






因为以前公司有这个需求所以我有去了解实现这个功能
ocr即:图片文字识别功能。就是读取图片上的文件信息,展示出来。一开始为成本考虑我想自己实现这个功能。于是查阅资料整理dome,基于roc语言库,真就让我写了一个文字识别功能出来。但是效果就一言难尽了。总的来说就是只有正面的,图像清晰的图片才能识别出去除了格式的文字信息出来。自己用一用还行,但是想要用到产品上进行商用还行洗洗睡吧。
自己的不行,就用别人的。一番查找对比以后最终有两家平台可以使用(基于效果和成本考虑),一家是百度一家是阿里。如果减低要求使用,百度基本算是免费的,阿里那就只有500次免费了(但是人家效果更好啊)。
百度和阿里都有多种ocr识别服务,带格式的去格式的,带位置的不带位置的。证件的多种多样。这里就展示最简单的那种。
百度的ocr使用需要先开通百度云上的ocr功能。整完就弄出一个如下图的应用就行了
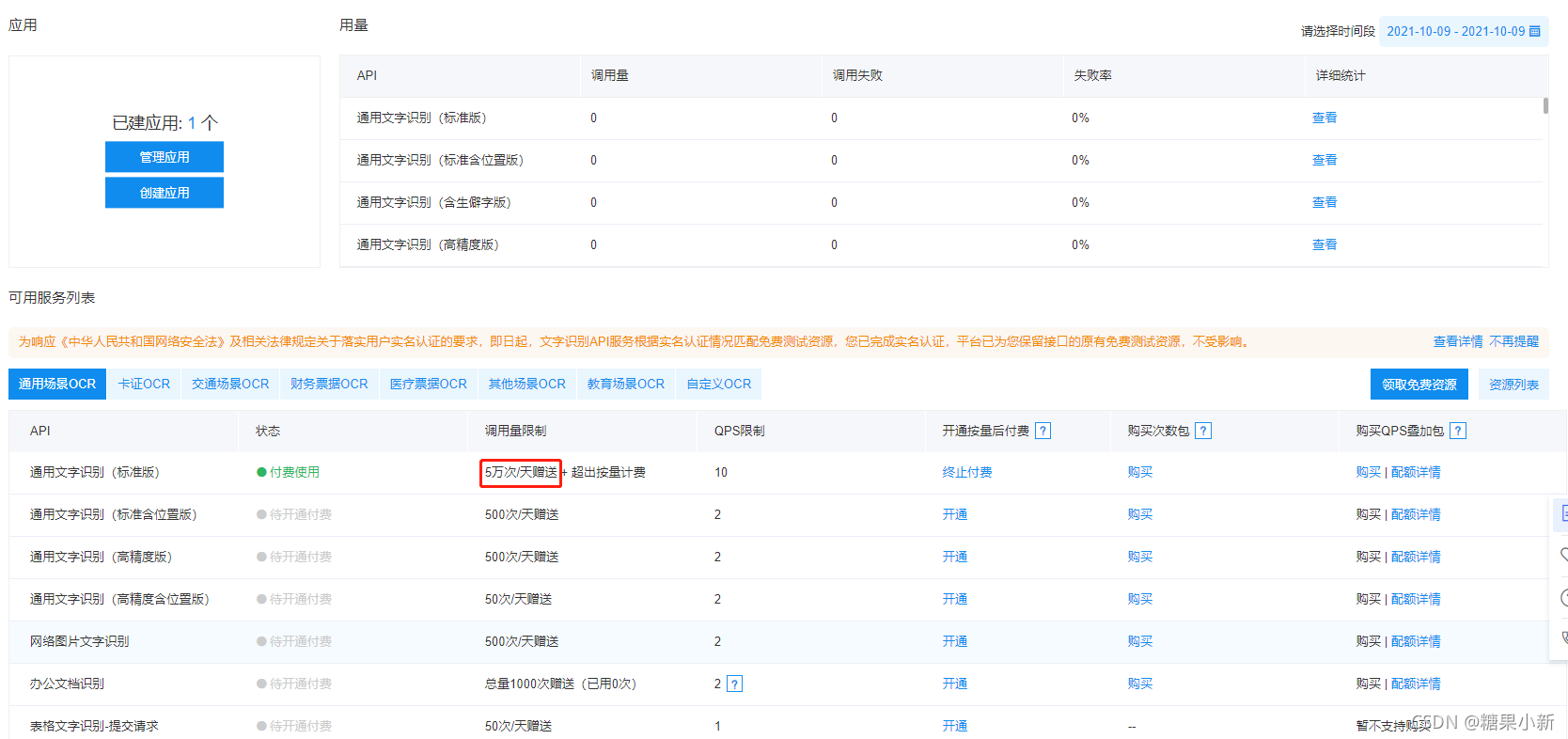
注意我们这里使用的是百度最基础的通用文件识别每天送5W次。qps是10但是这个要开通付费才有不然是2。不过只有每天超过5W的才会收费。然后使用的时候去百度api下jar包,基本都封装好了,我们填参数就行,傻子都会操作(所以说除了效果差一点,这就是良心商家啊) 话不多说符代码:

AipOcr client = new AipOcr("appID", "API Key", "Secret Key");
// System.setProperty("aip.log4j.conf", "path/to/your/log4j.properties");
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
// 传入可选参数调用接口
HashMap<String, String> options = new HashMap<String, String>();
options.put("language_type", "CHN_ENG");
options.put("detect_direction", "true");
options.put("detect_language", "true");
// options.put("detect_language", "true");
// options.put("probability", "true");
/* // 参数为本地图片路径
String image = "test.jpg";
JSONObject res = client.basicGeneral(image, options);
System.out.println(res.toString(2));
// 参数为本地图片二进制数组
byte[] file = readImageFile(image);
res = client.basicGeneral(file, options);
System.out.println(res.toString(2));*/
// 通用文字识别, 图片参数为远程url图片
System.out.println(new Date());
org.json.JSONObject res = client.basicAccurateGeneral("C:\\Users\\linrui\\Desktop\\测试用图片\\5.png", options);
System.out.println(res.toString());
一个main方法调用你就能看到结果
阿里的调用就略麻烦一些,首先你要在阿里云上购买次数,然后它会返给你一个应用的key 这个就是调用的许可证
接着参数什么的要自己封装 上代码
封装一个请求参数
/**
* 用于请求阿里的ocr识别的实例
*/
public class OcrAlDto implements Serializable {
//图像数据:base64编码,要求base64编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式,和url参数只能同时存在一个
private Byte[] img;
//图像url地址:图片完整URL,URL长度不超过1024字节,URL对应的图片base64编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式,和img参数只能同时存在一个
private String url;
//是否需要识别结果中每一行的置信度,默认不需要。 true:需要 false:不需要
private Boolean prob;
//是否需要单字识别功能,默认不需要。 true:需要 false:不需要
private Boolean charInfo;
//是否需要自动旋转功能,默认不需要。 true:需要 false:不需要
private Boolean rotate;
//是否需要表格识别功能,默认不需要。 true:需要 false:不需要
private Boolean table;
//是否需要分页功能,默认不需要。 true:需要 false:不需要
private Boolean page;
//是否需要分段功能,默认不需要。 true:需要 false:不需要
private Boolean paragraph;
//是否需要成行功能,默认不需要。 true:需要 false:不需要
private Boolean row;
//是否需要切边功能,默认不需要。 true:需要 false:不需要
private Boolean removeBoundary;
//是否需要去印章功能,默认不需要。 true:需要 false:不需要
private Boolean noStamp;
//字块返回顺序,false表示从左往右,从上到下的顺序,true表示从上到下,从左往右的顺序,默认false
private Boolean sortPage;
public Byte[] getImg() {
