






实习记录:
1. Redis高级数据类型
HyperLogLog:超级日志(原理是伯努利分布,LogLog算法的改进)
1)采用一种基数算法,用于完成独立总数的统计。(统计网站每天有多少个用户访问(UV(Unique Visitor),每天的用户访问量(同一用户进行去重)))
2)占据空间小,无论统计多少个数据,只占12K的内存空间
3)缺点:不精确的统计算法,标准误差为0.81%
Redis中命令:pfadd key value添加; pfcount key统计
Bitmap:位图
1)不是一种独立的数据结构,实际上就是字符串(redisTemplate.opsForValue())
2)支持按位存储数据,可以将其看成是byte数组
3)适合存储大量的连续的数据的布尔值。(是精确的,比如统计一个人一年的考勤,0表示没来,1表示来了)
2. 网站数据统计:
UV根据用户IP排重统计(这样可以把未登录的游客用户也统计进来。不能用Bitmap,因为游客没有userId)
DAU根据userId排重统计(用bitmap作为数据结构,把userId当做redisKey的位置索引)

3. 转发forward的请求类型是不会变的(前一个请求是post,转发后的请求也会是post)
4. 多线程
线程池可以让线程复用
JDK线程池:ExecutorService、ScheduledExecutorService
Spring 线程池:ThreadPoolTaskExecutor、ThreadPoolTaskScheduler
以上在分布式场景下无法使用
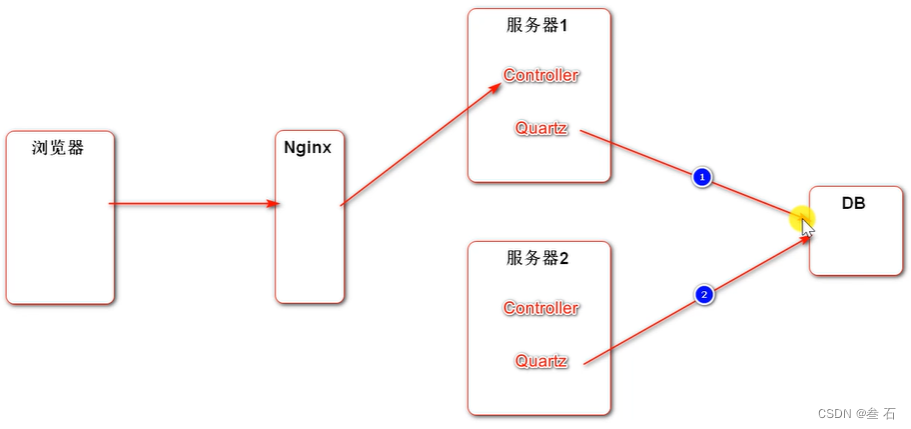
分布式定时任务:Spring Quartz
JDK和Spring线程池的定时任务的时间都是基于内存的,所以多服务器之间无法共享内存,导致每个服务器都会执行一遍定时任务,造成任务执行重复。
而Spring Quartz是基于一个数据库的,多个服务器之间的Quartz可以共享同一份数据,比如服务器1请求了DB之后,服务器2只能等待或者不再执行相同的任务,所以Quartz适合于分布式场景。
5. 多线程环境下可以用logger输出执行过程中的内容,logger可以输出线程的id和时间。
6. main方法中的其他线程不结束的话,main线程会等待它结束。而Test中方法的线程和它开启的线程是并发的,不会等待其他线程结束。
7. 当coreSize满了的时候,新来的任务会进入workQueue, 只有当workqueue满了的时候,当前的线程数量才会拓展到最大线程数量。这是我在Javaguide里找到的一句话:“当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。”(Spring自带的线程池ThreadPoolTaskExecutor和ThreadPoolTaskScheduler可以配核心数量、队列数量、最大线程数量,而JDK自带的线程池ExecutorService和ScheduledExecutorService不可以配置,所以常用Spring自带的线程池)
8. mysql数据量大(上亿)的时候,可以把一些数据存到es(宽表)里边来提高查询效率。
使用ES作为MySQL宽表的优势与实现方法(让你的数据查询速度提升100倍) - 编程大全
9. @Value(“${wk.image.storage}”}),使用@Value()注解可以获取到application.properties中配置的变量
10. 文件上传到云服务器的两种方式:

11. 后端用wkhtmltopdf工具保存长图时,主线程不会等待生成图片线程,所以不能将图片上传到七牛云(因为图片还未生成),
解决方案:设置一个定时任务,每隔500ms查看生成图片线程是否完毕,完毕后定时任务结束,若30s之后还未生成图片完毕,则抛出异常。
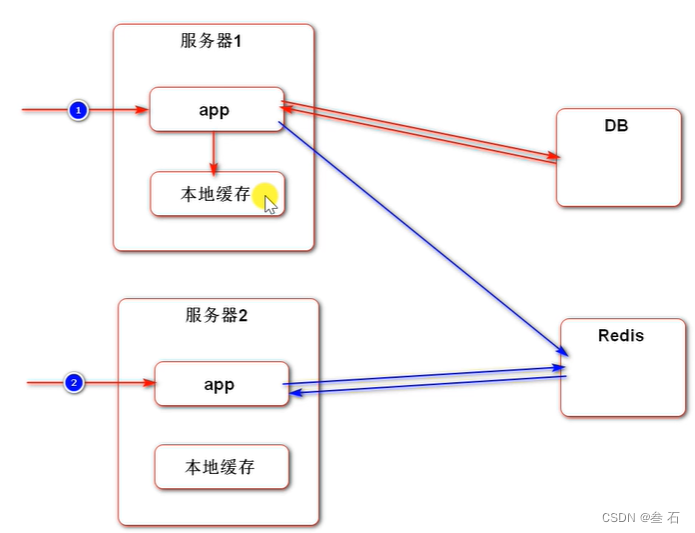
12. Caffeine是目前最好的本地缓存工具(将数据缓存在应用服务器上)
分布式缓存:是将数据存到NoSQL数据库里,比如Redis、MemCache(像“登录凭证”这种数据不能存在本地服务器缓存,因为分布式场景下,浏览器先访问服务器A,再访问服务器B,在A上缓存的登录凭证无法在B上获得)
13. 尽一切可能,避免直接访问数据库。
本地缓存(一级缓存)的效率要比Redis(二级缓存)高,因为少了网络开销,只需要访问内存。
14. 
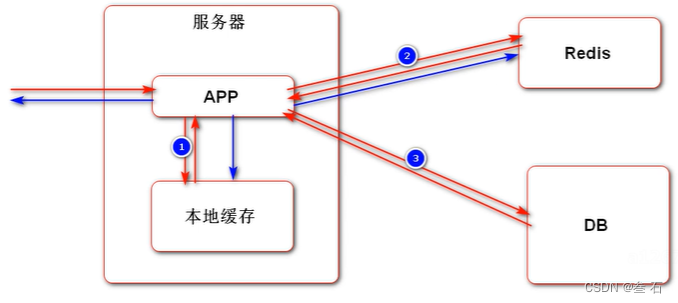
客户端向服务器发送请求,服务期先在本地缓存中查找数据,没有的话再去查找,仍未查到的话再去关系型DB中查找,并将查到的数据缓存在redis和本地缓存中,再将数据返回给浏览器。
15. Caffeine和Redis的相同点与不同点:
1)相同点:
两个都是缓存的方式
2)不同点:
Redis是将数据存储到内存里
Caffeine是将数据存储在本地应用里
Caffeine和Redis相比,没有了网络IO上的消耗
3)联系:
一般将两者结合起来,形成一二级缓存。使用流程大致如下:
去一级缓存中查找数据(caffeine-本地应用内)
如果没有的话,去二级缓存中查找数据(redis-内存)
再没有,再去数据库中查找数据(数据库-磁盘)
来自未来的缓存 Caffeine,带你揭开它的神秘面纱|内存|key|线程|队列|redis_网易订阅
16. Spring Actuator项目监控

日报:
2023.08.14:
1. 这周开始在石景山办公
2. 置顶、加精、删除功能:后端数据访问层、业务层开发;权限配置(SecurityConfig中添加接口的访问权限,前端thymeleaf根据用户权限显示不同按钮)
3. 了解Redis中的高级数据类型HyperLogLog和Bitmap
4. 网站数据统计,在拦截器中实现记录UV和DAU的逻辑,新建controller实现UV和DAU的计算
2023.08.15:
1. 上午请假和桑总去空军医院探望屈总
2. 测试JDK线程池(ExecutorService、ScheduledExecutorService)和Spring线程池(ThreadPoolTaskExecutor、ThreadPoolTaskScheduler)以及@EnableScheduling、@EnableAsync、@Async、@Scheduled()
3. 开腾讯会议,数库介绍代码和解答
4. 实习收获:mysql搜索调优,数据量极大时,添加索引也不能很好地降低查询速度,可以考虑将mysql中的数据导入到es中,再用es进行搜索(生态图谱项目,单表数据上亿,重点!)
2023.08.16:
1. 熟悉Spring Quartz,编写quartz的api
2. 看生态图谱项目代码
3. 热帖排行功能,用定时任务算帖子分数,将分数存在mysql数据库中,点最热时order by score
4. 抢到一张张杰的演唱会门票
5. 利用wkhtmltopdf工具,使用命令生成pdf和长图(看完视频,未跟着些代码,因为这个工具用处不大)
6. 文件上传到七牛云服务器(之前已经实现过,是在前端上传的)
2023.08.17:
1. 看完上传到七牛云那节视频
2. 看生态图谱项目发的资料
3. 使用Caffeine给热门帖子构建多级缓存(本地缓存和分布式缓存),构建30万条帖子数据并使用Jmeter做压力测试(吞吐量提升了20倍)
4. 了解单元测试,了解@BeforeClass, @AfterClass, @After, @Before, @After, @Test注解和Assert断言
5. 使用Actuator对项目的beans,loggers,info,health等端点(EndPoints)进行监控,并自定义了database端点,最后对database端点进行权限控制
6. 将最近两周的实习记录上传到CSDN上
2023.08.18:
1. 请假


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









