






Kubernetes是什么?
我们都知道容器和Docker,那么k8s是什么呢,我们不妨先回顾一下web应用开发的历史。
- 单体应用:应用的所有功能都放在一起,统一部署在一台机器上。这样部署的好处是特别方便,但是非常影响开发和发布效率,因为发布和部署需要多个团队来协调。
- 服务拆分:于是微服务开始出现,把单体服务按业务功能进行拆分。一个单体应用拆分出若干微服务。微服务提升了单个服务的开发部署效率。但是,随着服务数量的增加,管理复杂度成指数上升,同时每个服务都需要单独的机器资源,也可能造成资源浪费。
同时,部署环境也经历如下阶段
- 裸机部署:一个或者多个应用直接部署到物理机上。这样应用之间会互相影响,同时资源利用率也不高。
- 虚拟机部署:虚拟机解决了裸机部署的隔离问题,但是启动速度太慢,资源利用率也不高。
- 容器化部署:以Docker为代表的容器化部署解决了虚拟机的大部分问题。
因此,当前是微服务开发和容器化部署结合的阶段,需要一个平台来简化开发人员部署应用到容器中。这就是k8s要解决的问题,它帮助开发人员部署和管理容器化应用。它不是Docker的替代者,而是基于底层的容器引擎(Docker或者其他容器化方案)来部署和管理应用的平台。
Kubernetes is a software system that allows you to easily deploy and manage containerized applications on top of it.

开发人员只需要定义应用的规范(比如需要什么样的容器,需要几个),然后k8s会在集群里面把找到合适的机器把容器给运行起来。如果机器挂掉了,k8s会自动把容器运行到另外一台机器上。
k8s的总体结构

k8s的总体结构为master&slave架构,如上图所示:
1 master节点:为集群的控制平面,里面的几个组件的功能后面在详细介绍。或参考:
Kubernetes基本概念简介_kubernetes集群的基本概念-CSDN博客
2 worker节点:上面运行实际的容器,kubelet是worker节点上负责和master节点通信的守护进程。Container Runtime就是容器引擎,如Docker。

- 开发人员将应用打包为docker image推送到image registry里面
- 开发人员将应用运行环境要求(app manifest)提交给k8s master节点
- worker节点上的kubelet收到master的通知,按照app manifest启动容器
- 容器从image registry里面拉取应用image,并启动应用。
以上为应用在k8s中运行的基本流程。
Pod
从前面的介绍可以知道,应用是运行在容器里面,容器运行在Docker环境中,Docker是运行在操作系统之上。那Pod又是什么鬼?我们遇到的多数应用基本只需要一个容器。有的应用是需要多个容器配合起来才能运行的,那么就需要一个“东西”把这多个容器放在一起,让这些容器感觉是运行在同一台机器上,这个东西就是Pod。因为Pod有独立的hostname、ip地址,所以很多地方把Pod对比为虚拟机。
Pod基础
容器,Pod和Node的关系
下图是container, pod和node的逻辑关系,应用是运行在container里面。

Pod的实现方式:Pod本质上也是一个容器,它提供了其他容器运行的namespace(不是k8s的namespace),如下图所示。在node上执行"docker ps",可以发现很多命令为"/pause"的容器,它们就是Pod的infrastructure container了。

Pod是k8s中最基本的部署单元。

Pod是k8s中最基本的部署单元。因为Pod本质也是一个容器,所以Pod中的容器是不能分布在不同的机器上的。
不同Node上的Pod的网络是互通,这样Pod才能类比虚拟机。这个是k8s的规范要求,依赖底层网络插件的实现。

一个容器不运行多个进程,不相关的容器不要运行在同一个Pod中。

Pod标签
可以给Pod加上若干标签,如下图所示,标签在后面很多地方都会用到。

除了标签以外,还可以给Pod加上annotation,它和标签的区别是:标签名称较短,且可以根据标签来找到Pod。annotation可以放很长字符串,类似备注。
如何创建Pod?
既然Pod可以类比虚拟机,那么你可能想要创建出一个Pod出来玩玩。首先看看我们和k8s是怎么交互的,如下图示,我们在本地机器上通过kubectl命令行工具,与master节点上的APIServer通信,完成所有k8s的相关操作。

