







Part 2: The Boot Loader
加载内核
为了理解boot/main.c,你需要知道ELF二进制文件是什么。当你编译和链接一个C程序(如JOS内核)时,编译器将每个C源文件('. C ')转换为一个对象文件('.o'),其中包含以硬件期望的二进制格式编码的汇编语言指令。链接器接下来将所有已编译的目标文件合并为一个二进制映像,如obj/kern/kernel,在这里是ELF格式的二进制映像,ELF表示“可执行和链接格式”。
关于这种格式的完整信息可以在我们的参考页面上的ELF规范中找到,但你不需要在本课程中深入研究这种格式的细节。虽然作为一个整体,这种格式非常强大和复杂,但大部分复杂的部分是为了支持共享库的动态加载,我们在这个类中不会做这些。维基百科页面有一个简短的描述。
对于6.828来说,你可以把ELF可执行文件看作是一个带有加载信息的头文件,后面跟着几个程序段,每个程序段都是一个连续的代码块或数据,打算加载到指定的内存地址中。启动加载程序不修改代码或数据;它将它加载到内存中并开始执行。
ELF二进制文件以一个定长ELF头文件开始,接下来是一个变长程序头文件,列出了要加载的每个程序段。这些ELF头文件的C语言定义在inc/ ELF .h中。我们感兴趣的程序部分包括:
.text:程序的可执行指令。
.rodata:只读数据,例如C编译器生成的ASCII字符串常量。(但我们不会设置硬件来禁止写操作。)
.data: data区域保存程序的初始化数据,比如用int x = 5这样的初始化方法声明的全局变量。
当链接器计算程序的内存布局时,它会为未初始化的全局变量(如int x;)在内存中紧跟在.data之后的.bss段中预留空间。C语言要求“未初始化”的全局变量的值从0开始。因此,不需要将.bss的内容存储在ELF二进制文件中。相反,链接器只记录.bss段的地址和大小。加载器或程序本身必须将.bss段置零。
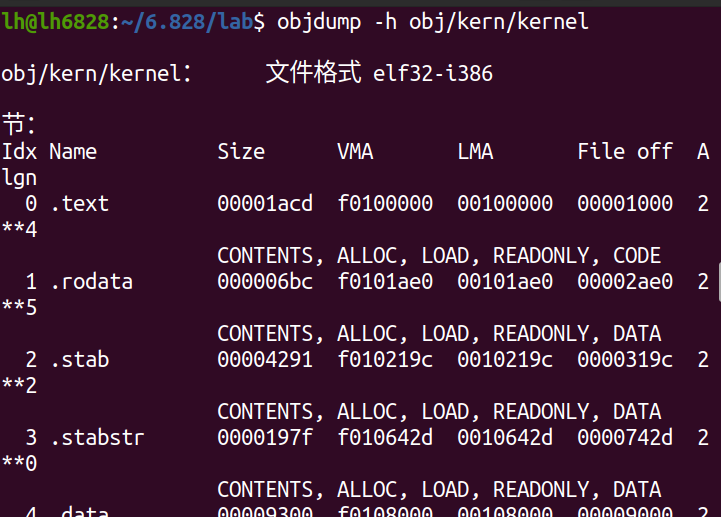
输入以下命令,可以检查内核可执行文件中所有段的名称、长度和链接地址的完整列表:
athena% objdump -h obj/kern/kernel
您将看到比上面列出的更多的部分,但其他部分对我们的目的不重要。其余的大部分用于保存调试信息,这些信息通常包含在程序的可执行文件中,但不会由程序加载器加载到内存中。
请特别注意.text部分的“VMA”(或链接地址)和“LMA”(或加载地址)。段的加载地址是该段应该加载到内存中的内存地址。
段的链接地址是段预期执行的内存地址(实际执行不一定是)。链接器以各种方式在二进制文件中编码链接地址,例如当代码需要一个全局变量的地址时,结果是如果从一个没有链接的地址执行,二进制文件通常无法工作。(可以生成位置无关的代码,其中不包含任何绝对地址。它被现代共享库广泛使用,但它有性能和复杂性成本,所以我们不会在6.828中使用它。)
链接地址是编译器给出的,用来计算偏移值,方便程序运行
通常,链接地址和加载地址是相同的。例如,查看引导加载程序的.text部分:
objdump -h obj/boot/boot.out
引导加载程序使用ELF程序头来决定如何加载各节。程序头指定了ELF对象的哪些部分需要加载到内存中,以及各个部分应该占用的目标地址。你可以输入以下命令查看程序头:
objdump -x obj/kern/kernel
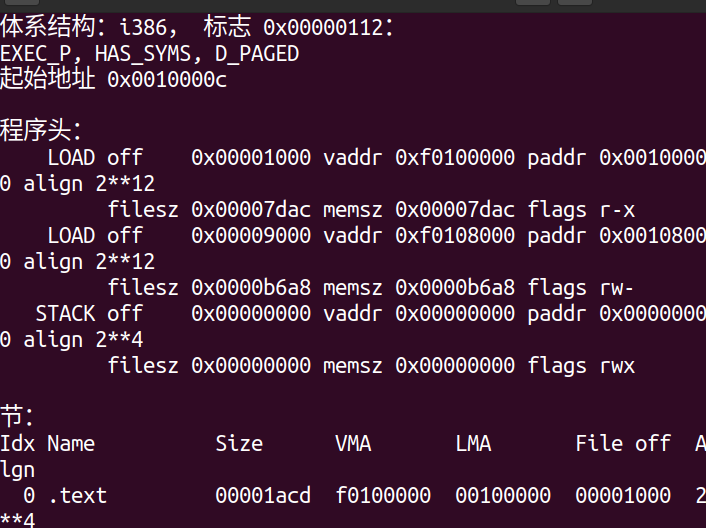
然后,在objdump输出的“程序头”下列出程序头。ELF对象中需要加载到内存中的区域标记为“LOAD”。给出了每个程序头的其他信息,如虚拟地址(“vaddr”)、物理地址(“paddr”)、加载区域的大小(“memsz”和“filesz”)。
回到boot/main.c中,每个程序头的ph->p_pa字段包含该段的目标物理地址(在本例中,它实际上是一个物理地址,尽管ELF规范对该字段的实际含义是模糊的)。
BIOS从地址0x7c00开始将引导扇区加载到内存中,因此这是引导扇区的加载地址。这也是启动扇区执行的地方,所以这也是它的链接地址。我们通过向boot/Makefrag中的链接器传递-Ttext 0x7C00来设置链接地址,这样链接器就会在生成的代码中生成正确的内存地址。
练习5
再次跟踪引导加载程序的前几个指令,并识别出第一个指令,如果您错误地获得引导加载程序的链接地址,它将“中断”或做错误的事情。然后将boot/Makefrag中的链接地址更改为错误,运行make clean,使用make重新编译lab,并再次跟踪到引导加载程序中,看看会发生什么。别忘了把链接地址改回来,然后再弄干净!
