






背景:
昨天偶然做一个爬取数据,做成直方图的小练习发现,最后出来的图标Y轴并不是按顺序排列,按照老规矩,百度一下,找到了原因,一个低级的问题
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
import bs4
import numpy as np
import matplotlib
import seaborn as sns
import requests
import pandas as pd
# import pickle
def datas() :#封装爬取数据函数,以便后续使用
url = 'https://www.iqiyi.com/dianying_new/i_list_paihangbang.html'
#按照获取的URL进行入参
res = requests.get(url)
#获取网页内容
# print(res.status_code)
#检查连接状态
bs = bs4.BeautifulSoup(res.text, 'html.parser')
#用BS解释网页
datas = bs.find('ul',class_="site-piclist").find_all('li')
#根据网页特征定位相关数据位置
data1 = {}#设置相应字典,用来装爬取到的数据并且返回
for data in datas :
mov_name = data.find('img')['title'] # 获取电影名字
try :
mov_rank = data.find('span',class_='dypd_piclist_nub dypd_piclist_nubHot').text #获取电影排名,由于前三特征与后面的不同,因此采用试错历遍相关特征
except :
mov_rank = data.find('span',class_='dypd_piclist_nub').text #同上
mov_score = data.find('span',class_='score').text #获取电影评分数据
data1[int(mov_rank)]=mov_score
return data1 # 返回获取到的数据
#-----------------------------------------------------------2.对数据进行清洗和处理---------------------------------
data_dict= datas() #提取前述数据进行处理
rate1=list(data_dict.keys())
rate2=list(data_dict.values())
d={' 排名 ':rate1,
' 评分 ':rate2}
df=pd.DataFrame(d) #将年份和比率结合一起
