






redis主从
将一个redis变成一堆redis,每个redis分工不同。用一群redis来实现当时一个redis的功能。
基本机构为一主多从。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ju4Imqwu-1589893045209)(images\1589885682558.png)]](https://i-blog.csdnimg.cn/blog_migrate/6c097b3bbd84f97297e55f267d63e6bc.png#pic_center)
对外提供io服务,内部的写入master,从slaver进行读取。做到读写分离,slaver需要按时同步master的数据。
效果:
- 主从配置以后可以做到读写分离,提高了redis集群的可读可写性能。如果读的压力高,只需要增加slaver节点即可。同时可以实现查询的负载均衡。
- 故障转移,master-slaver的结构可以做到故障转移,如果master不可用,剩下的slaver节点可以选举产生新的master,持续进行io服务。
- 数据冗余,高可用的核心就是冗余,数据安全的关键就是数据冗余。io通过master将数据写入redis集群中,slaver同步master数据,即便是master服务不可用,或者数据丢失,slaver依然存在数据备份。避免数据点单故障。
- 搭建集群的基本单元。集群中引入了槽道的概念,如果有一个redis组对外服务不可用(集群是会讲解),会导致整个redis集群瘫痪。
实战:
-
修改配置文件
[root@linux my-redis-config]# cp redis.conf redis-6379.conf [root@linux my-redis-config]# cp redis.conf redis-6380.conf [root@linux my-redis-config]# cp redis.conf redis-6381.conf修改内容:
port 6379 #端口修改 pidfile /var/run/redis_6379.pid # 后台pid修改 logfile "6379.log" #6379的日志 分来配置 dbfilename dump-6379.rdb #数据持久化改不同的 ----------------------------------------------------------------------------- 剩下的两个也改这些位置![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AhHqKtTI-1589893045211)(images\1589887231376.png)]](https://i-blog.csdnimg.cn/blog_migrate/b39549fdd0e53d6bd58e269d4c9ca068.png#pic_center)
此时启动了不同的redis,但目前还没开始配置主从。
这里可以写死在配置文件里,每次直接执行redis就会生效。如果如本例子,重启redis就需要重新配置。
进入客户端
我们用
info replication,来查看每个redis的状态。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sj3Rvnz2-1589893045213)(images\1589887609494.png)]](https://i-blog.csdnimg.cn/blog_migrate/b89fef29f8dbf1f3d9f42c0c45b2b666.png#pic_center)
现在都是master节点。
主从配置:
通过replicaof来进行主从配置。
配置文件中:
replicaof <masterip> <masterport> # 这里写上master节点的信息就可以绑定了
我们直接在内部进行配置
SLAVEOF 127.0.0.1 6379 # 配置了127.0.0.1 的6379为master节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GpIkGxg8-1589893045215)(images\1589888054720.png)]](https://i-blog.csdnimg.cn/blog_migrate/871e9c282f1908d791262352095634d5.png#pic_center)
测试读写:
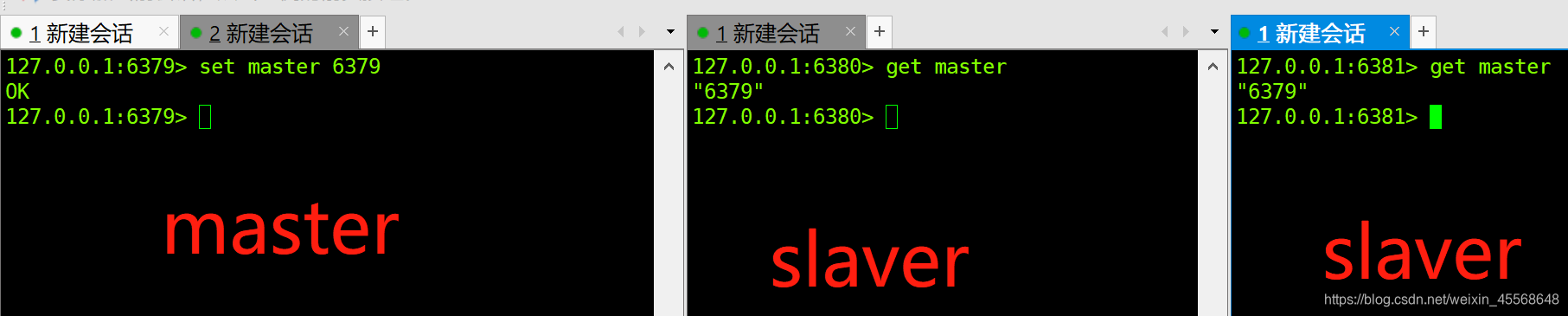
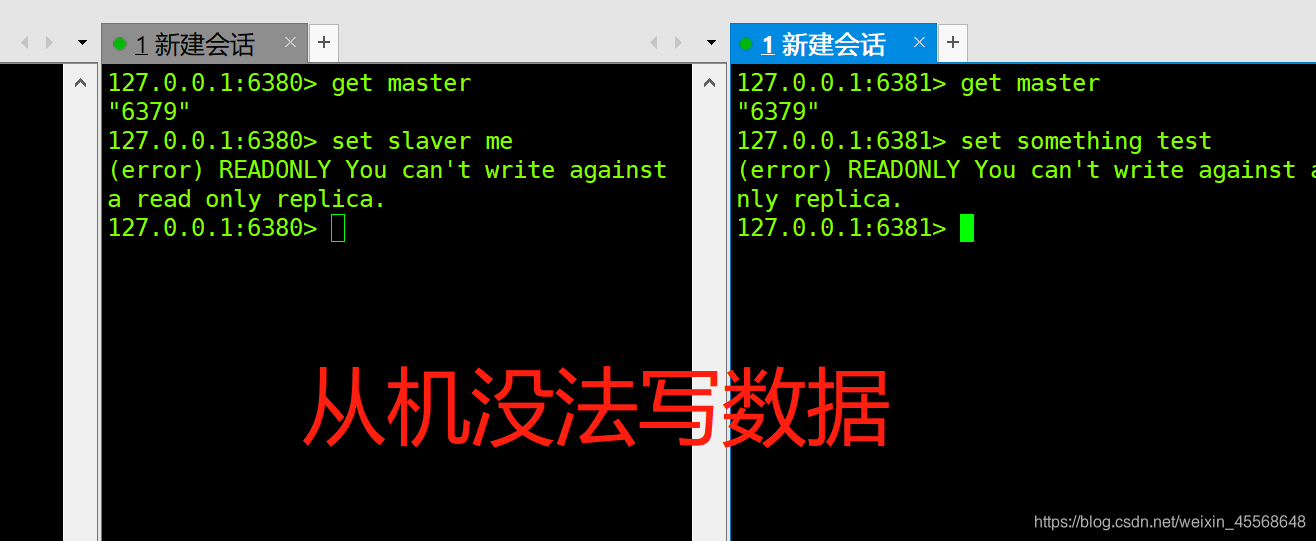
这时候数据已经同步了。
这个时候主机挂了,从机依然没法写。
我们接着测试,手动将从机升级成master
在不引用哨兵之前,通过手动进行修改。
手动设置一个slaver
#变成master
SLAVEOF no one
手动设置另一个slaver
#变成改变master
SLAVEOF 127.0.0.1 6380
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4MqvoVVr-1589893045220)(images\1589889393245.png)]](https://i-blog.csdnimg.cn/blog_migrate/eb71d05012caefb6325ecaf740e9f457.png#pic_center)
为了实现自动化切换,这时候我们需要一个进行对目前运行的redis进行监控,这个就是哨兵模式。
redis哨兵
哨兵模式是监控redis的master节点和slaver节点。同时在master挂了以后实现自动化的故障转移。即自动实现我们上面手动实现的过程。
结构:
每个节点都应该有哨兵进行监控,同时哨兵应该能监控到所有的节点。
