






一、Hadoop
1、分布式的运算存储系统
2、特点:扩容能力、高效率、低成本、可靠性
3、功能:
(1)海量数据的存储(HDFS)
(2)海量数据的分析(MapReduce)
(3)资源管理调度(YARN):Yet Another Resource Negotiator
4、Hadoop常用端口号?
| Hadoop2.0x | Hadoop3.0x | |
|---|---|---|
| HDFS端口 | 50070 | 9870 |
| MapReduce端口 | 8088 | 8088 |
二、HDFS
1、简介:HDFS是Hadoop的分布式文件系统
2、特点:高容错性、高吞吐量
3、读写流程
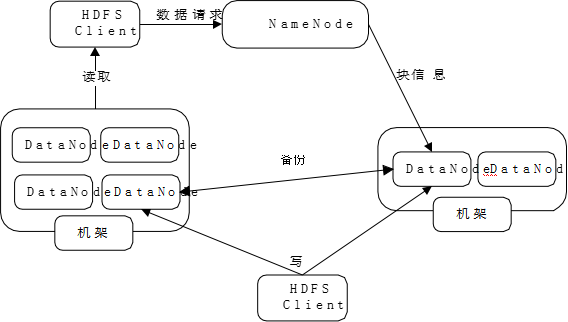
4、节点
| NamNode | HDFS 文件系统的管理节点 |
|---|---|
| DataNode | 提供真实文件数据的存储服务 |
三、MapReduce
1、运行过程
MapReduce 运行的时候,通过 Mapper 运行的任务读取 HDFS 中的数据文件,然后调用 自己的方法,处理数据,最后输出。Reducer 任务会接收 Mapper 任务输出的数据,作为自 己的输入数据,调用自己的方法,最后输出到 HDFS 的文件中。
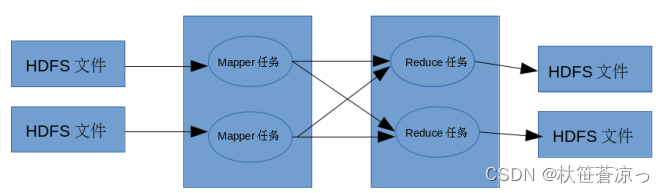
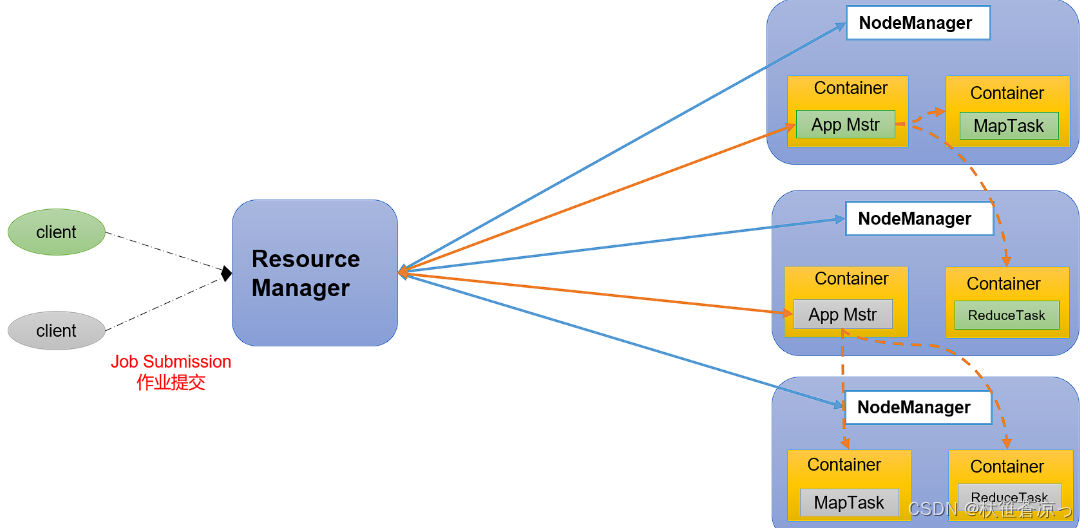
四、Yarn工作机制
1、Yarn调度器
FIFO 、Capacity Scheduler(容量调度器)和Fair Sceduler(公平调度器)
2、节点组件介绍
(1)ResourceManager:
- 处理客户端请求
- 监控NodeManager
- 启动监控ApplicationMaster
- 资源的分配与调度
(2)NodeManager
- 管理单个节点上的资源
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
(3)ApplicationMaster
- 为应用程序申请资源并分配给内部任务
- 任务的监控与容错
(4)container容器
- container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等
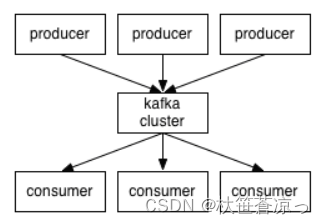
五、Kafka架构
1、简介
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景
2、特点
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
3、Kafka的使用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
4、Kakfa分区数
- 创建一个只有1个分区的topic。
- 测试这个topic的producer吞吐量和consumer吞吐量。
- 假设他们的值分别是Tp和Tc,单位可以是MB/s。
- 然后假设总的目标吞吐量是Tt,那么分区数 = Tt / min(Tp,Tc)。
例如:producer吞吐量 = 20m/s;consumer吞吐量 = 50m/s,期望吞吐量100m/s;
分区数 = 100 / 20 = 5分区
分区数一般设置为:3-10个
分区数不是越多越好,也不是越少越好,需要搭建完集群,进行压测,再灵活调整分区个数。
5、Kafka日志保存时间
默认保存7天;生产环境建议3天
