






一、shell基础
Linux系统中使用 GNU 命令支持三种不同类型的命令行参数
- Unix 风格,前面加单破折号
-vim - GNU风格,前面加双破折号
-- - BSD风格,前面不加破折号
如 ps 指令

可以看到 ps -ef 和 ps aux 这两个指令功能完全一样,只是两种不同命令风格而已
设置环境变量
需要写入环境变量配置文件才能在一系列shell中生效
/etc/profile #在这个文件写入会对所有用户生效
~/.bashrc #在这个文件写入只会对当前用户生效
为网卡添加临时 IP
# 为网卡添加临时IP
ifconfig ens33:1 192.168.109.201 netmask 255.255.255.0 # 方法一
ip addr add 192.168.109.201/24 dev ens33:1 # 方法二
# 删除方法
ip addr delete 192.168.109.201 dev ens33:1
脚本运行的几种方式 (脚本用处:批量的执行命令)
- bash script-name 或 sh script-name(推荐使用这种)
这是当脚本文件没有可执行权限时时常用的方法,不管脚本有无可执行权限都可以通过这种方式使用
- path/script-name 或 ./script-name
这是当脚本文件被赋予了可执行权限并且第一行指定了命令解释程序(一般为 #!/bin/bash)
- source script-name 或 . script-name
需要有可执行权限,source或者 “.” 命令的功能是:读入脚本并执行脚本,即在当前Shell中执行source或 “.” 加载并执行的相关脚本文件的命令及语句,而不是产生一个子Shell来执行文件中的命令。(这是和其他几种执行shell方式的最大不同)
shell 里面的所有东西都是字符串,即 shell 只有一种数据类型字符串
有两种类型的 shell 变量,变量都是键值对的形式,等号两边不能有空格
- 环境变量:环境变量可以从父进程传给子进程,因此 shell 的环境变量可以从当前 shell 进程传给 fork 出来的子进程;用 printenv 命令可以查看显示当前 shell 进程的环境变量
- 本地变量:本地变量只存在于当前shell进程,用set命令就可以显示当前shell进程中定义的所有变量 ( 包括本地变量和环境变量 ) 和函数
被双引号括住的内容,将被视为单一字符串;它防止通配符扩展,但允许变量扩展;这点与单引号的处理方式不同
“:” 是一个特殊的命令,称为空命令,该命令不做任何事;但 Exit Status 总是为真;
和 C 语言类似,“” 在 shell 中被用作转义字符,用于去除紧跟其后的单个字符的特殊含义(回车除外),换句话说,紧跟其后的字符取字面值
字符串替换
字符串替换规则为 ${parameter//pattern/string}
注意中间是两个// 代表的全部替换,中间是 / 代表替换字符串中第一次出现的模式
str=${parameter:~word} 使用 parameter 的值,如果 parameter 没有设置或者为 null,则使用word 的值赋值给 str
例1:替换标点将字符串变成字符串数组
string="hello,shell,split,test"
arr=(${string//,/ }) 加上()就变成了数组赋值,此时arr就是一个字符串数组
for var in ${arr[@]}
do
echo $var
done
命令 test 和 [ 属于条件测试命令;test 和 [ 可以互换,如 test -e /etc/passwd == [ -e /etc/passwd ]
[ -f file] 如果file存在且是一个普通文件则为真
[ -d dir ] 如果dir存在且是一个目录则为真
[ -z str ] 如果str的长度为0则为真
[ -n str ] 如果str的长度>0则为真
[ -s file ] 如果文件存在且非空则为真
[ str1 = str2 ] 如果两个字符串相同则为真
[ str1 != str2 ]如果两个字符串不相同则为真
[ ARG1 OP ARG2 ] 当且仅当 ARG1 和 ARG2 为整数或者取值为整数的变量
OP可以为:
-eq 等于 -ne 不等于 -lt 小于 -le 小于等于 -gt 大于 -ge 大于等于
echo $? 返回上一个进程退出时的返回值;如果为真返回0,为假返回1
作为一种好的编程习惯,应该总是把变量取值放在双引号之中
例:字符串比较
s1='Adas'
s2='Adas'
if [ ${s1} = ${s2} ]; then #写法2:这里不能使用eq,因为eq只能用于整数判断
if [[ ${s1} = A* ]]; then #支持正则
echo "hello"
fi
Shell 中的 “=~” 与 “==” 的区别在于前者支持正则表达式
[[ 7.6 =~ 7.6.* ]]
echo $? 输出0,代表相等
[[ 7.6 == 7.6.* ]]
echo $? 输出1,代表不相等
总结:
字符串比较用双中括号 “[[ ]]” 里面加 “=/!=”;算数比较用单中括号 “[ ]”,里面加 “-eq -ne -lt …”
算数运算用双小括号(());shell 命令及输出用小括号 ()
快速替换用花括号 {},表示取变量的值
Shell 中的各种符号
$()和反引号`` 作用一样,代表引用系统命令
$[] 和 $(()) 一样,都是进行数学运算的
[] 等价于 test命令
双小括号 (())
- 用于正数扩展,这种扩展运算是整形值的运算,
((exp))结果扩展并计算一个算数表达式的值,只要括号中的表达式符合C语言运算规则,都可用在$((exp))中 - 单纯用
(())也可以重定义新的变量值,如 a=5, ((a++)) 可将 a 重定义为6 - 用于算数比较,双括号中的变量可以不使用 $ 符号前缀,括号内支持多个表达式用逗号隔开,只要括号内的表达式符合C语言规则即可,如
for ((i=0;i<5;i++))
例1:输出 1-500 之间的所有7的倍数
for ((i=0;i<=500;i++))
do
if [ $[i%7] -eq 0 ]; then #写法1:这个eq只能用于整数值比较,字符串比较不能用
if [ $((i%7)) -eq 0 ]; then #写法2
if [[ i%7 -eq 0 ]]; then #写法3
echo $i
fi
done
[[]] 字符串比较,可以把右边当成一个模式而不仅仅是一个字符串 [[ hello == hell? ]]
逻辑运算符 &&、||、< 和 > 操作符能够正常存在于 [[]] 条件判断结构中,但是不能出现在[]结构中
if [[ $a != 1 && $a != 2 ]] 等价于
if [ $a -ne 1 ] && [ $a != 2 ] 等价于
if [ $a -ne 1 -a $a != 2 ]
可以看出使用 [[]] 内部如果有数学运算则不需要 $(()) ,可以将 [[]] 理解为就是在 [] 的基础上增加了正则和逻辑运算符
例2:输出一个文件中所有字符数小于8的单词
文件 test.txt 的内容如下:
how they are implemented and applied in computer
for i in `cat test.txt`
do
if [ `echo $i | wc -m` -lt 9 ]; then 方法1:注意这里是9,-m会统计换行符
if (( $(echo $i | wc -L) < 8 )); then 方法2
if (( $(expr length $i) < 8 )); then 方法3
if (( ${#i}<8 )); then 方法4:"#i"是计算变量i的字符个数
echo $i
fi
done
awk '{for(i=1;i<NF;i++) if(length($i<8)) print $i}' test.txt 方法5
esac 表示 case 语句块的结束;shell 脚本的 case 语句可以匹配字符串和 Wildcard,每个匹配分支可以有若干条命令,末尾必须要有 “;;” 结尾代表结束
break[n] 可以指定跳出几层循环
注:“ ( l s ) " l s 加上括号表示将 l s 当作命令执行; " (ls)" ls 加上括号表示将 ls 当作命令执行;" (ls)"ls加上括号表示将ls当作命令执行;"FILENAME” 表示取 FILENAME 变量里面的值
shell脚本调式方法:
- -n 读一遍脚本中的命令但不执行,用于检查脚本中的语法错误
- -v 一边执行脚本,一边将执行过的的脚本命令打印到标准错误输出
- -x 提供跟踪执行信息,将执行的每一条命令和结果依次打印出来
= 和 == 的区别
在 Shell 脚本中,== 和 = 是用于比较字符串的操作符,在大多数情况下,== 和 = 是等效的
= 或 == 两边的字符串需要使用双引号引起来,以避免由于特殊字符(例如空格)引起的问题
if [ "$str1" = "$str2" ]; then <=等价=> if [ "$str1" == "$str2" ]; then
echo "字符串相等"
else
echo "字符串不相等"
fi
内建命令:用户在命令行输入命令后,一般情况下 shell 会 fork 一个子进程并执行 exec 命令,但是 shell 的内建命令例外,执行内建命令相当于调用 shell 进程的一个函数,并不创建新的进程;
