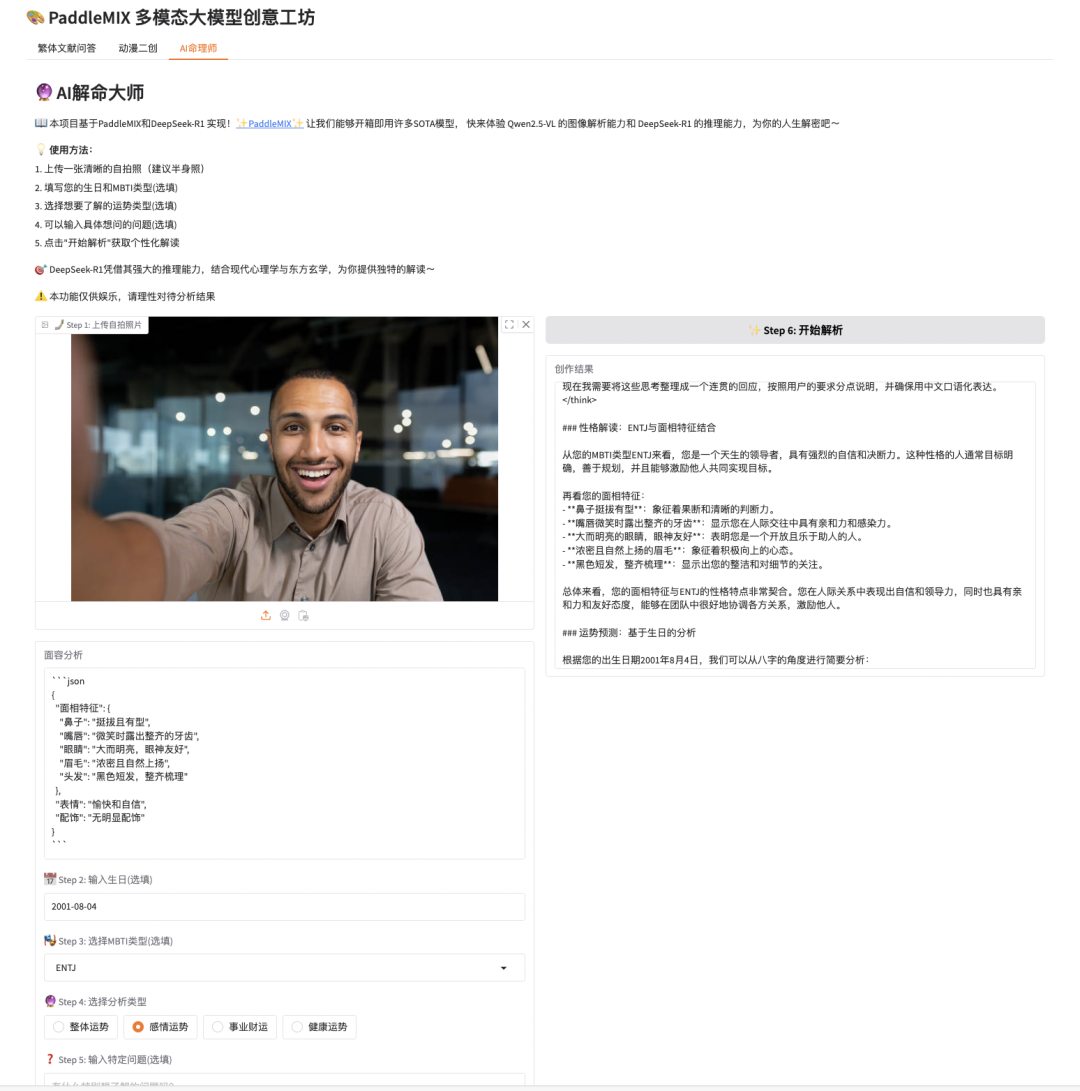
🔮 AI解命大师:通过 Qwen2.5-VL 识别用户上传的手相、面相或八字图片, DeepSeek-R1 进行深度分析并给出命理解读,以轻松幽默的方式为用户提供"命运指引"。
左右滑动查看更多
这三个应用的构建思路遵循相似的模式:首先利用 Qwen2.5-VL 强大的视觉理解能力对图像进行分析,再通过 DeepSeek-R1 进行深度的文本理解和生成。在技术实现层面,我们需要完成以下步骤:
模型加载:通过 PaddleMIX 模型库加载 Qwen2.5-VL 模型,同时调用 AIStudio 平台上已部署的 DeepSeek-R1 服务。
界面搭建:使用 Gradio 框架构建直观友好的交互界面,方便用户上传图片并获取分析结果。
提示词优化:精心设计和调优提示词(prompt),这是提升应用效果的关键因素。合适的提示词能够引导模型生成更准确、更有价值的内容。
通过这种"视觉理解+文本生成"的双模型协作方式,我们可以充分发挥两个模型各自的优势,打造出功能强大的多模态应用。下面开始进入实操环节。

应用构建

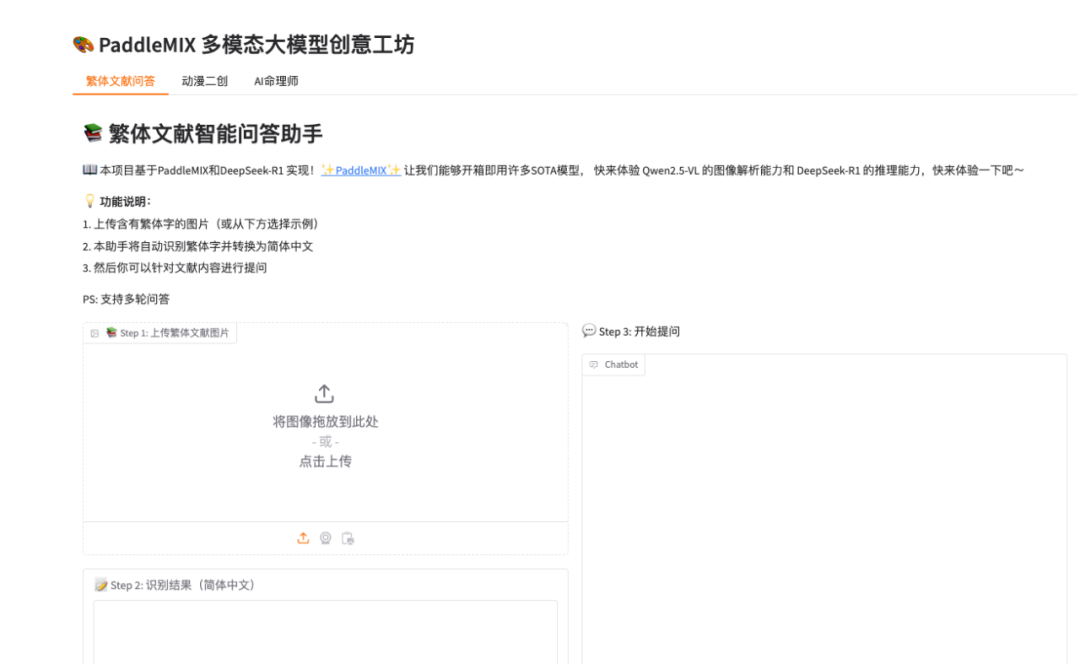
繁体文献智能问答助手
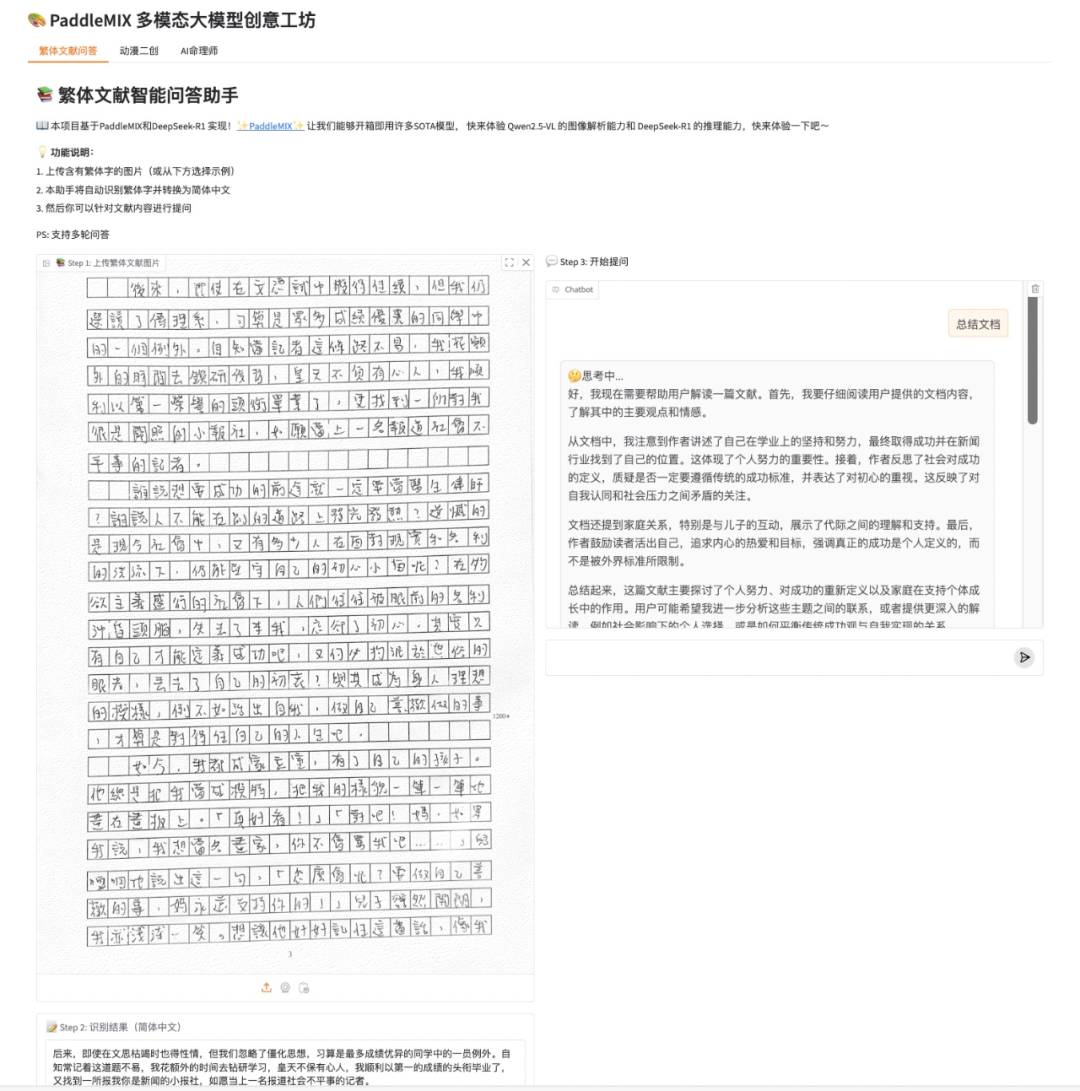
我们希望构建一个繁体文献智能问答助手,用户上传含有繁体字的图片,本助手将自动识别繁体字并转换为简体中文,然后用户可以针对文献内容进行提问。
为了实现这个智能问答助手,我们需要实现以下核心功能:
图片上传功能:支持用户上传含有繁体字的文献图片,包括繁体字文章、文献扫描件等。
繁体识别与转换:利用 Qwen2.5-VL 的图像识别能力自动识别图片中的繁体字,并智能转换为简体中文。
文献内容理解:基于 DeepSeek-R1 的文本理解能力,深入解读文献内容和上下文语境。
智能问答交互:用户可以针对文献内容进行提问,系统会给出尽可能准确、专业的解答。
首先,我们需要构建一个直观友好的 Gradio 界面。该界面主要包含以下功能:
支持用户上传含有繁体字的文献图片。
展示识别后的简体中文内容。
提供问答交互功能。
下面让我们来看看具体的界面实现代码。当用户上传图片后,系统会自动调用 analyze_traditional_texts 函数进行繁体字识别和转换,用户可以在识别结果的基础上,通过 chat_with_texts 函数进行智能问答交互,实现对文献内容的深入理解。
def create_interface():
"""创建主界面"""
with gr.Blocks(title="🎨 PaddleMIX 多模态大模型创意工坊") as interface:
gr.Markdown("# 🎨 PaddleMIX 多模态大模型创意工坊")
with gr.Tabs():
create_traditional_qa_tab()
return interface
def create_traditional_qa_tab():
