









Chapter02 Introduction to Stacks
What is a Stack
-
Principle: Last in, First out (LIFO)

the last element inserted is the first one to be removed
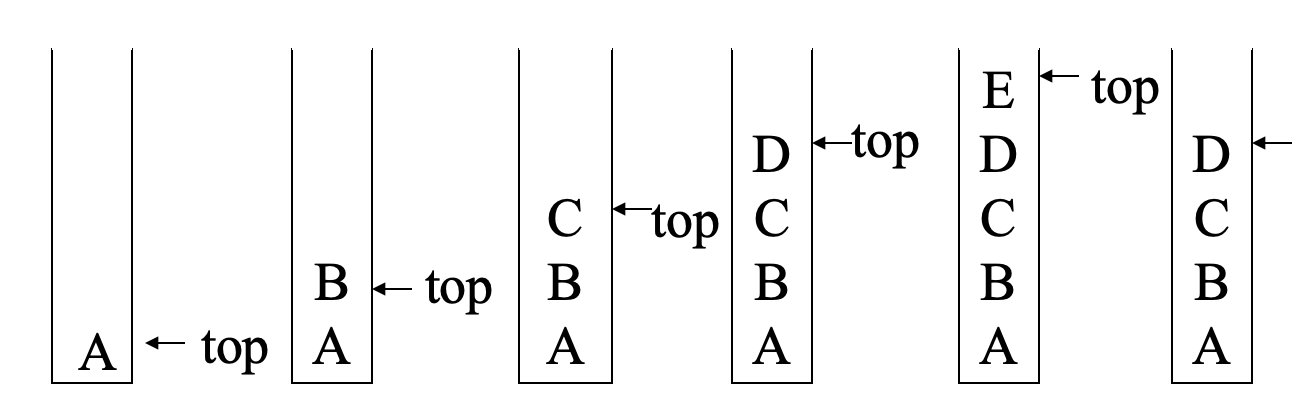
Definition of ‘Stack’
Def. A stack of elements is a finite sequence, together with the following operations:
createan empty stack- Test whether it’s
empty pusha new entry onto the top of the stack, provided the stack is not fullpopthe entry off the top of the stack, provided the stack is not full- Retrieve the
topentry from the stack, provided the stack is not full
Array-based Stack Implementation
Preset
enum Error_code{underflow, overflow, success}; // set status
const int maxstack = 10; // stack size
Interfaces & Construct Function
class MyStack
{
public:
MyStack();
bool empty() const;
Error_code push(const int &item);
Error_code pop();
Error_code top(int &item) const;
private:
int count;
int entry[maxstack];
};
MyStack::MyStack()
{
count = 0; // initialize count
}
Operation - empty
Algorithm:
- If the numbers of elements in the stack is bigger than 0, then it’s not empty.
- Otherwise, it’s empty.
Code:
bool MyStack::empty() const
{
bool outcome = true;
if (count > 0)
outcome = false;
return outcome;
}
Operation - push
Algorithm:
- If the number is bigger than max size, then return overflow
- Otherwise, place the item at the end of the array and increase count.
Code:
Error_code MyStack::push(const int &item)
{
Error_code outcome = success;
if (count >= maxstack)
outcome = overflow;
else
entry[count++] = item;
return outcome;
}
Operation - pop
Algorithm:
- If the array is empty, return underflow
- Otherwise, decrease count, you don’t have to remove the element from the array.
Code:
Error_code MyStack::pop()
{
Error_code outcome = success;
if (count == 0)
outcome = underflow;
else
--count;
return outcome;
}
Operation - top
Algorithm:
- If the array is empty, return underflow
- Otherwise, return the last element of the array.
Code:
Error_code MyStack::top(int &item) const
{
Error_code outcome = success;
if (count == 0)
outcome = underflow;
else
item = entry[count - 1];
return outcome;
}
Universal Stack
Add typedef double Stack_entry;
Sequence of N-elements Pop out of a Stack
f ( n ) = ∑ i = 1 n − 1 f ( i ) f ( n − 1 − i ) f(n)=\sum_{i=1}^{n-1} f(i)f(n-1-i) f(n)=i=1∑n−1f(i)f(n−1−i)
Stack in STL
#include <stack>- Define a stack:
stack<datatype> num; - Insert element:
num.push(item) - Access next element:
num.top() - Remove top element:
num.pop() - Test whether container is empty:
num.empty() - Return size:
num.size() - Construct ans insert element:
num.emplace() - Swap contents:
num1.swap(num2)
Practical Use of Stack 1 - Polish Expression
What is a Polish Expression
- Infix expressions(中序波兰式)
- An operator appears between its operands
- Example: a + b
- Prefix expressions(前序波兰式)
- An operator appears before its operands
- Example: + a b
- Postfix expressions(后序波兰式)
- An operator appears after its operands
- Example: a b +
Conversion Rules
To convert a fully parenthesized infix expression to a prefix form:
-
Move each operator to the position marked by its corresponding open parenthesis
-
Remove the parentheses
Example:
- Infix expression: ( ( a + b ) ∗ c ) ( (a + b) * c ) ((a+b)∗c)
- Prefix expression: ∗ + a b c * + a\ b\ c ∗+a b c
To convert a fully parenthesized infix expression to a postfix form:
- Move each operator to the position marked by its corresponding closing parenthesis
- Remove the parentheses
Example:
- Infix expression: ( ( a + b ) ∗ c ) ( (a + b) * c ) ((a+b)∗c)
- Postfix expression: a b + c ∗ a\ b + c\ * a b+c ∗
Advantages of prefix and postfix expressions:
- No precedence rules
- No association rules
- No parentheses
- Simple grammars
- Straightforward recognition and evaluation algorithms
Practical Use of Stack 2 - Bracket Matching
Practical Use of Stack 3 - Conversion
Chapter03 Queues
What is a Queue
-
All additions to the list are made at one end, called the rear or tail of the queue, and all deletions from the list are made at the other end, called the front or head of the queue.
-
Principle: first in, first out (FIFO)
ADT Queue Operations
- create an empty queue:
Queue::Queue(); - determine whether a queue is empty:
bool Queue::empty() const; - add a new item to the queue:
Error_code Queue::append(const Queue_entry &x); - remove the item that was added earliest:
Error_code Queue::serve(); - retrieve the item that was added earliest:
Error_code Queue::retrieve(Queue_entry &x) const;
The Implecation of a Sequential Queue
Interfaces
class Queue
{
public:
Queue();
bool empty() const;
Error_Code append(const int &item);
Error_Code serve();
Error_Code retrieve(int &item) const;
private:
int count;
int rear, front;
int queue[maxqueue];
};
Construction Functions
Queue::Queue()
{
count = 0;
rear = -1;
front = 0;
}
Operation - empty
Code:
bool Queue::empty() const
{
return count == 0;
}
Operation - append
Algorithm:
- If rear pointer is over the bound, then return overflow
- Otherwise, increase count and rear pointer, and place the item
Code:
Error_Code Queue::append(const int &item)
{
if (rear >= maxqueue - 1)
return overflow;
count++;
rear++;
queue[rear] = item;
return success;
}
Operation - serve
Algorithm:
- If the queue is empty, then return underflow
- Otherwise, decrease count and front pointer
Code:
Error_Code Queue::serve()
{
if (count <= 0)
return underflow;
count--;
front++;
return success;
}
Operation - retrieve
Algorithm:
- If the queue is empty, then return underflow
- Otherwise, return the item front pointer is pointing to.
Code:
Error_Code Queue::retrieve(int &item) const
{
if (count <= 0)
return underflow;
item = queue[front];
return success;
}
But, we can’t use this kind of queue because the queue is too short.
Instead, we have circular queue!!!
The Implecation of a Linear Queue
Presets
enum Error_code{underflow, overflow, success};
const int maxqueue = 10;
typedef int Queue_entry;
Interfaces
class queue
{
public:
queue();
bool empty() const; // check whether it is empty
Error_code serve(); // get off the queue
