







步骤一:在cmd下创建项目
>> scrapy startproject NewVideoMovie
>> cd NewVideoMovie
>> scrapy genspider spider http://www.yy6080.cn/vodtypehtml/1.html
创建结果:
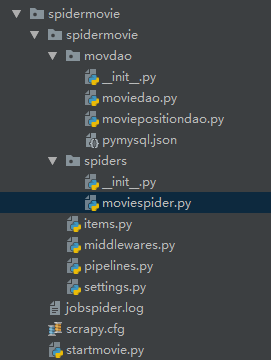
步骤二:编辑主程序
# -*- coding: utf-8 -*-
import scrapy
from day23.spidermovie.spidermovie.items import SpidermovieItem
count = 0
class MoviespiderSpider(scrapy.Spider):
name = 'moviespider'
# allowed_domains = ['http://www.yy6080.cn/vodtypehtml/1.html']
start_urls = ['http://www.yy6080.cn/vodtypehtml/1.html']
def parse(self, response):
movItems = response.xpath("//div[@class='movie-item']") # 返回选择器列表
# 遍历选择器列表
movLen = len(movItems)
movCount = 0
for movItem in movItems:
movCount += 1
sItem = SpidermovieItem()
# 解析电影名称
movieName = movItem.xpath("div[@class='meta']/div/a/text()")
if movieName:
sItem['movName'] = movieName.extract()[0].strip()
# print(movieName)
# 解析电影评分
movieScore = movItem.xpath("div[@class='meta']/div/span/text()")
if movieScore:
sItem['movScore'] = movieScore.extract()[0].strip()
# print(movieScore)
# 解析电影类型
movieType = movItem.xpath("div[@class='meta']/div[@class='otherinfo']/text()")
if movieType:
sItem['movType'] = movieType.extract()[0].strip()
# print(movieType)
# 解析电影链接
movieLink = movItem.xpath("div[@class='meta']/div/a/@href")
if movieLink:
sItem['movLink'] = "http://www.yy6080.cn" + movieLink.extract()[0].strip()
# print(movieLink)
nextPage = ""
nextPage1 = response.xpath("//a[@class='pagelink_a']/@href").extract()
nextText = response.xpath("//a[@class='pagelink_a']/text()").extract()
if nextText[-2] == "下一页":
url = "http://www.yy6080.cn" + nextPage1[-2]
nextPage = url
sItem['nextPage1'] = nextPage
pass
dataDetail = sItem['movLink']
if movieName and movieScore and movieType and movieLink:
yield scrapy.Request(url=dataDetail, callback=self.parsesecond,
meta={'item': sItem, 'movLen': movLen, 'movCount': movCount},
dont_filter=True)
pass
pass
pass
# 爬取二级页面
def parsesecond(self, response):
sItem = response.meta['item']
movLen = response.meta['movLen']
movCount = response.meta['movCount']
countens1 =response.xpath("//tbody/tr")
for countens2 in countens1:
text1 = ""
text2 = ""
tt1 = countens2.xpath("td[@class='span2']/span/text()")
if tt1:
text1 = tt1.extract()[0].strip()
pass
tt2 = countens2.xpath("td/a/text()")
if tt2:
text2 = tt2.extract()
pass
else:
tt2 = countens2.xpath("td/text()")
pass
if tt2:
text2 = tt2.extract()
pass
# 导演
if text1 == "导演":
if text2:
txr = ""
for temp in text2:
sItem['movie_director'] = temp.strip() + txr
else:
sItem['movie_director'] = None
pass
# 编剧
elif text1 == "编剧":
if text2:
txr = ""
for temp in text2:
sItem['movie_screenwriter'] = temp.strip() + txr
else:
sItem['movie_screenwriter'] = None
pass
# 类型
elif text1 == "类型":
if text2:
sItem['movie_type'] = text2[0]
else:
sItem['movie_type'] = None
pass
# 制片国家
elif text1 == "制片国家":
if text2:
sItem['movie_country'] = text2[0]
else:
sItem['movie_country'] = None
pass
# 制片国家
elif text1 == "制片国家":
if text2:
sItem['movie_country'] = text2[0]
else:
sItem['movie_country'] = None
pass
# 语言
elif text1 == "语言":
if text2:
sItem['movie_language'] = text2[0]
else:
sItem['movie_language'] = None
pass
# 上映时间
elif text1 == "上映时间":
if text2:
sItem['movie_showtime'] = text2[-1].strip(':')[-1]
else:
sItem['movie_showtime'] = None
pass
# 评分
elif text1 == "评分":
if text2:
sItem['movie_score'] = text2[0]
else:
sItem['movie_score'] = None
pass
# 电影主演
movie_tostar = countens2.xpath("//td[@id='casts']/a/text()")
if movie_tostar:
sItem['movie_tostar'] = movie_tostar.extract()[0].strip()
pass
# 剧情介绍
movie_plot = countens2.xpath("//div[@class='col-md-8']/p/text()")
if movie_plot:
sItem['movie_plot'] = movie_plot.extract()[0].strip()
pass
yield sItem
if movLen == movCount:
print("爬取下一页!" * 10)
print("--***--" * 10)
yield scrapy.Request(sItem['nextPage1'], self.parse, dont_filter=True)
pass
pass
pass
步骤三:编写items
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class SpidermovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
movName = scrapy.Field() # 名称
movScore = scrapy.Field() # 评分
movLink = scrapy.Field() # 链接
movType = scrapy.Field() # 类型
# movDetail = scrapy.Field()
nextPage1 = scrapy.Field()
# 二级页面
print("--***--**---"*6)
movie_director = scrapy.Field() # 导演
movie_screenwriter = scrapy.Field() # 编剧
movie_tostar = scrapy.Field() # 主演