创建Pod需要首先定义Pod的manifest,然后让k8s master按照manifest创建出Pod。
Pod的manifest是采用json或者yaml格式定义的,以下为一个最简单的pod定义(my-pod.yaml):
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- image: public/my-awesome-image
name: my-container
ports:
- containerPort: 8080
protocol: TCP它包括几部分:
- kind表示需要创建的是Pod,后面还会看到其他类型的资源
- metadata: 是Pod的元数据,这里只是设置其名称为my-pod
- spec:Pod中容器的定义,这里将从public/my-awesome-image创建一个名称为my-container,并开放8080端口的容器。
然后就可以用命令 kuebctl create -f my-pod.yaml 来创建Pod了。(这里只是简单描述一下,可以参考minikube的相关文档在本地建立单个节点的测试集群)
Pod是运行起来了,但作为一个有经验的开发人员,你可能会有一大堆问题,比如:
- 如何保证Pod的高可用,Pod挂了怎么办?
- 如何创建多个Pod,为应用提供水平扩展能力?
- 如何将Pod提供的服务对外暴露?
- 如何升级Pod?
- ...
接下来,我们来看k8s是如何解决这些问题的。
Beyond Pod: Tell me your dream
K8s的设计原则之一是:声明式优于命令式,就是说你告诉k8s你的愿望,它帮你实现。而不是你告诉k8s做什么。虽然上面我们已经创建出了一个Pod,但是在实际的应用场景下我们通常不直接创建Container,也不直接创建Pod。那我们想要得到高可用的容器集群的愿望如何实现呢?k8s提供了如下的方式来实现你的愿望。
ReplicationController(RC)/ReplicaSet(RS)
RC/RS是确保某个类型的Pod在集群中保持一定数量的副本数。通过它,k8s帮你实现“我希望的应用在集群中总是有x个节点”。它们二者很类似,RS是RC的替代版本,现在基本是用RS。一个RS包括以下几个部分:
- 标签选择器:通过它,RS能找到属于它管理的那些Pod
- replica count: 表示需要运行几个副本
- pod template: pod的模板,当前运行的副本数小于预期数量,将基于该模板创建出新Pod实例。

以下是创建一个RS的manifest,供参考
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 2
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
protocol: TCP类似的,也是通过命令行 kubectl create -f my-rs.yaml 来创建出RS,然后k8s将创建出对应数量的Pod。同时,该RS将监控集群中Pod的数量,使其数量和预期的数量一致。
其流程图可用下图表示

RS是通过标签来识别Pod,并保持Pod的数量的。
- 如果手动将Pod的标签移除(或者删除一个Pod),那么RS将会创建出一个新的Pod补足,旧的Pod将不受RS的管理。
- 如果手动创建出了一个有相同标签的Pod,那么k8s将销毁一个Pod,保持Pod数量与预期一致。
如下图示:

修改Pod的template
如果修改Pod的template,那么RS会怎么样?答案是,RS只管Pod的标签,并不管Pod运行的是什么image。如果更改了Pod的template,那么只会影响到新创建出的Pod。如下图示,更改了template,然后删除一个Pod,新创建的Pod使用新的模板,已有的Pod还是老的模板。这可以作为一种升级容器版本的方法。后面会介绍更好的方案。

Deployment
我们说k8s是声明式的,但是上面讲到当更改了RS的template(比如更改了container的image),RS不会重新部署Pod,已有的Pod还是运行老的image。这和预期有点不一样啊,期望的应该是k8s会自动调整Pod,使运行中的Pod的image与manifest中一致。
Deployment就是实现这个目标的。Deployment是基于ReplicaSet来实现的,Deployment会自动创建ReplicaSet。

当调整了Deployment中Pod template之后,如果需要升级容器(比如image变了),那么Deployment会滚动对Pod进行升级(实际是创建新的Pod,同时把老的Pod给销毁掉)。滚动升级过程中涉及到2个重要的参数maxSurge和maxUnavailable,它们决定了升级过程中Pod数量的上限和下限。假设预期有 desired 个Pod,升级过程中最多可有 desired + maxSurge 个Pod,最少必须有 desired - maxUnavailable 个Pod。
举例: desired = 3, maxSurge = 1, maxUnavaiable = 0 ,那么Pod个数的范围是 [3, 4],也就是每次最多升级一个Pod。