之前学过的 cd, alias, umask 以及 exit 命令都是内建命令,凡是用 which 命令查不到程序文件所在位置的命令都是内建命令
如 export,shift, if, eval, [ , for, while 等都是内建命令;内建命令虽然不会创建新的进程,但是也会有 Exit Status,执行结束后也会有一个状态码,也可以用特殊变量 $? 读出
echo 命令
#echo命令
echo "Hello" >> test.txt # ">>" 代表再原有文本后追加
echo "world" > test.txt # ">" 代表覆盖原有文本
“sh -c” 命令:它可以让 bash 将一个字串作为完整的命令来执行
sh -c "echo hello"
输出:hello
bash中的其他特殊符号
单引号 '':单引号内的所有特殊符号,如 $ 和 `` 都没有特殊含义
双引号 " ":双引号内中除去三个特殊符号 $ 代表调用变量的值,``代表引用命令,\ 代表转义字符, 其余都没有特殊含义
cut 命令:cut [选项] 文件名
-f 列号:提取第几列
-d 分隔符:设置间隔符号
cut -d ":" -f1 /etc/passwd #以":"作为分割,提取第一列
printf命令:
printf '%s %s %s\n' 1 2 3 4 5 6
# 输出结果为 1 2 3
# 4 5 6
print 命令与 printf 的区别是 print 会默认输出一个换行符,但是printf是Linux系统命令,print不是
而 awk 命令中既可以使用 print 也可以使用 printf
排序命令 sort:
sort [选项] 文件名
-n 以数值型进行排序,默认使用字符串型排序
-t 指定分隔符,默认分隔符是制表符
-f 忽略大小写
-r 反向排序
统计命令 wc:
wc [选项] 文件名
-l 统计行数
-w 统计单词数
-m 统计所有字符数
-L 显示最大宽度
echo "aaa"
wc -l 结果为1
wc -w 结果为1
wc -m 结果为4,包括后面的换行符或者空格
wc -L 结果为3,这个命令显示的就是实际的单词数
例1:shell 脚本(每隔一秒向文本文件输入当前日期)
touch hello.txt
while true
do echo $(date) >> hello.txt
sleep 1
done
例2:直接在 shell 终端测试是否存在 gcc 编译器
printf '#include<stdio.h>\nint main(){printf("cc OK!\n");}' > t.c && cc t.c && ./a.out && rm -f t.c a.out
用 source 执行脚本文件,执行过程不另开进程,脚本文件中设定的变量在当前 shell 中可以看到;
用 sh 执行脚本文件,是在当前进程另开一个子进程来执行脚本命令,脚本文件中设定的变量在当前 shell中不能看到
#!/bin/sh
echo "number:$#" # $# 是传给脚本的参数个数 (使用 sh xxx.sh 才可显示,使用 source xx.sh不显示)
echo "scname:$0" # $0 是脚本本身的名字
echo "first :$1" # $1是传递给该shell脚本的第一个参数
echo "second:$2" # $2是传递给该shell脚本的第二个参数
echo "argume:$@" # $@ 是传给脚本的所有参数的列表
附:$$ 是shell 本身的PID
Vim 多行注释
Crtl+v 进行 visual block 模式
按 j 或者 k 选中多行
按 大写I 进入插入模式,输入 '#'
之后按 Esc 键
取消注释
Ctrl + v 之后按 j 选中多行
按 d 取消即可
末行模式下
:1,$ s/^/HELLO/g 在所有行的开头加上"HELLO"
:1,$ s/$/WORLD/g 在所有行的末尾加上"WORLD"
vim 相关配置:~/.vim 目录是用来存放当前用户 vim 的相关配置文件
/etc/vim 用来存放存放全局的vim配置(就是适用于所有用户,会对所有用户生效)
文件
vimrc 用户配置文件,如显示行号等
set nu 显示行号
set tabstop=2 设置Tab长度为2
vim 退出viusal模式,在该模式下鼠标无法执行复制和粘贴功能
vim /usr/share/vim/vim81/defaults.vim 找到下面这三行注释掉即可
if has('mouse') 开启鼠标的复制粘贴功能,a表示所有模式
set mouse=a
endif
doc 为插件防止文档的地方
spell 拼写语法检查
syntax 语法描述脚本
目录
colors/ 存放vim配色方案
plugin/ 存放每次启动vim时都会被运行一次的插件
autoload/ 存放是当你真正需要的时候才被自动加载运行的文件,而不是在vim启动时就加载
zsh 和 Linux下的 sh、bash、csh等一样也是一个shell (命令解析器),oh-my-zsh是围绕zsh的一个开源项目,用来定制化 zsh 的
将 shell 从 bash 切换到 zsh 后,原来的/etc/profile 这些配置文件只针对bash起作用,需要将环境变量相关写在 .zshrc 中
export GOROOT=/usr/local/go
export PATH=$PATH:$GOROOT/bin
export GOPATH=/home/zhujinchao.0713/Golang
source <(kubectl completion zsh) #k8s命令行的补全脚本
注意shell和vim的区别,vim是一个编辑器,而shell是一个命令解释器(就是我们看到的终端),所以环境变量相关的命令需要配到.zshrc这类文件中;而vim的一些提示,比如文本高亮 syntax on 这些命令需要配置到 .vimrc这类文件中
Linux 修改用户默认的shell,参考这篇文章
如果觉得iterm2的字体厚度不够,可以在设置里把这个选项选成never,不开启抗锯齿功能

注意区别:ITerm2 是一个终端,zsh是一个shell(命令解析器)
代码里的左侧颜色标识
红色:未加入版本控制(刚clone到本地)
绿色:已经加入版本控制暂未提交
蓝色:加入了版本控制,已提交,有改动
白色:加入了版本控制,已提交,无改动
灰色:版本控制已忽略该文件
Vscode 上的mac提示快捷键

-
今天遇到一个问题,在开发机上vscode无法调试,按下F5之后总是一下就跳过,发现原来是vscode是不支持 软链 接的,而我调试所在的目录是通过链接进去的,所以调试不了,把目录位置改成
/data00/home/zhujinchao.0713就可以了

-
echo
注意:echo 后面如果接的是命令,而不是一个简单的文本参数,加双引号或者不加双引号这是两个区别
在shell中,echo $(ls)和echo "$(ls)"的区别在于
- 命令替换(command substitution)的方式
- 被传递给
echo命令的参数的形式。
echo $(ls)使用命令替换将ls命令的输出作为参数传递给echo命令。在执行命令替换之后,shell会将ls命令的输出按照空格分隔成多个单词,并将这些单词作为单独的参数传递给echo命令。因此,如果ls命令的输出包含空格或其他特殊字符,这些字符可能会被解释为命令参数的分隔符或具有其他意义的字符。例如,如果ls命令的输出包含文件名中带有空格的文件,则这些文件名中的空格可能会被解释为命令参数的分隔符,导致echo命令不会正确地输出这些文件名。
echo "$(ls)"使用双引号将ls命令的输出作为一个整体 字符串传递给echo命令。在使用双引号时,shell会将ls命令的输出作为单个参数传递给echo命令,并且保留输出中的空格和其他特殊字符的字面含义。因此,使用双引号的命令可以正确地输出 ls 命令的所有输出,包括文件名中带有空格或其他特殊字符的文件名
总结:加了 “” 就是命令输出什么,则 echo 也输出什么
不加 “” 就是 echo 输出时忽略掉换行符
二、正则表达式
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配;grep,awk,sed 等命令都可以支持正则表达式
通配符用来匹配符合条件的文件名,通配符是完全匹配 (精确匹配);ls,find,cp这些命令不支持正则表达式,所以只能使用shell自己的通配符来进行匹配
通配符可以看作是正则表达式的一部分
通配符字符类:
* 匹配0个或者多个任意字符
? 匹配单个任意字符
"-" 在[]括号内表示字符范围
"^" 位于[]括号的开头,匹配除括号中的字符之外的任意一个字符
[若干字符] 匹配方括号中任意一个字符
正则中数量限定符
?表示紧跟在它前面的单元应该匹配 0次或者1次
- 表示紧跟在它前面的单元应该匹配 1次或者多次
- … 0次或者多次
{N} … 精切匹配N次
{N, } … 至少N次
{, N} … 至多N次
{M, N} … 出现[M, N] 次
正则中位置限定符
^ 匹配行首的位置
$ 匹配行尾的位置
< 匹配单词开头的位置
> 匹配单词结尾的位置
\b 匹配单词开头和结尾的位置
\B 匹配非单词开头和结尾的位置
\w 匹配任何英文、数字、下划线 等价于 [A-Z a-z 0-9 _]
\W 与上面的相反 等价于 [^A-Z a-z 0-9 _]
