






 本文介绍了一种爬取起点中文网上小说章节的方法,包括分析网站结构、提取所需信息及保存为TXT文件的过程。
本文介绍了一种爬取起点中文网上小说章节的方法,包括分析网站结构、提取所需信息及保存为TXT文件的过程。
如题,分析起点中文网,并提取出来章节链接,保存为txt文档。
代码仅供交流使用,请勿用作商业用途,如有违规,请联系删除
一,分析
1.打开带有章节的链接,例如:(随便选的一篇文章)
2.打开浏览器的抓包工具f12(我用的是谷歌浏览器),点击页面的免费试读,因为页面是在一个页面跳转,不需要多开浏览器。
抓到包会发现很杂乱,通过筛选会出现所需要的一些链接,这些链接一个个点击查看返回详情,最后发现那条蓝色链接是包含所有这篇小说的目录的。
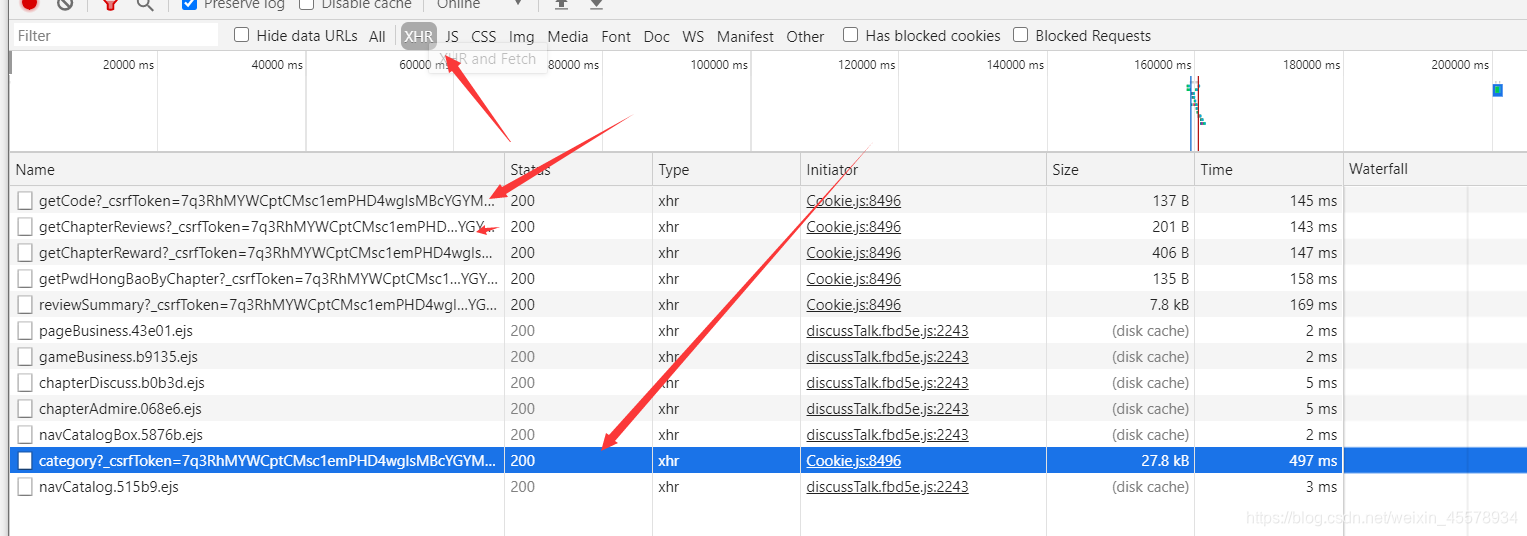
3.可以发现这个是一个get包,变化的参数有两个。

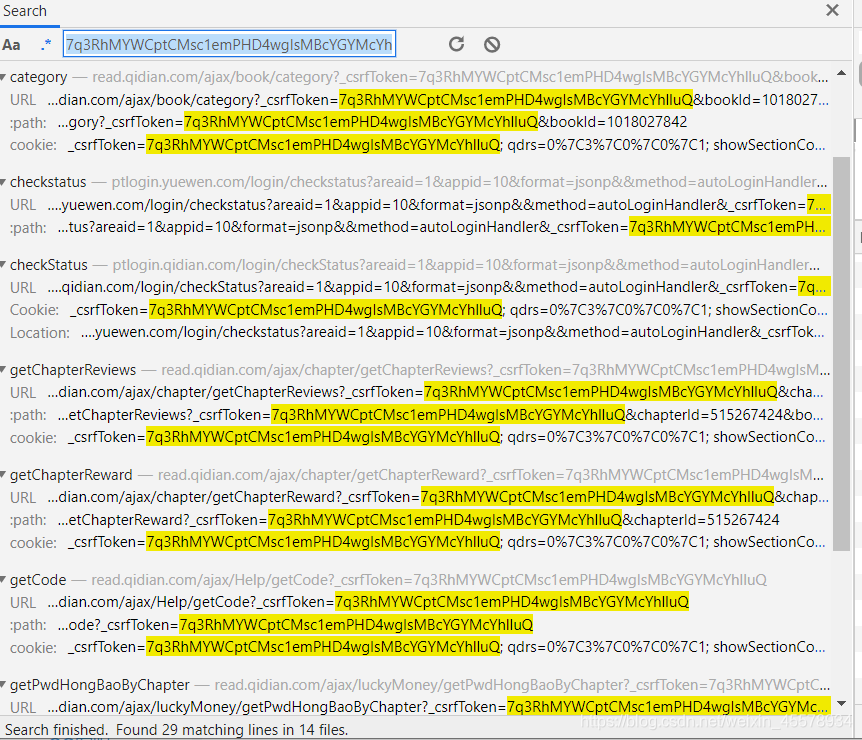
4.bookid可以发现是书的id,_csrfToken是一个可变的参数,这个得找到从哪获取的,先在所有链接里进行搜索这个内容,可以发现这个token是存在cookie中,查看了没有返回过cookie,就只能从refer来,找到最先出现这个token的链接,在这个链接里提取refer的,然后通过代码提取到这个token的值。

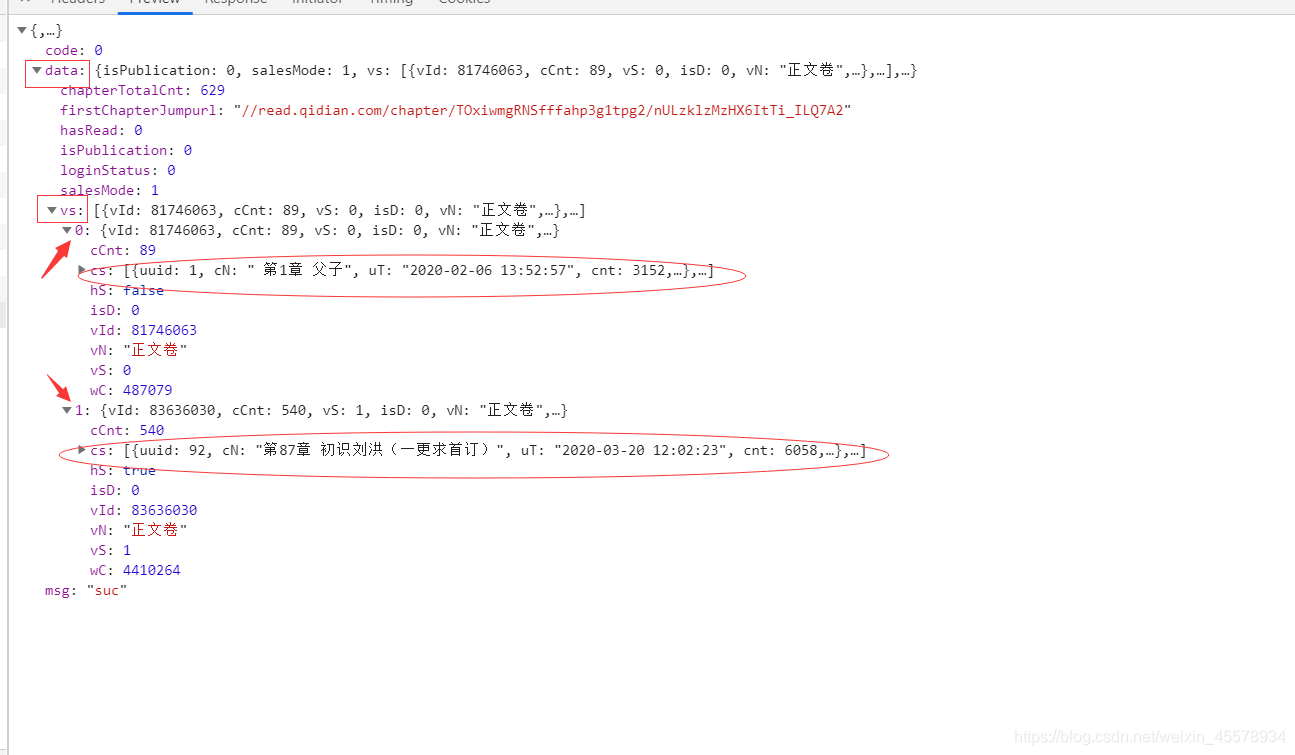
5.回到出现目录的链接那里(这个链接要在页面点击一下目录),分析返回的内容,返回的是属于json格式,提取也能用过key值提取出来,红色方框是主key,箭头是列表,小说包含的章节数多,圆圈的是代表目录的内容。具体的提取方式会在代码显示,公式是:返回内容[主key1][主key2][列表数][圆圈][具体提取的key]。其中提取的每章的链接需要自己补全。
二.代码
代码上面附上解释说明,详情请看:
def get_qidian(url):
import requests
import json
import re
from lxml import etree
#设置全局变量
some_ = ''
#提取bookid
bid = url.split("/")[-1]
