






1.为什么要引入并发编程
场景1:一个网络爬虫,按顺序爬取花了1个小时,采用并发下载减少到20分钟。
场景2:一个APP应用,优化前每次打开页面需要3秒,采用异步并发提升到每次200毫秒
引入并发,就是为了提升程序运行速度
1.1 程序提速的方法
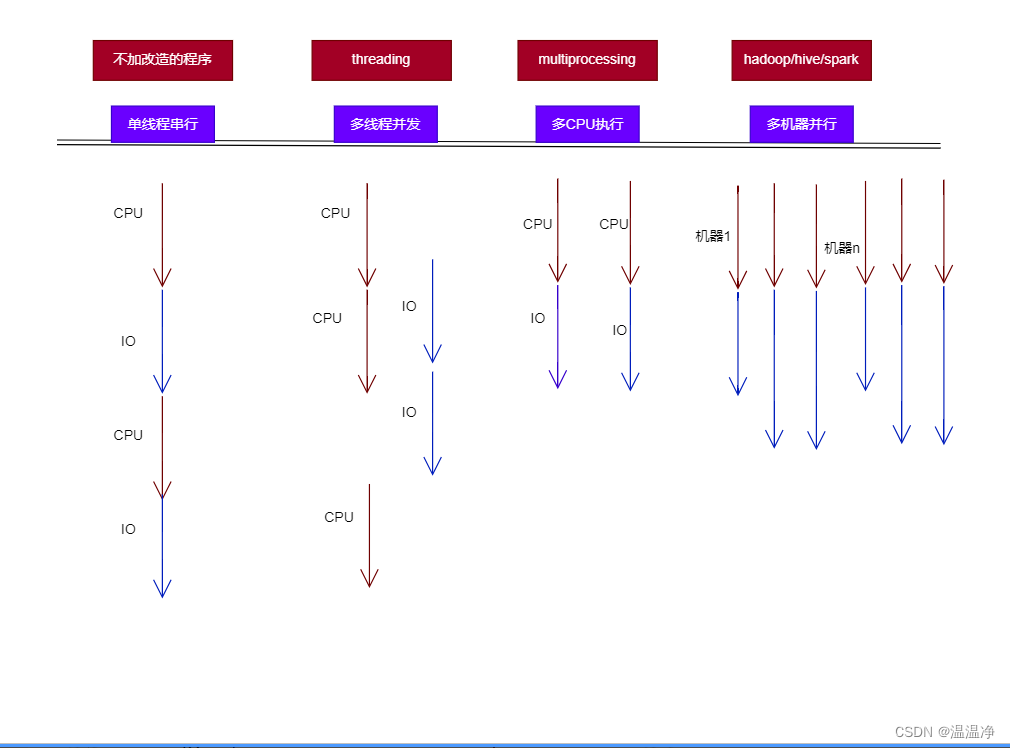
单线程串行
一般程序运行时单线程串行,我们有一个线程,CPU先执行,然后进行IO(数据的读取和写出)
在IO期间,CPU是不做什么事情的。等IO完成后,CPU开始进行运算,然后进行下次IO.
整体时间是会有些浪费,那就是在IO期间,CPU是等待的状态。
引入多线程并发
当我们引入多线程并发时,它的运行就发生了变化。
CPU开始执行时,如果遇到了IO操作,它就会切换到另外一个task进行执行。
当IO完成了以后,会通知CPU进行下一步的处理。
这里有个知识点,咱们电脑中的CPU和IO,这两个它们是可以同时并行进行的。
IO的执行,比如说读取内存、磁盘、网络,它的过程是不需要CPU参与的
这样的话,CPU可以释放出来,来执行其他的TASK,实现并发的加速.