"""创建繁体字识别问答标签页"""
with gr.Tab("繁体文献问答"):
gr.Markdown("# 📚 繁体文献智能问答助手")
with gr.Row():
with gr.Column():
image_input = gr.Image(type="pil", label="📚 Step 1: 上传繁体文献图片")
text_content = gr.Textbox(label="📝 Step 2: 识别结果(简体中文)", interactive=True, lines=10)
with gr.Column():
gr.Markdown("💬 Step 3: 开始提问")
gr.ChatInterface(
chat_with_texts,
additional_inputs=[text_content],
type="messages",
chatbot=gr.Chatbot(height=500),
theme="ocean",
cache_examples=True,
)
# 设置事件处理
image_input.change(fn=analyze_traditional_texts, inputs=[image_input], outputs=[text_content])下面,我们将着重实现两个关键的模型调用函数,以确保系统的高效运行与精准执行。
1. analyze_traditional_texts函数:
调用Qwen2.5-VL模型进行图片识别
将识别到的繁体字转换为简体中文
通过prompt "请识别图片中的繁体字,并转换为简体中文输出。格式要求和原文格式一致。输出简体字。"让Qwen2.5-VL模型更好地理解图片内容,输出简体字的同时,也保留了原文的格式。
2. chat_with_texts函数:
基于DeepSeek-R1模型实现智能问答
采用专业的系统提示词:“你是一个专业的文献解读专家。请基于以上文档内容和历史聊天记录回答用户问题。如果问题超出范围,请明确指出。" 确保回答的专业性和准确性
通过history_flag参数实现多轮对话功能,可根据需要保存或忽略历史对话记录
def analyze_traditional_texts(image):
"""识别图片中的繁体字"""
if not image:
return "请先上传图片"
prompt = "请识别图片中的繁体字,并转换为简体中文输出。格式要求和原文格式一致。输出简体字。"
for analysis in image_chat_model.generate_description(image, prompt):
yield analysis # 返回中间状态消息
if "请稍等,正在分析图片..." not in analysis:
return analysis
def chat_with_texts(message, history, text_content, history_flag=True):
# 输入验证
if not text_content:
yield "请先上传图片!"