正则种类:Basic 正则和 Extended 正则
使用 grep 用的基础正则;使用 egrep 用的是扩展正则
两者的区别在于对于基础正则 “( )”, "{ }"小括号和中括号都需要转义
正则表达式匹配IP地址
egrep "^((25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9][0-9]|[0-9]).){3}(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9][0-9]|[0-9])" file
三、sed、awk 工具
sed 意为流编辑器(Stream Editor),在 shell 脚本和 Makefile 中作为过滤器使用非常普遍,也就是把前一个程序的输出作为后一个程序的输入,经过一系列编辑命令转换成另外一种格式输出;sed 和 vi 都源于早期 Unix 的ed工具,所以很多 sed 命令和 vi 的末行命令都是相同的
sed [选项] '[动作]' 文件名 (动作需要加上引号)
选项:
-n 一般 sed 命令会把所有数据输出到屏幕,如果加上此选项,则只会把经过sed命令处理的行输出到屏幕
-e 允许对输入数据应用多条sed命令编辑
-i 用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出
sed 以行为单位处理文件,awk 比 sed 强的地方在于不仅能行为单位,还能以列为单位处理文件
sed常用参数:
a, append 追加 sed "2a xxxx" test.sh 在第2行后另起一行追加
i, insert 插入 sed "2i xxx" test.sh 在第2行插入
d, delete 删除 sed "2,4 d" test.sh 删除第2到4行
s, substitution 替换 sed "s/echo/printf/g" 将 echo 替换成 printf,后面的 /g 表示如果一行存在多个则全部替换
s是字符串替换,c是行替换
& 表示替换命令,如 sed -i 's/hello/#&/g' test.txt 将文件中的所有 hello 字符串前面加上#,如果改成 &# 代表在匹配的字符串后面加上#
所以Linux下禁用swap分区可以这么写
sed -i 's/.*swap.*/#&/' /etc/fstab #永久关闭
例1:提取IP地址
# 文本IP如下
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
cat IP | sed 's/^.*addr://' | sed 's/Bcast:.*$//' # ^代表开头,$代表末尾
例2:去除文件中非数字的内容
如 test.txt 文件内容为
a12b8
dsad1sbs
w12b33
vv89b8
只需要提取里面的数字字符
sed 's/[^0-9]+//g' test.txt
正则的 + 需要做一个转义, ^ 放在 [] 里面表示匹配除去括号内的所有内容
之后将其替换成空即可
awk 是以文件中的一行为单位进行处理的,每接收文件的一行,然后调用对应的命令来处理文本
在 awk 中,文件的每一行由域分隔符分开的每一项称为一个域,在不指定 -F 域分割符的情况下,默认的域分割符是空格
awk 选项 '模式或条件 {编辑命令}' 文件1 文件2
选项:
-F 指定分割行的标志
'{}' 单引号加上大括号表示对数据的处理动作
awk 包含的内建变量
NF: 当前处理的行的字段数(也叫做域的数量,当一行为非空行时,NF为正值;空行则NF的值为0)
NR: 当前处理的行的行号(行号从1开始)
$0: 当前处理的行的整行内容
$n: 当前处理行的第 n 个字段(也称为域)
注意两个关键词 BEGIN 和 END
BEGIN{这里面放的是执行前的语句}
{这里面放的是处理每一行要执行的语句}
END{这里面放的是处理完所有的行后要执行的语句}
awk 'BEGIN{x=0};//bin/bash$/{x++};END{print x}' /etc/passwd
统计以/bin/bash结尾的行数
例:对于文本 test.txt, 打印字母数大于5的单词
Hello world I am a handsome student
方法一:
awk 'BEGIN{FS="";RS=" ";}{if(NF>5) print}' test.txt
FS: 指定列分隔符
RS: 指定记录分隔符,也就是行分隔符,默认是'\n';现在就是遇见 " " 则切割为一行
指定上面两个选项之后,就将单词切割成了列形式
Hello
world
...
student
之后统计每一列的字段个数即可,由于指定列分隔符为空,所以这里的字段个数就是指的单词字符个数
方法二:
cat test.txt | xargs -n 1 | awk 'length($1)>5 {print $0}' 这个$0加不加都可以
例3:统计文本中每个单词出现的次数,以词频升序排列
demo.txt 文本如下
welcome byte
welcome to byte
byte
应该输出:
to 1
welcome 2
byte 3
cat demo.txt | xargx -n 1 | sort | uniq -c | sort -n | awk '{print $2,$1}'
xargs 会把输入的内容全部做一行输出,这里 -n 参数就指定每一行输出一个单词,默认的分隔符是空格
uniq 只会统计相邻元素,所以需要先用sort排个序, -c 表示在单词前面加上出现次数
之后再使用 sort -n 就是以词频排序
使用 awk 先打印第二列,再打印第一列
args 的默认输入命令是 echo,空格是默认定界符。这意味着通过管道传递给 xargs 的输入会包含换行和空白。不过通过xargs的处理,换行和空白将被空格取代。意思就是说,将一段文本内容传给 xargs 时,xargs会 将其中包含的换行和空格区域都替换成空格。这样的话,文件的内容就不再是多行而是只有一行内容
例4:去掉不需要的单词
test.txt 文本如下
big
nowcoder
Betty
basic
testing
要求:去掉输入中含有B和b的单词
grep -vi B test.txt #-i表示忽略大小写
grep -v [Bb] test.txt
awk '$0!~/[Bb]/{print $0}' test.txt
awk '!/[Bb]/' test.txt #上面的简写
sed '/[Bb]/d' test.txt
sed '/b|B/d' test.txt 不使用[]则需要转义|符号,因为sed默认使用的是基础正则
sed -E '/b|B/d' test.txt 使用扩展正则不需要转义
四、脚本实操
function read_dir() {
for file in `ls $1` #shell里面把反引号里面的命令认为是系统命令,$1是函数第一个参数
do
if [ -d $1/$file ] #判断是否是目录,是目录则递归
then
read_dir $1"/"$file
elif [ -f $1"/"$file ] #判断是否是文件,是文件则打印并修改权限
then
echo $1"/"$file #输出文件名字
chmod -w $1"/"$file #修改权限
fi
done
}
INIT_PATH='/home/chao/Documents/Software/go/src/' #初始化想要遍历的目录的路径
read_dir $INIT_PATH
#函数调用并传入这个路径,这个路径就是函数的第一个参数,由上面的$1接受
第一步: 将文件的内容通过管道(|)或重定向(<)的方式传给while
第二步: while中调用read将文件内容一行一行的读出来,并付值给read后跟随的变量。变量中就保存了当前行中的内容
方法一:使用管道
cat ./hello.txt | while read LINE; do
echo ${LINE}
done
方法二:使用重定向
while read LINE; do
echo $LINE
done < ./hello.txt
五、Linux管理
Linux 下文件目录结构
/bin(binary的缩写) 存放着经常使用的命令
/boot 存放的是启动Linux的一些核心文件,包括一些链接文件和镜像文件
/dev (device的缩写) 存放的 Linux 的外部设备,在 Linux 中访问外设的方式和访问文件的方式是相同的
/etc 用来存放所有的系统管理的配置文件
/home 目录是用户的主目录,在 Linux 中每一个用户都有一个自己的目录,一般该目录名是以用户的账号名命名的
/lib 目录存放的是系统最基本的动态链接共享库,其作用类似与 Windows 中的DLL文件
/media Linux会自动识别一些设备,例如U盘和光驱等,当识别后就自动挂载在该目录下,不能识别则需要我们手动挂载在 /mnt目录下
/mnt /opt /media 都是用来让用户挂载别的文件系统
/sbin (super binary 的缩写) 目录存放着管理员使用的系统管理程序,普通用户用不到这里面的东西,仅限管理员
/usr (unix shared resource 共享资源的缩写) 称为用户软件资源目录,用户的很多软件都会装在该目录下
/tmp (tempoary 的缩写) 临时文件
/var (variable 变量的缩写),存放一些缓存和一些需要动态变化的文件