但这种原理上,其实还是一个CPU来进行运行的。
2、python对并发编程的支持
多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成
多进程:multiprocessing,利用多核CPU的能力,真正的并发执行任务
异步IO:asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行
python提供的额外函数来提供辅助能力
1.使用lock对共享资源加锁,防止冲突访问。
比如说,多线程和进程同时访问同一个文件,同时写入就会有冲突。可以把文件锁起来,就可以有序访问
2.使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式
比如说爬虫的时候,可以用生产者-消费者模式来改造,生产者就是边爬取,消费者就是边解析,这两个是分开的两个步骤
3.使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结束、获取结果
4.使用subprocess启动外部程序的进程,并进行输入输出交互
比如说当你写好了一个exe程序,使用它,就可以调起这个exe程序,并跟它进行输入输出的交互,来实现交互式的进程通信
3、怎么选择多进程多线程协程
python并发编程的方式
多线程Thread、多进程Process、协程Coroutine
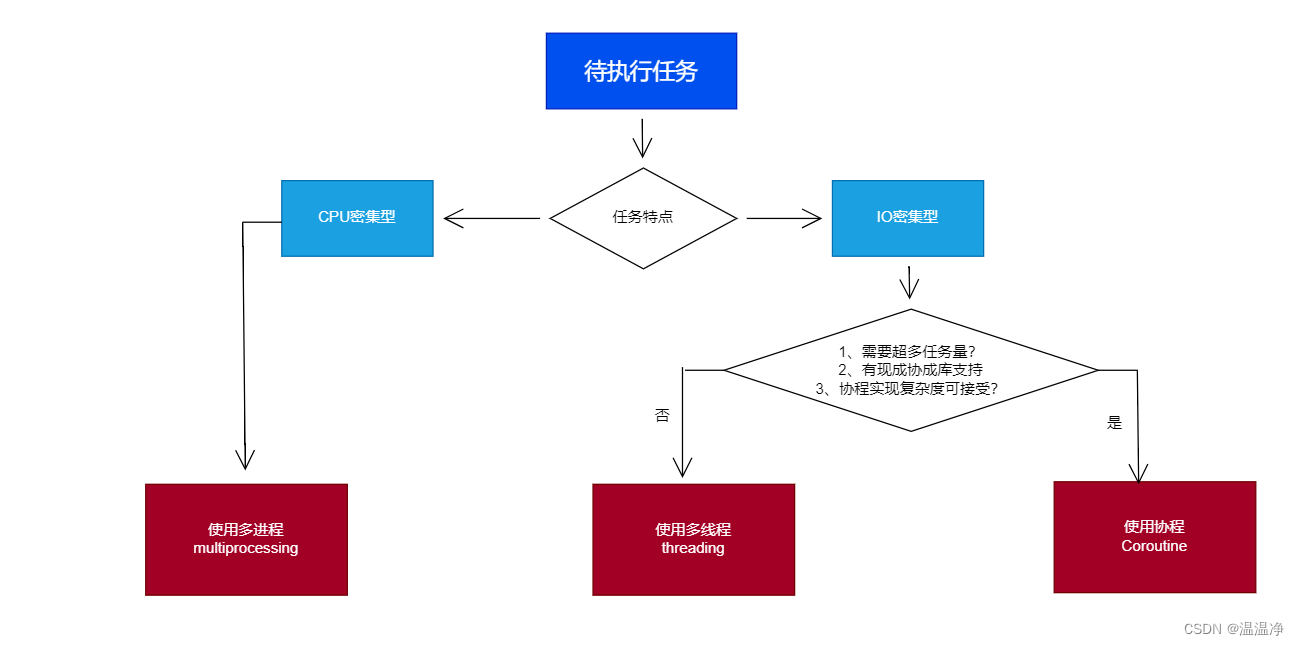
3.1、CPU密集计算与IO密集型计算
CPU密集型(CPU-bound):
CPU密集型也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高。
(也就是说系统的硬盘、内存性能相对CPU要好很多。系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),
I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading(负载)很高。)
例如:压缩解压缩、加密解密、正则表达式搜索
CPU使用率较高(例如:计算圆周率、对视频进行高清解码、矩阵运算等情况)的情况下,通常,线程数只需要设置为CPU核心数的线程个数就可以了。
(此时是最大效率。但是如果线程数/进程数远远超出 CPU 核心数量,反而会使得任务效率下降,因为频繁的切换线程或进程也是要消耗时间的。
因此对于 CPU 密集型的任务来说,线程数/进程数等于 CPU 数是最好的了。)
这一情况多出现在一些业务复杂的计算和逻辑处理过程中。比如说,现在的一些机器学习和深度学习的模型训练和推理任务,包含了大量的矩阵运算。
IO密集型(I/O bound)
IO密集型指的是系统运作大部分的状况是CPU在等I/O(硬盘/内存)的读/写操作,CPU占用率较低。
(硬盘适合长期保存大量的数据,而内存则适合暂存正在运行的程序和数据。)
例如:文件处理程序、网络爬虫程序、读写数据库程序
CPU 使用率较低,程序中会存在大量的 I/O 操作占用时间,导致线程空余时间很多,通常就需要开CPU核心数数倍的线程。
其计算公式为:IO密集型核心线程数 = CPU核数 / (1-阻塞系数)。
当线程进行 I/O 操作 CPU 空闲时,启用其他线程继续使用 CPU,以提高 CPU 的使用率。例如:数据库交互,文件上传下载,网络传输等。
简而言之,如果你的程序依赖大量的外部数据源,比如说内存、磁盘和网络,就是IO密集型
否则,如果只在CPU中进行计算,那就是CPU密集型。
详见:一分钟明白IO密集型与CPU密集型的区别
3.2、多进程、多线程、协程的对比
| 多进程Process(multiprocessing) | 多线程Thread(threading) | 多协程Coroutine(asyncio) | |
|---|---|---|---|
| 优点 | 可以利用多核CPU并行运算 | 相比进程,更轻量级、占用资源少 | 内存开销最少、启动协程数量最多 |
| 缺点 | 占用资源最多、可启动数目比线程少 | 多线程只能并发执行,不能利用多CPU(GIL,GIL全局解释器锁,cpython特有的) | 支持的库有限制(aiohttp vs requests)、代码实现复杂 |
