







1.1 预备知识
1.1.1 独热表示 one-hot
顾名思义,one-hot 表示以0向量开始,如果单词存在于句子或者文档中,则将向量中的相应条目设置成1,反之为0

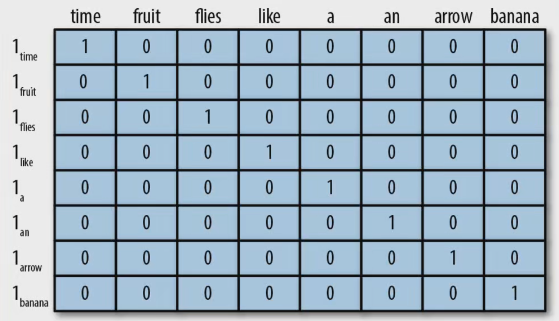
1.1.2 词频表示(TF)
短语、句子或者文档的词频表示就是其组成单词 “one-hot” 表示向量的总和
**TF(Term Frequency, 词频)**表示词条在文本中出现的频率,这个数字通常会被 归一化 (一般是词频除以文章总词数), 以防止它偏向长的文件(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)。TF用公式表示如下:
T
F
i
,
j
=
n
i
,
j
∑
k
n
k
,
j
(1.1)
TF_{i,j} = \frac{n_{i,j}}{\sum_k n_{k, j}}\tag{1.1}
TFi,j=∑knk,jni,j(1.1)
- n i , j n_{i,j} ni,j 表示词条 t i t_i ti 在文档 d j d_j dj 中出现的次数, T F i , j TF_{i,j} TFi,j 表示词条 t i t_i ti 在文档 d j d_j dj 中出现的频率

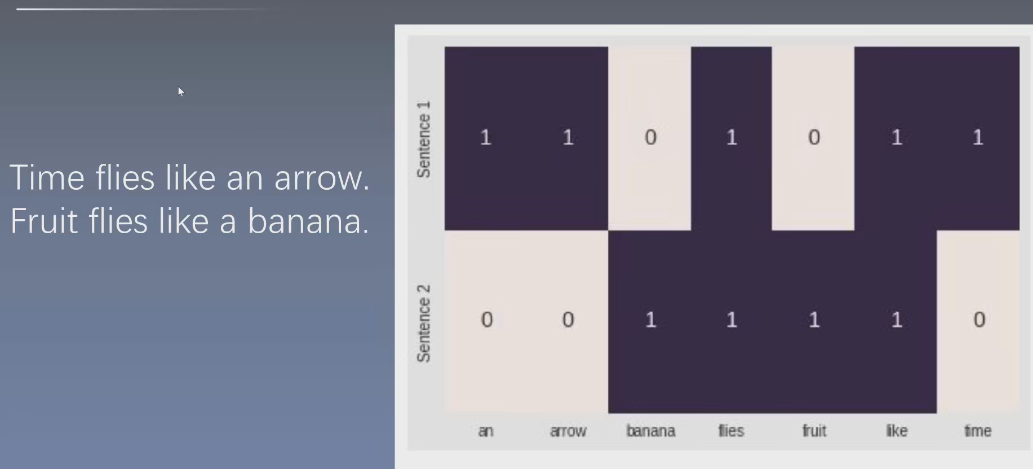
1.1.3 逆文档频率(IDF)
如果有一系列专业文献,只考虑词频,可能claim这样的高频常见词并不能增加我们认识的文献的信息,而低频罕见词Tetrafluoroethene(四氟乙烯)却反而有可能表达文献的本质。为了给这些词在表达中增加比重,给无意义词减小比重,就有了 逆文档频率(IDF)
逆文档频率
(
I
D
F
)
=
l
o
g
(
语料库中包含的总文档数
包含该词的总文档数
)
逆文档频率(IDF) = log(\frac{语料库中包含的总文档数}{包含该词的总文档数})
逆文档频率(IDF)=log(包含该词的总文档数语料库中包含的总文档数)
i d f ( t , D ) = l o g N ∣ { d ∈ D : t ∈ d } ∣ (1.2) idf(t, D) = log{\frac{N}{|\left \{ d\in D:t\in d \right \}|}}\tag{1.2} idf(t,D)=log∣{d∈D:t∈d}∣N(1.2)
- 包含该词的总文档数越小,说明该词越独特,整体IDF就越大
- D是文档集合,t是当前的词
