






源代码下载地址:https://github.com/grblHAL
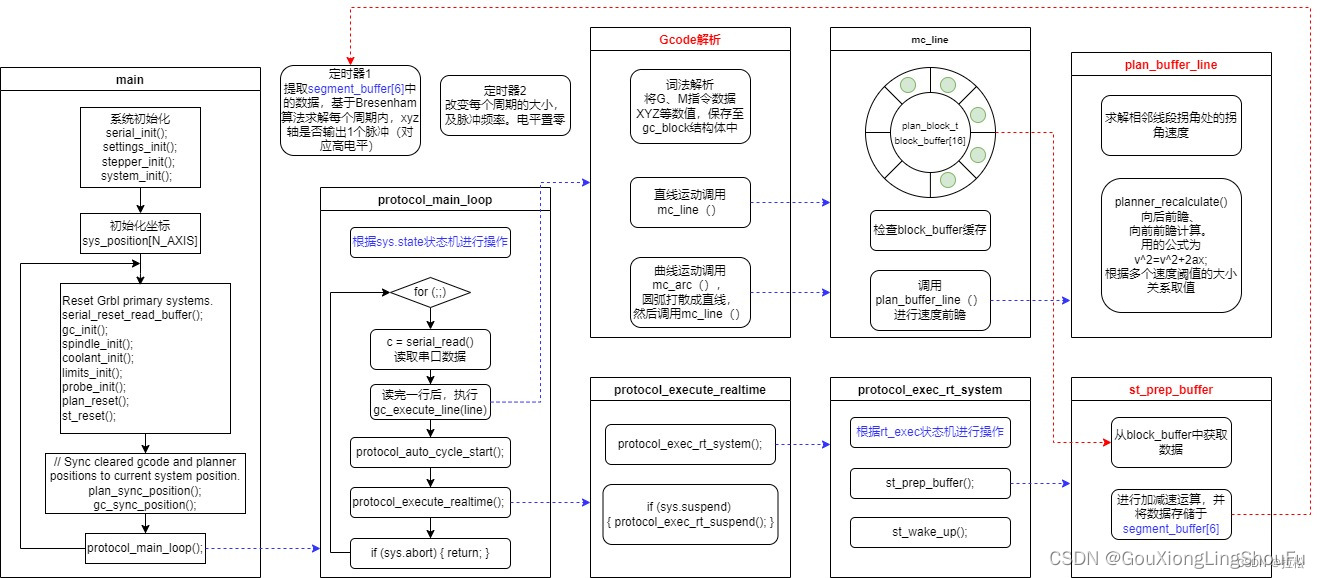 注:该图片来自《DIY运动控制器——移植grbl(软件架构、脉冲产生)---- 拉松》
注:该图片来自《DIY运动控制器——移植grbl(软件架构、脉冲产生)---- 拉松》
1 找到grblHAL入口函数
找到grbllib.cpp中的int grbl_enter (void)函数,在grbl_enter 函数中,先是对grbl核心的一些函数指针做了设置,接着对hal层的驱动做了设置,然后就是一堆初始化,包括language,gcode.mcode,alarm,errors,message,limit,setting,report,nvs,plugin和坐标系统等做了初始化。比较重要的是要知道hal.stream被初始化好了,我手上的代码是在plugin初始化的时候初始化的,重点关注一下hal.stream.read指针,大概的流程是PC发送的Gcode指令会由串口接收,串口数据会存到缓存区中,hal.stream.read能读取串口缓存区中的一个字节。在阅读代码的过程中,这些东西可以先略过。实在想看一看可以找到stream_register_streams和stream_select,在stream_select中有memcpy(&hal.stream, stream, sizeof(stream_io_t));接着进入一个循环,上来又是一堆初始化,这些初始化主要影响GRBL内核的状态,一些标志位,缓存区,消息等,让grbl内核进入初始化状态。重点需要关注:
if(!(looping = protocol_main_loop()))
这个函数才是真正干活的函数,接下来需要进入到这个函数内部。
2 Gcode指令接收
刚开始是一堆的分支,做一些消息的报告等等,这些不是重点,先忽略。接下来会看到一个死循环,然后在这个循环中能看到另一个循环:
while((c = hal.stream.read()) != SERIAL_NO_DATA)
这个循环的作用是从串口接收缓存区中读取一个字节存放到c中,接下来围绕着c又是一堆判断,可以看到:
if(!(line_flags.overflow = char_counter >= (LINE_BUFFER_SIZE - 1)))
line[char_counter++] = c;
最终c中存放的数据存放在了line这个数组中,c中的数据为’\n’或者’\r’的时候,在 } else if ((c == '\n') || (c == '\r')) {分支下能找到
gc_state.last_error = gc_execute_block(line);
可以看到,一整行G代码作为形参传递给了gc_execute_block,这里假设line中的G代码是
“G0 X0 Y0 F40000”
然后进入到gc_execute_block函数中,这个函数非常长,前面主要是对传进来的G代码做一个整理,先是去掉空行,做了一些语法上的判断,根据不同的G指令做了很多分支处理,这些解析过程可以先不关注,最终,G代码会转换成plan line data ,存储在&plan_data中。而给进参数会存在gc_block.values.xyz中(如上面的F4000中的4000)。接下来需要重点关注
3 直线圆弧插补
mc_line(gc_block.values.xyz, &plan_data);
mc_arc(gc_block.values.xyz, &plan_data, gc_state.position, gc_block.values.ijk, gc_block.values.r,
plane, gc_parser_flags.arc_is_clockwise ? -gc_block.arc_turns : gc_block.arc_turns);
先看mc_line,这个函数的作用是做直线运动,进入到这个函数之后,可以看到KINEMATICS_API和ENABLE_BACKLASH_COMPENSATION这两个宏包裹着的代码块是没有参与编译的,先不看着两个宏包裹着的代码块,那么这个函数就变成了:
bool mc_line (float *target, plan_line_data_t *pl_data)
{
if(!(pl_data->condition.target_validated && pl_data->condition.target_valid))
limits_soft_check(target, pl_data->condition);
if(state_get() != STATE_CHECK_MODE && protocol_execute_realtime()) {
do {
if(!protocol_execute_realtime())
return false;
if(plan_check_full_buffer())
protocol_auto_cycle_start();
else
break;
} while(true);
if(!plan_buffer_line(target, pl_data) && pl_data->spindle.hal->cap.laser && pl_data->spindle.state.on && !pl_data->spindle.state.ccw) {
protocol_buffer_synchronize();
pl_data->spindle.hal->set_state(pl_data->spindle.state, pl_data->spindle.rpm);
}
}
return !ABORTED;
}
这样看简洁了很多,当然并不是说这些宏内包裹的代码块不重要,我们到后面对GRBL研究更深入了再去分析这些代码块。
if(!(pl_data->condition.target_validated && pl_data->condition.target_valid))
在settings.c中能找到
{ Setting_SoftLimitsEnable, Group_Limits, LANG_GRBL_TEXT(Setting_SoftLimitsEnable_Name), NULL, Format_Bool, NULL, NULL, NULL, Setting_IsLegacyFn, set_soft_limits_enable, get_int, NULL },
大概的执行逻辑是:
1.收到$20
2.执行set_soft_limits_enable
3.调用tmp_set_soft_limits
4.sys.soft_limits.mask的对应位被设置为1
在gc_execute_block函数调用mc_line前,在STEP 4: EXECUTE!!的操作中,有
plan_data.condition.target_validated = plan_data.condition.target_valid = sys.soft_limits.mask == 0;
在GRBL中软件限位默认是开启的,也就是说plan_data.condition.target_validated = plan_data.condition.target_valid = 0;
limits_soft_check(target, pl_data->condition);函数是会被执行的。
接下来进入到limits_soft_check,可以看到KINEMATICS_API宏没有生效,走下面的分支
if(condition.target_validated ? !condition.target_valid : !grbl.check_travel_limits(target, sys.soft_limits, true)) {
根据上面的分析 condition.target_validated 的值为0 ,sys.soft_limits的值为0,三目运算符会执行“!grbl.check_travel_limits(target, sys.soft_limits, true)”找到
grbl.check_travel_limits = check_travel_limits;
当前形参传递进来的参数是4000(target = gc_block.values.xyz), 0b00000111(sys.soft_limits), true。进入 check_travel_limits 函数
static bool check_travel_limits (float *target, axes_signals_t axes, bool is_cartesian)
{
bool failed = false;
uint_fast8_t idx = N_AXIS;
if(is_cartesian && (sys.homed.mask & axes.mask)) do {
idx--;
if(bit_istrue(sys.homed.mask, bit(idx)) && bit_istrue(axes.mask, bit(idx)))
failed = target[idx] < sys.work_envelope.min.values[idx] || target[idx] > sys.work_envelope.max.values[idx];
} while(!failed && idx);
return is_cartesian && !failed;
}
这个函数判断所有的轴的给进量有没有超出允许的范围,如果超出了就返回false
回到limits_soft_check函数
这里我们先假设4000超过了最大的允许范围,那么会执行
sys.flags.soft_limit = On;
if(state_get() == STATE_CYCLE) {
system_set_exec_state_flag(EXEC_FEED_HOLD);
do {
if(!protocol_execute_realtime())
return;
} while(state_get() != STATE_IDLE);
}
mc_reset();
system_set_exec_alarm(Alarm_SoftLimit);
protocol_execute_realtime();
可以看到,超出范围之后,会调用mc_reset直接让系统复位,然后报告限位警告。
如果没有超出限位,limits_soft_check函数什么都不执行。
回到mc_line函数中。
protocol_execute_realtime();
这个函数是执行实时指令的,到处都是,也是一个很重要的函数,但是这里先不分析,后面进去看的,假定if(state_get() != STATE_CHECK_MODE && protocol_execute_realtime()) 的条件成立。
先检查plan block缓存区是不是满的,如果是满的会将系统状态标记为EXEC_CYCLE_START (执行循环启动)
4 运动规划
if(plan_check_full_buffer())
protocol_auto_cycle_start(); // Auto-cycle start when buffer is full.
接着在plan_buffer_line(target, pl_data)函数中作运动规划,这个函数是重点,它的注释为:
向缓冲区添加一个新的线性移动。target[N_AXIS]是带符号的绝对目标位置,以毫米为单位。进给速率指定运动的速度。如果进料速率是反向的,则进料速率表示“频率”,并将在1/feed_rate分钟内完成操作。传递给规划器的所有位置数据必须是机器位置,以保持规划器不受任何坐标系变化和偏移的影响,这些变化和偏移由g代码解析器处理。l注意:假设有可用的缓冲区。缓冲区检查在更高的级别由motion_control处理。换句话说,缓冲头永远不等于缓冲尾。此外,输入速率值有三种使用方式:如果invert_feed_rate为假,则作为正常的输入速率;如果invert_feed_rate为真,则作为逆时间;如果feed_rate为负,则作为seek/rapids速率(并且invert_feed_rate总是为假)。系统运动条件告诉规划器在总是未使用的块缓冲头中规划一个运动。避免改变规划器状态,保留缓冲区,保证后续模型运动仍能正确规划,而步进模块只指向块缓冲头执行特殊的系统运动。
简化一下这个函数,不考虑轴大于三和运动学的情况,就得到了下面这个函数:
bool plan_buffer_line (float *target, plan_line_data_t *pl_data)
{
plan_block_t *block = block_buffer_head;
int32_t target_steps[N_AXIS], position_steps[N_AXIS], delta_steps;
uint_fast8_t idx;
float unit_vec[N_AXIS];
memset(block, 0, sizeof(plan_block_t) - 2 * sizeof(plan_block_t *));
memcpy(&block->spindle, &pl_data->spindle, sizeof(spindle_t));
block->condition = pl_data->condition;
block->overrides = pl_data->overrides;
block->line_number = pl_data->line_number;
block->output_commands = pl_data->output_commands;
block->message = pl_data->message;
pl_data->message = NULL;
memcpy(position_steps, block->condition.system_motion ? sys.position : pl.position, sizeof(position_steps));
idx = N_AXIS;
do {
idx--;
target_steps[idx] = lroundf(target[idx] * settings.axis[idx].steps_per_mm);
if((delta_steps = target_steps[idx] - position_steps[idx])) {
block->steps[idx] = labs(delta_steps);
block->step_event_count = max(block->step_event_count, block->steps[idx]);
unit_vec[idx] = (float)delta_steps / settings.axis[idx].steps_per_mm;
} else {
block->steps[idx] = 0;
unit_vec[idx] = 0.0f;
}
if (delta_steps < 0)
block->direction_bits.mask |= bit(idx);
} while(idx);
if(block->spindle.css) {
float pos;
if((pos = (float)position_steps[block->spindle.css->axis] / settings.axis[block->spindle.css->axis].steps_per_mm - block->spindle.css->tool_offset) > 0.0f) {
if((block->spindle.rpm = block->spindle.css->surface_speed / (pos * (float)(2.0f * M_PI))) > block->spindle.css->max_rpm)
block->spindle.rpm = block->spindle.css->max_rpm;
} else
block->spindle.rpm = block->spindle.css->max_rpm;
if((pos = target[block->spindle.css->axis] - block->spindle.css->tool_offset) > 0.0f) {
if((block->spindle.css->target_rpm = block->spindle.css->surface_speed / (pos * (float)(2.0f * M_PI))) > block->spindle.css->max_rpm)
block->spindle.css->target_rpm = block->spindle.css->max_rpm;
} else
block->spindle.css->target_rpm = block->spindle.css->max_rpm;
block->spindle.css->delta_rpm = block->spindle.css->target_rpm - block->spindle.rpm;
}
if (block->step_event_count == 0)
return false;
pl_data->message = NULL;
pl_data->output_commands = NULL;
block->millimeters = convert_delta_vector_to_unit_vector(unit_vec);
block->acceleration = limit_acceleration_by_axis_maximum(unit_vec);
block->rapid_rate = limit_max_rate_by_axis_maximum(unit_vec);
if (block->condition.rapid_motion)
block->programmed_rate = block->rapid_rate;
else {
block->programmed_rate = pl_data->feed_rate;
if (block->condition.inverse_time)
block->programmed_rate *= block->millimeters;
}
if ((block_buffer_head == block_buffer_tail) || (block->condition.system_motion)) {
block->entry_speed_sqr = 0.0f;
block->max_junction_speed_sqr = 0.0f;
} else {
float junction_unit_vec[N_AXIS];
float junction_cos_theta = 0.0f;
idx = N_AXIS;
do {
idx--;
junction_cos_theta -= pl.previous_unit_vec[idx] * unit_vec[idx];
junction_unit_vec[idx] = unit_vec[idx] - pl.previous_unit_vec[idx];
} while(idx);
if (junction_cos_theta > 0.999999f)
block->max_junction_speed_sqr = MINIMUM_JUNCTION_SPEED * MINIMUM_JUNCTION_SPEED;
else if (junction_cos_theta < -0.999999f) {
block->max_junction_speed_sqr = SOME_LARGE_VALUE;
} else {
convert_delta_vector_to_unit_vector(junction_unit_vec);
float junction_acceleration = limit_acceleration_by_axis_maximum(junction_unit_vec);
float sin_theta_d2 = sqrtf(0.5f * (1.0f - junction_cos_theta));
block->max_junction_speed_sqr = max(MINIMUM_JUNCTION_SPEED * MINIMUM_JUNCTION_SPEED,
(junction_acceleration * settings.junction_deviation * sin_theta_d2) / (1.0f - sin_theta_d2));
}
}
if (!block->condition.system_motion) {
pl.previous_nominal_speed = plan_compute_profile_parameters(block, plan_compute_profile_nominal_speed(block), pl.previous_nominal_speed);
if(!block->condition.backlash_motion) {
memcpy(pl.previous_unit_vec, unit_vec, sizeof(unit_vec));
memcpy(pl.position, target_steps, sizeof(target_steps));
}
block_buffer_head = next_buffer_head;
next_buffer_head = block_buffer_head->next;
planner_recalculate();
}
return true;
}
先看target_steps[idx] = lroundf(target[idx] * settings.axis[idx].steps_per_mm);lroundf这个函数的作用是将传进去的浮点数做一个四舍五入的取整,settings.axis[idx].steps_per_mm的值的初始化过程是这样的:
PROGMEM const settings_t defaults = {
......
