






N e t 2 Net^2 Net2: A Graph Attention Network Method Customized for Pre-Placement Net Length Estimation
论文地址:https://arxiv.org/pdf/2011.13522.pdf
代码:无
net length是优化标准数字设计过程每个阶段的时序和功耗的关键指标。然而,大多数net length的信息在单元布局之前是不可用的,因此在布局前的设计阶段(如逻辑综合)明确考虑net length优化是一个重大挑战。这项工作通过提出一种定制的图注意网络方法(称为 N e t 2 Net^2 Net2)来解决这一挑战,该方法在单元放置之前估计单个网络的长度。其面向精度的版本 N e t 2 a Net^{2a} Net2a在识别长网络和长关键路径方面的准确率比以前的努力高出约15%。其快速版 N e t 2 f Net^{2f} Net2f比布局快1000倍以上,但在各项精度指标上仍优于前人的工作和其他神经网络技术。
构造有向图

5 nets { n 1 , n 2 , n 3 , n 4 , n 5 } \{n_1,n_2,n_3,n_4,n_5\} {n1,n2,n3,n4,n5} and 11 cells { c A , c B , … , c K } \{c_A,c_B,\dots,c_K\} {cA,cB,…,cK} . 对 n 3 n_3 n3包含3个cells { c D , c G , c H } \{c_D,c_G,c_H\} {cD,cG,cH},称为3-pin net。driver为cell c D c_D cD,sinks为cells { c G , c H } \{c_G,c_H\} {cG,cH}. n 3 n_3 n3的driver的area(所在区域还是面积?)称为 a d r i 3 a^3_{dri} adri3. n 3 n_3 n3 的 fan-in N i n 3 = { n 1 , n 2 } N^3_{in}=\{n_1,n_2\} Nin3={n1,n2}, fan-out N o u t 3 = { n 4 , n 5 } N_{out}^3=\{n_4,n_5\} Nout3={n4,n5}.
每个net只有一个driver,可有多个sinks。
directed graph的构建根据net为节点(以往研究以cell为节点),每个net通过共享的cell构成有向边。
net length 是训练和预测的标签。每个net length是放置后网的包围框的半周长。
算法
节点特征
节点特征包含:
- 基础信息:driver’s area、fan-in and fan-out size { ∣ N i n k , ∣ N o u t k ∣ , a d r i k } \{|N_{in}^k,|N_{out}^k|,a^k_{dri}\} {∣Nink,∣Noutk∣,adrik} .
- 考虑所有fan-in邻居节点和fan-out邻居节点的fan-in和fan-out size(步骤4-5);所有fan-out邻居节点的driver’s area(步骤6)

边特征
上面的节点特征已经包含了2-hop的领域信息。边特征用来捕获全图的全局信息。做法如下:
- 对net和cell组成的graph分别使用划分(聚类)算法,
M
M
M代表使用
h
M
E
T
I
S
hMETIS
hMETIS 算法对net graph划分的结果;
P
P
P代表对cell graph划分的结果。

N e t 2 Net^{2} Net2 模型
快速版本 N e t 2 f Net^{2f} Net2f
使用GAT,不考虑边特征,且拼接每层的节点嵌入: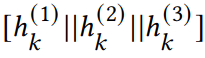
,最后使用MLP
精度版本 N e t 2 a Net^{2a} Net2a
考虑边特征。对有向边
n
b
→
n
k
n_b\to n_k
nb→nk:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BAEcPp6i-1617368836561)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210329220115239.png)]](https://img-blog.csdnimg.cn/20210402213357827.png)
以此作为初始特征,使用GAT进行迭代:
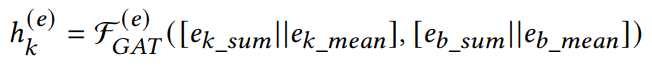
这样特征就同时考虑了节点和边特征,MLP层的输入为:
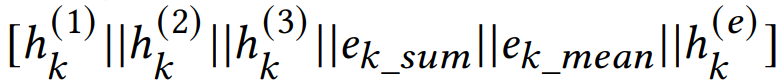
实验
实验设置
数据集: 利用7中design方式,每种方式生成10个netlists,每个netlists的统计信息如表2。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fmFF9Uuz-1617368836562)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210328115654075.png)]](https://img-blog.csdnimg.cn/20210402213559760.png)
训练:测试1-design中10个netlists分类性能时,使用其余-design中的60个netlists作为训练样本
参数配置:3-layer GNN, 2-layer ANN
基准模型:MC , ISPL, and Poly, ANN (MC:一阶邻居;ISPL:可捕获多阶;Poly、ANN:二阶邻居)
Correlation on Net Length
这节是为了测量预测值与真实值之间的相关系数。
首先只选取每个数据集中net length 长度为前95%的样本;然后,将样本的范围划分为20个相等的bins,并计算每个bin中预测和标签的平均值。图4显示了这20个平均预测与标签之间的相关系数