return
try:
# 构建系统提示词
system_prompt = f"""你是一个专业的文献解读专家。
## 文档内容
{text_content}
请基于以上文档内容和历史聊天记录回答用户问题。如果问题超出范围,请明确指出。
"""
# 构建消息历史
messages = [{"role": "system", "content": system_prompt}]
# 添加历史对话
if history_flag and len(history) > 0:
for msg in history:
messages.append({"role": msg["role"], "content": msg["content"]})
# 添加当前问题
messages.append({"role": "user", "content": message})
completion = client.chat.completions.create(
model="deepseek-r1",
temperature=0.6,
messages=messages,
stream=True,
)
result = ""
for chunk in completion:
if hasattr(chunk.choices[0].delta, 'reasoning_content') and chunk.choices[0].delta.reasoning_content:
content = chunk.choices[0].delta.reasoning_content
elif hasattr(chunk.choices[0].delta, 'content') and chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
if content == "<think>":
result += "🤔思考中..."
yield result
continue
if content == "</think>":
result += "✨思考完成!"
yield result
continue
result += content
yield result + "\n\n⌛ 正在生成回答,请稍候..."
yield result
except Exception as e:
yield f"对话出错: {str(e)}"现在整体已经构建的差不多了!由于Qwen2.5-VL的调用逻辑三个应用都一样,我们将其封装成类,方便后续调用。ImageChatModel的generate_description方法则负责生成描述,包括处理输入、生成响应等步骤。
class ImageChatModel:
def __init__(self, model_path="Qwen/Qwen2.5-VL-3B-Instruct"):
self.model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_path, dtype="bfloat16", attn_implementation="eager"
)
self.image_processor = Qwen2_5_VLImageProcessor()
self.tokenizer = MIXQwen2_5_Tokenizer.from_pretrained(model_path)
min_pixels = 256 * 28 * 28 # 200704
max_pixels = 1280 * 28 * 28 # 1003520
self.processor = Qwen2_5_VLProcessor(
self.image_processor, self.tokenizer, min_pixels=min_pixels, max_pixels=max_pixels
)
def generate_description(self, image: np.ndarray, question: str) -> str:
"""生成描述"""
# 准备消息
if isinstance(image, np.ndarray):
image = Image.fromarray(image)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image,
},
{"type": "text", "text": question},
],
}
]
texts = [self.processor.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)]
# 处理输入
image_inputs, video_inputs = process_vision_info(messages)
yield "请稍等,正在分析图片..."
inputs = self.processor(
text=texts,
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pd",
)
# 生成响应
with paddle.no_grad():
generated_ids = self.model.generate(**inputs, max_new_tokens=512, temperature=0.01)
output_text = self.processor.batch_decode(
generated_ids[0], skip_special_tokens=True, clean_up_tokenization_spaces=False
)
yield output_text[0]
高能回忆杀!为你喜欢的动漫画面二创
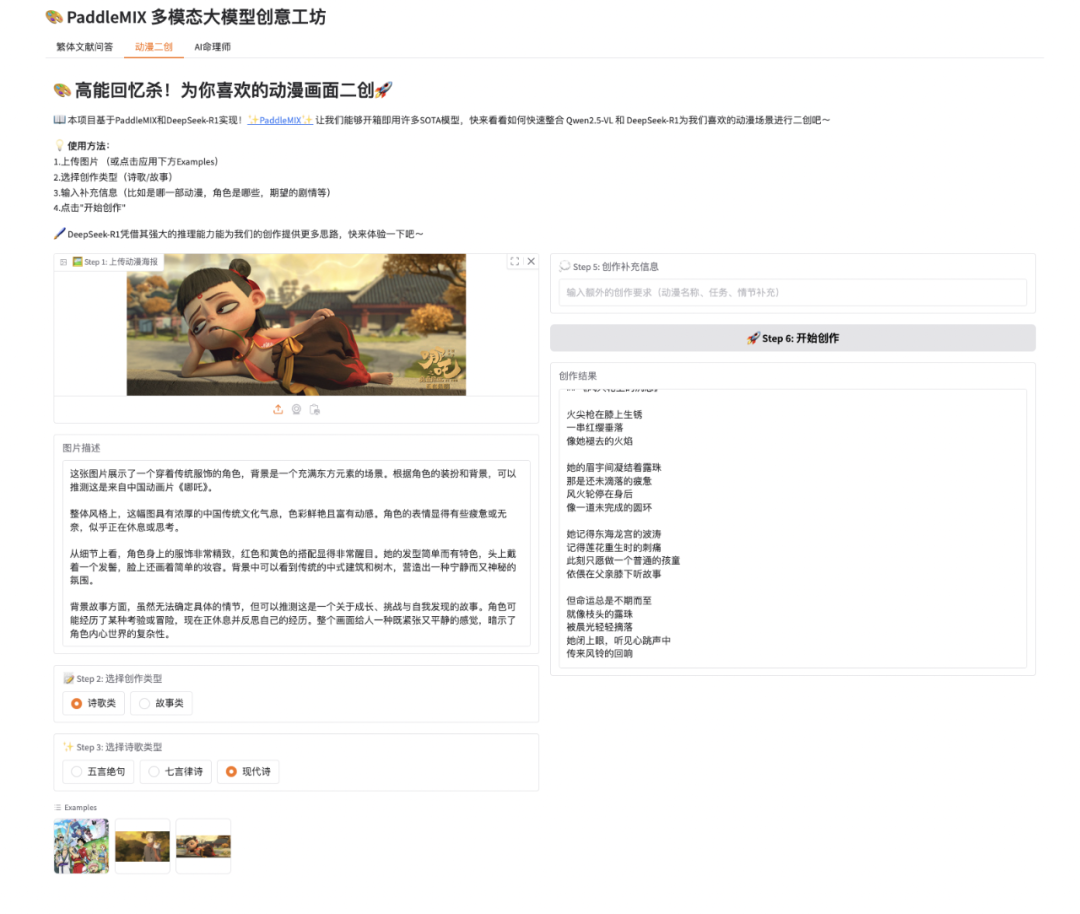
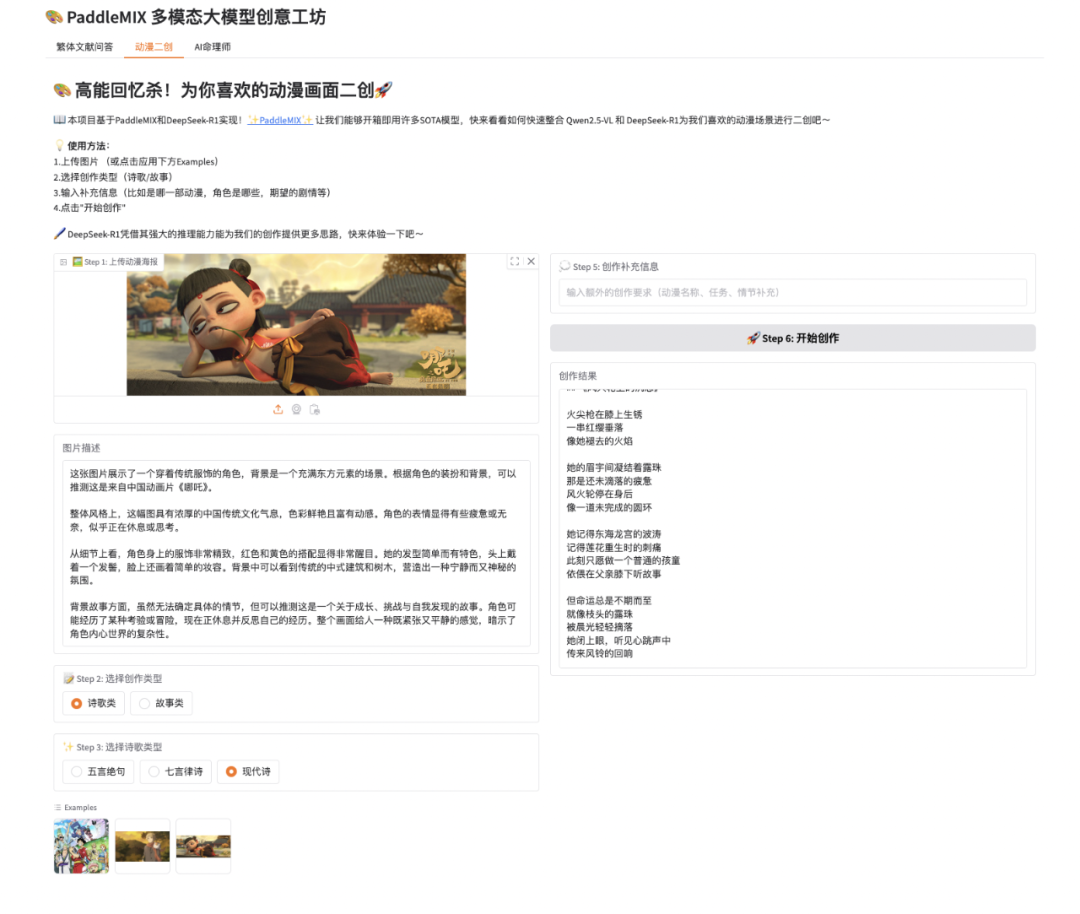
我们希望构建一个动漫二创助手,用户上传喜欢的动漫画面,本助手将自动分析图片内容并进行创意性的二次创作。
为了实现这个动漫二创助手,我们需要实现以下核心功能:
图片上传功能:支持用户上传动漫截图、插画等图片
图像分析:利用Qwen2.5-VL的图像识别能力自动分析动漫画面的内容、风格和情感
创意生成:基于DeepSeek-R1的创作能力,进行诗歌、故事等形式的二次创作
个性化定制:用户可以选择创作类型、风格,并提供补充信息来引导创作方向
首先,我们需要构建一个直观友好的Gradio界面。该界面主要包含以下功能:(1)支持用户上传动漫图片;(2)提供创作类型和风格的选择;(3)展示生成的创意内容
下面让我们来看看具体的界面实现代码,当用户上传图片后,会自动调用 analyze_image 函数进行图片分析,然后用户点击"开始创作"按钮后,会调用 anime_creation 函数进行创作。
def create_anime_creation_tab():
"""创建动漫二创标签页"""
with gr.Tab("动漫二创"):
gr.Markdown("# 🎨 高能回忆杀!为你喜欢的动漫画面二创🚀")
with gr.Row():
with gr.Column():
