







文件输入/输出
相关函数
fopen()函数
该函数声明在<stdio.h>中,他的第一个参数是待打开文件的名称,更准确的说是一个包含该文件的字符串地址;第2个参数是一个字符串,指定待打开文件的模式
| 模式字符串 | 含义 |
|---|---|
| r | 以读模式打开文件 |
| w | 以写模式打开文件,把现有文件的长度截为0[丢失该内容],如果文件不存在,则创建一个新文件 |
| a | 以写模式打开文件,在现有文件内容末尾添加内容,如果文件不存在,则创建第一个新文件 |
| r+ | 以更新模式打开文件(即可以读写文件) |
| w+ | 以更新模式打开文件,如果文件存在,则将文件的长度截为0;如果不存在,则创建一个新文件 |
| a+ | 以更新模式打开文件,在现有文件末尾添加内容,如果文件不存在则创建一个新文件;可以读取整个文件,但是只能从末尾添加内容 |
| rb wb ab r+b w+b rb+ wb+… | 与上述类似,但是是以二进制打开 |
像UNIX和Linux这样只有一种文件类型的系统,带b字母和不带b字母的模式相同
新的C11新增了带x字母的写模式,与以前的写模式相比具有更多特性。第一:如果以传统的一种写模式打开一个现有文件,fopen()会把该文件的长度截为0,这样就丢失了该文件的内容。但是使用带x字母的写模式,即使fopen()操作失败,原文件的内容也不会被删除。第二:如果环境允许,x模式的独占特性使得其它程序或线程无法访问正在被打开的文件
程序成功打开文件后,fopen()将返回文件指针,其它I/O函数可以使用这个指针指定该文件。文件指针是指向FILE的指针,FILE是一个定义stdio.h中的派生类型。文件指针fp并不指向实际的文件,它指向一个包含文件信息的数据对象,其中包含操作文件的的I/O函数所用的缓冲区信息
getc()和putc()函数
getc()和putc()函数与getchar()和putchar()函数类似
FILE *fp; // 文件指针
ch=getchar(); // 从标准输入中获取一个字符
ch=getc(fp); // 从fp指定的文件中获取一个字符
putc(ch,fp); // 把字符ch放入FILE指针fp指定的文件中
fclose()函数
fclose(fp)函数关闭fp指定的文件,必要时刷新缓冲区;对于比较正式的程序,应该检查是否成功关闭文件,如果成功关闭,fclose()函数返回0,否则返回EOF
if(fclose(fp)!=0)
printf("Erroe in closing file");
/* 如果磁盘已满、移动硬盘被移除或出现I/O错误,都会导致调用fclose()函数失败 */
fprintf()和fscanf()函数
文件I/O函数fprintf()和fscanf()函数的工作方式和printf()、scanf()类似;区别在于前者需要使用第1个参数指定待处理的文件[指向标准文件的指针]
FILE *fp;
int a;
fprintf(fp,"%s","aaa"); //输出aaa [成功写入返回写入字符个数,失败返回负数]
fscanf(fp,"%d",&n); //接受输入 [返回成功赋值个数]
fprintf(stdout,"aaa"); // 函数将会向显示器输出内容
fscanf(stdin,"%d",&a); // 函数将会从键盘读取数据
rewind()函数
FILE *fp;
rewind(fp); // 返回到文件文件开始处
fgets()和fputs()函数
fgets()函数读取输入直到第1个换行符的后面;或读到文件结尾;或读到STLEN-1个字符。然后在fgets()末尾添加一个空字符使之成为一个字符串【保留读取到的换行符】。fgets()函数在遇到EOF时将返回NULL值,可以利用这一机制检查是否到达文件结尾;如果未遇到EOF则返回之前传给它的第一个参数地址
fgets(buf,STLEN,fp);
/*
buf:char类型数组的名称
STLEN:字符串的大小
fp:是指向FILE的指针
*/
fputs(buf,fp);
/*
buf:字符串的地址
fp:用于指定目标文件
*/
由于fgets()函数保留了换行符,fputs()就不会再添加
随机访问:fseek()和ftell()
有了fseek()函数,便可把文件看作是数组,在fopen()打开的文件直接移动到任意字节处
fseek(fp,offset,ms);
/*
fp:FILE指针,指向待查找的文件
offset:偏移量
ms:文件的起始点模式
*/