# print(df) #输出结果
#-----------------------------------------------------------4.对数据进行清洗和处理---------------------------------
#-----------------------------------------------------------折线图---------------------------------
# x=rate1 #设置x轴
# y=rate2
# plt.figure(figsize=(200,8),dpi=80) #设置绘制的图像和字体大小
# plt.plot(x,rate2,color = 'y',label="score")#k是黄色
# plt.xlabel("rank")#横坐标名字
# plt.ylabel("score")#纵坐标名字
# x_major_locator=MultipleLocator(10)
# #把x轴的刻度间隔设置为10,并存在变量里
# ax=plt.gca()
# #ax为两条坐标轴的实例
# ax.xaxis.set_major_locator(x_major_locator)
# #把x轴的主刻度设置为10的倍数
# plt.xlim(1,146)
# #把x轴的刻度范围设置为1到146,十倍间隔
# plt.legend(loc = "best")#图例
# plt.show()
代码为上述,但是出来的结果如图
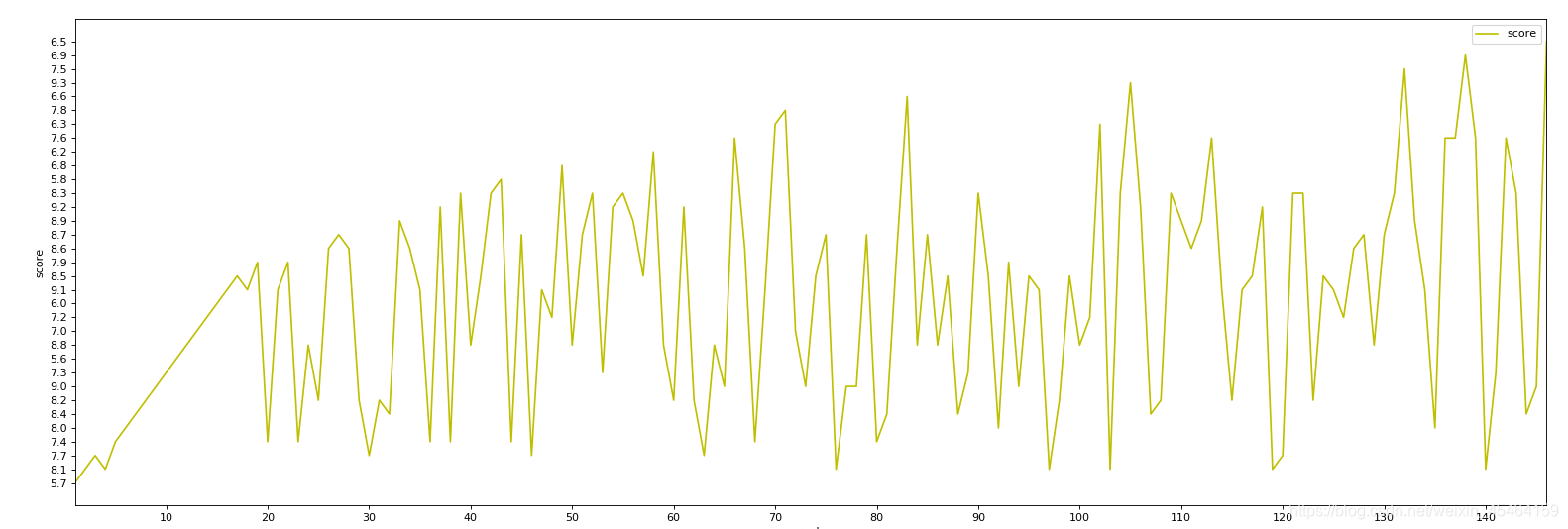
解决方案:
经过一番查证后发现其实是爬取数据的时候评分字段的数据类型是文本= =
因此多加一个int或者float就可以解决对应问题
for data in datas :
mov_name = data.find('img')['title'] # 获取电影名字
try :
mov_rank = data.find('span',class_='dypd_piclist_nub dypd_piclist_nubHot').text #获取电影排名,由于前三特征与后面的不同,因此采用试错历遍相关特征
except :
mov_rank = data.find('span',class_='dypd_piclist_nub').text #同上
mov_score = data.find('span',class_='score').text #获取电影评分数据
data1[int(mov_rank)]=float(mov_score)
输出结果
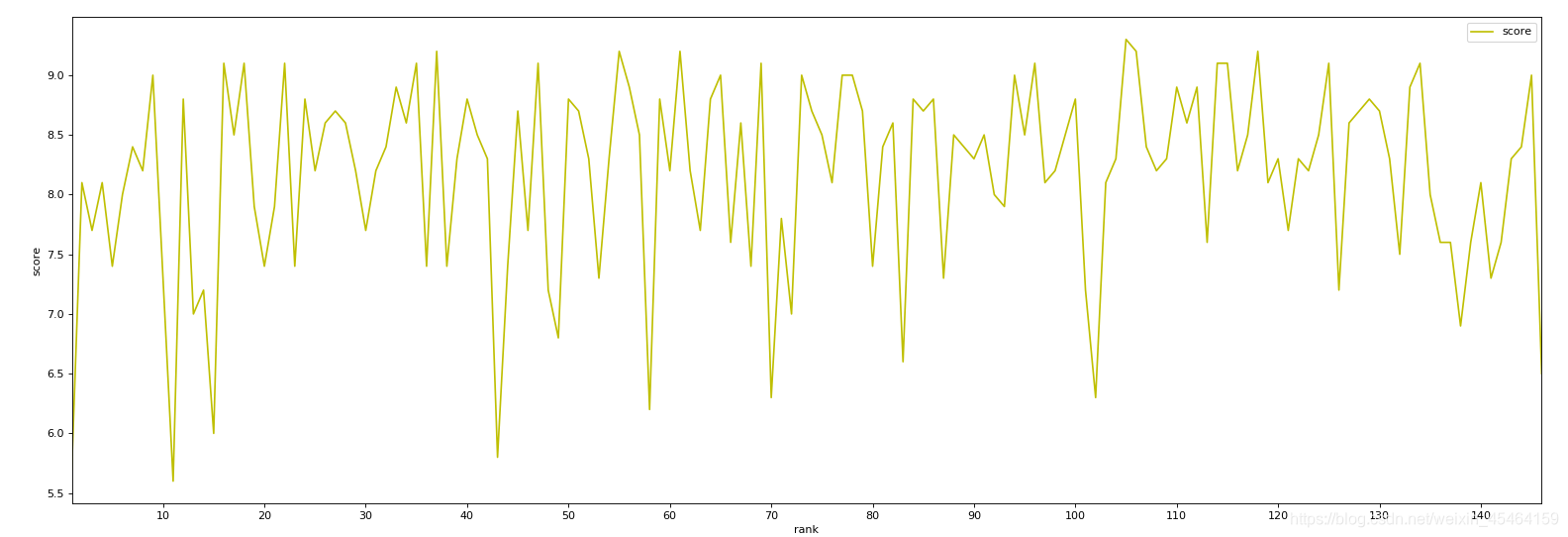 撒花(估计专业程序猿不会犯着低级错误)
撒花(估计专业程序猿不会犯着低级错误)














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









