






1.自制pdf导出
整体思路如下:
1.先定义输出流
2.定义文件名称、字体等后续需要的配置信息
3.设置响应头
4.定义字节数组流,用来缓存文件流
5.实例化文件对象,并设置字体:Document document = new Document(PageSize.A4);
6.打开文档之后对文档进行内容编辑
7.关闭文档
8.关闭输出流
整体代码展示如下:
/**
* 自制pdf并在浏览器下载,不适用多场景,因为自制界面不可复用
* @param request
* @param response
* @param mail 数据来源,正常工作都需要有数据填充在pdf,如果自己测试的话,可以在编辑文本内容的时候随便给数据填充即可,此处可以无需该参数
*/
public void downloadPdf(HttpServletRequest request, HttpServletResponse response, SendMail mail) {
// 输出到浏览器端
OutputStream out = null;
// 定义文件名称,加上当前时间是为了避免同一个文件在服务器重复,导致覆盖
String fileName = "测试文件" + System.currentTimeMillis() + ".pdf";
// 此处的try catch是工具识别自动填充的,用于捕捉文件编码异常
try {
fileName = URLEncoder.encode(fileName, "UTF-8");
} catch (UnsupportedEncodingException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
// 设置响应头,里面的参数可以按照这个设置,也可以自定义
response.setContentType("application/force-download");
response.setHeader("Content-Disposition",
"attachment;fileName=" + fileName);
try {
// 字节数组流,用来缓存文件流
ByteArrayOutputStream bos = new ByteArrayOutputStream();
// 文档对象 实现A4纸页面
Document document = new Document(PageSize.A4);
// 设置文档的页边距就是距离页面边上的距离,分别为:左边距,右边距,上边距,下边距
document.setMargins(70, 70, 20, 10);
// 创建标题字体
BaseFont title = null;
// 创建正文字体
BaseFont bf = null;
// 这里是判断系统获取系统字体,Windows系统无需进行判断,可直接设置字体,如下注释行所示:
// 字体设置:BaseFont bf = BaseFont.createFont(BaseFont.HELVETICA_BOLD, BaseFont.WINANSI, BaseFont.EMBEDDED);
if (isLinux()) {
title = BaseFont.createFont("/opt/gzpt/fonts/simhei.ttf", BaseFont.IDENTITY_H,
BaseFont.NOT_EMBEDDED);
bf = BaseFont.createFont("/opt/gzpt/fonts/simfang.ttf", BaseFont.IDENTITY_H,
BaseFont.NOT_EMBEDDED);
}else {
title = BaseFont.createFont("C:\\Windows\\Fonts\\simhei.ttf", BaseFont.IDENTITY_H,
BaseFont.NOT_EMBEDDED);
bf = BaseFont.createFont("C:\\Windows\\Fonts\\simfang.ttf", BaseFont.IDENTITY_H,
BaseFont.NOT_EMBEDDED);
}
PdfWriter pdfWriter = PdfWriter.getInstance(document, bos);
// 打开文档
document.open();
// 上面是基础的字体,代表使用哪一种字体,下面设置的是字体的字号,粗细等等属性
// 使用上面的title 字体 加粗,这个是标题字体
Font titleFont = new Font(title, 22, Font.BOLD);
// 使用字体,正文字体
Font font = new Font(bf, 16, Font.BOLD);
if (!TeeUtility.isNullorEmpty(title) || !TeeUtility.isNullorEmpty(bf)) {
// 添加pdf内容
addPdfContent(request, mail, document, titleFont, font);
document.close();
out = response.getOutputStream();
bos.writeTo(out);
out.flush();
bos.close();
pdfWriter.close();
System.out.println("创建成功!");
}