回顾内核的加载地址和链接地址。与引导加载程序不同的是,这两个地址并不相同:内核告诉引导加载程序以低地址(1兆字节)将其加载到内存中,但它期望从高地址执行。我们将在下一节深入探讨如何实现这一功能。
除了节信息,ELF头中还有一个字段对我们很重要,名为e_entry。这个字段保存了程序入口点的链接地址:程序文本部分中应该开始执行的内存地址。你可以看到入口点:
objdump -f obj/kern/kernel
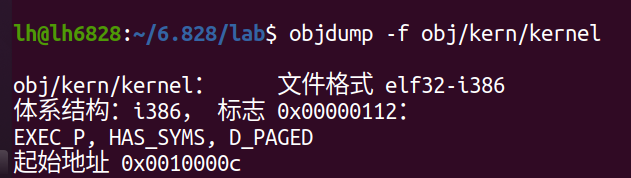
现在您应该能够理解boot/main.c中的最小ELF加载程序。它将内核的每个部分从磁盘读取到内存的加载地址,然后跳转到内核的入口点。
练习6
我们可以使用GDB的x命令检查内存。GDB手册提供了完整的细节,但就目前而言,只要知道命令x/Nx ADDR在ADDR处打印N个内存单词就足够了。(注意,命令中的两个` x `都是小写的。)警告:单词的大小不是通用标准。在GNU程序集中,一个单词是两个字节(xorw中的“w”代表单词,意思是两个字节)。
重置机器(退出QEMU/GDB并重新启动它们)。检查BIOS进入引导加载程序时0x00100000处的8个内存字,以及引导加载程序进入内核时的8个内存字。它们为什么不同?第二个断点处是什么?(实际上不需要使用QEMU来回答这个问题。只是觉得)。
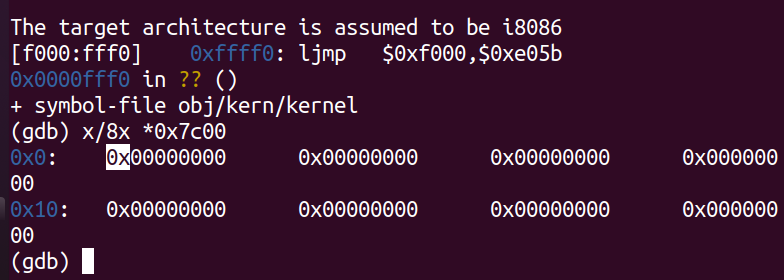


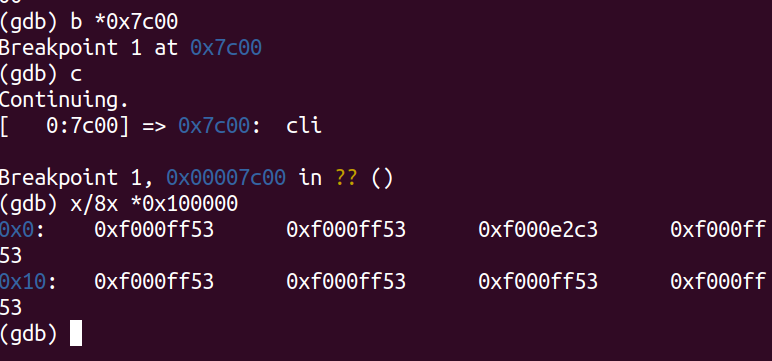
产生变化的原因在于boot loader将kernel加载到了内存当中。
输入命令objdump -x obj/kern/kernel,查看所有header
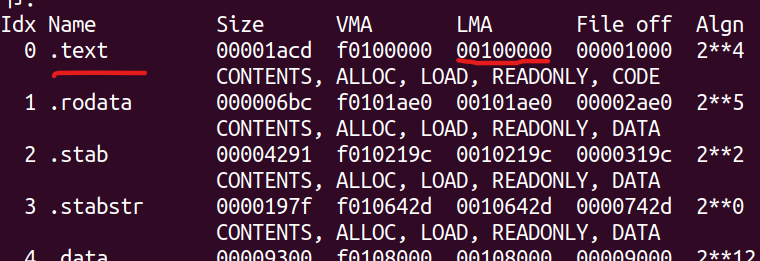
所以储存在0x100000中的应该是.text段
Part 3: The Kernel
我们现在开始更详细地考察最小JOS内核。(你终于可以写一些代码了!)与引导加载程序类似,内核以一些汇编语言代码开始,这些代码会进行一些设置,使C语言代码能够正确执行。
使用虚拟内存解决位置依赖问题
当我们检查上述引导加载程序的链接和加载地址时,它们完全匹配,但是内核的链接地址(由objdump打印)与其加载地址之间存在(相当大的)差异。回去检查一下,确保你能看到我们在说什么。(链接内核比引导加载程序要复杂得多,因此链接和加载地址位于kern/kernel.ld的顶部。)
操作系统内核通常喜欢链接并在非常高的虚拟地址上运行,例如0xf0100000,以便将处理器虚拟地址空间的较低部分留给用户程序使用。这种安排的原因在下一个实验中会更清楚。
许多机器在地址0xf0100000没有任何物理内存,因此我们不能指望能够在那里存储内核。相反,我们将使用处理器的内存管理硬件将虚拟地址0xf0100000(内核代码预期运行的链接地址)映射到物理地址0x00100000(启动加载程序将内核加载到物理内存)。这样,尽管内核的虚拟地址足够高,可以为用户进程留下足够的地址空间,但它将加载到PC RAM中1MB位置的物理内存中,就在BIOS ROM上面。这种方法要求PC至少有几兆字节的物理内存(这样物理地址0x00100000才能工作),但这可能适用于1990年左右以后构建的任何PC。
实际上,在下一个实验中,我们将把PC的整个底层256MB的物理地址空间,从物理地址0x00000000到0x0fffffff(2的28次方),分别映射到虚拟地址0xf0000000到0xffffffff(留下了虚拟底层的256MB)。您现在应该看到为什么JOS只能使用物理内存的前256MB。
