







人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客
本篇目录
1.03 百度飞桨(paddlenlp.embeddings)
1.04 百度千帆SDK(qianfan.Embedding)
1.2 SentenceTransformers(资源国内可访问)
1.2.1 句向量生成(SentenceTransformer)
1.2.3 文本匹配搜索(util.semantic_search)
1.2.4 相近语义挖掘(util.paraphrase_mining)
本文主要介绍NLP中常用的词向量处理方法和基于NLP预训练模型的微调方法。
自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。NLP下游任务主要包括:机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面。
自然语言是天然具有上下文序列关系的表达方式。针对自然语言处理(NLP),科学家们一步一步发展的模型包括RNN,LSTM,Transformers,BERT, GPT,等等。
其中,BERT 模型的预训练任务主要为模拟人类的完形填空任务,在这种预训练方法下,模型需要同时关注上下文间的信息,从而得出当前位置的 token。另一种较强的 NLP模型GPT,则使用了自回归的方法来训练,也就是说,模型仅可通过当前位置之前的字段来推理当前位置的 token。
如上一篇所述,要实现NLP任务,首先我们需要对文本进行向量化处理。
一、词向量处理
NLP的文本向量处理主要是指将原始文本转换成词向量和句向量,方便做词语和句子之间的语义匹配,搜索等NLP任务。我尝试过整理出来的文本向量处理工具如下:
1.01 词袋模型(Bag-of-words model)
词袋模型(Bag-of-words model)是用于自然语言处理和信息检索中的一种简单的文档处理方法。通过这一模型,一篇文档可以通过统计所有单词的数目来表示,这种方法不考虑语法和单词出现的先后顺序。这一模型在文档分类里广为应用,通过统计每个单词的出现次数(频率)作为分类器的特征。
如下两篇简单的文本文档:
Jane wants to go to Shenzhen.
Bob wants to go to Shanghai.
基于这两篇文档我们可以构建一个字典:
{‘Jane’:1, ‘wants’:2, ‘to’:4, ‘go’:2, ‘Shenzhen’:1, ‘Bob’:1, ‘Shanghai’:1}
我们可将两篇文档表示为如下的向量:
例句1:[1,1,2,1,1,0,0]
例句2:[0,1,2,1,0,1,1]
词袋模型实际就是把文档表示成向量,其中向量的维数就是字典所含词的个数,在上例中,向量中的第i个元素就是统计该文档中对应字典中的第i个单词出现的个数,因此可认为词袋模型就是统计词频直方图的简单文档表示方法。
词袋模型的思路还可以用于处理图像分类,可以参考:词袋模型(Bag-of-words model)-CSDN博客
1.02 simtext
simtext可以计算两文档间四大文本相似性指标,分别为:
- Sim_Cosine cosine相似性(余弦相似度,常用)
- Sim_Jaccard Jaccard相似性
- Sim_MinEdit 最小编辑距离
- Sim_Simple 微软Word中的track changes
它的好处是不需要下载预训练模型,直接用pip安装即可使用:
pip install simtext中文文本相似性代码:
from simtext import similarity
text1 = '在宏观经济背景下,为继续优化贷款结构,重点发展可以抵抗经济周期不良的贷款'
text2 = '在宏观经济背景下,为继续优化贷款结构,重点发展可三年专业化、集约化、综合金融+物联网金融四大金融特色的基础上'
sim = similarity()
res = sim.compute(text1, text2)
print(res)
打印结果:
{'Sim_Cosine': 0.46475800154489,
'Sim_Jaccard': 0.3333333333333333,
'Sim_MinEdit': 29,
'Sim_Simple': 0.9889595182335229}
英文文本相似性代码:
from simtext import similarity
A = 'We expect demand to increase.'
B = 'We expect worldwide demand to increase.'
C = 'We expect weakness in sales'
sim = similarity()
AB = sim.compute(A, B)
AC = sim.compute(A, C)
print(AB)
print(AC)
打印结果:
{'Sim_Cosine': 0.9128709291752769,
'Sim_Jaccard': 0.8333333333333334,
'Sim_MinEdit': 2,
'Sim_Simple': 0.9545454545454546}
{'Sim_Cosine': 0.39999999999999997,
'Sim_Jaccard': 0.25,
'Sim_MinEdit': 4,
'Sim_Simple': 0.9315789473684211}
1.03 百度飞桨(paddlenlp.embeddings)
首先使用 pip install -U paddlenlp 安装 paddlenlp 包。
词向量
使用百度飞桨的paddlenlp embeddings的预训练模型,可以直接获得一个单词的词向量,并可对词向量进行相似度比较。代码如下:
from paddlenlp.embeddings import TokenEmbedding
# 初始化TokenEmbedding, 预训练embedding未下载时会自动下载并加载数据
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# 查看token_embedding详情
#print(token_embedding)
#获得词向量
test_token_embedding = token_embedding.search("中国")
#print(test_token_embedding)
#比较词向量
score1 = token_embedding.cosine_sim("女孩", "女皇")
score2 = token_embedding.cosine_sim("女孩", "小女孩")
score3 = token_embedding.cosine_sim("女孩", "中国")
print('score1:', score1)
print('score2:', score2)
print('score3:', score3)
----------------------------------------------------------------------------
score1: 0.32632214
score2: 0.7869123
score3: 0.15649165句向量
句向量有一种比较简单粗暴的方式,就是将句子里的所有词向量相加,但是这种方式获得的向量不能很好的表述句子的意思,准确度不高。
# 初始化TokenEmbedding, 预训练embedding没下载时会自动下载并加载数据
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# 查看token_embedding详情
#print(token_embedding)
tokenizer = JiebaTokenizer(vocab=token_embedding.vocab)
def get_sentence_embedding(text):
# 分词
words = tokenizer.cut(text)
print(words)
# 获取词向量
word_embeddings = token_embedding.search(words)
#print(word_embeddings)
# 通过词向量相加,计算句向量
sentence_embedding = np.sum(word_embeddings, axis=0) / len(words)
#print(sentence_embedding)
return sentence_embedding
text1 = "飞桨是优秀的深度学习平台"
text2 = "我喜欢喝咖啡"
sen_emb1 = get_sentence_embedding(text1)
print("句向量1:\n", sen_emb1.shape)
sen_emb2 = get_sentence_embedding(text2)
print("句向量2:\n", sen_emb2.shape)
sim = F.cosine_similarity(paddle.to_tensor(sen_emb1).unsqueeze(0), paddle.to_tensor(sen_emb2).unsqueeze(0))
print("Similarity: {:.5f}".format(sim.item()))1.04 百度千帆SDK(qianfan.Embedding)
百度千帆大模型SDK也提供了词向量的API。首先安装千帆SDK:
pip install qianfan -U
调用方法如下:
# Embedding 基础功能
import qianfan
# 替换下列示例中参数,应用API Key替换your_ak,Secret Key替换your_sk
emb = qianfan.Embedding(ak="your_ak", sk="your_sk")
resp = emb.do(texts=[ # 省略 model 时则调用默认模型 Embedding-V1