举例: desired = 3, maxSurge = 1, maxUnavaiable = 1 ,那么Pod个数的范围是 [2, 4],也就是每次最多升级两个Pod。

此外,在滚动升级过程中,也可以对其进行控制,比如暂停、回滚等操作。可以看到,实现Deployment的底层是ReplicaSet。有了Deployment,不需要创建ReplicaSet,也不需要直接管理Pod,只要你设定你期望的Pod的状态即可。这就是声明式带来的体验上的变化。
DaemonSet
DaemonSet是确保你指定的Pod在每个worker节点上都运行有且仅有1个实例,这通常是用于node节点的一些监控。
Job
Job是确保指定的Pod只运行一次。运行完成后Pod即删除。以下为Job的manifest,需要注意其restartPolicy是OnFailure表示只有失败的时候才重启Pod。

CronJob
从名字可以看出,它的意思是定时运行指定的Pod。
Managed Pod
从上面可以看出,k8s中的Pod都是由一些更highlevel的对象来管理,确保Pod如您的期望运行。虽然你也可以手动运行Pod,但是手动运行的Pod属于unmanaged,在worker节点挂掉以后,是不会自动迁移到别的节点的。并不是说k8s的所有Pod都自动具备迁移的能力。具备自动迁移是因为Managed Pod, 这点需要特别注意。

Pod的其他组成部分
Pod的主要组成部分是Container。这里简单介绍一下Pod的其他组成部分。
Volume
我们都知道Container重启后,写入到文件系统中的数据就丢失了。为此,可以通过Volume来持久化数据,主要有几种类型的Volume:
emptyDir
主要用于Pod中多个Container之间共享数据,Pod重启后里面的数据也丢失了。Pod中的容器重启后,数据还在。如下图示:

gitRepo:
这是emptyDir的增强,Volume中的数据将首先从指定git中clone下来。但是需要注意的是,里面的内容不会与git同步。

HostPath
这是将worker节点的文件系统mount到container上。如果Pod在该Node上重启后,还能看到之前写入的内容。可用用于监控Node的Pod读取Node的信息。此外相同Node的多个Pod也可用于共享一些数据。

PersistentVolumes和PersistentVolumesClaim
简称为PV和PVC。这是k8s对集中存储的抽象,集群管理员可以定义一些PV,阿里云的容器服务中可以使用NAS,OSS和云盘作为PV。PV相当于是定义了集群中可用存储空间的一个大池子。PV是k8s集群的资源,不是属于某个namespace。
在Pod里面可以指定PVC,表示期望能获得多大的存储空间,然后k8s将从符合条件的PV中划一块空间给Pod使用。

Volume是k8s中的基础部分,后面很多功能都基于Volume来实现的。
ConfigMap配置项
实际的Container或多或少都需要一些配置参数,或者配置文件。为了便于集中管理这些配置项,可以首先创建ConfigMap资源(就是kv pairs,其中value可以是配置文件)。
在Pod中使用ConfigMap有两种方式:
- 通过定义环境变量,来引入ConfigMap中的配置项
- 以Volume的方式,在Pod的container中可以将这些配置项作为Volume挂载到container中。如下图所示。

Secrets
对于有保密性要求的配置,需要使用Secret类似的资源来存储。Secret与ConfigMap类似,只是Secret是以base64方式保存。作为Volume是mount到容器的内存中(/tmpfs里面)。
下图展示了一个容器mount了一个ConfigMap,一个Secret和一个emptyDir:

Downward API
容器有时需要获取一些关于Pod自身的一些元数据,比如Pod的label,名称等。通常有三种方式:
1 通过挂载downwardApiVolume,以文件的方式来读取这些信息,如下图所示

2 通过访问apiserver的rest接口来获取,访问api server需要的token和证书在每个Pod的/var/run/secrets/目录中都有(它们本质是个Secret)。

