







这里写目录标题
一. Hadoop–MapReduce自动化运行配置
1. idea下载Maven插件
插件名: Maven Helper
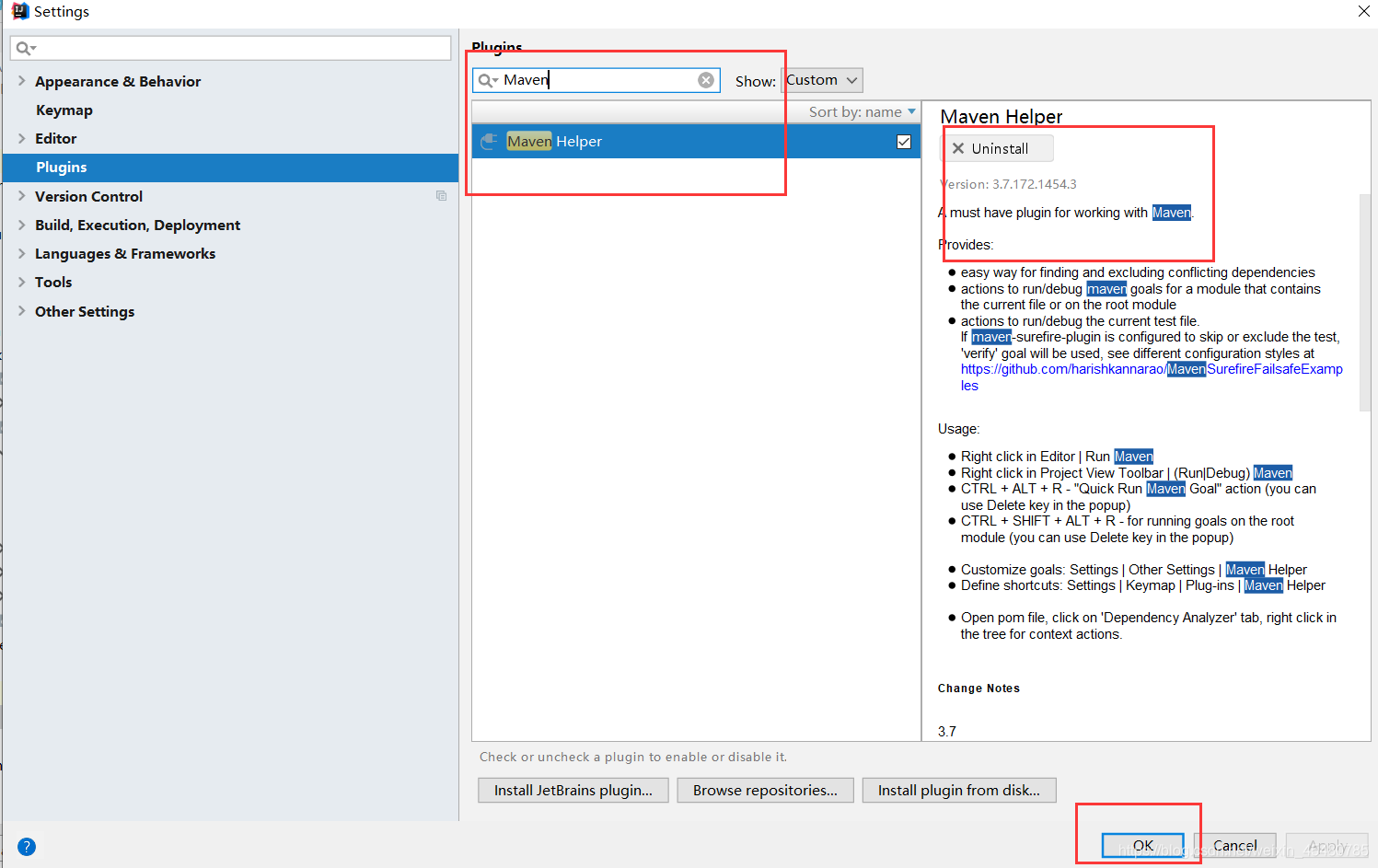
2. 指定main class 信息
2. 传统hadoop集群并执行hadoop_hdfs.jar包
[root@hadoop15 ~]# hadoop jar hadoop_hdfs.jar com.xizi.phonedata.PhoneCleanDataJob
- 默认直接通过maven插件打成jar包中没有指定main class 信息,因此在运行mapreduce的jar包时必须在指令后面明确指定main class 的信息是谁。
- 在执行mapreduce作业时会加大执行的难度,因此我们需要在打jar包时指定main class信息,减少执行作业时的操作,