.axis[X_AXIS].steps_per_mm = DEFAULT_X_STEPS_PER_MM,
......
}
// DEFAULT_X_STEPS_PER_MM 这个宏表示移动1mm需要多少步,需要通过齿轮的尺比等进行计算。
nvs_buffer_init
settings_restore(settings_all);
memcpy(&settings, &defaults, sizeof(settings_t));
通过上面这个计算,能将移动的距离转换成步进电机的步数。
if((delta_steps = target_steps[idx] - position_steps[idx]))
target_steps[idx] - position_steps[idx]这个计算能得到运动的方向和运动到目标位置需要多少步(target_steps[idx]和position_steps[idx]在坐标系内使用同一个参考点),delta_steps != 0的时候判断成立。
labs函数的作用是取整型变量的绝对值。
block->step_event_count = max(block->step_event_count, block->steps[idx]);
这个是为了记录当前运动块(block)中所需要的最大的步数,一条G指令可以被认为是一个运动块,运动块是指一个或多个轴运动到指定位置,举个例子:激光头现在在x,y(100,50)的位置,需要运行到(60,500)的位置,那这样的一个过程就是一个运动控制块。block->step_event_count记录的是x,y两根轴运动距离最长的步数。
unit_vec[idx] = (float)delta_steps / settings.axis[idx].steps_per_mm;
delta_steps 表示在该轴上从当前位置到目标位置需要的步数,settings.axis[idx].steps_per_mm 是该轴上每毫米对应的步数。因此,delta_steps / settings.axis[idx].steps_per_mm 计算的是在该轴上从当前位置到目标位置的距离(以毫米为单位)。将这个值赋给 unit_vec[idx],就得到了单位向量在该轴上的分量。
if (delta_steps < 0)
block->direction_bits.mask |= bit(idx);
这段代码的作用是设置方向位。位启用总是意味着方向是负的。
接着追踪一下block->spindle.css是怎么赋值的:
grbl.on_execute_realtime 的赋值是在plugin初始化的时候完成的,这是一个钩子函数,
这个函数内会完成一些辅助主轴工作的配件的相关控制,例如散热风扇。
当grbl.on_execute_realtime被递归调用完之后会返回true,接着sys_spindle[spindle_num].enabled会被设置为ture。
status_code_t gc_execute_block (char *block)
gc_state.spindle.hal = gc_block.spindle = spindle_get(gc_block.values.$); //在这里确定hal指针是不是NULL
gc_state.spindle.css = &gc_state.spindle.hal->param->css;
memcpy(&plan_data.spindle, &gc_state.spindle, sizeof(spindle_t));
mc_line(gc_block.values.xyz, &plan_data);
bool mc_line (float *target, plan_line_data_t *pl_data)
if(!plan_buffer_line(target, pl_data) && pl_data->spindle.hal->cap.laser && pl_data->spindle.state.on && !pl_data->spindle.state.ccw)
bool plan_buffer_line (float *target, plan_line_data_t *pl_data)
memcpy(&block->spindle, &pl_data->spindle, sizeof(spindle_t));
if(block->spindle.css)
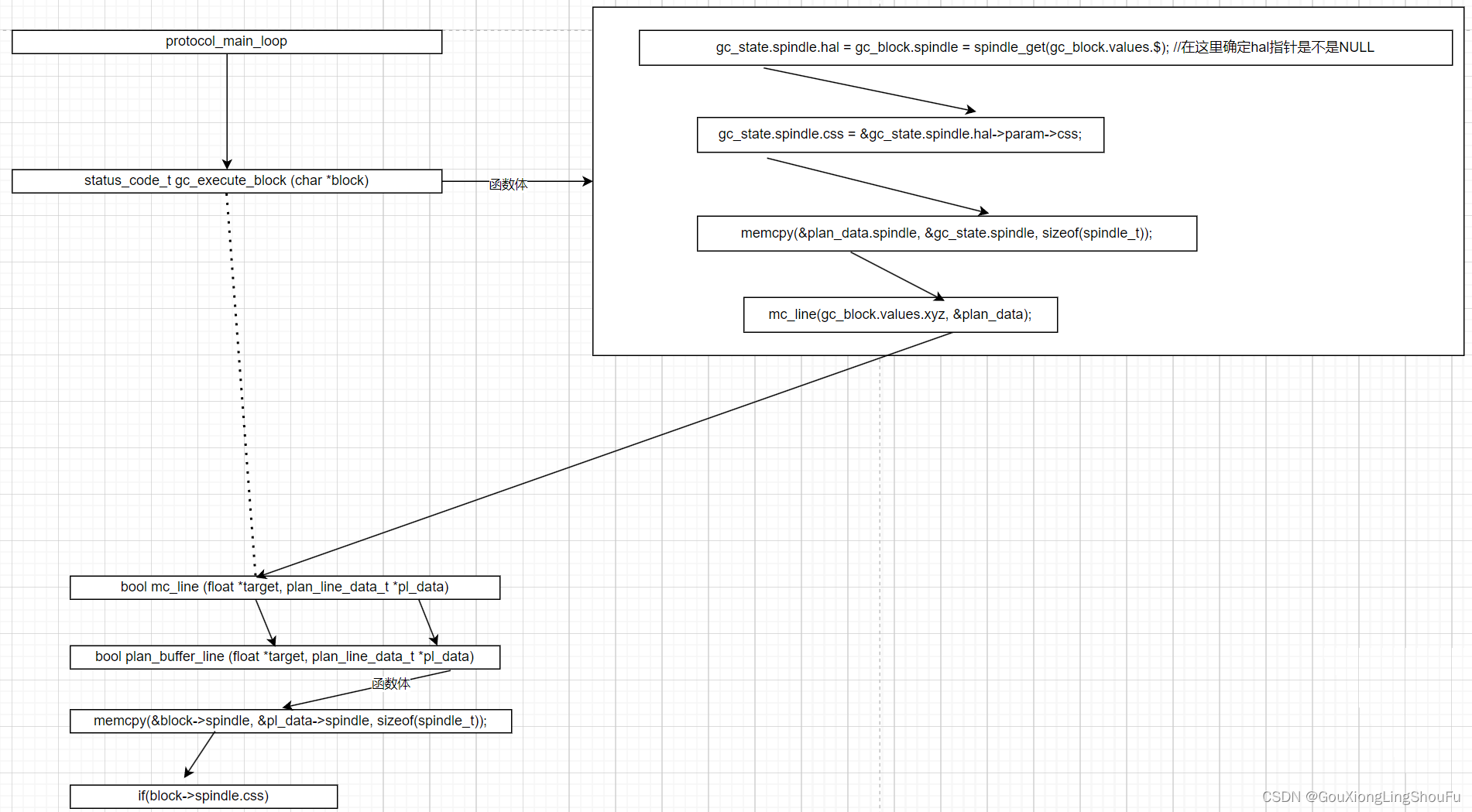
接着进入if的语句块内部。
if((pos = (float)position_steps[block->spindle.css->axis] / settings.axis[block->spindle.css->axis].steps_per_mm - block->spindle.css->tool_offset) > 0.0f) {
spindle.css->tool_offset:这个是表示当前钻头距离G92设置的原点之间的距离。
(float)position_steps[block->spindle.css->axis] / settings.axis[block->spindle.css:这是在计算当前钻头的位置,所以这个表达式就是当前位置距离参考点之间的距离。
block->spindle.rpm = block->spindle.css->surface_speed / (pos * (float)(2.0f * M_PI))
主轴转速(rpm)= 表面速度(surface_speed)/ (pos * (2π))
其中,
表面速度是工件上某一点在加工过程中的线速度。
pos 是钻头距离 G92 设置的参考点之间的距离。
2π 是圆周率(pi)的两倍,用于将距离转换为一个完整圆的周长。
至于
if((pos = (float)position_steps[block->spindle.css->axis] / settings.axis[block->spindle.css->axis].steps_per_mm - block->spindle.css->tool_offset) > 0.0f) {
if((block->spindle.rpm = block->spindle.css->surface_speed / (pos * (float)(2.0f * M_PI))) > block->spindle.css->max_rpm)
block->spindle.rpm = block->spindle.css->max_rpm;
} else
block->spindle.rpm = block->spindle.css->max_rpm;
这很容易就能看出来是将rpm限制在最大转速范围内。
block->millimeters = convert_delta_vector_to_unit_vector(unit_vec);
block->acceleration = limit_acceleration_by_axis_maximum(unit_vec);
block->rapid_rate = limit_max_rate_by_axis_maximum(unit_vec);
block->millimeters = convert_delta_vector_to_unit_vector(unit_vec);这里做的是向量归一化。
block->acceleration = limit_acceleration_by_axis_maximum(unit_vec);计算的是每mm的加速度增量,加速度/运动距离
float junction_unit_vec[N_AXIS];
float junction_cos_theta = 0.0f;
idx = N_AXIS;
do {
idx--;
junction_cos_theta -= pl.previous_unit_vec[idx] * unit_vec[idx];
junction_unit_vec[idx] = unit_vec[idx] - pl.previous_unit_vec[idx];
} while(idx);
// NOTE: Computed without any expensive trig, sin() or acos(), by trig half angle identity of cos(theta).
if (junction_cos_theta > 0.999999f)
// For a 0 degree acute junction, just set minimum junction speed.
block->max_junction_speed_sqr = MINIMUM_JUNCTION_SPEED * MINIMUM_JUNCTION_SPEED;
else if (junction_cos_theta < -0.999999f) {
// Junction is a straight line or 180 degrees. Junction speed is infinite.
block->max_junction_speed_sqr = SOME_LARGE_VALUE;
} else {
convert_delta_vector_to_unit_vector(junction_unit_vec);
float junction_acceleration = limit_acceleration_by_axis_maximum(junction_unit_vec);
float sin_theta_d2 = sqrtf(0.5f * (1.0f - junction_cos_theta)); // Trig half angle identity. Always positive.
block->max_junction_speed_sqr = max(MINIMUM_JUNCTION_SPEED * MINIMUM_JUNCTION_SPEED,
(junction_acceleration * settings.junction_deviation * sin_theta_d2) / (1.0f - sin_theta_d2));
}
这里是在计算余弦相似度(假设向量模为1),根据结算结果设置不同拐点的加速度。
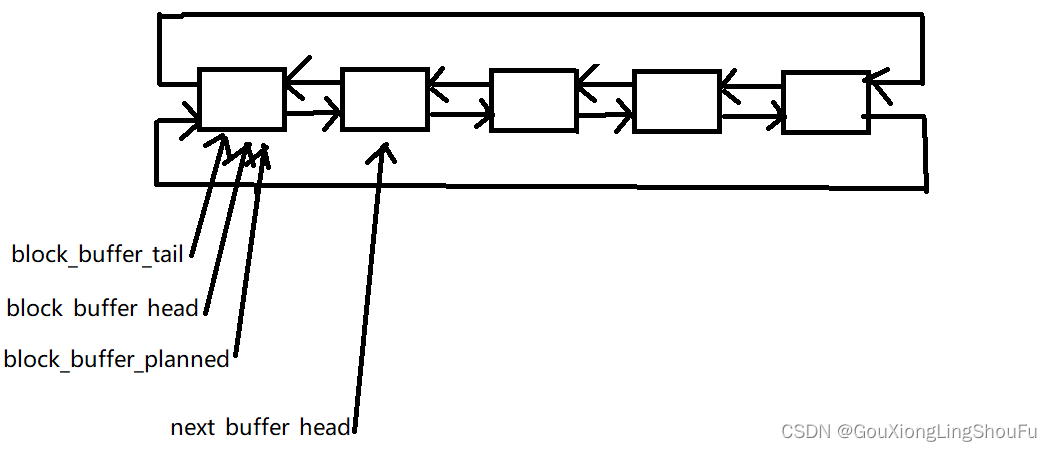
接下来需要追踪一下block指针指向的block_buffer_head这个数据结构,
先找到inline static void plan_reset_buffer (void)函数,通过他可以知道这个环形缓冲区的指针的初始状态
inline static void plan_reset_buffer (void)
{
if(block_buffer_tail) {
// Free memory for any pending messages and output commands after soft reset
while(block_buffer_tail != block_buffer_head) {
plan_cleanup(block_buffer_tail);
block_buffer_tail = block_buffer_tail->next;
}
}
block_buffer_tail = block_buffer_head = block_buffer; // Empty = tail == head
next_buffer_head = block_buffer_head->next; // = next block
block_buffer_planned = block_buffer_tail; // = block_buffer_tail
}
可以看到,环形缓冲区的内存是block_buffer指向的内存块,搜索block_buffer = 定位到了bool plan_reset (void)
plan_reset 则是在grbl_enter()中就被调用了,这说明在GRBL开始真正运行起来前,跟运动规划相关的内存就分配好了,接下来详细看一下plan_reset。
bool plan_reset (void)
{
if(block_buffer == NULL) {
block_buffer_size = settings.planner_buffer_blocks;//这里决定了这个环形缓冲区的大小,可以通过setting去设置,默认值在Config.h中的宏决定。
while((block_buffer = malloc((block_buffer_size + 1) * sizeof(plan_block_t))) == NULL) {//尝试分配内存,如果分配失败进入循环
if(block_buffer_size > 40)//如果连40个以下的element都申请不到,直接退出这个步骤。
block_buffer_size -= block_buffer_size >= 250 ? 100 : 10;//申请的element的数量大于250,则-100个element后再尝试申请,否则,-10后再次尝试申请。
else
break;
}
}
//实际申请到的element不达预期,上报警告信息。
if(block_buffer_size != settings.planner_buffer_blocks)
protocol_enqueue_rt_command(planner_warning);
if(block_buffer == NULL)//申请内存失败向上层抛出错误。
return false;
if(block_buffer_tail) {
while(block_buffer_tail != block_buffer_head) {
plan_cleanup(block_buffer_tail);
block_buffer_tail = block_buffer_tail->next;
}
block_buffer_tail = NULL;
}
memset(&pl, 0, sizeof(planner_t)); // Clear planner struct
uint_fast8_t idx;
//将block_buffer指向的内存变成了一个双向的循环链表。
for(idx = 0 ; idx <= block_buffer_size ; idx++) {
block_buffer[idx].prev = &block_buffer[idx == 0 ? block_buffer_size : idx - 1];
block_buffer[idx].next = &block_buffer[idx == block_buffer_size ? 0 : idx + 1];
}
plan_reset_buffer();
return true;
}
这个代码运行完之后,这些指针和内存之间的关系如图所示:
回到bool plan_buffer_line (float *target, plan_line_data_t *pl_data)函数中,pl_data中的参数赋值给了block指针指向的地址,也就是block_buffer_head指针指向的地址,block_buffer_head指针是这样移动的:
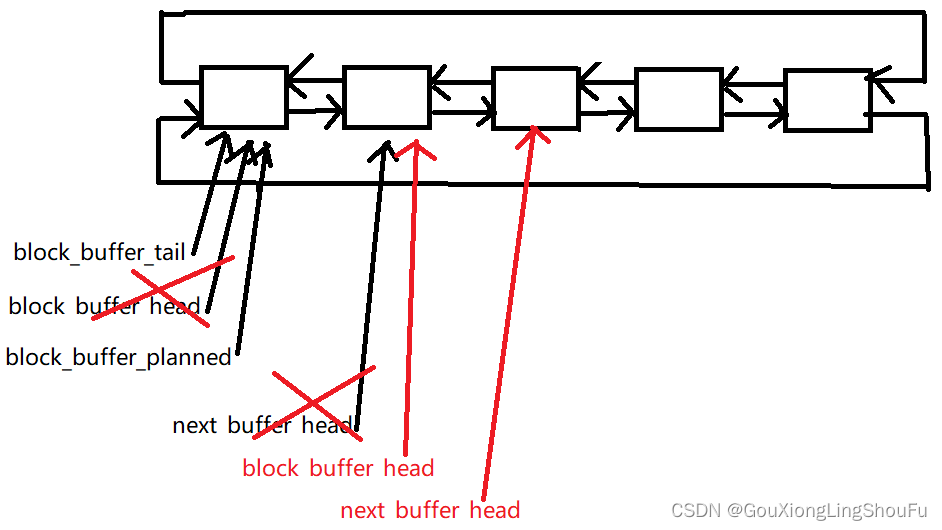
就是下面这段代码里面实现的这个指针移动,block->condition.system_motion默认是0的,但是我还没找到它什么时候变成了1.