3 通过ambassador来访问
第二种方式访问api server需要自己处理token和https证书相关的操作,稍微繁琐。另外一种方式是在Pod中运行一个ambassador(本质是运行kubectl proxy),它将在本地提供一个代理。Container只需要访问ambassador的8001端口即可访问APIServer,无需额外的认证操作,如下图示

这里就用到了sidecar模式,这也是为什么需要引入Pod。
StatefulSet: 管理有状态的Pod
微服务最好是无状态应用,但是有时总是无法避免有状态的应用的。k8s中通过StatefulSet来提供了对有状态应用的支持。
如何保持Pod重生后的不变性,包括以下两个部分:
- Pod Identity的不变性
- Pod的存储不变性
Pod Identity
Pod Identity包括Pod名称和IP地址,看下图

ReplicaSet中的Pod名称是随机的字符。StatefulSet中的Pod是以数字编号的。如果某个Pod挂了,重建Pod的时候就会以那个Pod名字来重建。
存储不变性
存储不变性是通过PV和PVC来实现,每个Pod都有一个和其名称对应的PVC。如下图所示。

Pod重建的时候会直接挂载到之前的PVC,如下图。

缩容
缩容的时候是从序号最大的那个Pod开始缩容,一次最多销毁一个Pod,Pod销毁后期PVC会继续保留。

如何避免多个相同name的Pod?
k8s只有在明确知道Pod已经被删除掉了(这包括用户主动删除Pod),才会重建新的Pod。如果因为某个Node和master无法通信,但是该Node上的Pod可能还是活的,这种情况只有用户手动介入,k8s是不会重建新的Pod的。类似集团中有状态应用替换机器,都需要pe手动确认的。
如何保证启动的数量和版本?ReplicationController
K8S是通过什么机制来保证Pod符合配置要求(镜像版本,部署个数等)。
ReplicationController
是一种kubernetes资源,确保运行的pod符合配置要求(声明式),简称RC。之所以把”声明式“标亮,是因为这跟K8S实现机理有关,所有的资源定义的API都是声明式api,这个在后续会详细聊。