- 如果需要在打包中指定main class 信息:只需要对打包插件进行配置即可:
3. 就可以直接执行jar包,不需要额外指定main class 信息
<plugins>
<!-- 在打包插件中指定main class 信息 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
// jar包位置
<outputDirectory>${basedir}/target</outputDirectory>
<archive>
<manifest>
//运行的类全类名
<mainClass>com.xizi.phonedata.PhoneCleanDataJob</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
jar包输出位置
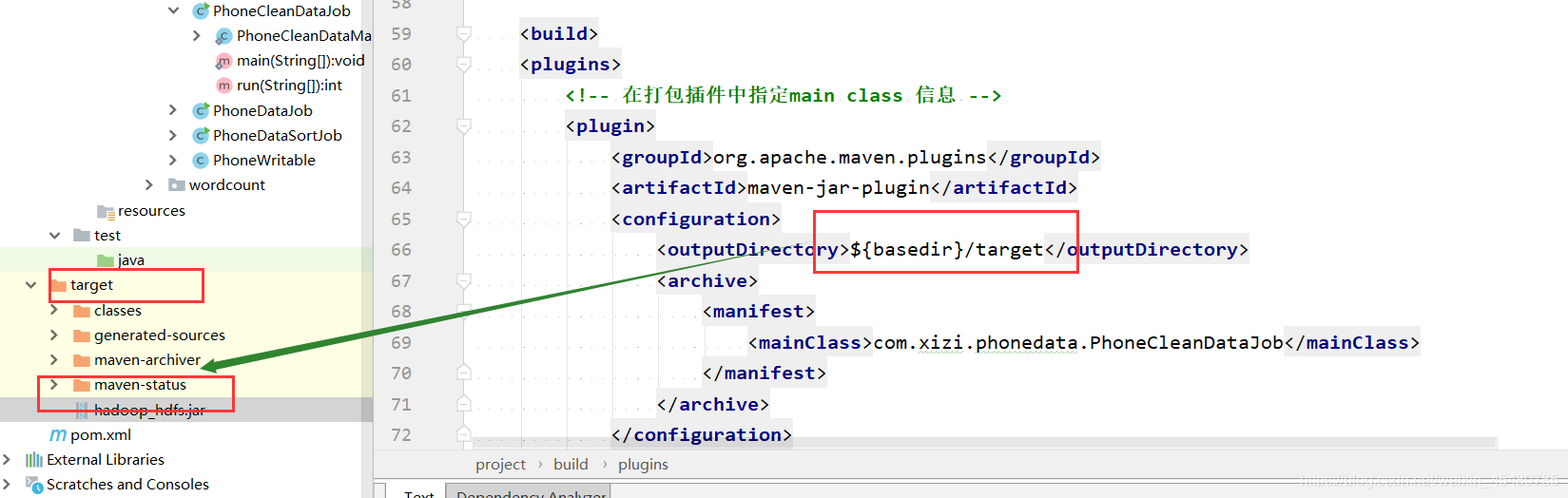
3. 使用wagon插件实现自动上传至hadoop集群
<build>
<!--扩展maven的插件中加入ssh插件-->
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<fromFile>target/test.jar 或者 ${project.build.finalName}.jar</fromFile>
<url>scp://root:123456@127.0.0.1/root</url>
</configuration>
</plugin>
</plugins>
</build>
1. 打包后直接执行wagon uplod-single即可
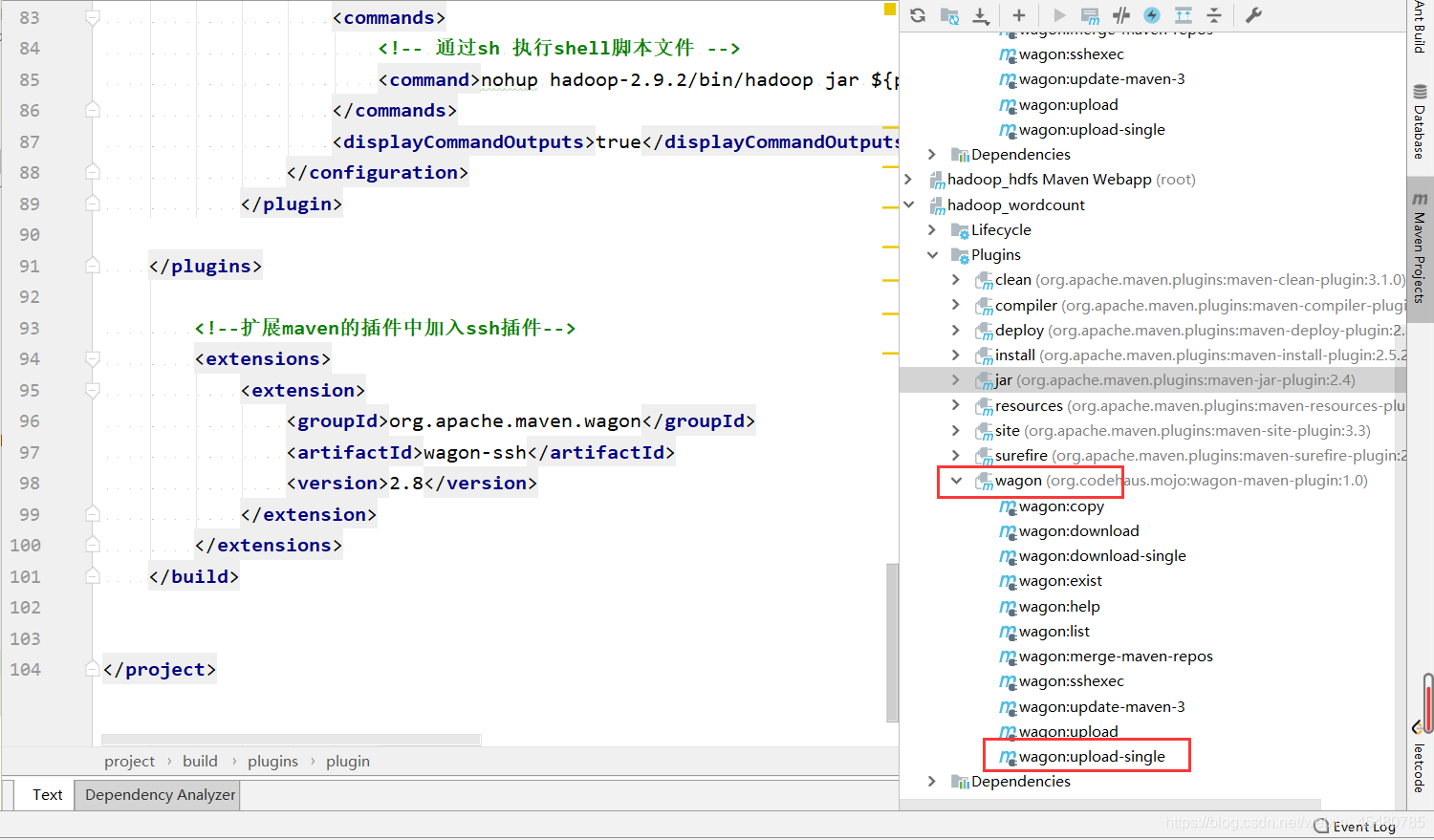