现在,我们只映射前4MB的物理内存,这足以让我们启动和运行。我们使用kern/entrypgdir.c中手写的、静态初始化的页目录和页表来实现这一点。现在,你不需要了解它如何工作的细节,只需要了解它实现的效果。直到kern/entry.S设置CR0_PG标志(不启动分页),内存引用被视为物理地址(严格地说,它们是线性地址,但boot/boot.S为我们建立了一个从线性地址到物理地址的身份映射,我们永远不会改变它)。一旦设置了CR0_PG,内存引用就是虚拟地址,由虚拟内存硬件(MMU)转换为物理地址。entry_pgdir将虚拟地址从0xf0000000到0xf0400000转换为物理地址0x00000000到0x00400000,将虚拟地址0x00000000到0x00400000转换为物理地址0x00000000到0x00400000。任何不在这两个范围内的虚拟地址都将导致硬件异常,因为我们还没有设置中断处理,这将导致QEMU转储机器状态并退出(或者无限重启,如果您没有使用6.828补丁版本的QEMU)。
练习7
https://www.cnblogs.com/wuhualong/p/lab01_exercise07_observe_memory_mapping.html
https://blog.csdn.net/weixin_51187533/article/details/123111228
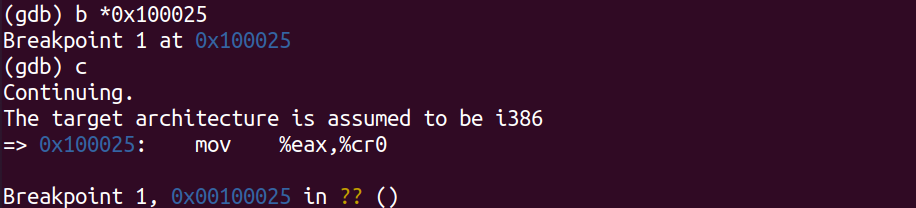
使用QEMU和GDB跟踪到JOS内核,并在movl %eax, %cr0处停止。检查0x00100000和0xf0100000的内存。现在,使用stepi GDB命令单步执行该指令。同样,检查0x00100000和0xf0100000的内存。确保你明白刚才发生了什么。
建立新映射后,如果映射不到位,将无法正常工作的第一条指令是什么?注释掉kern/entry.S中的movl %eax, %cr0,追踪它,看看你是否正确。
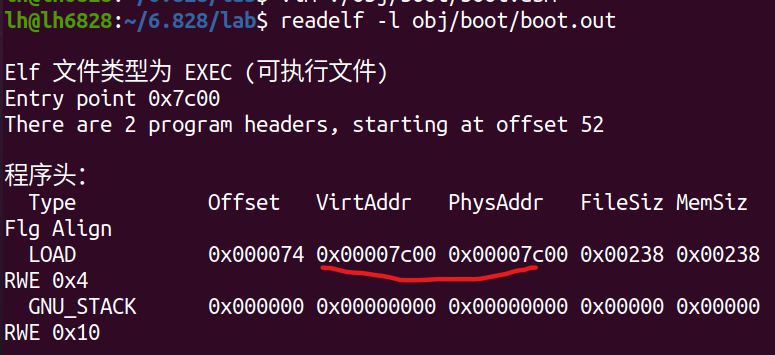
根据这个boot.out查看出其中物理地址和虚拟地址一样,就是刚开始BIOS和boot loader运行的代码
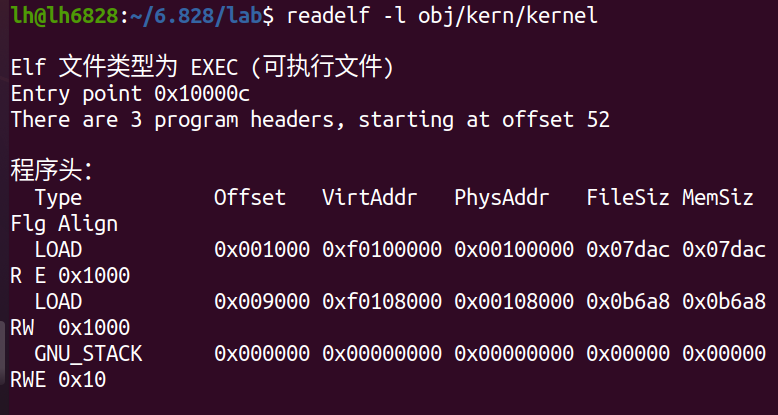
查看内核的虚拟地址和物理地址 发现两个相差很大
通过这个了解到 0x100000 内核加载的物理地址 0xf0100000 虚拟地址
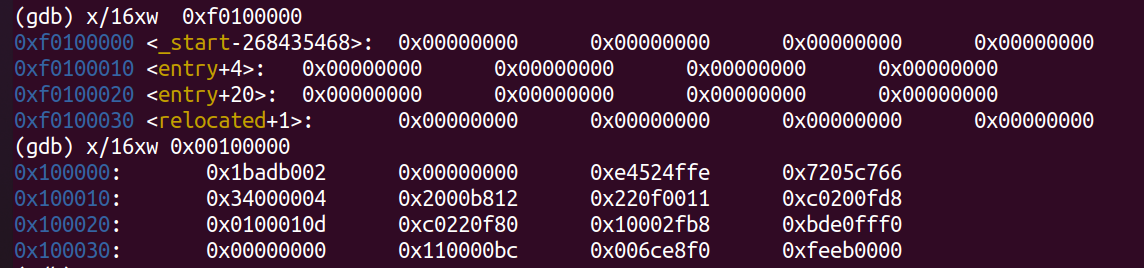
上面是进入内核后执行movl %eax, %cr0之前时候内核加载的虚拟地址和物理地址中内容的区别

执行这行代码之后,虚拟地址对应的内容中就存在内容了,而且和物理地址中相同。
movl %eax, %cr0 实现了虚拟地址的启用。

查看obj/kern/kernel.asm中的内容

查看此时寄存器的内容,发现最高位为1,所以启动分页实现虚拟地址启用

在启动分页失败之后,后面的跳转地址的指令就会失败,因为之后是按照虚拟地址计算偏移跳转的
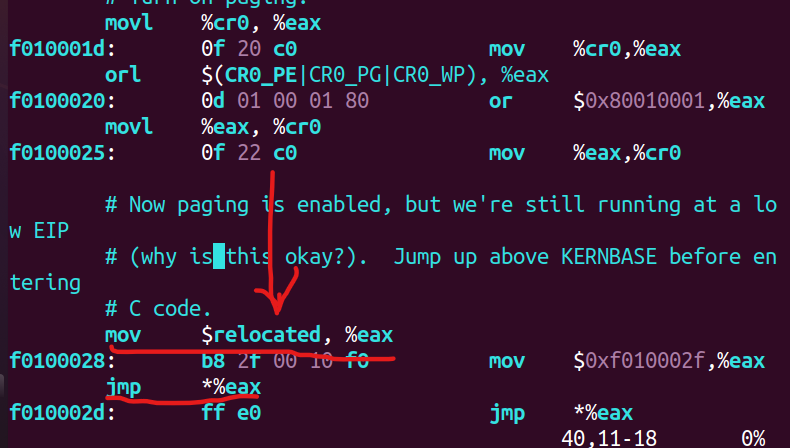
题目第二个问题是判断内存地址失败后哪些指令会运行失败,我判断是下面两条指令mov $relocated, %eax和jmp %eax就会失败,我的推理过程:relocated这个地址是由段地址加上偏移地址得到的,段地址是0xf0100008,如果地址映射失败,那些jmp %eax就会跳到0xf010008加上偏移量的物理地址,导致出错。gdb调试结果恰好验证了我的猜测是正确的。
将kern/entry.S的movl %eax, %cr0注释掉,重新启动qemu和gdb,在jmp %eax加断点,使用c命令运行到这里,使用x/16xw查看0x00100000和0xf0100000两个地址往后16个word的内容,发现两者不同,后者依然是全0(内容与第一节第1步的相同,此处不再提供)。可见地址映射确实失败了。
继续往下执行一步,发现gdb报错。应该是因为0xf010002c地址后面的数据全为0,导致把空指针赋给寄存器而报错。
(gdb) si
=>0xf010002c <relocated>: add %al,(%eax)
relocated () at kern/entry.S:7474 movl $0x0,%ebp # nuke frame pointer
(gdb)
Remote connection closed此时QEMU那边也打印一堆错误信息并终止运行:
qemu: fatal: Trying to execute code outside RAM or ROM at0xf010002cEAX=f010002c EBX=00010094ECX=00000000EDX=000000a4
ESI=00010094EDI=00000000EBP=00007bf8 ESP=00007bec
EIP=f010002c EFL=00000086 [--S--P-] CPL=0 II=0 A20=1 SMM=0HLT=0ES =001000000000 ffffffff 00cf9300 DPL=0DS [-WA]
CS =000800000000 ffffffff 00cf9a00 DPL=0 CS32 [-R-]
SS =001000000000 ffffffff 00cf9300 DPL=0DS [-WA]
DS =001000000000 ffffffff 00cf9300 DPL=0DS [-WA]
FS =001000000000 ffffffff 00cf9300 DPL=0DS [-WA]
GS =001000000000 ffffffff 00cf9300 DPL=0DS [-WA]
LDT=000000000000 0000ffff 00008200 DPL=0 LDT
TR =000000000000 0000ffff 00008b00 DPL=0 TSS32-busy
GDT= 00007c4c 00000017
IDT= 00000000 000003ff
CR0=00000011CR2=00000000CR3=00112000CR4=00000000DR0=00000000DR1=00000000DR2=00000000DR3=00000000
DR6=ffff0ff0 DR7=00000400
CCS=00000084 CCD=80010011 CCO=EFLAGS
EFER=0000000000000000
FCW=037f FSW=0000 [ST=0] FTW=00 MXCSR=00001f80
FPR0=00000000000000000000 FPR1=00000000000000000000
FPR2=00000000000000000000 FPR3=00000000000000000000
FPR4=00000000000000000000 FPR5=00000000000000000000
FPR6=00000000000000000000 FPR7=00000000000000000000
XMM00=00000000000000000000000000000000 XMM01=00000000000000000000000000000000
XMM02=00000000000000000000000000000000 XMM03=00000000000000000000000000000000
XMM04=00000000000000000000000000000000 XMM05=00000000000000000000000000000000
XMM06=00000000000000000000000000000000 XMM07=00000000000000000000000000000000GNUmakefile:165: recipe for target 'qemu-gdb' failed
make: *** [qemu-gdb] Aborted (core dumped)格式化打印到控制台
大多数人认为像printf()这样的函数是理所当然的,有时甚至认为它们是C语言的“原语”。但是在操作系统内核中,我们必须自己实现所有的I/O。
请通读kern/printf.c、lib/printfmt.c和kern/console.c,确保理解它们之间的关系。为什么printfmt.c位于单独的lib目录中,这一点在后面的实验中会很清楚。
练习8
我们省略了一小段代码——使用“%o”模式打印八进制数所需的代码。查找并填充此代码片段。
能够回答以下问题:
解释printf.c和console.c之间的接口。具体来说,console.c导出了什么函数?printf.c如何使用该函数?