| 模式 | 偏移量的起始点 |
|---|---|
| SEEK_SET | 文件开始处 |
| SEEK_CUR | 当前位置 |
| SEEK_END | 文件末尾 |
// 示例【旧的实现可能缺少这些定义,可以使用数值0L、1L、2L分别表示这3种模式 L的后缀表明其值是long类型】
fseek(fp,0L,SEEK_SET); // 定位至文件开始处
fseek(fp,10L,SEEK_SET); // 定位至文件中的第10个字节处
fseek(fp,2L,SEEL_CUR); // 从文件当前位置前移2个字节
fseek(fp,0L,SEEK_END); // 定位至文件结尾处
fseek(fp,-10L,SEEK_END); // 从文件结尾处回退10个字节
如果一切正常,fseek()的返回值为0;如果出现错误(如试图移动的距离超出文件的范围),其返回值为-1
ftell()函数的返回类型是long,它返回的是参数指向文件的当前位置距文件开始处的字节数
fgetpos()和fsetpos()函数
fseek()和ftell()潜在问题是,它们都把文件大小限制在long类型能表示的范围内。ANSI C新增了两个处理较大文件的新定位函数:fgetpos()和fsetpos();这两个函数不使用long类型的值表示位置,它们使用一种新类型:fpos_t(文件定位类型)。fpos_t类型不是基本类型,它根据其他类型来定义,fpos_t类型的变量或数据对象可以在文件中指定一个位置,它不能是数组类型
// 成功返回0 失败返回非0
fgetpos(fp,pos); // fp:指向文件的指针 pos:文件的当前位置距文件开头的字节数【fpos_t类型】
fsetpos(fp,pos); // fp:指向文件的指针 pos:设置文件指针指向偏移该值后指定的位置【fpos_t类型】
ungetc()函数
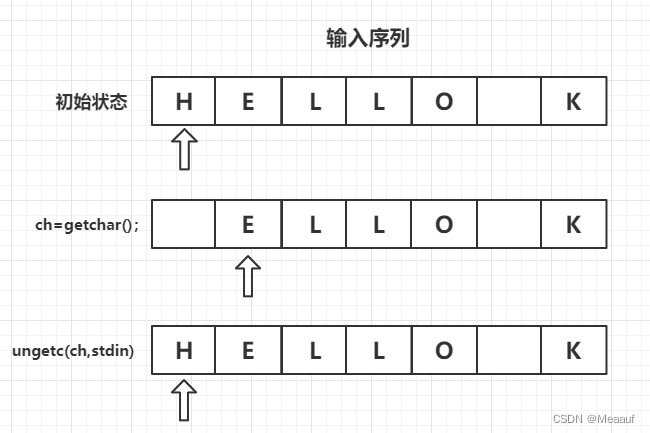
int ungetc()函数把c指定的字符返回输入流中,如果把一个字符放回输入流,下次调用标准输入函数时将读取该字符。例如:假设要读取下一个冒号之前的所有字符,但是不包括冒号本身,可以使用getchar()和getc()函数读取字符到冒号,然后使用ungetc()函数把冒号放回输入流中。ANSI C标准保证每次只会放回一个字符,如果实现允许把一行中的多个字符放回输入流,那么下一次输函数读入的字符顺序与返回顺序相反
int ungetc(int c,FILE *fp);
fflush()函数
int fflush(FILE *fp);
调用fflush()函数引起输出缓冲区中所有的未写入数据被发送到fp指定的输出文件,这个过程称为刷新缓冲区。如果fp是空指针,所有输出缓冲区都被刷新。在输入流中使用fflush()函数的效果是未定义的,只要最近一次操作不是输入操作,就可以用该函数来更新流(任何读写模式)
setvbuf()函数
setvbuf()函数创建了一个供标准I/O函数替换使用的存储区;在打开文件后且未对流进行其他操作之前,调用该函数。
int setvbuf(fp,buf,type,size);
/*
fp:文件流指针
buf:缓冲区首地址【非NULL 则必须创建一个缓冲区】
type:缓冲区类型
size:缓冲区内字节的数量
*/
参数类型
- _IOFBF(满缓冲):当缓冲区为空时,从流中读入数据;或当缓冲区满时,向流写入数据
- _IOLBF(行缓冲):每次从流中读入一行数据或先流中写入一行数据
- _IONBF(无缓冲):直接从流中读入数据或直接向流中写入数据,而没有缓冲区
【返回值】:成功返回0,失败返回非0
feof()和ferror()函数
如果标准输入函数返回EOF,则通常表明函数已到达文件结尾。然而,出现读取错误时,函数也会返回EOF。feof()和ferror()函数用于区分两种情况。
当上一次输入调用检测到文件结尾时,feof()函数返回一个非0值,否则返回0;
当读或写出现错误,ferror()函数返回一个非零值,否则返回0
指向标准文件的指针
<stdio.h>头文件爸3个文件指针和3个标准文件相关联,C程序会自动打开这3个标准文件
| 标准文件 | 文件指针 | 通常使用设备 |
|---|---|---|
| 标准输入 | stdin | 键盘 |
| 标准输出 | stdout | 显示器 |
| 标准错误 | stderr | 显示器 |
这些文件指针都是指向FILE的指针,所以它们可用作标准I/O函数的参数,如fclose(fp)中的fp
二进制模式和文本模式