movie_type = scrapy.Field() # 类型
movie_country = scrapy.Field() # 制片国家
movie_language = scrapy.Field() # 语言
movie_showtime = scrapy.Field() # 上映时间
movie_score = scrapy.Field() # 评分
movie_plot = scrapy.Field() # 剧情介绍
pass
步骤四:编写管道pipelines
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from .movdao.moviepositiondao import MovPositionDao
class SpidermoviePipeline(object):
def process_item(self, item, spider):
movPositionDao = MovPositionDao()
movPositionDao.create((item['movName'],
item['movScore'],
item['movLink'],
item['movType']))
movPositionDao.createdatil((item['movie_director'], item['movie_screenwriter'],
item['movie_tostar'], item['movie_type'],
item['movie_country'], item['movie_language'],
item['movie_showtime'], item['movie_score'],
item['movie_plot']))
print("通过管道输出!!!")
print(item['movName'])
print(item['movScore'])
print(item['movLink'])
print(item['movType'])
print('*************')
print(item['movie_director'])
print(item['movie_screenwriter'])
print(item['movie_tostar'])
print(item['movie_type'])
print(item['movie_country'])
print(item['movie_language'])
print(item['movie_showtime'])
print(item['movie_score'])
print(item['movie_plot'])
return item
步骤五:打开所需管道settings
# -*- coding: utf-8 -*-
# Scrapy settings for spidermovie project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'spidermovie'
SPIDER_MODULES = ['spidermovie.spiders']
NEWSPIDER_MODULE = 'spidermovie.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'spidermovie (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'spidermovie.middlewares.SpidermovieSpiderMiddleware': 543,
}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'spidermovie.middlewares.SpidermovieDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'spidermovie.pipelines.SpidermoviePipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 配置日志输出
LOG_LEVEL = 'ERROR'
LOG_FILE = 'jobspider.log'
步骤六:创建写入数据库文件
创建结果
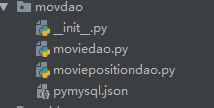
创建movIedao方法
import pymysql
import json
import os
class MovDao():
def __init__(self, configPath = 'pymysql.json'):
self.__connection = None
self.__cursor = None
self.__config = json.load(open(os.path.dirname(__file__) + os.sep + configPath, 'r')) # 通过json配置文件获得数据库的连接配置信息
print(self.__config)
pass
# 获取数据库连接的方法
def getConnection(self):
# 当有连接对象时直接返回连接对象
if self.__connection:
return self.__connection
# 否则通过建立新的连接对象
try:
self.__connection = pymysql.connect(**self.__config)
return self.__connection
except pymysql.MySQLError as e:
print("Exception" + str(e))
pass
pass
# 用于执行SQL语句的通用方法 # sql 注入
def execute(self, sql, params):
try:
self.__cursor = self.getConnection().cursor()
# execute 在执行delete update insert 返回int值,返回的对数据库里的数据修改
if params:
result = self.__cursor.execute(sql, params)
else:
result = self.__cursor.execute(sql)
return result
except (pymysql.MySQLError, pymysql.DatabaseError, Exception) as e:
print("出现数据库访问异常!!" + str(e))
self.rollback()
pass
def fetch(self):
if self.__cursor:
return self.__cursor.fetchall()
pass
def commit(self):
if self.__connection:
self.__connection.commit()
pass
def rollback(self):
if self.__connection:
self.__connection.rollback()
pass
def getLastRowId(self):
if self.__cursor:
return self.__cursor.lastrowid
def close(self):
if self.__cursor:
self.__cursor.close()
if self.__connection:
self.__connection.close()
pass
pass
创建moviepositiondao方法
from.moviedao import MovDao
# 定义一个电影数据操作的数据库访问类
class MovPositionDao(MovDao):
def __init__(self):
super().__init__()
pass
def create(self, params):
sql = "insert into mov_position (mov_name, mov_score, mov_type, mov_link) " \
"values (%s, %s, %s, %s)"
result = self.execute(sql, params)
self.commit()
return result
def createdatil(self, params):
sql = "insert into movie_position_data (movie_director, movie_screenwriter," \
" movie_tostar, movie_type, movie_country, movie_language, movie_showtime," \
" movie_score, movie_plot) " \
"values (%s, %s, %s, %s, %s, %s, %s, %s, %s)"
result = self.execute(sql, params)
self.commit()
self.close()
return result
pass
创建连接数据库的json文件
{"host": "127.0.0.1",
"user":"root",
"password" :"root",
"database":"db_mov_data",
"port":3306,
"charset":"utf8"}
步骤七:创建爬虫启动脚本
# 此脚本是爬虫启动脚本
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'moviespider'])
控制台打印效果:

数据库写入效果:

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









