






学习心得:计算机视觉之算法基础与OpenMMLab入门
注:基于子豪兄的讲解,我重点发散了计算机视觉之算法基础的相关部分,主要参考的是我现有的笔记
机器学习的本质
简单问题的学习
简单问题的学习过程是寻求最拟合方程 l ( x ) l(x) l(x)的过程(以不同面积房价预测为例)
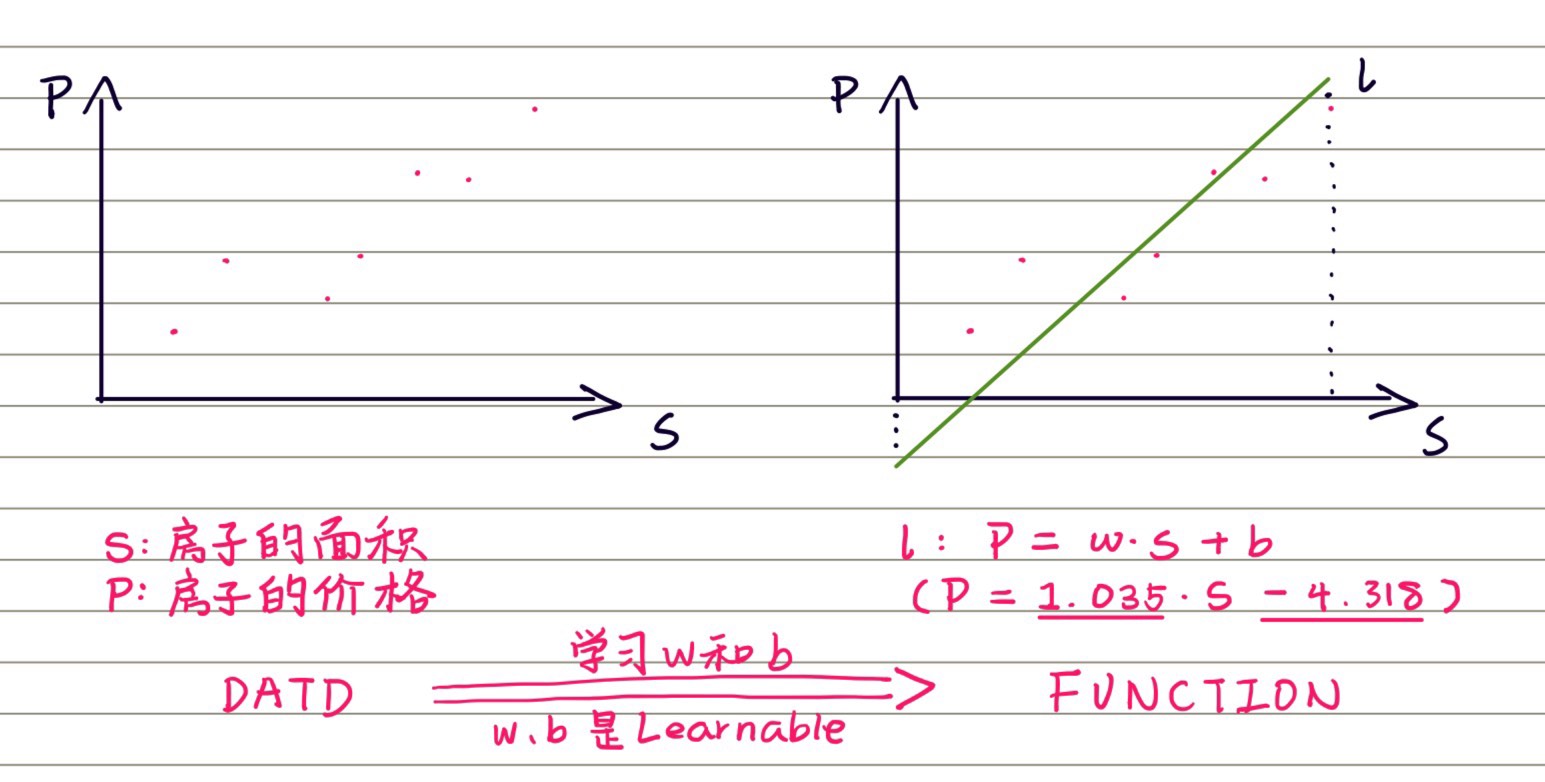
其中w、b是Learnable,代表了其对于预测精度的决定性,也代表了它是后期得到的,经优化确定之后模型就有了最好的预测能力
非结构化问题的学习
- 所习得的 l ( x ) l(x) l(x)转换为多层非线性变换,实现对DATA的高层抽象
- DATA输入也会更复杂,需要更多数据预处理操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FBOcI4Vm-1675318791325)(null)]
HIDEN LAYER的CELL
- 在多层感知机中,隐层由图示的CELL组建而成,每一个CELL接受上一层的多个CELL输入( S n S_n Sn),经过Activation(激活函数,此处以ReLU为例),得到该CELL对下一层的输出( S ′ S^{\prime} S′)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QKcHdZUq-1675318791405)(null)]
- Learnable: w 1 w1 w1、 w 2 w2 w2… w n wn wn ;bias(可去掉)
- W T = [ w 1 , w 2... w n ] W^T=[w1,w2...wn] WT=[w1,w2...wn]
- S = [ s 1 , s 2... s n ] T S=[s1,s2...sn]^T S=[s1,s2...sn]T
- O = W T S + b i a s O=W^TS+bias O=WTS+bias
- S ′ = A c t i v a t i o n ( O ) S^{\prime}=Activation(O) S′=Activation(O)
CV的基础任务
非像素级
IMAGE CLASSIFICTIOIN(分类)
- 一张图像中是否包含某种物体,对图像进行类别描述是Image Classification的主要研究内容

- 经典CNN:AlexNet(2012),在其之后,有很多基于CNN的算法也在ImageNet上取得了特别好的成绩,比如GoogleNet(2014)、VGGNet(2014)、ResNet(2015)以及DenseNet(2016)等
- 常用公共数据集(数据复杂度递增):
- MNIST:60k训练图像、10k测试图像、10个类别、图像大小1×28×28、内容是0-9手写数字
- CIFAR-10:50k训练图像、10k测试图像、10个类别、图像大小3×32×32
