







字节流相关用法和操作
在学习输入输出流的时候,我一直很困惑,到底输入输出流到底是个什么东西?我又该怎么去应用它呢?下面是我自己学习时的,看到一些文章和资料的一些整理与感悟,如有不对,请各位大佬指教,嘻嘻嘻~~~。
首先,为什么要用到输入输出流,他们是什么?官方一点的解释就是进行IO操作的时候,Java所有的I/O机制都是基于数据流进行输入输出,这些数据流表示了字符或者字节数据的流动序列,在java中我们使用输入流来向一个字节序列对象中写入,使用输出流来向输出其内容。通俗的讲它的使用场景是:在我们读取某个文件内容,或者将内容写入到某个文件的时候,我们就会用到输入输出流。
对于处理文件的不同,可以分为字节流和字符流,我们先说字节流。java字节流大致分为了五类:
1. 字节流基类:InputStream/OutPutStream
2. 处理文件类型:FileInputStream/FileOutputStream
3. 字节数组类型:ByteArrayInputStream/ByteArrayOutputStream
4. 装饰类:DataInputStream/DataOutputStream
5. 缓冲流:BufferedInputStream/BufferedOutputStream
一、基类流(In/Outputstream)
inputstream和outputstream最基础,下面的类都是继承其。刚开始我就不理解inputstream和outputstream到底哪个是读,哪个是写呢,以什么为参照物呢?实际很简单,以你自己为主人公,毕竟我们写程序的是最大的。然后你要去读某一个文件的时候,你就要使用inputstream,即将数据输入到你这里。而当你想要将内容写入到某个文件的时候,你就要使用outputstream,即从你这里将数据输出。
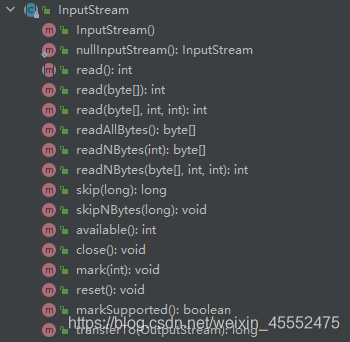
从上图可以看到InputStream的成员方法。抽象方法read()读取下一个字节,当读取到文件的末尾时候返回 -1。除了一次读取一个字节外,其还可以一次读多个字节,
read(byte b[], int off, int len)
- b :读入数据的缓冲区。
- off :在其处写入数据的数组 b 的初始偏移量。
- len :要读取的最大字节数。
其意思就是将读取的第一个字节写入到b[off]中,下一个字节则写入到b[off+1]中,读取的字节最大为len长度,返回的是缓冲区的总字节数,即实际读取到的字节数。如果设 k 为实际读取的字节数;这些字节将存储在元素 b[off] 至 b[off+k-1] 之间,而其余元素 b[off+k] 至 b[off+len-1] 不受影响。如果流中没有数据read就会阻塞直至数据到来或者异常出现或者流关闭。
skip()————表示跳过指定的字节数,来读取。调用时,一旦跳过就不能返回到原来的位置
mark()————方法在指定的位置打上标记
reset()————方法可以重新回到之前的标记索引处
他们可以一起合作实现可重复读的操作。一定是在打下mark()标记的地方,使用字节数组记录下接下来的路径上的所有字节数据,直到你使用了reset(),取出字节数组中的数据供你读取(实际上也不是一种能够重复读,只是用字节数组记录下这一路上的数据而已,等到你想要回去的时候将字节数组给你重新读取)。
Outputstream具体的方法和Inputstream差不多,一个是读一个是写,这里就不说了。但是,他们都是抽象类,想要实现具体的功能还是需要依赖他们的子类来实现。
二、文件字节流(FileIn/OutputStream)
FileInputStream/FileOutputStream就是上面所说的InputStream/OutputStream的子类。
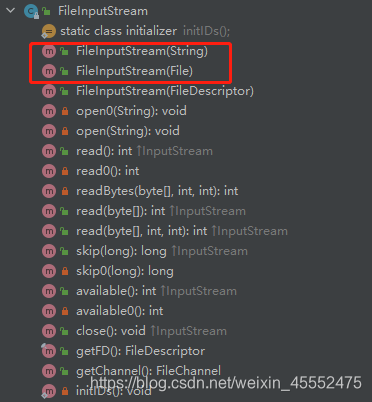