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
out.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
/**
* 给自制pdf文件添加文件内容
* @param request
* @param mail 数据来源,正常工作都需要有数据填充在pdf,如果自己测试的话,可以在编辑文本内容的时候随便给数据填充即可,此处可以无需该参数
* @param titleFont 内容标题字体
* @param font 内容字体
*/
private static void addPdfContent(HttpServletRequest request, SendMail mail, Document document, Font titleFont, Font font)
throws DocumentException {
// 段落
Paragraph p = null;
p = new Paragraph("测试标题", titleFont);
p.setLeading(30);
p.setAlignment(Element.ALIGN_CENTER); // 设置对齐方式,这个是居中对齐
document.add(p);
// 控制与下面内容的距离
p = new Paragraph(" ", font);
p.setLeading(30);
p.setAlignment(Element.ALIGN_CENTER); // 设置对齐方式,这个是居中对齐
document.add(p);
// 列宽占比
float[] columnWidths = { 2.5f, 5.0f };
// 插入2列表格
PdfPTable table = new PdfPTable(2);
table.setWidths(columnWidths);
// 单元格
PdfPCell cell = null;
cell = new PdfPCell(new Paragraph("送达单位名称", font));
// 居中对齐
cell.setHorizontalAlignment(1);
// 将单元格加入表格
table.addCell(cell);
// 获取送达单位并赋值
String sendDept = "测试单位";
// TeeUtility.isNullorEmpty()是系统框架自带工具,java的公用api例如StringUtils.isBlaak()等和此类似
cell = new PdfPCell(new Paragraph(TeeUtility.isNullorEmpty(sendDept) ? mail.getDeptName() : sendDept, font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph("送达单位邮箱", font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph(TeeUtility.isNullorEmpty(mail.getFrom()) ? "" : mail.getFrom(), font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph("受送达人名称", font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph(null, font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph("受送达人邮箱", font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph(TeeUtility.isNullorEmpty(mail.getReceive()) ? "" : mail.getReceive(), font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph("受送达人手机", font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph(TeeUtility.isNullorEmpty(mail.getTel()) ? "" : mail.getTel(), font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph("送达文书名称", font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph(TeeUtility.isNullorEmpty(mail.getRunName()) ? "" : mail.getRunName(), font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph("送达文书文号", font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph(TeeUtility.isNullorEmpty(mail.getPunishCode()) ? "" : mail.getPunishCode(), font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph("送达时间", font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph(TeeUtility.isNullorEmpty(mail.getSendMailDate().toString()) ? "" : mail.getSendMailDate().toString(), font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph("备注", font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