| 适用场景 | CPU密集型计算 | IO密集型计算、同时运行的任务数目要求不多 | IO密集型计算、需要超多任务运行、但有现成库支持的场景 |
3.3 .单线程与多线程爬虫
import threading
import time
from wj_demo.threading_demo.demo_base02.blog_spider import urls, craw
"""
I/O密集型操作
"""
def single_thread():
"""
单线程爬取
:return:
"""
print("single_thread begin")
for url in urls:
craw(url)
print("single_thread end")
def multi_thread():
"""
多线程爬取
:return:
"""
print("multi_thread begin")
threads = []
for url in urls:
threads.append(
threading.Thread(target=craw, args=(url,))
)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print("multi_thread end")
if __name__ == "__main__":
start = time.time()
single_thread()
end = time.time()
single_thread_cost = end - start
print(f"{single_thread.__name__} cost:", single_thread_cost, "seconds")
start = time.time()
multi_thread()
end = time.time()
multi_thread_cost = end - start
print(f"{multi_thread.__name__} cost:", multi_thread_cost, "seconds")
rate = single_thread_cost / multi_thread_cost
print(f'{single_thread.__name__} is cost {rate} {multi_thread.__name__}')
# single_thread cost: 17.854352235794067 seconds
# multi_thread cost: 6.92170524597168 seconds
# single_thread is cost 2.579473063546734 multi_thread
3.4 异步协程asyncio爬虫
import asyncio
import time
from wj_demo.threading_demo.thread02_base02.blog_spider import urls
start = time.time()
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
tasks = [loop.create_task(async_craw(url)) for url in urls]
loop.run_until_complete(asyncio.gather(*tasks))
end = time.time()
print('use time seconds:', end - start)
# use time seconds: 2.738969087600708
4、GIL全局解释器锁(英语:Global Interpreter Lock,缩写GIL)
是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。
即使在多核处理器上,使用GIL的解释器也只允许同一时间执行一个线程。
python解释器有多个版本 Cpython 、Jpython、Pypypython,但普遍使用的是Cpython解释器
GIL不是python的特点而是Cpython解释器的特点
GIL是保证解释器级别的数据的安全
GIL会导致同一个进程下的多个线程无法同时执行
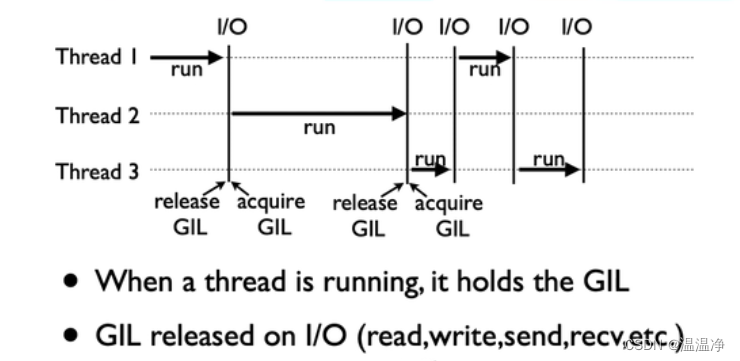
为什么用GIL?