return img;
}
public void setImg(Byte[] img) {
this.img = img;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public Boolean getProb() {
return prob;
}
public void setProb(Boolean prob) {
this.prob = prob;
}
public Boolean getCharInfo() {
return charInfo;
}
public void setCharInfo(Boolean charInfo) {
this.charInfo = charInfo;
}
public Boolean getRotate() {
return rotate;
}
public void setRotate(Boolean rotate) {
this.rotate = rotate;
}
public Boolean getTable() {
return table;
}
public void setTable(Boolean table) {
this.table = table;
}
public Boolean getPage() {
return page;
}
public void setPage(Boolean page) {
this.page = page;
}
public Boolean getParagraph() {
return paragraph;
}
public void setParagraph(Boolean paragraph) {
this.paragraph = paragraph;
}
public Boolean getRow() {
return row;
}
public void setRow(Boolean row) {
this.row = row;
}
public Boolean getRemoveBoundary() {
return removeBoundary;
}
public void setRemoveBoundary(Boolean removeBoundary) {
this.removeBoundary = removeBoundary;
}
public Boolean getNoStamp() {
return noStamp;
}
public void setNoStamp(Boolean noStamp) {
this.noStamp = noStamp;
}
public Boolean getSortPage() {
return sortPage;
}
public void setSortPage(Boolean sortPage) {
this.sortPage = sortPage;
}
}
然后封装返回参数
public class Ocr implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String sid;
private String prism_version;
private Integer prism_wnum;
private Integer angle;
private Integer height;
private Integer width;
private Integer orgHeight;
private Integer orgWidth;
private String content;
private String filePath;
private String wordPath;
private String ocrResult;
private String percentile;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOcrResult() {
return ocrResult;
}
public void setOcrResult(String ocrResult) {
this.ocrResult = ocrResult;
}
public String getPercentile() {
return percentile;
}
public void setPercentile(String percentile) {
this.percentile = percentile;
}
public String getWordPath() {
return wordPath;
}
public void setWordPath(String wordPath) {
this.wordPath = wordPath;
}
public String getFilePath() {
return filePath;
}
public void setFilePath(String filePath) {
this.filePath = filePath;
}
public String getSid() {
return sid;
}
public void setSid(String sid) {
this.sid = sid;
}
public String getPrism_version() {
return prism_version;
}
public void setPrism_version(String prism_version) {
this.prism_version = prism_version;
}
public Integer getPrism_wnum() {
return prism_wnum;
}
public void setPrism_wnum(Integer prism_wnum) {
this.prism_wnum = prism_wnum;
}
public Integer getAngle() {
return angle;