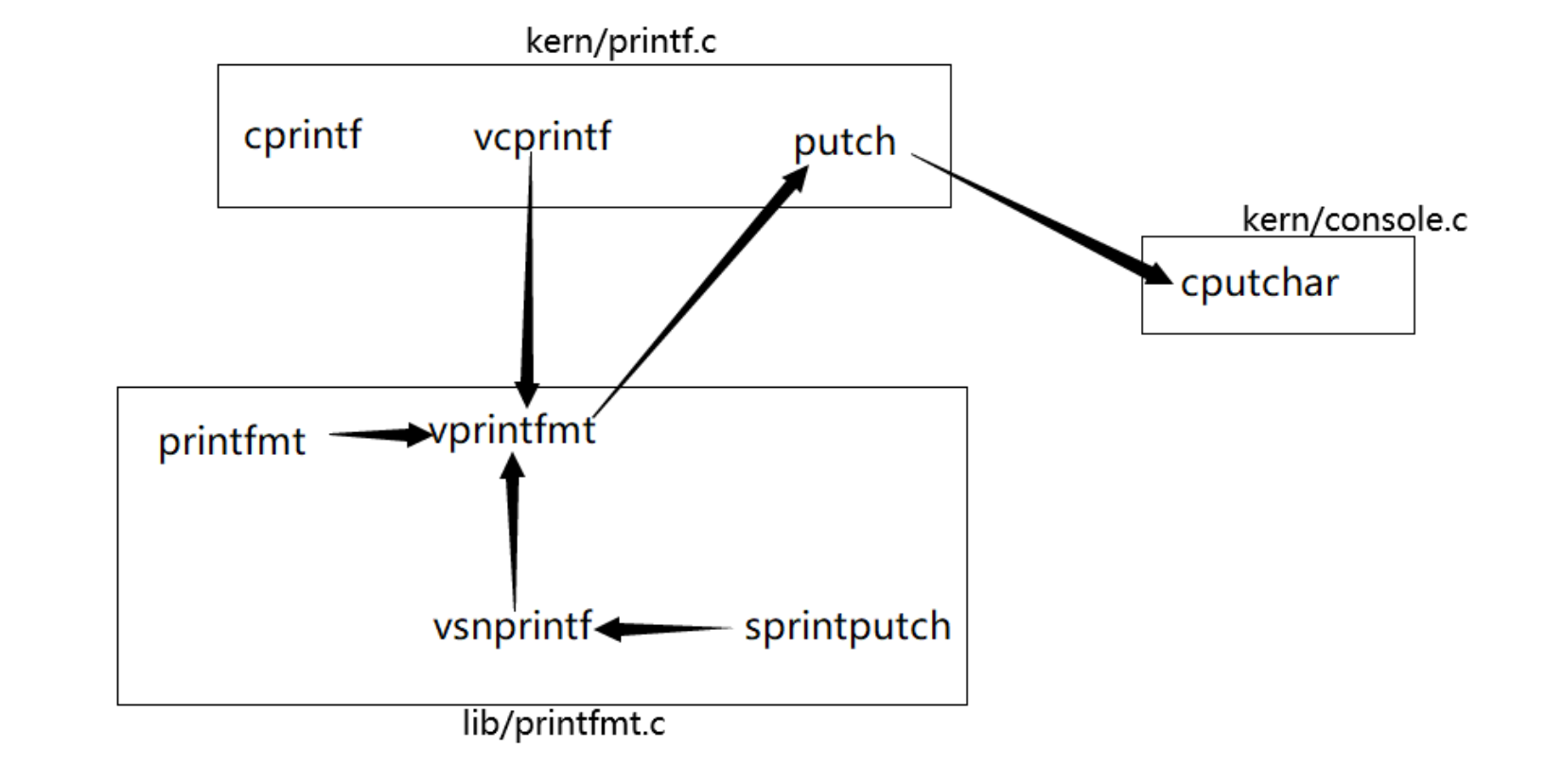
解答:printf.c中的putch函数调用了console.c中的cputchar函数,具体调用关系:cprintf -> vcprintf -> putch -> cputchar。
2.请在console.c中解释以下内容
1 if (crt_pos >= CRT_SIZE) {
2 int i;
3 memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t));
4 for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
5 crt_buf[i] = 0x0700 | ' ';
6 crt_pos -= CRT_COLS;
7 }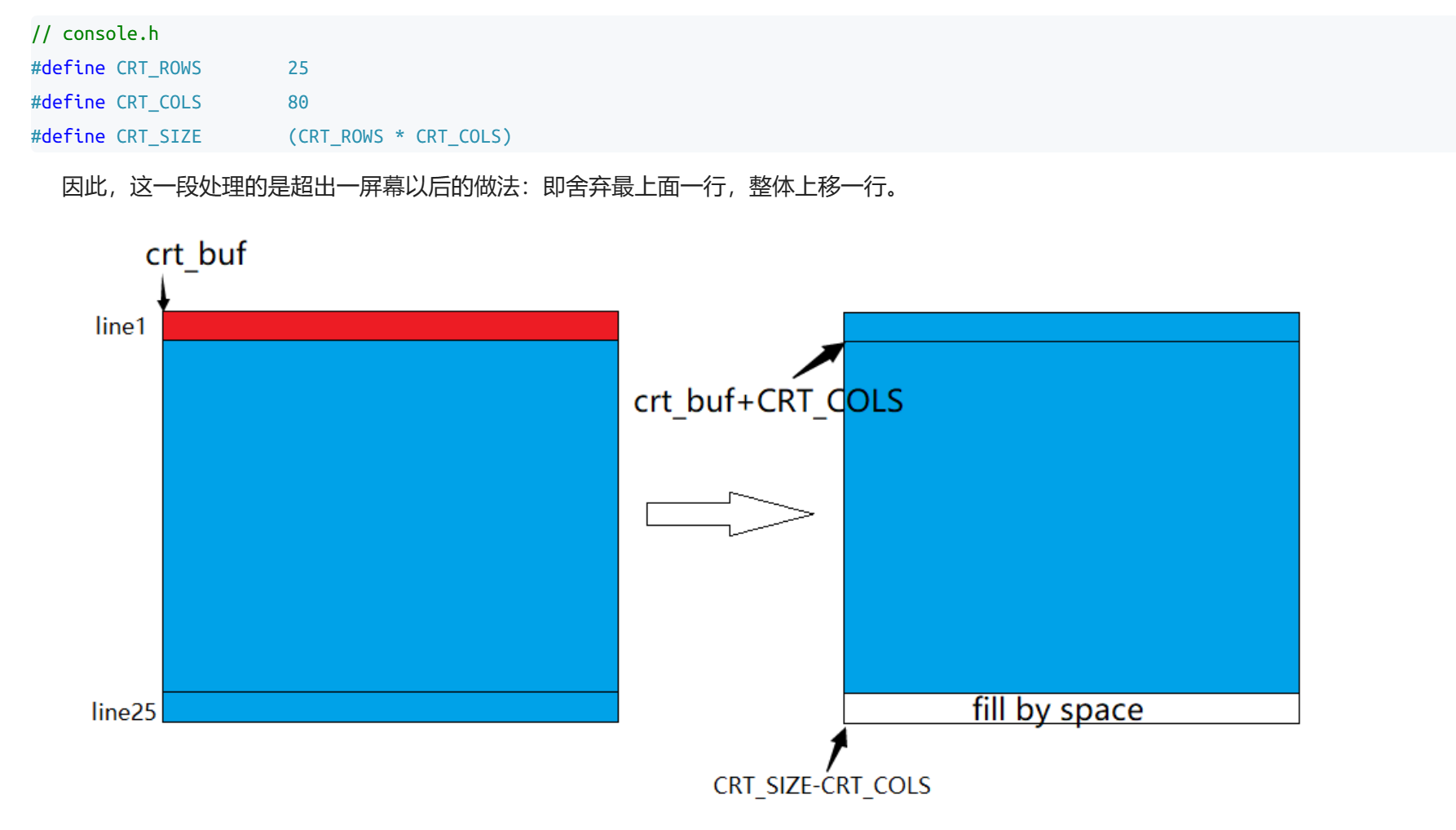
解答:联系代码上下文,可以理解这段代码的作用。首先,CRT(cathode ray tube)是阴极射线显示器。根据console.h文件中的定义,CRT_COLS是显示器每行的字长(1个字占2字节),取值为80;CRT_ROWS是显示器的行数,取值为25;而#define CRT_SIZE (CRT_ROWS * CRT_COLS)是显示器屏幕能够容纳的字数,即2000。当crt_pos大于等于CRT_SIZE时,说明显示器屏幕已写满,因此将屏幕的内容上移一行,即将第2行至最后1行(也就是第25行)的内容覆盖第1行至倒数第2行(也就是第24行)。接下来,将最后1行的内容用黑色的空格塞满。将空格字符、0x0700进行或操作的目的是让空格的颜色为黑色。最后更新crt_pos的值。总结:这段代码的作用是当屏幕写满内容时将其上移1行,并将最后一行用黑色空格塞满。
3.对于下列问题,你可能希望查阅第二讲的笔记。这些说明涵盖了GCC在x86上的调用约定。
逐步跟踪以下代码的执行过程:
int x = 1, y = 3, z = 4;
cprintf("x %d, y %x, z %d\n", x, y, z);在对cprintf()的调用中,fmt指向什么?ap指向什么?
(按执行顺序)列出对cons_putc、va_arg和vcprintf的每次调用。对于cons_putc,也列出它的参数。对于va_arg,列出ap在调用之前和之后所指向的内容。对于vcprintf,列出其两个参数的值。
做这个题首先需要直到C语言中可变参数实例