- d ∈ D : t ∈ d d\in D:t \in d d∈D:t∈d 表示 t 出现在某篇文档d中,而d又在总文档集合D中出现
1.1.4 词频逆文档频率表示(TF-IDF)
单词的 TF-IDF 分值就是 TF 和 IDF 的乘积,用公式表示如下。那么一句话的向量表示,就是词典里面所有词的词频逆文档频率。
t
f
i
d
f
(
t
,
d
,
D
)
=
t
f
(
t
,
d
)
×
i
d
f
(
t
,
D
)
(1.3)
tfidf(t, d, D) = tf(t,d) \times idf(t, D)\tag{1.3}
tfidf(t,d,D)=tf(t,d)×idf(t,D)(1.3)
- t f ( t , d ) tf(t,d) tf(t,d):t 这个词在文档 d 中出现了多少次
1.1.5 表示方法总结
致命问题:
- 词典多长,向量就有多长,计算量巨大(通常词典都是10000+)
- 太稀疏,一句话10个词的话,至少向量里面有9990个0(冗余,无意义)
- 语义鸿沟(相似度?语义相似性?深层次特征?),没办法了解这个词到底表示什么意义,对计算机而言就只是个标识而已,标识和标识之间没有关系。
解决方法: 稠密编码(特征嵌入)
1.2 NLP问题中的特征
1.2.1 直接可观测特征
单独词特征:组成词的字符和它们的次序,以及从中导出的属性,和其他外部信息资源的联系(文档中的词频,TF-IDF)
| 单独词特征 | 示例 |
|---|---|
| 词元和词干 | booked, books, booking $\longrightarrow $ book; pictures, pictured, picture $\longrightarrow $ pic-tur |
| 词典资源 | star $\longrightarrow $ an actor who plays a principle role;any celestial body visible from earth;someone who is dazzlingly skilled (ace, adept, champion, maven) |
| 分布信息 | apple & banana;apple & icecream? |
文本特征:观察到的特征是字符和词在文本中的数量和词序
- 权重(TF-IDF)
- N元组(组合特征)
N元组(n-gram)
