







JVM高频知识点合集【2】
1 JVM内存模型
1.1 运行时数据区
在JVM高频知识合集(面试)【1】里面已经对运行时数据区有详细的介绍,其实运行时数据区中点存储的数据是堆和方法区(非堆)。因此,此处JVM内存模型主要围绕着这两块区域讲解。
堆、方法区:线程共享
虚拟机栈、程序计数器、本地方法栈:线程私有
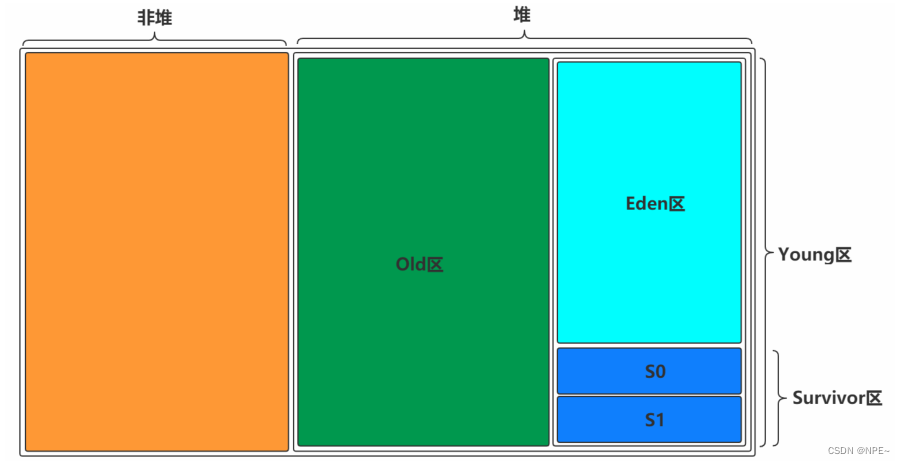
JVM内存模型主要包含两个重要部分:
一块是堆区、一块是非堆区
堆区:Old区、Young区
Young区主要分为:Survivor区(S0+S1)、Eden区
S0和S1一样大,也叫做From 和 To
1.2 对象的创建过程
一般情况下,新创建的对象都会被分配到Eden区,一些特殊的大对象会直接被分配到Old区
我是一个普通的Java对象,我出生在Eden区,在Eden区我还看到和我长的很像的小兄弟,我们在Eden
区中玩了挺长时间。有一天Eden区中的人实在是太多了,我就被迫去了Survivor区的“From”区,自
从去了Survivor区,我就开始漂了,有时候在Survivor的“From”区,有时候在Survivor的“To”区,
居无定所。直到我18岁的时候,爸爸说我成人了,该去社会上闯闯了。于是我就去了年老代那边,
年老代里,人很多,并且年龄都挺大的。
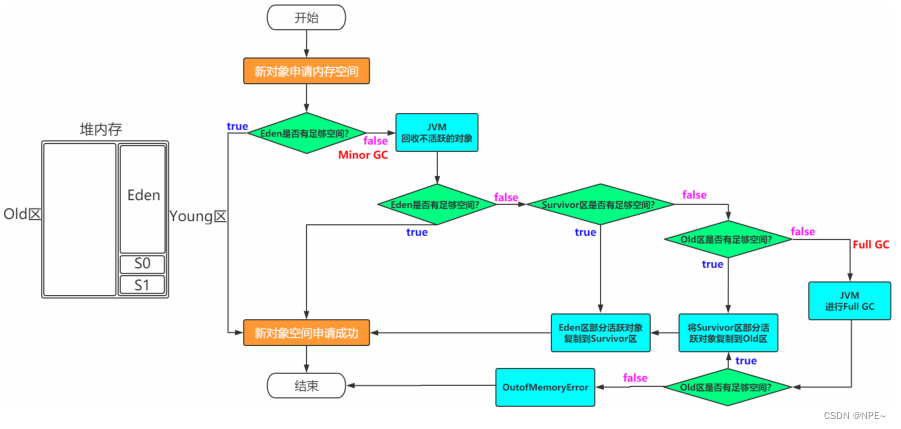
Eden(MinorGC) -> Survivor(复制Eden活跃对象) -> Old区(复制Survivor活跃对象)
FullGC -> OOM
1.3 常见知识点及问题
- 如何理解Minor、Major、Full GC
Minor GC:新生代
Major GC:老年代
Full GC:新生代+老年代
- 为什么需要Survivor区?只有Eden不行吗?