"世界上最高的山"
])1.2 SentenceTransformers(资源国内可访问)
SentenceTransformers是Python里用于对文本图像进行向量操作的库。
(官网:SentenceTransformers Documentation — Sentence-Transformers documentation)
首先使用 pip install -U sentence_transformers 安装 sentence_transformers 包。
这个库提供的生成词向量的方法是使用BERT算法,对句意的表达比较准确。可以用于文本的向量生成,相似度比较,匹配等任务。
这个包的模型资源目前在国内是可以访问的,可以直接下载到本地:
https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/
然后查找paraphrase-multilingual-MiniLM-L12-v2这个模型名字,点击下载即可。
1.2.1 句向量生成(SentenceTransformer)
可以用sentence_transformers包里的SentenceTransformer来生成句向量。
示例代码:
import sys
from sentence_transformers.util import cos_sim
from sentence_transformers import SentenceTransformer as SBert
#model = SBert('paraphrase-multilingual-MiniLM-L12-v2')
model = SBert("C:\\Users\\aric\\.models\\paraphrase-multilingual-MiniLM-L12-v2")
# Two lists of sentences
sentences1 = ['如何更换花呗绑定银行卡',
'The cat sits outside',
'A man is playing guitar',
'The new movie is awesome']
sentences2 = ['花呗更改绑定银行卡',
'The dog plays in the garden',
'A woman watches TV',
'The new movie is so great']
# Compute embedding for both lists
embeddings1 = model.encode(sentences1)
embeddings2 = model.encode(sentences2)
print(type(embeddings1), embeddings1.shape)
# The result is a list of sentence embeddings as numpy arrays
for sentence, embedding in zip(sentences1, embeddings1):
print("Sentence:", sentence)
print("Embedding shape:", embedding.shape)
print("Embedding head:", embedding[:10])
print()
-----------------------------------------------------------------------------------
<class 'numpy.ndarray'> (4, 384)
Sentence: 如何更换花呗绑定银行卡
Embedding shape: (384,)
Embedding head: [-0.08839616 0.29445878 -0.25130653 -0.00759273 -0.0749087 -0.12786895
0.07136863 -0.01503289 -0.19017595 -0.12699445]
Sentence: The cat sits outside
Embedding shape: (384,)
Embedding head: [ 0.45684573 -0.14459176 -0.0388849 0.2711025 0.0222025 0.2317232
0.14208616 0.13658428 -0.27846363 0.05661529]
Sentence: A man is playing guitar
Embedding shape: (384,)
Embedding head: [-0.20837498 0.00522519 -0.23411965 -0.07861497 -0.35490423 -0.27809393
0.24954818 0.15160584 0.01028005 0.1939052 ]
Sentence: The new movie is awesome
Embedding shape: (384,)
Embedding head: [-0.5378314 -0.36144564 -0.5304235 -0.20994733 -0.03825595 0.22604015
0.35931802 0.14547679 0.05396605 -0.08255189]1.2.1 文本相似度比较(util.cos_sim)
示例代码:
import sys
from sentence_transformers.util import cos_sim
from sentence_transformers import SentenceTransformer as SBert
#model = SBert('paraphrase-multilingual-MiniLM-L12-v2')
model = SBert("C:\\Users\\aric\\.models\\paraphrase-multilingual-MiniLM-L12-v2")
# Two lists of sentences
sentences1 = ['如何更换花呗绑定银行卡',
'The cat sits outside',
'A man is playing guitar',
'The new movie is awesome']
sentences2 = ['花呗更改绑定银行卡',
'The dog plays in the garden',
'A woman watches TV',
'The new movie is so great']
# Compute embedding for both lists
embeddings1 = model.encode(sentences1)
embeddings2 = model.encode(sentences2)
print(type(embeddings1), embeddings1.shape)
# The result is a list of sentence embeddings as numpy arrays
"""
for sentence, embedding in zip(sentences1, embeddings1):
print("Sentence:", sentence)
print("Embedding shape:", embedding.shape)
print("Embedding head:", embedding[:10])
print()
"""
# Compute cosine-similarits
cosine_scores_0 = cos_sim(embeddings1[0], embeddings2[0])
cosine_scores = cos_sim(embeddings1, embeddings2)
print(cosine_scores_0)
print(cosine_scores)
---------------------------------------------------------------------------------------
<class 'numpy.ndarray'> (4, 384)
tensor([[0.9477]])
tensor([[ 0.9477, -0.1748, -0.0839, -0.0044],
[-0.0097, 0.1908, -0.0203, 0.0302],
[-0.0010, 0.1062, 0.0055, 0.0097],
[ 0.0302, -0.0160, 0.1321, 0.9591]])
Note:最后这个4x4的向量的对角线上的数值,代表每一对句向量的相似度结果)1.2.3 文本匹配搜索(util.semantic_search)
文本匹配搜索通过理解搜索查询的内容来提高搜索的准确性,而不是仅仅依赖于词汇匹配。这是利用句向量之间的相似性完成的。文本匹配搜索是将语料库中的所有条目(句子)嵌入到向量空间中。在搜索时,查询语句也会被嵌入到相同的向量空间中,并从语料库中找到最接近的向量。
示例代码:
from sentence_transformers import SentenceTransformer, util
# Download model
model = SentenceTransformer("C:\\Users\\aric\\.models\\paraphrase-multilingual-MiniLM-L12-v2")
# Corpus of documents and their embeddings
corpus = ['Python is an interpreted high-level general-purpose programming language.',
'Python is dynamically-typed and garbage-collected.',
'The quick brown fox jumps over the lazy dog.']