Linux下文件和目录的颜色对应
白色----普通文件 蓝色----目录 绿色----可执行文件 红色----压缩文件 青色----链接文件
黄色----设备文件 灰色----其他文件(很少见)
chown 改变文件的所有者和所属组 chown [选项] [所有者][:][所属组] [文件名]
chown chao:chao /usr/test.txt #将test.txt文件所有者和所属组改变为chao和chao
groups 用来查看用户属于哪些用户组
groups root 查看用户chao属于哪些用户组
sudo 和 su 的区别
sudo 是用于借用管理员权限; su 是用于切换不同的用户身份
su 使用一定要加 '-' ,否则只是切换身份,没有切换环境变量
su - 切换成root用户,需要输入root用户的密码
sudo su - 切换成root用户,需要输入当前用户的密码
sudo `cmd` 输入的也是当前用户的密码
sudo -i 为了频繁的执行某些只有超级用户才能执行的命令,而不用每次输入密码,可以使用该命令,要求执行该命令的用户必须在sudoers中才行
给用户增加权限
Linux 下新创建的用户没有权限执行相关命令

只需按照提示将新建用户加入到 sudo 用户组即可
gpasswd -a chao sudo #加入用户组
newgrp sudo #更新用户组
之后查看 /etc/group 文件发现用户 chao 已经加入到了 sudo 用户组中

也可以直接打开 /etc/group 文件在 sudo 用户组后面添加上用户 chao
配置文件解析
hosts 文件
/etc/hosts 是一个没有扩展名的系统文件,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联 “数据库”,当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从 hosts 文件中寻找对应的 IP 地址,一旦找到系统便直接进行访问,如果没有找到则会再将网址提交DNS域名解析服务器解析出 IP 地址
VMware在默认安装完成之后,会创建三个虚拟的网络环境:VMnet0、VMnet1 和 VMnet8 (就是 vmware 提供的三种不同的虚拟交换机);
其类型分别为:桥接网络,Host-only 和 NAT
桥接:表示你的虚拟机与本地主机是同一级别,因此你的虚拟机与主机必须在同一个网段,虚拟机才能上网。虚拟机可以上外网,虚拟机之间也可以通信。如果需要使用 ftp,ssh,就需要使用这种网络环境
NAT:网络地址转换(NET Address Transform),这种情况,虚拟机与主机就不是一个级别的,虚拟机相当于寄宿在了主机中。这种情况虚拟机之间可以通信,虚拟机也可以访问局域网内的其他主机。但是局域网内的其他主机就不能访问虚拟机,而虚拟机可以通过主机来访问公网
Host-only:此时的虚拟机与主机存在一个与外界完全封闭虚拟网络中,虚拟机也只能与主机通信。如果虚拟机需要一个绝对安全的内网环境,就可以使用这种
动态获取IP命令:
sudo dhclient
Unicode 和 UTF-8 编码
Unicode编码:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。Unicode采用四个字节为每个字符编码,意思就是四个字节编码能囊括世界上所有字符。
UTF-8:Unicode编码的转换格式,可变长编码,相对于Unicode更节省空间,其可以使用 1~4 个字节来表示一个符号;UTF-8 是 Unicode 的实现方式之一
UTF-8编码规则:
- 对于单字节的符号,字节的最高位设为0,后面七位是这个符号的 Unicode 编码。所以对于英文字符(编码为 0~127),ASCII 编码和 UTF-8 编码完全相同
- 对于n字节的符号,第一个字节的前 n 位都设为1,第n+1位设为0,后面字节的前两位一律设为 10;剩下的符号位为这个符号的 Unicode 编码
所以 UTF-8 表示的字符范围如下,只能表示 0~2097151字符
1字节:0xxxxxxx 0~127
2字节:110xxxxx 10xxxxxx 128~2047
3字节:1110xxxx 10xxxxxx 10xxxxxx 2048~65535
4字节:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 65536~2097151
例:汉字 “朝” 的 Unicode 编码为 26397,转换成二进制为 110011100011101
从上面的表可以看出 26397 占三个字节,所以 UTF-8 编码为 111001101001110010011101,即15113373
查看一个服务可以使用 systemctl 或者 service 命令,推荐使用 service 命令
重启,暂停,停止服务也推荐使用 service 命令
如:service ssh restart|stop
- 服务端 创建共享目录,修改配置文件,重启服务
sudo apt install nfs-kernel-server
vim /etc/exports
#/ 10.3.0.0/16(rw,sync,insecure,no_subtree_check,no_root_squash)
#服务器端共项目录 -权限 -network 客户端ip
#/share -rw (-network 10.3.45.37)这个括号中内容可以不加
- 客户端 挂载服务器共享目录
apt-get install nfs-common #下载nfs命令
sudo mount 10.7.20.132:/home/chao/Documents/nfs /mnt
#将服务器上的共享目录挂在到我客户机的/mnt目录
tree /mnt #就可以查看到共享的文件
umount /mnt #取消挂载
1.SSH 分为客户端openssh-client 和 openssh-server
如果只是想登陆别的机器,客户端只需要安装 openssh-client(ubuntu有默认安装,如果没有则 sudo apt install openssh-client)
如果要使本机开放 SSH 服务就需要安装 openssh-server
2.查看 SSH 客户端版本
ssh -V #查看版本
3.确认 ssh-server 是否启动
ps -ef | grep ssh #或者
netstat -tlp
如果看到 sshd 那就说明 ssh-server 已经启动了,只有 ssh-agent 就说明 ssh-server 还没有启动
4.客户端登录 SSH
ssh username@remote_ip # 如 ssh chao@192.178.0.1
scp 命令传文件
scp [源文件目录加文件名] [user@ip]:[拷贝过去的目标文件目录]
SSH配置远程免密登录
- 使用命令
ssh-keygen -t rsa生成公钥和私钥 - 将公钥文件
id_rsa.pub拷贝到需要远程登录的服务器用户家目录下的.ssh/authorized_keys文件下(文件目录如果没有自已手动创建),之后 ssh 连接无须密码登录 - 配置
ssh [hostname]直接登录,无需输入密码
- 在本地 .ssh 目录下新建一个 config 文件,写入需要连接的远程服务器的信息,如下

之后直接 ssh node 即可登录远程服务器
附:ssh_config 是客户端 (也就是本机连接其他服务器) 的配置文件,sshd_config 是服务端 (也就是本机开放远程连接) 的配置文件
ssh 免密登录原理实际上是在连接的时候客户端会把私钥 (就是用户家目录下的 .ssh/id_rsa 文件中的内容) 与需要连接的服务端进行一个校验,因为服务端的 authorized_keys 存储的就是对应的公钥;客户端的 id_rsa 就好比一把钥匙,而authorized_keys 就好比一把锁,就是验证这个锁能否打开这个钥匙,如果匹配成功则无需密码即可登录
SSH 密钥登录具体可分为以下几步:
预备步骤,客户端通过ssh-keygen生成自己的公钥和私钥。
第一步,手动将客户端的公钥放入远程服务器的指定位置。
第二步,客户端向服务器发起 SSH 登录的请求。
第三步,服务器收到用户 SSH 登录的请求,发送一些随机数据给用户,要求用户证明自己的身份。
第四步,客户端收到服务器发来的数据,使用私钥对数据进行签名,然后再发还给服务器。
第五步,服务器收到客户端发来的加密签名后,使用对应的公钥解密,然后跟原始数据比较。如果一致,就允许用户登录。
如果您的 .ssh 目录中有多个私钥文件,但没有使用 -i 参数指定要使用的密钥文件,SSH 客户端将按照下述顺序查找私钥文件,并使用找到的第一个可用的私钥文件进行身份验证
id_rsa
id_dsa
id_ecdsa
id_ed25519
校验私钥对应的公钥: ssh-keygen -t ed25519 -y -f id_ed25519_vei
使用特定的私钥登录:ssh -i ./ssh/id_ed25519_vei root@10.37.65.117
-t 参数:指定生成的密钥类型,有 dsa | ecdsa | ecdsa-sk | ed25519 | ed25519-sk | rsa 这几种
-y 参数:用于从已有的私钥文件中提取公钥
-i 参数:指定要使用的密钥文件
Q:ssh 连接成功后总是过段时间就断开?