如果没有Survivor,Eden区没进行一次Minor GC,存活对象就会被送到老年代。这样一来,老年
代很快会被会被填满,触发Major GC(因为Major GC一般伴随着Minor GC,因此可以看做触发
了Full GC)
老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC长很多,会极其影响
程序的执行和响应速度。
那么,会有人说,为什么不对老年代的空间进行增加或减少呢?
1.如果增加老年代空间,则需要更多的存活对象才能填满老年代。虽然降低了Full GC频率,但是
伴随着老年代的空间加大,一旦发生Full GC,执行所需要的时间也就更长。
2.如果减少老年代空间,虽然Full GC所需要的时间减少,但是老年代会很快被存活对象填满,
Full GC频率增加
综上:Survivor存在的意义:减少被送到老年代的对象,进而减少Full GC的发生,Survivor的
预筛选保证,只有经历16次Minor GC还能在新生代中存活的对象,才会被送到老年代(对象年龄
存储在Mark Word中,每经历一次Minor GC,age++)
- 为什么需要两个Survivor区?
解决了碎片化。
假设只有一个Survivor区:
刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中存活的对象就会移动到
Survivor区。这样继续循环下去,下一次Eden区满了的时候,问题来了,此时进行Minor GC,
Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显
这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。
如果有两个Survivor区:永远有一个Survivor space是空的,另一个非空的Survivor space
无碎片。
- 新生代中Eden:S1:S2为什么是8:1:1?
新生代的可用内存:复制算法用来担保的内存为9:1
可用内存中Eden:S1区为8:1
即新生代中Eden:S1:S2 = 8:1:1
现代的商业虚拟机都是采用这种收集算法来回收新生代,IBM公司的专门研究表明,新生代中对象
大概98%都是"朝生夕死"的。
- 堆内存中都是线程共享的区域吗?
JVM默认为每个线程在Eden区上开辟一个buffer区域,用来加速对象的分配,称为TLAB,全
称:Thread Local Allocation Buffer。
对象优先在TLAB上分配,但是TLAB空间会比较小,如果对象较大,那么还是在共享区域上分配。
2 垃圾回收(Garbage Collect)
之前有提到过堆内存中有垃圾回收,比如Young区的Minor GC, Old 区的Major GC,Young区和Old区的Full GC。
但是,对于一个对象而言,我们如何确定它是垃圾呢?是否需要被回收?怎样对它进行回收呢?
2.1 如何确定一个对象是垃圾?
首先,我们要想进行垃圾回收,就得先知道什么样的对象是垃圾。
- 引用计数法
对于某个对象而言,只要应用程序中持有该对象的引用,就说明该对象不是垃圾,如果一个对象没
有任何指针对其引用,那么它就是垃圾。
弊端:A、B相互持有引用(成环)
- 可达性分析
通过GC Root对象,开始向下寻找,看某个对象是否可达
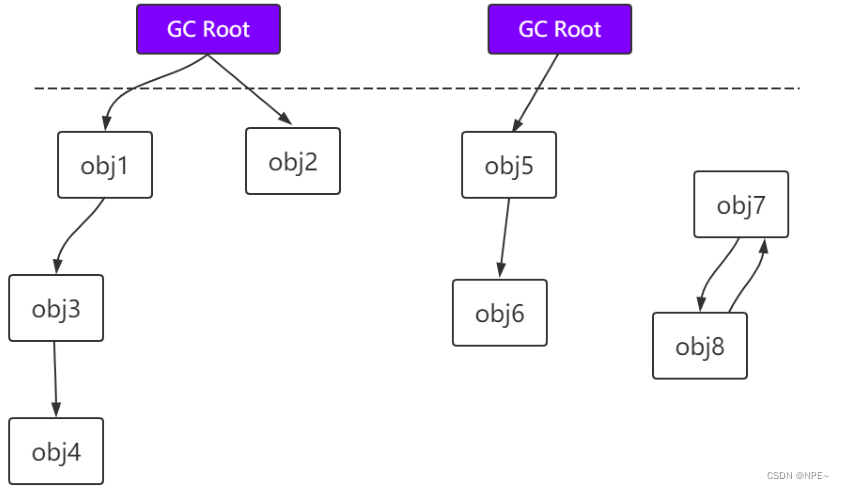
能够作为GC Root:类加载器、Thread、虚拟机栈的本地变量表、static成员、常量引用、本地方法栈
虚拟机栈(栈帧中的本地变量表)中引用的对象
方法区中类静态属性引用的对象
方法区中常量引用的对象
本地方法栈中JNI(native方法)引用的对象
2.2 什么时候会垃圾回收?