if (!block->condition.system_motion) {
pl.previous_nominal_speed = plan_compute_profile_parameters(block, plan_compute_profile_nominal_speed(block), pl.previous_nominal_speed);
if(!block->condition.backlash_motion) {
memcpy(pl.previous_unit_vec, unit_vec, sizeof(unit_vec));
memcpy(pl.position, target_steps, sizeof(target_steps));
}
block_buffer_head = next_buffer_head;
next_buffer_head = block_buffer_head->next;
planner_recalculate();
}
static void planner_recalculate (void)函数这里面是前瞻算法,它的主要作用是重新计算运动计划中各个块(block)的入口速度(entry_speed_sqr),以确保整个运动过程的平滑性和安全性。这个过程通常被称为速度规划或速度平滑。反向遍历(Reverse pass):从最后一个规划好的块开始,向前遍历到第一个规划好的块。在这个过程中,根据每个块的加速度(acceleration)、行进距离(millimeters)和后续块的入口速度,计算当前块的最大可能入口速度(entry_speed_sqr),同时确保不超过块的最大入口速度(max_entry_speed_sqr)。这个过程是为了确保在每个转折点,机器都能以安全的速度减速到下一个块。
正向遍历(Forward pass):从第一个规划好的块开始,向后遍历到最后一个规划好的块。在这个过程中,根据每个块的加速度、行进距离和前一个块的入口速度,重新计算当前块的入口速度,以确保加速过程的平滑性。最后计算好的数据存在plan_buffer每个element的entry_speed_sqr 字段中。
再一次回到mc_line函数内部,这次需要进入protocol_execute_realtime函数了。
bool protocol_execute_realtime (void)
{
if(protocol_exec_rt_system()) {
sys_state_t state = state_get();
if(sys.suspend)
protocol_exec_rt_suspend(state);
#if NVSDATA_BUFFER_ENABLE
if((state == STATE_IDLE || (state & (STATE_ALARM|STATE_ESTOP))) && settings_dirty.is_dirty && !gc_state.file_run)
nvs_buffer_sync_physical();
#endif
}
return !ABORTED;
}
先进去protocol_exec_rt_system函数
if (sys.rt_exec_alarm && (rt_exec = system_clear_exec_alarm())) { // Enter only if any bit flag is true
if((sys.reset_pending = !!(sys.rt_exec_state & EXEC_RESET))) {
killed = true;
spindle_all_off();
hal.coolant.set_state((coolant_state_t){0});
}
system_raise_alarm((alarm_code_t)rt_exec);
if(killed)
hal.driver_reset();
if((sys.blocking_event = (alarm_code_t)rt_exec == Alarm_HardLimit ||
(alarm_code_t)rt_exec == Alarm_SoftLimit ||
(alarm_code_t)rt_exec == Alarm_EStop ||
(alarm_code_t)rt_exec == Alarm_MotorFault)) {
system_set_exec_alarm(rt_exec);
switch((alarm_code_t)rt_exec) {
case Alarm_EStop:
grbl.report.feedback_message(Message_EStop);
break;
case Alarm_MotorFault:
grbl.report.feedback_message(Message_MotorFault);
break;
default:
grbl.report.feedback_message(Message_CriticalEvent);
break;
}
system_clear_exec_state_flag(EXEC_RESET); // Disable any existing reset
*line = '\0';
char_counter = 0;
hal.stream.reset_read_buffer();
while (bit_isfalse(sys.rt_exec_state, EXEC_RESET)) {
if(bit_istrue(sys.rt_exec_state, EXEC_STATUS_REPORT)) {
system_clear_exec_state_flag(EXEC_STATUS_REPORT);
report_realtime_status();
}
protocol_poll_cmd();
grbl.on_execute_realtime(STATE_ESTOP);
}
system_clear_exec_alarm(); // Clear alarm
}
}
这部分代码负责处理系统中发生的各种报警情况。具体来说,它检查是否有报警被触发(sys.rt_exec_alarm),如果有,就执行相应的处理逻辑。以下是主要的处理步骤:
- 检查重置请求:如果检测到重置请求(EXEC_RESET),则关闭主轴和冷却液,并标记系统需要重置(sys.reset_pending)。
- 引发报警:根据报警类型(rt_exec),引发相应的报警。
- 处理关键事件:如果报警是由硬限位、软限位、紧急停止或电机故障引发的,则将其视为阻塞事件(sys.blocking_event),并根据报警类型给出相应的反馈信息。
- 等待重置:如果发生了关键事件,系统将等待重置命令。在等待期间,它会不断检查是否有状态报告请求或其他实时命令,并相应地执行它们。
- 清除报警:一旦收到重置命令,系统将清除报警标志,并继续正常运行。
if (sys.rt_exec_state && (rt_exec = system_clear_exec_states())) {
if((sys.reset_pending = !!(rt_exec & EXEC_RESET))) {
if(!killed) {
spindle_all_off();
hal.coolant.set_state((coolant_state_t){0});
}
if(!(sys.abort = !hal.control.get_state().e_stop)) {
hal.stream.reset_read_buffer();
system_raise_alarm(Alarm_EStop);
grbl.report.feedback_message(Message_EStop);
} else if(hal.control.get_state().motor_fault) {
sys.abort = false;
hal.stream.reset_read_buffer();
system_raise_alarm(Alarm_MotorFault);
grbl.report.feedback_message(Message_MotorFault);
}
if(!killed)
hal.driver_reset();
return !sys.abort;
}
if(rt_exec & EXEC_STOP) {
sys.cancel = true;
sys.step_control.flags = 0;
sys.flags.feed_hold_pending = Off;
sys.override_delay.flags = 0;
if(sys.override.control.sync)
sys.override.control = gc_state.modal.override_ctrl;
gc_state.tool_change = false;
gc_state.modal.spindle.rpm_mode = SpindleSpeedMode_RPM;
hal.driver_reset();
if(!sys.flags.keep_input && hal.stream.suspend_read && hal.stream.suspend_read(false))
hal.stream.cancel_read_buffer(); // flush pending blocks (after M6)
sys.flags.keep_input = Off;
gc_init();
plan_reset();
st_reset();
sync_position();
gc_spindle_off();
gc_coolant_off();
flush_override_buffers();
if(!((state_get() == STATE_ALARM) && (sys.alarm == Alarm_LimitsEngaged || sys.alarm == Alarm_HomingRequired)))
state_set(hal.control.get_state().safety_door_ajar ? STATE_SAFETY_DOOR : STATE_IDLE);
}
if (rt_exec & EXEC_STATUS_REPORT)
report_realtime_status();
if(rt_exec & EXEC_GCODE_REPORT)
report_gcode_modes();
if(rt_exec & EXEC_TLO_REPORT)
report_tool_offsets();
if (rt_exec & EXEC_PID_REPORT)
report_pid_log();
if(rt_exec & EXEC_RT_COMMAND)
protocol_execute_rt_commands();
rt_exec &= ~(EXEC_STOP|EXEC_STATUS_REPORT|EXEC_GCODE_REPORT|EXEC_PID_REPORT|EXEC_TLO_REPORT|EXEC_RT_COMMAND);
if(sys.flags.feed_hold_pending) {
if(rt_exec & EXEC_CYCLE_START)
sys.flags.feed_hold_pending = Off;
else if(!sys.override.control.feed_hold_disable)
rt_exec |= EXEC_FEED_HOLD;
}
if(rt_exec)
state_update(rt_exec);
}
这段代码主要处理系统的实时状态和执行实时命令。具体来说,它包括以下几个部分:
- 重置处理:如果检测到重置请求 (EXEC_RESET),则关闭主轴和冷却液,并根据控制信号的状态(如紧急停止和电机故障)更新系统的报警和中止状态。如果没有被“杀死”(killed),则执行驱动器重置。
- 停止执行:如果检测到停止请求 (EXEC_STOP),则设置取消标志(sys.cancel),重置各种系统状态和控制标志,并重新初始化 G-code 解析器和运动规划器。如果当前状态不是报警状态或需要回零,则将系统状态设置为空闲或安全门打开状态。
- 状态报告:如果有状态报告请求 (EXEC_STATUS_REPORT),则报告实时状态。
- G-code 模式报告:如果有 G-code 模式报告请求 (EXEC_GCODE_REPORT),则报告当前 G-code 模式。
- 工具偏移报告:如果有工具偏移报告请求 (EXEC_TLO_REPORT),则报告工具长度偏移。
- PID 日志报告:如果有 PID 日志报告请求 (EXEC_PID_REPORT),则报告 PID 日志。
- 执行实时命令:如果有实时命令执行请求 (EXEC_RT_COMMAND),则执行实时命令。
- 喂送保持处理:如果有喂送保持请求 (EXEC_FEED_HOLD),则根据系统设置更新喂送保持标志。
- 状态更新:根据实时执行标志更新系统状态。
grbl.on_execute_realtime(state_get());
这一段是跟插件有关需要实时处理的内容
if(!sys.override_delay.feedrate && (rt_exec = get_feed_override())) {
override_t new_f_override = sys.override.feed_rate;
override_t new_r_override = sys.override.rapid_rate;
do {
switch(rt_exec) {
case CMD_OVERRIDE_FEED_RESET:
new_f_override = DEFAULT_FEED_OVERRIDE;
break;
case CMD_OVERRIDE_FEED_COARSE_PLUS:
new_f_override += FEED_OVERRIDE_COARSE_INCREMENT;
break;
case CMD_OVERRIDE_FEED_COARSE_MINUS:
new_f_override -= FEED_OVERRIDE_COARSE_INCREMENT;
break;
case CMD_OVERRIDE_FEED_FINE_PLUS:
new_f_override += FEED_OVERRIDE_FINE_INCREMENT;
break;
case CMD_OVERRIDE_FEED_FINE_MINUS:
new_f_override -= FEED_OVERRIDE_FINE_INCREMENT;
break;
case CMD_OVERRIDE_RAPID_RESET:
new_r_override = DEFAULT_RAPID_OVERRIDE;
break;
case CMD_OVERRIDE_RAPID_MEDIUM:
new_r_override = RAPID_OVERRIDE_MEDIUM;
break;
case CMD_OVERRIDE_RAPID_LOW:
new_r_override = RAPID_OVERRIDE_LOW;
break;
}
new_f_override = constrain(new_f_override, MIN_FEED_RATE_OVERRIDE, MAX_FEED_RATE_OVERRIDE);
} while((rt_exec = get_feed_override()));
plan_feed_override(new_f_override, new_r_override);
}
这段代码主要处理进给率和快移速率的实时重写(override)命令。具体来说,它执行以下操作:
- 获取重写命令:通过 get_feed_override 函数获取当前的进给率或快移重写命令。
- 根据命令调整重写值:根据获取的命令,调整新的进给率重写值(new_f_override)和快移速率重写值(new_r_override)。命令包括重置进给率和快移速率到默认值、粗调和微调进给率增加或减少,以及设置快移速率到中等或低速。
- 限制重写值范围:确保新的重写值在允许的范围内(MIN_FEED_RATE_OVERRIDE 到 MAX_FEED_RATE_OVERRIDE)。
- 更新计划重写值:使用 plan_feed_override 函数更新运动计划系统中的进给率和快移速率重写值。
if(!sys.override_delay.spindle && (rt_exec = get_spindle_override())) {
bool spindle_stop = false;
spindle_ptrs_t *spindle = gc_spindle_get();
override_t last_s_override = spindle->param->override_pct;
do {
switch(rt_exec) {
case CMD_OVERRIDE_SPINDLE_RESET:
last_s_override = DEFAULT_SPINDLE_RPM_OVERRIDE;
break;
case CMD_OVERRIDE_SPINDLE_COARSE_PLUS:
last_s_override += SPINDLE_OVERRIDE_COARSE_INCREMENT;
break;
case CMD_OVERRIDE_SPINDLE_COARSE_MINUS:
last_s_override -= SPINDLE_OVERRIDE_COARSE_INCREMENT;
break;
case CMD_OVERRIDE_SPINDLE_FINE_PLUS:
last_s_override += SPINDLE_OVERRIDE_FINE_INCREMENT;
break;
case CMD_OVERRIDE_SPINDLE_FINE_MINUS:
last_s_override -= SPINDLE_OVERRIDE_FINE_INCREMENT;
break;
case CMD_OVERRIDE_SPINDLE_STOP:
spindle_stop = !spindle_stop;
break;
default:
if(grbl.on_unknown_accessory_override)
grbl.on_unknown_accessory_override(rt_exec);
break;
}
last_s_override = constrain(last_s_override, MIN_SPINDLE_RPM_OVERRIDE, MAX_SPINDLE_RPM_OVERRIDE);
} while((rt_exec = get_spindle_override()));
spindle_set_override(spindle, last_s_override);
if (spindle_stop && state_get() == STATE_HOLD && gc_state.modal.spindle.state.on) {
if (!sys.override.spindle_stop.value)
sys.override.spindle_stop.initiate = On;
else if (sys.override.spindle_stop.enabled)
sys.override.spindle_stop.restore = On;
}
}
这段代码主要处理主轴转速的实时重写(override)命令,以及主轴停止命令。具体来说,它执行以下操作:
- 获取重写命令:通过 get_spindle_override 函数获取当前的主轴转速重写命令。
- 根据命令调整重写值:根据获取的命令,调整主轴转速重写值(last_s_override)。命令包括重置主轴转速到默认值、粗调和微调主轴转速增加或减少。
- 处理主轴停止命令:如果接收到主轴停止命令(CMD_OVERRIDE_SPINDLE_STOP),则切换 spindle_stop 标志的状态。
- 限制重写值范围:确保新的重写值在允许的范围内(MIN_SPINDLE_RPM_OVERRIDE 到 MAX_SPINDLE_RPM_OVERRIDE)。
- 更新主轴重写值:使用 spindle_set_override 函数更新主轴系统中的转速重写值。
- 处理主轴停止逻辑:如果在暂停状态下接收到主轴停止命令,并且主轴当前处于开启状态,则根据系统的当前状态更新主轴停止重写的标志(sys.override.spindle_stop.initiate 和 sys.override.spindle_stop.restore)。
if(!sys.override_delay.coolant && (rt_exec = get_coolant_override())) {
coolant_state_t coolant_state = gc_state.modal.coolant;
do {
switch(rt_exec) {
case CMD_OVERRIDE_COOLANT_MIST_TOGGLE:
if (hal.driver_cap.mist_control && ((state_get() == STATE_IDLE) || (state_get() & (STATE_CYCLE | STATE_HOLD)))) {
coolant_state.mist = !coolant_state.mist;
}
break;
case CMD_OVERRIDE_COOLANT_FLOOD_TOGGLE:
if ((state_get() == STATE_IDLE) || (state_get() & (STATE_CYCLE | STATE_HOLD))) {
coolant_state.flood = !coolant_state.flood;
}
break;
default:
if(grbl.on_unknown_accessory_override)
grbl.on_unknown_accessory_override(rt_exec);
break;
}
} while((rt_exec = get_coolant_override()));
if(coolant_state.value != gc_state.modal.coolant.value) {
coolant_set_state(coolant_state); // Report flag set in coolant_set_state().