2. 执行命令操作: clean package wagon:upload-single
4. 使用wagon上传jar完成后远程执行job作业
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<fromFile>target/${project.build.finalName}.jar</fromFile>
<url>scp://root:123456@127.0.0.1/root</url>
<commands>
<!-- 通过sh 执行shell脚本文件 -->
<command>nohup hadoop-2.9.2/bin/hadoop jar hadoop_wordcount-1.0-SNAPSHOT.jar > /root/mapreduce.out 2>&1 & </command>
</commands>
<displayCommandOutputs>true</displayCommandOutputs>
</configuration>
</plugin>
1. 执行命令操作:clean package wagon:upload-single wagon:sshexec
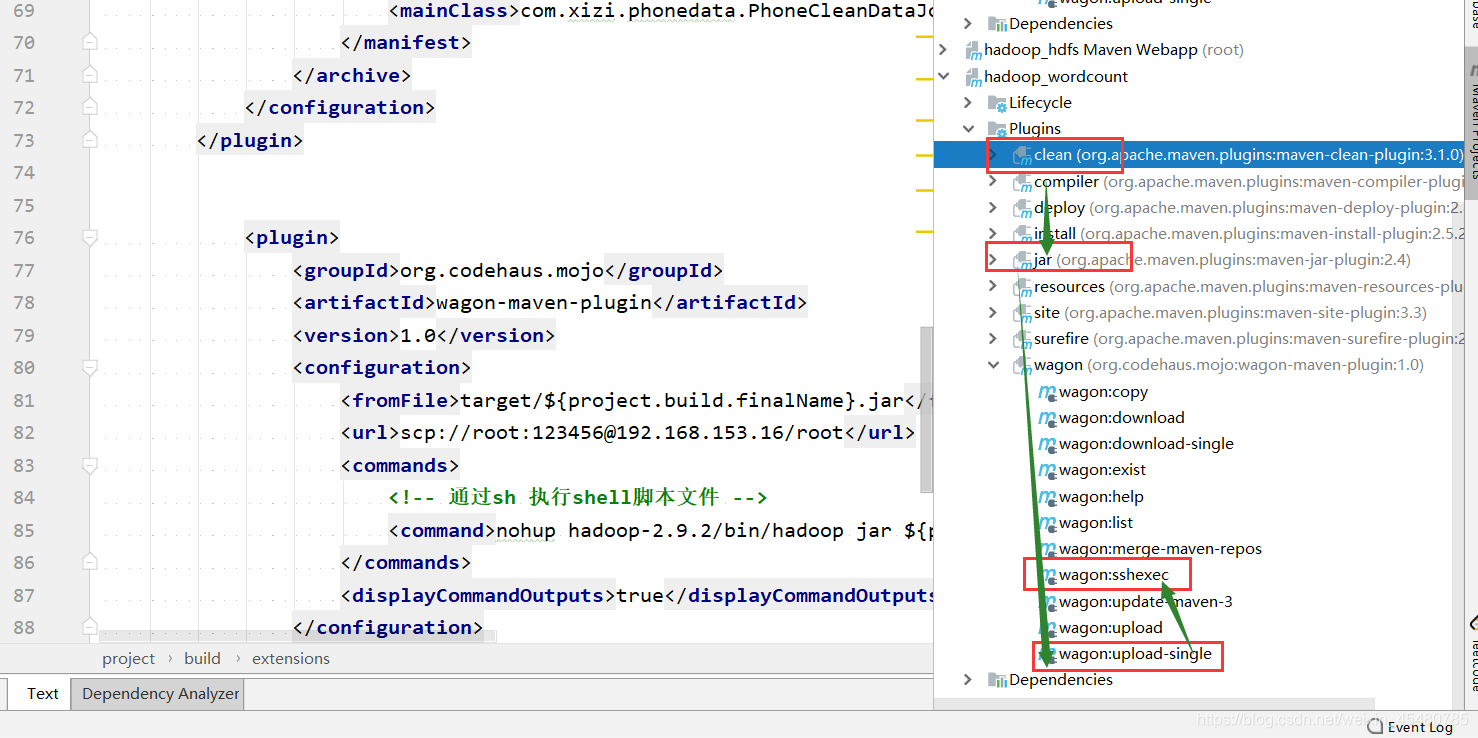
2. 执行优化 一行代码直接优化
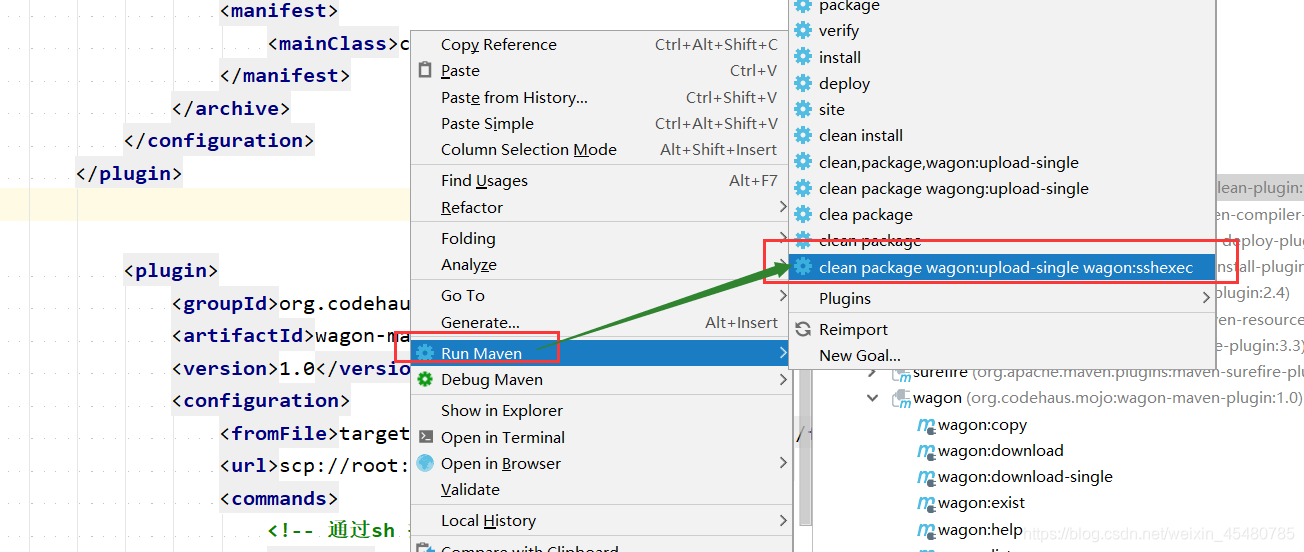
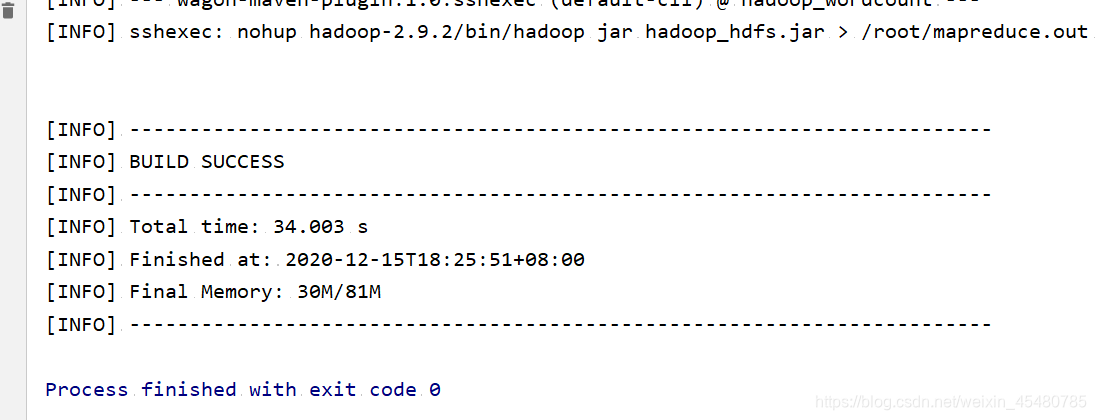
3. 执行成功














 4437
4437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