GC是由JVM自动完成的,根据JVM系统环境而定,时机是不确定的。
当然,我们也可以手动进行垃圾回收,比如调用System.gc通知JVM进行一次垃圾回收,但是具体什么时刻运行也无法控制。也就是说System.gc()只是通知要回收,什么时候回收由JVM决定。但是不建议手动调用该方法,因为GC消耗资源比较大。
(1)Eden或S区不够用了
(2)老年代空间不够用了
(3)方法区空间不够用了
(4)System.gc()
2.3 垃圾回收算法
2.3.1 标记-清除(Mark-Sweep)
- 标记
找出内存中需要回收的对象,并把它们标记出来
此时堆中所有的对象都会被扫描一遍,从而才能确定需要回收对的对象,比较耗时
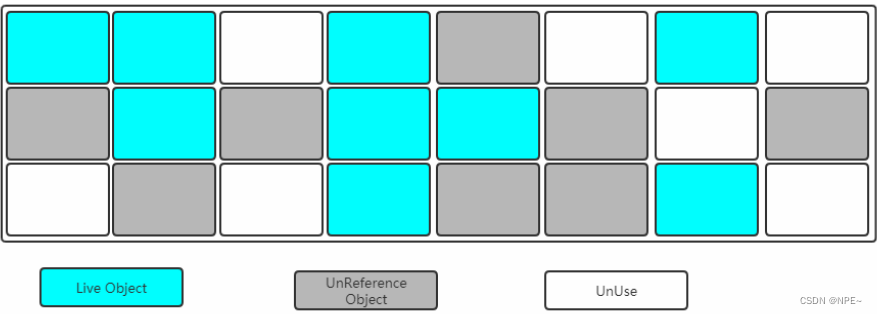
- 清除
清除掉被标记需要回收的对象,释放出对应的空间
缺点:
标记清除之后会产生大量不连续的内存碎片,导致需要分配大对象时候,无足够连续内存而GC
(1)标记和清除过程都比较耗时,效率不高
(2)内存碎片过多,无连续内存,分配大对象困难
2.3.2 标记-复制(Mark-Copying)
将内存划分为两块相等的区域,每次只使用其中的一块

当其中一块内存使用完了,就将还存活的对象复制到另一块上面,然后把已经使用过的内存空间一次性清除掉。
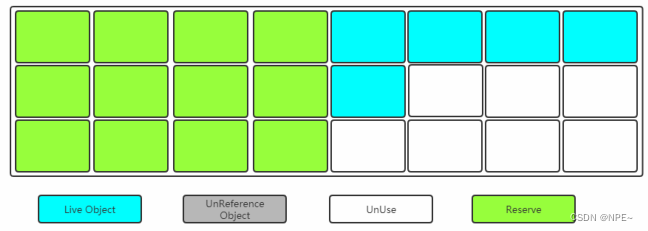
缺点:空间利用率低
2.3.3 标记-整理(Mark-Compact)
复制收集算法在对象存活率较高的时候就需要进行较多的复制操作,效率会变低。更关键的是,如果不想浪费50%的空间就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以老年代一般不能直接选用这种算法。
标记过程仍然与"标记-清除"算法一样,但是后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
其实上述过程相对"复制"算法来讲,少了一个"保留区"
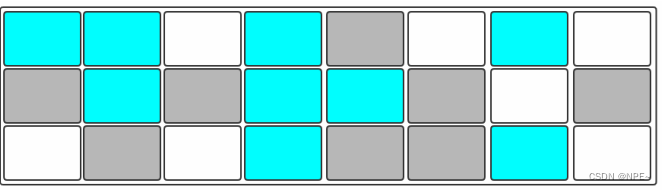
让所有存活的对象都向一端移动,清理掉边界以外的内存。
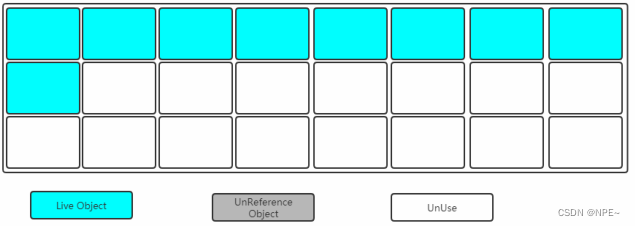
2.3.4 分代收集算法
既然在啊上面介绍了3种垃圾收集算法,那么在堆内存中到底用哪一个呢?
Young区:复制算法(Young区对象生命周期短,Young区复制效率高)
Old区:标记清除或标记整理(Old区对象存活时间长)