Identifying Long Nets
这节为了测试模型在预测长net length 时的性能。(二分类)
选了每个netlists中最长的10%的net,附以标签为真,其余90%为假,通过AUROC测量准确率。每个design的准确率=其10个netlists的均值。由于cell多的nets通常更长,故增加通过计算cell数量来判断net length的方法来作为基准


Results on Path Length Estimation
在许多EDA工具中,预置时序报告不包括布线延迟,这阻碍了在早期准确识别关键路径。net length估计的一个应用是预测任意给定路径的长度,该长度与路径上的放置后导线延迟相关。path length被定义为该路径上所有网络上的网络长度的总和。
为了验证模型在path length上的性能,对于每个netlists,我们根据预布局定时报告收集定时关键路径。此阶段的报告仅包括信元延迟。这条道路的松弛必须是负的。在这些路径中,考虑到放置后的布线延迟,较长的路径对时序更为关键。因此,我们应用模型来识别那些最长的关键路径。估计的path length是路径上的所有网络之间的预测网络长度的总和。
识别10%最长path的AUROC结果:

为了测量模型在比较任意一对路径时,能够识别出最长的那条路的能力。为了避免在长度相似的路径之间进行无意义的比较,对于每个路径,将它与netlist中比它长或短30%的所有路径进行比较。结果如下:

Runtime Comparison
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LjTCCGEP-1617368836566)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210331112541493.png)]](https://img-blog.csdnimg.cn/20210402214355939.png)
N
e
t
2
a
Net^{2a}
Net2a需要额外的计算Partition的运行时间;
N
e
t
2
a
Net^{2a}
Net2a比placement快十倍以上,并且可通过使用稀疏partition方法来进一步在larger designs上缩短时间。
N e t 2 f Net^{2f} Net2f比placement快一千倍以上。
DISCUSSION
N e t 2 a Net^{2a} Net2a的哪个策略发挥了作用。通过分解模型,测量识别最长10%的net length和path length性能。
“Edge ANN”: 使用edge feature 不适使用GNN;将edge feature聚合到目标节点上,与节点特征一起进行人工神经网络处理。
"Simple Net": 使用简单的GNN结构,节点卷积只使用一层GAT,边卷积只考虑边特征,且只包含一层权重
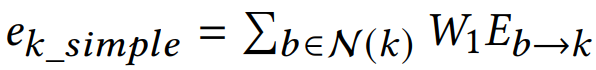
注:这是原始的: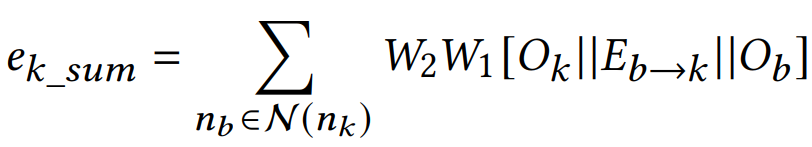
不考虑边特征时,“Edge ANN”和"Simple Net"的感受野分别减少到2和3-hop。
进一步,为了分析不同的边特征对模型的贡献。‘F0 Net’, ‘F1 Net’ and ‘F2+f 3 Net’ 分别表示只使用 F 0 , F 1 , F 2 & f 3 F0,F1,F2\&f3 F0,F1,F2&f3。‘Less 𝑃 Net’ 表示使用简单但是速度较快的partition P(for cell graph)

















 2227
2227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