每个哨兵之间相互监督,所有哨兵监视所有节点。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B26mIjko-1589893045221)(images\1589890224463.png)]](https://i-blog.csdnimg.cn/blog_migrate/a5d601289e8635be70eeac328a259ce7.png#pic_center)
在写一个哨兵(sentinel)的配置文件。
全哨兵配置文件:
sentinel monitor <master-name> <ip> <redis-port> <quorum>
# 告诉sentinel去监听地址为ip:port的一个master,这里的master-name可以自定义,quorum是一个 数字,指明当有多少个sentinel认为一个master失效时,master才算真正失效
sentinel auth-pass <master-name> <password>
# 设置连接master和slave时的密码,注意的是sentinel不能分别为master和slave设置不同的密码,因 此master和slave的密码应该设置相同。
sentinel down-after-milliseconds <master-name> <milliseconds>
# 这个配置项指定了需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。 单位是 毫秒,默认为30秒
sentinel parallel-syncs <master-name> <numslaves>
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这 个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为 replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状 态。
sentinel failover-timeout <master-name> <milliseconds>
# failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那 里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时, slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了。
我们实验,启动三个哨兵配置如下
sentinel monitor master6379 127.0.0.1 6379 2 #监控的主节点
port 26379 #哨兵的端口号
-------------------------------------------------------------
sentinel monitor master6379 127.0.0.1 6379 2
port 26380
-------------------------------------------------------------
sentinel monitor master6379 127.0.0.1 6379 2
port 26381
运行起来以后,我们kill掉master节点。
查看sentinel的日志。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CedpJMEY-1589893045221)(images\1589892844539.png)]](https://i-blog.csdnimg.cn/blog_migrate/e4188938dc995fde37d8ddf06cea5c40.png#pic_center)
通过客户端查看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uGIrJKje-1589893045222)(images\1589892929031.png)]](https://i-blog.csdnimg.cn/blog_migrate/3e343f5370ea4f70ac80397e225da163.png#pic_center)
可以参考 Redis的哨兵 conf配置。
注意:解压之后有sentinel.conf里面有相关的配置,可以直接更改配置文件。
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
这个数字越小,完成failover所需的时间就越长,
但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。
可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,
这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,
一个是事件的类型,
一个是事件的描述。
如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
#通知脚本
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
还有配置的资料(来自于 艾编程一期飞天班笔记)
# redis的安装根目录下,有个sentinel.conf
# 部署三个哨兵节点,同时监控一组redis服务(只有一个节点其实也可以,但风险)
# bind 127.0.0.1 192.168.1.1
# 测试的时候放开访问保护
protected-mode no
port 26379 #默认是26379
daemonize yes
pidfile /var/run/redis-sentinel-26379.pid #pid 集群要区分开
logfile /usr/local/redis-6379/sentinel/redis-sentinel.log #日志,非常重要
