






来源:通信学报
面向隐私保护的非聚合式数据共享综述
李尤慧子1, 殷昱煜1, 高洪皓2,3, 金一4, 王新珩5
1 杭州电子科技大学计算机学院,浙江 杭州 310018
2 上海大学计算机工程与科学学院,上海 200444
3 韩国嘉泉大学计算机工程系,城南市 461701
4 北京交通大学计算机与信息技术学院,北京 100044
5 西交利物浦大学电气与电子工程系,江苏 苏州 215123
摘要:海量数据价值虽高但与用户隐私关联也十分密切,以高效安全地共享多方数据且避免隐私泄露为目标,介绍了非聚合式数据共享领域的研究发展。首先,简述安全多方计算及其相关技术,包括同态加密、不经意传输、秘密共享等;其次,分析联邦学习架构,从源数据节点和通信传输优化方面探讨现有研究;最后,整理对比面向隐私保护的非聚合式数据共享框架,为后续研究方案构建和运行提供支撑。此外,总结提出非聚合式数据共享领域的挑战和潜在的研究方向,如复杂多参与方场景、优化开销平衡、相关安全隐患等。
关键词:隐私保护 ; 数据共享 ; 联邦学习 ; 安全多方计算

论文引用格式:
李尤慧子, 殷昱煜, 高洪皓, 等. 面向隐私保护的非聚合式数据共享综述[J]. 通信学报, 2021, 42(6): 195-212.
LI Y H Z, YIN Y Y, GAO H H, et al. Survey on privacy protection in non-aggregated data sharing[J]. Journal on Communications, 2021, 42(6): 195-212.