Error_code append(const Queue_entry &item); // get into the queue
Error_code retrieve(Queue_entry &item) const; // read the front of the queue
bool full() const; // check whether it is full
int size() const; // calculate the size of the queue
void clear(); // clear the whole queue
Error_code serve_and_retrieve(Queue_entry &item);
private:
int count;
int front, rear;
Queue_entry entry[maxqueue];
};
Construct Function
queue::queue()
{
count = 0;
front = 0;
rear = maxqueue - 1;
}
Operation - empty
Code:
bool queue::empty() const
{
return !count;
}
Operation - serve
Algorithm:
- If the queue is empty, then return underflow
- Otherwise
- Decrease count
- If front pointer is greater than bound, then set it as 0
- Otherwise, increase it
Code:
Error_code queue::serve()
{
if (count <= 0)
return underflow;
count--;
front = (front + 1 == maxqueue) ? 0 : (front + 1);
return success;
}
Operation - append
Algorithm:
- If count is larger than maxqueue, return overflow
- Otherwise
- Increase count
- If rear pointer is greater than bound, then set it as 0
- Otherwise, add one to it
- Set the item
Code:
Error_code queue::append(const Queue_entry &item)
{
if (count + 1 > maxqueue)
return overflow;
count++;
rear = (rear + 1 == maxqueue) ? 0 : (rear + 1);
entry[rear] = item;
return success;
}
Operation - retrieve
Algorithm:
- If the queue is empty, return underflow
- Otherwise, return the item the front pointer is pointing to
Code:
Error_code queue::retrieve(Queue_entry &item) const
{
if (count <= 0)
return underflow;
item = entry[front];
return success;
}
Operation - full, size, clear
Code:
bool queue::full() const
{
return count == maxqueue;
}
int queue::size() const
{
return count;
}
void queue::clear()
{
count = 0;
front = 0;
rear = maxqueue - 1;
}
Queue in STL
#include <queue>- Define a queue:
queue<datatype> q - Test whether the container is empty:
q.empty() - Return size:
q.size() - Access next element:
q.front() - Access last element:
q.back() - Insert element:
q.push(item) - Construct and insert element:
q.emplace(item) - Remove next element:
q.pop() - Swap contents:
q.swap(r)
Practical Use of Queue
Demonstration
In order to test a pragramm, we can use Menu-driven demonstration program.
Airport Simulation
Chapter04 Linked Stacks and Queues
Basic Rules for Memory Allocating in C++
// take integers malloc for example
int *p; // set a pointer
p = new int; // malloc
delete p; // delete memory
p = nullptr;
// for arrays
int *p;
p = new int[<array_size>];
delete [] p;
p = nullptr;
Pointers to Structures
(*p).the_data => p->the_data
The Basics of Linked Structures
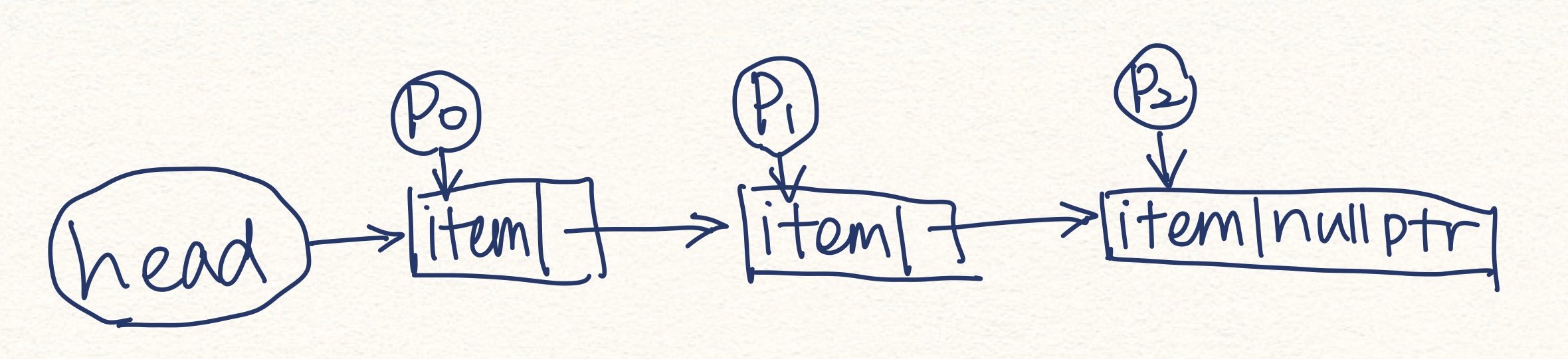
Impliment a Linked List
#include <iostream>
typedef int Node_entry;
struct Node
{
Node_entry entry;
Node *next;
Node();
Node(Node_entry item, Node* add_on = NULL);
};
Node::Node()
{
next = NULL;
}
Node::Node(Node_entry item, Node* add_on)
{
entry = item;
next = add_on;
}
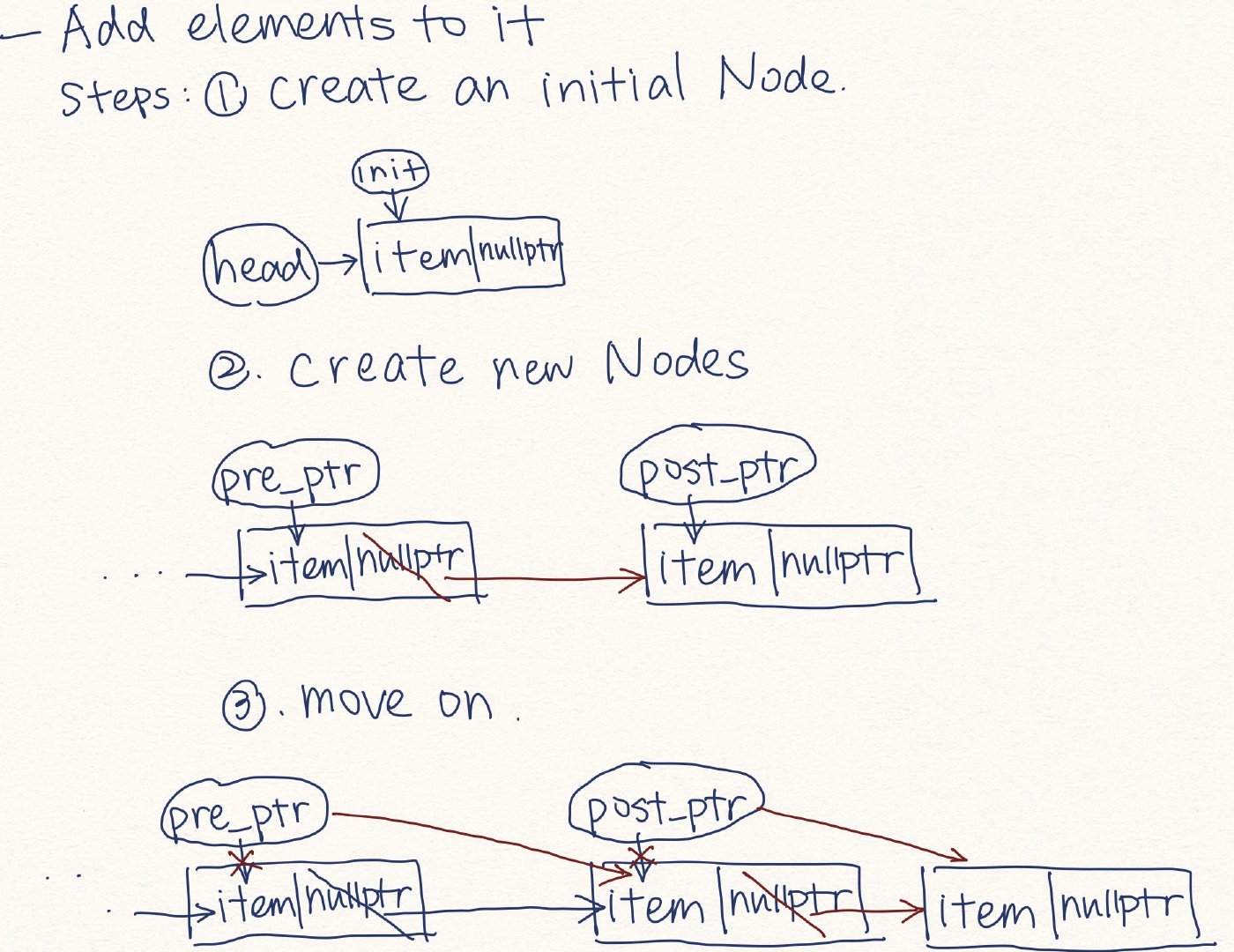
Add Elements to it
int num;
cin >> num;
Node* head = new Node(num);
Node* p = head;
while (cin >> num)
{
Node* q = p->next = new Node(num);
p = q;
}
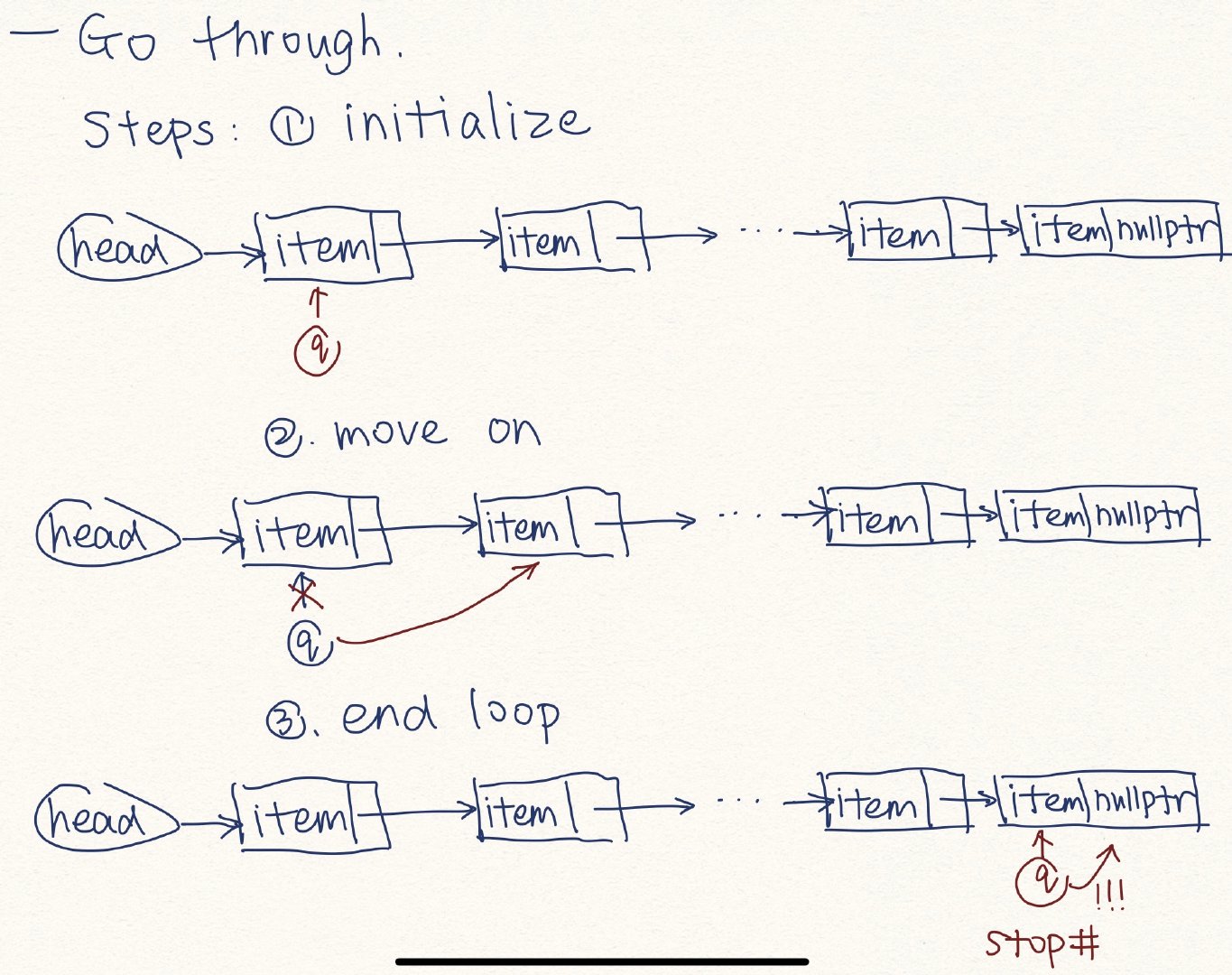
Go Through the Elements
for (Node* q = head; q != nullptr; q = q->next)
cout << q->entry << endl;
Delete Items
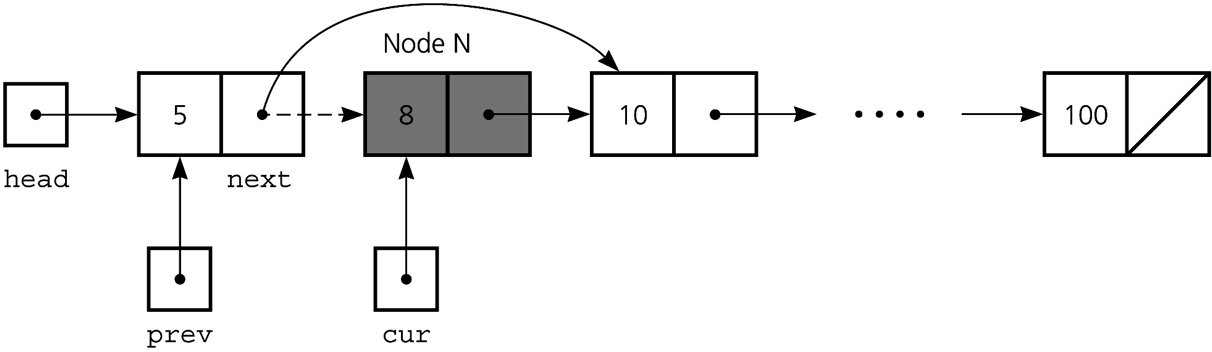
-
Delete an interior node:
prev->next = cur->next;
-
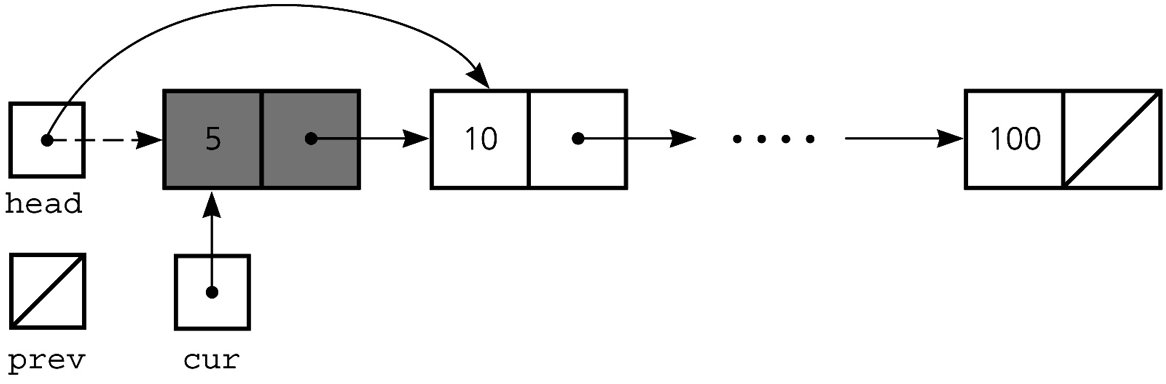
Delete the first node:
head = head->next
-
Remember to release memory:
delete cur; cur = NULL;
Insert Items
-
Insert a node between two nodes:
newPtr->next = prev->next; prev->next = newPtr;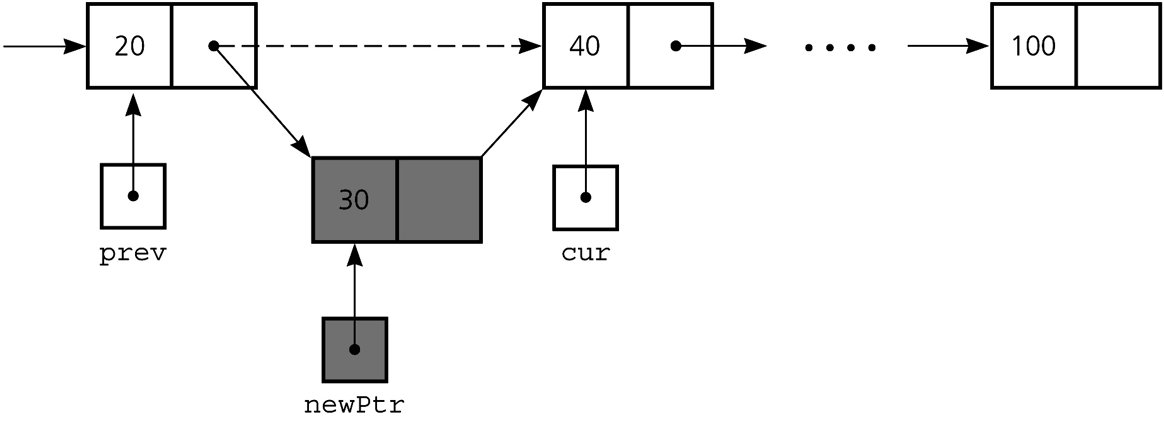
-
Insert a node at the beginning:
newPtr->next = head; head = newPtr;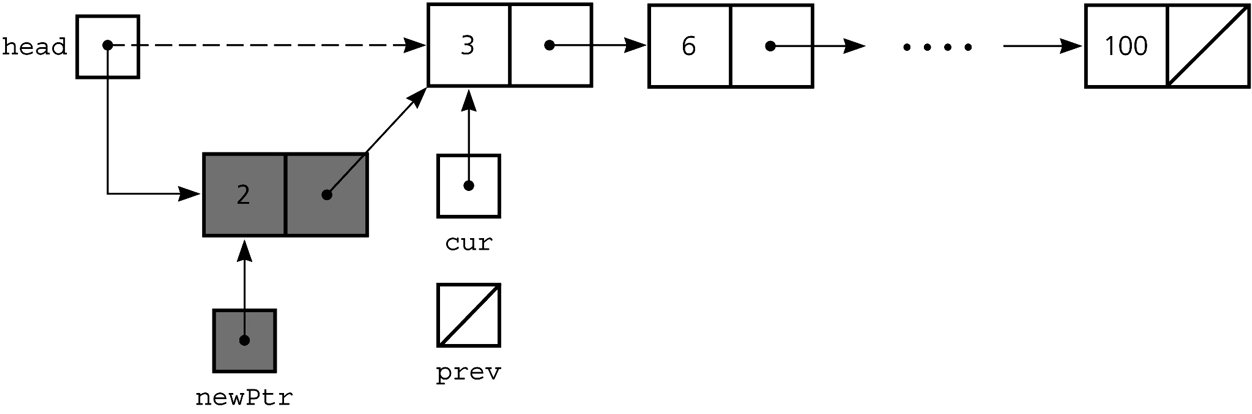
Search Items
Node* prev, *cur;
for (prev = nullptr, cur = head; (cur != nullptr) && (newValue > cur->item); prev = cur, cur = cur->next);
Linked Stacks
What is a Linked Stack?
Define: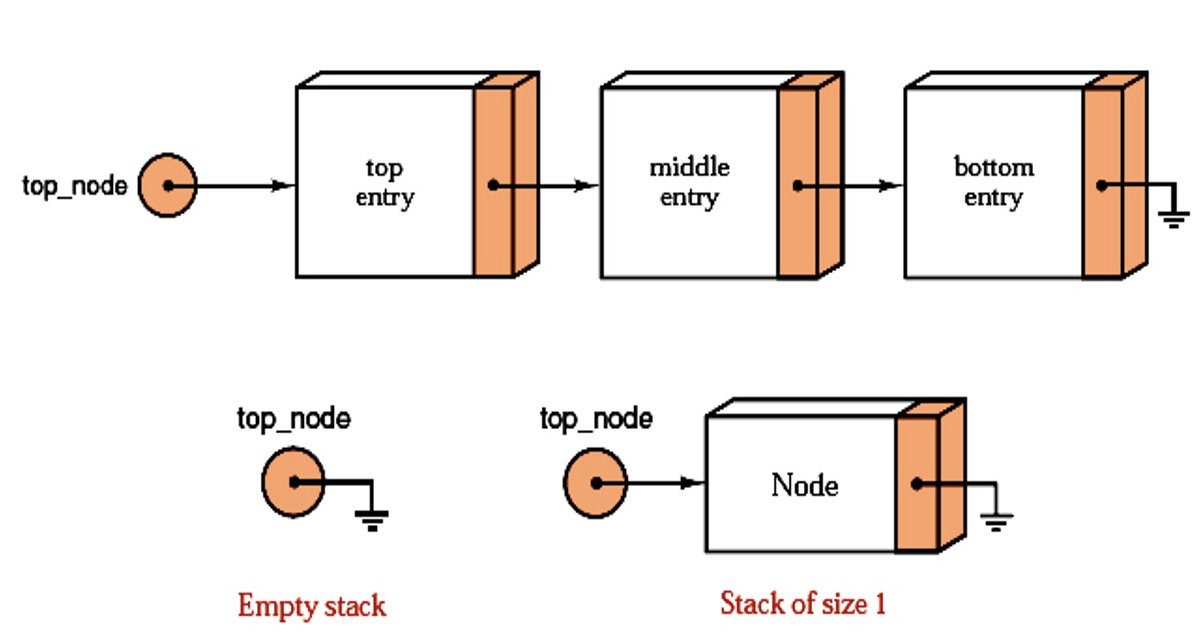
Push:
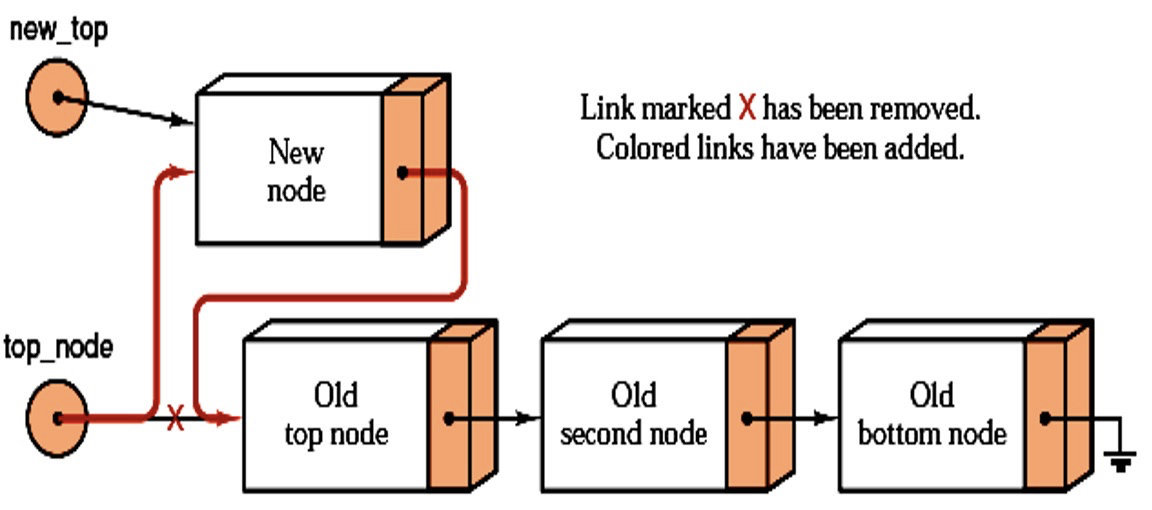
Pop:
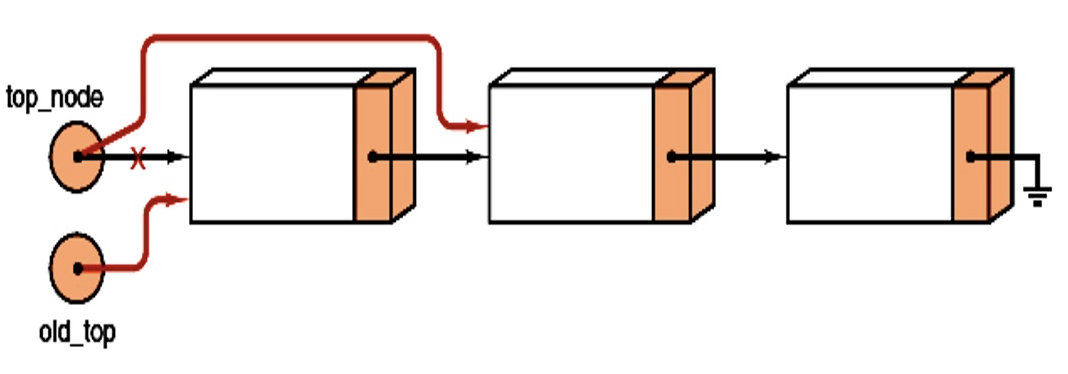
How to Implement a Linked Stack?
Preset
typedef int Node_entry;
typedef int node_entry;
enum Error_code{success, overflow, underflow};
struct Node
{
Node_entry entry;
Node *next;
Node();
Node(Node_entry item, Node* add_on = nullptr);
};
Node::Node()
{
next = nullptr;
}
Node::Node(Node_entry item, Node* add_on)
{
entry = item;
next = add_on;
}
Interfaces
class Stack
{
public:
Stack();
bool empty() const;
Error_code push(const Node_entry &item);
Error_code pop();
Error_code top(Node_entry &item) const;
~Stack(); // Safty features for linked structures
protected:
Node* top_node;
};
Constructor and Destructor
Stack::Stack()
{
top_node = nullptr;
}
Stack::~Stack()
{
while (!empty())
pop();
}
Operation - empty
Code:
bool Stack::empty() const
{
return (top_node == nullptr);
}
Operation - push
Algorithm:
newa new node- If
newreturns null, then return overflow - Otherwise, place new node at the top
Code:
Error_code Stack::push(const Node_entry &item)
{
Node* new_top = new Node(item, top_node);
if (new_top == nullptr)
return overflow;
top_node = new_top;
return success;
}
Operation - pop
Algorithm:
- If the stack is empty, return underflow
- Otherwise, move top pointer to the second item
- Delete the old item.
Code:
Error_code Stack::pop()
{
Node* old_top = top_node;
if (top_node == nullptr)
return underflow;
top_node = old_top->next;
delete old_top;
return success;
}
Operation - top
Algorithm:
- If the stack is empty, return underflow
- Otherwise, return the top element
Code:
Error_code Stack::top(Node_entry &item) const
{
if (top_node == nullptr)
return underflow;
item = top_node->entry;
return success;
}
Linked Stacks with Safeguards
Destructor
-
Often used to delete dynamically allocated objects that would otherwise become garbage.
-
Prototype:
Stack::~Stack();
Overloading the Assigning Operator
This happens when:
Stack outer_stack;
for (int i = 0; i < 1000000; i++)
{
Stack inner_stack;
inner_stack.push(some_data);
inner_stack = outer_stack;
}
Problems:
- Memory leak for
some_data outer_stackwill become a dangling pointer after first loop.