https://www.cnblogs.com/bettercoder/p/3488299.html
https://www.jianshu.com/p/e43f2d3d3216
看这个就基本能懂,小结一下:
对于函数中的可变参数,第一个参数是固定参数,是必须有的,这个题目中的第一个参数就是字符串:"x %d, y %x, z %d\n",在cprintf函数中,使用fmt指向这个字符串。然后后面的x、y、z是ap指向的,ap是一个va_list类型的变量,专门用来保存可变参数。之后使用va_start函数初始化ap,然后使用va_arg取得取地下一个参数y的地址并保存在ap中,这样就不可以遍历访问这些变量的值了。
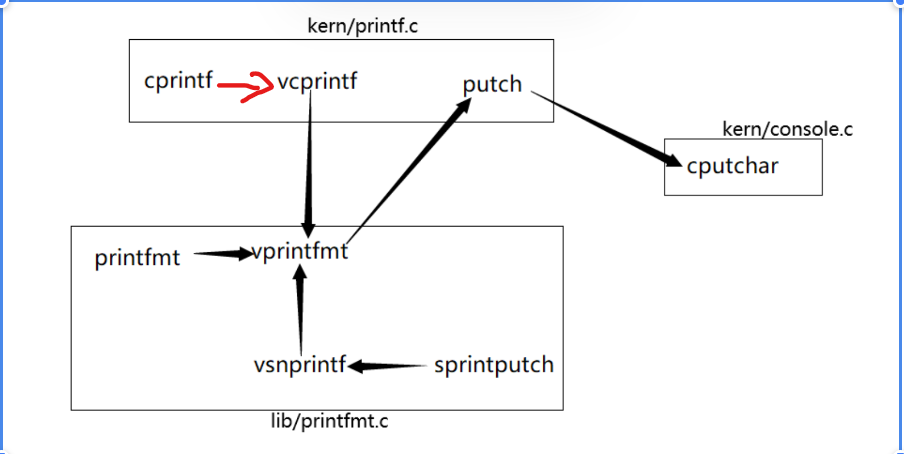
小结函数:
基本上按照这道题看,就是从cprintf这个函数开始,按照如图所示的方式调用
vprintfmt函数最关键:解析字符串——就是fmt指向的参数,然后根据字符串中数字输出的方式进行打印,其中putch和cputchar函数似乎就是调用底层的汇编语言进行操作,因为其中好像有gcc内联汇编的语句。
4.运行下面的代码。
unsigned int i = 0x00646c72;
cprintf("H%x Wo%s", 57616, &i);输出是什么?解释这个输出是如何按照前一个练习的逐步方式实现的。下面是一个将字节映射到字符的ASCII表。
输出取决于x86是小端序的这一事实。如果x86系统是大端序的,你会将i设置为什么来产生相同的输出呢?是否需要将57616更改为其他值?
小端:He110 world
大端:hell0 dlorw
Here's a description of little- and big-endian and a more whimsical description.
5.在下面的代码中,在’y='的后面将会打印什么?(注意:答案不是一个明确的数。)为什么这会发生?
cprintf("x=%d y=%d", 3);
x=3 y=随机 y是随机的,因为这个时候ap这个指针指向3存储的下一个地址,这个地址当中的值是未知的。
6.假设GCC改变了它的调用约定,按照声明的顺序将参数压入栈中,这样最后一个参数就会压入栈中。如何改变cprintf或它的接口,以便仍然可以向它传递可变数量的参数?
(如果将GCC的调用约定改为参数从左到右压栈,为支持参数数目可变需要怎样修改cprintf函数?)