cell = new PdfPCell(new Paragraph(null, font));
cell.setHorizontalAlignment(1);
table.addCell(cell);
document.add(table);
}
以上就是编辑自制pdf内容以及下载的整体代码,亲测有效,流程走完之后会在浏览器弹出pdf下载,和在浏览器下载文件一模一样。
如下是内容展示:
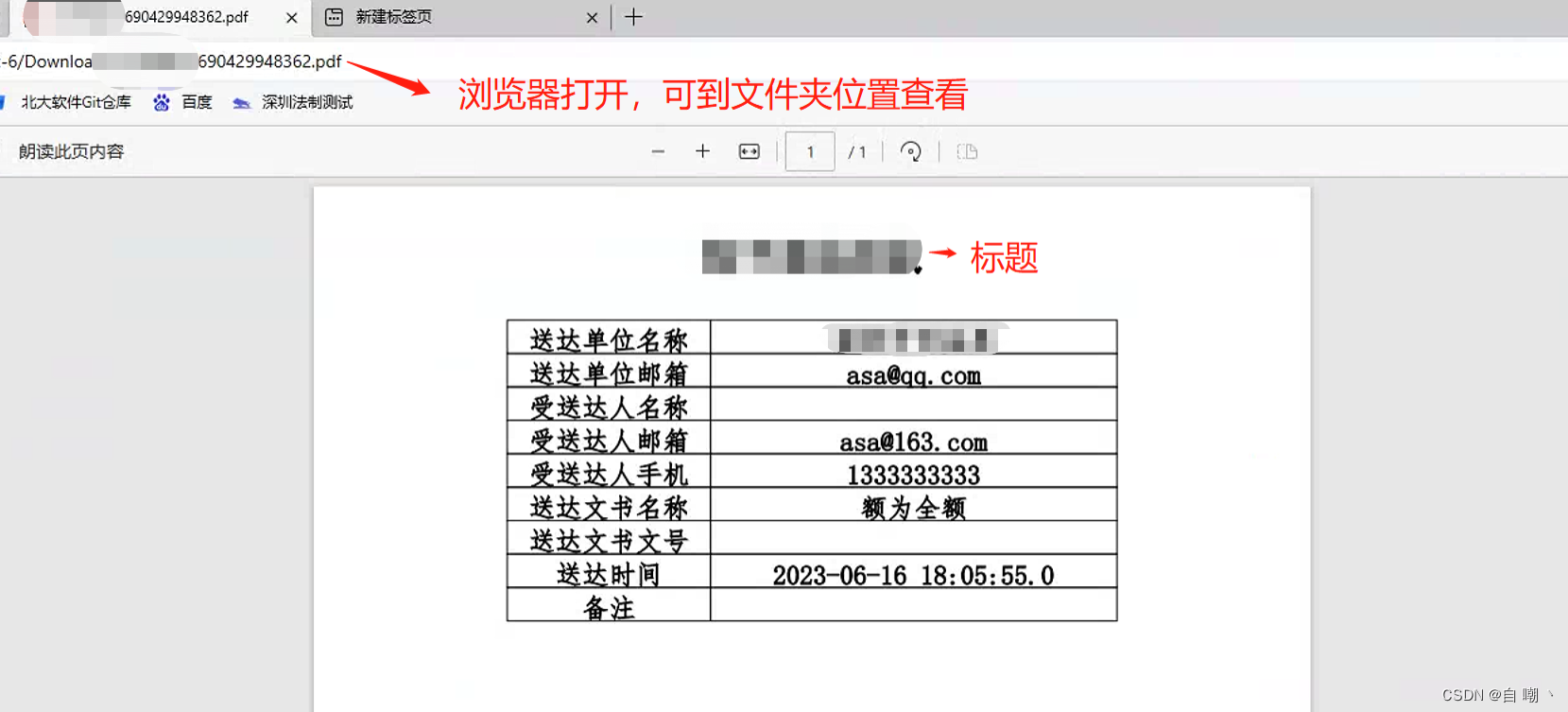
2.pdf模板填充数据导出
整体思路如下:
1.需要先找到数据填充的模板
2.通过Adobe Acrobat DC软件给模板识别需要填充的位置,并在该位置填充字段信息,用于程序识别并进行赋值
3.准备好字体,正常情况下需要在服务器上传对于的字体,用于在服务器部署程序并识别字体
4.写程序填充数据
填充模板如下,并通过Adobe Acrobat DC把需要填充的地方进行识别,并设置了字段:

字体准备:直接把系统自带的字体复制出来使用即可,本地可以直接识别系统字体,但是服务器也需要设置字体。
代码编写:
/**
* 通过pdf模板填充数据生成新的pdf,支持预览+下载(download参数判断是否下载),适用多场景
* @param request
* @param response
* @param templateName 模板名称
* @param object 数据源
* @param download 是否下载
*/
public static void generatePdf(HttpServletRequest request, HttpServletResponse response, String templateName,
Object object, boolean download) {
try {
System.setProperty("javax.xml.parsers.DocumentBuilderFactory",
"com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl");
OutputStream responseOutputStream = response.getOutputStream();
ByteArrayOutputStream fileOut = new ByteArrayOutputStream();
// 模板在项目中的位置
Resource resource = new PathMatchingResourcePatternResolver()
.getResource("com/lz/zfjd/utils/pdf/resource/" + templateName);
PdfReader reader = new PdfReader(resource.getInputStream());
PdfStamper ps = new PdfStamper(reader, fileOut);
BaseFont bf ;
if (isLinux()) {
// 正式环境字体存放位置
// bf = BaseFont.createFont("/home/gzpt/app/oaop/fonts/simsun.ttc,1", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
// 测试服务器字体存放位置
bf = BaseFont.createFont("/opt/gzpt/fonts/simsun.ttc,1", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
} else {
// 宋体
bf = BaseFont.createFont("C:\\Windows\\Fonts\\simsun.ttc,1", BaseFont.IDENTITY_H,
BaseFont.NOT_EMBEDDED);
}
ArrayList<BaseFont> fontList = new ArrayList<BaseFont>();
fontList.add(bf);
// 取出报表模板中的所有字段
AcroFields fields = ps.getAcroFields();
fields.setSubstitutionFonts(fontList);
PdfUtil.fillData(fields, PdfUtil.turnMap(object));
// 必须要调用这个,否则文档不会生成的 如果为false那么生成的PDF文件还能编辑,一定要设为true