2.4 垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
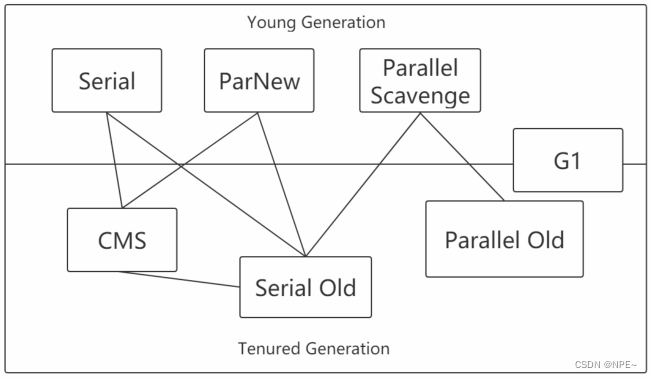
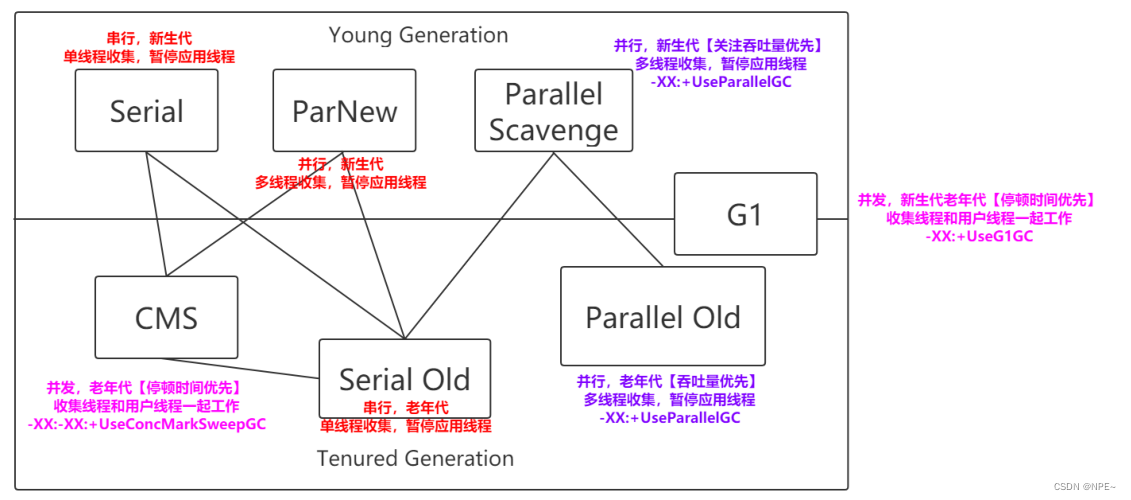
2.4.1 Serial(Young、复制)
Seriall是最基本、发展历史最悠久的,在JDK1.3之前是虚拟机新生代收集的唯一选择
单线程收集器,不仅仅意味着它只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的
是其在垃圾收集的时候需要暂停其他线程。
-- 优点:简单高效,拥有很高的单线程收集效率
-- 缺点:收集过程需要暂停所有用户线程
-- 算法:复制算法
-- 适用范围:新生代
-- 应用:Client模式下的默认新生代收集器
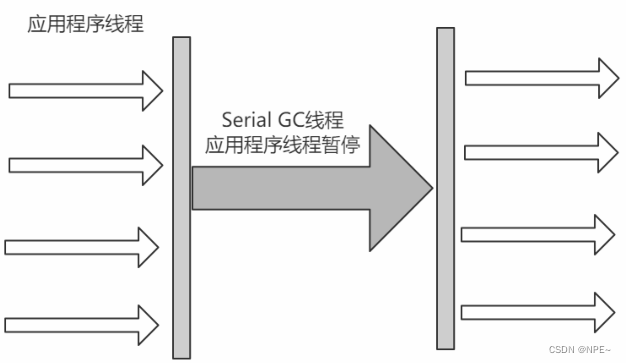
2.4.2 Serial Old(Old、标整)
Serial Old收集器时Serial收集器的老年代版本,也是一个单线程收集器,不同是采用"标记-整理算法",运行过程和Serial收集器一样。
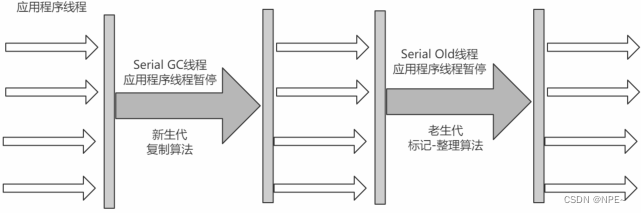
2.4.3 ParNew(Serial 的多线程版)
可以把该收集器理解为Serial收集器的多线程版本
优点:在多CPU时,比Serial效率高
缺点:收集过程暂停所有用户线程,单CPU时比Serial效率差
算法:复制算法
适用范围:新生代
应用:运行在Server模式下的虚拟机中首选的新生代收集器
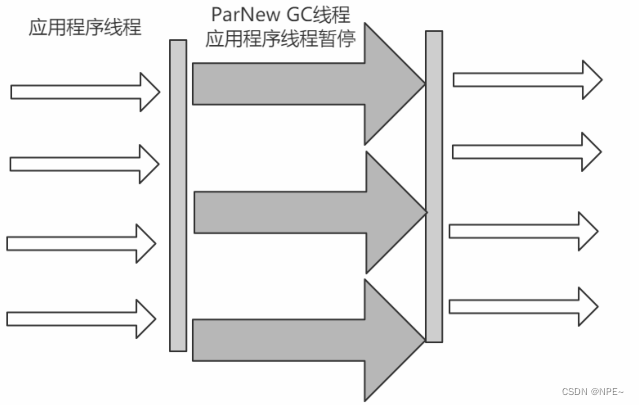
2.4.4 Parallel Scavenge(Young区,多线程,吞吐量+)
Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器,看上去和ParNew一样,但是Parallel Scavenge更关注系统的吞吐量。
吞吐量:系统单位时间内所处理的信息量
吞吐量=运行用户代码的时间 /(运行用户代码的时间+垃圾收集的时间)
比如:虚拟机一共运行了100分钟,垃圾收集时间用了1分钟,吞吐量=(100-1)/100=99%
若吞吐量越大,意味着垃圾收集的时间越短,则用户代码可以充分利用CPU资源,尽快完成程序的运算任务。
-XX:MaxGCPauseMillis 控制最大的垃圾收集停顿时间
-XX:GCRatio 直接设置吞吐量大小