image_input = gr.Image(type="pil", label="🖼️ Step 1: 上传动漫海报")
image_analysis = gr.Textbox(label="图片描述", interactive=False)
with gr.Group() as creation_type_group:
creation_type = gr.Radio(choices=["诗歌类", "故事类"], label="📝 Step 2: 选择创作类型", value="诗歌类")
with gr.Group() as poem_group:
style_type_poem = gr.Radio(choices=["五言绝句", "七言律诗", "现代诗"], label="✨ Step 3: 选择诗歌类型", value="现代诗")
with gr.Group(visible=False) as story_group:
style_type_story = gr.Radio(choices=["微小说", "剧本大纲", "分镜脚本"], label="✨ Step 3: 选择故事类型", value="微小说")
style = gr.Radio(
choices=["热血", "治愈", "悬疑", "古风", "科幻", "日常"], label="🎨 Step 4: 选择创作风格", value="治愈"
)
with gr.Column():
custom_prompt = gr.Textbox(label="💭 Step 4: 创作补充信息(选填)", placeholder="输入额外的创作要求(动漫名称、任务、情节补充)")
generate_btn = gr.Button("🚀 Step 5: 开始创作")
progress_status = gr.HTML(
visible=False,
value="""
<div style="padding: 1rem; border-radius: 0.5rem; background-color: #f3f4f6; margin-bottom: 1rem;">
<p style="margin: 0; display: flex; align-items: center; gap: 0.5rem;">
<span style="display: inline-block; animation: spin 1s linear infinite;">✨</span>
<span id="progress-message">正在构思创意...</span>
</p>
</div>
""",
)
output_text = gr.Textbox(label="创作结果", interactive=False)
# 设置事件处理
setup_events(
image_input,
image_analysis,
creation_type,
story_group,
poem_group,
generate_btn,
style_type_poem,
style_type_story,
style,
custom_prompt,
output_text,
)
generate_btn.click(
fn=anime_creation,
inputs=[
image_input,
image_analysis,
creation_type,
style_type_poem,
style_type_story,
style,
custom_prompt,
],
outputs=[output_text],
)下面我们来实现模型调用的两个核心函数:
1. analyze_image函数:
调用Qwen2.5-VL模型进行动漫图片识别
通过精心设计的prompt让模型分析动漫场景、人物和风格
通过prompt “请描述这个动漫图片,需要1. 推测动漫是哪一部;2. 给出图片的整体风格;3.描述图像中的细节,并推测可能的背景故事。"让Qwen2.5-VL模型深入理解动漫画面的内容和情感
2. anime_creation函数:
基于DeepSeek-R1模型实现创意二创
采用专业的系统提示词:“你是一个了解动漫,富有才情的作家,能根据图片描述和创作要求进行创作” 确保创作的专业性和趣味性
支持诗歌和故事两种创作形式,可以根据用户选择的风格(如热血、治愈、悬疑等)进行个性化创作
通过自定义prompt支持用户补充创作要求,让创作更贴合用户期望
def analyze_image(image):
if not image:
return "请先上传图片"
prompt = "请描述这个动漫图片,需要1. 推测动漫是哪一部;2. 给出图片的整体风格;3.描述图像中的细节,并推测可能的背景故事。"
for analysis in image_chat_model.generate_description(image, prompt):
yield analysis # 返回中间状态消息
if "请稍等,正在分析图片..." not in analysis:
return analysis
def anime_creation(
image, image_analysis, creation_type, poem_type, story_type, style, custom_prompt, progress=gr.Progress()
):
"""生成创作内容"""
if not image:
return "请先上传图片"
progress(0.2, desc="🎨 正在构思创意...")
if creation_type == "诗歌类":
req = f"请创作一首{poem_type}, 需要取诗歌的名字"
else:
req = f"请创作{style}风格的{story_type},需要取章节名"
prompt = f"""
你是一个了解动漫,富有才情的作家,能根据图片描述和创作要求进行创作
## 图片描述
{image_analysis}
## 创作要求
1. {req}
2. 内容上贴合图片描述,创作风格贴合图片的风格,尽可能推断出这个动漫是什么,人物有哪些
3. 如果有自定义需求:{custom_prompt},需要满足;没有不需要。
"""
progress(0.4, desc="✍️ 正在创作中...")
completion = client.chat.completions.create(
model="deepseek-r1",
temperature=0.6,
messages=[
{"role": "user", "content": prompt}
],
stream=True,
)
result = ""
for chunk in completion:
if hasattr(chunk.choices[0].delta, 'reasoning_content') and chunk.choices[0].delta.reasoning_content:
result += chunk.choices[0].delta.reasoning_content
else:
result += chunk.choices[0].delta.content
yield result + "\n\n⌛ 创作火力全开中,请稍候..."
