







一、分类的目的和分类的方法
目标
- 能够说出项目中进行文本的目的
- 能够说出意图识别的方法
- 能够说出常见的分类的方法
1.1 文本分类的目的
回顾之前的流程,我们可以发现文本分类的目的就是为了进行意图识别
在当前我们的项目的下,我们只有两种意图需要被识别出来,所以对应的是2分类的问题
可以想象,如果我们的聊天机器人有多个功能,那么我们需要分类的类别就有多个,这样就是一个多分类的问题。例如,如果希望聊天机器人能够播报当前的时间,那么我们就需要准备关于询问时间的语料,同时其目标值就是一个新的类别。在训练后,通过这个新的模型,判断出用户询问的是当前的时间这个类别,那么就返回当前的时间。
同理,如果还希望聊天机器人能够播报未来某一天的天气,那么这个机器人就还需要增加一个新的进行分类的意图,重新进行训练。
1.2. 机器学习中常见的分类方法
在前面的机器学习的课程中我们学习了朴素贝叶斯,决策树等方法都能够帮助我们进行文本的分类,那么我们具体该怎么做呢?
1.2.1 步骤
- 特征工程:对文本进行处理,转化为能够被计算的向量来表示。我们可以考虑使用所有词语的出现次数,也可以考虑使用tfidf这种方法来处理。
- 对模型进行训练。
- 对模型进行评估
1.2.2 优化
使用机器学习的方法进行文本分类的时候,为了让结果更好,我们经常从两个角度出发
- 特征工程的过程中处理的更加细致,比如文本中类似你,我,他这种词语可以把它剔除;某些词话出现的次数太少,可能并不具有代表意义;某些词语出现的次数太多,可能导致影响的程度过大等等都是我们可以考虑的地方。
- 使用不同的算法进行训练,获取不同算法的结果,选择最好的,或者是使用集成学习方法。
1.2. 深度学习实现文本分类
前面我们简单回顾了使用机器学习如何来进行文本分类,那么使用深度学习该如何实现呢?
在深度学习中我们常见的操作就是:
- 对文本进行embedding的操作,转化为向量
- 之后再通过多层的神经网络进行线性和非线性的变化得到结果
- 变换后的结果和目标值进行计管得到损失函数,比如对数似然损失等
- 通过最小化损失函数,去更新原来模型中的参数
二、fasttext实现文本分类
目标
- 知道fastext是什么
- 能够应用fasttext进行文本分类
- 能够完成项目中意图识别的代码
2.1 fastText的介绍
文档地t址: https://fasttext.cc/docs/en/support.html.fastText is a library for efficient learning of word representations and sentenceclassification.
fastText是一个单词表示学习和文本分类的库
优点: 在标准的多核CPU上,能够训练10亿河级别话料库的词向量在10分钟之内,能够在1分钟之内给30万多类别的50多万句子进行分类。
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率
fasttext是什么
a 用来获取词向量,进行文本分类的模块
b 分类的效率,得到词向量的效率高
2.2 安装和基本使用
2.2.1 安装步骤:
- 下载 git clone https://github ,com/facebookresearch/fastText.git
- cd
cd fastText - 编译
make - 安装
python setup.py install
2.2.2 基本使用
- 把数据准备为需要的格式
- 进行模型的训练、保存和加载、预测
#1,训练.
model = fastText.train_supervised("./data/text_classify.txt",wordngrams=1,epoch=20
#2,保存
model.save_mode(" /data/ft_classify.model")
#3,加载
model = fastTextload_model("./data/ft_classify.model")
textlist =[句子1,句了2]
#4,预测,传入句子列表
ret = model.predict(textlist)
2.3 意图识别实现
2.3.1 数据准备
数据准备最终需要的形式如下:


2.3.1.1 准备特征文本
使用之前通过模板构造的样本和通过爬虫抓取的百度上的相似问题
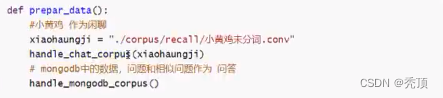
2.3.1.2 准备闲聊文本
使用小黄鸡的语料,地址: https://github.com/faleleak/dgk lost conv/tree/master/results
2.3.1.3 把文本转化为需要的格式
对两部分文本进行分词、合并,转化为需要的格式


2.3.1.4 思考:
是否可以把文本分制为单个字作为特征呢?
修改上述代码,准备一份以单个字作为特征的符合要求的文本
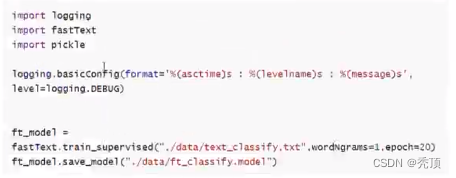
2.3.2 模型的训练
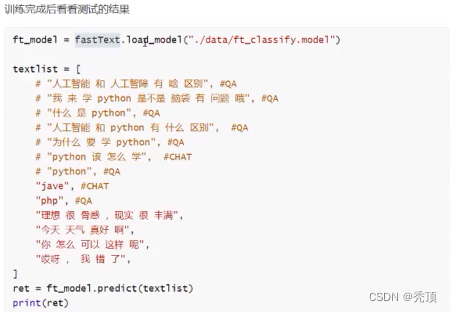
2.3.2.2 模型的准确率该如何观察呢?
观察准备去,首先需要对文本进行划分,分为训练集和测试集,之后再使用测试集观察模型的准
确率
2.3.3 模型的封装
为了在项目中更好的使用模型,需要对模型进行简单的封装,输入文本,返回结果
这里我们可以使用把单个字作为特征和把词语作为特征的手段结合起来实现