2.4.5 Parallel Old(Old区,多线程,标整,吞吐量+)
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法进行垃圾回收,也是更加关注系统的吞吐量。
2.4.6 CMS(Old区, 垃圾、用户线程并发,标清)
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器
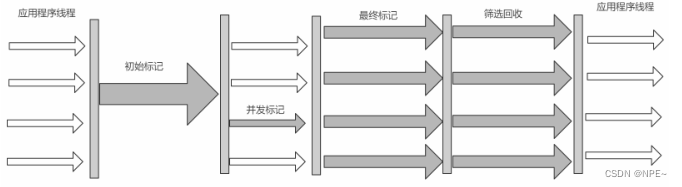
采用的是"标记-清除算法",整个过程分为4步:
(1)初始标记 initial mark 标记GC Roots直接关联对象,不同Tracing,速度很快
(2)并发标记 concurrent mark 进行GC Roots Tracing
(3)重新标记 remark 修改并发标记因用户程序变动的内容
(4)并发清除 concurrent sweep 清除不可达对象回收空间,同时有新垃圾产生,留着下次
清理称为浮动垃圾
由于整个过程中,有并发标记和并发清除,收集器线程可以与用户线程一起工作,所以总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行。
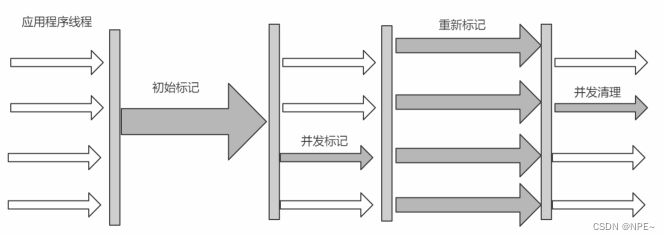
初始标记(找到GC Root关联对象) - 并发标记(Tracing) - 重新标记(并发标记时候,用户变动的内容) - 并发清除(清除垃圾)
优点:并发收集、低停顿
缺点:产生大量空间碎片、并发阶段会降低吞吐量
2.4.7 G1(Young、Old;Region,标整,用户期望回收time)
Garbage First,使用G1收集器时,Java堆的内存分布与其他收集器有很大的差别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留着新生代与老年代的概念,但是新生代和老年代不再是物理隔离的,它们都是一部分Region(不需要连续)的集合。
每个Region大小都是一样的,可以是1-32M之间的数值,但是必须保证是2^n
如果对象太大,一个Region放不下[超过Region大小的50%],那么就会直接放到H中
设置Region大小: -XX:G1HeapRegionSize=M
所谓Garbage-First,其实就是优先回收垃圾最多的区域
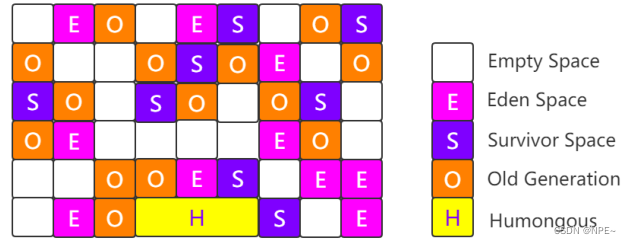
1.分代收集(仍然保留了分代概念)
2.空间整合(整体上属于"标记-整理算法",不会导致空间碎片)