gc_state.modal.coolant = coolant_state;
if(grbl.on_override_changed)
grbl.on_override_changed(OverrideChanged_CoolantState);
}
}
这段代码主要处理冷却液控制的实时重写命令,具体来说:
- 获取重写命令:通过 get_coolant_override 函数获取当前的冷却液重写命令。
- 处理重写命令:根据获取的命令,切换冷却液的状态。如果接收到雾化冷却液切换命令(CMD_OVERRIDE_COOLANT_MIST_TOGGLE),且系统支持雾化控制并且处于空闲、循环或暂停状态,那么切换雾化冷却液的状态。如果接收到泛洪冷却液切换命令(CMD_OVERRIDE_COOLANT_FLOOD_TOGGLE),且系统处于空闲、循环或暂停状态,那么切换泛洪冷却液的状态。
- 更新冷却液状态:如果冷却液状态发生变化,则使用 coolant_set_state 函数更新冷却液系统中的状态,并在全局状态 gc_state.modal.coolant 中记录新的冷却液状态。如果有重写状态变化的回调函数(grbl.on_override_changed),则调用该函数。
5. 运动控制块和电机驱动之间的链接
if (state_get() & (STATE_CYCLE | STATE_HOLD | STATE_SAFETY_DOOR | STATE_HOMING | STATE_SLEEP| STATE_JOG))
st_prep_buffer();
这里是重点,我们进入到st_prep_buffer中去。
while (segment_buffer_tail != segment_next_head) {}
先看看这个数据结构是什么样子的,直接在stepper.c文件下搜索segment_next_head,可找到segment_buffer_tail = segment_buffer_head = &segment_buffer[0]; 先来看看它所在的函数 st_reset,st_reset函数也是在grbl_enter中的初始化阶段就被调用了,回到st_reset中可以看到
st_go_idle();//这个st_是stepper,表示步进电机
进入到这个函数中去
ISR_CODE void ISR_FUNC(st_go_idle)(void)
{
sys_state_t state = state_get();//这里是获取系统的运行状态
hal.stepper.go_idle(false);//在这个里面需要干的工作一个是关闭定时器,另一个是让电机驱动引脚回到一个默认的状态,例如高电平。
if (((settings.steppers.idle_lock_time != 255) || sys.rt_exec_alarm || state == STATE_SLEEP) && state != STATE_HOMING) {
if(state == STATE_SLEEP)
hal.stepper.enable((axes_signals_t){0});//硬件抽象层,实际上是标记stepper_enabled.mask对应的位就能实现控制某个轴的使能/失能
else {
sys.steppers_deenergize = true;
hal.delay_ms(settings.steppers.idle_lock_time, st_deenergize);//延时settings.steppers.idle_lock_time毫秒后,调用st_deenergize按照里面的逻辑来使轴失能
}
} else
hal.stepper.enable(settings.steppers.idle_lock_time == 255 ? (axes_signals_t){AXES_BITMASK} : settings.steppers.deenergize);//settings.steppers.idle_lock_time这个值是settng中管理的。
}
回到st_prep_buffer函数中
uint_fast8_t idx, idx_max = (sizeof(st_block_buffer) / sizeof(st_block_t)) - 1;
for(idx = 0 ; idx <= idx_max ; idx++) {
st_block_buffer[idx].next = &st_block_buffer[idx == idx_max ? 0 : idx + 1];
st_block_buffer[idx].id = idx + 1;
}
这是将存储步进块的element组成一个循环链表。
idx_max = (sizeof(segment_buffer) / sizeof(segment_t)) - 1;
for(idx = 0 ; idx <= idx_max ; idx++) {
segment_buffer[idx].next = &segment_buffer[idx == idx_max ? 0 : idx + 1];
segment_buffer[idx].id = idx + 1;
segment_buffer[idx].amass_level = 0;
}
这里是将用来存储运动控制块的element组成一个循环链表,这里的数据来自运动规划器中的plan_block_t块(block_buffer)
st_prep_block = &st_block_buffer[0];
pl_block = NULL;
segment_buffer_tail = segment_buffer_head = &segment_buffer[0];
segment_next_head = segment_buffer_head->next;
memset(&prep, 0, sizeof(st_prep_t));
memset(&st, 0, sizeof(stepper_t));
这些就是一些指针的初始化,回到st_prep_buffer中去,while循环是默认进去的。
if (pl_block == NULL) {
这个判断默认是进去的
pl_block = sys.step_control.execute_sys_motion ? plan_get_system_motion_block() : plan_get_current_block();
如果sys.step_control.execute_sys_motion=1,接下来执行的是系统的运动控制块,这个块生成后存储在block_buffer_head指针指向的地址中。从目前的源码来看,GRBL HAL只支持一个系统生成的运动控制块。
速度曲线重新计算和停车逻辑
if (prep.recalculate.velocity_profile) {
if (settings.parking.flags.enabled) {
if (prep.recalculate.parking)
prep.recalculate.velocity_profile = Off;
else
prep.recalculate.flags = 0;
} else
prep.recalculate.flags = 0;
}
若不需要重新计算速度曲线,则更新下一个准备块
st_prep_block = st_prep_block->next;
uint_fast8_t idx = N_AXIS;
do {
idx--;
st_prep_block->steps[idx] = pl_block->steps[idx] << MAX_AMASS_LEVEL;
} while (idx);
st_prep_block->step_event_count = pl_block->step_event_count << MAX_AMASS_LEVEL;
st_prep_block->direction_bits = pl_block->direction_bits;
st_prep_block->programmed_rate = pl_block->programmed_rate;
st_prep_block->millimeters = pl_block->millimeters;
st_prep_block->steps_per_mm = (float)pl_block->step_event_count / pl_block->millimeters;
st_prep_block->output_commands = pl_block->output_commands;
st_prep_block->overrides = pl_block->overrides;
st_prep_block->backlash_motion = pl_block->condition.backlash_motion;
st_prep_block->message = pl_block->message;
pl_block->message = NULL;
prep.steps_per_mm = st_prep_block->steps_per_mm;
prep.steps_remaining = pl_block->step_event_count;
prep.req_mm_increment = REQ_MM_INCREMENT_SCALAR / prep.steps_per_mm;
prep.dt_remainder = prep.target_position = 0.0f; // Reset for new segment block
根据当前控制状态设置当前速度
if (sys.step_control.execute_hold || prep.recalculate.decel_override) {
prep.current_speed = prep.exit_speed;
pl_block->entry_speed_sqr = prep.exit_speed * prep.exit_speed;
prep.recalculate.decel_override = Off;
} else
prep.current_speed = sqrtf(pl_block->entry_speed_sqr);
设置反馈率
if ((st_prep_block->dynamic_rpm = pl_block->condition.is_rpm_rate_adjusted)) {
prep.inv_feedrate = pl_block->condition.is_laser_ppi_mode ? 1.0f : 1.0f / pl_block->programmed_rate;
} else
st_prep_block->dynamic_rpm = !!pl_block->spindle.css;
可以看出,如果有步进电机丢步补偿的需求,可以考虑加在
else {
st_prep_block = st_prep_block->next;
uint_fast8_t idx = N_AXIS;
do {
idx--;
// 检测丢步并进行补偿
if (检测到丢步条件) {
st_prep_block->steps[idx] = 补偿后的步数;
} else {
st_prep_block->steps[idx] = pl_block->steps[idx] << MAX_AMASS_LEVEL;
}
} while (idx);
// 其余代码保持不变...
}
梯形加减速算法
prep.mm_complete = 0.0f; // 默认情况下,速度规划在距离运动控制块结束0.0mm处完成。
float inv_2_accel = 0.5f / pl_block->acceleration; // 计算加速度的倒数的一半,用于后续计算。
if (sys.step_control.execute_hold) { // [强制减速至零速度]
// 如果处于Feed Hold状态,则计算减速到零速度的参数。
prep.ramp_type = Ramp_Decel; // 设置减速阶段。
// 计算相对于运动控制块结束点的减速距离。
float decel_dist = pl_block->millimeters - inv_2_accel * pl_block->entry_speed_sqr;
if (decel_dist < 0.0f) {
// 如果整个运动控制块都在减速中,则计算结束时的速度。
prep.exit_speed = sqrtf(pl_block->entry_speed_sqr - 2.0f * pl_block->acceleration * pl_block->millimeters);
} else {
prep.mm_complete = decel_dist; // 设置Feed Hold结束点。
prep.exit_speed = 0.0f; // 设置退出速度为0。
}
} else { // [正常操作]
// 计算或重新计算运动控制块的速度规划参数。
prep.ramp_type = Ramp_Accel; // 初始化为加速阶段。
prep.accelerate_until = pl_block->millimeters; // 默认加速到运动控制块的结束。
float exit_speed_sqr;
if (sys.step_control.execute_sys_motion)
prep.exit_speed = exit_speed_sqr = 0.0f; // 强制在系统运动结束时停止。
else {
exit_speed_sqr = plan_get_exec_block_exit_speed_sqr(); // 获取计划器块的退出速度平方。
prep.exit_speed = sqrtf(exit_speed_sqr); // 计算退出速度。
}
float nominal_speed = plan_compute_profile_nominal_speed(pl_block); // 计算名义速度。
float nominal_speed_sqr = nominal_speed * nominal_speed; // 计算名义速度平方。
float intersect_distance = 0.5f * (pl_block->millimeters + inv_2_accel * (pl_block->entry_speed_sqr - exit_speed_sqr)); // 计算加速和减速相交的距离。
prep.target_feed = nominal_speed; // 设置目标进给速度为名义速度。
if (pl_block->entry_speed_sqr > nominal_speed_sqr) { // 如果入口速度大于名义速度,则需要减速。
prep.accelerate_until = pl_block->millimeters - inv_2_accel * (pl_block->entry_speed_sqr - nominal_speed_sqr); // 计算加速结束点。
if (prep.accelerate_until <= 0.0f) { // 如果只需要减速。
prep.ramp_type = Ramp_Decel; // 设置为减速阶段。
// 计算结束时的速度。
prep.exit_speed = sqrtf(pl_block->entry_speed_sqr - 2.0f * pl_block->acceleration * pl_block->millimeters);
prep.recalculate.decel_override = On; // 标记为减速覆盖,以便加载下一个块时进行处理。
} else {
// 如果是减速到巡航或巡航-减速类型。
prep.decelerate_after = inv_2_accel * (nominal_speed_sqr - exit_speed_sqr); // 计算减速开始点。
prep.maximum_speed = nominal_speed; // 设置最大速度为名义速度。
prep.ramp_type = Ramp_DecelOverride; // 设置为减速覆盖阶段。
}
} else if (intersect_distance > 0.0f) {
if (intersect_distance < pl_block->millimeters) { // 如果是梯形或三角形类型。
prep.decelerate_after = inv_2_accel * (nominal_speed_sqr - exit_speed_sqr); // 计算减速开始点
if (prep.decelerate_after < intersect_distance) { // 如果是梯形类型
prep.maximum_speed = nominal_speed; // 设置最大速度为名义速度
if (pl_block->entry_speed_sqr == nominal_speed_sqr) {
// 如果入口速度等于名义速度,则为巡航-减速或纯巡航类型
prep.ramp_type = Ramp_Cruise; // 设置为巡航阶段
} else {
// 如果是全梯形或加速-巡航类型
prep.accelerate_until -= inv_2_accel * (nominal_speed_sqr - pl_block->entry_speed_sqr); // 计算加速结束点
}
} else { // 如果是三角形类型
prep.accelerate_until = prep.decelerate_after = intersect_distance; // 设置加速结束和减速开始点为相交点
prep.maximum_speed = sqrtf(2.0f * pl_block->acceleration * intersect_distance + exit_speed_sqr); // 计算最大速度
}
} else { // 如果是纯减速类型
prep.ramp_type = Ramp_Decel; // 设置为减速阶段
}
} else { // 如果是纯加速类型
prep.accelerate_until = 0.0f; // 设置加速结束点为0
prep.maximum_speed = prep.exit_speed; // 设置最大速度为退出速度
}
}
if(state_get() != STATE_HOMING)
sys.step_control.update_spindle_rpm |= pl_block->spindle.hal->cap.laser; // 如果不是寻找原点状态且为激光模式,则强制更新主轴转速
probe_asserted = false; // 重置探针状态
接下来更新主轴转速和PWM信号
if (sys.step_control.update_spindle_rpm || st_prep_block->dynamic_rpm) { // 检查是否需要更新转速
float rpm;
st_prep_block->spindle = pl_block->spindle.hal; // 获取当前主轴的硬件抽象层(HAL)接口
if (pl_block->spindle.state.on) { // 如果主轴处于开启状态
if(pl_block->spindle.css) { // 如果使用恒速切削(CSS)模式
float npos = (float)(pl_block->step_event_count - prep.steps_remaining) / (float)pl_block->step_event_count; // 计算切割位置
rpm = spindle_set_rpm(pl_block->spindle.hal, // 计算并设置转速
pl_block->spindle.rpm + pl_block->spindle.css->delta_rpm * npos,