Sloution: Deep Copy !!!
class Myclass
{
protected:
int a1;
private:
int a2;
public:
Myclass();
void set(int a1, int a2);
void operator = (const Myclass &original); // Overloading the Assigning Operator
void print();
;}hi
void Myclass::operator =(const Myclass &original)
{
a1=original.a1 + 100;
a2=original.a2 + 100;
}
The Implement of Operator = in Stack
Algorithm:
- If
=is done to itself, then done - Otherwise
- remove all the original items in the stack
- If the new stack is empty, then done
- Otherwise
- copy every element from
originaltothis
- copy every element from
Code:
void Stack::operator = (const Stack &original)
{
if (this == &original)
return;
while (!empty())
pop();
Node* new_top, *new_copy, *original_node = original.top_node;
if (original_node == nullptr)
new_top = nullptr;
else
{
new_copy = new_top = new Node(original_node->entry);
while (original_node->next != nullptr)
{
original_node = original_node->next;
new_copy->next = new Node(original_node->entry);
new_copy = new_copy->next;
}
}
top_node = new_top;
}
The Copy Constructor
This happens when:
void destroy_the_stack(Stack copy)
{
}
//在此调用copy的析构函数
int main()
{
Stack vital_data;
destroy_the_stack(vital_data);
}
//在此调用vital_data的析构函数
//结果vital_data中的栈空间被两次释放
Solution:
Algorithm:
- If the stack is empty, then done
- Otherwise
- copy every element from
originaltotop_node_stack
- copy every element from
Code:
Stack::Stack(const Stack &original)
{
Node *new_copy, *original_node = original.top_node;
if (original_node == nullptr)
top_node = nullptr;
else
{
top_node = new_copy = new Node(original_node->entry);
while (original_node->next != nullptr)
{
original_node = original_node->next;
new_copy->next = new Node(original_node->entry);
new_copy = new_copy->next;
}
}
}
Linked Queues
Presets
enum Error_code {underflow, overflow, success};
typedef int Queue_entry;
typedef int Node_entry;
struct Node
{
Node_entry entry;
Node *next;
Node();
Node(Node_entry item, Node *add_on = nullptr);
};
Interfaces
class Queue
{
public:
Queue();
Queue(const Queue &original);
bool empty() const;
Error_code append(const Queue_entry& item);
Error_code serve();
Error_code retrieve(Queue_entry &item) const;
int size() const;
void clear();
void operator = (const Queue &original);
~Queue();
protected:
Node *front, *rear;
};
Constructor and Destructor
Queue::Queue()
{
front = rear = nullptr;
}
Queue::~Queue()
{
while (!empty())
serve();
}
Operation - empty
bool Queue::empty() const
{
return front == nullptr;
}
Operation - append
Algorithm:
- If heap is full, return overflow
- Otherwise
- If rear is empty, which implies that the queue is empty, then place the new_rear in the front=rear position
- Otherwise, add to the rear of the queue
Code:
Error_code Queue::append(const Queue_entry& item)
{
Node *new_rear = new Node(item);
if (new_rear == nullptr)
return overflow;
if (rear == nullptr)
front = rear = new_rear;
else
{
rear->next = new_rear;
rear = new_rear;
}
return success;
}
Operation - serve
Algorithm:
- If the queue is empty, return underflow
- Otherwise
- move front pointer to the next item
- delete old front
- If front is null, which implies that the queue is empty, then rear should also be null
Code:
Error_code Queue::serve()
{
if (front == nullptr)
return underflow;
Node *old_front = front;
front = old_front->next;
if (front == nullptr)
rear = nullptr;
delete old_front;
return success;
}
Operation - size
Algorithm:
- traverse the queue and count
Code:
int Queue::size() const
{
Node *p = front;
int count = 0;
while (p != nullptr)
{
p = p->next;
count++;
}
return count;
}
Operation - clear
Code:
int Queue::clear()
{
while (!empty())
serve();
}
Chapter05 Recursion
Introduction
Tree-Diagram Definitions
-
Root - The root of a tree has no parent
-
Leaf - A leaf of a tree has no children
-
Depth - Define depth(
<X>) of node<X>in a tree rooted at<R>to be length of path from<X>to<R>[from up to bottom (max)] -
Height - Define height(
<X>) of node<X>to be max depth of ant node in the subtree rooted at<X>[from bottom to up]
Two Parts of Recursion
- base case
- recursion step
Backtracking Algorithm
Eight Queens Problem
- Two Dimensonal Array
- Loops - Low Performance
- One Dimensional Array
- Loops - How about N-Queens Problem? -> Recursion!!!
- Recursion - Backtracking
the main structure of backtracking:
backtracking (data, ptr)
if BaseCase:
return Success
else
for i in range(X):
if noConflict:
backtracking(data, ptr--)
the solution for eight queens (in python)
#Programming for the Puzzled -- Srini Devadas
#A Profusion of Queens
#Given the dimension of a square "chess" board, call it N, find a placement
#of N queens such that no two Queens attack each other using recursive search
#This procedure initializes the board to be empty, calls the recursive N-queens
#procedure and prints the returned solution
def nQueens(size):
board = [-1] * size
rQueens(board, 0, size)
#This procedure checks that the most recently placed queen on column current
#does not conflict with queens in columns to the left.
def noConflicts(board, current):
for i in range(current):
if (board[i] == board[current]):
return False
if (current - i == abs(board[current] - board[i])):
return False
return True
#This procedure places a queens on the board on a given column so it does
#not conflict with the existing queens, and then calls itself recursively
#to place subsequent queens till the requisite number of queens are placed
def rQueens(board, current, size):
if (current == size):
print(board)
else:
for i in range(size):
board[current] = i
if (noConflicts(board, current)):
rQueens(board, current + 1, size)
a = input()
nQueens(a)
Chapter06 Lists and Strings
The Implementation of Lists (using array)
Preset
const int max_list = 300;
typedef int List_entry;
enum Error_code{underflow, range_error, overflow, success};
Interfaces
class List
{
public:
List();
int size() const;
bool full() const;
bool empty() const;
void clear();
void traverse(void (*visit)(List_entry &));
Error_code retrieve(int position, List_entry &x) const;
Error_code replace(int position, const List_entry &x);
Error_code remove(int position, List_entry &x);
Error_code insert(int position, const List_entry &x);
protected:
int count;
List_entry entry[max_list];
};
Constructor
List::List()
{
count = 0;
}
Operation - size
Code:
int List::size() const
{
return count;
}
Operation - full
Code:
bool List::full() const
{
return (count == max_list);
}
Operation - empty
Code:
bool List::empty() const
{
return (count == 0);
}
Operation - clear
Code:
void List::clear()
{
count = 0;
}
Operation - traverse
Code:
void List::traverse(void (*visit)(List_entry &))
{
for (int i = 0; i < count; i++)
(*visit)(entry[i]);
}
Operation - retrieve
Algorithm:
- If the index is over range, then return range_error
- Otherwise, get the item
Code:
Error_code List::retrieve(int position, List_entry &x) const
{
if (position < 0 || position >= count)
return range_error;
x = entry[position];
return success;
}
Operation - replace
Algorithm:
- If the index is over range, then return range_error
- Otherwise, replace the item
Code:
Error_code List::replace(int position, const List_entry &x)
{
if (position < 0 || position >= count)
return range_error;
entry[position] = x;
return success;
}
Operation - remove
Algorithm:
- If the list is empty, then return underflow
- Else if the index is over range, then return range_error
- Otherwise, use the next item to cover current item
Code:
Error_code List::remove(int position, List_entry &x)
{
if (empty())
return underflow;
if (position < 0 || position >= count)
return range_error;
x = entry[position];
for (int i = position; i < count - 1; ++i)
entry[i] = entry[i + 1];
count--;
return success;
}
Operation - insert
Algorithm:
- If the list is full, then return overflow
- Else if the index is over range, return range_error
- Otherwise, use the precessor to cover the current item
Code:
Error_code List::insert(int position, const List_entry &x)
{
if (full())
return overflow;
if (position < 0 || position > count)
return range_error;
for (int i = count - 1; i >= position; --i)
entry[i + 1] = entry[i];
entry[position] = x;
count++;
return success;
}
The time efficiency of lists (sequencial)
| List Data Structure | insert(i, x) | remove(i) | List() | clear() | empty() | full() | size() | replace(i, x) | retrieve(i) |
|---|---|---|---|---|---|---|---|---|---|
| Array | n n n | n n n | 1 1 1 | 1 1 1 | 1 1 1 | 1 1 1 | 1 1 1 | 1 1 1 | 1 1 1 |
The Implementation of Linked_Lists
Preset
typedef <#type#> Node_entry;
typedef <#type#> List_entry;
enum Error_code{underflow, range_error, overflow, success};
const int max_list = 30;
struct Node
{
Node_entry entry;
Node* next;
Node();
Node(Node_entry item, Node* add_on);
};
Node::Node()
{
next = nullptr;
}
Node::Node(Node_entry item, Node* add_on)
{
entry = item;
next = add_on;
}
Interfaces
class List
{
public:
~List();
List();
List(const List ©);
void operator = (const List ©);
int size() const;
bool full() const;
bool empty() const;
void clear();
void traverse(void (*visit)(List_entry &));
List_entry retrieve(int position) const;
List_entry replace(int position, const List_entry &x);
List_entry remove(int position);
void insert(int position, const List_entry &x);
protected:
int count;
Node* head;
Node* set_position(int position) const;
};
Constructors and Destructor
List::List()
{
count = 0;
head = nullptr;
}
List::~List()
{
List_entry x;
while (!empty())
remove(0, x);
}
Copy Functions
List::List(const List ©)
{
count = 0;
head = nullptr;
Node* q = copy.head;
int ptr = 0;
while (q != nullptr)
{
insert(ptr, q->entry);
q = q->next;
ptr++;
}
}
void List::operator = (const List ©)
{
if (this == ©)
return;
List_entry x;
while (!empty())
remove(0, x);
Node* q = copy.head;
int ptr = 0;
while (q)
{
insert(ptr, q->entry);
q = q->next; ptr++;
}
}
Operation - set_position
Code:
Node* List::set_position(int position) const
{
Node* ans = head;
for (int i = 0; i < position; ++i)
ans = ans->next;
return ans;
}
Operation - size, empty, clear, traverse
Code:
int List::size() const
{
return count;
}
bool List::empty() const
{
return (count == 0);
}
void List::clear()
{
List_entry x;
while (!empty())
remove(0, x);
}
void List::traverse(void (*visit)(List_entry &))
{
Node* p_Node = head;
while (p_Node != nullptr)
{
visit(p_Node->entry);
p_Node = p_Node->next;
}
}
Operation - full
Algorithm:
- new a new item to see wheather heap is full
Code:
bool List::full() const
{
Node* new_node;
new_node = new Node;
if (new_node == nullptr)
return true;
else
{
delete new_node;
return false;
}
}
Operation - retrieve
Code:
Error_code List::retrieve(int position, List_entry &x) const
{
if (position < 0 || position >= count)
return range_error;
Node* p_node = set_position(position);
x = p_node->entry;
return success;
}
Operation - replace
Code:
Error_code List::replace(int position, const List_entry &x)
{
if (position < 0 || position >= count)
return range_error;
Node* p_node = set_position(position);
p_node->entry = x;
return success;
}
Operation - remove
Algorithm:
- Check range
- If position is not the head node, link previous->next with current
- Otherwise, change the head pointer
- delete the item from the memory
- Decrease count
Code:
Error_code List::remove(int position, List_entry &x)
{
if (position < 0 || position >= count)
return range_error;
Node* previous, *following;
if (position > 0)
{
previous = set_position(position - 1);
following = previous->next;
previous->next = following->next;
}
else
{
following = head;
head = head->next;
}
x = following->entry;
delete following;
count--;
return success;
}
Operation - insert
Algorithm:
- Check range
- If position is the head of the list, set head as following
- Otherwise, set position-1 and position+1 as previous and following
- Create the new node
- Check heap size
- If position is the head of the list, set the new_node as the head
- Otherwise, set new_node as previous->next
- Increase count
Code:
Error_code List::insert(int position, const List_entry &x)
{
if (position < 0 || position > count)
return range_error;
Node* new_Node, *previous = nullptr, *following;
if (position > 0)
{
previous = set_position(position - 1);
following = previous + 1;
}
else
following = head;
new_Node = new Node(x, following);
if (new_Node == nullptr)
return overflow;
if (position == 0)
head = new_Node;
else
previous->next = new_Node;
count++;
return success;
}
| List Data Structure | insert(i, x) | remove(i) | List() | clear() | empty() | full() | size() | replace(i, x) | retrieve(i) |
|---|---|---|---|---|---|---|---|---|---|
| Array | n n n | n n n | 1 1 1 | 1 1 1 | 1 1 1 | 1 1 1 | 1 1 1 | 1 1 1 | 1 1 1 |
| Linked List | n n n | n n n | 1 1 1 | n n n | 1 1 1 | 1 1 1 | 1 1 1 | n n n | n n n |
The Advanced Version for Linked Lists - Doubly Linked List
Implementation
typedef int Node_entry;
typedef int List_entry;
struct Node
{
Node_entry entry;
Node* next;
Node* back;
Node();
Node(Node_entry item, Node* previous = nullptr, Node* following = nullptr);
};
Node::Node()
{
next = nullptr;
back = nullptr;
}
Node::Node(Node_entry item, Node* previous, Node* following)
{
next = following;
entry = item;
back = previous;
}
class List
{
public:
~List();
List();
List(const List ©);
void operator = (const List ©);
int size() const;
bool full() const;
bool empty() const;
void clear();
void traverse(void (*visit)(List_entry &));
List_entry retrieve(int position) const;
List_entry replace(int position, const List_entry x);
List_entry remove(int position);
void insert(int position, const List_entry x);
protected:
int count;
mutable int current_position;
mutable Node *current;
Node *head;
void set_position(int position) const;
};
void List::set_position(int position) const
{
if (current_position <= position)
for (; current_position != position; current_position++)
current = current->next;
else
for (; current_position != position; current_position--)
current = current->back;
}
void List::insert(int position, const List_entry x)
{
Node* previous, * following, * new_node;
if (position == 0)
{
if (count == 0)
following = nullptr;
else
{
set_position(0);
following = current;
}
previous = nullptr;
}
else
{
set_position(position - 1);
previous = current;
following = previous->next;
}
new_node = new Node(x, previous, following);
if (previous != nullptr)
previous->next = new_node;
if (following != nullptr)
following->back = new_node;
current = new_node;
current_position = position;
if (position == 0)
head = new_node;
count++;
}
List_entry List::remove(List_entry position)
{
Node* previous, * following; // here following is not position+1, but position itself !!!
if (position > 0)
{
set_position(position - 1);
previous = current;
following = previous->next;
previous->next = following->next;
if (following->next)
following->next->back = previous;
}
else
{
following = head;
head = head->next;
if (head)
head->back = nullptr;
current = head;
current_position = 0;
}
List_entry x = following->entry;
delete following;
count--;
return x;
}
List::~List()
{
while (!empty())
remove(0);
}
List::List()
{
count = 0;
head = nullptr;
}
List::List(const List ©)
{
count = 0;
head = nullptr;
Node* q = copy.head;
int ptr = 0;
while (q)
{
insert(ptr, q->entry);
q = q->next; ptr++;
}
}
void List::operator = (const List ©)
{
if (this == ©)
return;
while (!empty())
remove(0);
Node* q = copy.head;
int ptr = 0;
while (q)
{
insert(ptr, q->entry);
q = q->next; ptr++;
}
}
int List::size() const
{
return count;
}
bool List::full() const
{
Node* new_node;
new_node = new Node;
if (new_node == nullptr)
return true;
else
{
delete new_node;
return false;
}
}
bool List::empty() const
{
return (count == 0);
}
void List::clear()
{
while (!empty())
remove(0);
}
void List::traverse(void (*visit)(List_entry &))
{
Node* p_Node = head;
while (p_Node)
{
visit(p_Node->entry);
p_Node = p_Node->next;
}
}
List_entry List::retrieve(int position) const
{
set_position(position);
return current->entry;
}
List_entry List::replace(int position, const List_entry x)
{
set_position(position);
List_entry tmp = current->entry;
current->entry = x;
return tmp;
}
Comments on Different Data Structures
- The advantange of Linked structures:
- Dynamic storage
- Insert and delete easily and quickly
- The downsides of Linked structures:
- Extra storage space needed
- Cannot use direct access memory
How to Choose Between Different Structures
- Contiguous storage is generally preferable
- when the entries are individually very small;
- when the size of the list is known when the program is written;
- few insertions or deletions need to be made except at the end of the list;
- when random access is important.
- Linked storage proves superior
- when the entries are large;
- when the size of the list is not known in advance;
- when flexibility is needed in inserting, deleting, and rearranging the entries.