由上图画红圈的,一个传参是String,一个传参是File,其实都是想表达的同一个意思。只是第一种构造方法传的是一个确定文件的路径,内部将此路径封装成File类型。而第二种构造方法,直接绑定的是一个具体的文件。其内部方法和父类是差不多的。
1、FileInputStream 就是读某个文件的内容。
接下来我们用代码来实践一下,首先在我的D盘根目录下,创建一个hello.txt文件,里面写上hello i am lane保存下来。下面我们读取hello.txt的内容。
2、具体操作
public class InputAndOutputStream {
public static void main(String[] args) {
try {
FileInputStream fileInputStream = new FileInputStream("D://hello.txt");
//这里指令字节数组的大小,但是这么写是有隐患的下面会提到
byte[] buffer = new byte[1024];
//返回读取的字节数
int x = fileInputStream.read(buffer, 0, buffer.length);
String s = new String(buffer);
fileInputStream.close();
System.out.println(x);
System.out.println(s);
System.out.println(buffer.length);
} catch (IOException e) {
e.printStackTrace();
}
}
}
输出结果为:
15
hello i am lane
1024
读出的内容和我们想象的是一样的,而在hello i am lane的后面有很多的空格,这是因为byte数组初始化的时候,数组的大小大于文件字节长度的大小,所以后面会有许多空格。返回的字节数为15,就是5个字母+1个空格+1个字母+1个空格+2个字母+1个空格+4个字母为5+1+1+1+2+1+4=15个字节。
3、我们再看看FileOutputStream,他的使用和FileInputStream差不多,方法如下:
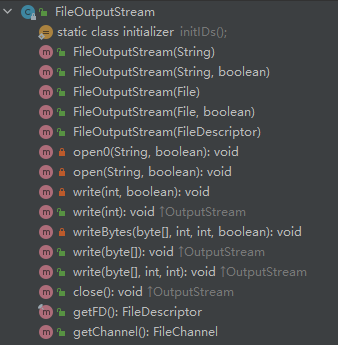
其作用就是将你已经有的内容写入到一个文件中。下面我们将复制hello.txt的内容到copyhello.txt中。
public class InputAndOutputStream {
public static void main(String[] args) {
try {
FileOutputStream outputStream = new FileOutputStream("D://copyhello.txt");
String ss = s;
byte[] write = ss.getBytes("UTF-8");
outputStream.write(write, 0, write.length);
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
这个时候你去D盘根目录下,你会神奇的发现,多了一个copyhello.txt文件,且打开后发现里面的内容就是之前hello.txt中的。
三、动态字节流数组(ByteArrayIn/OutputStream)
在上面我们初始化字节数组的时候是固定了他的大小,但是这么写byte[] buffer = new byte[1024];一般是不太好的,存在隐患。试想一下,如果我们要读取的内容的字节数超过了1024怎么办?当然可以定义一个无限大的数组,但是这样内存的利用率就会极低,根本就不可取。所以我们可以用动态字节流数组ByteArrayInputStream来解决这个问题。ByteArrayInputStream的内部使用了类似于ArrayList的动态数组扩容的思想。
ByteArrayInputStream他的方法如下:
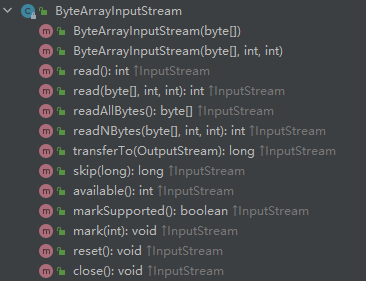
ByteArrayInputStream内部定义了一个buf数组和记录数组中实际的字节数,read()也很简单,读取下一个字节,read(byte b[], int off, int len) 将内置字节数组读入目标数组。实际上,整个ByteArrayInputStream也就是将一个字节数组封装在其内部。为什么这么做?主要还是为了方便参与整个InputStream的体系,复用代码。
而ByteArrayOutputStream如下:
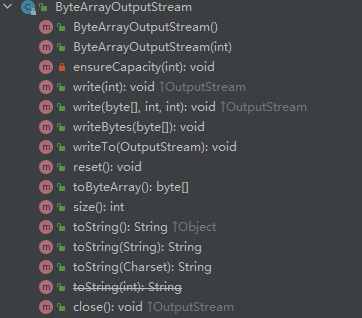
和ByteArrayInputStream一样,内部依然封装了字节数组buf和实际容量count,通过构造方法可以指定内置字节数组的长度。主要的是write(),将外部传入的字节数组写到内置数组中,writeTo()可以理解为将自己内置的数组交给OutputStream 的其他子类使用。toByteArray和toString则会将内置数组转换成指定类型返回。
那我们就看一下他的具体用法是什么样子的吧,我们还是以之前D盘创建的hello.txt文件为例
public class InputAndOutputStream {
public static void main(String[] args) {
try {
FileInputStream fileInputStream = new FileInputStream("D://hello.txt");
ByteArrayOutputStream baryOutput =new ByteArrayOutputStream();
int x =0;
while((x = fileInputStream.read()) !=-1){
baryOutput.write(x);
}
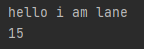
System.out.println(baryOutput.toString());
System.out.println(baryOutput.size());
} catch (IOException e) {
e.printStackTrace();
}
}
}
输出结果如下,我们这里可以看到他的长度只有15,正好是文本的长度,很好的利用了内存。不像上面使用byte数组的时候,定义的数组大小为1024,实际只用到了15。动态扩容的方法极大的提高的内存的利用率。
四、缓冲流(DataIn/OutputStream)
1、上面所说到的流都是直接通过操作字节数组来实现输入输出的,那如果我们想要输入一个字符串类型或者int型或者double类型,那还需要调用各自的转字节数组的方法,然后将字节数组输入到流中。我们可以使用装饰流,帮我们完成转换的操作。
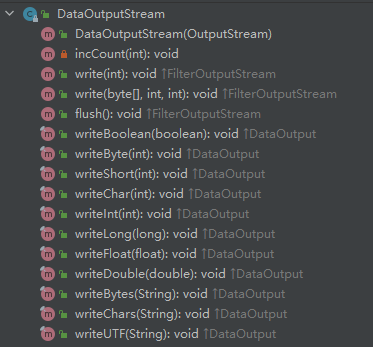
2、我们先看DataOutputStream,其方法如下:DataOutputStream只有一个构造方法,必须传入一个OutputStream类型参数。(其实它的内部还是围绕着OutputStream,只是在它的基础上做了些封装)。我们看到,有writeBoolean、writeByte、writeShort、writeDouble等方法。他们内部都是将传入的 boolean,Byte,short,double类型变量转换为了字节数组,然后调用从构造方法中接入的OutputStream参数的write方法。
DataOutputStream方法如下:
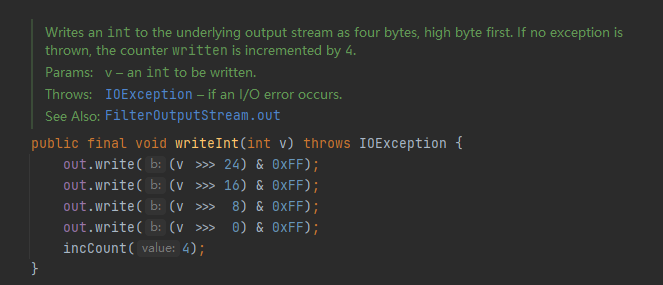
我们拿其中一个方法来具体的看看writeInt(int v),它将一个四个字节的int类型,分开写入,先写入高八位。总共写四次,第一次将高八位移动到低八位与上0xFF获得整个int的低八位,这样就完成了将原高八位写入的操作,后续操作类似。
