






JVM学习总结
JVM(Java Virtual Machine)–Java程序的运行环境,是一种规范
- 是Java可以一次编写,多处运行的基础
- 自动内存管理,垃圾回收功能
- 数组下标越界检查,C语言没有下标越界检查
- 多台,面向对象的基石(虚方法表的机制,实现多态)
一、JVM结构
- 类加载器 ClassLoader
- JVM内存结构
- 程序计数器
- 堆
- 虚拟机栈
- 本地方法栈
- 方法区
- 执行引擎
- 解释器
- 即时编译器
- 垃圾回收
二、内存结构
- 程序计数器
- 虚拟机栈
- 本地方法栈
- 堆
- 方法区
1、程序计数器(Program Counter Register 程序计数器、寄存器)

- 作用,是记住下一条jvm指令的执行地址
- 特点:
- 是线程私有的
- 不会存在内存溢出
2、虚拟机栈
Java Virtual Machine Stacks(Java虚拟机栈)
-Xss 设置虚拟机栈的内存大小;
- 每个线程运行时需要的内存,称为虚拟机栈
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能由一个活动栈帧,对应着当前正在执行的那个方法。
2.1、局部变量是否线程安全
– 如果是私有的,线程安全
– 如果是共享的,线程不安全。
– 如果方法内局部变量没有逃离方法的作用范围,它是线程安全的。
– 如果局部变量引用了对象,并逃离方法的作用范围,则需考虑线程安全问题。
2.2、虚拟机栈内存溢出
java.lang.StackOverflowErro
-Xss256k 设置虚拟机栈的内存大小。
- 栈帧过多导致栈内存溢出
- 栈帧过大导致栈内存溢出
2.3、线程运行诊断
Linux系统 top命令,查看进程CPU使用情况。
案例1:cpu占用过多
定位
- 用top命令定位哪个进程对cpu的占用过高
- ps H -eo pid,tid,%cpu | grep 进程id (用ps命令进一步定位是哪个线程引起的cpu占用过高)
- jstack 进程id
- 可以根据线程id找到有问题的线程,进一步定位到有问题的代码行数。
3、本地方法栈
native 本地方法运行所占用的内存空间。
程序计数器、虚拟机栈、本地方法栈 : 都是线程私有。
4、堆
Heap 堆
- 通过new关键字,创建的对象都会使用堆内存。
特点:
- 线程共享,堆中对象都需要考虑线程安全问题。
- 有垃圾回收机制。
4.1、堆内存溢出
java.lang.OutOfMemoryError:java heap space
-Xmx8m 设置堆空间大小
4.2、堆内存诊断
- jps工具
- 查看当前系统中有哪些Java进程
- jmap工具
- 查看堆内存占用情况(只能查看某一时刻的情况)
- jmap -heap 进程id
- jconsole工具
- 图形界面的,多功能的监测工具,可以连续监测。
- 可以监测堆内存,还可以监测线程和cup。
- jvisualVM工具
- jvisualvm 可视化的方式展示虚拟机使用情况
- 堆 Dump,堆的快照
- 堆里面的对象类型,个数,占用内存大小等。
5、方法区
JVM规范 – 方法区定义
- 方法区是所有jvm线程共享的区域。
- 存储了和类的结构相关的信息
- 运行时常量池
- 类的成员变量
- 方法数据
- 成员方法和构造器方法的代码
- 包括特殊方法
- 方法区在虚拟机启动的时候创建
- 逻辑上是堆的组成部分,逻辑上,实际上看实现厂商。
- 该规范并不强制方法区的位置。
- Oracle的hotspot虚拟机,在jdk1.8之前,方法区的实现是永久代,永久代的位置在堆内存。1.8之后,元空间替换永久代,迁出堆空间,使用操作系统的内存空间。但是String Table还是在堆空间中。
- 永久代、元空间,都是方法区的一种实现。
- 方法区申请内存不足,也会报OOM。OutOfMemoryError
下图中常量池为运行时常量池
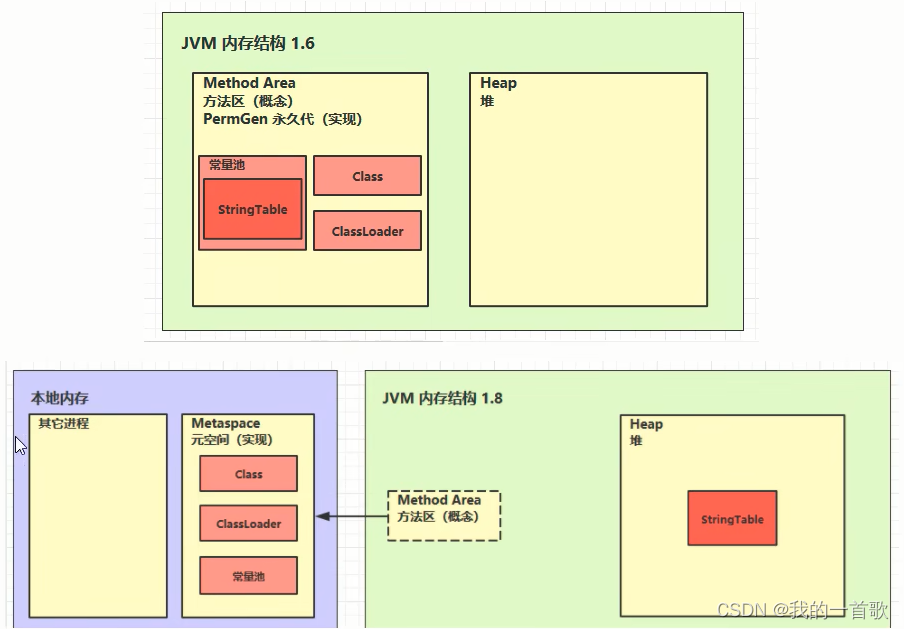
5.1、方法区内存溢出
- 1.8以前会导致永久代内存溢出
- 1.8以后会导致元空间内存溢出
-XX:MaxMetaspaceSize=8m 设置元空间最大内存为8M