pl_block->spindle.hal->param->override_pct);
} else { // 如果不使用CSS模式
rpm = spindle_set_rpm(pl_block->spindle.hal, // 计算并设置转速
pl_block->condition.is_rpm_rate_adjusted && !pl_block->condition.is_laser_ppi_mode
? pl_block->spindle.rpm * prep.current_speed * prep.inv_feedrate
: pl_block->spindle.rpm, pl_block->spindle.hal->param->override_pct);
}
} else { // 如果主轴处于关闭状态
pl_block->spindle.hal->param->rpm = rpm = 0.0f; // 将转速设置为0
}
if(rpm != prep.current_spindle_rpm) { // 如果计算出的新转速与当前转速不同
if(pl_block->spindle.hal->get_pwm != NULL) { // 如果支持获取PWM信号
prep.current_spindle_rpm = rpm; // 更新当前转速
prep_segment->update_pwm = pl_block->spindle.hal->update_pwm; // 更新PWM更新函数
prep_segment->spindle_pwm = pl_block->spindle.hal->get_pwm(rpm); // 获取并设置新的PWM值
} else { // 如果不支持获取PWM信号
prep_segment->update_rpm = pl_block->spindle.hal->update_rpm; // 更新RPM更新函数
prep.current_spindle_rpm = prep_segment->spindle_rpm = rpm; // 更新转速值
}
sys.step_control.update_spindle_rpm = Off; // 重置更新标志
}
}
下面是计算定时器的初值,和一些其他运动参数
float step_dist_remaining = prep.steps_per_mm * mm_remaining; // 将剩余距离mm_remaining转换为步数
uint32_t n_steps_remaining = (uint32_t)ceilf(step_dist_remaining); // 对剩余步数进行向上取整
prep_segment->n_step = (uint_fast16_t)(prep.steps_remaining - n_steps_remaining); // 计算本段要执行的步数
// 如果在Feed Hold的结束处且没有步骤要执行,则退出
if (prep_segment->n_step == 0 && sys.step_control.execute_hold) {
sys.step_control.end_motion = On;
if (settings.parking.flags.enabled && !prep.recalculate.parking)
prep.recalculate.hold_partial_block = On;
return;
}
dt += prep.dt_remainder; // 将上一段的剩余执行时间应用到当前段
float inv_rate = dt / ((float)prep.steps_remaining - step_dist_remaining); // 计算调整后的步进率的倒数
uint32_t cycles = (uint32_t)ceilf(cycles_per_min * inv_rate); // 计算每步需要的周期数(cycles/step)
// 如果主轴同步,则更新目标位置和巡航标志
if((prep_segment->spindle_sync = pl_block->spindle.state.synchronized)) {
prep.target_position += dt * prep.target_feed;
prep_segment->cruising = prep.ramp_type == Ramp_Cruise;
prep_segment->target_position = prep.target_position;
}
#ifdef ADAPTIVE_MULTI_AXIS_STEP_SMOOTHING
// 计算步进定时和多轴平滑级别
if (cycles < amass.level_1)
prep_segment->amass_level = 0;
else {
prep_segment->amass_level = cycles < amass.level_2 ? 1 : (cycles < amass.level_3 ? 2 : 3);
cycles >>= prep_segment->amass_level;
prep_segment->n_step <<= prep_segment->amass_level;
}
#endif
prep_segment->cycles_per_tick = cycles; // 设置每个定时器周期的周期数
prep_segment->current_rate = prep.current_speed; // 设置当前速率
segment_buffer_head = segment_next_head; // 更新段缓冲区头指针
segment_next_head = segment_next_head->next; // 移动到下一个段
pl_block->millimeters = mm_remaining; // 更新剩余毫米数
prep.steps_remaining = n_steps_remaining; // 更新剩余步数
prep.dt_remainder = ((float)n_steps_remaining - step_dist_remaining) * inv_rate; // 更新剩余执行时间
// 检查是否完成了运动控制块
if (mm_remaining <= prep.mm_complete) {
if (mm_remaining > 0.0f) { // 如果是强制终止的结束
sys.step_control.end_motion = On;
if (settings.parking.flags.enabled && !prep.recalculate.parking)
prep.recalculate.hold_partial_block = On;
return; // 退出
} else {
if (sys.step_control.execute_sys_motion) {
sys.step_control.end_motion = On;
return;
}
pl_block = NULL; // 设置指针为空,表示需要检查并加载下一个计划块
plan_discard_current_block(); // 丢弃当前计划块
}
}
6 电机驱动和脉冲的产生
接下来去看一下定时器的中断服务函数,在里面做了些什么工作。
ISR_CODE void ISR_FUNC(stepper_driver_interrupt_handler)(void) {
#if ENABLE_BACKLASH_COMPENSATION
static bool backlash_motion; // 用于背隙补偿的标志
#endif
// 当有运动块要执行时,开始一个步进脉冲
if(st.exec_block) {
hal.stepper.pulse_start(&st); // 调用硬件抽象层的函数开始步进脉冲
st.new_block = st.dir_change = false; // 重置新块和方向改变标志
if (st.step_count == 0) // 如果当前运动段完成,清空当前运动段
st.exec_segment = NULL;
}
// 如果没有要执行的运动段,尝试从步进缓冲区中弹出一个
if (st.exec_segment == NULL) {
// 缓冲区中有内容吗?如果有,加载并初始化下一个运动段。
if (segment_buffer_tail != segment_buffer_head) {
// 初始化新的运动段并加载要执行的步数
st.exec_segment = (segment_t *)segment_buffer_tail;
//这里是关键的,提前为下一次的运动段设置好定时器的初值
hal.stepper.cycles_per_tick(st.exec_segment->cycles_per_tick); // 设置定时器初值
st.step_count = st.exec_segment->n_step; // 加载要执行的步数
// 如果新段开始了一个新的规划块,初始化步进变量和计数器
if (st.exec_block != st.exec_segment->exec_block) {
// 检查方向是否改变
if((st.dir_change = st.exec_block == NULL || st.dir_outbits.value != st.exec_segment->exec_block->direction_bits.value))
st.dir_outbits = st.exec_segment->exec_block->direction_bits; // 更新方向位
st.exec_block = st.exec_segment->exec_block; // 更新当前执行的规划块
st.step_event_count = st.exec_block->step_event_count; // 更新步进事件计数
st.new_block = true; // 标记为新的规划块
#if ENABLE_BACKLASH_COMPENSATION
backlash_motion = st.exec_block->backlash_motion; // 更新背隙补偿标志
#endif
// 同步执行的覆写控制
if(st.exec_block->overrides.sync)
sys.override.control = st.exec_block->overrides;
// 执行与运动同步的输出命令
while(st.exec_block->output_commands) {
output_command_t *cmd = st.exec_block->output_commands;
cmd->is_executed = true;
if(cmd->is_digital)
hal.port.digital_out(cmd->port, cmd->value != 0.0f);
else
hal.port.analog_out(cmd->port, cmd->value);
st.exec_block->output_commands = cmd->next;
}
// 将要打印的消息加入队列
if(st.exec_block->message) {
if(message == NULL) {
message = st.exec_block->message;
protocol_enqueue_rt_command(output_message);
} else
free(st.exec_block->message);
st.exec_block->message = NULL;
}
// 初始化布雷森汉姆线算法的计数器
st.counter_x = st.counter_y = st.counter_z
#ifdef A_AXIS
= st.counter_a
#endif
#ifdef B_AXIS
= st.counter_b
#endif
#ifdef C_AXIS
= st.counter_c
#endif
#ifdef U_AXIS
= st.counter_u
#endif
#ifdef V_AXIS
= st.counter_v
#endif
= st.step_event_count >> 1;
#ifndef ADAPTIVE_MULTI_AXIS_STEP_SMOOTHING
memcpy(st.steps, st.exec_block->steps, sizeof(st.steps)); // 复制步数信息
#endif
}
#ifdef ADAPTIVE_MULTI_AXIS_STEP_SMOOTHING
// 根据AMASS级别调整布雷森汉姆算法的增量计数器
st.amass_level = st.exec_segment->amass_level;
st.steps[X_AXIS] = st.exec_block->steps[X_AXIS] >> st.amass_level;
st.steps[Y_AXIS] = st.exec_block
// 根据AMASS级别调整布雷森汉姆算法的增量计数器
st.steps[Y_AXIS] = st.exec_block->steps[Y_AXIS] >> st.amass_level;
st.steps[Z_AXIS] = st.exec_block->steps[Z_AXIS] >> st.amass_level;
#ifdef A_AXIS
st.steps[A_AXIS] = st.exec_block->steps[A_AXIS] >> st.amass_level;
#endif
#ifdef B_AXIS
st.steps[B_AXIS] = st.exec_block->steps[B_AXIS] >> st.amass_level;
#endif
#ifdef C_AXIS
st.steps[C_AXIS] = st.exec_block->steps[C_AXIS] >> st.amass_level;
#endif
#ifdef U_AXIS
st.steps[U_AXIS] = st.exec_block->steps[U_AXIS] >> st.amass_level;
#endif
#ifdef V_AXIS
st.steps[V_AXIS] = st.exec_block->steps[V_AXIS] >> st.amass_level;
#endif
#endif
// 更新主轴PWM或RPM(如果有必要)
if(st.exec_segment->update_pwm)
st.exec_segment->update_pwm(st.exec_segment->spindle_pwm);
else if(st.exec_segment->update_rpm)
st.exec_segment->update_rpm(st.exec_segment->spindle_rpm);
} else {
// 缓冲区为空,进入空闲状态
st_go_idle();
// 在速率控制运动完成时确保PWM正确设置
if (st.exec_block && st.exec_block->dynamic_rpm && st.exec_block->spindle->cap.laser)
st.exec_block->spindle->update_pwm(st.exec_block->spindle->pwm_off_value);
st.exec_block = NULL;
system_set_exec_state_flag(EXEC_CYCLE_COMPLETE); // 标记循环完成
return; // 退出中断服务例程
}
}
// 检查探针状态,监测探针引脚状态并在触发时记录系统位置
if (sys.probing_state == Probing_Active && hal.probe.get_state().triggered) {
sys.probing_state = Probing_Off;
memcpy(sys.probe_position, sys.position, sizeof(sys.position));
bit_true(sys.rt_exec_state, EXEC_MOTION_CANCEL);
#ifdef MINIMIZE_PROBE_OVERSHOOT
if((probe_asserted = segment_buffer_head->next == segment_buffer_tail)) {
segment_buffer_head = segment_buffer_tail->next;
if(st.step_count < 3 || st.step_count < (st.exec_segment->n_step >> 3))
segment_buffer_head = segment_buffer_head->next;
segment_next_head = segment_next_head->next;
}
#endif
}
// 执行步进脉冲
register axes_signals_t step_outbits = (axes_signals_t){0};
// 使用布雷森汉姆线算法执行步进位移
// 对于每个轴,检查是否需要生成步进脉冲,并更新系统位置
// 示例:
st.counter_x += st.steps[X_AXIS];
if (st.counter_x > st.step_event_count) {
step_outbits.x = On;
st.counter_x -= st.step_event_count;
#if ENABLE_BACKLASH_COMPENSATION
if(!backlash_motion)
#endif
sys.position[X_AXIS] = sys.position[X_AXIS] + (st.dir_outbits.x ? -1 : 1);
}
// ... 对其他轴重复上述逻辑
// 在归零循环中,锁定并阻止所需轴的移动
if (state_get() == STATE_HOMING)
st.step_outbits.value &= sys.homing_axis_lock.mask;
// 如果当前运动段完成,前进至下一个运动段
if (st.step_count == 0 || --st.step_count == 0) {
segment_buffer_tail = segment_buffer_tail->next; // 移动至下一个段
}
}
这个函数中,主要工作是确定何时生成高脉冲信号以及如何控制步进电机的运动,GRBL0.8跟grblHAL有了一些改进,只用到了一个定时器,这一点跟开始那张图中的描述有些差异。
7 bresenham算法
首先来复习一下直线方程:
斜截式:y=kx+b
点斜式:(y-y0)=k(x-x0)
参考:
https://blog.csdn.net/qq_43306298/article/details/109351600
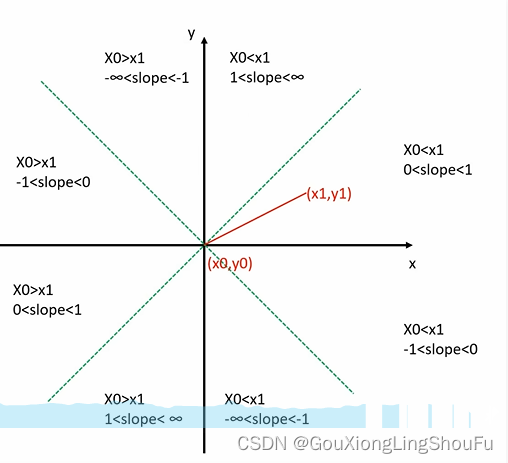
bresenham算法只使用int类型的加减和比较绘制直线,水平和竖直的直线单独处理,剩余的部分等分为8个部分,从最简单的(X,Y)(1>k>0)开始。
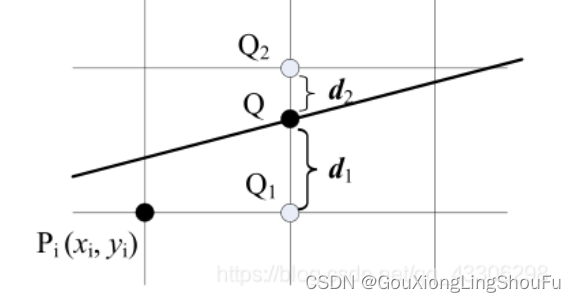 Q点的y是kx+b,Q2点的y是yi+1,Q1点的y是yi,变化的x可以写成xi+n,代入公式y=kx+b中,得到了d2=yi+1-k(xi+n)+b,d1=k(xi+n)+b-yi。
Q点的y是kx+b,Q2点的y是yi+1,Q1点的y是yi,变化的x可以写成xi+n,代入公式y=kx+b中,得到了d2=yi+1-k(xi+n)+b,d1=k(xi+n)+b-yi。
要想知道是正右方还是右上方,只需要知道d1和d2哪个大即可。因此我们的目标转换为判断d1-d2是否大于0.
