







HBase第二天——HBase安装
自己的话:我愿平东海,身沉心不改;
大海无平期,我心无绝时。
HBase的集群环境搭建
一、下载对应的HBase的安装包
所有关于CDH版本的软件包下载地址如下:
http://archive.cloudera.com/cdh5/cdh/5/
HBase对应的版本下载地址如下:
http://archive.cloudera.com/cdh5/cdh/5/hbase-1.2.0-cdh5.14.0.tar.gz
二、Zookeeper 正常部署
首先保证 Zookeeper 集群的正常部署,并启动之:
[hadoop1 zookeeper-3.4.10]$ bin/zkServer.sh start
[hadoop2 zookeeper-3.4.10]$ bin/zkServer.sh start
[hadoop3 zookeeper-3.4.10]$ bin/zkServer.sh start
三、Hadoop 正常部署
Hadoop 集群的正常部署并启动:
[hadoop1 ~]$ start-all.sh
四、压缩包上传并解压
将我们的压缩包上传到node01服务器
并解压HBase 到指定目录
tar -zxvf hbase-1.3.1.tar.gz -C
/opt/module
五、修改配置文件
修改 HBase 对应的配置文件
[hadoop1 ~]$ cd /opt/module/hbase-1.3.1/conf
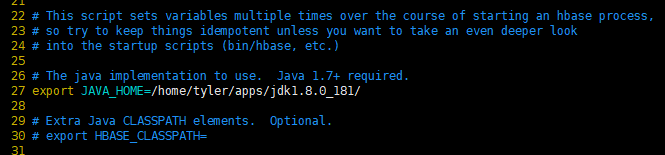
1. 修改hbase-env.sh 内容:
注释掉HBase使用内部zk
vim hbase-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_192
export HBASE_MANAGES_ZK=false

