










文章目录
一、前言
首先感谢一下作者Python伊甸园提供的思路:中国知网爬虫,本文也是基于高级检索进行筛选和相关信息的爬取,但在实际操作过程中发现知网的框架有所变化,所以在原代码的基础上进行了一些修改和针对性优化,此篇文章目的在于记录一些编写代码过程中所用到的知识和相关细节
配置需求:python chromedriver
二、思路分析
1.访问知网主页

2.跳转至高级检索页面并点击专业检索
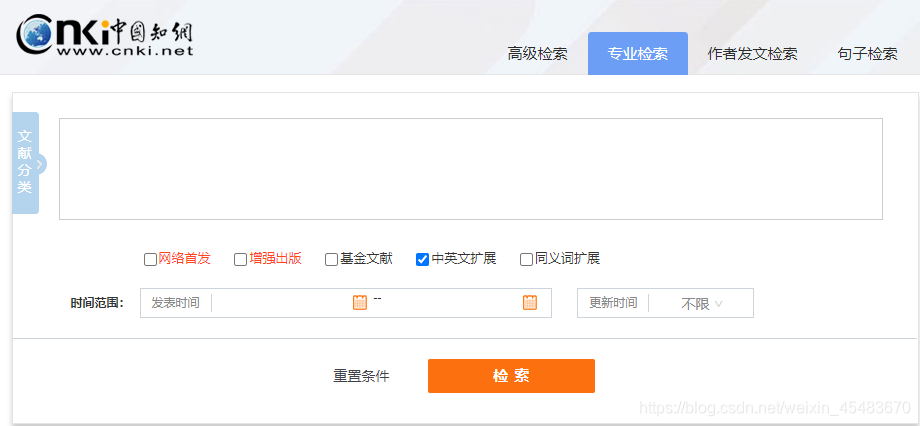
3.输入检索条件并检索
4.依次爬取不同页面信息
三、代码实现
1.初始化检索条件
可以视情况加一加请求头之类的东西
# 加载chromedriver,此处路径需根据实际情况调整
driver_path = r"D:\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
# 查询关键字
keyword = ' SU=机器学习'
search(keyword, date_start="2018-1-1", date_end="2020-10-31")
2.调用search函数完成检索
此处search函数需要三个参数,分别是查询关键字和起始时间
def search(key, date_start, date_end):
# 跳转至高级检索页面
url = 'https://kns.cnki.net/kns8/AdvSearch?dbprefix=SCDB&&crossDbcodes=CJFQ%2CCDMD%2CCIPD%2CCCND%2CCISD%2CSNAD' \
'%2CBDZK%2CCJFN%2CCCJD '
driver.get(url)
# 点击专业检索
search_page = driver.find_element_by_xpath("/html/body/div[4]/div/div[2]/ul/li[4]")
search_page.click()
# 设置时间等待,等待搜索框加载完毕
time.sleep(3)
# 定位搜索框,输入关键字
search_win = driver.find_element_by_css_selector('.textarea-major')
search_win.send_keys(key)
search_btn = driver.find_element_by_css_selector('.btn-search')
# 操作日期控件(定位起始时间)
js = 'document.getElementById("datebox0").removeAttribute("readonly");'
driver.execute_script(js)
js_value = 'document.getElementById("datebox0").value="{}"'.format(date_start)
driver.execute_script(js_value)
# 操作日期控件(定位终止时间)
js = 'document.getElementById("datebox1").removeAttribute("readonly");'
driver.execute_script(js)
js_value = 'document.getElementById("datebox1").value="{}"'.format(date_end)
driver.execute_script(js_value)
# 点击检索
search_btn.click()
3.爬取当前页面信息
这里只采集了不同条目包括标题、作者、来源、时间、数据库、被引用次数和下载次数在内的7个信息
def parse_page():
html = etree.HTML(driver.page_source)
# 获取所有行信息
trs = html.xpath('//table[@class="result-table-list"]/tbody/tr')
# 在行中迭代,逐行提取信息
for tr in trs:
# strip删除字符串开头和结尾处的换行符
title = tr.xpath('./td//a[@class="fz14"]//text()')
title = ''.join(title).strip()
authors = tr.xpath('./td[@class="author"]//text()')
authors = ''.join(authors).strip()
source = tr.xpath('./td[@class="source"]/a//text()')
source = ''.join(source).strip()
date = tr.xpath('./td[@class="date"]//text()')
date = ''.join(date).strip()
database = tr.xpath('./td[@class="data"]//text()')
database = ''.join(database).strip()
counted = tr.xpath('./td[@class="quote"]//text()')
counted = ''.join(counted).strip()
if counted == '':
counted = '0'
download_count = tr.xpath('./td[@class="download"]//text()')
if len(download_count) == 1:
download_count = '0'
else:
download_count = download_count[1]
# 数据封装
data_pack = {
"title": title,
"authors": authors,
"source": source,
"date": date,
"database": database,
"counted": counted,
"downloadCount": download_count,
}
datas.append(data_pack)
time.sleep(random.uniform(2, 4))
4.翻页,等待下一次爬取
def next_page():
driver.execute_script("$(arguments[0]).click()", driver.find_element_by_id('PageNext'))
time.sleep(2)
因为知网的反爬机制,所以大概每翻30页左右会弹出一个验证码,如果要自动化处理的话还得专门写个函数识别验证码,不过小体量的数据完全可以通过人工方式方式进行处理,所以就没单独写了
5.存储数据
本文思路是依次将每一页的每一个条目的信息以字典类型封装,然后依次存入数组,最后将数组转化为DataFrame对象,然后用pandas函数直接写入Excel。不过这样做存在一个问题,就是如果爬取过程出现中断,会导致数据全部无法写入,用分段式写入的模式能解决这个问题,以后可能会进行优化
def store(data):
# 获取当前文件位置的绝对路径,目标文件将会生成在此代码同级的文件夹中
abs_path = os.path.dirname(os.path.abspath(__file__))
# 给文件命名,组合字符串
out_path = os.path.join(abs_path, 'test.xlsx')
# 用pandas将字典对象data转换为DataFrame对象
df = pd.DataFrame(data)
# 用内置函数直接导入Excel
df.to_excel(out_path)
四、源代码
import os
import re
import time
import random
import pandas as pd
from lxml import etree
from selenium import webdriver
def next_page():
driver.execute_script("$(arguments[0]).click()", driver.find_element_by_id('PageNext'))
time.sleep(2)
def parse_page():
html = etree.HTML(driver.page_source)
# 获取所有行信息
trs = html.xpath('//table[@class="result-table-list"]/tbody/tr')
# 在行中迭代,逐行提取信息
for tr in trs:
# strip删除字符串开头和结尾处的换行符
title = tr.xpath('./td//a[@class="fz14"]//text()')
title = ''.join(title).strip()
authors = tr.xpath('./td[@class="author"]//text()')
authors = ''.join(authors).strip()
source = tr.xpath('./td[@class="source"]/a//text()')
source = ''.join(source).strip()
date = tr.xpath('./td[@class="date"]//text()')
date = ''.join(date).strip()
database = tr.xpath('./td[@class="data"]//text()')
database = ''.join(database).strip()
counted = tr.xpath('./td[@class="quote"]//text()')
counted = ''.join(counted).strip()
if counted == '':
counted = '0'
download_count = tr.xpath('./td[@class="download"]//text()')
if len(download_count) == 1:
download_count = '0'
else:
download_count = download_count[1]
# 数据封装
data_pack = {
"title": title,
"authors": authors,
"source": source,
"date": date,
"database": database,
"counted": counted,
"downloadCount": download_count,
}
datas.append(data_pack)
time.sleep(random.uniform(2, 4))
def search(key, date_start, date_end):
# 跳转至高级检索页面
url = 'https://kns.cnki.net/kns8/AdvSearch?dbprefix=SCDB&&crossDbcodes=CJFQ%2CCDMD%2CCIPD%2CCCND%2CCISD%2CSNAD' \