6、Kafka的机器数量
Kafka机器数量 = 2 *(峰值生产速度 * 副本数 / 100)+ 1
7、Kafka与Flume比较
- flume:cloudera公司研发
- 适合多个生产者
- 适合下游数据消费者不多的情况
- 适合数据安全性要求不高的操作
- 适合与Hadoop生态圈对接的操作
- kafka:linkedin公司研发
- 适合数据下游消费众多的情况
- 适合数据安全性要求较高的操作,支持replication
8、Kafka高效读写数据是如何保证的?
- Kafka本身是分布式集群,可以采用分区技术,并行度高
- 读数据采用稀疏索引,可以快速定位要消费的数据
- 顺序写磁盘:Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。
- 页缓存 + 零拷贝技术
9、Kafka如何提升吞吐量:提高消费者吞吐量、提高生产者吞吐量、增加分区
六、Hive
1、简介
- Hive 本身是建立在 Hadoop 体系结构上的数据仓库基础构架,可以将结构化的数据文 件映射为一张数据库表,并提供完整的 ql 语句,把 ql 语句转化成 mapreduce 程序提交给 hadoop集群完成相关任务。
- Hive 的数据存储在 HDFS 中,大部分的计算、查询由 MapReduce 完成
2、hive与数据库的比较
- Hive 和数据库除了拥有类似的查询语言,再无类似之处。
- 数据存储位置
Hive 存储在 HDFS ;数据库将数据保存在块设备或者本地文件系统中。 - 数据更新
Hive中不建议对数据的改写;而数据库中的数据通常是需要经常进行修改的, - 执行延迟
Hive 执行延迟较高;数据库的执行延迟较低。当然,这个是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。 - 数据规模
Hive支持很大规模的数据计算;数据库可以支持的数据规模较小。
3、内部表和外部表区别
- 删除数据时:
- 内部表:元数据、原始数据,全删除
- 外部表:只删除元数据
4、Hive中4个By区别?
- Order By:全局排序,只有一个Reducer。
- Sort By:分区内有序。
- Distrbute By:类似MR中Partition,进行分区,结合sort by使用。
- Cluster By:当Distribute by和Sorts by字段相同时,可以使用Cluster by方式。
六、Spark
1、Spark和Hadoop的最大区别
- Hadoop主要解决,海量数据的存储和海量数据的分析计算。
- Spark主要解决海量数据的分析计算。
2、Spark常用端口号
- 4040 spark-shell任务端口
- 7077 内部通讯端口。类比Hadoop的8020/9000
- 8080 查看任务执行情况端口。类比Hadoop的8088
- 18080 历史服务器。类比Hadoop的19888
七、Flume
1、简介:flume是分布式的,可靠的,高可用的,用于对不同来源的大量的日志数据进行有效收集、聚集和移动,并以集中式的数据存储的系统;适用于多个生产者且下游消费者不多的情况。
2、组件介绍(source 、channel、sink)
- source组件是用来采集日志
- channel组件是用来缓冲日志的
- sink组件是用来保存日志;日志信息保存到hdfs、hive、hbase
此三组件被统称为agent(source +channel+sink)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