用途
1、pod或者节点发生故障时,可以自动恢复;
2、实现水平伸缩
组成
RC的声明主要分为三个部分,pod selector、replicas、pod template。通过这些我们就可以告诉K8S一个应用在部署在容器中时,用哪个版本的镜像,运行多少个。RC也会通过pod selector进行管理和运维动作。
Pod selector:用于确认作用域内有哪些pod
Replicas:指定应运行的副本数量
Podtemplate:用于创建新的pod副本模板
How it works
场景1:当一个Pod出现故障,我们将其手动触发删除时;RC会拉取template中配置版本的镜像,创建一个相同标签的Pod。在实际工作中,如果遇到某一个节点无法work,我们在aone里操作销毁的时候,最底层的调度就是这样的。
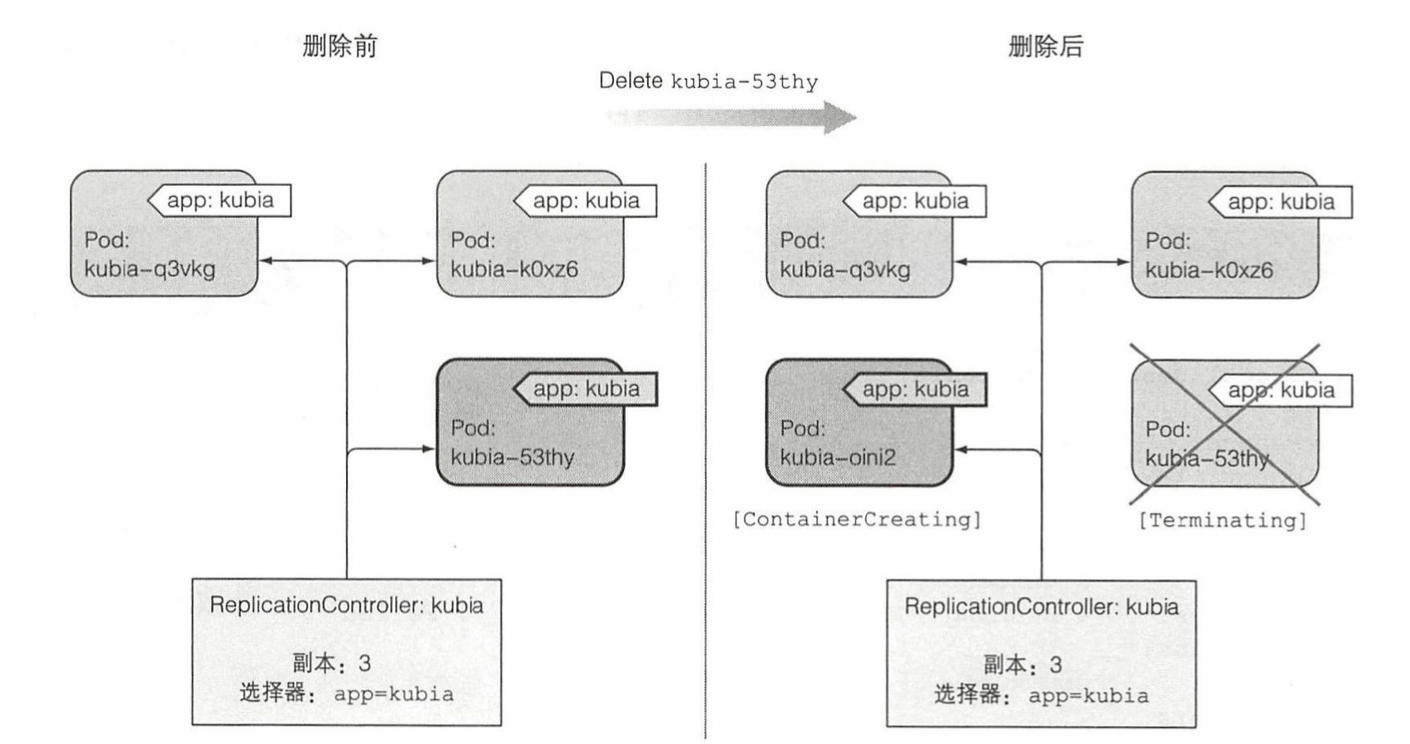
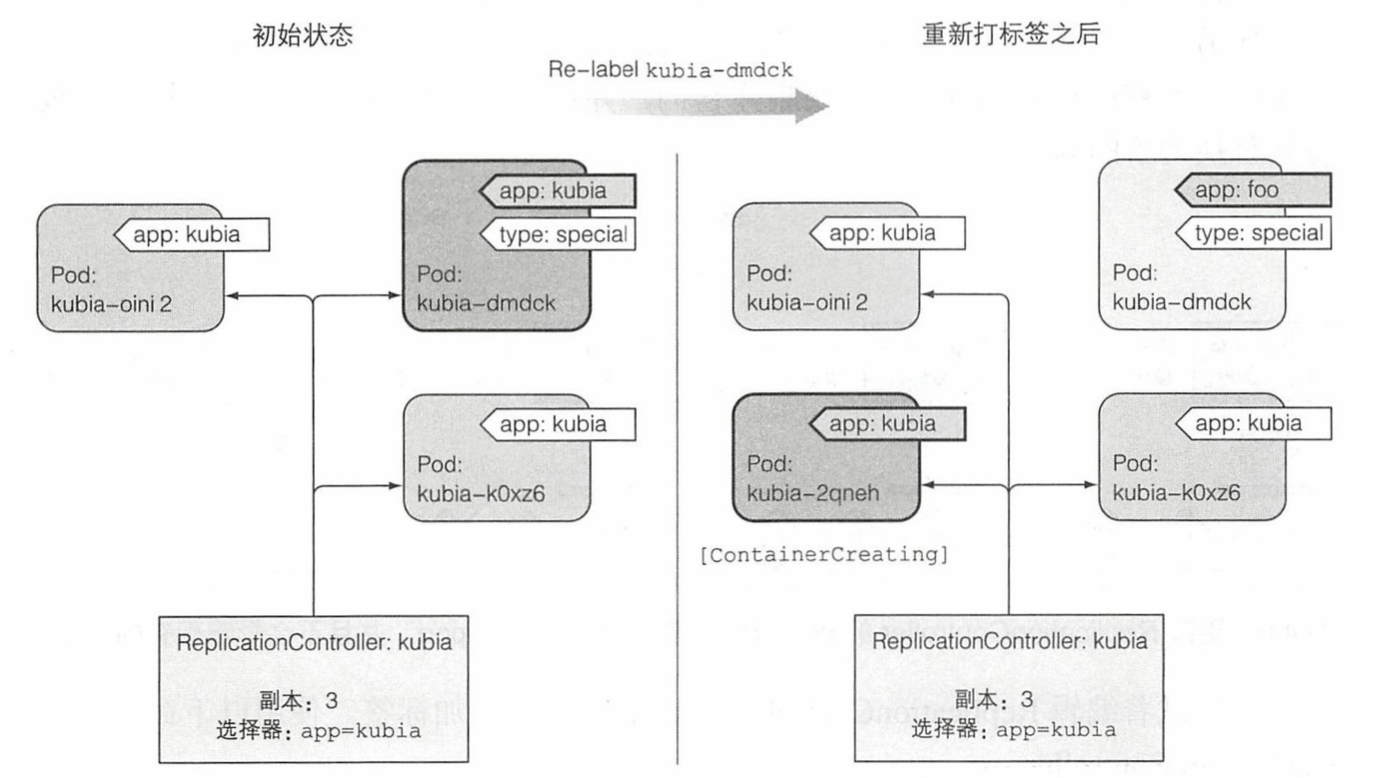
场景2:当一个标签为kubia的pod,被重新打上新标签的时候,RC会发现数量不符合要求,拉取template中配置版本的镜像,创建标签为kubia的Pod。在实际工作中,当我们在重新部署的时候,第一个要重新部署的pod可能会被打上”待销毁“的标签,等新的pod启动之后,才正式的销毁。
场景3:当RC感知到 Replicas声明减少。实际工作中,在缩容的时候,K8S会按照一定的优先级规则,对已有容器进行销毁。优先级规则的底层逻辑总结起来就是:状态越稳定,销毁优先级越低。
优先级如下:
1 如果pod没分配到节点,先被删除 2 如果pod的状态是 Pending>PodUnknown>PodRunning,则Pending优先被删除,PodUnknown次之,PodRunning最后被删除。 3 不是Ready状态的Pod先被删除。 4 如果Pod都是Ready状态,则最后一个变成Ready状态的Pod先被删除(Ready时间最短的)。 5 重启次数大的Pod先被删除。 6 创建时间最新的Pod先被删除。
场景4:当RC感知到Replicas声明增加。实际工作中的扩容场景,过程与场景1类似,不赘述。
场景5:当镜像版本升级的时候。
注意,修改模板的动作,并不会触发容器的重新部署,但当场景1、2出现的时候,RC会控制用新的镜像版本创建Pod。
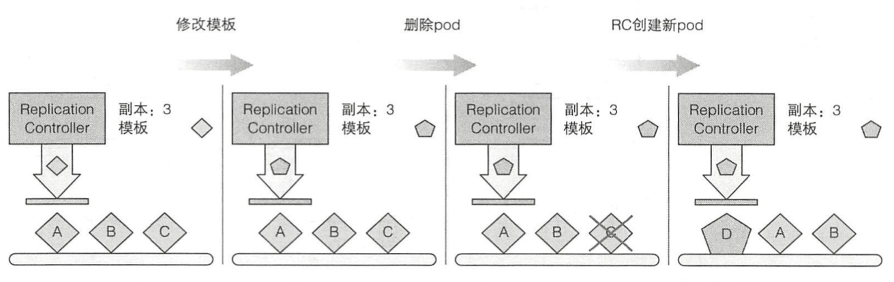
ReplicationSet和StatefulSet
ReplicationSet与ReplicationController类似,但拥有较RC更强大的标签筛选器,是RC的上位替代品,简称RS。
StatefulSet:从rc和rs的副本机制可以看出来,当新创建一个pod的时候,和原有pod是完全没有关系的,也就是说他们是用来管理无状态Pod的。而StatefulSet是用于管理有状态Pod的,应对新的pod需要与原pod具有相同的网络标识,可以访问同一份持久化数据等需求。由于涉及到的其他资源很多,我会放到第二篇笔记中来记录,顺便引出volume和网络等资源。
如何触发应用升级?
副本机制和其他控制器-手动升级
上一节我们了解了K8S内部是如何用rc、rs等资源来保证pod的是符合配置要求的。也提到了镜像版本升级是不会触发更新的,所以在实际运维的时候,用户不可能手动的来触发。我们先来看下手动操作带来的问题:
手动升级的弊端

