







爬虫简单介绍
用户和网站服务器的操作如下
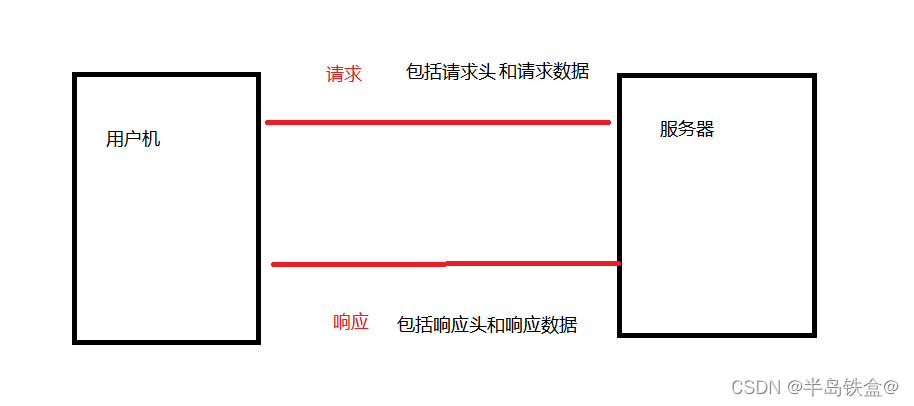 而爬虫需要做的是模拟仿照用户机,去向服务器发送请求数据,并接受响应数据,接着去解析数据,获得我们想要的数据
而爬虫需要做的是模拟仿照用户机,去向服务器发送请求数据,并接受响应数据,接着去解析数据,获得我们想要的数据
步骤大致分为
准备好要爬取的网址
定义爬虫的参数
开始爬
获取爬取的数据
使用xpath技术去解析数据
获取我们想要的数据
准备
新建一个maven项目,并配置pom.xml
爬虫jar包工具,jsoup
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
IO流传输下载jar包 commons-io
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
爬取网站图片练习
爬取当前页面的图片
https://dou.yuanmazg.com/doutu?page=1

主要操作步骤和代码
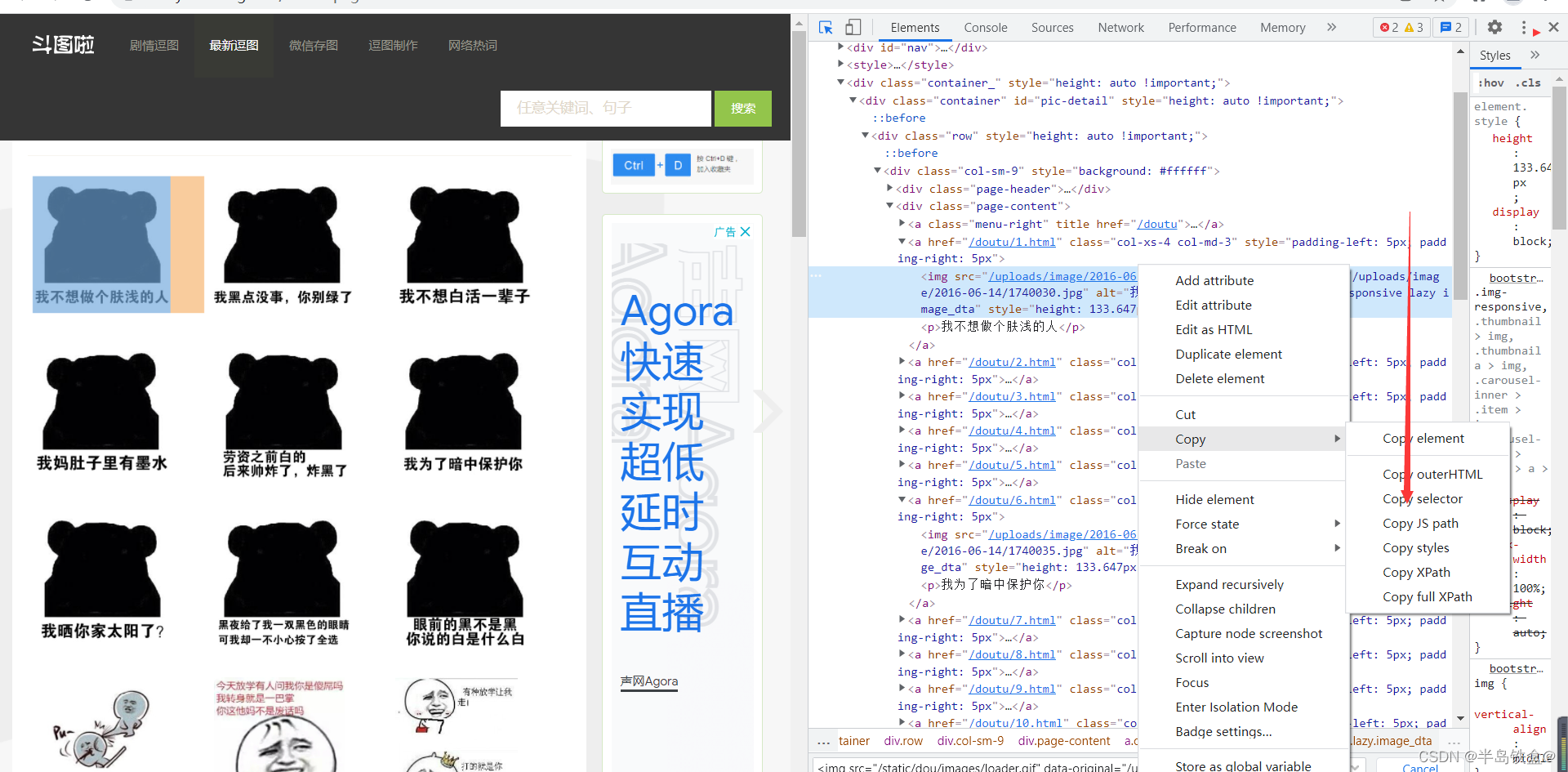
选定一张图片复制它的selector
#pic-detail > div > div.col-sm-9 > div.page-content > a:nth-child(2) > img
a:nth-child(2)
a 后面的字符代表该图片是该页面下面的第几张图片
那么把 后面的字符去掉,就可以代表全部的图片了
Elements select =dom.select("#pic-detail > div > div.col-sm-9 > div.page-content > a > img");
定义爬虫的参数
Connection.Response response = Jsoup
.connect("https://dou.yuanmazg.com/doutu?page=1")
.header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0")
.ignoreContentType(true)