3.可预测的停顿(比CMS更先进的地方在于能让使用者明确指定一个长度为M毫秒的时间片段内,
消耗在垃圾收集上的时间不得超过N毫秒)
整体过程:
- 初始标记(Initial Marking)
标记GC Root能够关联的对象,并且修改TAMS的值,需要暂定用户线程
- 并发标记(Concurrent Marking)
从GC Root出发,进行可达性分析,找出存活的对象,与用户线程并发执行
- 最终标记(Final Marking)
修正因并发标记阶段中因用户程序而导致变动的数据,需要暂停用户线程
- 筛选回收(Live Data Counting and Evacuation)
对各个Region的回收价值和成本进行排序,根据用户所期望的停顿时间指定回收计划
2.4.8 ZGC(Page、10ms以内)
zero garbage collector, 号称"零停顿"。JDk11新引入的ZGC收集器,不管在物理上还是逻辑上,都不存在新老年代概念了,会分为一个个Page,当进行GC操作时会对page进行压缩,因此没有碎片问题
目前只能在64位的linux上使用,因此使用得较少
特点:
- 可以达到10ms以内的停顿时间要求
- 支持TB级别的内存
- 堆内存变大后停顿时间还是在10ms以内

2.4.9 垃圾收集器分类、总结
- 串行收集器:Serial和Serial Old
只能有一个垃圾回收线程执行,用户线程暂停。
--适用于内存比较小的嵌入式设备。
- 并行垃圾收集器[吞吐量优先]:Parallel Scanvenge、Parallel Old
多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
--使用科学计算、后台处理等交互场景
"并行":多个线程
- 并发收集器[停顿时间优先]:CMS、G1
用户线程和垃圾收集线程同时执行(但不一定是并行的,可能是交替执行的),垃圾收集线程在执
行的时候不会暂定用户线程的运行。
--适用于对于时间有要求的场景,如:web
| 名称 | 特点 |
|---|---|
| Serial | Young区、单线程、复制算法 |
| Serial Old | Old区、单线程、标记整理算法 |
| ParNew | Young区、多线程、复制算法 |
| Parallel Scavenge | Young区、多线程、复制算法、吞吐量优先 |
| Parallel Old | Old区、多线程、标记整理算法、吞吐量优先 |
| CMS | Old区、垃圾收集线程与用户线程并发、标记清除算法 |