'%2CBDZK%2CCJFN%2CCCJD '
driver.get(url)
# 点击专业检索
search_page = driver.find_element_by_xpath("/html/body/div[4]/div/div[2]/ul/li[4]")
search_page.click()
# 设置时间等待,等待搜索框加载完毕
time.sleep(3)
# 定位搜索框,输入关键字
search_win = driver.find_element_by_css_selector('.textarea-major')
search_win.send_keys(key)
search_btn = driver.find_element_by_css_selector('.btn-search')
# 操作日期控件(定位起始时间)
js = 'document.getElementById("datebox0").removeAttribute("readonly");'
driver.execute_script(js)
js_value = 'document.getElementById("datebox0").value="{}"'.format(date_start)
driver.execute_script(js_value)
# 操作日期控件(定位终止时间)
js = 'document.getElementById("datebox1").removeAttribute("readonly");'
driver.execute_script(js)
js_value = 'document.getElementById("datebox1").value="{}"'.format(date_end)
driver.execute_script(js_value)
# 点击检索
search_btn.click()
def main():
# 提取总页数页码
pages = driver.find_element_by_class_name('total').text
pages = re.sub(r"\D", "", pages)
# 下面这个数字指的是爬取的页数
for i in range(int(pages)):
# 解析当前页面
parse_page()
print("成功爬取第" + str(i + 1) + "页")
# 翻页
next_page()
try:
# 检测下一页是否存在翻页按钮
driver.find_element_by_id('PageNext')
# 捕获所有异常(目前只处理了弹出验证码一种)
except:
# 此处对应两种情况,验证码页面和最后一页
verify = input("请输入验证码后按回车继续或者输入1退出")
if verify == '1':
parse_page()
print("成功爬取第" + str(i + 1) + "页(最后一页),程序结束")
break
pass
# 如果觉得爬取速度太快可以把下面这行代码取消注释,增长间隔时间
# time.sleep(random.uniform(2, 4))
def store(data):
# 获取当前文件位置的绝对路径,目标文件将会生成在此代码同级的文件夹中
abs_path = os.path.dirname(os.path.abspath(__file__))
# 给文件命名,组合字符串
out_path = os.path.join(abs_path, 'test.xlsx')
# 用pandas将字典对象data转换为DataFrame对象
df = pd.DataFrame(data)
# 用内置函数直接导入Excel
df.to_excel(out_path)
if __name__ == "__main__":
# 加载chromedriver,此处路径需根据实际情况调整
driver_path = r"D:\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
# 查询关键字
keyword = 'SU=机器学习'
search(keyword, date_start="2020-10-25", date_end="2020-10-31")
# 战术停顿
time.sleep(3)
datas = []
# 主体函数
main()
# 存储数据
store(datas)
# 关闭浏览器
driver.close()
# 关闭chromedriver进程
driver.quit()
五、部分结果展示
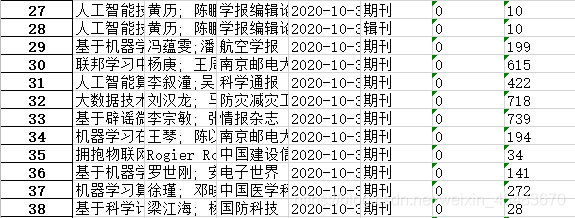
PS:因为所做测试数量有限,所以爬取结果可能会存在一定问题,还需根据实际情况进行适当调整,也希望各位积极反馈和批评指正
参考文章链接:
https://blog.csdn.net/weixin_42830697/article/details/103181039?utm_medium=distribute.pc_relevant.none-task-blog-searchFromBaidu-3.not_use_machine_learn_pai&depth_1-utm_source=distribute.pc_relevant.none-task-blog-searchFromBaidu-3.not_use_machine_learn_pai

















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