三、fasttext的原理剖析
目标
- 能够说出fasttext的架构
- 能够说出fasttext速度快的原因
- 能够说出fastText中层次化的softmax是如何实现的
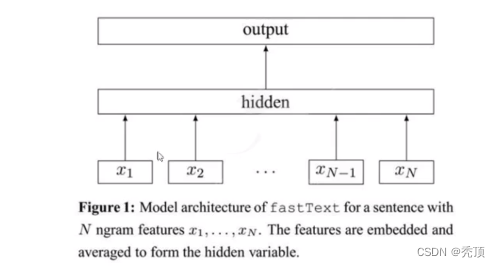
3.1 fastText的模型架构
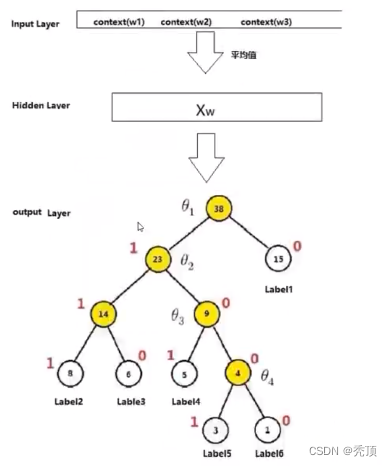
fastText的架构非常简单,有三层: 输入层、隐藏层、输出层(Hierarchical Softmax)
输入层: 是对文档embedding之后的向量,包含有N-garm特征
隐藏层: 是对输入数据的求和平均
输出层: 是文档对应标签
如下图所示:
3.1.1 N-garm的理解
3.1.1.1 bag of word
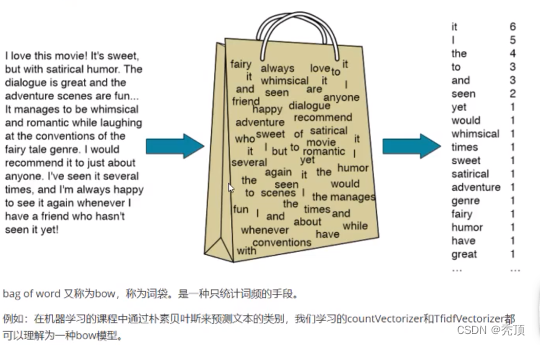
3.1.1.2 N-gram模型

3.2 fastText模型中的层次化的softmax
为了得高效率,在fastText中计算分类标签的概率的时候,不再是使用传统的softmax来进行多分类的计算,而是使用的哈夫曼树(Huffman,也成为夫曼树),使用层次化的softmax (Hierarchial softmax) 来进行概率的计算。
3.2.1 哈夫曼树
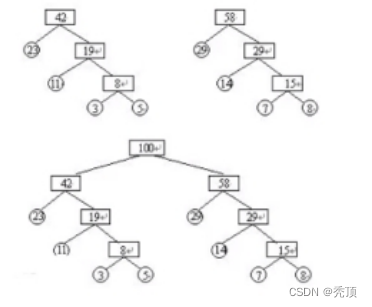
3.2.1.1 哈夫曼树的定义
哈夫曼树概念:给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
3.2.1.2 哈夫曼树的相关概念

3.2.1.3 哈夫曼树的构造算法
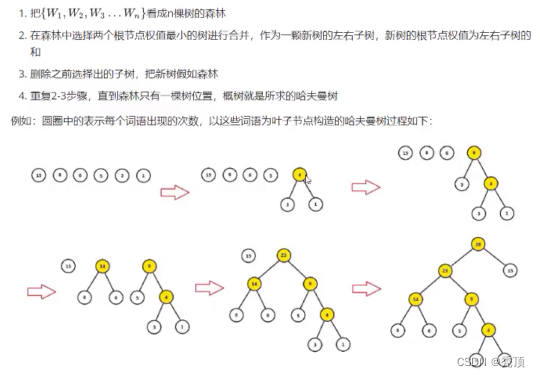
可见
- 权重越大,距高根节点越近
- 叶子的个数为n,构造哈夫曼树中新增的节点的个数为n-1
3.2.2 哈夫曼编码

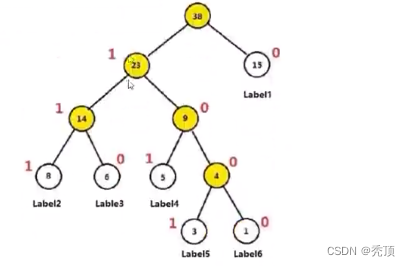
3.2.3 梯度计算





















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