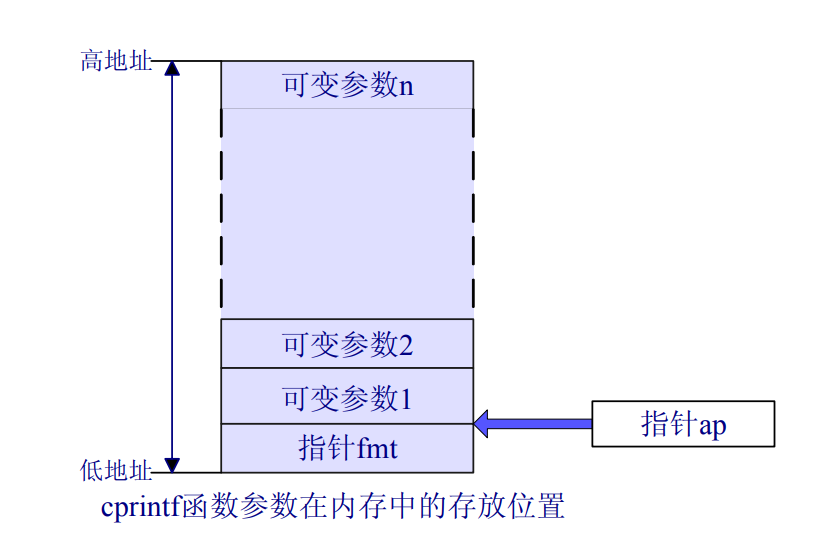
原来是这样的
现在应该是相反了,有两种方法。一种是程序员调用cprintf函数时按照从右到左的顺序来传递参数,这种方法不符合我们的阅读习惯、可读性较差。第二种方法是在原接口的最后增加一个int型参数,用来记录所有参数的总长度,这样我们可以根据栈顶元素找到格式化字符串的位置。这种方法需要计算所有参数的总长度,也比较麻烦
challenge:增强控制台,允许文本以不同的颜色打印。传统的方法是让它解释打印到控制台的文本字符串中嵌入的ANSI转义序列,但你可以使用任何你喜欢的机制。在6.828参考页面和其他网站上有大量关于编程VGA显示硬件的信息。如果你喜欢冒险,可以尝试将VGA硬件切换到图形模式,并使控制台在图形帧缓冲区上绘制文本。
堆栈
在本实验的最后一个练习中,我们将更详细地探索C语言在x86上使用栈的方式,并在此过程中编写一个有用的新内核监视器函数,用于打印栈的回溯:从嵌套调用指令到当前执行点保存的指令指针(IP)值的列表。
练习9
MIT 6.828 JOS学习笔记12 Exercise 1.9 - fatsheep9146 - 博客园 (cnblogs.com) 看这个
判断一下操作系统内核是从哪条指令开始初始化它的堆栈空间的,以及这个堆栈坐落在内存的哪个地方?内核是如何给它的堆栈保留一块内存空间的?堆栈指针又是指向这块被保留的区域的哪一端的呢?
前面已经分析过boot.S和main.c文件的运行过程,这个文件中的代码是PC启动后,BIOS运行完成后,首先执行的两部分代码。但是它们并不属于操作系统的内核。当main.c文件中的bootmain函数运行到最后时,它执行的最后一条指令就是跳转到entry.S文件中的entry地址处。此时控制权已经被转交给了entry.S。
在跳转到entry之前,并没有对%esp,%ebp寄存器的内容进行修改,可见在bootmain中并没有初始化堆栈空间的语句。
下面进入entry.S,在entry.S中我们可以看到它最后一条指令是要调用i386_init()子程序。这个子程序位于init.c文件之中。在这个程序中已经开始对操作系统进行一些初始化工作,并且自重进入mointor函数。可见到i386_init子程序时,内核的堆栈应该已经设置好了。所以设置内核堆栈的指令就应该是entry.S中位于 call i386_init 指令之前的两条语句:
movl $0x0,%ebp # nuke frame pointer
movl $(bootstacktop),%espx86栈指针(esp寄存器)指向当前正在使用的栈的最低位置。在为栈分配的区域中,该位置以下的所有内容都是空闲的。将值压入栈涉及减小栈指针,然后将值写入栈指针指向的位置。从栈弹出一个值涉及读取栈指针指向的值,然后增加栈指针。在32位模式下,栈只能保存32位的值,并且esp总是可以被4整除。各种x86指令,比如call,都是“硬连接”到堆栈指针寄存器的。
相反,ebp(基本指针)寄存器主要是根据软件约定与栈相关联的。在进入C函数时,函数的序言代码通常会将前一个函数的基指针压入栈中来保存它,然后在函数运行期间将当前esp值复制到ebp中。如果程序中的所有函数都遵守这个约定,那么在程序执行期间的任何给定点,都可以通过跟踪保存的ebp指针链,并确定导致程序中特定点到达的嵌套函数调用序列,从而对堆栈进行回溯。这种能力可能特别有用,例如,当某个函数因为传递了错误的参数而导致断言失败或panic时,但你不确定是谁传递了错误的参数。栈回溯可以让你找到有问题的函数。
对于ESP、EBP寄存器的理解 - 狂奔~ - 博客园 (cnblogs.com)
练习10
MIT 6.828 JOS学习笔记13 Exercise 1.10 - fatsheep9146 - 博客园 (cnblogs.com)
为熟悉x86平台上的C语言调用约定,请在obj/kern/kernel.asm中找到test_backtrace函数的地址,在那里设置一个断点,并检查在内核启动后每次调用它时发生了什么。每个递归的test_backtrace嵌套层在栈上压入多少个32位的单词,这些单词是什么?
注意,为了让这个练习正常工作,您应该使用工具页面或Athena上提供的打过补丁的QEMU版本。否则,你必须手动将所有断点和内存地址转换为线性地址。
上面的练习应该提供了实现堆栈回溯函数所需的信息,你应该调用该函数mon_backtrace()。这个函数的原型已经在kern/monitor.c中了。你可以完全用C语言完成,但你可能会发现inc/x86.h中的read_ebp()函数很有用。还必须将这个新函数挂钩到内核监视器的命令列表中,以便用户可以交互式地调用它。
backtrace函数应该以以下格式显示函数调用帧的列表:
Stack backtrace:
ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
每一行包含一个ebp、eip和args。ebp值表示指向该函数使用的栈的基指针,即栈指针在函数进入和函数序言代码设置基指针之后的位置。列出的eip值是函数的返回指令指针:当函数返回时,控件将返回到的指令地址。返回指令指针通常指向调用指令之后的指令(为什么?)最后,在args之后列出的5个十六进制值是函数的前5个参数,它们会在函数被调用之前被压入栈。当然,如果调用函数时传入的参数少于5个,那么这5个值并不都有用。(为什么回溯代码不能检测实际有多少个参数?如何修复这个限制?)