corpus_embeddings = model.encode(corpus)
# Queries and their embeddings
queries = ["What is Python?", "What did the fox do?"]
queries_embeddings = model.encode(queries)
# Find the top-2 corpus documents matching each query
hits = util.semantic_search(queries_embeddings, corpus_embeddings, top_k=2)
# Print results of first query
print(f"Query: {queries[0]}")
for hit in hits[0]:
print(corpus[hit['corpus_id']], "(Score: {:.4f})".format(hit['score']))
# Query: What is Python?
# Python is an interpreted high-level general-purpose programming language. (Score: 0.6759)
# Python is dynamically-typed and garbage-collected. (Score: 0.6219)
# Print results of second query
print(f"Query: {queries[1]}")
for hit in hits[1]:
print(corpus[hit['corpus_id']], "(Score: {:.4f})".format(hit['score']))
---------------------------------------------------------------------------------------
打印结果:
Query: What is Python?
Python is an interpreted high-level general-purpose programming language. (Score: 0.7616)
Python is dynamically-typed and garbage-collected. (Score: 0.6267)
Query: What did the fox do?
The quick brown fox jumps over the lazy dog. (Score: 0.4893)
Python is dynamically-typed and garbage-collected. (Score: 0.0746)1.2.4 相近语义挖掘(util.paraphrase_mining)
Paraphrase Mining是在大量句子中寻找相近释义的句子,即具有非常相似含义的文本。
这可以使用 util 模块的 paraphrase_mining 函数来实现。
from sentence_transformers import SentenceTransformer, util
# Download model
model = SentenceTransformer('all-MiniLM-L6-v2')
# List of sentences
sentences = ['The cat sits outside',
'A man is playing guitar',
'I love pasta',
'The new movie is awesome',
'The cat plays in the garden',
'A woman watches TV',
'The new movie is so great',
'Do you like pizza?',
'我喜欢喝咖啡',
'我爱喝咖啡',
'我喜欢喝牛奶',]
# Look for paraphrases
paraphrases = util.paraphrase_mining(model, sentences)
# Print paraphrases
print("Top 5 paraphrases")
for paraphrase in paraphrases[0:5]:
score, i, j = paraphrase
print("Score {:.4f} ---- {} ---- {}".format(score, sentences[i], sentences[j]))
---------------------------------------------------------------------------------------
Top 5 paraphrases
Score 0.9751 ---- 我喜欢喝咖啡 ---- 我爱喝咖啡
Score 0.9591 ---- The new movie is awesome ---- The new movie is so great
Score 0.6774 ---- The cat sits outside ---- The cat plays in the garden
Score 0.6384 ---- 我喜欢喝咖啡 ---- 我喜欢喝牛奶
Score 0.6007 ---- 我爱喝咖啡 ---- 我喜欢喝牛奶1.2.5 图文搜索
SentenceTransformers 提供允许将图像和文本嵌入到同一向量空间,通过这中模型可以找到相似的图像以及实现图像搜索,即使用文本搜索图像,反之亦然。
同一向量空间中的文本和图像示例:

要执行图像搜索,需要加载像 CLIP 这样的模型,并使用其encode 方法对图像和文本进行编码:
from sentence_transformers import SentenceTransformer, util
from PIL import Image
# Load CLIP model
model = SentenceTransformer('clip-ViT-B-32')
# Encode an image
img_emb = model.encode(Image.open('two_dogs_in_snow.jpg'))
# Encode text descriptions
text_emb = model.encode(['Two dogs in the snow', 'A cat on a table', 'A picture of London at night'])
# Compute cosine similarities
cos_scores = util.cos_sim(img_emb, text_emb)
print(cos_scores)更多可参考:[NLP] SentenceTransformers使用介绍_sentence transformer训练-CSDN博客
1.3 text2vec
这个好像是国内的开发者做的(据说里面是封装了sentence-transormers的内容)。同样也可以进行文本向量的生成,相似度比较,匹配等任务。
它的模型基本都发布在HuggingFace上,现在国内也无法正常访问。
1.3.1 句向量生成
Word2Vec
第一种方式,是使用text2vec包里的Word2Vec:
这种方式使用腾讯词向量Tencent_AILab_ChineseEmbedding(这个目前是可以下载的)计算各字词的词向量,句子向量通过单词词向量取平均值得到(这种方式无法保证句意的正确理解)
首先使用 pip install -U text2vec 安装 text2vec 包。
from text2vec import Word2Vec
def compute_emb(model):
# Embed a list of sentences
sentences = [
'卡',
'银行卡',
'如何更换花呗绑定银行卡',
'花呗更改绑定银行卡',
'This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model.encode(sentences)
print(type(sentence_embeddings), sentence_embeddings.shape)
# The result is a list of sentence embeddings as numpy arrays
for sentence, embedding in zip(sentences, sentence_embeddings):