6、常量池
- 常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息。
- 运行时常量池,常量池是*.class文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址。
7、StringTable
// 常量池中的信息,都会被加载到运行时常量池中,这时 a b ab 都是常量池中的符号,还没有变为Java字符串对象
// ldc #2 会把 a 符号变为"a"字符串对象
// ldc #3 会把 b 符号变为"b"字符串对象
// 懒惰的行为,只有运行到那行代码的时候,才会创建字符串对象,放在串池中(StringTable[] 是hashtable结构,不能扩容)。
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
// 字符串字面量也是 延迟 成为对象的
// 因为s4是变量拼接,数值不确定,底层是new StringBuilder,拼接后.toString 返回,toString()是new了新的String。所以地址值不同
System.out.println(s3 == s4); // false
// javac 在编译期间的优化,s3执行的时候会被优化为“ab”
System.out.println(s3 == s5); // true
// 1.8和1.6都是true
// 1.8,s4调用intern()方法,如果常量池中没有"ab"字符串,则将本身地址放到常量池,此时常量池和堆中引用的是同一块地址。如果常量池中已经存在,则不放入,并且返回值是常量池中的地址。
// 1.6,调用intern()方法,如果常量池中已有,则不放入,如果没有,则复制一份放入常量池,返回值是常量池中的地址。
// 此题不管1.8还是1,6都是true,原因常量池中已经有了字符串"ab",所以s6的值,都是指向常量池中的地址。
System.out.println(s3 == s6); // true
String x = "ab";
String s = new String("a") + new String("b");
String s2 = s.intern();
System.out.println(s == x); // false
System.out.println(s2 == x); // true
// 如果没有String x = "ab";
System.out.println(s == "ab"); // true
System.out.println(s2 == "ab"); // true
// 因为调用intern后,发现串池中没有ab,于是将堆中地址放入串池,所以s=="ab",的时候,"ab"的地址指向的就是堆中的地址。
特性:
- 常量池中的字符串仅是符号,第一次用到时才变为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串常量拼接的原理时编译期优化
- 字符串变量拼接的原理是StringBuilder(1.8)
- 可以使用intern方法,主动将串池中还没有的字符串对象放入串池
- intern方法返回的就是串池中的对象。
- 1.8将这个字符串对象尝试放入串池,如果有则不会放入,如果没有则放入,会把串池中的对象返回
- 1.6将这个字符串对象尝试放入串池,如果有则不会放入,如果没有会把此对象复制一份,放入串池,会把串池中的对象放回。
- jdk1.7,将字符串常量池从永久代放到了堆中;主要是考虑到垃圾回收的时机。
- jdk1.8,取消永久代,改为元空间,使用操作系统内存。
7.1、StringTable垃圾回收
8、直接内存 Direct Memory
- 常见于NIO操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受JVM内存回收管理
如果不使用直接内存,读写文件的时候,从磁盘文件读取到系统内存,再从系统内存读取到Java堆内存,因为Java无法直接操作系统内存,所以读写效率就没那么高。
如果使用了直接内存,读写文件的时候,从磁盘文件直接读取到直接内存,Java代码也能直接访问操作直接内存,所以效率高了。