一种 特征组合 案例:在给定的长度下由连续的词序列组成。二元词能比单独的词富含更多的信息,在很多案例里都是有效的。但是,并不是所有二元组都有效,先验知识也没办法告诉我们哪个二元组有效,所以只能靠模型去降低权重或抛弃。
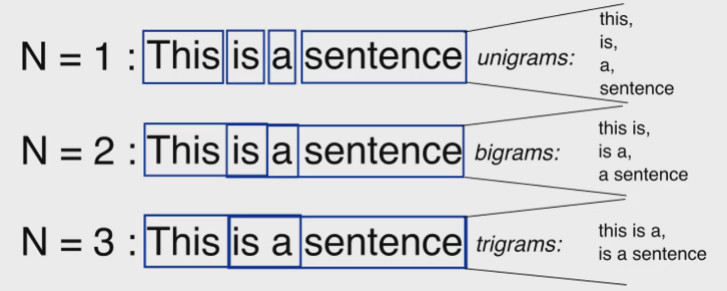
上下文词特征:考虑词在句子或者文本中时,一个能直接观测到的特征就是其在句子中的位置,以及围绕它的词。由此引出一个概念——窗口。
窗口:围绕词的窗口聚焦于词的直接上下文(即目标每侧的k个词),由此可基于窗口进行统计共现频率,特征组合,词预测等一系列任务。
1.2.2 可推断的语言学特征
自然语言的句子并非只是词语的线性排序,还是遵循一定结构的。这个结构又遵循复杂的某种不易于直接观察到的规律,这个规律叫做 语法。
针对这些规则或规律的学习就被称为面向学习的 语言学。
有的语言模板仍未被挖掘,有的已经被充分理解,例如 词性,部分 语法,部分语义信息。
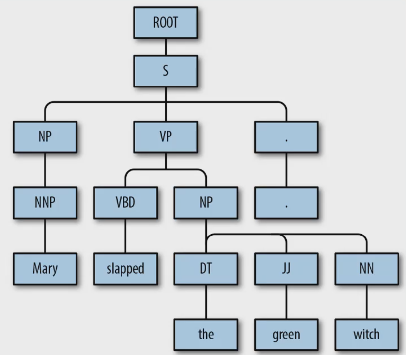
存在专门的系统,以不同的准确率来 预测 词性,语法树,语义角色以及一些其他语言学属性。
浅层句法分析 主要识别短语词性,识别词之间关系则称为 句法分析。句法分析又分为【成分句法分析】和【依存句法分析】。
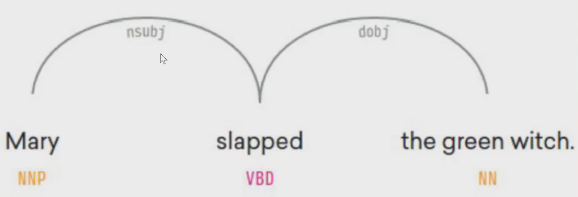
1.3 特征输入(特征编码)
1.3.1 独热编码
见[独热表示](#1.1.1 独热表示 one-hot)
1.3.2 稠密编码(特征嵌入)
稠密向量表示不再以one-hot中的一维来表示各个特征,而是把每个 核心特征(词、词性、位置等)都嵌入到 d 维空间中,并用空间中的一个向量表示。通常空间维度 d 远小于每个特征的样本数(40000的词表,100或200维向量)。**嵌入的向量(每个核心特征的向量表示)**作为网络参数与神经网络中的其他参数一起被训练。
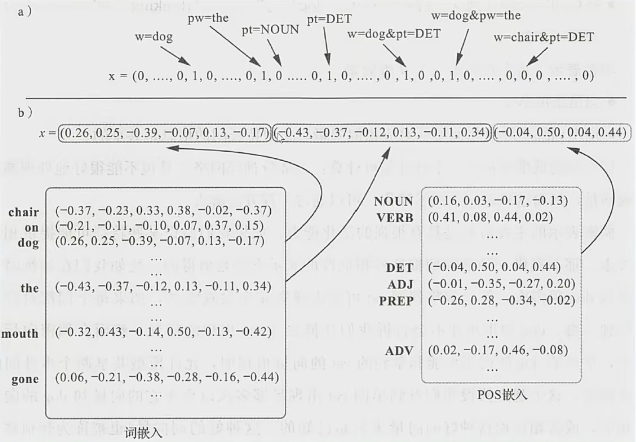
稠密编码总结:
- 抽取一组和预测输出类别相关的核心语言学特征
- 对于每一个感兴趣的特征,检索出相应的向量
- 将特征向量组合(拼接、相加或两两组合)成输入向量 x
- 将 x 输入到非线性分类器中(前馈神经网络)
稠密编码优势:
- 模型训练会导致相似特征对应相似向量,相似特征之间信息共享
- 假设某些特征可以提供相似线索,稠密编码表示法 则有望能够捕捉这些相似性
- 可计算性强
- 可进行预训练
1.3.3 组合稠密向量