# progress(1.0, desc="✅ 生成完成!")
yield result
AI解命大师
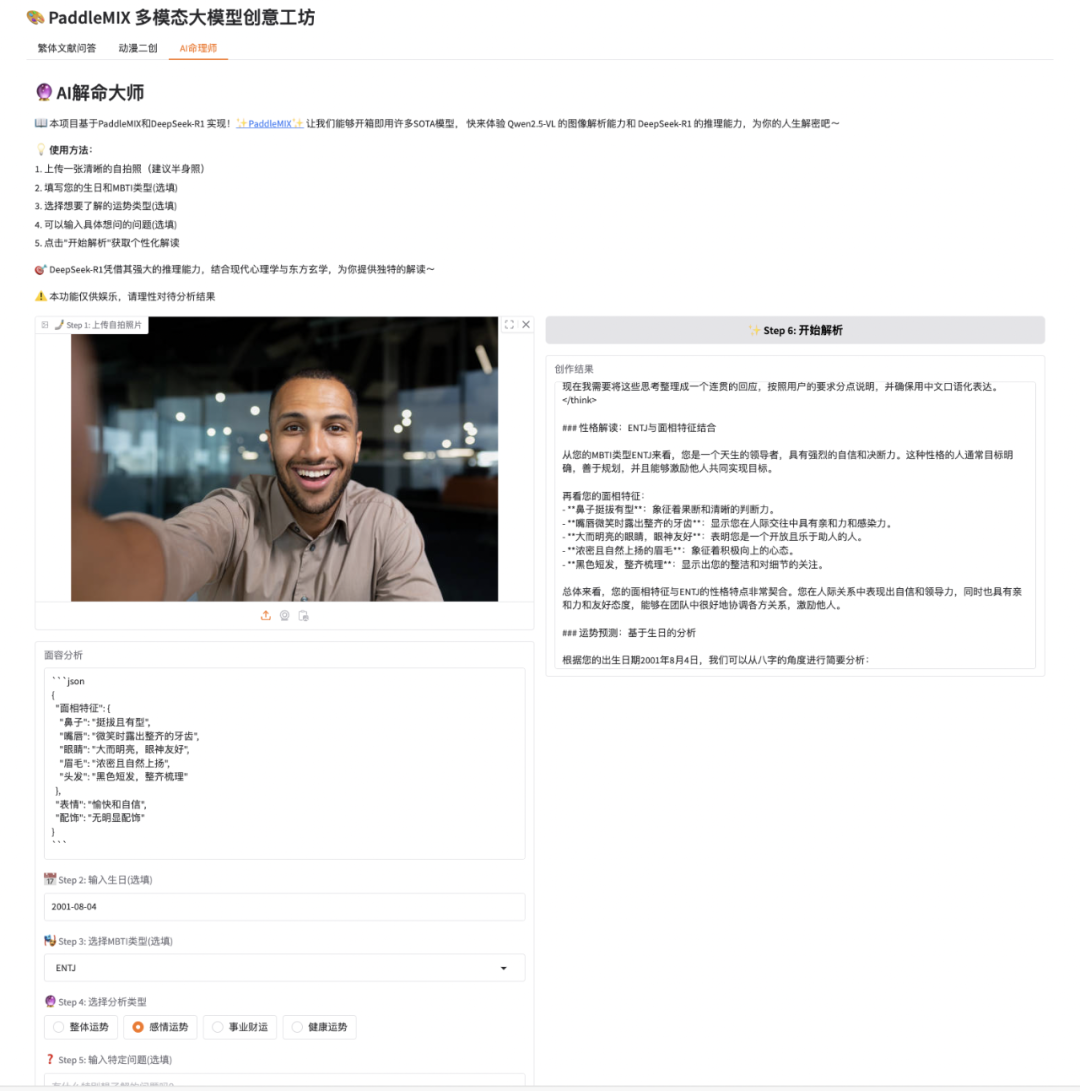
我们希望构建一个 AI 解命大师,用户上传自拍照,本助手将自动分析面相并进行个性化的命理解读。
为了实现这个 AI 解命大师,我们需要实现以下核心功能:
图片上传功能:支持用户上传清晰的自拍照(建议半身照)
图像分析:利用 Qwen2.5-VL 的图像识别能力自动分析面相特征、气质和神态
命理解读:基于 DeepSeek-R1 的推理能力,结合现代心理学与东方玄学进行个性化解读
个性化定制:用户可以填写生日、MBTI 类型,选择想要了解的运势类型,并提供具体问题来引导解读方向
首先,我们需要构建一个直观友好的 Gradio 界面。该界面主要包含以下功能:(1)支持用户上传自拍照;(2)提供生日、MBTI类型、运势类型等信息的填写;(3)展示生成的个性化解读内容
下面让我们来看看具体的界面实现代码,当用户上传图片后,会自动调用 analyze_face 函数进行面相分析,然后用户点击"开始解析"按钮后,会调用analyze_fortune 函数进行命理解读。
def create_fortune_tab():
"""创建AI命理师标签页"""
with gr.Tab("AI命理师"):
gr.Markdown("# 🔮 AI解命大师")
with gr.Row():
with gr.Column():
image_input = gr.Image(type="pil", label="🤳 Step 1: 上传自拍照片")
image_analysis = gr.Textbox(label="面容分析", interactive=False)
birthday = gr.Textbox(label="📅 Step 2: 输入生日(选填)", placeholder="格式:YYYY-MM-DD", value="")
mbti_type = gr.Dropdown(
choices=[
"无",
"INTJ",
"INTP",
"ENTJ",
"ENTP",
"INFJ",
"INFP",
"ENFJ",
"ENFP",
"ISTJ",
"ISFJ",
"ESTJ",
"ESFJ",
"ISTP",
"ISFP",
"ESTP",
"ESFP",
],
label="🎭 Step 3: 选择MBTI类型(选填)",
value="无"
)
analysis_type = gr.Radio(
choices=["整体运势", "感情运势", "事业财运", "健康运势"], label="🔮 Step 4: 选择分析类型", value="整体运势"
)
custom_question = gr.Textbox(label="❓ Step 5: 输入特定问题(选填)", placeholder="有什么特别想了解的问题吗?")
with gr.Column():
generate_btn = gr.Button("✨ Step 6: 开始解析")
output_text = gr.Textbox(label="创作结果", interactive=True)
# 设置事件处理
image_input.change(fn=analyze_face, inputs=[image_input], outputs=[image_analysis])
generate_btn.click(
fn=analyze_fortune,
inputs=[image_input, image_analysis, birthday, mbti_type, analysis_type, custom_question],
outputs=[output_text],
)下面我们来实现模型调用的两个核心函数:
1. analyze_face 函数:
调用 Qwen2.5-VL 模型进行面相分析
通过精心设计的 prompt 让模型分析面相特征、气质和神态
通过 prompt "请详细描述此人的性别,面相特征,包括美貌长相、五官、表情、配饰等细节,输出为 JSON 格式,中文。" 让 Qwen2.5-VL 模型深入理解面相的特征和气质
2. analyze_fortune 函数:
基于 DeepSeek-R1 模型实现命理解读
采用专业的系统提示词:“你是一位专业的 AI 命理师,擅长将现代心理学与东方玄学相结合。xxx” 确保命理解读的专业性和趣味性
支持整体运势、感情运势、事业财运、健康运势四种分析类型,可以根据用户选择的分析类型进行个性化解读
通过自定义 prompt 支持用户补充特定问题,让命理解读更贴合用户期望。
def analyze_face(image):
if not image:
return "请先上传图片"
"""分析面容特征"""
image_prompt = "请详细描述此人的性别,面相特征,包括美貌长相、五官、表情、配饰等细节,输出为JSON格式,中文。"
for analysis in image_chat_model.generate_description(image, image_prompt):
yield analysis # 返回中间状态消息
if "请稍等,正在分析图片..." not in analysis:
return analysis
def analyze_fortune(
image, image_analysis, birthday, mbti_type, analysis_type, custom_question, progress=gr.Progress()
):
"""分析运势"""
if not image:
return "请先上传照片"
if not image_analysis:
return "请先等待图片分析结果"
# progress(0, desc="正在启动 AI 命理师...")
yield "分析中..."