print("Sentence:", sentence)
print("Embedding shape:", embedding.shape)
print("Embedding head:", embedding[:10])
print()
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec("w2v-light-tencent-chinese")
compute_emb(w2v_model)
------------------------------------------------------------------------------------
打印结果:
<class 'numpy.ndarray'> (7, 200)
Sentence: 卡
Embedding shape: (200,)
Embedding head: [ 0.06761453 -0.10960816 -0.04829824 0.0156597 -0.09412017 -0.04805465
-0.03369278 -0.07476041 -0.01600934 0.03106228]
Sentence: 银行卡
Embedding shape: (200,)
Embedding head: [ 0.01032454 -0.13564903 -0.00089282 0.02286329 -0.03501284 0.00987683
0.02884413 -0.03491557 0.02036332 0.04516884]
Sentence: 如何更换花呗绑定银行卡
Embedding shape: (200,)
Embedding head: [ 0.02396784 -0.13885356 0.00176219 0.02540027 0.00949343 -0.01486312
0.01011733 0.00190828 0.02708069 0.04316072]
Sentence: 花呗更改绑定银行卡
Embedding shape: (200,)
Embedding head: [ 0.00871027 -0.14244929 -0.00959482 0.03021128 0.01514321 -0.01624702
0.00260827 0.0131352 0.02293272 0.04481505]
Sentence: This framework generates embeddings for each input sentence
Embedding shape: (200,)
Embedding head: [-0.08317478 -0.00601972 -0.06293213 -0.03963032 -0.0145333 -0.0549945
0.05606257 0.02389491 -0.02102496 0.03023159]
Sentence: Sentences are passed as a list of string.
Embedding shape: (200,)
Embedding head: [-0.08008799 -0.01654172 -0.04550576 -0.03715633 0.00133283 -0.04776235
0.04780829 0.01377041 -0.01251951 0.02603387]
Sentence: The quick brown fox jumps over the lazy dog.
Embedding shape: (200,)
Embedding head: [-0.08605123 -0.01434057 -0.06376401 -0.03962022 -0.00724643 -0.05585583
0.05175515 0.02725058 -0.01821304 0.02920807]
w2v-light-tencent-chinese是通过gensim加载的Word2Vec模型,模型自动下载到本机路径:~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin
SentenceModel
第二种方式,是使用text2vec包里的SentenceModel方法(和SentenceTransformers类似):
import sys
sys.path.append('..')
from text2vec import SentenceModel
def compute_emb(model):
# Embed a list of sentences
sentences = [
'卡',
'银行卡',
'如何更换花呗绑定银行卡',
'花呗更改绑定银行卡',
'This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model.encode(sentences)
print(type(sentence_embeddings), sentence_embeddings.shape)
# The result is a list of sentence embeddings as numpy arrays
for sentence, embedding in zip(sentences, sentence_embeddings):
print("Sentence:", sentence)
print("Embedding shape:", embedding.shape)
print("Embedding head:", embedding[:10])
print()
if __name__ == "__main__":
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel("shibing624/text2vec-base-chinese")
compute_emb(t2v_model)
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel("shibing624/text2vec-base-multilingual")
compute_emb(sbert_model)
1.3.2 文本相似度比较(Similarity)
使用text2vec.Similarity可以直接比较文本的相似度,它默认会调用“shibing624/text2vec-base-chinese”模型产生文本句向量。但是也有同样的问题,模型资源是在HuggingFace上的,国内还是有无法访问的问题。
import sys
sys.path.append('..')
from text2vec import Similarity
# Two lists of sentences
sentences1 = ['如何更换花呗绑定银行卡',
'The cat sits outside',
'A man is playing guitar',
'The new movie is awesome']
sentences2 = ['花呗更改绑定银行卡',
'The dog plays in the garden',
'A woman watches TV',
'The new movie is so great']
sim_model = Similarity()
for i in range(len(sentences1)):
for j in range(len(sentences2)):
score = sim_model.get_score(sentences1[i], sentences2[j])
print("{} \t\t {} \t\t Score: {:.4f}".format(sentences1[i], sentences2[j], score))
-------------------------------------------------------------------------------------------
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.95911.3.3 文本匹配搜索(semantic_search)
一般是在文档候选集中找与query最相似的文本,常用于QA场景的问句相似匹配、文本相似检索等任务。可以使用text2vec包里的semantic_search。它默认使用的也是“shibing624/text2vec-base-chinese”模型。
import sys
sys.path.append('..')