STL <lists>
-
Capacity
empty(): Test whether container is emptysize(): Return sizemax_size: Return maximum size
-
Element access
front(): Access first elementback(): Access last element
-
Modifiers:
assign(number, item): Assign new content to container (The same function as constructor)emplace_front(item): Construct and insert element at beginningpush_front(item): Insert element at beginningpop_front(): Delete first elementemplace_back(item): Construct and insert element at the endpush_back(item): Add element at the endpop_back(): Delete last elementemplace(iterators, item): Construct and insert elementinsert(position, item): Insert elementserase(position): Erase elementsswap(anotherList): Swap contentresize(size, add_on_value): Change sizeclear(): Clear content
-
Operations:
remove(item): Remove elements with specific valueremove_if(function): Remove elements fulfilling conditionunique(): Remove duplicate valuesmerge(anotherList, cmp): Merge sorted listssort(cmp): Sort elements in containerreverse(): Reverse the order of elements
-
Non-member function overloads
swap (list1, list2): Exchanges the contents of two lists
C++ String
The Implementation of Strings
class String
{
public:
String(); // defult constructor
~String(); // destructor
String(const String ©); // copy constructor
void operator = (const String ©); // operator
String(const char* copy); // conversion from C-string
String(List<char> &fromList); // conversion from List
const char* c_str() const; // conversion to C-string
protected:
char* entries;
int length;
};
bool operator == (const String &first, const String &second);
bool operator < (const String &first, const String &second);
bool operator > (const String &first, const String &second);
bool operator >= (const String &first, const String &second);
bool operator <= (const String &first, const String &second);
bool operator != (const String &first, const String &second);
String::String()
{
entries = new char[1]; // allocate new space for \0
entries[0] = '\0'; // \0
length = 0; // set length
}
String::~String()
{
delete [] entries;
}
String::String(const String ©)
{
length = copy.length;
entries = new char[length + 1];
for (int i = 0; i < length; ++i)
entries[i] = copy.entries[i];
entries[length] = '\0';
}
void String::operator = (const String ©)
{
if (*this == copy)
return;
delete [] entries;
length = copy.length;
entries = new char[length + 1];
for (int i = 0; i < length; ++i)
entries[i] = copy.entries[i];
entries[length] = '\0';
}
String::String(const char* copy)
{
length = sizeof(copy);
entries = new char[length + 1];
for (int i = 0; i < length; ++i)
entries[i] = copy[i];
entries[length] = '\0';
}
String::String(List<char> &fromList)
{
length = fromList.size();
entries = new char[length + 1];
for (int i = 0; i < length; ++i)
entries[i] = fromList.retrieve(i);
entries[length] = '\0';
}
const char* String::c_str() const
{
return (const char*) entries;
}
bool operator == (const String &first, const String &second)
{
return strcmp(first.c_str(), second.c_str()) == 0;
}
bool operator < (const String &first, const String &second)
{
return strcmp(first.c_str(), second.c_str()) < 0;
}
bool operator > (const String &first, const String &second)
{
return strcmp(first.c_str(), second.c_str()) > 0;
}
bool operator >= (const String &first, const String &second)
{
return strcmp(first.c_str(), second.c_str()) >= 0;
}
bool operator <= (const String &first, const String &second)
{
return strcmp(first.c_str(), second.c_str()) <= 0;
}
bool operator != (const String &first, const String &second)
{
return strcmp(first.c_str(), second.c_str()) != 0;
}
STL <string>
size()
Return length of string (public member function )length()
Return length of string (public member function )max_size()
Return maximum size of string (public member function )resize()
Resize string (public member function )capacity()
Return size of allocated storage (public member function )reserve(x)
Request a change in capacity (public member function )clear()
Clear string (public member function )empty()
Test if string is empty (public member function )shrink_to_fit()
Shrink to fit (public member function )operator[]
Get character of string (public member function )at(position)
Get character in string (public member function )back()
Access last character (public member function )front()
Access first character (public member function )operator+=
Append to string (public member function )append(str_to_add, begin_position, length_to_add)
Append to string (public member function )push_back(c)
Append character to string (public member function )assign(number, string_to_assign)/(string_to_assign, begin_position, length_to_assign)
Assign content to string (public member function )insert(position)
Insert into string (public member function )erase(begin_position, length)
Erase characters from string (public member function )replace(start, length, string_to_replace, start, length)
Replace portion of string (public member function )swap(anotherString)
Swap string values (public member function )pop_back()
Delete last character (public member function )c_str()
Get C string equivalent (public member function )copy(chr, length, begin_position)
Copy sequence of characters from string (public member function )find(str)/(chr)
Find content in string (public member function )rfind(str)/(chr)
Find last occurrence of content in string (public member function )find_first_of(chr, begin_position)
Find character in string (public member function )find_last_of
Find character in string from the end (public member function )find_first_not_of(chr, begin_position)
Find absence of character in string (public member function )find_last_not_of
Find non-matching character in string from the end (public member function )substr(begin_position, length)
Generate substring (public member function )compare(start, length, string_to_replace, start, length)
Compare strings (public member function )string::npos
Maximum value for size_t (public static member constant )operator+
Concatenate strings (function )relational operators
Relational operators for string (function )swap(a, b)
Exchanges the values of two strings (function )operator>>
Extract string from stream (function )operator<<
Insert string into stream (function )getline()
Get line from stream into string (function )
Chapter07 Searching
Introduction
- key: We are given a list of records, where each record is associated with one piece of information, which we shall call a key
- target: We are given one key, called the target, and are asked to search the list to find the record(s) (if any) whose key is the same as the target.
- Internal Searching: all the records are kept in high-speed memory
- External Searching: most of the records are kept in disk files
Implementation of Key Class
Key_Class_Version_1
class Key
{
public:
Key(int x = 0);
int the_key() const; // retrieve the key
private:
int key;
};
bool operator == (const Key &x, const Key &y);
Key::Key(int x)
{
key = x;
}
int the_key() const
{
return key;
}
bool operator == (const Key &x, const Key &y)
{
return x.the_key() == y.the_key();
}
Record_Class_Version_1
class Record
{
public:
operator Key();
Record(int x = 0, int y = 0);
private:
int key;
int other;
}
Record::operator Key()
{
Key tmp(key);
}
Record::Record(int x, int y)
{
key = x;
other = y;
}
Key_Class_Version_2
class Key
{
public:
Key(int x = 0);
Key(const Record &r); // use constructor to convert !!!
int the_key() const;
private:
int key;
};
bool operator == (const Key &x, const Key &y);
Key::Key(int x)
{
key = x;
}
Key::Key(const Record &r)
{
key = r.the_key();
}
int the_key() const
{
return key;
}
bool operator == (const Key &x, const Key &y)
{
return x.the_key() == y.the_key();
}
Record_Class_Version_2
class Record
{
public:
Record(int x = 0, int y = 0);
int the_key() const;
private:
int key;
int other;
}
Record::Record(int x, int y)
{
key = x;
other = y;
}
int Record::the_key() const
{
return key;
}
Sequential Search
int SequentialSearch(const List<Record> &the_list, const Key &target)
{
int len = the_list.size();
for (int position = 0; position < len; ++position)
if (the_list.retrieve(position) == target)
return position;
return -1;
}
Binary Search
- What is needed for a Binary Search: 1. Ordered; 2. Sequencial
Ordered Lists
Definition
An ordered list is a list in which each entry contains a key, such that the keys are in order. That is, if entry i comes before entry j in the list, then the key of entry i is less than or equal to the key of entry j
Implementation
# include <lnked_lists.cpp>
class Ordered_Lists: public List
{
public:
void insert(const Record &data); // overload
void insert(int position, const Record &data); // override
List_entry replace(int position, const Record &data); // override
};
void Ordered_Lists::insert(const Record &data)
{
int length = size();
int position;
for (int position = 0; position < length; ++position)
if (data < retrieve(position))
break;
List::insert(position, data);
}
void Ordered_Lists::insert(int position, const Record &data)
{
if (position > 0)
if (retrieve(position - 1) > data) // check right side
return;
if (position < size())
if (retrieve(position) < data) // check left side
return;
List::insert(position, data);
}
List_entry Ordered_Lists::replace(int position, const Record &data)
{
if (position > 0)
if (retrieve(position - 1) > data) // check right side
return;
if (position < size())
if (retrieve(position + 1) < data) // check left side
return;
entry[position] = data;
}
class Record
{
public:
Record();
Record(int x, int y = 0);
int the_key() const;
private:
int key;
int other;
};
bool operator > (const Record &x, const Record &y);
bool operator < (const Record &x, const Record &y);
ostream & operator << (ostream & output, Record &x);
Record::Record()
{
key = 0;
other = 0;
}
Record::Record(int x, int y = 0)
{
key = x;
other = y;
}
int Record::the_key() const
{
return key;
}
bool operator > (const Record &x, const Record &y)
{
return x.the_key() > y.the_key();
}
bool operator < (const Record &x, const Record &y)
{
return x.the_key() < y.the_key();
}
ostream & operator << (ostream &output, Record &x)
{
output << x.the_key();
output << endl;
return output;
}
Searching
- Initializing: set bottom and top
- Compare
- Iterate
Forgetful Version
Forget the possibility that the Key target might be found quickly and continue, whether target has been found or not, to subdivide the list until what remains has length 1 1 1.
Code:
vector<int> num;
int recursive_binary_1(int target, int begin, int end)
{
if (end > begin)
{
int mid = (begin + end) / 2;
if (target <= num[mid])
recursive_binary_1(target, begin, mid);
else
recursive_binary_1(target, mid + 1, end);
}
if (end < begin)
return -1;
if (num[end] == target)
return end;
return -1;
}
int binary_search_1(int target)
{
int begin = 0, end = num.size() - 1;
while (end > begin)
{
int mid = (begin + end) / 2;
if (target <= num[mid])
end = mid;
else
begin = mid + 1;
}
if (end < begin)
return -1;
if (num[end] == target)
return end;
return -1;
}
Recognizing Version
Examines the element in the middle of the array. If it is the sought item, stop searching.
vector<int> num;
int recursive_binary_2(int target, int begin, int end)
{
if (begin <= end)
{
int mid = (begin + end) / 2;
if (num[mid] == target)
return mid;
else if (num[mid] < target)
return recursive_binary_2(target, mid + 1, end);
else
return recursive_binary_2(target, begin, mid - 1);
}
else
return -1;
}
int binary_search_2(int target)
{
int begin = 0, end = num.size() - 1;
while (begin <= end)
{
int mid = (begin + end) / 2;
if (num[mid] == target)
return mid;
else if (num[mid] < target)
begin = mid + 1;
else
end = mid - 1;
}
return -1;
}
Time Efficiency
O ( l o g 2 n ) O(log_2n) O(log2n)
Chapter08 Sorting
Introduction
The Stability of Sorting Algorithm
After the sorting, the elements with the same key is in oritginal order.
Insertion Sort (Stable)
Example:
Sort keys: 5 , 3 , 2 , 1 , 4 , 6 5, 3, 2, 1, 4, 6 5,3,2,1,4,6
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 5 | 3 | 2 | 1 | 4 | 6 |
| 3 | 5 | 2 | 1 | 4 | 6 |
| 2 | 3 | 5 | 1 | 4 | 6 |
| 1 | 2 | 3 | 5 | 4 | 6 |
| 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | 2 | 3 | 4 | 5 | 6 |
Algorithm:
- look at the i i ith element
- If it is smaller than the previous one
- memorize the current one
- move the previous one to the current place
- loop until the current one is in the right place
Code:
void List::insertion_sort()
{
int current_position;
int position;
Record current;
for (current_position = 1; current_position < count; ++current_position)
{
if (entry[current_position - 1] > entry[current_position])
{
position = current_position;
current = entry[current_position];
do
{
entry[position] = entry[position - 1];
position--;
} while (position > 0 && entry[position - 1] > current);
entry[position] = current;
}
}
}
Efficiency:
- 每插入一个值,需要的平均比较次数为 i / 2 i / 2 i/2
- 所以比较总次数平均为 1 / 2 + 2 / 2 + . . . + ( n − 1 ) / 2 ≈ 1 / 4 n 2 1/2 + 2/2 + ... + (n - 1) / 2 \approx 1 / 4 n^2 1/2+2/2+...+(n−1)/2≈1/4n2
- 移动次数与比较次数相同
- 最好情况: n n n, n n n
- 最坏情况: 1 / 2 n 2 1/2n^2 1/2n2, 1 / 2 n 2 1/2n^2 1/2n2
Selection Sort (Not Stable)
Algorithm:
- choose the smallest / larget unsorted element, swap with the element on its position
Code:
void List::selection_sort()
{
for (int position = 0; position < count - 1; ++position) // 最后一个元素自动排好啦~
{
int min_i = min_key(position, count - 1);
swap(entry[min_i], entry[position]);
}
}
int List::min_key(int low, int high) const
{
int min_i = low;
for (int i = low + 1; i <= high; ++i) // 第一个元素不需要查找,最后一个因为上面没有包含,需要加进去
if (entry[i] < entry[min_i])
min_i = i;
return min_i;
}
Efficiency:
-
总比较次数: ( n − 1 ) + ( n − 2 ) + … + 1 ≈ 1 / 2 n 2 (n - 1) + (n - 2) + … + 1 \approx 1 / 2 n ^ 2 (n−1)+(n−2)+…+1≈1/2n2
-
总移动次数: 3 ( n − 1 ) 3(n-1) 3(n−1) (一次swap三步)
-
Selection Insertion (average) Assignment of entries 3 n + O ( 1 ) 3 n+O(1) 3n+O(1) 1 / 4 n 2 + O ( n ) 1/4n^2 + O(n) 1/4n2+O(n) Comparison of keys 1 / 2 n 2 + O ( n ) 1/2n^2 + O(n) 1/2n2+O(n) 1 / 4 n 2 + O ( n ) 1/4n^2 + O(n) 1/4n2+O(n)
Shell Sort
Example:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 3 | 2 | 9 | 6 | 8 | 25 | 10 | 16 | 19 | 12 | 7 |
| 5 | 9 | 19 | 25 | ||||||||
| 3 | 6 | 10 | 12 | ||||||||
| 2 | 7 | 8 | 16 | ||||||||
| 5 | 3 | 2 | 9 | 6 | 7 | 19 | 10 | 8 | 25 | 12 | 16 |
Algorithm:
- Set a step
- Do insertion sort
- Set a smaller step
- Do insertion sort again
- …
void List::shell_sort()
{
int increment = count;
do
{
increment = increment / 3 + 1;
for (int start = 0; start < increment; ++start)
sort_interval(start, increment);
} while (increment > 1);
}
void List::sort_interval(int start, int increment) // insertion sort
{
int current_position;
int position;
List_entry current;
for (current_position = start + increment; current_position < count; current_position += increment)
{
if (entry[current_position - increment] > entry[current_position])
{
position = current_position;
current = entry[current_position];
do
{
entry[position] = entry[position - increment];
position -= increment;
} while (position > start && entry[position - increment] > current);
entry[position] = current;
}
}
}
Merge Sort
Example:
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 4 | 2 | 8 | 9 | 5 | 0 |
| 4 | 2 | 8 | 9 | 5 | 0 |
| 2 | 4 | 8 | 5 | 9 | 0 |
| 2 | 4 | 8 | 0 | 5 | 9 |
| 0 | 2 | 4 | 5 | 8 | 9 |
Algorithm:
- Divide
- Iterate
- Combine
Code:
For sequencial list:
// teacher's example
void Mergesort(Sortable_list & mylist)
{
Sortable_list secondlist;
if (mylist.size() > 1)
{
divide_from(mylist, secondlist);
Mergesort(mylist);
Mergesort(secondlist);
combine(mylist, secondlist);
}
}
void divide_from(Sortable_list & mylist, Sortable_list & secondlist)
{
int mid = (mylist.size() - 1) / 2; //分割点的坐标
int secondsize = mylist.size() - (mid + 1); //子序列二的长度(中间的在右半边)
for (int i = 0; i < secondsize; i++)
{
Record x;
if (mylist.retrieve(mid + 1, x) == success)
{
secondlist.insert(i, x);
mylist.remove(mid + 1, x); //在原序列中删除该节点
}
}
}
void combine(Sortable_list & firstsortlist, const Sortable_list & secondsortlist)
{
Sortable_list tmp;
int m = 0, n = 0, i = 0; //m为第一个列表的下标,n为第二个列表的下标
while (m < firstsortlist.size() && n<secondsortlist.size())
{
Record x, y;
firstsortlist.retrieve(m, x);
secondsortlist.retrieve(n, y);
if (x <= y)
{
tmp.insert(i++, x); //i为合并后列表的下标
m++;
}
else
{
tmp.insert(i++, y);
n++;
}
}
while (m < firstsortlist.size())
{
Record x;
firstsortlist.retrieve(m, x);
tmp.insert(i++, x);
m++;
}
while (n < secondsortlist.size())
{
Record y;
secondsortlist.retrieve(n, y);
tmp.insert(i++, y);
n++;
}
firstsortlist = tmp;
}
// my algorithm:
void List::merge_sort()
{
MergeSort(entry, count, 0, count);
}
void List::MergeSort(List_entry* a, int len, int start, int end)
{
if (1 < end - start)
{
int mid = (start + end + 1) / 2;
MergeSort(a, mid - start, start, mid);
MergeSort(a, end - mid, mid, end);
int l, r;
List L, R;
for (l = 0; l < mid - start; ++l)
L.insert(l, a[start + l]);
for (r = 0; r < end - mid; ++r)
R.insert(r, a[mid + r]);
l = 0; r = 0;
while (start < end)
{
if ((r >= R.size()) || (l < L.size() && L.retrieve(l).the_key() < R.retrieve(r).the_key()))
{
a[start] = L.retrieve(l);
l++;
}
else
{
a[start] = R.retrieve(r);
r++;
}
start++;
}
}
}
Downsides: storage
For linked list:
void List::merge_sort()
{
recursive_merge_sort(head);
}
void List::recursive_merge_sort(Node* &sub_list)
{
if (sub_list != nullptr && sub_list->next != nullptr) // more than one element
{
Node* second_list = divide_from(sub_list);
recursive_merge_sort(sub_list);
recursive_merge_sort(second_list);
sub_list = merge(sub_list, second_list);
}
}
Node* List::divide_from(Node* sub_List)
{
Node* position, *midpoint = sub_List, *second_list;
if (midpoint == nullptr)
return nullptr;
position = midpoint->next;
while (position != nullptr)
{
position = position->next;
if (position != nullptr)
{
midpoint = midpoint->next;
position = position->next;
}
}
second_list = midpoint->next;
midpoint->next = nullptr;
return second_list;
}
Node* List::merge(Node* L, Node* R) // chaining
{
Node* last_sorted;
Node merged;
last_sorted = &merged;
while (L != nullptr && R != nullptr)
{
if (L->entry <= R->entry)
{
last_sorted->next = L; // chain
last_sorted = L; // relocate
L = L->next; // move on
}
else
{
last_sorted->next = R;
last_sorted = R;
R = R->next;
}
}
if (L == nullptr)
last_sorted->next = R;
else
last_sorted->next = L;
return merged.next;
}
Efficiency: O ( n ) = n l o g n O(n) = nlogn O(n)=nlogn
Quick Sort
Example:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 66 | 30 | 35 | 29 | 19 | 32 | 35 |
| 29 | 30 | 35 | 66 | 19 | 32 | 35 |
| 29 | 19 | 35 | 66 | 30 | 32 | 35 |
| 19 | 29 | 35 | 66 | 30 | 32 | 35 |
| √ | √ | 35 | 66 | 30 | 32 | 35 |
| √ | √ | 30 | 66 | 35 | 32 | 35 |
| √ | √ | √ | 66 | 35 | 32 | 35 |
| √ | √ | √ | 35 | 66 | 32 | 35 |
| √ | √ | √ | 35 | 32 | 66 | 35 |
| √ | √ | √ | 32 | 35 | 66 | 35 |
| √ | √ | √ | √ | √ | 66 | 35 |
| √ | √ | √ | √ | √ | 66 | 35 |
| √ | √ | √ | √ | √ | 35 | 66 |
| 19 | 29 | 30 | 32 | 35 | 35 | 66 |
Algorithm: Keep every elements smaller than pivot on its left, bigger on the right.