# 生成命理分析
# progress(0.4, desc="🎯 正在解读命理...")
prompt = f"""
你是一位专业的AI命理师,擅长将现代心理学与东方玄学相结合。
## 图像分析
{image_analysis}
## 用户信息
- 生日:{birthday}
- MBTI:{mbti_type}
- 分析类型:{analysis_type}
- 特定问题:{custom_question if custom_question else "无"}
请根据以上信息进行分析:
1. 结合性别、面相特征和MBTI给出性格解读
2. 基于生日和当前时间给出运势预测
3. 针对用户选择的分析类型给出具体建议
4. 如果有特定问题,请特别关注相关方面
注意:保持专业性的同时要适当融入趣味性,最后注明"本结果仅供娱乐"。
"""
completion = client.chat.completions.create(
model="deepseek-r1",
temperature=0.6,
messages=[
{"role": "user", "content": prompt}
],
stream=True,
)
result = ""
for chunk in completion:
if hasattr(chunk.choices[0].delta, 'reasoning_content') and chunk.choices[0].delta.reasoning_content:
result += chunk.choices[0].delta.reasoning_content
else:
result += chunk.choices[0].delta.content
yield result + "\n\n⌛ 正在生成中,请稍候..."
# progress(1.0, desc="✅ 生成完成!")
yield result最终将三个标签页整合到一起,并启动Gradio服务,就可以在本地浏览器中访问我们的趣味应用了~
def create_interface():
"""创建主界面"""
with gr.Blocks(title="🎨 PaddleMIX 多模态大模型创意工坊") as interface:
gr.Markdown("# 🎨 PaddleMIX 多模态大模型创意工坊")
with gr.Tabs():
create_traditional_qa_tab()
create_anime_creation_tab()
create_fortune_tab()
return interface
def main():
"""主函数"""
interface = create_interface()
interface.queue()
、
interface.launch(
share=True,
ssr_mode=False,
max_threads=1 # 限制并发请求数
)
if __name__ == "__main__":
main()
应用部署
下面进入应用部署部分,这部分将介绍我们如何在AI Studio上调用免费的DeepSeek-R1模型以及如何基于Gradio部署趣味应用。

调用免费的DeepSeek-R1模型API
在上文讲到的三个应用中,我们通过下面的方式实现调用DeepSeek-R1服务,这里缺失了client的定义,下面让我们补全这部分。
completion = client.chat.completions.create(
model="deepseek-r1",
temperature=0.6,
messages=messages,
stream=True,
)
result = ""
for chunk in completion:
if hasattr(chunk.choices[0].delta, 'reasoning_content') and chunk.choices[0].delta.reasoning_content:
result += chunk.choices[0].delta.reasoning_content
else:
result += chunk.choices[0].delta.content
yield result + "\n\n⌛ 创作火力全开中,请稍候..."访问飞桨星河社区AI Studio,找到我们独属的访问令牌,然后复制替换下方代码中的{api_key},接下来我们就可以免费使用DeepSeek-R1服务啦~ 对这部分还有疑问的朋友可以查阅帮助文档,有更详细的讲解。
访问令牌:
https://aistudio.baidu.com/account/accessToken
帮助文档:
https://ai.baidu.com/ai-doc/AISTUDIO/rm344erns#打印思维链(deepseek-r1)
from openai import OpenAI
client = OpenAI(
api_key="{api_key}",
base_url="https://aistudio.baidu.com/llm/lmapi/v3"
)示例:
image_file="PaddleMIX/applications/MULLM/examples/haizeiwang.jpeg"
visualize_image(image_file)
image_analysis = analyze_image(image_file)
print(image_analysis)
print(anime_creation(image_analysis, "诗歌类", "现代诗", "", "", ""))输出:

这张图片来自动漫《海贼王》(One Piece)。整体风格充满了活力和动感,色彩鲜艳,人物表情生动,背景充满了樱花瓣飘落的浪漫氛围。
图片中的人物包括:
中间穿着红色披风的角色是主角路飞(Luffy),他手持剑,面带微笑。
左边是一个戴着绿色头巾、手持刀的角色,可能是索隆(Sorosu)。
右边是一个穿着黄色衣服、手持帽子的角色,可能是山治(Sanji)。
最后一个角色穿着绿色帽子,可能是乔巴(Jabberwocky)。
背景中有许多樱花树,天空晴朗,给人一种春天的感觉。这些元素共同营造出一种轻松愉快的氛围,可能是某个节日或特殊场合。
好的,用户让我根据《海贼王》的图片描述写一首现代诗,还要起个名字。首先,我需要确认图片中的主要元素:路飞、索隆、山治、乔巴,樱花背景,整体氛围轻松愉快。
用户希望诗歌贴合图片风格,也就是充满活力和动感,色彩鲜艳。我得用生动的意象和明快的节奏来表现。现代诗不需要押韵,但要有画面感和情感。
首先考虑诗的结构。可能需要分几个小节,每个部分对应不同人物或场景。比如开头用樱花作为背景,中间描绘各个角色,最后点出冒险的主题。
名字方面,要抓住樱花和冒险的结合,比如“樱瓣与草帽的狂想曲”既有画面感又点出草帽海贼团。
接下来是具体诗句。路飞在中间,红色披风,手持剑,微笑。可以用“红披风切开风的果核”这样的比喻,表现他的活力和力量。索隆的三把刀和绿色头巾,用“三柄月光”来象征,既有色彩又有动态。山治的黄色衣服和踢技,用“黄金螺旋”形容他的动作,樱花被气流卷起。乔巴的可爱和樱花帽子,可以写“樱花落在驯鹿的帽檐”。
然后要处理整体氛围,樱花纷飞的背景和伙伴们的互动,用“刀刃与拳锋是另一种落樱”连接战斗与美景。结尾点出冒险和自由的主题,用“春天在甲板上永不靠岸”表达他们的旅程永不停歇。
检查是否涵盖所有元素:人物特征、樱花背景、欢乐氛围,以及海贼王的冒险精神。有没有遗漏的部分?比如背景的晴朗天空,可能在诗中用“天空蓝得近乎透明”来表现。
最后调整语言,让诗句流畅,有节奏感,同时保持现代诗的自由。避免生硬,确保每句之间有自然的过渡。这样应该符合用户的要求了。
《樱瓣与草帽的狂想曲》
天空蓝得近乎透明时
三柄月光在绿藻头少年的腰间苏醒
草帽压住风的褶皱 红披风切开
季风最柔软的果核
黄金螺旋踢出樱花雪的涟漪
山治的烟圈悬停在半空
像一串未完成的海图坐标
驯鹿的帽檐接住整个春天的绒毛
那些粉红在刀刃上跳弗朗明戈
刀刃与拳锋是另一种落樱
在鸥鸟的瞳孔里绽放
我们撕碎云层当入场券
闯入新世界的花见酒宴
盐粒与砂糖在船帆顶端结晶成银河
当金属碰撞声震落花瓣雨
橡胶拳头击碎镜面般的海平线
所有誓言都浸泡在
梅利号甲板永不消散的樱花酿里
(注:末句"梅利号"是草帽海贼团的首艘海贼船,承载着整个团队最初的羁绊与冒险记忆。)
向上滑动查看更多

部署Gradio应用
通过解析代码我们也更深入地理解应用的实现细节和技术创新,快跟着我们的aistudio教程一起来动手实践一下吧!