# print(bid)
headers ={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"
}
res = requests.get(url, headers=headers)
#提取后面用到的refer
new_url = 'https:' + re.search(re.compile(r'<a class="red-btn J-getJumpUrl " href="(.*?)"'), res.text).group(1)
#提取小说名字
title = re.search(re.compile('《(.*?)》'), res.text).group(1)
#两种提取cookie成字典模式
#第一种
# print(res.cookies.list_domains())
# print(res.cookies.list_paths())
# print(res.cookies.get_dict(res.cookies.list_domains()[0],res.cookies.list_paths()[0]))
#第二种
cookie = requests.utils.dict_from_cookiejar(res.cookies)
Token = cookie['_csrfToken']
#更新字典的headers
headers.update({"x-requested-with": "XMLHttpRequest", "referer": new_url})
headers.update(cookie)
#解码返回的内容
res = requests.get(f'https://read.qidian.com/ajax/book/category?_csrfToken={Token}&bookId={bid}',
headers=headers).text.encode("raw_unicode_escape").decode()
# 把返回的内容转为json格式
res = json.loads(res)
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"
}
#提取列表
for s in res['data']['vs']:
#提取目录内容
for i in s['cs']:
#提取章节名字
chapter = i['cN']
#提取链接后半部分
ch_url = 'https://read.qidian.com/chapter/' + i['cU']
# print(chapter)
# print(ch_url)
#https://read.qidian.com/chapter/
#<div class="read-content j_readContent">
res = requests.get(ch_url, headers=headers).text
# print(res)
#通过etree提取每一章的内容
selector = etree.HTML(res)
txt_ = selector.xpath('//div[@class="read-content j_readContent"]/p/text()')
# print(txt_)
all_txt = ''
for g in txt_:
#对每一条内容进行处理
g = str(g)
g = g.replace('\u3000\u3000', '').replace('\n', '').strip() + '\n'
all_txt = all_txt + g
#把所有内容放在一个变量里,最后再保存
all_txt = chapter + '\n\n' + all_txt
some_ = some_ + all_txt
#把所有处理好了,进行写出保存
with open(f'{title}.txt', 'w') as f:
f.write(some_)
f.close()
if __name__ == '__main__':
get_qidian('https://book.qidian.com/info/1018027842')本文仅交流学习,觉得有帮助的点个赞,后续将会发布更多的好文章,请持续关注。

















 2318
2318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