三、垃圾回收
1、如何判断对象可以被回收
1.1、引用计数法
Java对象被引用一次,次数就加一,取消引用就减一,当计数为0时,就可以被垃圾回收。
但是此方法会导致循环引用不被回收。
1.2、可达性分析算法(java虚拟机判断垃圾的算法)
根对象,就是不会被垃圾回收的对象。
在垃圾回收之前,会对堆中的所有对象进行扫描,判断:
从根对象出发,能够直接或间接被根对象引用的对象,不会被垃圾回收;
如果从根对象出发,找不到或者不能被根对象直接或间接引用的对象,就会被垃圾回收。
- Java虚拟机中的垃圾回收器采用可达性分析来探索所有存活的对象;
- 扫描堆中的对象,看是否能够沿着GC Root对象,为起点的引用链找到该对象,找不到,表示可以回收;
- 哪些对象可以作为GC Root?
1.3、引用类型
- 强引用
- 平时使用的都是强引用
- GC Root没有直接或间接引用的对象,可以被垃圾回收
- 软引用
- 当没有强引用直接引用的时候,发生垃圾回收且垃圾回收后,内存还不足,则软引用会被回收
- 弱引用
- 只要发生垃圾回收,就会回收
- 虚引用
- 只要发生垃圾回收就会被回收,并且虚引用会进入引用队列
- 终结器引用
2、垃圾回收算法
2.1、标记清除
- 速度快,但容易产生内存碎片
2.2、标记整理
- 速度慢,不会产生内存碎片
2.3、复制
- 不会产生内存碎片,需要双倍的空间
3、分代回收
-
新生代(Minor GC)
-
伊甸园 新创建的对象会被分配在伊甸园。当创建新的对象时,发现伊甸园内存不足,则发生第一次GC,并将存活下来的对象移到幸存区to。移动后,幸存区to变为from,幸存区from变为to,始终保持垃圾回收开始前,to是空的。(后面再次出发minor gc 的时候,from中的存活的对象也要复制到to中)
-
幸存区from
-
幸存区to
minor gc 会引发stop the world,暂停其他用户的线程,垃圾回收线程先工作,执行完毕再恢复其他线程的运行,因为在垃圾回收过程中,涉及到对象内存地址的变化。
当对象寿命超过阈值时,会晋升至老年代,最大阈值15
当minor gc后仍然内存不足,则会将幸存的所有对象移动至老年代。
超出Eden区的大对象,也会直接进入老年代。
-
-
老年代(Full GC)
- 当老年代空间不足,会先尝试触发minor gc(非必须,但最好),如果之后空间仍不足,那么触发full gc,STW时间更长。
- 因为老年代很多对象都会引用到新生代的对象,先进行Minor gc可以提高老年代full gc的速度。
4、相关VM参数
| 堆初始大小 | -Xms |
|---|---|
| 堆最大大小 | -Xmx或-XX:MaxHeapSize=size |
| 新生代大小 | -Xmn或(-XX:NewSize=size + -XX:MaxNewSize=size) |
| 幸存区比例(动态) | -XX:InitialSurvivorRatio=ratio 和 -XX:+UseAdaptiveSizePolicy |
| 幸存区比例 | -XX:SurvivorRatio=ratio |
| 晋升阈值 | -XX:MaxTenuringThreshold=threshold |
| 晋升详情 | -XX:+PrintTenuringDistribution |
| GC详情 | -XX:+PrintGCDetails -verbose:gc |
| FullGC 前 MinorGC | -XX:+ScavengeBeforeFullGC |
- 单个线程内部的OOM,不会导致整个Java进程的结束
5、垃圾回收器
- 串行
- 单线程
- 堆内存较小,适合个人电脑
- 吞吐量优先
- 多线程
- 堆内存较大,多核
- 让单位时间内,STW的时间最短
- -XX:+UseParallelGC -XX:+UseParallelOldGC
- 垃圾回收期间,用户线程不能运行
- 响应时间优先
- 多线程
- 堆内存较大,多核
- 尽可能让单次STW的时间最短
- -XX:+UseConcMarkSweepGC -XX:+UseParNewGC 当并发失败的情况,使用串行垃圾回收器SerialOld代替
- 垃圾回收期间,用户线程可并发运行