手动操作通常有俩种模式。
第一种是recreate:升级完rc之后把所有的pod全部删除等rc自动创建;或者创建俩个rc,等新rc下的pod全部可用,再把服务重定向到新的pod上。这样会导致服务的短暂(也不一定短暂)不可用,或者造成资源的浪费。
第二种是rolling-update,也是创建俩个rc,销毁一个旧的,然后创建一个新的,直到全部切换。这样的问题是手工操作很复杂,通过kubctl客户端访问api的方式进行,很有可能中间中断鲁棒性很低。而且很大一个问题是由于是先销毁,所以无法回滚。
Pod的资源限制
我们可以对Pod中的Container设置CPU和内存、存储等资源的限制。有两个重要的参数可以设置:
- requests: 表明container需要的资源的最小值
- limits: 表明container需要的资源的最大值
关于requests和limits的一些要点:
- Pod的资源限制是其container的限制值的综合
- requests是Scheduler调度Pod的依据,需要满足Node所有Pod的requests之和小于node上该资源的总和。也就是要保证Pod的基本需求。
- limit限制了Pod能使用某个资源的最大值。对应内存,如果超过了limits就会出现OOM。
- 在容器中的应用,看到的是Node的CPU数量和Node的内存,而实际上容器是无法使用那么多资源的。如果应用是根据机器上的CPU数来设置线程数,那么可能导致开启过多线程。如果应用是根据内存总量来设置java的heap大小,可能导致无法启动。
- Node上所有Pod的limits之和可能超过Node资源总量,这就是over-commit.
- over-commit之后出现资源不够用,就会开始清理Pod。清理的原则是根据Pod的QoS的优先级来选择。
Pod QoS
Pod QoS包括三类,它们的优先级的递增的:
- BestEffort
- Burstable
- Guaranteed
QoS是不能设置的,而是根据Pod的request和limits的设置决定的。