答:这是因为有些路由器检测到有些TCP连接闲置时间过长没有数据包传输就会将其断开,解决方案就是让服务端或者客户端按时发送心跳包即可
选择将客户端定时发送心跳包即可,因为这样只需要配置一次,在用户家目录下的 .ssh/config 中加入以下几行即可
Host *
ServerAliveInterval 60
Q:配置root用户远程登录
有时我们忘记了root用户密码,但是又想使用root用户远程登录到机器,这时候可以如下操作
注:Ubuntu 默认不允许 root 直接用户远程登录,但是可以先普通用户登录后再切换到 root 用户
这里切换root用户,使用 sudo su -,这样输入的是当前用户的密码
如果想直接使用 root 登录,在需要登录的主机上的 /etc/ssh/sshd_config 文件中找到 PermitRootLogin 在其下加入一行允许 root 远程登录即可

再在本机上新建一个公钥,放在root目录下的 /root/.ssh/authorized_keys,之后就可以 ssh root@远程IP
Q: 公钥复制到了目标主机的 authorized_keys 中但还是无法登录
考虑是否是以下原因:
-
是否开启了
PubkeyAuthentication yes,未开启的话,则只能使用用户名和密码登录 -
是否开启了
PermitRootLogin yes,未开启的话则root用户不能远程直接登录 -
防火墙
今天发现了一件事,使用 ufw 命令关闭了防火墙,但是发现使用 systemctl status firewalld.service 命令却显示防火墙依然是 running 状态


注意:使用 ufw 和 firewall 这两个命令互相独立,都是用于防火墙控制,当它们同时安装在服务器上时,就可能有冲突;只关闭 ufw 没有关闭 firewall 则防火墙仍然不能正常关闭
Linux 防火墙相关指令
常见的 linux 系统防火墙有:ufw、firewall、iptables,其中,
- ufw 是 Debian/Ubuntu 系列的默认防火墙
- firewall 是红帽系列7及以上的防火墙(如 CentOS 7.x)
- iptables 是红帽系列6及以下(如 CentOS 6.x)的防火墙
首先,iptables 是最底层、最古老的防火墙系统,所有系统都会存在此防火墙,但一般而言只需保证该防火墙处于完全开放状态即可,其他不用管他,更不需要复杂的配置。而 ufw 和 firewalld 都是较新 linux系统上的替代 iptables 的工具,当他们同时安装在服务器上时,两者之间就会存在冲突
所以 ufw 和 firewall 这两个只需要安装一个即可,在 Ubuntu 内置 ufw,不需要安装 firewall
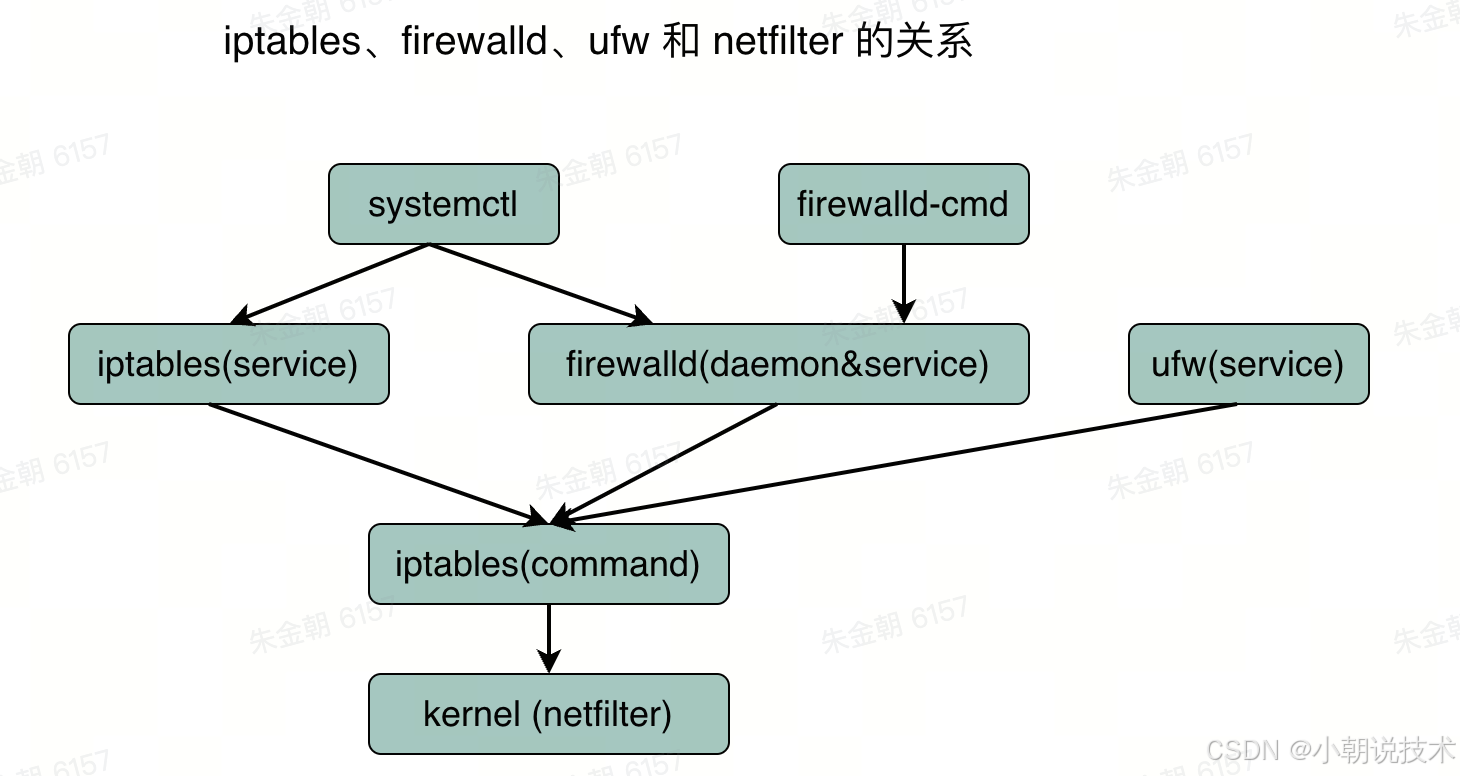
ufw 指的就是 Uncomplicated firewall,使用该命令来配置防火墙
开启 ufw 服务
systemctl status ufw.service 1.这是系统层面的开启
ufw enable 2.这是应用层面的开启(用这个开启和关闭,上面不用)
ufw allow 80 #开放指定端口
ufw deny 80 #关闭指定端口
ufw deny from 192.168.1.0/24 #拦截指定网段内的地址
ufw deny from 192.168.1.23 #拦截指定IP
ufw allow from 192.168.1.0/24 to any port 80 #向某个网段内的地址开放指定本机的80端口
ufw status numberd #查看防火墙规则
