







人脸数据读取、处理与变量提取
1.读取人脸照片数据
import os
names = os.listdir('olivettifaces')
names[0:5] # 查看前5项读取的文件名![]()
# 获取到文件名称后,便可以通过如下代码在Python中查看这些图片
from PIL import Image
img0 = Image.open('olivettifaces\\' + names[0])
img0.show()2.人脸数据处理 - 特征变量提取
# 图像灰度处理及数值化处理
import numpy as np
img0 = img0.convert('L')
img0 = img0.resize((32, 32))
arr = np.array(img0)
arr # 查看数值化后的结果
import pandas as pd
pd.DataFrame(arr) 
# 上面获得的32*32的二维数组,还不利于数据建模,所以我们还需要通过reshape(1, -1)方法将其转换成一行(若reshape(-1,1)则转为一列),也即1*1024格式
arr = arr.reshape(1, -1)
print(arr) # 查看转换后的结果,这一行数就是代表那张人脸图片了,其共有32*32=1024列数 ![]()
因为总共有400张照片需要处理,若将400个二维数组堆叠起来会形成三维数组,因为我们需要使用flatten()函数将1*1024的二维数组降维成一维数组,并通过tolist()函数将其转为列表方便之后和其他图片的颜色数值信息一起处理。
print(arr.flatten().tolist()) # 下面这一行数就是那张人脸转换后的结果了 
# 构造所有图片的特征变量
X = [] # 特征变量
for i in names:
img = Image.open('olivettifaces\\' + i)
img = img.convert('L')
img = img.resize((32, 32))
arr = np.array(img)
X.append(arr.reshape(1, -1).flatten().tolist())
import pandas as pd
X = pd.DataFrame(X)
X # 查看400张图片转换后的结果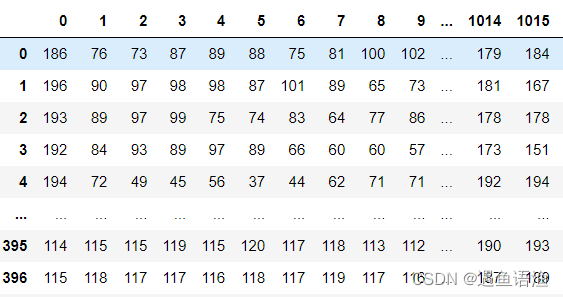
print(X.shape) # 查看此时的表格结构 ![]()
3.人脸数据处理 - 目标变量提取
# 获取目标变量y:第一张图片演示
print(int(names[0].split('_')[0]))![]()
# 批量获取所有图片的目标变量y
y = [] # 目标变量
for i in names:
img = Image.open('olivettifaces\\' + i)
y.append(int(i.split('_')[0]))
print(y) # 查看目标变量,也就是对应的人员编号 
数据划分与降维
1.划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)2.PCA数据降维
# 数据降维模型训练
from sklearn.decomposition import PCA
pca = PCA(n_components=100)
pca.fit(X_train)# 对训练集和测试集进行数据降维
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)# 我们通过如下代码验证PCA是否降维:
print(X_train_pca.shape)
print(X_test_pca.shape)
模型的搭建与使用
1.模型搭建
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier() # 建立KNN模型
knn.fit(X_train_pca, y_train) # 用降维后的训练集进行训练模型2.模型预测
y_pred = knn.predict(X_test_pca) # 用降维后的测试集进行测试
print(y_pred) # 将对测试集的预测结果打印出来
# 通过和之前章节类似的代码,我们可以将预测值和实际值进行对比:
import pandas as pd
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head() # 查看表格前5行 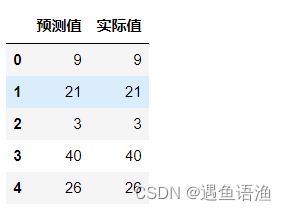
# 查看预测准确度 - 方法1
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score) ![]()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