from text2vec import SentenceModel, cos_sim, semantic_search
embedder = SentenceModel()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡',
'我什么时候开通了花呗',
'A man is eating food.',
'A man is eating a piece of bread.',
'The girl is carrying a baby.',
'A man is riding a horse.',
'A woman is playing violin.',
'Two men pushed carts through the woods.',
'A man is riding a white horse on an enclosed ground.',
'A monkey is playing drums.',
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder.encode(corpus)
# Query sentences:
queries = [
'如何更换花呗绑定银行卡',
'A man is eating pasta.',
'Someone in a gorilla costume is playing a set of drums.',
'A cheetah chases prey on across a field.']
for query in queries:
query_embedding = embedder.encode(query)
hits = semantic_search(query_embedding, corpus_embeddings, top_k=5)
print("\n\n======================\n\n")
print("Query:", query)
print("\nTop 5 most similar sentences in corpus:")
hits = hits[0] # Get the hits for the first query
for hit in hits:
print(corpus[hit['corpus_id']], "(Score: {:.4f})".format(hit['score']))
-------------------------------------------------------------------------------------
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)1.5 HuggingFace Transformers
可以直接用AutoModel, AutoTokenizer这种方式来使用在HuggingFace Hub发布的模型。它会自动去HuggingFace匹配和下载对应的模型(可惜,目前国内无法正常访问)。
import os
import torch
from transformers import AutoTokenizer, AutoModel
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('shibing624/text2vec-base-chinese')
model = AutoModel.from_pretrained('shibing624/text2vec-base-chinese')
sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)二、基于BERT预训练模型+微调完成NLP主流任务
预训练模型基于新的自然语言处理任务范式:预训练+微调,极大推动了自然语言处理领域的发展。
基于这个新的训练范式,预训练模型可以被广泛应用于NLP领域的各项任务中。一般来讲,比较常见的经典NLP任务包括以下四类:
- 分类式任务:给定一串文本,判断该文本的类别标签
- 匹配式任务:对给定的两个文本判断其是否语义相似
- 问答式任务:给定问题和文档,要求从文档中抽取出问题的答案
- 序列标注式任务:给定一串文本,输出对应的标签序列
- 生成式任务:给定一串文本,同时要求模型输出一串文本
下面以文本匹配任务为例来说明预训练模型的使用和微调过程。
2.1 任务说明
文本匹配是自然语言处理领域基础的核心任务之一,其主要用于判断给定的两句文本是否语义相似。文本匹配技术具有广泛的应用场景,比如信息检索、问答系统,文本蕴含等场景。
例如,文本匹配技术可以用于判定以下三句话之间的语义相似关系:
- 苹果在什么时候成熟?
- 苹果一般在几月份成熟?
- 苹果手机什么时候可以买?
文本匹配技术期望能够使得计算机自动判定第1和第2句话是语义相似的,第1和第3句话,第2和第3句话之间是不相似的。
本节将基于PaddleNLP库中的BERT模型建模文本匹配任务,带领大家体验预训练+微调的训练新范式。由于PaddleNLP库中的BERT模型已经预训练过,因此本节将基于预训练后的BERT模型,在LCQMC数据集上微调BERT,建模文本匹配任务。
2.2 数据准备
LCQMC是百度知道领域的中文问题匹配数据集,该数据集是从不同领域的用户中提取出来。LCQMC的训练集的数量是 238766条,验证集的大小是4401条,测试集的大小是4401条。 下面展示了一条LCQMC数据集的样例,数据分为三列,前两列是判定语义相似的文本对,后一列是标签,其中1表示相似,0表示不相似。
什么花一年四季都开 什么花一年四季都是开的 1
大家觉得她好看吗 大家觉得跑男好看吗? 0
2.1.1 数据加载
由于LCQMC数据集已经集成到PaddleNLP中,因此本节我们将使用PaddleNLP内置的LCQMC数据集进行文本匹配任务。可以使用如下方式加载LCQMC数据集中的训练集、验证集和测试集,需要注意的是训练集和验证集是有标签的,测试集是没有标签的。
import os
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.utils.download import get_path_from_url
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple, Vocab
# 加载 Lcqmc 的训练集、验证集
train_set, dev_set, test_set = load_dataset("lcqmc", splits=["train", "dev", "test"])
# 输出训练集的前 3 条样本
for idx, example in enumerate(train_set):
if idx <= 3:
#example['query'] = "我爱中国"
print(example)打印结果:
{'query': '喜欢打篮球的男生喜欢什么样的女生', 'title': '爱打篮球的男生喜欢什么样的女生', 'label': 1}