于是:
误差ei = d1 - d2
= [k(xi + 1) + b - yi] - [yi + 1 - (k(xi + 1) + b)]
= 2kxi - 2yi + 2b + 2k -1
e(i+1) = 2kx(i+1) - 2y(i+1) + 2b + 2k -1
= 2k (xi + 1) - 2y(i+1) + 2b + 2k -1 //因为k为(0,1)因此x(i+1) = xi + 1
= 2kxi - 2yi + 2b + 2k - 1 - 2y(i+1) + 2yi + 2k //这里为了凑ei在式子中多增加了-2yi+2yi
= ei - 2(y(i+1) - yi) + 2k
在阅读的过程中我对一些标志位的作用感到疑惑,我将其整理到了下面并加以说明:
typedef union {
uint8_t value;
struct {
uint8_t hard_enabled :1,//表示硬件限位是否使能
soft_enabled :1,//表示软件限位是否使能;
check_at_init :1,//表示是否在初始化时检查极限开关状态;
jog_soft_limited :1,//表示在Jog模式下是否使用软件限位;
two_switches :1,//表示是否配置两个极限开关;
unassigned :3;//保留未分配
};
} limit_settings_flags_t; // 限位开关的标志
//函数原型:ISR_CODE axes_signals_t ISR_FUNC(limit_signals_merge)(limit_signals_t signals)
limit_signals_merge( hal.limits.get_state() ).value//这个点运算实际上是在访问函数的返回值
typedef union {
uint16_t value;
struct {
uint16_t report_inches :1,//该位控制是否以英寸为单位报告位置。
restore_overrides :1,//该位控制是否在复位时恢复所有覆盖。
unused0 :1,//保留
sleep_enable :1,//该位控制是否启用睡眠模式。
disable_laser_during_hold :1,//该位控制是否在暂停时关闭激光器。
force_initialization_alarm :1,//该位控制是否发出初始化警报。
legacy_rt_commands :1,//该位控制是否启用旧版运行时命令的处理。
restore_after_feed_hold :1,//该位控制是否在“进给保持”后恢复之前的状态。
unused1 :1,//保留
g92_is_volatile :1,//该位控制 G92 命令是否具有易失性(即只对当前运动有效)。
report_echo_line_received :1,//该位控制是否将来自机器人的响应行输出到主机
line_number_enable :1,//该位控制是否启用行号。
buzz_enable :1,//该位控制蜂鸣器。
webui_auth_enable :1,//该位控制 Web UI 是否需要身份验证。
unassigned :2;//保留
};
} settingflags_t;
typedef union {
uint16_t value;
uint16_t mask;
struct {
uint16_t reset :1; // 复位信号标志位
uint16_t feed_hold :1; // 进给保持信号标志位
uint16_t cycle_start :1; // 循环启动信号标志位
uint16_t safety_door_ajar :1; // 安全门未关闭信号标志位
uint16_t block_delete :1; // 块删除信号标志位
uint16_t stop_disable :1; // 停止禁用信号标志位(M1)
uint16_t e_stop :1; // 急停信号标志位
uint16_t probe_disconnected :1; // 探针未连接信号标志位
uint16_t motor_fault :1; // 电机故障信号标志位
uint16_t motor_warning :1; // 电机警告信号标志位
uint16_t limits_override :1; // 限位覆盖信号标志位
uint16_t single_block :1; // 单个块模式信号标志位
uint16_t unassigned :2; // 未分配的位
uint16_t probe_triggered :1; // 探针触发保护信号标志位
uint16_t deasserted :1; // 如果信号取消激活,则设置此标志。注意:如果设置了此标志,请勿将其传递给 control_interrupt_handler。
};
} control_signals_t;
typedef union {
uint8_t value;
struct {
uint8_t ignore_when_idle :1; // 空闲时忽略信号标志位
uint8_t keep_coolant_on :1; // 保持冷却液开启信号标志位
uint8_t unassigned :6; // 未分配的位
};
} safety_door_setting_flags_t;
/* 这些都是实时指令 */
#define EXEC_STATUS_REPORT bit(0) // 执行状态报告
#define EXEC_CYCLE_START bit(1) // 执行循环启动
#define EXEC_CYCLE_COMPLETE bit(2) // 完成循环执行
#define EXEC_FEED_HOLD bit(3) // 执行进给保持
#define EXEC_STOP bit(4) // 停止执行
#define EXEC_RESET bit(5) // 执行复位
#define EXEC_SAFETY_DOOR bit(6) // 安全门状态改变
#define EXEC_MOTION_CANCEL bit(7) // 取消运动
#define EXEC_SLEEP bit(8) // 进入休眠状态
#define EXEC_TOOL_CHANGE bit(9) // 刀具更换
#define EXEC_PID_REPORT bit(10) // PID报告
#define EXEC_GCODE_REPORT bit(11) // G代码报告
#define EXEC_TLO_REPORT bit(12) // TLO报告
#define EXEC_RT_COMMAND bit(13) // 运行实时指令
#define EXEC_DOOR_CLOSED bit(14) // 关闭安全门
#define ASCII_SOH 0x01 //报头开始标志
#define ASCII_STX 0x02 //正文开始标志
#define ASCII_ETX 0x03 //正文结束标志
#define ASCII_EOT 0x04 //传输结束标志
#define ASCII_ENQ 0x05 //请求/询问
#define ASCII_ACK 0x06 //肯定确认
#define ASCII_BS 0x08 //退格
#define ASCII_TAB 0x09 //水平制表符
#define ASCII_LF 0x0A //换行
#define ASCII_CR 0x0D //回车
#define ASCII_XON 0x11 //打开发送控制
#define ASCII_XOFF 0x13 //关闭发送控制
#define ASCII_NAK 0x15 //否定确认
#define ASCII_EOF 0x1A //文件结束标志
#define ASCII_CAN 0x18 //取消当前处理
#define ASCII_EM 0x19 //介质结束标志
#define ASCII_ESC 0x1B //转义字符
#define ASCII_DEL 0x7F //删除字符
#define ASCII_EOL "\r\n" //回车换行符
/* 短路求值的风格,先判断sys.rt_exec_alarm,如果为假rt_exec = system_clear_exec_alarm()不会执行 */
if (sys.rt_exec_alarm && (rt_exec = system_clear_exec_alarm())) {
}
enum GrblMessageCode {
Message_None = 0, //!< 0 - 保留值,请勿更改。
Message_CriticalEvent = 1, //!< 1 - 关键事件消息。
Message_AlarmLock = 2, //!< 2 - 报警锁定消息。
Message_AlarmUnlock = 3, //!< 3 - 报警解锁消息。
Message_Enabled = 4, //!< 4 - 使能消息。
Message_Disabled = 5, //!< 5 - 失能消息。
Message_SafetyDoorAjar = 6, //!< 6 - 安全门打开消息。
Message_CheckLimits = 7, //!< 7 - 检查限位消息。
Message_ProgramEnd = 8, //!< 8 - 程序结束消息。
Message_RestoreDefaults = 9, //!< 9 - 恢复默认设置消息。
Message_SpindleRestore = 10, //!< 10 - 主轴恢复消息。
Message_SleepMode = 11, //!< 11 - 休眠模式消息。
Message_EStop = 12, //!< 12 - 紧急停止消息。
Message_HomingCycleRequired = 13, //!< 13 - 需要回零循环消息。
Message_CycleStartToRerun = 14, //!< 14 - 循环启动重新执行消息。
Message_ReferenceTLOEstablished = 15, //!< 15 - 参考工具长度偏置建立消息。
Message_MotorFault = 16, //!< 16 - 电机故障消息。
Message_LockEngaged, //!< 锁定已启用消息。
Message_Gsensor, //!< 加速度传感器消息。
Message_DriverIncompatible, //!< 驱动器不兼容消息。
Message_PowerSupplied, //!< 电源供电消息。
Message_NoPowerSupply, //!< 无电源供应消息。
Message_EstopEngaged, //!< 紧急停止已激活消息。
Message_EstopCleared, //!< 紧急停止已解除消息。
Message_SerialStreamConnected, //!< 串口流连接消息。
Message_USBSerialStreamConnected, //!< USB串口流连接消息。
Message_TelnetStreamConnected, //!< Telnet流连接消息。
Message_WebsocketStreamConnected, //!< Websocket流连接消息。
Message_BluetoothStreamConnected, //!< 蓝牙流连接消息。
Message_SdcardStreamConnected, //!< SD卡流连接消息。
Message_FlashfsStreamConnected, //!< Flash文件系统流连接消息。
Message_YmodemStreamConnected, //!< Ymodem流连接消息。
Message_ItgStreamConnected, //!< ITG流连接消息。
Message_SerialStreamDisconnected, //!< 串口流断开连接消息。
Message_USBSerialStreamDisconnected, //!< USB串口流断开连接消息。
Message_TelnetStreamDisconnected, //!< Telnet流断开连接消息。
Message_WebsocketStreamDisconnected, //!< Websocket流断开连接消息。
Message_BluetoothStreamDisconnected, //!< 蓝牙流断开连接消息。
Message_SdcardStreamDisconnected, //!< SD卡流断开连接消息。
Message_FlashfsStreamDisconnected, //!< Flash文件系统流断开连接消息。
Message_YmodemStreamDisconnected, //!< Ymodem流断开连接消息。
Message_ItgStreamDisconnected, //!< ITG流断开连接消息。
Message_ProbeFailed, //!< 探针失败消息。
Message_NvsWarning, //!< Nvs警告消息。
Message_GcodeMessage, //!< G代码消息。
Message_InputBufferClear, //!< 输入缓冲区清除消息。
Message_SdcardEnd, //!< SD卡结束消息。
Message_SdcardInitFailed, //!< SD卡初始化失败消息。
Message_SdcardMountFailed, //!< SD卡挂载失败消息。
Message_ToolChgExecWarning, //!< 刀具更换执行警告消息。
Message_ToolChgG593CycleStart, //!< G593刀具更换循环启动消息。
Message_ToolChgCycleStart, //!< 刀具更换循环启动消息。
// OTA
Message_EngraveInterruption, //!< 雕刻中断消息。
Message_NoNetworkConnection, //!< 无网络连接消息。
Message_OtaSuccessful, //!< OTA成功消息。
Message_OtaFailed, //!< OTA失败消息。
Message_ReportProgress, //!< 进度报告消息。
Message_CurrVerLastest, //!< 当前版本最新消息。
// powerunit
Message_PowerSavingMode, //!< 电源节能模式消息。
Message_PowerDetection, //!< 电源检测消息。
// safekeeper
Message_EmergencySwitchEngaged, //!< 紧急开关已启用消息。
Message_LaserExposureTimeout, //!< 镭射曝光超时消息。
// Message_lockClose, // 锁闭消息。
// Webui
Message_WebuiRestartOngoing, //!< Web界面重启进行中消息。
Message_WebuiSpiffsReset, //!< Web界面Spiffs重置消息。
Message_WebuiUnknowCommand, //!< Web界面未知命令消息。
Message_WebuiUpFailed, //!< Web界面上传失败消息。
Message_WebuiUploadOk, //!< Web界面上传成功消息。
// GADGET
Message_SdcardTestBegin, //!< SD卡测试开始消息。
Message_SdcardTestEnd, //!< SD卡测试结束消息。
// WIFI MESSAGE
Message_WifiApReady, //!< WiFi AP已准备就绪消息。
Message_WifiApStop, //!< WiFi AP停止消息。
Message_WifiApConnected, //!< WiFi AP已连接消息。
Message_WifiApDisConnected, //!< WiFi AP已断开连接消息。
Message_WifiApScanCompleted, //!< WiFi AP扫描完成消息。
Message_WifiStaActive, //!< WiFi Sta活动消息。
Message_WifiStaKeepTryingConnetced, //!< WiFi Sta保持尝试连接消息。
Message_WifiStaDisConnected, //!< WiFi Sta已断开连接消息。
Message_WifiGetIP, //!< WiFi获取IP消息。
Message_WifiSettingReset, //!< WiFi设置重置消息。
Message_WifiStaSettingReset, //!< WiFi Sta设置重置消息。
Message_WifiApSettingReset, //!< WiFi AP设置重置消息。
Message_StepperNotCommunicate, //!< 步进电机通信失败消息。
Message_SdcardResetStream, //!< SD卡重置流消息。
Message_WebuiServicesEnabled, //!< Web界面服务已启用消息。
Message_UdiskInsert, //!< U盘插入消息。
Message_UdiskPullOut, //!< U盘拔出消息。
Message_ShockMovementDetected, //!< 检测到震动运动消息。
Message_UdiskStreamConnected, //!< U盘流连接消息。
Message_UdiskStreamDisconnected, //!< U盘流断开连接消息。
Message_ModbusInitFailed, //!< Modbus初始化失败消息。
// Bluetooth
#if defined(CONFIG_IDF_TARGET_ESP32) || defined(CONFIG_IDF_TARGET_ESP32S3)
Message_BluetoothOk, //!< 蓝牙正常消息。
#endif
#ifdef UART_OTA_ENABLE //UART OTA
Message_UartOtaReady, //!< UART OTA准备就绪消息。
Message_UartOtaExit, //!< UART OTA退出消息。
#endif
Message_NextMessage, //!< 下一个未分配的消息号。
_Message_Max_ = Message_NextMessage //!< 最大消息号。
};
typedef union {
uint8_t value; // 整个联合体的值
struct {
uint8_t feed_rate_disable :1; // 进给速率禁用标志位,占1位
uint8_t feed_hold_disable :1; // 进给保持禁用标志位,占1位
uint8_t spindle_rpm_disable :1; // 主轴转速禁用标志位,占1位
uint8_t parking_disable :1; // 停车禁用标志位,占1位
uint8_t reserved :3; // 预留位,占3位
uint8_t sync :1; // 同步标志位,占1位
};
} gc_override_flags_t;
typedef struct {
motion_mode_t motion; //!< 运动模式 {G0,G1,G2,G3,G38.2,G80}
feed_mode_t feed_mode; //!< 进给模式 {G93,G94,G95}
bool units_imperial; //!< 单位制 {G20,G21}
bool distance_incremental; //!< 距离增量模式 {G90,G91}
bool diameter_mode; //!< 直径模式 {G7,G8}(适用于车床)
//< uint8_t distance_arc; //!< 弧长距离模式 {G91.1}(注意:不支持跟踪,仅支持默认值)
plane_select_t plane_select; //!< 平面选择 {G17,G18,G19}
//< uint8_t cutter_comp; //!< 刀具补偿 {G40}(注意:不支持跟踪,仅支持默认值)
tool_offset_mode_t tool_offset_mode; //!< 刀具偏置模式 {G43,G43.1,G49}
coord_system_t coord_system; //!< 工件坐标系 {G54,G55,G56,G57,G58,G59,G59.1,G59.2,G59.3}
// control_mode_t control; //!< 控制模式 {G61}(注意:不支持跟踪,仅支持默认值)
program_flow_t program_flow; //!< 程序流程控制 {M0,M1,M2,M30,M60}
coolant_state_t coolant; //!< 冷却状态 {M7,M8,M9}
spindle_state_t spindle; //!< 主轴状态 {M3,M4,M5}
gc_override_flags_t override_ctrl; //!< 控制指令覆盖标志位 {M48,M49,M50,M51,M53,M56}
spindle_rpm_mode_t spindle_rpm_mode; //!< 主轴转速模式 {G96,G97}
cc_retract_mode_t retract_mode; //!< 循环插补撤退模式 {G98,G99}
bool scaling_active; //!< 比例缩放状态 {G50,G51}