访问AI Studio 教程:
https://aistudio.baidu.com/projectdetail/8940626
教程里面包含手把手带大家构建用一张V100 32G显卡构建基于Qwen2.5-VL 3B模型 + DeepSeek-R1(API调用)的三个趣味应用。提示:要求更好效果可以选用7B模型。
下面展示部署Gradio应用环节,进行fork,“启动环境”进入运行操作,请注意选择V100 32G或A100 40G。
1. 运行代码
cd work
tar -xvf serve.tar2. 在serve/app_deploy中填写你的key
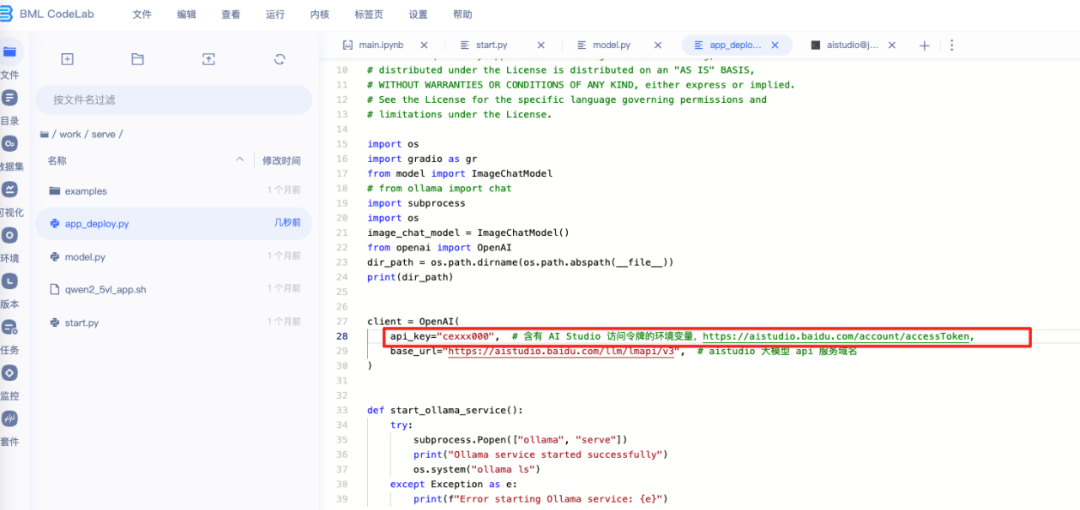
3. 更新应用发布
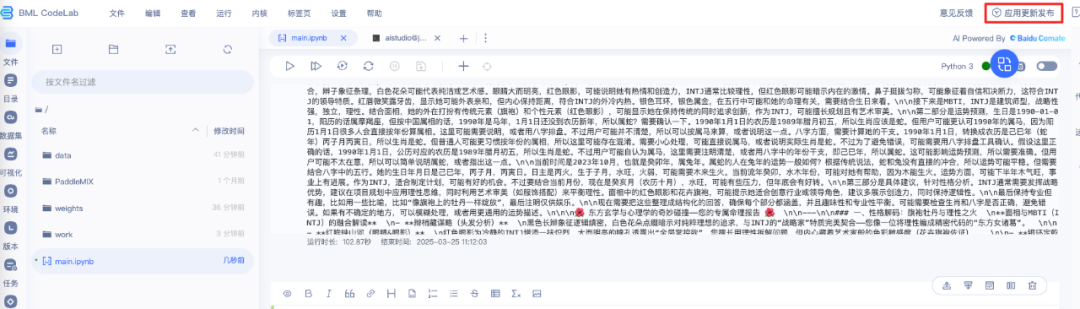
4. 新建repo,选择gradio版本,repo名称
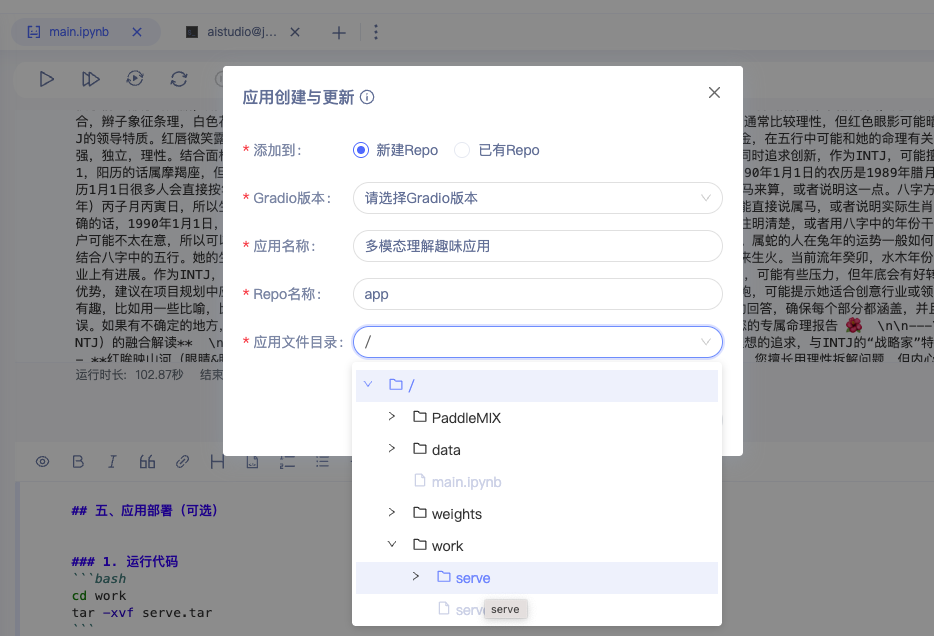
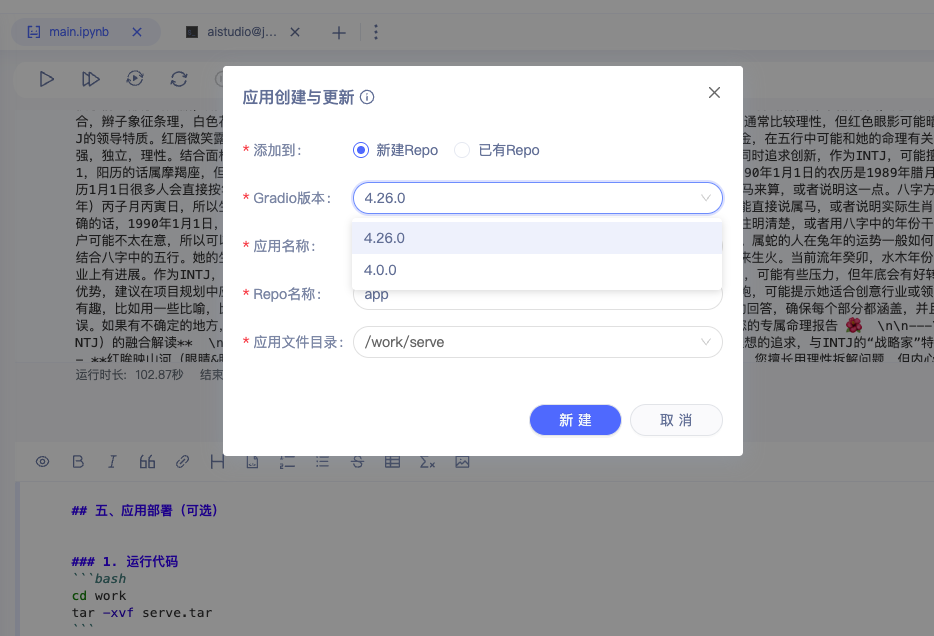
左右滑动查看更多
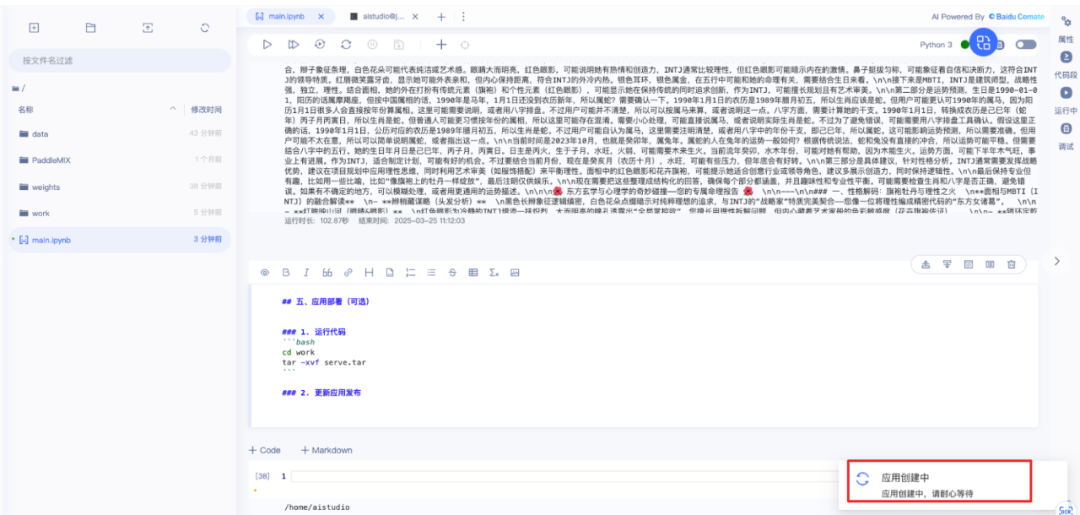
5. 等待应用创建完成
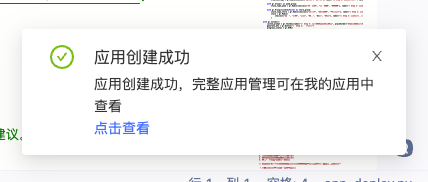
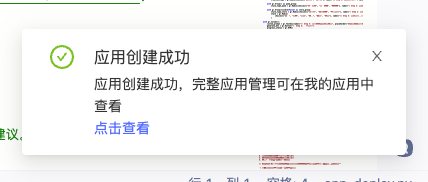
6. 点击查看,填写发布更新应用信息,可选择公开,注意选择GPU套餐
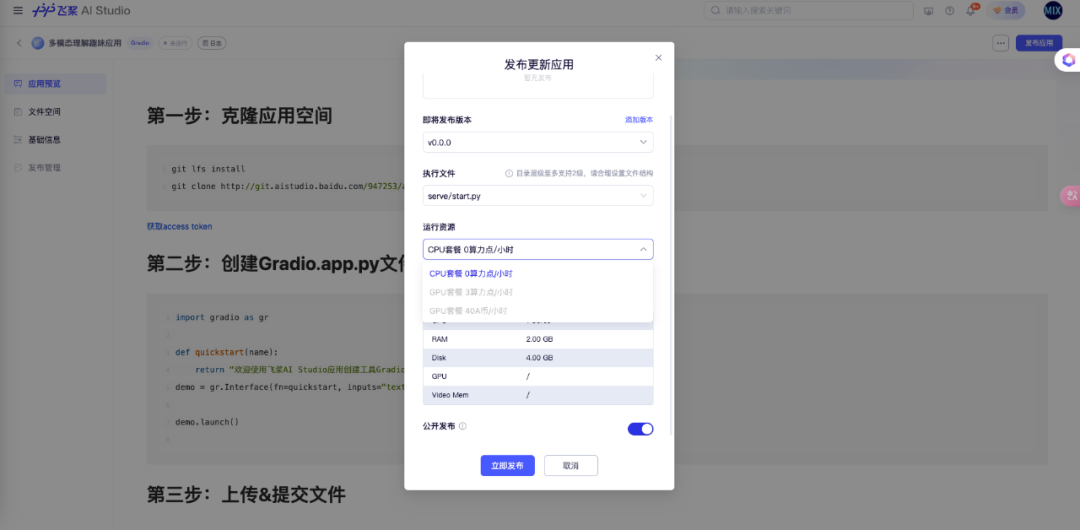
等待后台日志发布完成,可以点击试玩你的应用了~

总结
本文介绍了基于 PaddleMIX 套件构建的三个多模态理解应用实例。我们结合了 Qwen2.5-VL 在视觉理解方面的优势和 DeepSeek-R1 在中文理解和推理方面的特长,实现了:
📚 繁体文献智能问答助手:通过识别繁体文字并转换为简体中文,帮助用户快速理解古籍内容并进行智能问答。
🎨 动漫场景二次创作:将用户上传的动漫场景转化为富有创意的故事或诗歌,为经典画面注入新的生命力。