| G1 | Young区、Old区(Region概念)并发、标记整理算法,用户指定停顿时间 |
| ZGC | Page,10ms以内停顿 |
2.5 常见问题
-
吞吐量和停顿时间
- 停顿时间:垃圾收集器进行垃圾回收时,用户线程暂停时间
- 吞吐量:运行用户代码时间/(运行用户代码时间+垃圾收集时间)
- 停顿时间越短就越适合需要和用户交互的程序使用,良好的响应速度可以提升用户体验;
- 高吞吐量则可以高效地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太
多交互的应用。
"上面两个指标也是评价垃圾收集器好坏的标准"。
-
如何选择合适的垃圾收集器
Oracle官网:
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/collectors.html#
sthref28- 优先调整堆的大小,让JVM自己来选择
- 如果内存小于100M,使用串行收集器
- 如果是单核,且没有停顿时间要求,使用串行或JVM自己选择
- 如果允许停顿时间超过1s,选择并行或JVM自己选择
- 如果响应时间最重要,并且不能超过1s,使用并发收集器
-
对于G1垃圾收集器
JDK7开始使用,JDK8非常成熟, JDK9为默认,使用新老代
是否使用G1收集器?
(1)50%以上的堆被存活对象占用
(2)对象分配和晋升的速度变化非常大
(3)垃圾回收时间比较长
- G1中的RSet
全称Rememberd Set,用于记录维护Region中对象得引用关系
试想,在G1垃圾收集器进行新生代的垃圾收集时,也就是Minor GC,假如该对象被老年代的
Region所引用,这个时候新生代对的对象就不能被回收,该怎么记录呢?
这个时候,我们就想到了用一个类似于map的结构,key记录region的地址,value表示引用该对象
的集合,这样就能知道该对象被哪些老年代的对象所引用,从而不能被回收。
- 如何开启需要的垃圾收集器
(1)串行:
-XX:+UseSerialGC
-XX:+UseSerialOldGC
(2)并行(吞吐量优先):
-XX:+UseParallelGC
-XX:+UseParallelOldGC
(3)并发收集器(响应时间优先):
-XX:+UseConcMarkSweepGC
-XX:+UseG1GC














 1801
1801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