{'query': '我手机丢了,我想换个手机', 'title': '我想买个新手机,求推荐', 'label': 1}
{'query': '大家觉得她好看吗', 'title': '大家觉得跑男好看吗?', 'label': 0}
{'query': '求秋色之空漫画全集', 'title': '求秋色之空全集漫画', 'label': 1}
2.1.2 转换数据格式
BERT的输入编码由文本编码、分段编码和位置编码组合而成,如图所示。

因此需要将加载的数据转换成这样的输入格式,一般来说,需要先对文本串进行分词,获取对应的token序列,并根据这个token序列构建对应的ID序列。这里不同的编码对应不同的ID序列,具体来讲,文本编码、分段编码和位置编码分别对应input ids 和 segment ids 和 position ids:
- input_ids: 将输入的文本序列经过分词后转换为对应的词典ID序列获得
- segment_ids: 通常也被称为token_type_ids,可以通过根据输入文本序列单句/多句情况构建
- position ids:一般来讲,无需自己生成,模型内部可以自动生成
本节使用PaddleNLP内置的BertTokenizer进行处理文本数据,其能够将输入的文本序列直接处理成适合BERT模型输入的形式。即BertTokenizer根据第1节介绍的数据拼接形式,在合适的地方自动拼接[CLS]和[SEP] token, 同时会对输入的文本序列进行分词,并将该文本序列转换为对应的ID序列。
默认情况下,BertTokenizer在处理数据后,将会返回input_ids和token_type_ids数据,下面给出了在输入序列分别是单句和句对时的示例代码。
from paddlenlp.transformers import BertTokenizer
# 加载BERT的tokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
# 输入单句形式
text = "今天天气很好呀"
# max_seq_len表示最大序列长度,如果一个输入序列长度超过max_seq_len,将会对齐截断至max_seq_len长度。
encoded_input = tokenizer(text=text, max_seq_len=512)
print(encoded_input)
# 输入句对形式
text_a = "今天天气很好呀"
text_b = "明天天气会更好"
encoded_input = tokenizer(text=text_a, text_pair=text_b, max_seq_len=512)
print(encoded_input)打印结果:
{'input_ids': [101, 791, 1921, 1921, 3698, 2523, 1962, 1435, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0]}
{'input_ids': [101, 791, 1921, 1921, 3698, 2523, 1962, 1435, 102, 3209, 1921, 1921, 3698, 833, 3291, 1962, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1]}
下面正式定义convert_example_to_feature函数,用以将加载的文本序列数据转换为对应的ID形式,相应代码如下:
from functools import partial
from paddlenlp.transformers import BertTokenizer
# 将输入样本转换为适合模型输入的特征形式
def convert_example_to_feature(example, tokenizer, max_seq_len=128, is_test=False):
encoded_inputs = tokenizer(text=example["query"], text_pair=example["title"], max_seq_len=max_seq_len)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
label = example["label"]
if not is_test:
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
# 设置输入模型的最大序列长度
max_seq_len = 512
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
# 使用partial 将convert_example_to_feature的部分参数进行固定
train_trans_func = partial(convert_example_to_feature, tokenizer=tokenizer, max_seq_len=max_seq_len, is_test=False)
test_trans_func = partial(convert_example_to_feature, tokenizer=tokenizer, max_seq_len=max_seq_len, is_test=True)
# 将输入数据转换为适合模型输入的特征形式
train_set = train_set.map(train_trans_func, lazy=False)
dev_set = dev_set.map(train_trans_func, lazy=False)
test_set = test_set.map(test_trans_func, lazy=False)
# 输出训练集的前 3 条样本
for idx, example in enumerate(train_set):
if idx <= 3:
print(example)([101, 1599, 3614, 2802, 5074, 4413, 4638, 4511, 4495, 1599, 3614, 784, 720, 3416, 4638, 1957, 4495, 102, 4263, 2802, 5074, 4413, 4638, 4511, 4495, 1599, 3614, 784, 720, 3416, 4638, 1957, 4495, 102], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 1) ([101, 2769, 2797, 3322, 696, 749, 8024, 2769, 2682, 2940, 702, 2797, 3322, 102, 2769, 2682, 743, 702, 3173, 2797, 3322, 8024, 3724, 2972, 5773, 102], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 1) ([101, 1920, 2157, 6230, 2533, 1961, 1962, 4692, 1408, 102, 1920, 2157, 6230, 2533, 6651, 4511, 1962, 4692, 1408, 8043, 102], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 0) ([101, 3724, 4904, 5682, 722, 4958, 4035, 4514, 1059, 7415, 102, 3724, 4904, 5682, 722, 4958