}
public void setAngle(Integer angle) {
this.angle = angle;
}
public Integer getHeight() {
return height;
}
public void setHeight(Integer height) {
this.height = height;
}
public Integer getWidth() {
return width;
}
public void setWidth(Integer width) {
this.width = width;
}
public Integer getOrgHeight() {
return orgHeight;
}
public void setOrgHeight(Integer orgHeight) {
this.orgHeight = orgHeight;
}
public Integer getOrgWidth() {
return orgWidth;
}
public void setOrgWidth(Integer orgWidth) {
this.orgWidth = orgWidth;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
封装请求 代码中的key就是上文中的key
/**
* 向指定 URL 发送POST方法的请求
*
* @param url 发送请求的 URL
* @param param 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
*/
public static String ocrpost(String url, String param) {
PrintWriter out = null;
BufferedReader in = null;
String result = "";
try {
URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection conn = realUrl.openConnection();
// String s = PropKit.get("ocr.al.key");
conn.setRequestProperty("Authorization", "APPCODE " + key);
conn.setRequestProperty("Content-Type", "application/json");
// 设置通用的请求属性
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 发送POST请求必须设置如下两行
conn.setDoOutput(true);
conn.setDoInput(true);
// 获取URLConnection对象对应的输出流
out = new PrintWriter(conn.getOutputStream());
// 发送请求参数
out.print(param);
// flush输出流的缓冲
out.flush();
out.close();
InputStream ips = conn.getInputStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buf = new byte[1024];
int length = 0;
while ((length = ips.read(buf)) != -1) {
baos.write(buf, 0, length);
baos.flush();
}
byte[] responsData = baos.toByteArray();
baos.close();
//处理写响应信息
result = new String(responsData, "UTF-8");
} catch (Exception e) {
System.out.println("发送 POST 请求出现异常!" + e);
}
return result;
}
main方法
@Test
public void aliocr(){
OcrAlDto ocrAlDto = new OcrAlDto();
ocrAlDto.setRotate(true);
ocrAlDto.setNoStamp(true);
ocrAlDto.setRemoveBoundary(true);
ocrAlDto.setProb(true);
ocrAlDto.setUrl("http://baidu/uplo/20210410/B00247DAB527_20210410_142745_2.jpg");//可以直接使用网上的图片路径
String data = JSONObject.toJSONString(ocrAlDto);
String ocrResult = OcrHttp.ocrpost(ocrRequestUrl, data);
Ocr ocr = JSONObject.parseObject(ocrResult, Ocr.class);
if (ocr == null) {
throw new RuntimeException("ocr识别失败。。请检查图片是否可以访问");
}
if (ocr.getContent() != null) {
String content = ocr.getContent().replaceAll("\n", "");
System.out.println(content);
}
}
我一直说的差距在哪里呢,差距就是矫正图片的角度,阿里的ocr识别不管你的图片文件歪到什么角度它到会帮你矫正到正面识别文字,而百度的只会帮你矫正90度和180度角,一旦角度倾斜明显,文字的顺序会整个乱掉

















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