DataIntputStream方法如下:
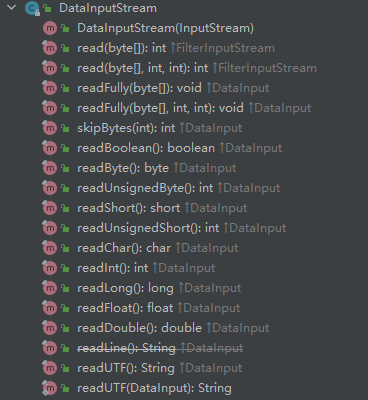
3、具体用法和上面的也差不多,当执行完下面代码后,你就会发现你的D盘根目录下又出现了一个hello11.txt文件了,然后打开这个文件你会发现,嗯?怎么和我预期的不一样,他竟然乱码了,但是使用DataInputStream读的时候它又能正常的读出来,这是不是很奇怪啊?这与编码是有关系的,这个问题有兴趣的可以自己去搜搜看,这里我就不具体说了。
public class InputAndOutputStream {
public static void main(String[] args) {
try {
DataOutputStream dataOutputStream = new DataOutputStream(new FileOutputStream("D://hello11.txt"));
dataOutputStream.writeInt(123456);
dataOutputStream.close();
FileInputStream fin = new FileInputStream("D://hello11.txt");
DataInputStream dis = new DataInputStream(fin);
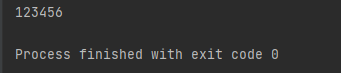
System.out.println(dis.readInt());
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果如下:
五、缓冲流(BufferedIn/OutputStream)
在这之前,我们读取一个字节就要将它写会磁盘,这样来回开销很大,我们可以使用缓冲区来提高效率,在缓冲区满的时候,或者流关闭时候,将缓冲区中所有的内容全部写会磁盘。BufferedInputStream和BufferedOutputStream也是一对装饰流,我们先看看BufferedInputStream:
BufferedInputStream方法如下:
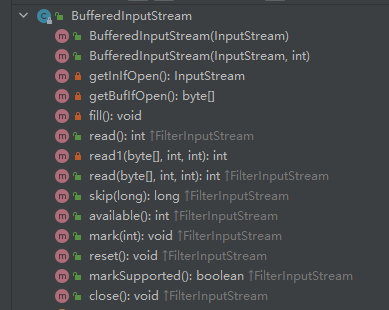
一样也是装饰类流,第一种构造方法要求必须传入InputStream类型参数,DEFAULT_BUFFER_SIZE 指定了默认的缓冲区的大小,当然还可以使用第二种构造方法指定缓冲区的大小(当然不能超过上界),read方法读取的时候会将数据读入内部的缓冲区中,当然缓冲区也是可以动态扩容的。
具体用法其实和上面的都是大同小异
public class InputAndOutputStream {
public static void main(String[] args) {
try {
BufferedInputStream bi = new BufferedInputStream(new FileInputStream("D://hello.txt"));
bi.read();
System.out.println(bi.available());
} catch (IOException e) {
e.printStackTrace();
}
}
}
BufferedOutputStream和它是逆操作。传参的时候传入一个OutputStream就可以了其方法如下:
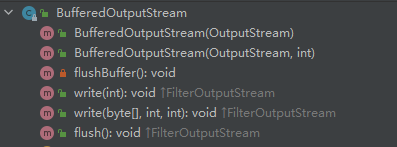
这种缓冲字节流可以很大程度上提高我们的程序执行的效率,所以一般在使用别的流的时候都会包装上这层缓冲流。
———————Ending啦,最后有什么问题,麻烦大家可以指出来,一起进步哦!———————


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