- Set one number (middle number) as the pivot;
- Swap pivot to the head of the list;
- Traverse every element after pivot and exchage to the front
- swap pivot to the bi-partition place
- Iterate
Code:
void List::quick_sort()
{
recursive_quick_sort(0, count - 1);
}
void List::recursive_quick_sort(int low, int high)
{
int pivot_position;
if (low < high)
{
pivot_position = partition(low, high);
recursive_quick_sort(low, pivot_position - 1);
recursive_quick_sort(pivot_position + 1, high);
}
}
int List::partition(int low, int high)
{
Record pivot;
int last_small = low;;
swap(entry[low], entry[(low + high) / 2]); // 偶数个元素取左侧
pivot = entry[low];
for (int i = low + 1; i <= high; ++i)
{
if (entry[i] < pivot)
{
last_small++;
swap(entry[last_small], entry[i]);
}
}
swap(entry[low], entry[last_small]);
return last_small;
}
Efficiency: O ( n ) = n l o g n O(n) = nlogn O(n)=nlogn
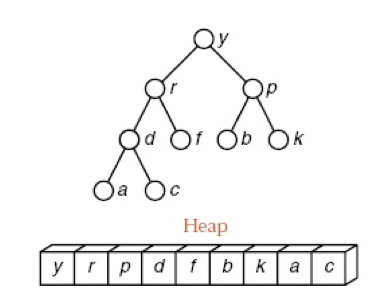
Heap Sort
What is a Heap:
Def. A heap is a list in which each entry contains a key, and, for all positions k in the list, the key at position k is at least as large as the keys in positions 2 k + 1 2k+1 2k+1 and 2 k + 2 2k + 2 2k+2, provided these positions exist in the list.
Heap Example:
Algorithm:
- Initialize the list into a heap
- Store the last element into a temp variable, and then put the head of the heap into the last place
- Insert the temp variable into the heap
- Loop
Code:
void List::heap_sort()
{
build_heap();
for (int last_unsorted = count - 1; last_unsorted > 0; --last_unsorted)
{
List_entry current = entry[last_unsorted]; // record the last deleted element (make space for the last sorted element)
entry[last_unsorted] = entry[0];
insert_heap(current, 0, last_unsorted - 1); // compete the biggest and place current
}
}
void List::build_heap()
{
for (int low = count / 2 - 1; low >= 0; --low) // from the second last level of the tree,奇数个指向靠左侧
{
List_entry current = entry[low];
insert_heap(current, low, count - 1);
}
}
void List::insert_heap(const List_entry ¤t, int low, int high)
{
int large = low * 2 + 1;
while (large <= high)
{
if (large + 1 <= high && entry[large] < entry[large + 1])
large++; // choose larger element
if (current >= entry[large])
break; // the right place for it
else
{
entry[low] = entry[large];
low = large;
large = 2 * low + 1;
}
}
entry[low] = current;
}
❓ Time Efficiency Analysis for Sorting Algorithms
Chapter09 Tables
Introduction
What is a table?
- It is an abstract data structure
- It stores elements just like a list
- The retrieve operation for a table only needs constant time ( O ( 1 ) O(1) O(1))
For Arrays
-
One Dimensional Array
- For
a[n], L O C ( i ) = a + i ∗ l LOC(i) = a + i * l LOC(i)=a+i∗l (l == sizeof(a[0]))
- For
-
Two Dimensional Array
- For
a[n][m], L O C ( i , k ) = a + ( j ∗ m + k ) ∗ l LOC(i, k) = a + (j*m + k) * l LOC(i,k)=a+(j∗m+k)∗l (l == sizeof(a[0][0]))
- For
-
Soecial Two Dimensional Array
-
Lower triangular matrix
-
a 0 , 0 0 ⋯ 0 0 a 1 , 0 a 1 , 1 ⋯ 0 0 ⋮ ⋮ ⋱ ⋮ ⋮ a n − 2 , 0 a n − 2 , 1 ⋯ a n − 2 , n − 2 0 a n − 1 , 0 a n − 1 , 1 ⋯ a n − 1 , n − 2 a n − 1 , n − 1 \begin{matrix} a_{0,0} & 0 & \cdots & 0 & 0 \\ a_{1,0} & a_{1,1} & \cdots & 0 & 0 \\ \vdots & \vdots & \ddots &\vdots &\vdots \\ a_{n-2,0} & a_{n-2,1} & \cdots & a_{n-2, n-2} & 0 \\ a_{n-1,0} & a_{n-1,1} & \cdots & a_{n-1, n-2} & a_{n-1, n-1} \end{matrix} a0,0a1,0⋮an−2,0an−1,00a1,1⋮an−2,1an−1,1⋯⋯⋱⋯⋯00⋮an−2,n−2an−1,n−200⋮0an−1,n−1
-
L O C ( i , j ) = a + ( i × ( i + 1 ) ÷ 2 + j ) ∗ l LOC(i, j) = a + (i \times (i+1) \div 2 + j) * l LOC(i,j)=a+(i×(i+1)÷2+j)∗l
-
-
Strictly upper triangular matrix
-
a 0 , 0 a 0 , 1 ⋯ a 0 , n − 2 a 0 , n − 1 0 a 1 , 1 ⋯ a 1 , n − 2 a 1 , n − 1 ⋮ ⋮ ⋱ ⋮ ⋮ 0 0 ⋯ a n − 2 , n − 2 a n − 2 , n − 1 0 0 ⋯ 0 a n − 1 , n − 1 \begin{matrix} a_{0, 0} & a_{0,1} & \cdots & a_{0, n-2} & a_{0, n-1} \\ 0 & a_{1,1} & \cdots & a_{1, n-2} & a_{1, n-1} \\ \vdots & \vdots & \ddots &\vdots &\vdots \\ 0 & 0 & \cdots & a_{n-2, n-2} & a_{n-2, n-1} \\ 0 & 0 & \cdots & 0 & a_{n-1, n-1} \end{matrix} a0,00⋮00a0,1a1,1⋮00⋯⋯⋱⋯⋯a0,n−2a1,n−2⋮an−2,n−20a0,n−1a1,n−1⋮an−2,n−1an−1,n−1
-
L O C ( i , j ) = a + ( ( j − i ) + ( n + [ n − ( i − 1 ) ] ) × i ÷ 2 ) ∗ l = a + ( j − i + 1 / 2 × i × ( 2 n − i + 1 ) ) ∗ l LOC(i, j) = a + ((j - i) + (n + [n-(i - 1)]) \times i \div 2)*l\\ =a + (j - i + 1/2 \times i \times (2n-i+1)) * l LOC(i,j)=a+((j−i)+(n+[n−(i−1)])×i÷2)∗l=a+(j−i+1/2×i×(2n−i+1))∗l
-
-
Jagged Array
- We add an accesss array to record the index of the begging element of a line

- We add an accesss array to record the index of the begging element of a line
-
Inverted Tables
- We add an access table to record the sorting of each key

- We add an access table to record the sorting of each key
-
Radix Sort
-
基数排序的思想:
-
假设待排序的集合有 n n n个记录 F = ( R 0 , R 1 , … R n − 1 ) F=(R0,R1,…Rn-1) F=(R0,R1,…Rn−1),记录 R i Ri Ri的排序码 k i k_i ki含有 d d d部分 ( k i 0 , k i 1 , … , k i d − 1 ) (k_{i_0}, k_{i_1},…, k_{i_{d-1}}) (ki0,ki1,…,kid−1),
-
N N N个记录对排序码有序是指∶任意两个记录 R i R_i Ri和 R j ( 0 ≤ i ≤ j ≤ n − 1 ) R_j(0≤i≤j≤n-1) Rj(0≤i≤j≤n−1)满足词典次序有序关系: ( k i 0 , k i 1 , … , k i d − 1 ) < ( k j 0 , k j 1 , … , k j d − 1 ) (k_{i_0}, k_{i_1},…, k_{i_{d-1}}) < (k_{j_0}, k_{j_1},…, k_{j_{d-1}}) (ki0,ki1,…,kid−1)<(kj0,kj1,…,kjd−1)
-
其中 k 0 k_0 k0称为最高位排序码, k d − 1 k_{d-1} kd−1称为最低位排序码。
-
-
Algorithms:
-
第一种是高位优先法:先对最高位排序码 k 0 k_0 k0排序,将所有记录分成若干堆,每堆中的记录都具有相同的 k 0 k_0 k0,然后分别就每堆对排序码 k 1 k_1 k1排序,分成若干子堆,如此重复,直到对 k d − 1 k_{d-1} kd−1排序,最后将各堆按次序叠在一起成为一个有序序列。
第二种是低位优先法:从最低位排序码 k d − 1 k_{d-1} kd−1起排序,然后再对高一位排序码 k d − 2 k_{d-2} kd−2排序,如此重复,直到对 K 0 K_0 K0排序后便成为一个有序序列。 -
An Example:
0 1 2 3 4 5 6 7 8 9 36 5 16 98 95 47 32 36 48 10 Radix Element1 Element2 Element3 0 10 1 2 32 3 4 5 5 95 6 36 16 36 7 47 8 98 48 9 0 1 2 3 4 5 6 7 8 9 10 32 05 95 36 16 36 47 98 48 Radix Element1 Element2 Element3 0 05 1 10 16 2 3 32 36 36 4 5 47 48 6 7 8 9 95 98 0 1 2 3 4 5 6 7 8 9 5 10 16 32 36 36 47 48 95 98 const int key_size = 10; class Key { char str[key_size]; public: Key (char s[]); char* the_key() const; }; Key::Key(char s[]) { for(int i = 0; i <= strlen(s); i++) str[i] = s[i]; } char* Key::the_key() const { return (char *)str; } class Record { public: operator Key(); // implicit conversion from Record to Key . Record(char s[] = ""); char * the_key() const; char key_letter(int position) const; // get the specific letter of a specific position private: char str[key_size]; }; ostream & operator << (ostream &output, Record &x); { output << x.the_key(); return output; } Record::Record(char s[]) { for(int i = 0; i <= strlen(s); i++) str[i] = s[i]; } Record::operator Key() { Key tmp(str); } char Record::key_letter(int position) const // special function for radix sort { if (position < strlen(str)) return str[position]; else return '\0'; // align } char * Record::the_key() const { return (char *)str; }Code:
void Sortable_list::radix_sort() { Record data; MyQueue<Record> queues[max_chars]; // build a set of heaps for (int position = key_size - 1; position >= 0; position--) // Loop from the least to the most significant position. { while (remove(0, data) == success) { int queue_number = alphabetic_order(data.key_letter(position)); queues[queue_number].append(data); // Queue operation. } rethread(queues); // Reassemble the list. } } int alphabetic_order(char c) // from char to int: 'a' -> 1 { if (c == ' ' || c == '\0') // align character return 0; if ('a' <= c && c <= 'z') return c - 'a' + 1; if ('A' <= c && c <= 'Z') return c - 'A' + 1; return 27; } void Sortable_list::rethread(MyQueue<Record> queues[]) { Record data; for (int i = 0; i < max_chars; i++) { while (!queues[i].empty()) { queues[i].retrieve(data); insert(size(), data); queues[i].serve(); } } }
-
Hashing
Hashing Functions
- Truncation (Direct Hashing)
- fast
- can not distribute keys evenly
- Folding (Matrix Ways)
- spread more evenly than truncation
- Modular Arithmetic
- H ( k e y ) = k e y m o d m Η(key)=key\ mod\ m H(key)=key mod m
- m m m is a prime number which is close to the numbers of keys
- Random Hashing Functions
- Universal Hashing
But, when two keys maps to the same place in the hashing function, it is called collide.
To solve collide, we use Open Addressing or Chaining
Open Addressing
- Linear Probing
- Increment Functions
- Quadratic Probing
- …
Preset & Operation - clear
Code:
int hashing(const Record &new_entry)
{
return new_entry.the_key() % hash_size;
}
int hashing(const Key &new_entry)
{
return new_entry.the_key() % hash_size;
}
void Hash_table::clear()
{
for (int i = 0; i < hash_size; ++i)
{
Record tmp;
table[i] = tmp;
}
}
Operation - insert
Algorithm:
- Calculate the result of the hashing function
- If the key already exists, then duplicate error
- Otherwise, check whether the current place is empty
- If empty, put the element there
- Otherwise, calculate the next place to put and loop (0 for empty, -1 for deleted)
Code:
Error_code Hash_table::insert(const Record &new_entry)
{
Error_code result = success;
int probe_count = 0, // check whether it is full
increment = 1, // increment used for quadratic probing
probe = hashing(new_entry); // position currently probed in the hashing table
if (retrieve(Record(new_entry), (Record&)new_entry) == success)
return duplicate_error;
while (table[probe] != 0 // check for empty-0
&& table[probe] != -1 // check for empty--1
&& probe_count < (hash_size + 1) / 2) // check for overflow
{
probe_count++;
probe = (probe + increment) % hash_size;
increment += 2;
}
if (table[probe] == 0)
table[probe] = new_entry;
else if (table[probe] == -1)
table[probe] = new_entry;
else
result = overflow;
return result;
}
Operation - retrieve
Algorithm:
- Calculate the result of the hashing function
- check whether the current element is the target
- If is, complete
- Otherwise, calculate the next possible position
Code:
Error_code Hash_table::retrieve(const Key &target, Record &found) const
{
int probe_count = 0, // go through the whole list
increment = 1, // increment used for quadratic probing
prob = hashing(target); // position currently probed in the hashing table
while (table[prob] != 0 // empty?
&& table[prob].the_key() != target.the_key() // not found
&& probe_count < (hash_size + 1) / 2) // the whole list
{
probe_count++;
prob = (prob + increment) % hash_size;
increment += 2;
}
if (table[prob].the_key() == target.the_key())
{
found = table[prob];
return success;
}
return not_presented;
}
Oeration - remove
Algorithm:
The same as retrieve.
Code:
Error_code Hash_table::remove(const Key &target, Record &found) // 一般情况与n无关,时间复杂度O(1),
{
int probe_count = 0, // go through the whole list
increment = 1, // increment used for quadratic probing
prob = hashing(target); // position currently probed in the hashing table
while (table[prob] != 0 // empty?
&& table[prob].the_key() != target.the_key() // not found
&& probe_count < (hash_size + 1) / 2) // the whole list
{
probe_count++;
prob = (prob + increment) % hash_size;
increment += 2;
}
if (table[prob].the_key() == target.the_key())
{
found = table[prob];
table[prob] = -1;
return success;
}
return not_presented;
}
Chaining
const int hash_size = 97;
class Hash_table {
public:
void clear();
Error_code insert(const Record &new_entry);
Error_code retrieve(const Key &target, Record &found) const;
Error_code remove(const Key &target, Record &found);
private:
List<Record> table[hash_size]; // every element of the table is in a list of index H(key)
};
int hash(const Record &new_entry)
{
return new_entry.the_key() % hash_size;
}
int hash(const Key &new_entry)
{
return new_entry.the_key() % hash_size;
}
void Hash_table::clear()
{
for (int i = 0; i < hash_size; i++)
table[i].clear();
}
Error_code Hash_table::insert(const Record &new_entry)
{
int probe = hash(new_entry);
for (int i = 0; i < table[probe].size(); i++) // check duplicate situations
{
Record tmp;
table[probe].retrieve(i,tmp);
if (tmp == new_entry)
return duplicate_error;
}
table[probe].insert(0, new_entry);
return success;
}
Error_code Hash_table::retrieve(const Key &target, Record &found) const
{
int probe = hash(target);
for (int i = 0; i < table[probe].size(); i++)
{
Record tmp;
table[probe].retrieve(i, tmp);
if (target == tmp)
{
found = tmp;
return success;
}
}
return not_present;
}
Error_code Hash_table::remove(const Key &target, Record &found)
{
int probe = hash(target);
for (int i = 0; i < table[probe].size(); i++)
{
Record tmp;
table[probe].retrieve(i, tmp);
if (target == tmp)
{
table[probe].remove(i, found);
return success;
}
}
return not_present;
}
Load Factors
For open addressing, the maximum factor is 1 1 1. For chaining, there is no limit.
Chapter10 Binary Tree
Binary Trees
Terminology
Root: node without parent
Siblings: nodes share the same parent
Internal node: node with at least one child
External node (leaf ): node without children
Ancestors of a node: parent, grandparent, grand-grandparent, etc.
Descendant of a node: child, grandchild, grand-grandchild, etc.
Depth of a node: number of ancestors
Height of a tree: maximum depth of any node
Degree of a node: the number of its children
Degree of a tree: the maximum number of its node.
Subtree
Definitions
Def:
A binary tree is either empty, or it consists of a node called the root together with two binary trees called the left subtree and the right subtree of the root.
So there are five different types of binary trees:
1> ø;
2> root with no children
3> root with left subtree
4> root with right subtree
5> root with left & right subtree
Full Binary Tree: if the depth of a full binary tree is k k k, then there are 2 k + 1 − 1 2^{k+1}-1 2k+1−1 nodes
Complete Binary Tree: if the depth of a complete binary tree is k k k, then there are 2 k − 1 < n ≤ 2 k + 1 − 1 2^{k} - 1 < n \le 2^{k+1} - 1 2k−1<n≤2k+1−1 nodes, if there are n n n nodes, the depth is k = ⌊ l o g 2 n ⌋ k = \lfloor log_2n \rfloor k=⌊log2n⌋
Travesal of Binary Trees
With preorder traversal we first visit a node, then traverse its left subtree, and then traverse its right subtree.