.timeout(10000)
.execute();
.header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0")
这一句意思是
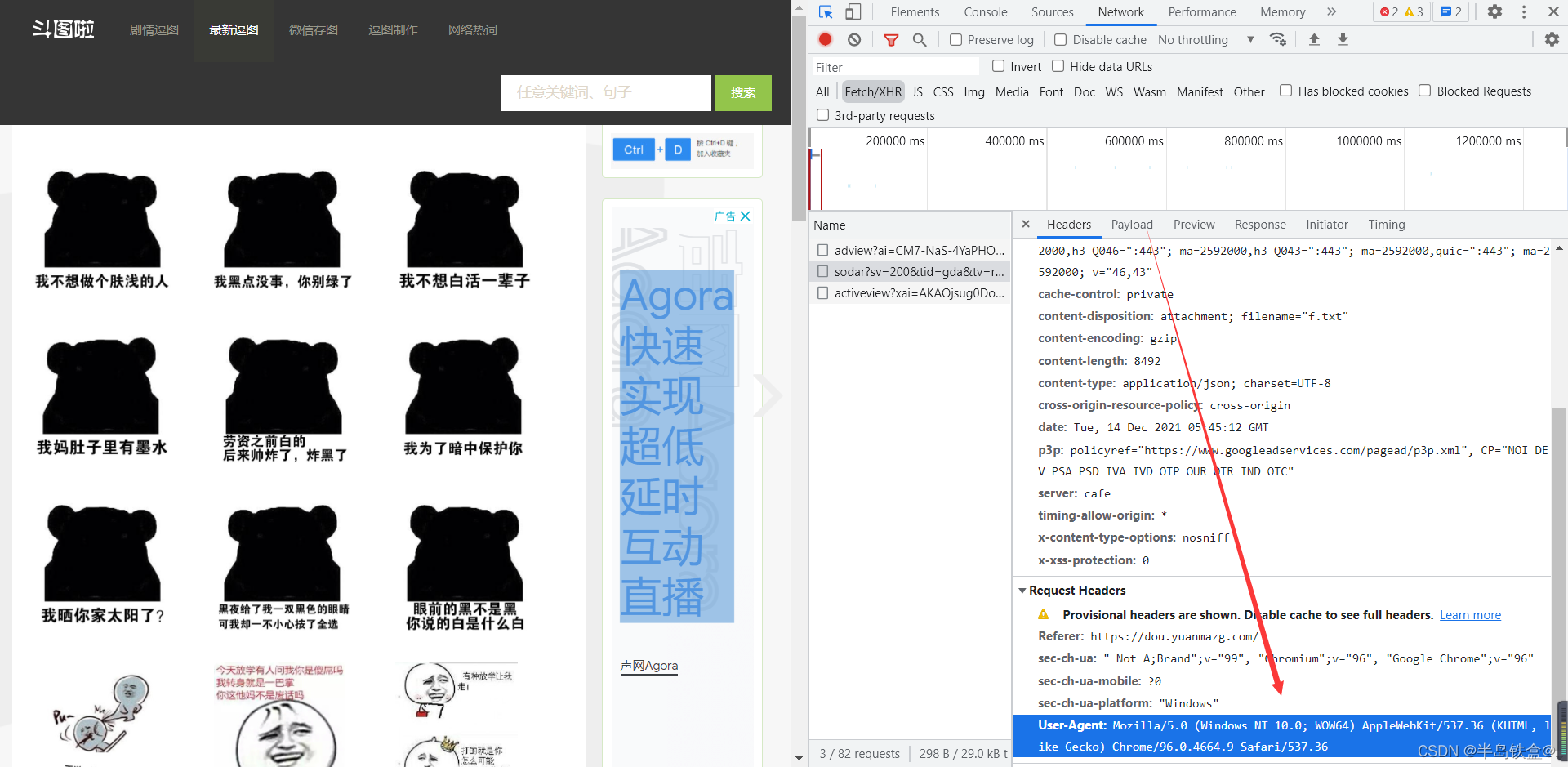
告诉目标服务器我们是以用户浏览器去访问的
execute()相当于一个回车键;
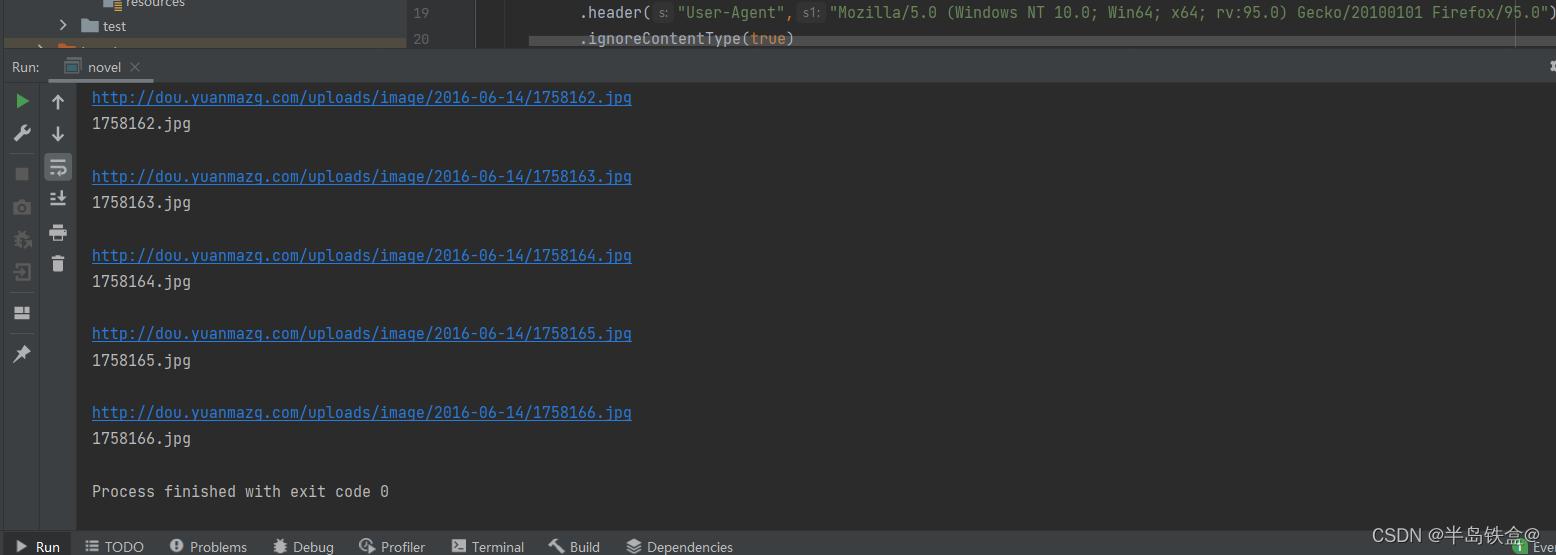
输出文件到目标文件夹下
byte[] bytes = imgResponse.bodyAsBytes();
IOUtils.write(bytes,new FileOutputStream(new File("d://斗图啦//"+filename)));
String img_url = element.attr(“data-original”);
提取"data-original"里面的数据
完整代码
package com.zygxy.parse;
import org.apache.commons.io.IOUtils;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class Jsoup_Study {
public static void main(String[] args) throws IOException {
//Jsoup 模拟浏览器发起请求
String website="http://dou.yuanmazg.com";
Connection.Response response = Jsoup
.connect("https://dou.yuanmazg.com/doutu?page=1")
.header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36")
.ignoreContentType(true)
.timeout(10000)
.execute();
//
System.out.println(response.header("Content-Type")); //响应头
System.out.println(response.body()); //响应体
String html=response.body();
//Jsoup 解析HTML
Document dom = Jsoup.parse(html);
//选择器
//获取多个
//#pic-detail > div > div.col-sm-9 > div.page-content > a:nth-child(2) > img
Elements select = dom.select("#pic-detail > div > div.col-sm-9 > div.page-content > a > img");
//获取单个
for (Element element:select)
{
String img_url=element.attr("data-original");
String realurl=website+img_url;
int i = img_url.lastIndexOf("/");
String filename=img_url.substring(i+1);
System.out.println(filename);
System.out.println(realurl);
Connection.Response imgResponse = Jsoup.connect(realurl)
.ignoreContentType(true)
.timeout(10000)
.maxBodySize(10 * 1024 * 1024) //10M的缓冲区
.execute();
//因为图片是二进制 音频 视频 图片 都用
byte[] bytes = imgResponse.bodyAsBytes();
IOUtils.write(bytes,new FileOutputStream(new File("d://斗图啦//"+filename)));
}
}
}
















 6081
6081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