四、Garbage First(G1)
- jdk1.7官方开始支持
- jdk1.9开始为默认垃圾回收器
适用场景
- 同时注重吞吐量喝低延迟,默认的暂停目标是200ms
- 超大堆内存,会将堆划分为多个大小相等的Region
- 整体上是标记+整理算法,两个区域之间是复制算法
1、相关JVM参数
-XX:+UseG1GC
-XX:G1HeapRegionSize=size
-XX:MaxGCPauseMillis=time
2、JDK 8u20 字符串去重
- 优点:节省大量内存
- 缺点:略微多占用了cpu的时间,新生代回收时间略微增加
- -XX:+UseStringDeduplication(默认开启)
- 将所有新分配的字符串放入一个队列
- 当新生代回收时,G1并发检查是否有字符串重复
- 如果值一样,让它们引用用一个char[]
- 注意,与String.intern()不一样
- String.intern()关注的是字符串对象
- 而字符串去重关注的是char[]
- 在JVM内部,使用了不同的字符串表。
3、JDK 8u40 并发标记类卸载
所有对象都经过并发标记后,就能知道哪些类不再被使用,当一个类加载器(自定义类加载器)的所有类都不再使用,则卸载它所加载的所有类。
-XX:+ClassUnloadingWithConcurrentMark 默认开启
4、JDK 8u60 回收巨型对象
- 一个对象大于region的一半时,称之为巨型对象
- G1不会对巨型对象进行拷贝
- 回收时被优先考虑
- G1会跟踪老年代所有incoming引用,这样老年代incoming引用为0的巨型对象就可以在新生代垃圾回收时处理掉。
5、JDK 9 并发标记起始时间的调整
- 并发标记必须在堆空间占满前完成,否则退化为FullGC
- JDK 9 之前需要使用 -XX:InitiatingHeapOccupancyPercent
- JDK 9 可以动态调整
- -XX:InitiatingHeapOccupancyPercent 用来设置初始值
- 进行数据采样并动态调整
- 总会添加一个安全的空挡空间
五、GC调优
GC主要影响网络延迟、响应效率,因为一旦GC时间过长,stw的时间就会长,就会影响响应时间。
注重细节,避免非必要的内存浪费:
如sql查询语句,只查自己需要的,不必要的可以不查;
如能用基本类型,不用包装类型,可以积少成多,节约内存。
1、确定调优目标
- 低延迟
- 如果是互联网项目,则更加注重低延迟
- CMS,G1,ZGC
- JDK9开始,默认使用G1
- 高吞吐量
- 如果是科学运算类项目,则更加注重高吞吐量
- ParallelGC
2、最快的GC就是不发生GC
- 查看fullGC前后的内存占用,考虑下面几个问题
- 数据是不是太多
- 如:resultSet = statement.executeQuery(“select * from 大表”)
- 数据表示是否太臃肿
- 对象图
- 对象大小
- 是否存在内存泄漏
- 数据是不是太多
3、新生代调优
-
新生代的特点:
- 所有的new操作的内存分配非常廉价
- TLAB thread-local allocation buffer
- 死亡对象的回收代价是零
- 大部分对象用过即死
- Minor GC的时间远远低于full GC
- 所有的new操作的内存分配非常廉价
-
-Xmn新生代内存分配VM参数
- 并非越大越好
- 因为如果新生代内存过大,会延长Minor GC的时间,影响响应时间
- 控制在堆的25%-50%之间
- 幸存区尽量大一些
- 如果一些本应存活时间较短的对象,因为幸存区不足,而进入老年代,则需要到发生Full GC的时候才能被清楚
- 晋升阈值相对小一些
- 让长时间存活的对象尽快晋升,避免长时间存活的对象在幸存区来回复制
- -XX:MaxTenuringThreshold=threshold(阈值设置)
- 并非越大越好
4、老年代调优
- 优先考虑调优新生代
- 实在不行,就增加老年代,提升1/4左右的内存














 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