With inorder traversal we first traverse the left subtree, then visit the node, and then traverse its right subtree.
With postorder traversal we first traverse the left subtree, then traverse the right subtree, and finally visit the node.
How to recover a tree from a traversal order?
Inorder + preorder / postorder
Linked Implement of Complete Binary Trees
Operation - Traverse
Algorithm:
- If the subnode is empty, then return.
- Otherwise, use iterations to traverse
Code:
template <class Entry>
void Binary_tree<Entry>::preorder(void (*visit)(Entry &))
{
recursive_preorder(root, visit);
}
template <class Entry>
void Binary_tree<Entry>::recursive_preorder(Binary_node<Entry>* sub_root, void (*visit)(Entry &))
{
if (sub_root != nullptr)
{
(*visit)(sub_root->data);
recursive_preorder(sub_root->left, visit);
recursive_preorder(sub_root->right, visit);
}
}
Operation - Height
Code:
template <class Entry>
int Binary_tree<Entry>::height() const
{
int count = size();
if (count == 0)
return -1;
int tmp = 1;
int k;
for (k = 0; tmp <= count; ++k)
tmp *= 2;
return k - 1;
}
template <class Entry>
int Binary_tree<Entry>::height() const
{
return recur_height(root);
}
template <class Entry>
int Binary_tree<Entry>::recur_height(Binary_node<Entry> *subroot) const
{
if (subroot == nullptr)
return 0;
return max(recur_height(subroot->left), recur_height(subroot->right)) + 1;
}
Operation - Insertion
Algorithm:
- If the tree is empty, then create a new root node and return
- Otherwise
- Get the position of the current node which is
size() - Use a stack to store the route from the root to the current node
- Pop the items from the stack and follow the route to the current node
- Get the position of the current node which is
template<class Entry>
void Binary_tree<Entry>::insert(Entry &x)
{
if (empty())
{
root = new Binary_node<Entry>(x);
count++;
return;
}
stack<int> numbers;
int tmp_cnt = size();
while (tmp_cnt > 0)
{
if (tmp_cnt % 2 == 0) // right
numbers.emplace(1);
else // left
numbers.emplace(-1);
tmp_cnt = (tmp_cnt - 1) / 2;
}
Binary_node<Entry> *current = root;
while (numbers.size() > 1)
{
if (numbers.top() == -1)
current = current->left;
else
current = current->right;
numbers.pop();
}
if (numbers.top() == -1)
current->left = new Binary_node<Entry>(x);
else
current->right = new Binary_node<Entry>(x);
count++;
}
Binary Search Tree
Definition: It is sorted by inorder traversal.
Implement of BST
Operation - search
Algorithm(for search_for_node():
- If the subroot is empty or subroot is already the target, then return
- Otherwise, if the subroot is smaller than the target, go to the right subtree, otherwise, go to the left subtree
Code:
Error_code Search_tree<Record>::tree_search(Record &target) const
{
Error_code result = success;
Binary_node<Record> *found = search_for_node(root, target);
if (found == nullptr)
result = not_present;
else
target = found->data;
return result;
}
// recursive version
Binary_node<Record> *Search_tree<Record>::search_for_node(Binary_node<Record>* sub_root, const Record &target) const
{
if (sub_root == nullptr || sub_root->data == target)
return sub_root;
else if (sub_root->data < target)
return search_for_node(sub_root->right, target);
else
return search_for_node(sub_root->left, target);
}
// nonrecursive version
Binary_node<Record> *Search_tree<Record>::search_for_node(Binary_node<Record>* sub_root, const Record &target) const
{
while (sub_root != NULL && sub_root->data != target)
{
if (sub_root->data < target)
sub_root = sub_root->right;
else
sub_root = sub_root->left;
}
return sub_root;
}
Operation - insertion
Algorithm (for search_and_insert()):
- If the subroot is empty, then it is the place for us to insert the node
- Else if the subroot is bigger than the new_data, go to the left subroot
- Else if the subroot is smaller than the new_data, go to the right subroot
- Otherwise, return error
Code:
Error_code Search_tree<Record>::insert(const Record &new_data)
{
Error_code result = search_and_insert(Binary_tree<Record>::root, new_data);
if (result == success)
Binary_tree<Record>::count++;
return result;
}
Error_code Search_tree<Record>::search_and_insert(Binary_node<Record>* &sub_root, const Record &new_data)
{
if (sub_root == nullptr)
{
sub_root = new Binary_node<Record>(new_data);
return success;
}
else if (new_data < sub_root->data)
return search_and_insert(sub_root->left, new_data);
else if (new_data > sub_root->data)
return search_and_insert(sub_root->right, new_data);
else
return error;
}
Operation - remove
Algorithm:
- If the node is a leaf, remove it by
nullptr - Else if the node only has one nonempty subnode, link the node’s parent with the subtree
- Otherwise
- find the one which is before the vertex in-traversal order (the rightest child in the left-subtree)
- replace the subroot with that node
- deal with the left subtree of that node
- If there is only one node in the left subnode of subroot, link subroot with the left subtree of that node
- Otherwise link parent with the left subtree of that node
Code:
template <class Record>
Error_code Search_tree<Record>::remove(const Record &target)
{
Error_code result = search_and_destroy(Binary_tree<Record>::root, target);
if (result == success)
Binary_tree<Record>::count--;
return result;
}
template <class Record>
Error_code Search_tree<Record>::search_and_destroy(Binary_node<Record>* &sub_root, const Record &target)
{
if (sub_root == nullptr || sub_root->data == target)
return remove_root(sub_root);
else if (target < sub_root->data)
return search_and_destroy(sub_root->left, target);
else
return search_and_destroy(sub_root->right, target);
}
template <class Record>
Error_code Search_tree<Record>::remove_root(Binary_node<Record>* &sub_root)
{
if (sub_root == nullptr) // no subnode
return not_present;
Binary_node<Record>* to_delete = sub_root;
if (sub_root->right == nullptr) // only one left subnode
sub_root = sub_root->left;
else if (sub_root->left == nullptr) // only one right subnode
sub_root = sub_root->right;
else // with two subnodes
{
to_delete = sub_root->left;
Binary_node<Record>* parent = sub_root;
while (to_delete->right != nullptr) // go to the right most node of the left subtree
{
parent = to_delete;
to_delete = to_delete->right;
}
sub_root->data = to_delete->data; // replace
if (parent == sub_root) // there is only one node in the left subnode of subroot
sub_root->left = to_delete->left;
else
parent->right = to_delete->left;
}
delete to_delete;
return success;
}
Balanced BST
Algorithm:
We first name all the elements in sorted order. Then for index x x x, we use x % 2 k = 0 x\%2^k = 0 x%2k=0 to calculate its depth in the tree.
-
If k = 0 k=0 k=0, then it is a leaf.
-
If it’s not a leaf, find the last node in depth k − 1 k-1 k−1 as its left child.
-
If k + 1 k+1 k+1 exists, then link it.
-
We use a list to record the last nodes of every level
Preset
class Buildable_tree: public Search_tree<Record>
{
public:
Error_code build_tree(const List<Record> &supply);
private:
void build_insert(int count, const Record &new_data, List<Binary_node<Record>*> & last_node);
Binary_node<Record> *find_root(List<Binary_node<Record>*> &last_node);
void connect_trees(const List<Binary_node<Record>*> &last_node);
};
Operation - build_tree
Algorithm:
- First set the first element of last_node as null
- Retrieve every element of supply and check whether there is any unsorted element
- Insert the elements into the tree
- Find the level of the element
- Link the node (left ptr) with the last node of the lower level
- Update the last_node
- If this is a new level, insert a new item
- Otherwise, replace the original one
- Set the root of the tree (using the last element of last_node)
- Connect disconnected nodes
- If the right ptr is not null, i.e. the node is connected, then find another one
- Otherwise, link the node (right ptr) with the last node of the nearest lower level
Code:
Error_code Buildable_tree<Record>::build_tree(const List<Record> &supply)
{
Error_code ordered_data = success;
int count = 0; // number of entries inserted so far
Record x, last_x;
List<Binary_node<Record>*> last_node; // points to last nodes on each level
last_node.insert(0, nullptr); // permanently null
while (supply.retrieve(count, x) == success)
{
if (count > 0 && x <= last_x) // check supply is an ordered array
{
ordered_data = fail;
break;
}
build_insert(++count, x, last_node);
last_x = x;
}
root = find_root(last_node);
connect_trees(last_node);
return ordered_data;
}
void Buildable_tree<Record>::build_insert(int count, const Record &new_data, List<Binary_node<Record>*> & last_node)
{
int level; // level of the new node above the leaves
for (level = 1; count % 2 == 0; ++level)
count /= 2;
Binary_node<Record> *next_node = new Binary_node<Record>(new_data), *parent; // one level higher in last_node
last_node.retrieve(level - 1, next_node->left);
if (last_node.size() <= level)
last_node.insert(level, next_node);
else
last_node.replace(level, next_node);
if (last_node.retrieve(level = 1, parent) == success && parent->right == nullptr)
parent->right = next_node;
}
Binary_node<Record> *Buildable_tree<Record>::find_root(List<Binary_node<Record>*> &last_node)
{
Binary_node<Record> *high_node;
last_node.retrieve(last_node.size() - 1, high_node);
return high_node;
}
void Buildable_tree<Record>::connect_trees(const List<Binary_node<Record>*> &last_node)
{
Binary_node<Record> *high_node, // from last_node will null right child
*low_node; // for right child of high_node
int high_level = last_node.size() - 1, low_level;
while (high_level > 2)
{
last_node.retrieve(high_level, high_node);
if (high_node->right != nullptr)
high_level--; // search down for highest dangling node
else
{
low_level = high_level;
do // find the highest tree not in the left subtree
{
last_node.retrieve(--low_level, low_node);
} while (low_node != nullptr && low_node->data < high_node->data); // 继续寻找的条件
high_node->right = low_node;
high_level = low_level;
}
}
}
❗️AVL Trees
Definition
An AVL tree is a binary search tree in which the heights of the left and right subtrees of the root differ by at most 1 1 1 and in which the left and right subtrees are again AVL trees.
Balanced Factors: Used to discribe the height difference of left and right tree. left high, right high, equal
Preset
left* | balance_factor | data | right* |
|---|
enum Balanced_factor {left_higher, equal_height, right_higher};
template <class Record>
struct AVL_node
{
Balanced_factor balance;
Record data;
AVL_node<Record> *left;
AVL_node<Record> *right;
AVL_node();
AVL_node(const Record &x);
void set_balance(Balanced_factor b);
Balanced_factor get_balance() const;
};
template <class Record>
AVL_node<Record>::AVL_node()
{
left = nullptr;
right = nullptr;
balance = equal_height;
}
template <class Record>
AVL_node<Record>::AVL_node(const Record &x)
{
data = x;
left = nullptr;
right = nullptr;
balance = equal_height;
}
template <class Record>
void AVL_node<Record>::set_balance(Balanced_factor b)
{
balance = b;
}
template <class Record>
Balanced_factor AVL_node<Record>::get_balance() const
{
return balance;
}
Operation - insert
Rotation:
-

- Four types: [LL, RR], [LR, RL]
- RR:

- RL

Algorithm:
- If the subtree is empty, then create a new node and return taller
- Else if duplicate error, return not taller
- Else if the new_data is smaller / larger than the subroot, then it should be added to the left / right subtree
- Recursively insert
- Deal with imbalance (taller)
- If subroot is equal height, set left / right higher
- If subroot is right / left higher, set it as balanced
- Otherwise, it is LLorLR / RRorRL imbalance, then use left_balance / right_balance
- If subroot->left / subroot->right is left_higher(LL) / right_highter(RR), set subroot, left_tree / right_tree balance and rotate the subroot right
- Otherwise, it is LR / RL, which require two rotations
- If left_tree->right / right_tree->left is equal height, then set subroot and left_tree balance
- Else if it is right / left higher, set subroot equal height and left_tree left higher / eight_tree right higher
- Else, set subroot right / left higher and left_ tree / right_tree equal high
- Set itself equal
- Rotate left / right for left_tree / right_tree and left / right for subroot
Code:
template <class Record>
Error_code AVL_tree<Record>::avl_insert(AVL_node<Record>* &sub_root, const Record &new_data, bool &taller)
{
Error_code result = success;
if (sub_root == nullptr) // Base Case: 子树为空,插入位点找到
{
sub_root = new AVL_node<Record>(new_data);
taller = true;
}
else if (new_data == sub_root->data) // 相同键
{
result = duplicate_error;
taller = false;
}
else if (new_data < sub_root->data) // 插入在左子树
{
result = avl_insert(sub_root->left, new_data, taller);
if (taller == true) // 不平衡!
{
switch (sub_root->get_balance())
{
case left_higher: // LR/LL型不平衡
left_balance(sub_root);
taller = false;
break;
case equal_height:
sub_root->set_balance(left_higher);
break;
case right_higher:
sub_root->set_balance(equal_height);
taller = false;
break;
default:
break;
}
}
}
else // 插入在右子树
{
result = avl_insert(sub_root->right, new_data, taller);
if (taller == true)
{
switch (sub_root->get_balance())
{
case left_higher:
sub_root->set_balance(equal_height);
taller = false;
break;
case equal_height:
sub_root->set_balance(right_higher);
break;
case right_higher: // RR/RL型不平衡
right_balance(sub_root);
taller = false;
break;
default:
break;
}
}
}
return result;
}
template <class Record>
void AVL_tree<Record>::rotate_left(AVL_node<Record>* &sub_root)
{
if (sub_root == nullptr || sub_root->right == nullptr)
cout << "WARNING: program error detected in rotate left" << endl;
else
{
AVL_node<Record> *right_tree = sub_root->right;
sub_root->right = right_tree->left;
right_tree->left = sub_root;
sub_root = right_tree;
}
}
template <class Record>
void AVL_tree<Record>::rotate_right(AVL_node<Record>* &sub_root)
{
if (sub_root == nullptr || sub_root->left == nullptr)
cout << "WARNING: program error detected in rotate right" << endl;
else
{
AVL_node<Record> *left_tree = sub_root->left;
sub_root->left = left_tree->right;
left_tree->right = sub_root;
sub_root = left_tree;
}
}
template <class Record>
void AVL_tree<Record>::right_balance(AVL_node<Record>* &sub_root)
{
AVL_node<Record>* &right_tree = sub_root->right;
switch (right_tree->get_balance())
{
case right_higher: // RR型不平衡
sub_root->set_balance(equal_height);
right_tree->set_balance(equal_height);
rotate_left(sub_root);
break;
case equal_height:
cout << "WARNING: program error in right balance" << endl;
break;
case left_higher: // RL型不平衡
AVL_node<Record> *sub_tree = right_tree->left;
switch (sub_tree->get_balance())
{
case equal_height:
sub_root->set_balance(equal_height);
right_tree->set_balance(equal_height);
break;
case left_higher:
sub_root->set_balance(equal_height);
right_tree->set_balance(right_higher);
break;
case right_higher:
sub_root->set_balance(left_higher);
right_tree->set_balance(equal_height);
break;
default:
break;
}
sub_tree->set_balance(equal_height);
rotate_right(right_tree);
rotate_left(sub_root);
break;
}
}
template <class Record>
void AVL_tree<Record>::left_balance(AVL_node<Record>* &sub_root)
{
AVL_node<Record>* &left_tree = sub_root->left;
switch (left_tree->get_balance())
{
case left_higher: // LL型不平衡
sub_root->set_balance(equal_height);
left_tree->set_balance(equal_height);
rotate_right(sub_root);
break;
case equal_height:
cout << "WARNING: program error in left balance" << endl;
break;
case right_higher: // LR型不平衡
AVL_node<Record> *sub_tree = left_tree->right;
switch (sub_tree->get_balance())
{
case equal_height:
sub_root->set_balance(equal_height);
left_tree->set_balance(equal_height);
break;
case right_higher:
sub_root->set_balance(equal_height);
left_tree->set_balance(left_higher);
break;
case left_higher:
sub_root->set_balance(right_higher);
left_tree->set_balance(equal_height);
break;
default:
break;
}
sub_tree->set_balance(equal_height);
rotate_left(left_tree);
rotate_right(sub_root);
break;
}
}
Operation - remove
Algorithm:
- If subroot is null, return not found
- Else if we found the element
- If the left / right subtree is empty, then we can link the subroot with the right / left subtree and of course shorter
- Otherwise,
Code:
template <class Record>
Error_code AVL_tree<Record>::remove(Record &new_data)
{
bool shorter = true;
return avl_remove(root, new_data, shorter);
}
template <class Record>
Error_code AVL_tree<Record>::avl_remove(AVL_node<Record>* &sub_root, Record &new_data, bool &shorter)
{
Error_code result = success;
Record sub_record;
if (sub_root == nullptr) // 没找到该元素
{
shorter = false;
return not_present;
}
else if (new_data == sub_root->data) // 找到该元素
{
AVL_node<Record>* to_delete = sub_root;
if (sub_root->right == nullptr) // 右子树空,可以直接删除
{
sub_root = sub_root->left;
shorter = true;
delete to_delete;
return success;
}
else if (sub_root->left == nullptr) // 左子树空,可以直接删除
{
sub_root = sub_root->right;
shorter = true;
delete to_delete;
return success;
}
else // 都不为空
{
to_delete = sub_root->left;
AVL_node<Record> *parent = sub_root;
while (to_delete->right != nullptr) // 查找中序遍历的前序
{
parent = to_delete;
to_delete = to_delete->right;
}
// swap
sub_root->data = to_delete->data;
new_data = to_delete->data;
sub_record = new_data;
}
}
if (new_data < sub_root->data)
{
result = avl_remove(sub_root->left, new_data, shorter);
if (sub_record.the_key() != 0)
sub_root->data = sub_record;
if (shorter == true)
{
switch (sub_root->get_balance())
{
case left_higher:
sub_root->set_balance(equal_height);
break;
case equal_height:
sub_root->set_balance(right_higher);
shorter = false;
break;
case right_higher: // RR/RL型不平衡
shorter = right_balance2(sub_root);
break;
default:
break;
}
}
}
if (new_data > sub_root->data)
{
result = avl_remove(sub_root->right, new_data, shorter);
if (sub_record.the_key() != 0)
sub_root->data = sub_record;
if (shorter == true)
{
switch (sub_root->get_balance())
{
case left_higher: // LL/RL型不平衡
shorter = left_balance2(sub_root);
break;
case equal_height:
sub_root->set_balance(left_higher);
shorter = false;
break;
case right_higher:
sub_root->set_balance(equal_height);
break;
default:
break;
}
}
}
return result;
}
template <class Record>
bool AVL_tree<Record>::right_balance2(AVL_node<Record>* &sub_root)
{
bool shorter;
AVL_node<Record>* &right_tree = sub_root->right;
switch (right_tree->get_balance())
{
case right_higher: // RR型不平衡-1
sub_root->set_balance(equal_height);
right_tree->set_balance(equal_height);
rotate_left(sub_root);
shorter = true;
break;
case equal_height: // RR型不平衡-2
right_tree->set_balance(left_higher);
rotate_left(sub_root);
shorter = false;
break;
case left_higher: // RL型不平衡
AVL_node<Record>* sub_tree = right_tree->left;
switch (sub_tree->get_balance())
{
case equal_height:
sub_root->set_balance(equal_height);
right_tree->set_balance(equal_height);
break;
case left_higher:
sub_root->set_balance(equal_height);
right_tree->set_balance(right_higher);
break;
case right_higher:
sub_root->set_balance(left_higher);
right_tree->set_balance(equal_height);
break;
default:
break;
}
sub_tree->set_balance(equal_height);
rotate_right(right_tree);
rotate_left(sub_root);
shorter = true;
break;
}
return shorter;
}
template <class Record>
bool AVL_tree<Record>::left_balance2(AVL_node<Record>* &sub_root)
{
bool shorter;
AVL_node<Record>* &left_tree = sub_root->left;
switch (left_tree->get_balance())
{
case left_higher: // LL型不平衡-1
sub_root->set_balance(equal_height);
left_tree->set_balance(equal_height);
rotate_right(sub_root);
shorter = true;
break;
case equal_height: // LL型不平衡-2
left_tree->set_balance(left_higher);
rotate_left(sub_root);
shorter = false;
break;
case right_higher: // LR型不平衡
AVL_node<Record>* sub_tree = left_tree->right;
switch (sub_tree->get_balance())
{
case equal_height:
sub_root->set_balance(equal_height);
left_tree->set_balance(equal_height);
break;
case right_higher:
sub_root->set_balance(equal_height);
left_tree->set_balance(left_higher);
break;
case left_higher:
sub_root->set_balance(right_higher);
left_tree->set_balance(equal_height);
break;
default:
break;
}
sub_tree->set_balance(equal_height);
rotate_left(left_tree);
rotate_right(sub_root);
shorter = true;
break;
}
return shorter;
}
Splay Trees
Definition
In a splay tree, every time we access a node, whether for insertion or retrieval, we lift the newly-accessed node all the way up to become the root of the modified tree.