UNIX只有一种文件格式,所以不需要进行特殊的转换。许多MS-DOS编辑器都是使用Ctrl+Z标记文本文件的结尾。以文本模式打开这样的文件时,C能识别作为文件结尾标记的字符。但是,以二进制模式打开相同的文件时,Ctrl+Z被看作是文件中的一个字符,而实际的文件结尾符在该字符后面。文件结尾符可能紧跟在Ctrl+Z字符后面,或在文件中可能用空字符填充
二进制I/O :fread()和fwrite()
为保证数值在存储前后一致,最精确的做法是使用与计算机相同的位组合来存储;因此,double类型的的值应该存储在一个double大小的单元中。如果以程序所用的表示法把数据存储在文件中,则称为以二进制形式存储数据。不存在从数值到字符串的转换过程,对于标准I/O,fread()和fwrite()函数用于以二进制形式处理数据
实际上,所有的数据都是以二进制形式存储的,甚至连字符都以字符码的二进制表示来存储。如果文件中的所有数据都被解释成字符码,则称该文件包含文本数据;如果部分或所有数据被解释成二进制形式的数值数据,则称该文件包含二进制数据(另外,用数据表示机器语言指令的文件都是二进制文件)
size_t fwrite()函数
//fwrite()函数把二进制数据写入文件,size_t是根据标准C类型定义的类型,它是sizeof运算符返回的类型 通常是unsigned int
size_t fwrite(ptr,size,nmemb,stream);
/*
ptr:写入数据地址
size、nmemb::总写入数字符数有size*nmemb决定
stream:文件指针
*/
// 示例:保存一个大小为256字节的数据对象(如数组)
char buffer[256];
fwrite(buffer,256,1,fp);
【返回值】:返回实际写入的nmemb数目 失败返回值会小于nmemb
size_t fread()函数
size_t fread(buffer, size, count, stream);
/*fread()函数:从文件流中读取数据
buffer:接受数据的地址
size:一个单元的大小
count:单元个数
stream:文件流
*/
// 示例:读取文件中10个double大小的值
double arr[10];
fread(arr,sizeof(double),10,fp);
fread()函数每次从stream中最多读取count个单元,每个单元大小为size个字节,将读取的数据放到buffer;文件流的位置指针后移size*count字节
【返回值】:返回实际读取的单元个数,小于count,则文件可能结束或读取出错
案例分析(二进制I/O读写)
通过命令行获取原始文件名和拷贝文件名,实现文件拷贝功能
#include <stdio.h>
#include <stdlib.h>
#define BUF 256
void file_copy(FILE* fs,FILE* ft);
int main(int argc,char** argv)
{
FILE* source; // 定义源文件指针
FILE* target; // 定义拷贝文件指针
if(argc!=3)
{
printf("Parameter error.");
exit(EXIT_FAILURE); // 表示没有成功运行程序 返回1
}
if((source=fopen(argv[1],"rb"))==NULL) // 判断源文件是否读取成功
printf("Can't open %s.\n",argv[1]);
if((target=fopen(argv[2],"wb"))==NULL)
printf("Can't open %s.\n",argv[2]); // 判断拷贝文件是否读取成功
file_copy(source,target);
printf("Success copy.");
return 0;
}
void file_copy(FILE* fs,FILE* ft) // 文件拷贝函数
{
size_t bt; // 存储 fread()返回值
static char str[BUF]; // 定义存储数组
while((bt=fread(str,sizeof(char),BUF,fs))>0)
fwrite(str,sizeof(char),bt,ft);
}
编译程序


运行编译文件

查看结果

















 1544
1544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











