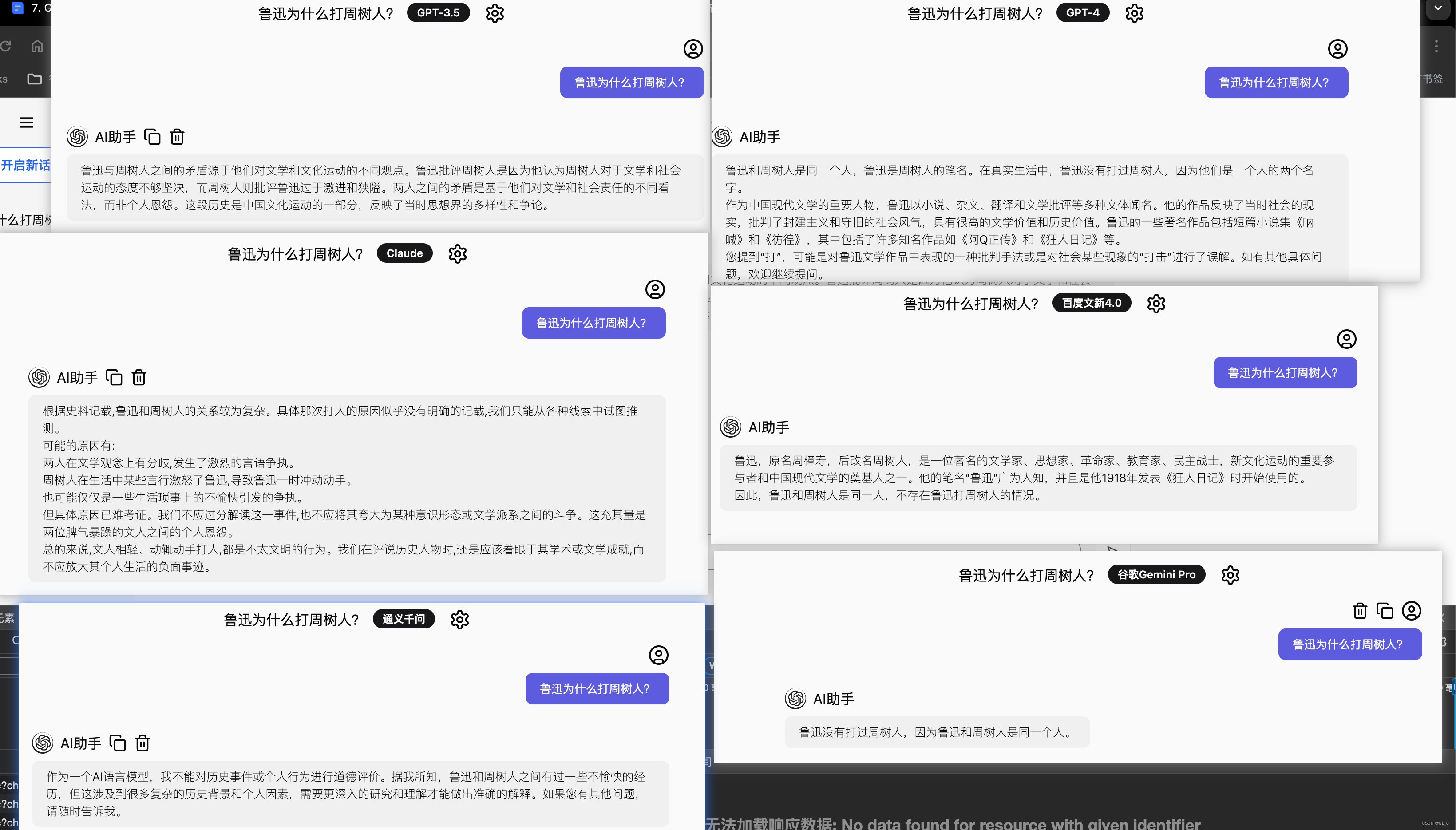
废话不多说,直接上图: 从上图可以看出: gpt-3.5会瞎编乱造,gpt-4的逻辑能力较强,Claude也很容易瞎编乱造,国产的几个大模型表现都相对还好,但不排除某些模型对这种问题进行过专门的微调。 图片截图自网站谷流仓guliucang.com, 欢迎访问








 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