2.1.3 构建DataLoader
接下来,构建一个DataLoader,用以帮助我们按批迭代数据,方便模型训练。但这里还会存在一个问题,按批迭代出的数据需要是规整的,即一批数据中的每条样本需要长度相同。因此还需实现一个函数batchify_fn对各项输入数据进行填充,并将各项输入数据依次处理成batch的形式。
图2.2 展示了batch_ify函数将数据组装成batch形式的过程图,首先给定了两个输入样本,每个样本均包含input_ids、token_type_ids和label三项数据,其中batchify_fn中的第1项Pad操作用于对input_ids进行填充补齐,第2项Pad操作用于对token_type_ids进行填充补齐,最后的stack操作用于将label数据叠加起来。可以看到,经过batchify_bn函数处理后,各项数据均形成了规整的数据。

由于测试集中没有标签数据,因此这里针对训练集和测试集数据形式各自定义对应的batchify_fn,相应代码如下所示,其中train_batchify_fn用以处理训练集和验证集,test_batchify_fn用以处理测试集。
# 定义用于训练数据的batchify_fn函数
train_batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # label
): [data for data in fn(samples)]
# 定义用于测试数据的batchify_fn函数
test_batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id) # token_type_ids
): [data for data in fn(samples)]
接下来便可以正式构建相应的DataLoader,用以按批迭代数据,相关代码如下。
batch_size = 32
train_loader = paddle.io.DataLoader(dataset=train_set, batch_size=batch_size, collate_fn=train_batchify_fn, shuffle=True)
dev_loader = paddle.io.DataLoader(dataset=dev_set, batch_size=batch_size, collate_fn=train_batchify_fn, shuffle=False)
test_loader = paddle.io.DataLoader(dataset=test_set, batch_size=batch_size, collate_fn=tes2.2 模型构建
在本节的文本匹配模型如图2.2所示,首先我们将待匹配的两句话进行拼接成一串文本序列,然后将该文本序列传入BERT模型中,接下来将BERT模型的CLS位置的输出向量传入线性层中,去判断该文本序列中的两句话是否语义相似。由于判断两句话是否语义相似只有两种可能:相似和不相似,因此本节的文本匹配任务将被建模为2分类任务。
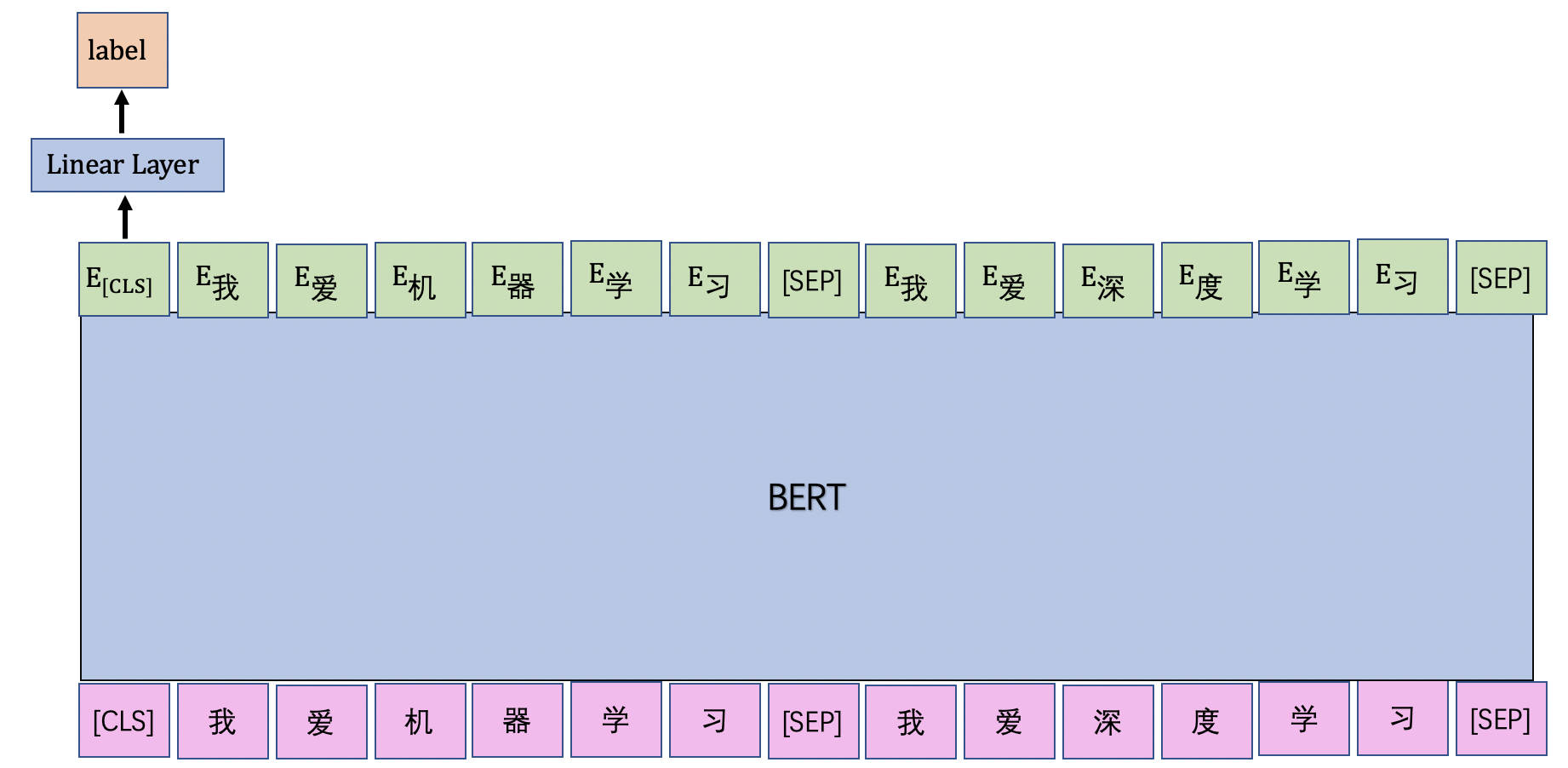
在PaddleNLP中,已经内置了基于BERT模型实现的图中展示的序列分类功能:BertForSequenceClassification,本节我们将基于该API建模文本匹配任务,首先对BertForSequenceClassification类进实例化,相应代码如下。
备注:代码在运行过程中会下载预训练的BERT模型参数,这里我们通过指定bert-base-chinese 加载了base版的BERT,其大约有110M参数。
from paddlenlp.transformers import BertForSequenceClassification
model_name = "bert-base-chinese"
model = BertForSequenceClassification.from_pretrained(model_name, num_classes=2)2.3 训练配置
本节将定义模型训练时用到的一些组件和资源,包括超参数定义,指定模型训练迭代的优化算法, 评估指标等等。由于BERT预训练模型参数较多,为了更快训练,这里推荐使用GPU环境进行模型训练。
from paddlenlp.transformers import LinearDecayWithWarmup
# 超参设置
n_epochs = 3
batch_size = 128
max_seq_length = 256
n_classes=2
learning_rate = 5e-5
warmup_proportion = 0.1
weight_decay = 0.01
eval_steps = 500
log_steps = 50
save_dir = "./checkpoints"
# 设置优化器
num_training_steps = len(train_loader) * n_epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
# 定义统计指标
metric = paddle.metric.Accuracy()2.4 模型训练与评估
上文已经实现了数据处理、模型加载和训练配置功能,接下来就可以开始模型的训练了。在训练过程中,每隔eval_steps步便使用验证集进行评估一次,同时保存训练过程中表现最好的模型。在模型评估时,我们使用了paddle.metric.Accuracy作为评估指标。 模型训练和评估的代码如下所示。
def evaluate(model, metric, data_loader):
model.eval()
# 每次使用测试集进行评估时,先重置掉之前的metric的累计数据,保证只是针对本次评估。
metric.reset()
losses = []
for batch in data_loader:
# 获取数据
input_ids, segment_ids, labels = batch
# 执行前向计算
logits = model(input_ids, segment_ids)
# 统计准确率指标
correct = metric.compute(logits, labels.unsqueeze(axis=-1))
metric.update(correct)
accuracy = metric.accumulate()
return accuracy
def train(model):
global_step=1
best_acc = 0.