打印的第一行反映了当前执行的函数,即mon_backtrace本身,第二行反映了调用mon_backtrace的函数,第三行反映了调用该函数的函数,以此类推。你应该打印所有未完成的栈帧。通过学习kern/entry。你会发现有一种简单的方法告诉你什么时候停止。
以下是你在K&R第5章中读到的一些特别的要点,在接下来的练习和以后的实验中都值得记住。
如果int* p = (int*)100,那么(int)p + 1和(int)(p + 1)是不同的数:第一个是101,第二个是104。在将整数与指针相加时(如第二种情况),整数会隐式地乘以指针所指向对象的大小。
p[i]定义为与*(p+i)相同,表示p所指向的内存中的第i个对象。上述加法规则在对象大于1字节时适用。
&p[i]与(p+i)相同,得到的是p所指向的内存中第i个对象的地址。
尽管大多数C程序从来不需要转换指针和整数,但操作系统经常需要转换。当你看到涉及内存地址的加法运算时,问问自己这是整数加法还是指针加法,并确保加法的值是否被正确相乘。
练习11
实现上述backtrace函数。请使用与示例中相同的格式,否则评分脚本将会混淆。当你认为它能正常工作时,运行make grade,看看它的输出是否符合评分脚本的要求,如果不符合,就修复它。在你提交了你的实验1代码之后,欢迎你以任何你喜欢的方式改变回溯函数的输出格式。
如果您使用read_ebp(),请注意GCC可能会生成“优化”的代码,在mon_backtrace()的函数序言之前调用read_ebp(),这将导致不完整的堆栈跟踪(最近函数调用的堆栈帧丢失)。虽然我们已经尝试禁用导致此重排的优化,但您可能希望检查mon_backtrace()的程序集,并确保对read_ebp()的调用发生在函数序言之后。
在这一点上,你的backtrace函数应该给你导致mon_backtrace()被执行的堆栈上的函数调用者的地址。但在实践中,你通常想知道与这些地址对应的函数名。例如,你可能想知道哪些函数可能包含导致内核崩溃的bug。
为了帮助您实现此功能,我们提供了函数debuginfo_eip(),该函数在符号表中查找eip并返回该地址的调试信息。该函数定义在kern/kdebug.c中。
练习12
https://blog.csdn.net/weixin_41761478/article/details/101102354
《MIT 6.828 Lab 1 Exercise 12》实验报告 - whl1729 - 博客园 (cnblogs.com)
修改您的堆栈回溯函数,以显示每个eip对应的函数名、源文件名和行号。
在debuginfo_eip中,__STAB_ *是从哪里来的?这个问题的答案很长;为了帮助你找到答案,你可能需要做以下事情:
look in the file kern/kernel.ld for __STAB_*
run objdump -h obj/kern/kernel
run objdump -G obj/kern/kernel
run gcc -pipe -nostdinc -O2 -fno-builtin -I. -MD -Wall -Wno-format -DJOS_KERNEL -gstabs -c -S kern/init.c, and look at init.s.
查看引导加载程序是否在加载内核二进制文件时加载符号表
通过插入对stab_binsearch的调用来查找地址对应的行号,完成debuginfo_eip的实现。
向内核监视器添加一个backtrace命令,并扩展mon_backtrace的实现,以调用debuginfo_eip,并为表单的每个堆栈帧打印一行:
K> backtrace
Stack backtrace:
ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000
kern/monitor.c:143: monitor+106
ebp f010ffd8 eip f0100193 args 00000000 00001aac 00000660 00000000 00000000
kern/init.c:49: i386_init+59
ebp f010fff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00 0000ffff
kern/entry.S:70: <unknown>+0
K>
每一行给出了文件名和栈帧的eip文件中的行,后面是函数名和eip与函数第一条指令的偏移量(例如,monitor+106表示返回的eip比monitor的开头多106字节)。
确保将文件和函数名打印在单独的一行上,以避免混淆评分脚本。
提示:printf格式字符串提供了一种简单的(虽然不明确)方法来打印像stab表中那样以非空字符结尾的字符串。printf(" %。*s", length, string)打印字符串中最多长度的字符看看printf手册页,以了解为什么这样做可行。
你可能会发现回溯过程中遗漏了一些函数。例如,您可能会看到对monitor()的调用,但不会看到对runcmd()的调用。这是因为编译器内联了一些函数调用。其他优化可能会让你看到意想不到的行号。如果从GNUMakefile中去掉-O2,则回溯可能会更有意义(但内核将运行得更慢)。
实验提供了int debuginfo_eip(uintptr_t addr, struct Eipdebuginfo *info)函数,功能是输入一个指令地址addr,和一个Eipdebuginfo结构指针,该函数会查找addr处指令有关的信息,若查找成功则返回0,并把信息填充到该结构中,比如指令所在文件、行号、函数名、函数第一条指令地址等。
要理解并利用这个函数,要先理解stab表。
stab表
stab表是什么?
GCC把C语言源文件( ‘.c’ )编译成汇编语言文件( ‘.s’ ), 汇编器把汇编语言文件翻译成目标文件( ‘.o’ )。在目标文件中, 调试信息用 ‘.stab’ 打头的一类汇编指导命令表示, 这种调试信息格式叫’Stab’, 即符号表(Symbol table)。这些调试信息包括行号、变量的类型和作用域、函数名字、函数参数和函数的作用域等源文件的特性。
由此我们知道要求输出的信息就是调试信息。
那么是怎么把调试信息填入目标文件的呢?
在GCC编译源文件时, 如要生成Stab调试信息, 打开编译选项 ‘- gstabs’ 。汇编器处理 ‘.stab’ 打头指导命令, 把Stab中的调试信息填入 ‘.o’ 文件的符号表和串表(string table)中,最后由链接器链接所有的目标文件和有关的库生成可执行文件( ‘a.out’ ),这个可执行文件含有一个符号表和一个串表。















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