🔮 AI解命大师:基于面相、手相等图片进行命理分析,以轻松幽默的方式为用户提供个性化解读。
通过这些应用的构建过程,我们不仅展示了多模态大模型的强大能力,也为读者提供了完整的实践指南,包括模型加载、界面搭建、提示词优化等关键步骤。相信这些经验能够帮助更多开发者快速上手多模态应用开发,探索更多有趣的应用场景。
通过实践这些案例,大家可以更好地理解多模态模型的应用方法,并在此基础上开发出适合自己需求的应用。
为了帮助您深入理解应用构建思路及代码实现细节,基于PaddleMIX实操使用Qwen2.5 - VL和DeepSeek - R1开发属于你自己的文档图像理解、智能教育辅导、动漫角色设计、命理看相分析等创新应用,我们将开展“多模态大模型PaddleMIX产业实战精品课”。3月31日正式开营,报名即可免费获得项目消耗算力(限时一周),名额有限,立即扫描下方二维码预约吧!

应用体验(访问下方链接试玩):
https://aistudio.baidu.com/application/detail/65916
项目地址:
Qwen2.5-VL+R1 应用:
https://github.com/PaddlePaddle/PaddleMIX/tree/develop/applications/MULLM
Qwen2.5-VL:
https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/examples/qwen2_5_vl
AI Studio 教程:
https://aistudio.baidu.com/projectdetail/8940626
论文链接:
Qwen2.5-VL:
https://arxiv.org/pdf/2502.13923
DeepSeek-R1:
https://arxiv.org/pdf/2501.12948






关注【飞桨PaddlePaddle】公众号
获取更多技术内容~


















 2745
2745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