- move left - zig
- move right - zag
Top-Down Splay
Algorithm:
-
Three-way Tree Partition
- central subtree: contains target
- smaller-key subtree: contains nodes smaller than target
- larget-key subtree: contains nodes greater than target
-
Each time, we modify two levels
type operation Zig-zag Link_rightLink_leftZig-zig rotate_rightLink_rightZig Link_rightZag-zag rotate_leftLink_leftZag-zig Link_leftLink_rightZag Link_left -
Implication
template <class Record> void Splay_tree<Record>::link_right(Binary_node<Record>* ¤t, Binary_node<Record>* &first_large) { first_large->left = current; // 挂左 first_large = current; // 重设first_large current = current->left; // 将central的根结点设为原来的左边 } template <class Record> void Splay_tree<Record>::link_left(Binary_node<Record>* ¤t, Binary_node<Record>* &last_small) { last_small->right = current; // 挂右 last_small = current; // 重设last_small current = current->right; // 将central的根结点设为原来的右边 } template <class Record> void Splay_tree<Record>::rotate_right(Binary_node<Record>* ¤t) { Binary_node<Record>* left_tree = current->left; current->left = left_tree->right; left_tree->right = current; current = left_tree; } template <class Record> void Splay_tree<Record>::rotate_left(Binary_node<Record>* ¤t) { Binary_node<Record>* right_tree = current->right; current->right = left_tree->left; right_tree->left = current; current = right_tree; } template <class Record> Error_code Splay_tree<Record>::splay(const Record &target) { Binary_node<Record>* dummy = new Binary_node<Record>; Binary_node<Record>* current = root, *child, *last_small = dummy, *first_large = dummy; while (current != nullptr && current->data != target) { if (target < current->data) { child = current->left; if (child == nullptr || target == child->data) // zig link_right(current, first_large); else if (target < child->data) // zig-zig { rotate_right(current); link_right(current, first_large); } else // zig-zag { link_right(current, first_large); link_left(current, last_small); } } else { child = current->right; if (child == nullptr || target == child->data) // zag link_left(current, last_small); else if (target > child->data) // zag-zag { rotate_left(current); link_left(current, last_small); } else // zag-zig { link_left(current, last_small); link_right(current, first_large); } } } Error_code result; if (current == nullptr) { current = new Binary_node<Record>(target); result = entry_inserted; last_small->right = first_large->left = nullptr; } else { result = entry_found; last_small->right = current->left; first_large->left = current->right; } root = current; root->right = dummy->left; root->left = dummy->right; delete dummy; return result; }
Chapter11 Multiway Tree
Tries
Definition
A trie of order m m m is either empty or consists of an ordered sequence of exactly m m m tries of order$ m$.

Preset
const int num_chars = 28;
struct Trie_node
{
Trie_node();
Record *data;
Trie_node *branch[num_chars];
};
Trie_node::Trie_node()
{
data = nullptr;
for (int i = 0; i < num_chars; i++)
branch[i] = nullptr;
}
enum Error_code{not_present, overflow, underflow, duplicate_error, success};
class Trie
{
public:
Error_code insert(const Record &new_entry);
Error_code trie_search(const Record &target, Record &x) const;
Trie();
private:
Trie_node *root = nullptr;
};
int alphabetic_order(char c)
{
if (c == ' ' || c == '\0')
return 0;
if ('a' <= c && c <= 'z')
return c - 'a' + 1;
if ('A' <= c && c <= 'Z')
return c - 'A' + 1;
return 27;
}
Trie::Trie()
{
root = nullptr;
}
Operation - insert
Algorithm:
- If the tree is empty, new a new node
- Otherwise
- From the root, go down the tree. If the branch of the character is empty, then create a new one.
- In the end, create a new leaf.
Code:
Error_code Trie::insert(const Record &new_entry)
{
Error_code result = success;
if (root == nullptr)
root = new Trie_node;
int position = 0;
char next_char;
Trie_node* location = root;
while (location != nullptr && (next_char = new_entry.key_letter(position)) != '\0')
{
int next_position = alphabetic_order(next_char);
if (location->branch[next_position] == nullptr)
location->branch[next_position] = new Trie_node;
location = location->branch[next_position];
position++;
}
if (location->data != nullptr)
result = duplicate_error;
else
location->data = new Record(new_entry);
return result;
}
Operation - search
Algorithm:
- Choose the branch of the current character and go through the tree
Code:
Error_code Trie::trie_search(const Record &target, Record &x) const
{
int position = 0;
char next_char;
Trie_node* location = root;
while (location != nullptr && (next_char = target.key_letter(position)) != '\0')
{
location = location->branch[alphabetic_order(next_char)];
position++;
}
if (location != nullptr && location->data != nullptr)
{
x = *(location->data);
return success;
}
else
return not_present;
}
MST——B-Tree
Definition
Balanced Multiway Trees: A B-tree of order m m m is an m m m-way search tree in which:
- All leaves are on the same level.
- All internal nodes except the root have at most m m m nonempty children, and at least $┌ m/2 ┐ $ nonempty children.
- The number of keys in each internal node is one less than the number of its nonempty children, and these keys partition the keys in the children in the fashion of a search tree.
- The root has at most m m m children, but may have as few as 2 2 2 if it is not a leaf, or none if the tree consists of the root alone.
Algorithm
- Insertion
- Search the tree for the new key. This search (if the key is truly new) will terminate in failure at a leaf.
- Insert the new key into to the leaf node. If the node was not previously full, then the insertion is finished.
- Full node Split:
4. When a key is added to a full node, then the node splits into two nodes, side by side on the same level, except that the median key is not put into either of the two new nodes.
5. When a node splits, move up one level, insert the median key into this parent node, and repeat the splitting process if necessary.
6. When a key is added to a full root, then the root splits in two and the median key sent upward becomes a new root. This is the only time when the B-tree grows in height.
Preset
template <class Entry, int order>
struct B_node
{
B_node();
int count;
Entry data[order - 1];
B_node<Entry, order> *branch[order];
};
template <class Entry, int order>
B_node<Entry, order>::B_node()
{
count = 0;
}
enum Error_code{not_present, duplicate_error, overflow, success};
template <class Entry, int order>
class B_tree
{
public:
Error_code search_tree(Entry &target);
B_tree();
/* insert */
Error_code insert(const Entry &new_entry);
/* delete */
Error_code remove(const Entry &target);
private:
B_node<Entry, order> *root;
Error_code recursive_search_tree(B_node<Entry, order> *current, Entry &target);
Error_code search_node(B_node<Entry, order> *current, const Entry &target, int &position);
/* insert */
Error_code push_down(B_node<Entry, order> *current, const Entry &new_entry, Entry &median, B_node<Entry, order> * &right_branch);
void push_in(B_node<Entry, order>* current, const Entry &entry, B_node<Entry, order> *right_branch, int position);
void split_node(B_node<Entry, order> *current, const Entry &extra_entry, B_node<Entry, order> *extra_branch, int position, B_node<Entry, order>* &right_half, Entry &median);
/* delete */
Error_code recursive_remove(B_node<Entry, order> *current, const Entry &target);
void remove_data(B_node<Entry, order> *current, int position);
void copy_in_predecessor(B_node<Entry, order> *current, int position);
void restore(B_node<Entry, order> *current, int position);
void move_left(B_node<Entry, order> *current, int position);
void move_right(B_node<Entry, order> *current, int position);
void combine(B_node<Entry, order> *current, int position);
};
template <class Entry, int order>
B_tree<Entry, order>::B_tree()
{
root = nullptr;
}
Operation - search
Algorithm:
- If current node is nullptr, search for the position of the next branch
- Move all the way through the data of the data of the branch until find the position
- Check whether the target is in that position
- Already find the target!
- Otherwise, recursively find in the branch of the subnode
Code:
template <class Entry, int order>
Error_code B_tree<Entry, order>::search_tree(Entry &target)
{
return recursive_search_tree(root, target);
}
template <class Entry, int order>
Error_code B_tree<Entry, order>::recursive_search_tree(B_node<Entry, order> *current, Entry &target)
{
Error_code result = not_present;
int position;
if (current != nullptr)
{
result = search_node(current, target, position);
if (result == not_present)
result = recursive_search_tree(current->branch[position], target);
else
target = current->data[position];
}
return result;
}
template <class Entry, int order>
Error_code B_tree<Entry, order>::search_node(B_node<Entry, order> *current, const Entry &target, int &position)
{
position = 0;
while (position < current->count && target > current->data[position])
position++;
if (position < current->count && target == current->data[position])
return success;
else
return not_present;
}
Operation - insert
Algorithm:
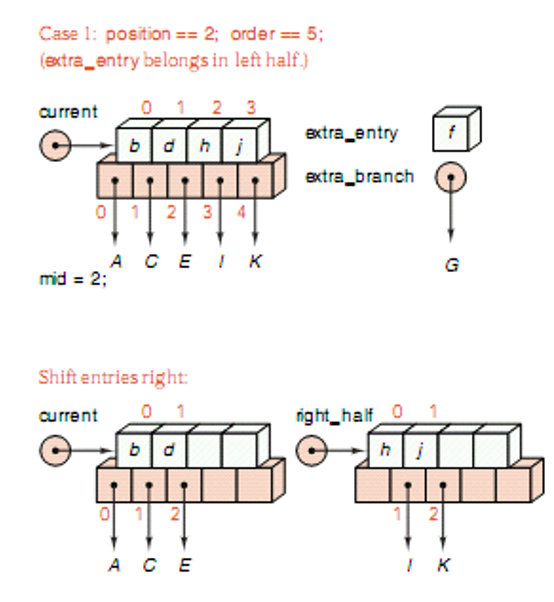
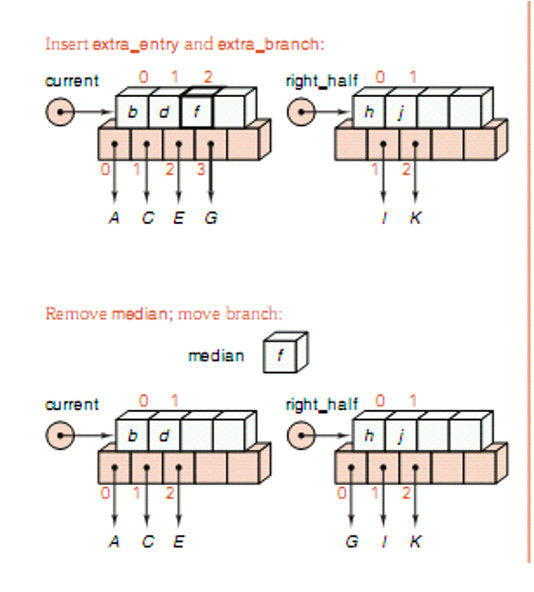
push_down- If current is empty, then put the entry here???