ufw insert 1 deny freom 192.168.1.23 #新插入规则放在第一条
端口号用于在传输层区分上层应用层的协议
防火墙概念及其分类
- 包过滤防火墙:针对 IP(源IP、目标IP)及端口(源port、目标port)两个条件进行数据包的安全过滤,不考虑其他任何因素
- 状态防火墙:包括包过滤防火墙的所有功能,同时追踪数据包的每一个工作状态,主要是多个一个状态检查表
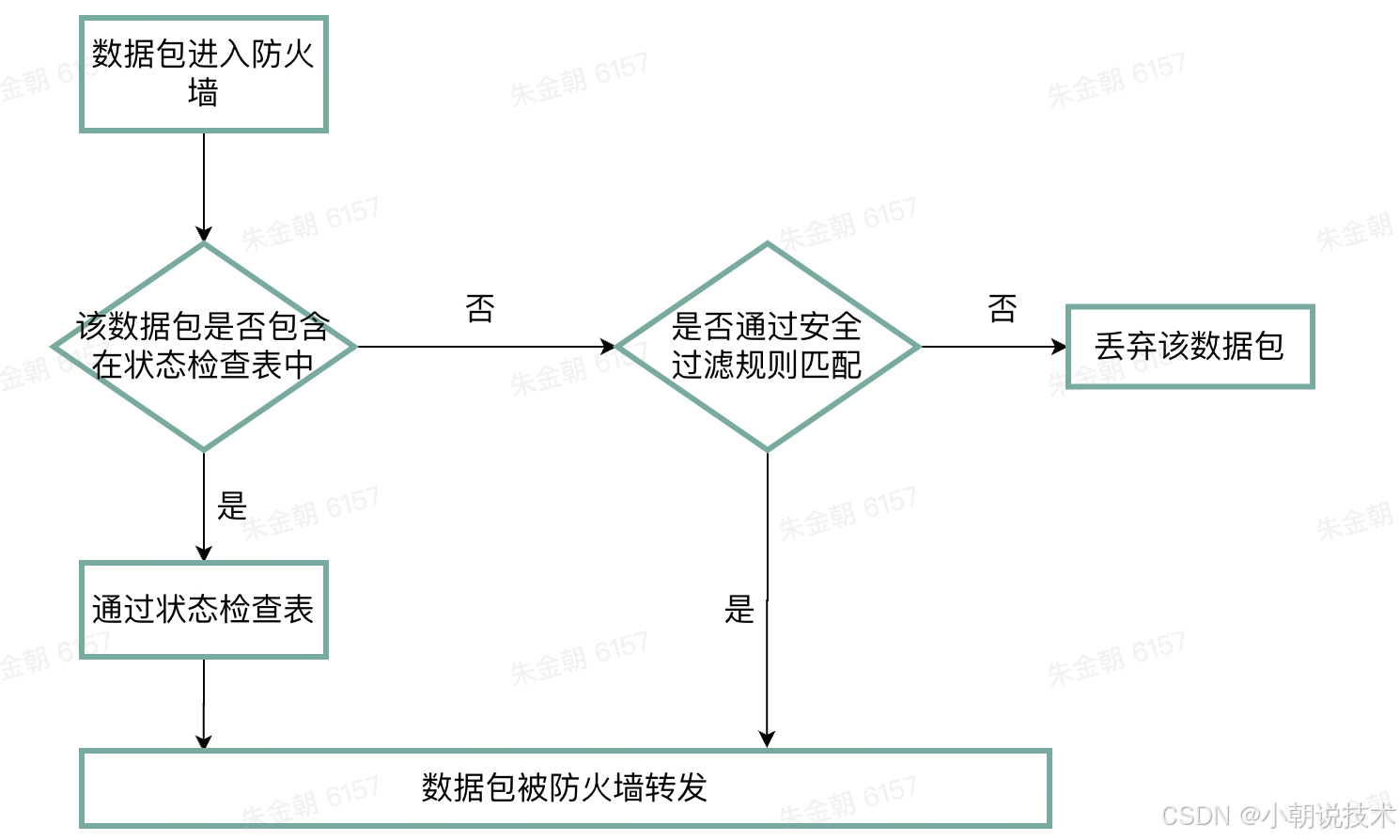
流量分类
- 入站流量:目标地址为防火墙所在服务器
- 出站流量:源地址为服务器
- 转发流量:源地址和目标地址均不是防火墙所在服务器
Iptables 策略与规则链 (5表5链)
Iptables 服务把处理或过滤流量的策略称为规则,多条规则组成一个规则链(chains)
iptables 具有5条规则链,处理各个传输环节的数据包
- PREROUTING:路由选择前,路由选择前处理数据包;入站包及转发包都可以使用
- INPUT:路由选择后,目的地为本机,入站包才可以使用
- OUTPUT:本机产生的数据包对外转发,出站包才可以使用
- FORWARD:路由选择后,目的地不为本机,转发包才可以使用
- POSTROUTING:离开本机网卡前,路由选择后处理数据包,所有数据包都可以使用,最后一步的处理,如 SNAT(源地址转换),地址伪装等
5张表(注意:表不包含链,表是指的规则的类别,这种类别的规则可以放到 input 链,也可以放到 output 链中)
- Filter 表:包过滤,使用三条链,INPUT,FORWARD,OUTPUT
- Nat 表:地址转换,只是实现源地址到目标地址的转换,使用三条链,PREROUTING,OUTPUT,INPUT,POSTROUTING
- Mangle 表:修改数据包的相关内容,如TTL,TOS字段等,其主要作用就是给数据包打标记,以便于做如策略路由的操作,该表可以使用所有链
- Raw 表:连接跟踪管理,可以选择不追踪某些数据包,默认系统的所有数据包都会被跟踪
- Security 表:强制访问控制 MAC
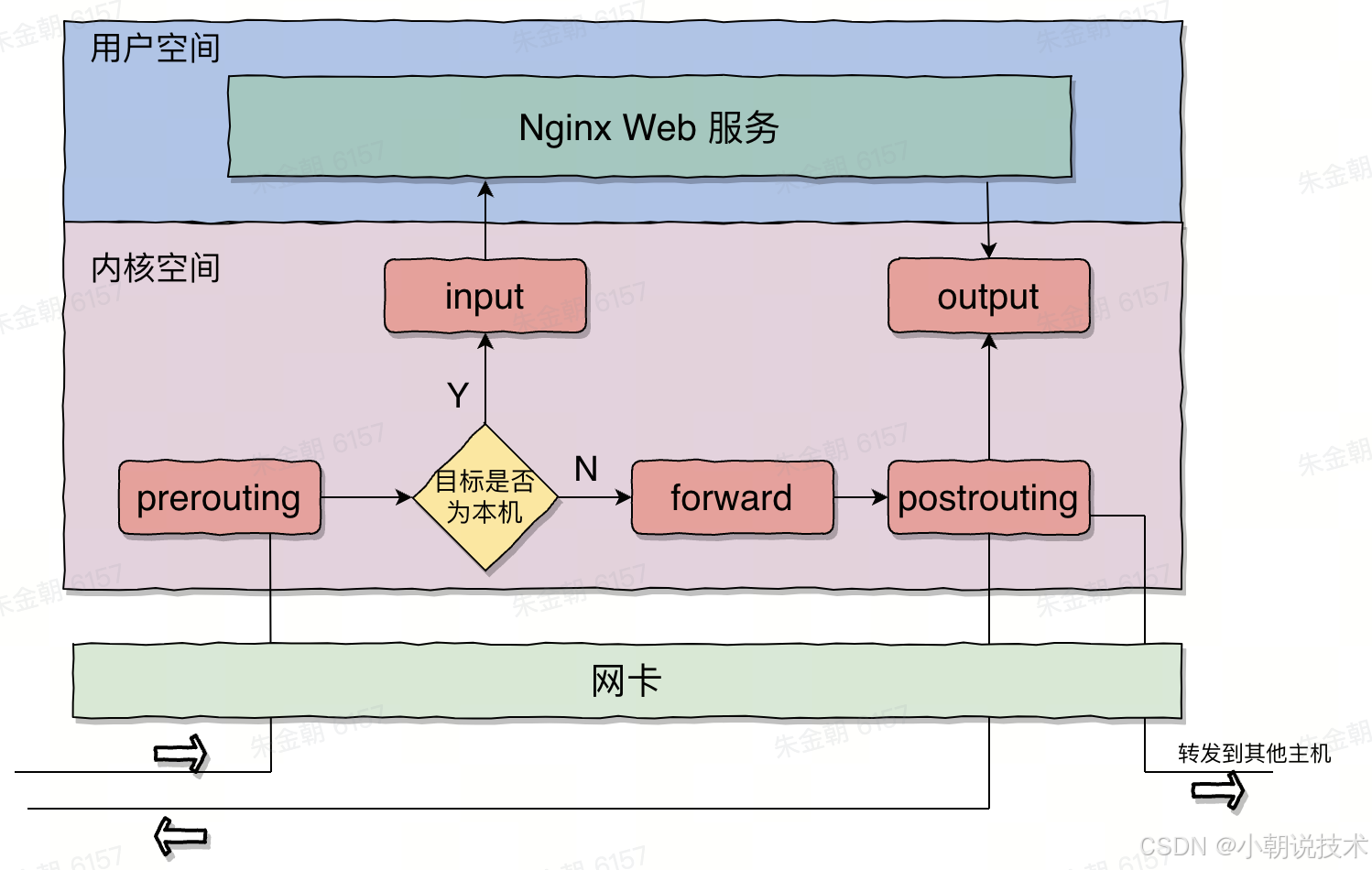
以后个人机上主要配置的就是 filter 表中的 input 和 output 链
Iptable 操作
防火墙规则从上往下配置,一旦匹配到相关规则,则剩余的规则不会再检查
iptables [-t talbe] CMD [option] [chain] <rules> -j <target>
CMD 命令就是增删改查
操作选项:
-A 规则链末尾添加规则
-I 指定的规号位置插入一条规则,需要先使用 --line-number 选项确定插入的位置
-R 替换掉指定的规则
-D 删除指定的规则
iptables -vnL
-v 表示显示详细信息,包括每条规则的匹配包数量和匹配字节数
-n 表示显示规则的时候不要显示协议或者主机的名称,只显示ip地址和端口
-L 列出链中的规则
iptables -A INPUT -p tcp --dport 22 -j ACCEPT 本机开放22端口
iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT 让本机从源端口22进来的数据包再放行出去,是从源端口22进来的数据包,不要理解成从22端口出去
iptables -P INPUT DROP 更改 INPUT 链的默认规则
iptables -P OUTPUT DROP 更改 OUTPUT 链的默认规则
配置进来的数据包只要成功建立连接则自动放行出去