- 如果request和Limits都没有设置,则为BestEffort
- 如果Pod中所有容器的reqeust==limits,则为Guaranteed
- 其他则为Burstable
也就是说如果设置了limits,将得到更高优先级的QoS,所以限制也是一种保障。
除了可以设置单个Pod的资源限制,k8s也可以设置某个namespace的Pod的默认值,以及某个namespace能分配的资源的上限。
Service
上一节我们讲了怎么让Pod运行起来,但是光是运行起来也没用啊,还需要对外提供服务。这一节来看怎么把Pod提供的服务对外暴露。我们都非常熟悉集团的VIP、VIPServer、统一接入,阿里云api网关等基础设施。k8s中也有对应的服务,只是名称不一样而已。
k8s中的Service是什么?
看图说话,k8s中的Service就类似我们熟知的VIP。

再看一张图:Service是通过标签来找到对应提供服务的Pod的。(Pod的标签重要性可见一般)

既然Service可类比为VIP,那么Service的IP是内部的还是外部IP呢?答案是看情况,有以下几种情况。
ClusterIP
以下为默认情况下Service的manifest:对外的端口是80,后端服务器的标签是app=kubia,后端服务器的端口是8080。此时,Service的IP是k8s集群的内部IP。
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: kubia比如 kubectl get svc 返回的如下Service即为这种类型。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP这类似于集团的私有VIP,只能集群中Pod能访问。
NodePort
顾名思义,它是在worker节点上开放一个端口,示意图如下。外部客户端首先访问worker节点上对应的端口,然后在中转到服务IP上。

对应的manifest如下,注意其type为NodePort,同时指定了nodePort为30123:

LoadBalancer

它是在NodePort的前端加上了一个负载均衡,类似于SLB。这通常是云上部署的集群才能支持。
Headless Service
Headless Service就是不绑定任何集群内部IP的服务,类似于集团的VIPServer。通过k8s集群的DNS,可以解析到Service的后端Pod IP地址,实现直连Pod访问其提供的服务。
Ingress
上面提到的都是基于网络层的方式,Ingress是基于http层的实现,类似API 网关,如下图所示

liveness probe vs readiness check
k8s支持两种“健康”检查,它们用途不一样,放在一起对比起来看更容易理解。
liveness probe 是worker节点kubelet主动对容器的健康状态的探测,判断容器是否还活着。支持的探测方式有http请求,执行指定的脚步。如果探测失败,kubelet会重启容器。注意:这是worker节点上的kubelet主动去探测,如果Node自身宕机导致Pod不可用,liveness probe也无能为力了,只能依靠ReplicaSet等机制去保证Pod的迁移。
Readiness check是Service判断Pod是否已经就绪。外部请求只会发送给已经就绪的Pod,类似VIP的健康检查(熟悉的status.taobao)。readiness check失败不会导致容器重启,只是会暂时从Service的后端服务器中移除。
K8S Internals
前面从使用者角度介绍了k8s,这一节简单介绍一下k8s的内部实现。
总体结构如下

Master节点:
- etcd存储集群元数据,提供高可用的存储
- apiserver提供对外的接口,是master的重要部分
- Scheduler:根据Pod的需求,寻找适合Pod的Node
- ControllerManager,包括各种Controller,如上面的ReplicaSetController
Worker节点:
- kubelet:是node上的守护进程 ,统管Node上的所有事务。
- kube-proxy: 和网络相关的组件
- Container Runtime,容器的运行时,如Docker
事件驱动的流程
k8s中很多流程都是靠事件来驱动的,各组件都监听API Server发出的事件,然后做出响应。以创建Deployment为例来简单说明


上图是创建一个Deployment的流程
- 用户只和apiserver交互。用户通过API Server的rest接口,创建了Deployment资源。API Server将Deployment的信息写入到etcd中,然后发送消息给DeploymentController。
- DeploymentController开始调用APIServer创建ReplicaSet, APIServer也是先记录到etcd中,然后通知ReplicaSetController
- ReplicaSetController收到消息后开始创建Pod,API Server也是先记录到etcd中,然后通知Scheduler
- Scheduler将Pod分配到某个node,这步也只是调用apiserver记录到etcd中,并通知kubelet
- Node上的kubelet收到通知后,开始调用Docker创建容器。
这种结构下,每个组件的职责非常清楚,非常符合单一职责原则。
kube-proxy
kube-proxy监听api server的消息,在node上修改iptables,使得pod能访问到server后端的Pod。如下图示:
PodA要通过ServiceB访问PodB1-3。PodA上kube-proxy监听API Server上关于ServiceB对应的后端IP变化的消息。当PodA访问ServiceB的IP(172.30.0.1:80)时,iptables将会把目标IP改成其后端Pod的IP。

Master节点的高可用

Master节点的高可用包括以下几个部分:
- 奇数台机器来部署etcd,从而实现存储的高可用
- API Server本身并无状态,因此也可以部署多个,并且和etcd部署在同一台机器上,这样apiserver只需和本地的etcd通信。
- API Server前端加上负载均衡,提供给Node节点访问
- Controller Manager和Scheduler采用active-standby方案,只有一个处于active状态,其他处于standby状态。
系统组件多是部署在Pod中
k8s中的系统组件,比如api-server, controller- manager等本身是部署在Pod中的,这也算是吃自己的狗粮吧。执行 kubectl get pod -n kube-system 可以看到这些系统组件的pod。所以,master节点上也运行了kubelet,上面运行了很多系统相关的pod。
总结
k8s的基础是Pod。由于其声明式的特点,我们通常不自己创建Pod,而是通过ReplicaSet, StatefulSet等来管理这些Pod。当然,我们也可以不直接创建ReplicaSet,而是创建Deployment来管理应用。类似的,Service也是一样,NodePort是基于ClusterIp类型的Service,LoadBalancer是基于NodePort的。还有ConfigMap/Secrets等都是基于Volume,可以看到k8s是组合前面的功能来实现更复杂的功能。K8s的架构也是非常清晰。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