设计之初,是为了规避并发问题引入GIL,现在却很难去除了。
为了解决多线程之间数据完整性和状态同步问题
原因详解:
Python中对象的管理,是使用引用计数进行的,引用数为0则释放对象
开始:线程A和线程B都引用了对象obj,obj.ref_num=2,线程A和线程B都想撤销对obj的引用
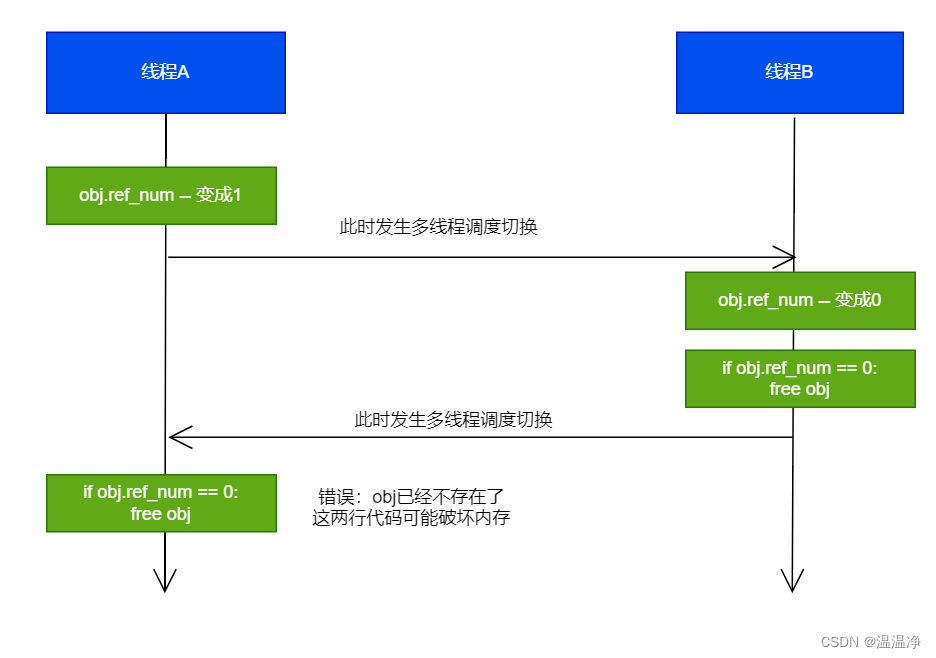
简化了python对共享资源的管理
不加锁,会导致引用计数器混乱 释放掉别人的内存
怎么规避GIL带来的限制?
1、多线程threading机制依然是有用的,用于IO密集型计算
因为I/O(read,write,send,recv,etc)期间,线程会释放GIL,实现CPU和IO的并行
因为多线程用于IO密集型计算依然可以大幅提升速度
但是多线程用于CPU密集型计算时,只会更加拖慢速度
2、使用multiprocessing的多进程机制实现并行计算、利用多核CPU优势
为了应对GIL的问题,Python提供了multiprocessing














 2339
2339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