dir /usr/local/redis-6379/sentinel #工作空间
# sentinel监控的核心配置
# 最后一个2,quorum,>=2个哨兵主观认为master下线了,master才会被客观下线,才会选一个slave成为master
sentinel monitor icoding-master 127.0.0.1 6379 2
# master访问密码
sentinel auth-pass icoding-master icoding
# sentinel主观认为master挂几秒以上才会触发切换
sentinel down-after-milliseconds icoding-master 3000
# 所有slave同步新master的并行同步数量,如果是1就一个一个同步,在同步过程中slave节点是阻塞的,同步完了才会放开
sentinel parallel-syncs icoding-master 1
# 同一个master节点failover之间的时间间隔
sentinel failover-timeout icoding-master 180000
配置完毕 启动项目
进入哨兵客户端
redis-cli -p 26379
#查看 master的配置信息
sentienl master <master-name>
#查看 master的配置信息
sentinel slaves <master-name>
#查看 master的配置信息
sentienl sentinels <master-name>
得到下面信息:
127.0.0.1:26379> sentinel master icoding-master
1) "name"
2) "icoding-master"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
7) "runid"
8) "1af6295a965c3760de3acd6aa6b029f2220281e2"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "271"
19) "last-ping-reply"
20) "271"
21) "down-after-milliseconds"
22) "30000"
23) "info-refresh"
24) "838"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "613238"
29) "config-epoch"
30) "0"
31) "num-slaves"
32) "0"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "2"
37) "failover-timeout"
38) "180000"
39) "parallel-syncs"
40) "1"
采坑注意:如果从节点设置了masterauth,主节点没有密码也不能进行连接。
可以通过查看日志看出错的地方。
哨兵的通信
这时候redis的主从就配置完了。现在思考一个问题,我们配置哨兵的时候并没有对哨兵进行主从配置,那么哨兵间是怎么通信的?
我们配置的时候所有的哨兵都是配置在在了redis-6379master节点下面。也就说,所有的哨兵都会找到master节点,我们看看master的监控。
127.0.0.1:6379> MONITOR
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wMpVjIC5-1590052041296)(images\image-20200521155636000.png)]](https://i-blog.csdnimg.cn/blog_migrate/38301f642b59529134639c35a8dde775.png#pic_center)
在配置文件里可以看到他的id号
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cdc6Olur-1590052041297)(images\image-20200521160100152.png)]](https://i-blog.csdnimg.cn/blog_migrate/5537307fb669c8552cc3bde756cc6ff8.png#pic_center)
哨兵是怎么选举真的master呢?(取自 艾编程一期班)
slave选举机制
会考虑的slave选举的信息
- 和master断开的时长
- slave的优先级:replica-priority 100
- 复制的offset位移程度
- run_id
如果slave和master连接断开超过:down-after-milliseconds icoding-master这个配置的10倍以上绝对不考虑
slave的选举排序顺序
1、按照slave优先级进行排序,replica priority越低,优先级越高
2、如果replica priority级别相同,看offset越靠后(复制的内容多少),优先级越高
3、如果上面两个条件都一样,这个时候看run_id ,run_id字符排序越靠前越优先
先选一个执行主从的sentinel,这个sentinel在根据主从选举算法进行选举
程序如何确保访问有效
如果我们直接连接master还是不能解决故障转移的问题
这个时候就需要连接我们哨兵ip port
spring:
redis:
host: 127.0.0.1
password: 123456
sentinel:
master: <master-name>
nodes: 39.99.199.5:26379,39.99.199.5:26381,39.99.199.5:26382 (sentinel-node)

















 2568
2568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