bool canned_cycle_active; //!< 固定循环激活状态
float spline_pq[2]; //!< 样条曲线控制参数 {G5}
} gc_modal_t;
/*ISR_CODE void ISR_FUNC(enqueue_feed_override)(uint8_t cmd)这种写法主要是使用ISR_CODE ,将被标记的代码段放到RAM中去运行。
grbl\override.cpp:static override_queue_t feed = {0}, accessory = {0};
这两个缓存区前一个存储实时更新的激光强度,另一个存储实时调节的电机的运转速度。*/
enum GrblAlarmCode{
Alarm_None = 0, // 无警报
Alarm_HardLimit = 1, // 硬限位触发警报
Alarm_SoftLimit = 2, // 软限位触发警报
Alarm_AbortCycle = 3, // 中止循环警报
Alarm_ProbeFailInitial = 4, // 探测失败(初始阶段)警报
Alarm_ProbeFailContact = 5, // 探测失败(接触阶段)警报
Alarm_HomingFailReset = 6, // 回零失败(复位阶段)警报
Alarm_HomingFailDoor = 7, // 回零失败(门控阶段)警报
Alarm_FailPulloff = 8, // 提起失败警报
Alarm_HomingFailApproach = 9, // 回零失败(接近阶段)警报
Alarm_EStop = 10, // 急停警报
Alarm_HomingRequried = 11, // 需要回零警报
Alarm_LimitsEngaged = 12, // 极限已激活警报
Alarm_ProbeProtect = 13, // 探测保护警报
Alarm_Spindle = 14, // 主轴警报
Alarm_HomingFailAutoSquaringApproach = 15, // 回零失败(自动方阵接近阶段)警报
Alarm_SelftestFailed = 16, // 自检失败警报
Alarm_MotorFault = 17, // 电机故障警报
_Alarm_AlarmMax_ , // 警报极限值,不是真正的警报代码
};
typedef struct {
// 报告entry points,在重置时由core设置。
report_t report;
// GRBL核心事件 - 可以由驱动程序或核心进行订阅。
on_state_change_ptr on_state_change; // 状态改变时的回调函数指针
on_program_completed_ptr on_program_completed; // 程序完成时的回调函数指针
on_execute_realtime_ptr on_execute_realtime; // 实时执行时的回调函数指针
on_execute_realtime_ptr on_execute_delay; // 延迟执行时的回调函数指针
on_unknown_accessory_override_ptr on_unknown_accessory_override; // 未知附件覆盖时的回调函数指针
on_report_options_ptr on_report_options; // 报告选项时的回调函数指针
on_report_command_help_ptr on_report_command_help; // 报告命令帮助时的回调函数指针
on_global_settings_restore_ptr on_global_settings_restore; // 全局设置恢复时的回调函数指针
on_get_alarms_ptr on_get_alarms; // 获取报警时的回调函数指针
on_get_errors_ptr on_get_errors; // 获取错误时的回调函数指针
on_get_messages_ptr on_get_messages; // 获取消息时的回调函数指针
on_get_settings_ptr on_get_settings; // 获取设置时的回调函数指针
on_realtime_report_ptr on_realtime_report; // 实时报告时的回调函数指针
on_unknown_feedback_message_ptr on_unknown_feedback_message; // 未知反馈消息时的回调函数指针
on_unknown_realtime_cmd_ptr on_unknown_realtime_cmd; // 未知实时命令时的回调函数指针
on_unknown_sys_command_ptr on_unknown_sys_command; // 未知系统命令时的回调函数指针(如果未处理,返回Status_Unhandled)
on_get_commands_ptr on_get_commands; // 获取命令时的回调函数指针
on_user_command_ptr on_user_command; // 用户自定义命令时的回调函数指针
on_stream_changed_ptr on_stream_changed; // 流改变时的回调函数指针
on_homing_rate_set_ptr on_homing_rate_set; // 设置回零速度时的回调函数指针
on_homing_crrent_ptr on_homing_end; // 回零完成时的回调函数指针
on_probe_fixture_ptr on_probe_fixture; // 探测夹具时的回调函数指针
on_probe_start_ptr on_probe_start; // 探测开始时的回调函数指针
on_probe_completed_ptr on_probe_completed; // 探测完成时的回调函数指针
on_toolchange_ack_ptr on_toolchange_ack; // 换刀确认时的回调函数指针(从中断上下文调用)
on_laser_ppi_enable_ptr on_laser_ppi_enable; // 激光器PPI使能时的回调函数指针
on_spindle_select_ptr on_spindle_select; // 主轴选择时的回调函数指针
// 核心entry points - 在调用driver_init()之前由core设置。
enqueue_gcode_ptr enqueue_gcode; // 加入G代码队列的回调函数指针
enqueue_realtime_command_ptr enqueue_realtime_command; // 加入实时命令队列的回调函数指针
} grbl_t;
typedef union {
uint16_t value;
struct {
uint16_t mpg_mode :1, //!< MPG模式标志。在切换到辅助输入流时设置。(目前未使用)
probe_succeeded :1, //!< 跟踪上次探测周期是否成功。
soft_limit :1, //!< 跟踪状态机的软限位错误。
exit :1, //!< 系统退出标志。与中止命令一起使用,用于终止主循环。
block_delete_enabled :1, //!< 设置为true启用块删除。
feed_hold_pending :1, //!< 待处理的进给保持标志。
delay_overrides :1, /*延迟覆盖标志。当delay_overrides标志位被设置为1
时,表示延时覆盖已启用。这意味着在处理G代码时,
如果检测到了相应的实时命令来修改加速度或最大速度,
延时将根据新的设置进行调整。通过启用延时覆盖,
您可以在不更改全局设置的情况下,针对特定的操作部分
调整运动的延迟。*/
optional_stop_disable :1, //!< 通过实时命令将M1(可选停止)禁用的标志。
single_block :1, //!< 设置为true以禁用M1(可选停止),通过实时命令。
keep_input :1, //!< 设置为true,在执行停止时不清除输入缓冲区。
unused :6; //!< 未使用的位。
};
} system_flags_t;
#if 0
STATE_IDLE (空闲状态,值为0):表示机器控制器处于空闲状态,没有任何标志位被设置。
STATE_ALARM (报警状态,值为bit(0)):表示机器控制器处于报警状态,锁定所有G代码进程,但允许访问设置。在报警状态下,通常需要采取相应的措施来解除报警并恢复正常操作。
STATE_CHECK_MODE (G代码检查模式,值为bit(1)):表示机器控制器处于G代码检查模式,只锁定规划器和运动部分。在该模式下,机器控制器通常不会执行实际的运动,而是仅检查G代码的有效性和合规性。
STATE_HOMING (回零状态,值为bit(2)):表示机器控制器正在执行回零循环,即将各轴回到预定的零点位置。
STATE_CYCLE (运行状态,值为bit(3)):表示机器控制器正在执行加工循环或正在执行运动。
STATE_HOLD (停止状态,值为bit(4)):表示机器控制器处于主动停止状态,即暂停加工进程。
STATE_JOG (手动操作状态,值为bit(5)):表示机器控制器处于手动操作模式,用于手动控制机床进行移动。
STATE_SAFETY_DOOR (安全门状态,值为bit(6)):表示安全门未关闭或略开,此时机器控制器会暂停进给并切断系统电源,以确保操作员的安全。
STATE_SLEEP (休眠状态,值为bit(7)):表示机器控制器处于休眠状态,此时通常会暂停所有运动和加工操作,以节省能源。
STATE_ESTOP (紧急停止状态,值为bit(8)):表示机器控制器处于紧急停止模式,类似于报警状态,但与报警状态相比,紧急停止模式可能会有不同的处理方式。
STATE_TOOL_CHANGE (工具更换状态,值为bit(9)):表示机器控制器处于手动工具更换模式,类似于停止状态,但会停止主轴并允许手动操作。
#endif
MATLAB仿真
% 不考虑逆时间模式
% 特别说明: GRBL的mc_line直线处理函数,没有做任何操作,也就是说直线对GRBL来说都采用直接过渡,直接做速度约束。
function grbl_simulate()
%%%%%% 圆弧 %%%%%%
% target = [20,10,10];
% postion = [10,10,10];
% offset = [5, 0, 0 ];
% raduis = sqrt( offset(1)^2 + offset(2)^2 );
% turns = -1;
% mc_arc(target, postion, offset, raduis, turns);
%%%%%% 速度前瞻-拐点速度求解 %%%%%%
sys_position = [0,0,0; 6,8,0; 20,0,0; 25,30,0; 30,2,0];
steps_per_mm = [100 , 80, 60]; %1mm = 100个脉冲
acc = [12000,6000,3000]; %各个轴的加速度
vec = [10000,5000,3000]; %各个轴的速度
n_axis = length( steps_per_mm );
[millimeters, rapid_rate, acceleration,junction_speed] = plan_buffer_line( sys_position, n_axis, steps_per_mm, acc, vec);
%%%%%% 速度前瞻-前瞻与后顾 %%%%%%
planner_recalculate(length(sys_position) - 1, rapid_rate, junction_speed, millimeters, acceleration);
end
% 圆弧插补仿真
% G2 X... Y... Z... I... J... K... [F...]
% 圆弧指令需要先用直线指令移动到起点,然后才能开始画圆
% 顺时针(CW)或逆时针(CCW)
% target : 表示目标位置,XYZ三个轴。在GRBL中这个参数有Gcode指定
% postion : 当前的坐标位置,XYZ
% offset : 从当前位置到圆心的偏移量,IGK
% raduis : 半径,以i=n,j=m,k=0为例,raduis = sqrt( (x-i)^2 + (y-j)^2 )
% plane : 选择平面 x,y平面 z为线性轴,或者xz, yz平面,这里1xy;2xz;3yz;
% turns :大于0逆时针,小于0顺时针,绝对值-1表示圈数
% 总结 : 这个插补算法不要求终点一定在圆弧上,它的思路是计算
% 1 (起始点-圆心)(终点-圆心)两条连线之间的夹角θ。
% 2 通过弓高误差约束插入的弦,并计算弦长
% 3 总弧长 / 弦长 = 插补段数
% 4 θ / 插补段数 = 插补角度
% 5 使用圆的参数方程{x = r*cos(θ), y = r*sin(θ)} 计算得到插补线段末端的坐标点
% 参考文献 : https://blog.csdn.net/cln512/article/details/120748647
function mc_arc(target, postion, offset, raduis, turns)
ARC_ANGULAR_TRAVEL_EPSILON = 0.0000005; % 最小浮点误差约束
N_ARC_CORRECTION = 12; % 控制间隔多次才使用sin cos函数运算
arc_tolerance = 0.002;% 插补公差mm
% 理论上 2pi = 6.283185,但是由于浮点误差,可能会导致2pi = 6.283184或者2pi = 6.283186
% 这样导致一个完整的圆弧被错认为是一个极小的圆弧,导致出错。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%start%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 下面这部分的运算的主要目的是把圆心当成坐标原点,然后得到这个圆心坐标系下起始点和终点的坐标,方便求得(起始点-圆心)(终点-圆心)两条连线之间的夹角
x_rv = -offset(1);
y_rv = -offset(2);
% 圆心坐标:起始点 - 偏移量
x_center = postion(1) - x_rv;
y_center = postion(2) - y_rv;
% 目标点到圆心之间的距离
x_rt = target(1) - x_center;
y_rt = target(2) - y_center;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%end%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%start 求夹角%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% arctan(A) + arctan(B) = arctan(A+B/1-AB)
% arctan(A) - arctan(B) = arctan(A-B/1+AB)
% A = arctan(y/x)
% B-A = arctan( ( y1/x1 - y0/x0 ) / ( 1 + ( y1/x1 * y0/x0 ) ) )
% = arctan( (x0y1 - x1y0) / (x0x1 + y0y1) )
% 求(起始点-圆心)(终点-圆心)两条连线之间的夹角
ybuf = x_rv*y_rt - x_rt*y_rv;
xbuf = x_rv*x_rt + y_rt*y_rv;
angular_travel = atan2( ybuf, xbuf );
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%end%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%start%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
if( turns > 0 )
if(angular_travel <= ARC_ANGULAR_TRAVEL_EPSILON)% 逆时针旋转时弧度接近0认为是旋转了1周
angular_travel = angular_travel + (2 * pi);
end
elseif( angular_travel >= -ARC_ANGULAR_TRAVEL_EPSILON ) % 顺时针旋转时弧度接近0认为是旋转了1周
angular_travel = angular_travel - (2 * pi);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%end%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 参考 https://blog.csdn.net/cln512/article/details/120748647 的时候需要注意,angular_travel标识的是角度不是圆心到弓高之间的距离
% 描述:
% 画一个半径为r的圆
% 画弦k,使得k的弓高为插补误差arc_tolerance
% 过圆心做弦的垂线h(一定平分弦)
% h = r - arc_tolerance
% k^2 = r^2 - h^2
% = r^2 - (r - arc_tolerance)^2
% = r^2 - (r^2 - 2*r*arc_tolerance + arc_tolerance^2)
% = 2*r*arc_tolerance - arc_tolerance^2
% = arc_tolerance * ( 2 * r - arc_tolerance )
if( 2 * raduis > arc_tolerance ) % 圆弧直径必须大于插补公差
arc_length = angular_travel * raduis / 2; % 这里计算的是向量夹角对应的弧的半径,这里除2是后面运算的预处理
chord_length = arc_tolerance * (2 * raduis - arc_tolerance);% 计算插补线段的长度
segments = abs( floor( arc_length / chord_length ) );
else
segments = 0;
end
if( segments > 0 )
% 插补弦所在的弧对应角度
theta_per_segment = angular_travel / segments;
% 三角函数的泰勒展开
% sin(x) = x - x^3/3! + (高阶无穷小(x^3))
% cos(x) = 1 - x^2/2! + (高阶无穷小(x^2))
cos_T = 2 - theta_per_segment * theta_per_segment;
sin_T = theta_per_segment * 0.16666667 * ( cos_T + 4 );% 这里的近似计算是GRBL中直接提取出来的,应该是一个通过实验计算出来的式子
cos_T = cos_T / 2; % 前面扩大了2倍,现在除回来
count = 0;% 计数器,用于统计使用了泰勒展开式做近似计算的次数
% 和差化积推导
% e^ix = cosx + i*sinx
% e^(a+b) = (cos(a) + i*sin(a))*(cos(b) + i*sin(b))
% = cos(a)cos(b) - sin(a)sin(b) + i*sin(a)cos(b) + i*sin(b)cos(a)
% cos(a+b) = cos(a)cos(b) - sin(a)sin(b)
% sin(a+b) = sin(a)cos(b) + sin(b)cos(a)
% 在极坐标中,圆的参数方程为{x = r*cos(θ), y = r*sin(θ)}
% φ = θ, 第一个扇区的角度是φ, 插入一个θ
% x = r * cos(φ + θ) = r * [cos(φ)cos(θ) - sin(φ)sin(θ)]
% 带入圆参数方程 x = r*cos(φ), y = r*sin(φ)
% = x * cos(θ) - y * sin(θ)
% y = r * sin(φ + θ) = r * [sin(φ)cos(θ) + sin(θ)cos(φ)]
% 带入圆参数方程 x = r*cos(φ), y = r*sin(φ)
% = y*cos(θ) + x*sin(θ)
positions = zeros(segments + 1, 2);
pos_x = x_center + x_rv;
pos_y = y_center + y_rv;
for loop = 0 : 1 : segments
positions(loop+1, :) = [pos_x, pos_y]; % 为了画图准备的
if( count < N_ARC_CORRECTION )
r_axisi = y_rv * cos_T + x_rv * sin_T;
x_rv = x_rv*cos_T - y_rv*sin_T;
y_rv = r_axisi;
count = count + 1;
else
% 这个运算以起始点为参考,计算插补loop次以后的坐标,而且用标准sin cos
% 目的是为了矫正使用泰勒展开结果计算的累积误差
cos_Ti = cos(loop * theta_per_segment);