ps.setFormFlattening(true);
ps.close();
if (download) {
writerFile(request, response, templateName, false);
}
fileOut.writeTo(responseOutputStream);
} catch (Exception e) {
System.out.println("pdf生成异常:" + e);
throw new RuntimeException("操作异常请联系管理员!");
}
}
// 判断是否是liunx系统,用于给本地和服务器字体存放位置进行区分
public static boolean isLinux() {
Properties prop = System.getProperties();
String os = prop.getProperty("os.name");
if (os != null && os.toLowerCase().indexOf("linux") > -1) {
return true;
} else {
return false;
}
}
/**
* 循环遍历,填充Adobe Acrobat DC设置字段的数据
*
* @param fields
* @param data
* @throws IOException
* @throws DocumentException
*/
private static void fillData(AcroFields fields, Map<String, String> data) throws IOException, DocumentException {
Map<String, AcroFields.Item> formFields = fields.getFields();
for (String key : data.keySet()) {
if (formFields.containsKey(key)) {
String value = data.get(key);
// 为字段赋值,注意字段名称是区分大小写的
fields.setField(key, value);
}
}
}
// 把数据源的数据封装到map中,用于后续赋值使用
private static Map<String, String> turnMap(Object object) {
Map<String, Object> stringObjectMap = BeanUtil.beanToMap(object);
Map<String, String> map = new HashMap<String, String>(stringObjectMap.size() * 2);
// 打印输出属性名称和属性值
for (Map.Entry<String, Object> entry : stringObjectMap.entrySet()) {
String key = entry.getKey();
Object value = entry.getValue();
}
return map;
}
/**
* 写出文件
*
* @param request
* @param response
* @param fileName
* @param deleteOnExit 是否需要删除本地文件
*/
private static void writerFile(HttpServletRequest request, HttpServletResponse response, String fileName,
boolean deleteOnExit) throws IOException {
File file = new File("/" + fileName);
file.createNewFile();
response.setCharacterEncoding(request.getCharacterEncoding());
response.setContentType("application/pdf");
try {
FileInputStream fis = new FileInputStream(file);
// 这里主要防止下载的PDF文件名乱码
response.setHeader("Content-Disposition",
"attachment; filename=" + URLEncoder.encode(file.getName(), "UTF-8"));
IOUtils.copy(fis, response.getOutputStream());
response.flushBuffer();
if (deleteOnExit) {
file.deleteOnExit();
}
} catch (Exception e) {
System.out.println("pdf生成异常:" + e);
throw new RuntimeException("操作异常请联系管理员!");
}
}
以上代码就是通过模板识别的方式进行pdf赋值并导出的方式,具体制作效果如下:
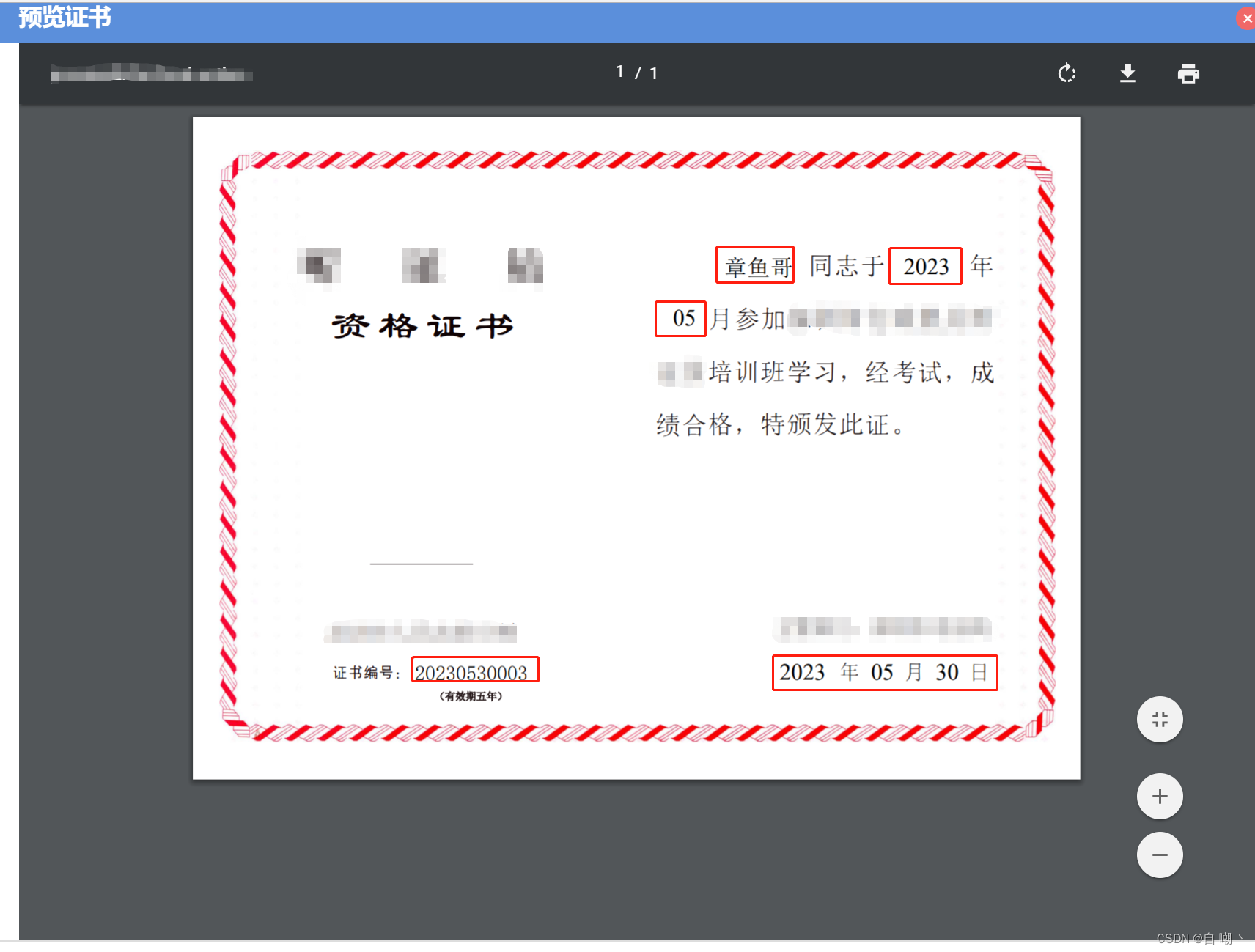














 2966
2966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