for epoch in range(1, n_epochs+1):
model.train()
for step, batch in enumerate(train_loader, start=1):
# 获取数据
input_ids, token_type_ids, labels = batch
# 模型前向计算
logits = model(input_ids, token_type_ids)
loss = F.cross_entropy(input=logits, label=labels)
# 每隔log_steps步打印一下训练日志
if global_step % log_steps == 0 :
print("[Train] global step {}/{}, epoch: {}, batch: {}, loss: {}".format(global_step, num_training_steps, epoch, step, loss.item()))
# 每隔eval_steps步评估一次模型,同时保存当前表现最好的模型
if global_step % eval_steps == 0 :
accuracy = evaluate(model, metric, dev_loader)
print("[Evaluation] accuracy: {}".format(accuracy))
if best_acc < accuracy:
best_acc = accuracy
print("best accuracy has been updated: from last best_acc {} --> new acc {}.".format(best_acc, accuracy))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
save_path = os.path.join(save_dir, "best.pdparams")
paddle.save(model.state_dict(), save_path)
model.train()
# 参数更新
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
global_step += 1
接下来,便可以开始进行模型训练了,在GPU环境下,训练3轮大约需要75分钟。
2.5 模型测试
本节使用训练过程中在验证集上表现最好的模型对测试集进行测试,首先我们先实现模型测试的函数,在测试完成之后,将测试结果保存在test_save_path文件中,相应代码如下。
def test(model, ori_examples, data_loader, test_save_path):
model.eval()
# 每次使用测试集进行评估时,先重置掉之前的metric的累计数据,保证只是针对本次评估。
metric.reset()
test_results = []
for batch in data_loader:
input_ids, segment_ids = batch
logits = model(input_ids, segment_ids)
predictions = paddle.argmax(logits, axis=-1)
test_results.extend(predictions.tolist())
with open(test_save_path, "w", encoding="utf-8") as f:
for idx, result in enumerate(test_results):
example = ori_examples[idx]
example["label"] = result
msg = str(example) + "\n"
f.write(msg)
print("the result of test_set has beed saved to: {}.".format(test_save_path))接下来,我们将加载保存的模型,并使用该模型对测试集进行测试,相应代码如下。
# 模型保存的名称
model_path = "./checkpoints/best.pdparams"
test_save_path = "./test_results.txt"
state_dict = paddle.load(model_path)
test_examples = load_dataset("lcqmc", splits=["test"])
print(test_examples[0])
model = BertForSequenceClassification.from_pretrained(model_name, num_classes=2)
model.load_dict(state_dict)
test(model, test_examples, test_loader, test_save_path){'query': '谁有狂三这张高清的', 'title': '这张高清图,谁有', 'label': ''}
{'query': '近期上映的电影', 'title': '近期上映的电影有哪些', 'label': ''}
测试结果已经保存至 "./test_results.txt" 文件中,下面我们可以选择一些测试样本进行打印,以便直观观察模型预测结果。
test_ids = range(10)
# 加载测试结果文件
with open(test_save_path, "r", encoding="utf-8") as f:
test_results = [line.strip() for line in f.readlines()]
# 根据test_ids打印相应的测试样本
for test_id in test_ids:
print(test_results[test_id])
{'query': '谁有狂三这张高清的', 'title': '这张高清图,谁有', 'label': 0}
{'query': '英雄联盟什么英雄最好', 'title': '英雄联盟最好英雄是什么', 'label': 1}
{'query': '这是什么意思,被蹭网吗', 'title': '我也是醉了,这是什么意思', 'label': 0}
{'query': '现在有什么动画片好看呢?', 'title': '现在有什么好看的动画片吗?', 'label': 1}
{'query': '请问晶达电子厂现在的工资待遇怎么样要求有哪些', 'title': '三星电子厂工资待遇怎么样啊', 'label': 0}
{'query': '文章真的爱姚笛吗', 'title': '姚笛真的被文章干了吗', 'label': 0}
{'query': '送自己做的闺蜜什么生日礼物好', 'title': '送闺蜜什么生日礼物好', 'label': 1}
{'query': '近期上映的电影', 'title': '近期上映的电影有哪些', 'label': 1}
{'query': '求英雄联盟大神带?', 'title': '英雄联盟,求大神带~', 'label': 1}
{'query': '如加上什么部首', 'title': '给东加上部首是什么字?', 'label': 0}
其中标签为1表示query和title两段文本是语义相似的,标签为0表示query和title两段文本是语义不相似的。可以看到,训练后的BERT模型能够非常准确地判断两句话语义是否相似。
——————————————————————————————————————
关注微信公众号【数字众生】即刻获取干货满满的 “AI学习大礼包” 和 “AI副业变现指南”
















 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