- Otherwise, recursively
push_down- If the length is smaller than order,
push_in- For every element after the current node, move to the right position
- Place the current node in the empty position
- Otherwise,
split_node- Create a new right_half
- If the extra entry belongs to the left half, move the entries to the right half, place the extra entry
- Otherwise, temporarily place the median in the left half, move the entries to the right half
- Remove median from the left half
- If the length is smaller than order,
Code:
template <class Entry, int order>
Error_code B_tree<Entry, order>::insert(const Entry &new_entry)
{
Entry median;
B_node<Entry, order> *right_branch, * new_root;
Error_code result = push_down(root, new_entry, median, right_branch);
if (result == overflow)
{
new_root = new B_node<Entry, order>;
new_root->count = 1;
new_root->data[0] = median;
new_root->branch[0] = root;
new_root->branch[1] = right_branch;
root = new_root;
result = success;
}
return result;
}
template <class Entry, int order>
Error_code B_tree<Entry, order>::push_down(B_node<Entry, order> *current, const Entry &new_entry, Entry &median, B_node<Entry, order> * &right_branch)
{
Error_code result;
int position;
if (current == nullptr)
{
median = new_entry;
right_branch = nullptr;
result = overflow;
}
else
{
if (search_node(current, new_entry, position) == success)
result = duplicate_error;
else
{
Entry extra_entry;
B_node<Entry, order> *extra_branch;
result = push_down(current->branch[position], new_entry, extra_entry, extra_branch);
if (result == overflow)
{
if (current->count < order - 1)
{
result = success;
push_in(current, extra_entry, extra_branch, position);
}
else
split_node(current, extra_entry, extra_branch, position, right_branch, median);
}
}
}
return result;
}
template <class Entry, int order>
void B_tree<Entry, order>::push_in(B_node<Entry, order>* current, const Entry &entry, B_node<Entry, order> *right_branch, int position)
{
for (int i = current->count; i > position; --i)
{
current->data[i] = current->data[i - 1];
current->branch[i + 1] = current->branch[i];
}
current->data[position] = entry;
current->branch[position + 1] = right_branch;
current->count++;
}
template <class Entry, int order>
void B_tree<Entry, order>::split_node(B_node<Entry, order> *current, const Entry &extra_entry, B_node<Entry, order> *extra_branch, int position, B_node<Entry, order>* &right_half, Entry &median)
{
right_half = new B_node<Entry, order>;
int mid = order / 2;
if (position <= mid)
{
for (int i = mid; i < order - 1; ++i)
{
right_half->data[i - mid] = current->data[i];
right_half->branch[i + 1 - mid] = current->branch[i + 1];
}
current->count = mid;
right_half->count = order - 1 - mid;
push_in(current, extra_entry, extra_branch, position);
}
else
{
mid++;
for (int i = mid; i < order - 1; ++i)
{
right_half->data[i - mid] = current->data[i];
right_half->branch[i + 1 - mid] = current->branch[i + 1];
}
current->count = mid;
right_half->count = order - 1 - mid;
push_in(right_half, extra_entry, extra_branch, position - mid);
}
median = current->data[current->count - 1];
right_half->branch[0] = current->branch[current->count];
current->count--;
}
Operation - remove (advanced)
Code:
template <class Entry, int order>
Error_code B_tree<Entry, order>::remove(const Entry &target)
{
Error_code result = recursive_remove(root, target);
if (root != nullptr && root->count == 0)
{
B_node<Entry, order> *old_root = root;
root = root->branch[0];
delete old_root;
}
return result;
}
template <class Entry, int order>
Error_code B_tree<Entry, order>::recursive_remove(B_node<Entry, order> *current, const Entry &target)
{
Error_code result;
int position;
if (current == nullptr)
result = not_present;
else
{
if (search_node(current, target, position) == success)
{
result = success;
if (current->branch[position] != nullptr)
{
copy_in_predecessor(current, position);
recursive_remove(current->branch[position], current->data[position]);
}
else
remove_data(current, position);
}
else
result = recursive_remove(current->branch[position], target);
if (current->branch[position] != nullptr)
if (current->branch[position]->count < (order - 1 / 2))
restore(current, position);
}
return result;
}
template <class Entry, int order>
void B_tree<Entry, order>::remove_data(B_node<Entry, order> *current, int position)
{
for (int i = position; i < current->count - 1; ++i)
current->data[i] = current->data[i + 1];
current->count--;
}
template <class Entry, int order>
void B_tree<Entry, order>::copy_in_predecessor(B_node<Entry, order> *current, int position)
{
B_node<Entry, order> *leaf = current->branch[position];
while (leaf->branch[leaf->count] != nullptr)
leaf = leaf->branch[leaf->count];
current->data[position] = leaf->data[leaf->count - 1];
}
template <class Entry, int order>
void B_tree<Entry, order>::restore(B_node<Entry, order> *current, int position)
{
if (position == current->count)
{
if (current->branch[position - 1]->count > (order - 1) / 2)
move_right(current, position - 1);
else
combine(current, position);
}
else if (position == 0)
{
if (current->branch[1]->count > (order - 1) / 2)
move_left(current, 1);
else
combine(current, 1);
}
else
{
if (current->branch[position - 1]->count > (order - 1) / 2)
move_right(current, position - 1);
else if (current->branch[position + 1]->count > (order - 1) / 2)
move_left(current, position + 1);
else
combine(current, position);
}
}
template <class Entry, int order>
void B_tree<Entry, order>::move_left(B_node<Entry, order> *current, int position)
{
B_node<Entry, order> *left_branch = current->branch[position - 1], *right_branch = current->branch[position];
left_branch->data[left_branch->count] = current->data[position - 1];
left_branch->branch[++left_branch->count] = right_branch->branch[0];
current->data[position - 1] = right_branch->data[0];
right_branch->count--;
for (int i = 0; i < right_branch->count; ++i)
{
right_branch->data[i] = right_branch->data[i + 1];
right_branch->branch[i] = right_branch->branch[i + 1];
}
right_branch->branch[right_branch->count] = right_branch->branch[right_branch->count + 1];
}
template <class Entry, int order>
void B_tree<Entry, order>::move_right(B_node<Entry, order> *current, int position)
{
B_node<Entry, order> *right_branch = current->branch[position - 1], *left_branch = current->branch[position];
right_branch->branch[right_branch->count + 1] = right_branch->branch[right_branch->count];
for (int i = right_branch->count; i > 0; --i)
{
right_branch->data[i] = right_branch->data[i - 1];
right_branch->branch[i] = right_branch->branch[i - 1];
}
right_branch->count++;
right_branch->data[0] = current->data[position];
right_branch->branch[0] = left_branch->branch[left_branch->count--];
current->data[position] = left_branch->data[left_branch->count];
}
template <class Entry, int order>
void B_tree<Entry, order>::combine(B_node<Entry, order> *current, int position)
{
int i;
B_node<Entry, order> *left_branch = current->branch[position - 1], *right_branch = current->branch[position];
left_branch->data[left_branch->count] = current->data[position - 1];
left_branch->branch[++left_branch->count] = right_branch->branch[0];
for (i = 0; i < right_branch->count; ++i)
{
left_branch->data[left_branch->count] = right_branch->data[i];
left_branch->branch[++left_branch->count] = right_branch->branch[i + 1];
}
current->count--;
for (i = position - 1; i < current->count; ++i)
{
current->data[i] = current->data[i + 1];
current->branch[i + 1] = current->branch[i + 2];
}
delete right_branch;
}
Chapter12 Graph
Representation of Graph
Adjacency Matrix / Table
Use Matrix A[0…N-1][0…N-1]
- if
iandjare adjacent,A[i][j] = 1 - otherwise,
A[i][j] = 0 - if
ihas a loop,A[i][i] = 1 - Otherwise,
A[i][i] = 0 - Implementation
/*
as a bit-string
*/
template <int max_set>
struct Set
{
bool is_element[max_set];
};
template <int max_size>
class Digraph
{
int count;
Set<max_size> neibors[max_size];
};
/*
as an adjacency table
*/
template <int max_size>
class Digraph
{
int count;
bool adjacency[max_size][max_size];
}
Adjacency List
typedef int Vertex;
template <int max_size>
class Digraph
{
int count;
List<Vertex> neibors[max_size];
};
/*
linked
*/
class Edge;
class Vertex
{
Edge* first_edge;
Vertex* next_vertex;
};
class Edge
{
Vertex *end_point;
Edge* next_edge;
};
class Digraph
{
Vertex* first_vertex;
}
| Cost | Adjacency Matrix | Adjacency List |
|---|---|---|
| Given two vertices u and v: find out whether u and v are adjacent | $O(1) $ | degree of node $ O(N) $ |
| Given a vertex u: enumerate all neighbors of u | $O(N) $ | degree of node $ O(N) $ |
| For all vertices: enumerate all neighbors of each vertex | $ O(N^2) $ | Summations of all node degree $O(E) $ |
Traversal Algorithms
Depth First
Go through one path until the end and then change one.
template <int max_size>
void Digraph<max_size>::depth_first(void(*visit)(Vertex &)) const
{
bool visited[max_size];
Vertex c;
for (all v in G)
visited[v] = false;
for (all v in G)
if (!visited[v])
traverse(v, visited, visit);
}
template <int max_size>
void Digraph<max_size>::traverse(Vertex &x, bool visited[], void (*visit)(Vertex &)) const
{
Vertex w;
visited[v] = true;
(*visit)(v);
for (all w adjacent to v)
if (!visited[w])
traverse(w, visited, visit);
}
Breath First
template <int max_size>
void Digraph<max_size>::breadth_first(void(*visit)(Vertex &)) const
{
Queue q;
bool visited[max_size];
Vertex v, w, x;
for (all v in G)
visited[v] = false;
for (all v in G)
{
if (!visited[v])
{
q.append(v);
while (!q.empty())
{
q.retrieve(w);
if (!visited[w])
{
visited[w] = true;
(*visited)(w);
for (all w adjacent to w)
q.append(x);
}
q.serve();
}
}
}
}
Topological Order
Definition:
Let G G G be a directed graph with no cycles.
A topological order for G G G is a sequential listing of all the vertices in G G G such that, for all vertices v v v, w w w ∈ \in ∈ G G G, if there is an edge from v v v to w w w, then v v v precedes w w w in the sequential listing.
Depth-first
Algorithm:
- Start by finding a vertex that has no successors and place it last in the order.
- By recursive, After placed all the successors of a vertex into the topological order, then place the vertex itself in position before any of its successors.
Example:
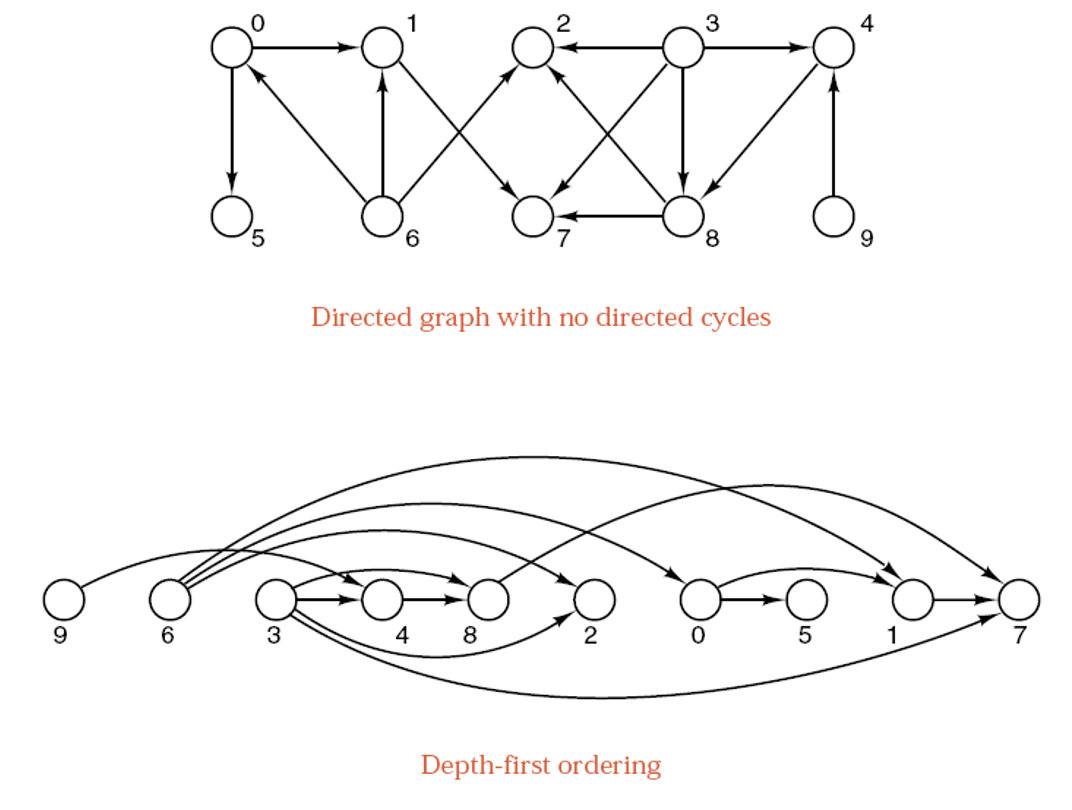
Code:
template <int graph_size>
void Digraph<graph_size>::depth_sort(List<Vertex> &topological_order)
{
bool visited[graph_size];
Vertex v;
for (v = 0; v < count; v++)
visited[v] = false;
topological_order.clear();
for (v = 0; v < count; v++)
if (!visited[v]) // Add v and its successors into topological order.
recursive_depth_sort(v, visited, topological_order);
}
template <int graph_size>
void Digraph<graph_size>::recursive_depth_sort(Vertex v, bool *visited, List<Vertex> &topological_order)
{
visited[v] = true;
int degree = neighbors[v].size();
for (int i = 0; i < degree; i++)
{
Vertex w; // A (neighboring) successor of v
neighbors[v].retrieve(i, w);
if (!visited[w]) // Order the successors of w.
recursive_depth_sort(w, visited, topological_order);
}
topological_order.insert(0, v); // Put v into topological_order.
}
Breadth-first
Algorithm:
- Start by finding the vertices that should be first in the topological order. That is the vertices which have no predecessor.
- Apply the fact that every vertex must come before its successors.
Example:
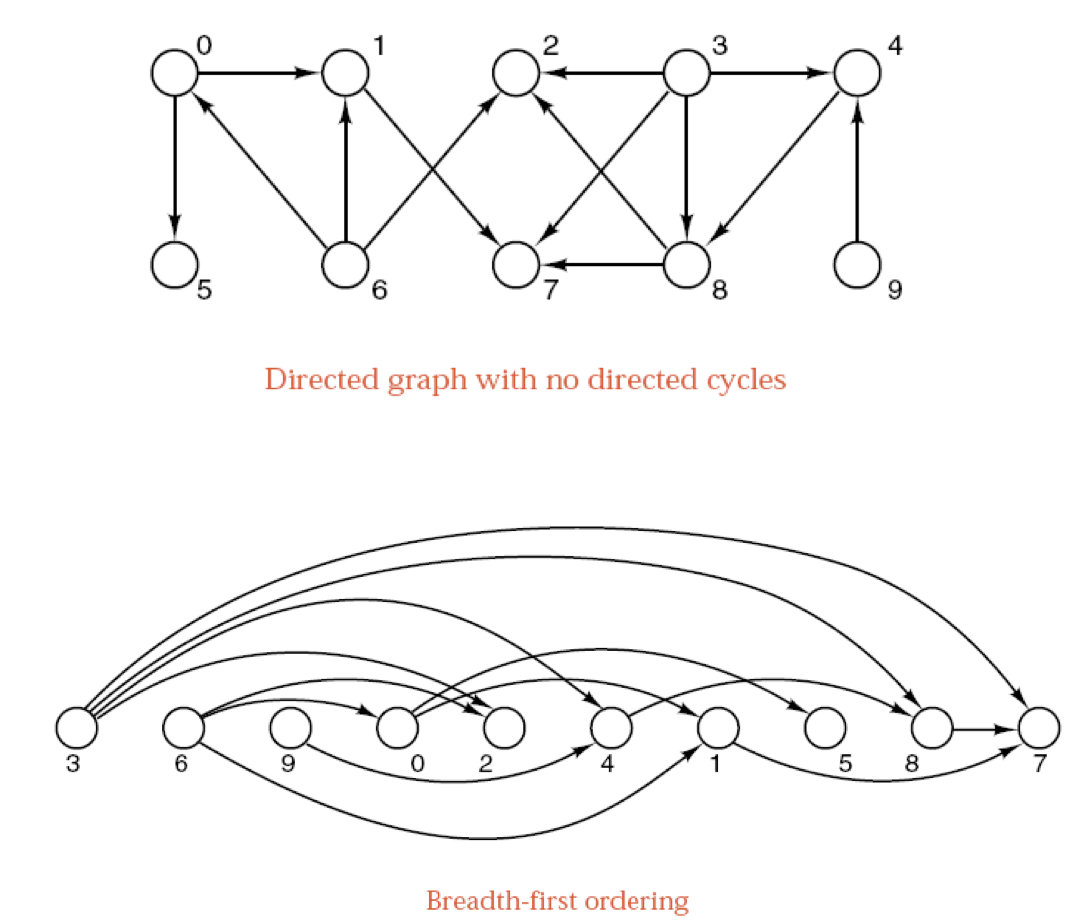
Code:
template <int graph_size>
void Digraph<graph_size>::breadth_sort(List<Vertex> &topological_order)
{
topological_order.clear();
Vertex v, w;
int predecessor_count[graph_size];
for (v = 0; v < count; v++)
predecessor_count[v] = 0;
for (v = 0; v < count; v++)
{
for (int i = 0; i < neighbors[v].size(); i++)
{
neighbors[v].retrieve(i, w); // Loop over all edges v--w.
predecessor_count[w]++;
}
}
Queue ready_to_process;
for (v = 0; v < count; v++)
if (predecessor_count[v] == 0)
ready_to_process.append(v);
while (!ready_to_process.empty()
{
ready_to_process.retrieve(v);
topological_order.insert(topological order.size(), v);
for (int j = 0; j < neighbors[v].size(); j++)
{
neighbors[v].retrieve(j, w); // Traverse successors of v.
predecessor_count[w]−−;
if (predecessor_count[w] == 0)
ready_to_process.append(w);
}
ready_to_process.serve();
}
}
Shortest Paths – Dijkstra Algorithm
template <class Weight, int graph_size>
class Digraph
{
public: // Add a constructor and methods for Digraph input and output.
void set_distances(Vertex source, Weight distance[]) const;
protected:
int count;
Weight adjacency[graph_size][graph_size];
};
template <class Weight, int graph_size>
void Digraph<Weight, graph_size>::set_distances(Vertex source, Weight distance[]) const
{
Vertex v, w;
bool found[graph_size]; // Vertices found in S
for (v = 0; v < count; v++)
{
found[v] = false;
distance[v] = adjacency[source][v];
}
found[source] = true; // Initialize with vertex source alone in the set S.
distance[source] = 0;
for (int i = 0; i < count; i++)
{ // Add one vertex v to S on each pass.
Weight min = infinity;
for (w = 0; w < count; w++)
if (!found[w])
if (distance[w] < min)
{
v = w;
min = distance[w];
}
found[v] = true;
for (w = 0; w < count; w++)
if (!found[w])
if (min + adjacency[v][w] < distance[w])
distance[w] = min + adjacency[v][w];
}
}
Minimal Spanning Trees (MST)
Definition: A minimal spanning tree of a connected network is a spanning tree such that the sum of the weights of its edges is as small as possible.
Algorithm:
- Start with a source vertex.
- Keep a set X of those vertices whose paths to source in the minimal spanning tree that we are building have been found.
- Keep the set Y of edges that link the vertices in X in the tree under construction.
- The vertices in X and edges in Y make up a small tree that grows to become our final spanning tree.
Initially:
- source is the only vertex in X, and Y is empty.
At each step:
- we add an additional vertex to X:
- This vertex is chosen so that an edge back to X has samllest weight. This minimal edge back to X is added to Y .
- neighbor[w], is a vertex in X which is nearest to w.
- distance[w], is the value for the nearst distance of w.
Code:
template <class Weight, int graph size>
class Network: public Digraph<Weight, graph_size>
{
public:
Network();
void read(); // overridden method to enter a Network
void make_empty(int size = 0);
void add_edge(Vertex v, Vertex w, Weight x);
void minimal_spanning(Vertex source, Network<Weight, graph_size> &tree) const;
};
template <class Weight, int graph_size>
void Network<Weight, graph size>::minimal_spanning(Vertex source, Network<Weight, graph_size> &tree) const
{
tree.make_empty(count);
bool component[graph_size]; // Vertices in set X
Weight distance[graph_size]; // Distances of vertices adjacent to X
Vertex neighbor[graph_size]; // Nearest neighbor in set X
Vertex w;
for (w = 0; w < count; w++)
{
component[w] = false;
distance[w] = adjacency[source][w];
neighbor[w] = source;
}
component[source] = true; // source alone is in the set X.
for (int i = 1; i < count; i++)
{
Vertex v; // Add one vertex v to X on each pass.
Weight min = innity;
for (w = 0; w < count; w++)
if (!component[w])
if (distance[w] < min)
{
v = w;
min = distance[w];
}
if (min < innity)
{
component[v] = true;
tree.add_edge(v, neighbor[v], distance[v]);
for (w = 0; w < count; w++)
if (!component[w])
if (adjacency[v][w] < distance[w])
{
distance[w] = adjacency[v][w];
neighbor[w] = v;
}
}
else
break; // finished a component in disconnected graph
}
}















 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