- CIFAR-100:50k训练图像、10k测试图像、100个类别、图像大小3×32×32
- ImageNet:1.2M训练图像、50k验证图像、1k个类别。2017年及之前,每年会举行基于ImageNet数据集的ILSVRC竞赛
LOCALIZATION(定位)
- 在Image Classification的基础上,还想知道图像中的单个主体对象具体在图像的什么位置,通常是以包围盒(bounding box)的形式。网络带有两个输出头。一个分支用于做图像分类,另一个分支用于判断目标位置,即输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W3VzHdsd-1675318791386)(null)]
OBJECT DETECTION(检测)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cjcDqrz2-1675318791397)(null)]
-
Object Detection通常是从图像中输出多个目标的Bounding Box以及类别,同时完成了Image Classification何Localization。在Localization中,通常只有一个目标,而目标检测更一般化,其图像中出现的目标种类和数目都不定。近年来,目标检测研究趋势主要向更快、更有效的检测系统发展
-
经典算法:
- two-stage:R-CNN(第一个高效模型)、Fast R-CNN、Faster R-CNN、R-FCN等;
- one-stage:YOLO、SSD等
-
PASCAL VOC 包含20个类别。通常是用VOC07和VOC12的trainval并集作为训练,用VOC07的测试集作为测试。
-
常用公共数据集(数据复杂度递增):
- PASCAL VOC:20个类别。通常是用VOC07和VOC12的trainval并集作为训练,用VOC07的测试集作为测试
- MS COCO:COCO比VOC更困难。80k训练图像、40k验证图像、20k没有公开标记的测试图像(test-dev),80个类别。通常是用80k训练和35k验证图像的并集作为训练,其余5k图像作为验证,20k测试图像用于线上测试
像素级/细粒度级
SEGMENTATION(分割)
分割任务是将整个图像分成像素组,然后对其进行标记和分类,难度上比非像素级更大,特征更加复杂
语义分割
- 语言分割试图在语义上理解图像中每个像素在大类上的从属(例如天空、汽车、摩托车等)。
- 基本思路:
- 二分类:我们将图像输入模型,得到和图像一样长宽的输出,其输出为单通道概率图,每个像素代表其属于第二类的可能性,进行二值化得到分割结果
- 多分类:我们将图像输入模型,得到和图像一样长宽的输出,其输出为多通道,每个通道代表不同类别,本质是给每个类别一张二值图以得到多类分割结果
- 经典算法:FCN(全卷积神经网络)、UNet、PSPNet、DeepLabV3系列、UPerNet等