iptables -A INPUT -p tcp -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
iptables -A OUTPUT -p tcp -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
以后防火墙先把这三条规则配置好,新添加的规则直接就放在 INPUT 链下即可,不再需要管 OUTPUT 链

查看网关:ip route show
六、Linux 系统编程
/proc/sys/fs/file-max 查看系统能够打开的最大的文件数目
Socket 通信原理
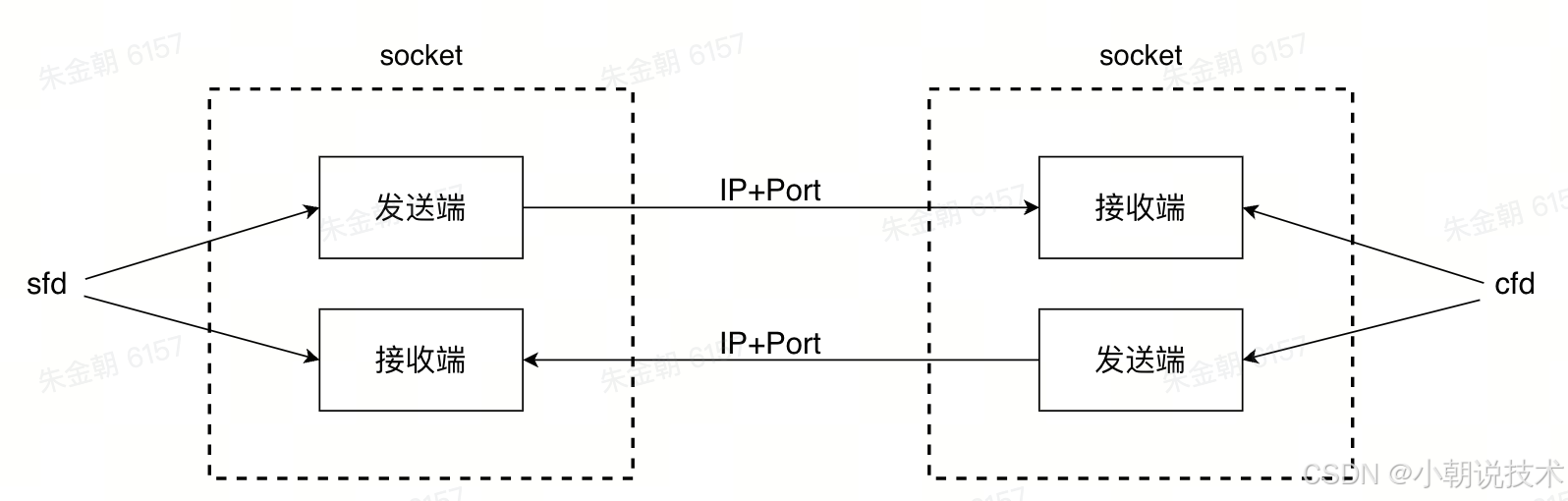
socket 一定是成对出现的, sfd 表示服务端文件描述符,cfd 表示客户端文件描述符
一个文件描述符指向两个缓冲区,这样便可以同时读写
select 和 epoll 的伪代码
select 与平台无关,无论是 Linux 和 windows 还是 Mac 都有,因为其是C语言的一个库函数
poll 和 epoll 只有 Linux 平台有,其是系统函数
select 伪代码
while true {
select (流[]); //阻塞
//有消息到达
for i in 流[]{
if i has 数据{
读 或者 其他处理
}
}
}
epoll 伪代码
while true {
可处理的流[] = epoll_wait(epoll_fd); //阻塞
//有消息到达,全部放在"可处理的流[]"中
for i in 可处理的流[]{
读 或者 其他处理
}
}
同步、异步、阻塞、非阻塞的区别
- 同步:我调用一个功能,该功能没有结束前,我死等结果
- 异步:我调用一个功能后立刻返回,不需要立刻知道该功能结果,有结果后回调通知我即可
- 阻塞:调用一个函数,该函数没有接收完数据或者没有得到结果之前,函数不会返回
- 非阻塞:调用一个函数,该函数立刻返回,通过 select 通知调用者
同步IO和异步IO区别在于:数据拷贝的时候进程是否阻塞
阻塞IO和非阻塞IO区别在于:应用程序的调用是否立刻返回
多路IO是一种同步IO模型,实现一个线程可以监视多个文件描述符,一旦某个文件描述符就绪,就能够通知应用程序进行相应的读写操作,没有文件描述符就绪时就会阻塞应用程序并交出CPU
多路指的是多个网络连接,复用指的是同一个线程
总结:多路复用只是指的用同一个线程/进程监控多个socket连接(注意这个进程只负责监控,但是处理连接请求既可以使用单线程也可以使用多线程)
一次IO访问会经历两个阶段:内核准备数据 -> 将数据从 kernel 区拷贝到 user 区
阻塞IO和非阻塞IO(以 read 来举例)
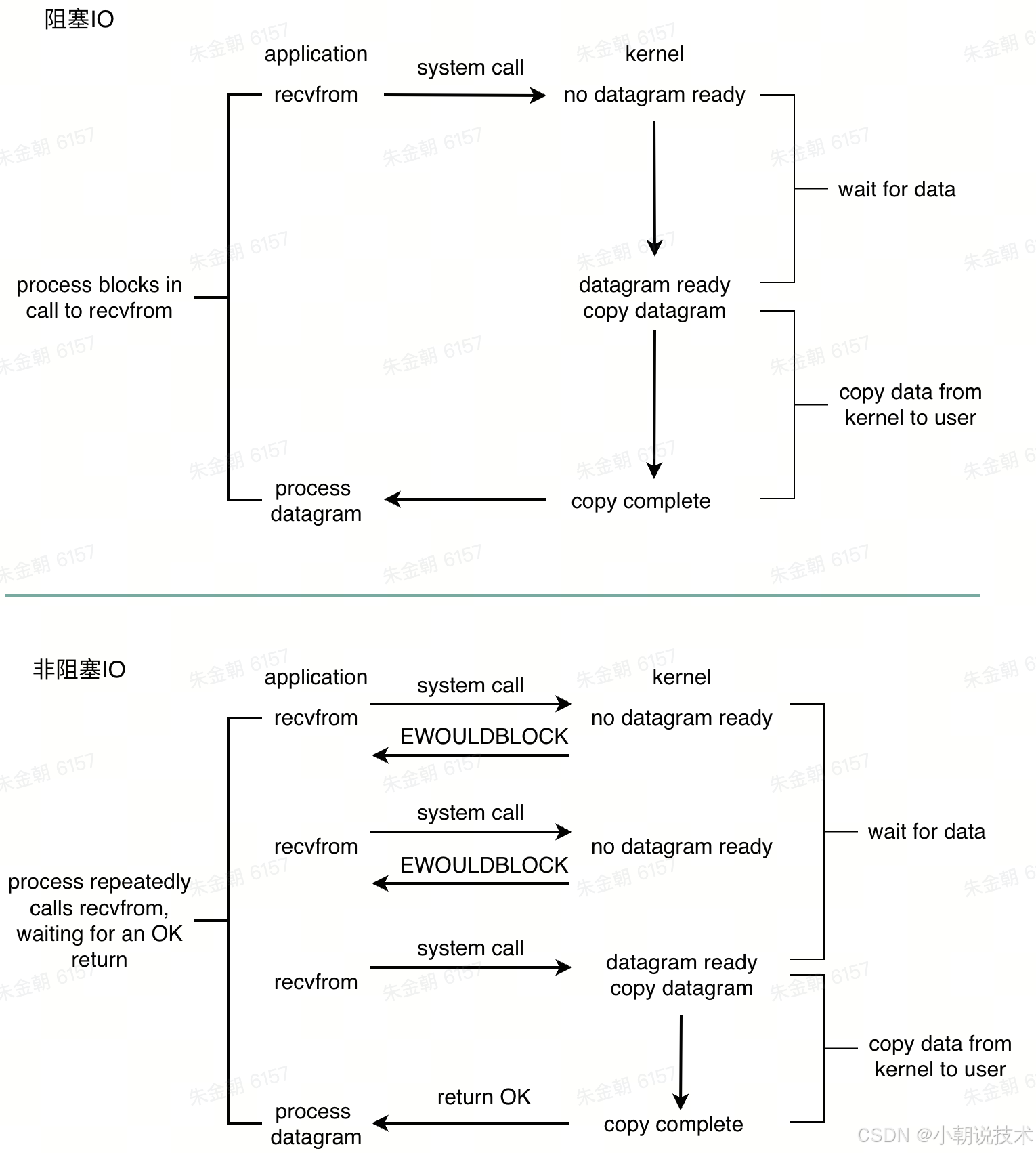
从上面可以看出阻塞 IO 便会使得应用程序在上面两个阶段都会阻塞等待
当用户进程执行 read 操作时,如果内核没有把数据准备好,则并不会阻塞用户程序,而是会立刻返回一个 error,之后引用程序不断轮询内核,一旦内核中的数据准备好并且再次收到用户进程的 system call,则内核会马上把数据拷贝到用户区;所以非阻塞IO的特点就是应用程序会不断主动询问内核数据是否准备好
C-S模型(服务器模型演化)
1.服务端一个进程监听,多个客户端连接;服务端一个进程处理
2.服务端一个进程监听,多个客户端连接;服务端对于每来一个连接开一个进程处理
3.多路IO:不需要应用程序自己监视客户端连接,取而代之由内核代替应用程序监听客户端连接