sin_Ti = sin(loop * theta_per_segment);
x_rv = ( -offset(1) ) * cos_Ti - ( -offset(2) ) * sin_Ti;
y_rv = ( -offset(2) ) * cos_Ti + ( -offset(1) ) * sin_Ti;
count = 0;
end
pos_x = x_center + x_rv;
pos_y = y_center + y_rv;
end
% figure;
plot(positions(:, 1), positions(:, 2), 'b-o');
hold on;
% 这个命令用于保持当前图像,使得接下来的绘图命令可以在同一个图上继续绘制,而不是创建一个新的图像。
scatter(x_center, y_center, 'r*');
% 使用scatter函数在图中标记圆弧的圆心。x_center和y_center是圆心的x和y坐标。
% 'r*' 是格式字符串,指定使用红色(red)和星号标记(star marker)来显示圆心位置。
xlabel('X position');
% xlabel函数添加x轴的标签,这里的标签是 'X position'。
ylabel('Y position');
% ylabel函数添加y轴的标签,这里的标签是 'Y position'。
title('Arc path visualization');
% title函数给图像添加标题,这里的标题是 'Arc path visualization'。
axis equal;
% axis equal命令调整坐标轴的刻度,使x轴和y轴的单位刻度长度相同。这样做可以确保图形的比例正确,圆形看起来不会变形。
grid on;
% grid on命令开启网格,这有助于更准确地看到每个点的位置。
hold off;
% hold off命令关闭保持状态,这意味着如果之后再进行绘图,MATLAB将在新的图像窗口中创建图像,而不是在当前图像上继续绘制。
end
end
% 速度前瞻 - 拐角速度求解
% motion_path : 运动路径,[[0,0,0],[1,1,1],[2,2,2]],从000出发过111到222
% n_axis : 轴的数量
% steps_per_mm : 1mm需要多少脉冲
% acceleration : 各个轴的加速度
% axis_max_rate : 各个轴的最大速度
% 参考文献 : https://blog.csdn.net/cln512/article/details/120748978?spm=1001.2014.3001.5502
% 总结 :GRBL的速度前瞻比较有意思,它的前瞻段数是缓存区中有多少个块,就前瞻多少个块。
% :1 先将mm坐标系换算成电机最小步进距离组成的坐标系
% 2 将各个轴的位移计算出来,并且又换算成mm
% 3 然后计算当前位移方向上各个轴的单位矢量的分量。
% 4 然后计算出当前位移方向上各个轴的加速度,速度的单位矢量投射到各个轴上的分量
% 5 计算拐角速度,通过给定一个误差h确定假想圆的大小,这个假想圆与两个向量相切,于是圆的向心速度就是拐角速度。
function [bmillimeters, brapid_rate, bacceleration, bjunction_speed] = plan_buffer_line(motion_path, n_axis, steps_per_mm, acceleration, axis_max_rate)
junction_deviation = 0.01;%mm, 人为给定的用于控制圆弧大小的误差系数
node_num = length(motion_path);
previous_unit_vec = zeros( n_axis );
block_max_junction_speed_sqr = zeros( node_num ); % 最大拐角速度
block_millimeters = zeros( node_num ); % block_millimeters 位移的模长
block_acceleration = zeros( node_num );
block_rapid_rate = zeros( node_num );
sys_position = zeros( node_num );% 系统的初始位置
% 仿真需要的预处理,把motion_path的第一个点转化成起始点
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% start %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
for i = 1: 1 : n_axis
sys_position(i) = round( motion_path(1, i) * steps_per_mm(i) );
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% figure;
plot(motion_path(:, 1), motion_path(:, 2), 'b-o');
hold on;
xlabel('X');
ylabel('Y');
zlabel('Z');
title('motion path');
grid on;
hold off;
for node = 2 : 1 : node_num
target_steps = zeros( n_axis,1 );
block_steps = zeros( n_axis,1 );
unit_vec = zeros( n_axis,1 );
block_dir = zeros( n_axis,1 ); % 记录运动方向, 1反方向, 0正方向
junction_unit_vec_buf = zeros( n_axis,1 );
block_step_event_count = 0;
for axis = 1: 1 : n_axis
% 第一步
% mm 坐标系转换成 脉冲步数坐标系
target_steps(axis) = round( motion_path(node, axis) * steps_per_mm(axis) );
% 计算当前位置运动到目标位置的变换量
delta_steps = target_steps(axis) - sys_position(axis);
% 更新位置
sys_position(axis) = target_steps(axis);
if( delta_steps ~= 0 )
block_steps(axis) = abs( delta_steps ); % 每个轴的位移
if( block_steps(axis) > block_step_event_count ) % 全部轴中最大的位移
block_step_event_count = block_steps; % TODO : 这里只是记录最大位移,仿真的时候没什么作用。
end
% 第二步
unit_vec(axis) = delta_steps / steps_per_mm(axis); % 单个轴的单位向量
else % 位置没有变化的轴
block_steps(axis) = 0;
unit_vec(axis) = 0;
end
% 记录运动方向
block_dir(axis) = 0;
if( unit_vec(axis) < 0 )
block_dir(axis) = 1;
end
end
% 单位向量描述了目标运动方向中各轴的参与比例。单位向量的每个分量代表了该方向中相应轴的相对贡献程度。
% 例如,一个向量 [0.6,0.8,0] 表明在当前的运动方向中,Y轴的贡献大于X轴,而Z轴不参与。
% block_millimeters = sqrt(x0^2 + y0^2 + z0^2)
% new_unit_vec(0) = x0/sqrt(x0^2 + y0^2 + z0^2)
% new_unit_vec(1) = y0/sqrt(x0^2 + y0^2 + z0^2)
% new_unit_vec(2) = z0/sqrt(x0^2 + y0^2 + z0^2)
% 第三步
[block_millimeters(node-1),new_unit_vec] = convert_delta_vector_to_unit_vector( unit_vec );
% fprintf("block_millimeters = %.10f\r\n",block_millimeters(node));
% fprintf("new_unit_vec = %.10f,%.10f,%.10f\r\n",new_unit_vec(1),new_unit_vec(2),new_unit_vec(3));
% 速度或者加速度 / 单位向量
% 这个操作的核心是确定在不超过单个轴的最大速度或加速度限制的情况下,系统在该方向上能够达到的最大速度或加速度。
% 物理意义: 给定一个方向,如果某个轴的单位向量分量较小,意味着该轴在整体运动中承担较小的部分。
% 然而,如果这个轴的最大速度或加速度很低,即使其分量小,它也可能成为整体运动的限制因素。
% 通过将轴的最大速度或加速度除以其单位向量分量,可以得出该轴在维持整体运动方向不变的情况下能提供的最大速度或加速度。
% 这个结果告诉我们,为了不超过这个轴的限制,整个系统在这个方向上的最大速度或加速度应该是多少。
% 这里能引出一个提速的方法:如果最慢的轴的速度的平方的2倍开根号大于速度最块的轴,那么可以考虑走45度角的斜线。
% 第四步
block_acceleration(node-1) = limit_acceleration_by_axis_maximum(new_unit_vec, acceleration);
block_rapid_rate(node-1) = limit_max_rate_by_axis_maximum( new_unit_vec, axis_max_rate );
% 第五步
% 拐角速度求解
% 作图 :纵坐标为速度,横坐标为时间, 在第一象限上任意画一点A(x,y0),连接原点O与A,然后画点B(2*x, 0),连接AB点
% 这就是一段行程内速度的变化曲线,然后画第二段,画点C(2*x+n, y1),点D(2(2*x+n),0),连接BC,CD。
% AB,BC看做是首尾相连的向量,B点就是速度的衔接点,向量拐角记作theta。
% 向量夹角是共尾部后的夹角。所以速度拐角(junction_theta) = 180 - theta。
% 向量夹角公式:cos<a,b> = ab/(|a|*|b|)
% = x1x2 + y1y2 + z1z2 / sqrt(x1*x1 + y1*y1 + z1*z1)*sqrt(x2*x2 + y2*y2 + z2*z2)
% junction_cos_theta = cos(180 - theta)
% = -cos(theta)
% = -(x1x2 + y1y2 + z1z2 / sqrt(x1*x1 + y1*y1 + z1*z1)*sqrt(x2*x2 + y2*y2 + z2*z2))
% 由于是单位矢量,所以:sqrt(x1*x1 + y1*y1 + z1*z1) = sqrt(x2*x2 + y2*y2 + z2*z2)) = 1
% junction_cos_theta = -(x1x2 + y1y2 + z1z2)
% = -x1x2 - y1y2 - z1z2
junction_cos_theta = 0; % cos(θ)
for i = 1 : 1 : n_axis
junction_cos_theta = junction_cos_theta - ( new_unit_vec(i) * previous_unit_vec(i) );
junction_unit_vec_buf(i) = new_unit_vec(i) - previous_unit_vec(i); % 向量减法;代表的是从上一个方向到当前方向需要发生的变化。
previous_unit_vec(i) = new_unit_vec(i);
end
% 这里的思想是用圆弧的向速度作为拐角的过渡速度
% 需要用到圆周运动的向心加速度的公式 : a_c = v^2 /r ;其中a是加速度;c是下标,意思是centripetal;v 是物体的线速度或切线速度;r 是圆的半径
% 直线与圆相切,圆心和切点的连线垂直切线。
% 作图:一个首尾相连的向量 Ventry、Vexit,它们连接处的夹角为theta;圆O与Ventry、Vexit相切;h是theta的角平分线上的一段距离,起点在向量的交点处,终点在内切圆上。
% 大小人为给定,它控制着圆的大小。向量 Vjunction = Vexit - Ventry。
% 二倍角公式:cos(θ) = 2 * cos^2(θ/2) - 1 = 1 - 2*sin^2(θ/2)
% 化简能得到 sin(θ/2) = sqrt( (1 - cos(θ)) / 2 )
% 结合图知道 sin(θ/2) = r / (r+h)
% v^2 = a * r = acc * ( ( h * sin(θ/2) ) / ( 1 - sin(θ/2) ) )
if( junction_cos_theta > 0.999999 ) %夹角为零度,拐角的衔接速度需要降到0
block_max_junction_speed_sqr(node-1) = 0;
elseif(junction_cos_theta < -0.999999) %夹角为180,拐角的衔接速度不需要任何处理,把过渡速度设置成一个巨大的值,表示不参与后面的处理
block_max_junction_speed_sqr(node-1) = 10^38;
else
[~,junction_unit_vec] = convert_delta_vector_to_unit_vector(junction_unit_vec_buf);
junction_acceleration = limit_acceleration_by_axis_maximum(junction_unit_vec, acceleration);
sin_theta_d2 = sqrt( 0.5 * (1 - junction_cos_theta) );% sin(θ/2)
block_max_junction_speed_sqr(node-1) = ( junction_acceleration * junction_deviation * sin_theta_d2 / (1 - sin_theta_d2) );
end
fprintf("block_max_junction_speed_sqr = %.10f\r\n",block_max_junction_speed_sqr(node-1));
end
bmillimeters = block_millimeters;
brapid_rate = block_rapid_rate;
bacceleration = block_acceleration;
bjunction_speed = block_max_junction_speed_sqr;
end
function [magnitude,unit_vector] = convert_delta_vector_to_unit_vector(vector)
% 经过这个计算 unit_vector中的各分量的合成矢量大小为1(单位矢量)
asix_num = length(vector);
unit_vector = zeros(asix_num);
magnitude = 0;
for i = 1 : 1 : asix_num
magnitude = magnitude + vector(i)^2;
end
if( magnitude == 0 ) %如果合成矢量为0,不再做后面的计算
return;
end
magnitude = sqrt( magnitude ); % 模长
inv_magnitude = 1 / magnitude; % 计算模长变成单位向量的缩放倍数
for i = 1 : 1 : asix_num
unit_vector(i) = vector(i) * inv_magnitude; % 缩小每个分量使得合成矢量是单位矢量
end
end
function limit_value = limit_acceleration_by_axis_maximum(vector, acc)
asix_num = length(vector);
limit_value = 10^38;
for i = 1 : 1 : asix_num
if( vector(i) ~= 0 )
buf = acc(i) / vector(i);
if( buf < limit_value )
limit_value = buf;
end
end
end
end
function limit_value = limit_max_rate_by_axis_maximum(vector, rate)
asix_num = length(vector);
limit_value = 10^38;
for i = 1 : 1 : asix_num
if( vector(i) ~= 0 )
buf = rate(i) / vector(i);
if( buf < limit_value )
limit_value = buf;
end
end
end
end
% 速度前瞻 - 速度约束
% 前瞻算法不仅约束拐点速度,也对一段行程内的最大速度做约束。
% GRBL的速度约束模型是直接直接过渡的约束模型
% 参考文献 : 《数控系统连续小线段的路径优化与速度前瞻控制算法研究_聂伟刚》
% 《基于运动控制卡的PC数控进给速度前瞻控制_刘青山》
% 《嵌入式数控系统速度前瞻规划算法研究_游达章》
% https://blog.csdn.net/cln512/article/details/120749226?spm=1001.2014.3001.5502
% 后顾速度约束的思想:
% 把末端速度当成是起始速度,向起始段的方向计算每一段,看该段上的距离和加速度能否达到所需要的末端速度
% 利用运动动学基本公式: V^2 = V0^2 + 2at。约束条件:V = min{设定速度,机器允许的最大速度,sqrt(V0^2 + 2at)}
% 这是直接过渡法的速度约束公式,前瞻也是用了同样的方法。
%%%%这个函数模型将期望速度设置为最大速度
% segments : 路径的段数
% rapid_rate : 该位移方向上的目标速度
% junction_speed : 拐角速度
% millimeters : 位移长度
% acc : 加速度
function planner_recalculate(segments, rapid_rate, junction_speed, millimeters, acc)
% 预处理 计算 2at
tow_at_buf = zeros(segments, 1);
for seg = 1 : 1 : segments
tow_at_buf(seg) = 2 * millimeters(seg) * acc(seg);
end
% 后顾过程
v_path_restriction = zeros(segments, 1);
entry_speed_sqr = zeros(segments, 1) + 1;
% 计算每个段的入口速度的平方
for seg = segments : -1 : 1
% V^2 = V0^2 + 2at
v_path_restriction(seg) = rapid_rate(seg)^2 + tow_at_buf(seg);
if v_path_restriction(seg) > junction_speed(seg)^2
entry_speed_sqr(seg+1) = junction_speed(seg)^2;
else
entry_speed_sqr(seg+1) = v_path_restriction(seg);
end
end
% 前瞻过程
for seg = 1 : 1 : segments
% V^2 = V0^2 + 2at
v_path_restriction(seg) = rapid_rate(seg)^2 + tow_at_buf(seg);
if v_path_restriction(seg) > junction_speed(seg)^2
if entry_speed_sqr(seg+1) > junction_speed(seg)^2
entry_speed_sqr(seg+1) = junction_speed(seg)^2;
end
else
if entry_speed_sqr(seg+1) > v_path_restriction(seg)
entry_speed_sqr(seg+1) = v_path_restriction(seg);
end
end
end
% entry_speed_sqr - 是速度的平方
% 绘制图形并标记每一个点
figure;
plot(1 : segments + 1, entry_speed_sqr, 'LineWidth', 2, 'Marker', 'o', 'MarkerFaceColor', 'r', 'MarkerEdgeColor', 'k');
title('Entry Speed Squared per Segment');
xlabel('Segment Number');
ylabel('Entry Speed Squared (V^2)');
grid on;
end

















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