- 常用公共数据集比较杂,涉及了遥感、医学影像、自动驾驶等各个专业和领域,体量庞大且专业性强,这里不做展示
实例分割
- 和语义分割的本质区别在于,语义分割是得到在大类上的从属关系,实例分割进一步区分大类中不同实体间的区别。比如,如果一群人打排球,语义分割和实例分割都会将其分割结果归类为「人」,但是语义分割的分割结果是一个大多边形把人都包起来(图1),而实例分割会给每个人一个多边形包起来(图2)
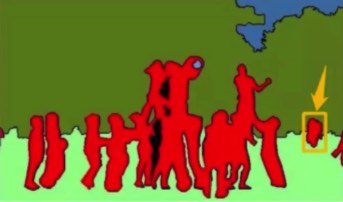
![[(img-PwFUlp2l-1675318791410)(null)]](https://img-blog.csdnimg.cn/5e761bd725634a6198349f393a671535.png)
关键点检测
- 提取分析对象的关键点,例如人脸的关键点有眼珠、眼角、鼻尖、嘴尖、下颚转折点等等,通过提取这些点的二维坐标就可以得到大概的线状、面状分布特征,如果能够提取三位点坐标,则可以引入深度特征,实现更加复杂的应用
为何分类是最基础的任务?
基于分类算法,可以在后面连接到各种其他任务的算法(例如检测、分割等),或者与其他算法头并行。总之,如果没有了分类,检测器的包围框将没有实际的参考价值,分割器的像素之间划分开的差异也没有实际意义,所以分类算法是一切人工智能算法的基础,分类领域的突破是下游任务发展的重要推动力
DEEPLEARNING算法的设计
- 朴素点说,深度学习模型的隐层可以专心负责特征提取,输入层可以任意输入各种模态的数据。声音数据可以经过滤波算法以及可视化算法转化成彩图和视觉算法共用输入层、语言数据可以切分为Seg序列,映射为一维feature vector作为Token输入Transformer算法……所以,DL算法本质上是支持多模态的
- 但单纯将各种模态数据映射为统一的输入结构,容易损失数据特征,因此需要针对分析对象的性质和关键特征来设计模型的输入层,以及隐层中的特征提取方式
- 而视频和音频数据相比于单帧数据,带有时序特征,在设计上如何考虑多帧之间的时序关系是非常重要的,因此难度也要更高。常见的应用有:
- 片段引导:划分视频片段,并对应某类片段的受众,引导受众跳转到感兴趣片段
- 片段查询:根据用户的自然语言描述,截取出符合描述条件的片段
子豪兄总结的新颖且有前景的研究领域
- 可解释性分析、显著性分析(兴趣排名No.3)
- 图机器学习、图神经网络(兴趣排名No.1)
- 人工智能+VR AR元宇宙
- 轻量化压缩部署(兴趣排名No.2)
- 各行各业垂直细分应用
- NERF
- Diffusion
- 隐私计算、联邦学习、可信计算
- AI基础设施平台
- 预训练大模型















 6528
6528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