基于窗口的特征:假设 i 为中心词,两边各包含 k 个单词的窗口,窗口大小为2,那我们要关注的编码就是在位置 i-2, i-1, i+1, i+2 上的词。将这些词表示组合之后作为新特征使用。
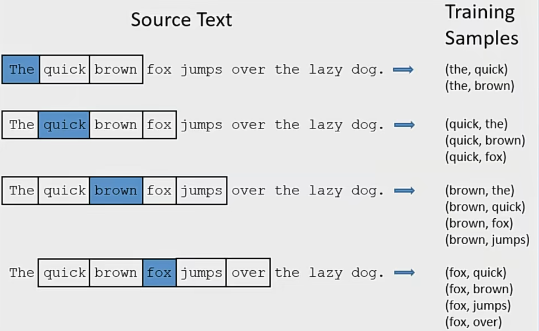
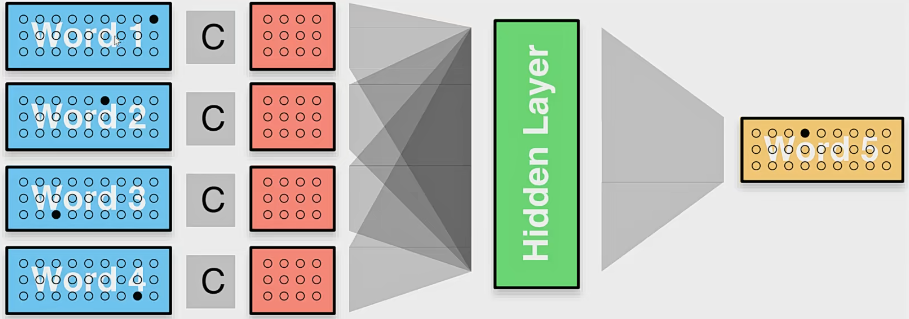
可变特征数目——连续词袋:前馈神经网络使用固定维度的输入,这样能够很容易地与抽取固定数目特征的抽取函数相适应,每个特征用一个向量表示,通过 拼接组合向量,这种方法中输入向量的每个区域对应一个不同特征。但有时不能预先确定特征的数目(如在文本分类任务中,通常句子中的每个词都是一个特征),因此我们需要使用 固定大小的向量 表示任意数量的特征。例如 连续词袋(CBOW)模型。
C
B
O
W
(
f
1
,
.
.
.
f
k
)
=
1
k
∑
i
=
1
k
v
(
f
i
)
(1.4)
CBOW(f_1,...f_k)=\frac{1}{k}\sum_{i=1}^kv(f_i)\tag{1.4}
CBOW(f1,...fk)=k1i=1∑kv(fi)(1.4)
W C B O W ( f 1 , . . . , f k ) = 1 ∑ i = 1 k a i ∑ i = 1 k a i v ( f i ) (1.5) WCBOW(f_1,...,f_k)=\frac{1}{\sum_{i=1}^ka_i}\sum_{i=1}^ka_iv(f_i)\tag{1.5} WCBOW(f1,...,fk)=∑i=1kai1i=1∑kaiv(fi)(1.5)
无论在文本分类的任务中有多多少个词,最后都可以变成固定的大小。使用固定大小的向量表示任意数量的特征
1.3.4 其他特征输入
- 距离与位置特征
- pad & unk
- pad 填充到相同长度,方便进入NN进行训练。向量表示为0,没有意义
- unk 测试集上如果出现训练集中没有的词,会给他一个unk特征。向量表示为0,没有意义
- 词丢弃
- 特征组合(指定特征间的交互)
- 向量共享(dog前一词后一词,中心词上下文应该共享同样的词向量嘛)
- 维度(每个特征分配多少维)
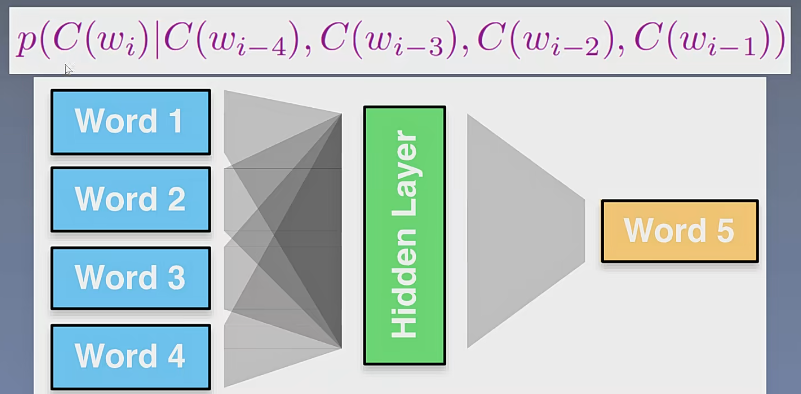
1.4 文本的向量化表示(嵌入)
目标是希望神经网络发现如下的规律,于是有网络结构图:














 1959
1959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