未使用多路IO之前调用Accpet函数会阻塞等待客户端的连接,但是使用了多路IO之后调用 Accept 就不会再阻塞了,因为无论是 select、poll、还是 epoll 其返回的都是有事件发生的文件描述符集合,之后调用 Accept 与其直接建立连接即可
七、排错
Q : 今天遇到一个问题,在访问公司网站时,发现 ping 能通,但是工作机 curl 不通,但是本机能 curl 通,感到很奇怪,于是总结一下这两个命令的应用场景
ping 命令是用来测试主机之间网络的连通性。利用的是 ICMP 协议,ICMP是网络层协议,由于是网络层不会到达应用层,所以 ping 命令是无法检测系统端口是否开放;用 ping 命令能通只能说明这两个主机之间的网络连接没有问题;(注意只有应用层协议才会用到端口,像 HTTP 协议用的是80端口,SSH 协议用的是22端口);
curl http://[域名/ip] (默认80端口)
所以上面问题原因大概率就是访问的网站服务没有对工作机开放
curl 功能很强大,可以用来测定是否可以访问其他服务器上的服务,是一种命令行工具,作用是发出网络请求,然后获取数据,显示在"标准输出"(stdout)上面
curl 命令可以用来执行下载、发送各种 HTTP 请求,指定 HTTP 头部等操作
# curl -O 下载文件
curl -O http://a.b.c/a.tar 把a.tar下载到本地了
curl -o newName.tar http://a.b.c/a.tar 把a.tar下载下来顺便改名为newName.tar
# 有的网址是自动跳转的。使用 -L 参数,curl 就会跳转到新的网址
curl -L www.sina.com
参数:
-s/--slient 静默模式,不输出任何东西
-S/--show-error 显示错误,在选项-s中,当curl出现错误时将显示
-f/--fail 不输出HTTP错误
-L/--location 重定向
附:telnet 是用来探测指定 ip 是否开放指定端口
telnet [域名或者Ip] [端口号] 空间使用空格分割,不要加 ":"
netstat 命令用来查看端口信息
查看本地监听的端口:netstat -ntlp
netstat [参数]
-n 以数字形式显示地址和端口(这个必须加)
-l 显示监听的socket连接
-p 显示占用端口的进程名
lsof(list open files)查找进程开启或者启动的文件设备
有的时候我们进入容器想要查看监听的端口号,但是没有netstat命令,于是便可以使用 lsof 命令查看进程监听的端口

可以看出起 listen 的是 8090 端口,中间的一列 6,7,8,9,10,11 表示的是任务ID
参看知乎的文章 ,鸟哥私房菜第542页
wget 命令用来下载
wget https://golang.google.cn/dl/go1.17.8.linux-amd64.tar.gz
dig 用于 dns 查询命令
dig baidu.com 查询DNS寻址过程
dig +short baidu.com 直接显示DNS寻址结果
dig @8.8.8.8 baidu.com 向特定DNS服务器寻址
dig ns com 查询com顶级域名的ns记录
dig a com 查询com顶级域名的a记录
dig -x 192.30.252.153 用于查询PTR记录(用IP查域名)
如何修改本地的dns配置,直接修改 /etc/reslov.conf 文件里面的内容即可















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