2. 修改hbase-site.xml 内容:
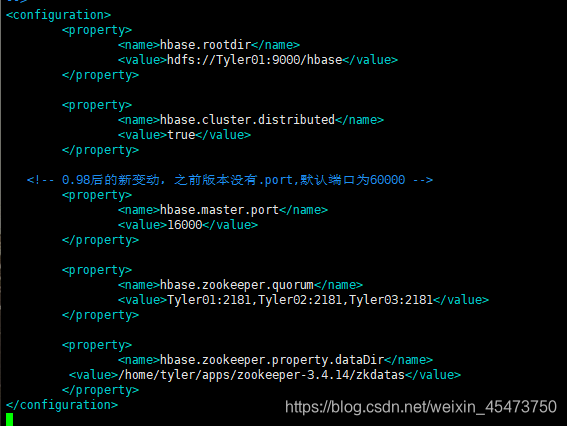
修改hbase-site.xml
vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</
value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/zkData</value>
</property>
</configuration>
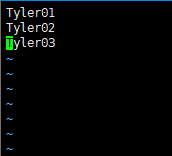
3. 修改regionservers内容:
vim regionservers
hadoop01
hadoop02
hadoop03
4. 创建back-masters配置文件,实现HMaster的高可用
vim backup-masters
hadoop02
5. 软连接 hadoop 配置文件到 hbase:
[hadoop1 module]$ ln -s /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml /opt/module/hbase/conf/core-site.xml
[hadoop2 module]$ ln -s /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml
六、HBase 远程发送到其他集群
将我们第一台机器的hbase的安装包拷贝到其他机器上面去
cd /opt/module
scp -r hadoop-2.7.2/ hadoop02:$PWD
scp -r hadoop-2.7.2/ hadoop03:$PWD
七、三台机器添加HBASE_HOME的环境变量
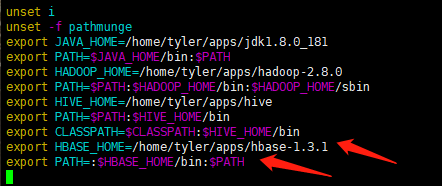
vim /etc/profile
export HBASE_HOME=/opt/module/hadoop-2.7.2
export PATH=:$HBASE_HOME/bin:$PATH
八、HBase 集群启动
1.启动方式 1
[hadoop1 hbase]$ bin/hbase-daemon.sh start master
[hadoop1 hbase]$ bin/hbase-daemon.sh start regionserver
提示:如果集群之间的节点时间不同步,会导致 regionserver 无法启动,抛出ClockOutOfSyncException 异常。
修复提示:
- a、同步时间服务
请参看帮助文档:《尚硅谷大数据技术之 Hadoop 入门》 - b、属性:hbase.master.maxclockskew 设置更大的值
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
<description>Time difference of regionserver from master</description>
</property>
2.启动方式 2
[hadoop1 hbase]$ bin/start-hbase.sh
查看进程,是否全部开启:
jps
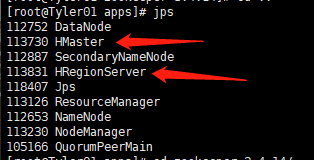
3.对应的停止服务:
[hadoop1 hbase]$ bin/stop-hbase.sh
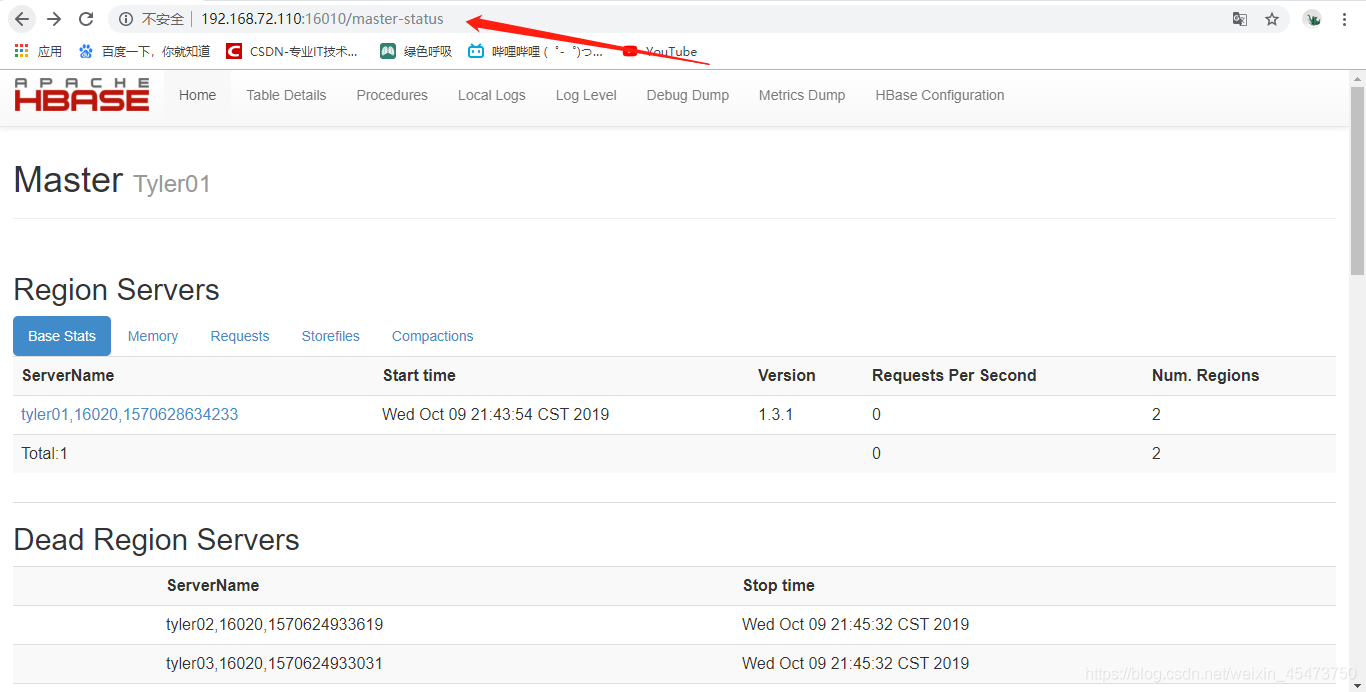
九、查看 HBase 页面
启动成功后,可以通过“host:port”的方式来访问 HBase 管理页面,例如:
http://hadoop1:16010















 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