1 引言
当今世界处在信息时代,并正快速进入全面的数字世界。随着5G的广泛应用,物联网爆发出了蓬勃的生命力,移动与物联网终端发展情况如图1所示。海量数据隐藏着重要的价值,这也是近年来人工智能、深度学习等领域飞速发展的主要因素之一,然而,数据一旦非法泄露,会造成巨大的损失。2020年中国网络安全报告显示,病毒样本总量为1.48亿个,较2019年同期上涨43.71%;超两亿条用户信息被出售,造成数千万经济损失。国外数据隐私问题也十分严峻,2019年英国航空公司因违反用户隐私条例被信息监管局罚款近2 亿英镑(约合15.8 亿元人民币)。各国为了推动数据隐私保护,颁布了一系列法律条文,如欧盟的 GDPR(General Data Protection Regulation)、美国的 CCPA(California Consumer Privacy Act)以及我国的《中华人民共和国网络安全法》。由此可见,数据隐私保护十分重要。
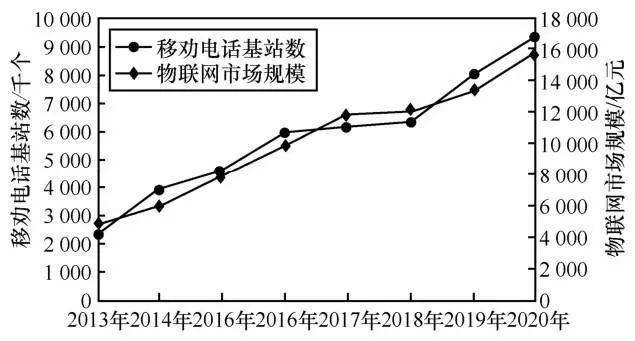
图1 移动与物联网终端发展情况
加密是保护数据隐私的主要手段。在聚合式数据共享方法中,各数据生产者使用加密算法编码源数据,然后传输至数据处理中心;数据处理中心通过解密算法获取数据信息,聚合所有源数据进行数据挖掘等复杂的操作。加密保证了数据传输时的隐私安全,但无法确保数据处理中心的安全,如果数据处理中心被攻破,则会造成全部数据的泄露。相对地,非聚合式数据共享方法旨在不汇集所有源数据的情况下,同样达到数据共享要完成的最终目标。非聚合式数据共享主要包含两层意思:首先,数据不汇聚,避免了单点故障(中心点被攻破)造成的潜在隐私泄露危险;其次,数据共享不是指狭义的源数据分享,而是从广义角度来看,期望达到数据共享的最终目标,例如数据处理和数据挖掘。最优场景是在不分享源数据的情况下完成处理和挖掘操作,进一步避免数据隐私泄露的可能。
从非聚合式架构来看,1982年提出的安全多方计算(SMC, secure multi-party computation)是早期主要的非聚合式数据共享方法。安全多方计算继承了分布式的特点,计算参与方地位平等且互不信任,无中心节点。利用加密算法,如同态加密等,数据接收方只能处理加密后的数据,无法获知源数据信息。处理后的数据再传送回数据发送方,发送方经过解密后获得计算结果。安全多方计算利用密码学和底层数据交互协议,保证计算参与方在不获取源数据的情况下,完成数据处理操作,增强了数据的隐私性。早期,由于安全多方计算复杂度高,通常采用哈希映射等方法进行传输,但其安全性不足。其他参与方可以通过枚举操作来确定对方数据集中存在的元素,从而获取对方的隐私信息。随着边缘计算等新型计算架构的发展以及设备计算能力的增强,安全多方计算的实际需求和部署能力也相应提升,相关技术(如不经意传输拓展协议、秘密分享、隐私求交等)为数据隐私保护提供了可靠的指导方案和技术基础。
近年来,云计算、物联网和机器学习高速发展,广泛应用于智慧城市、智慧安防等领域。海量异构数据聚合在云平台上,通过各类机器学习和深度学习算法对数据进行分析,挖掘数据隐藏的知识信息。然而,随着数据和用户隐私的关联度越发密切,把全部源数据聚合到中心节点再进行模型训练的方法隐私泄露风险就越大。因此,谷歌于 2017 年提出联邦学习,旨在不需要通过中心化的数据训练就能获得机器学习模型。各数据提供方在本地进行数据训练,把参数等隐私无关信息发给参数服务器进行全局调优,再把优化后的模型应用到本地,以实现在不提供原始数据的情况下,获取全局的数据“知识”。联邦学习是典型的非聚合式数据共享方法,源数据不出本地,降低了隐私泄露的风险,同时完成了数据共享的目标,即获得优化训练模型。
数据的重要性日益增加,为了更好地保护数据隐私安全,本文针对非聚合式数据共享方法进行介绍和分析,主要综述了安全多方计算和联邦学习的相关研究。安全多方计算侧重于数据传输和计算外包,本文从原理、算法复杂度、适用场景等情况比较分析各类交互协议,增强数据交互的安全性。联邦学习侧重于数据挖掘,旨在从多个数据孤岛上全局分析数据潜在价值,其框架主要包括本地数据训练、参数信息传输交互、参数服务器全局调优。本文从与数据隐私关联性较强的数据源(本地数据)和通信传输两方面讨论对比现有的联邦学习优化方法。此外,本文总结整理了现有面向隐私保护的非聚合式数据共享框架,同时从复杂多参与方场景、优化开销平衡等方面提出了非聚合式数据共享隐私保护潜在的4个研究方向及建议。
2 安全多方计算
安全多方计算是密码学领域用于多个数据方在无可信第三方的情况下,安全且保护隐私地协同计算某个或某些约定函数的方法。SMC由Yao于1982 年提出,用来解决著名的百万富翁问题,即2个百万富翁比较谁更加富有,而不能泄露具体的财富值。
安全多方计算广泛应用于敏感数据协同计算的场景。例如,根据个人的信用记录、购买记录、社交喜好等协同挖掘个性化推荐服务;广告转化率收益计算,即利用属于第三方平台的广告点击数据和商品平台的购买数据分析观看特定广告的用户中有多大比例购买了该商品等。
安全多方计算利用数据交互协议,保证计算参与方在不知道源数据的情况下,完成数据处理操作,增强了数据的隐私性。不同的数据交互协议特点各异,适用场景也不同,主要的MPC数据交互协议如下。
2.1 同态加密
在基于加密的数据交互协议中,最常用的是同态加密技术,由Rivest、Adleman和Dertouzos提出。该技术不仅支持加密数据传统的传输、存储操作,还支持用户直接对加密数据进行计算,其结果等价于原始数据计算后再加密。
同态性质是针对加密函数来说的,一般分为加(减)法同态、乘(除)法同态(也称单同态)和全同态。其简单定义如下。设存在映射g:G1→G2,则有
加法同态:g(x+y)=g(x)+g(y), x ,y∈G1
乘法同态:g(x+y)=g(x)× g(y),x,y∈G1
全同态:同时满足上述2个性质
若一个加密函数满足加法或乘法同态,则其支持在加密数据上做加法或乘法计算而不损害数据,若同时满足加法、乘法同态,即全同态,则几乎可以支持任何计算操作。广泛使用的RSA算法满足乘法同态,Paillier算法满足加法同态。
同态加密常常应用在云计算环境中,保证数据传输过程和云中心节点计算时的数据隐私安全。例如,在云外包的场景中,Abadi等实现了2个协议,通过加法同态加密等操作实现安全对抗半诚实对手,其中EO-PSI(efficient outsourced private set intersection)具有较好的大数据集拓展性。而文献采用加法同态加密技术实现隐私集合交集(PSI, private set intersection)协议和PSI-CA(private set intersection cardinality)协议。
针对两方数据集大小差异大的情况,Resende等使用同态加密和布谷鸟过滤器优化中提出的协议,在半诚实对手模型中实现了单向隐私求交协议;文献则利用全同态加密解决数据集差异大的问题。
同态加密的优点是可以在不泄露源数据的情况下,得到同样加密的计算结果,但是,合适的加密函数定义难,而且其最大的局限性在于复杂度过高,普遍应用还需要进一步的研究和发展。
2.2 逻辑电路和不经意传输
安全多方计算主要包括计算和数据传输2个方面。基于逻辑电路方案被认为是通用的计算设计方法,因为任何函数都可以转化成对应的逻辑电路,借助对电路真值表的替换、加密和打乱,形成Garbled Table。参与方间的数据传输可以通过不经意传输技术交换必要的消息,最后某一方计算出最终的结果。图2展示了以两方为例的情景。首先,由 Alice 根据需求构造电路,确定真值表内容。为门中的每条线秘密地生成2个密钥 ,分别对应输入 0、1,替换该门对应真值表中的值。用前两项加密第三项,然后随机打乱得到 Garbled Table。Bob通过不经意传输从Alice那里获得其输入对应的密钥、Garble Table和自己输入对应的密钥等必要信息,最后计算该门对应的输出C。在这一过程中,Bob不用泄露自己的输入,也不知道Alice的任何信息。
,分别对应输入 0、1,替换该门对应真值表中的值。用前两项加密第三项,然后随机打乱得到 Garbled Table。Bob通过不经意传输从Alice那里获得其输入对应的密钥、Garble Table和自己输入对应的密钥等必要信息,最后计算该门对应的输出C。在这一过程中,Bob不用泄露自己的输入,也不知道Alice的任何信息。
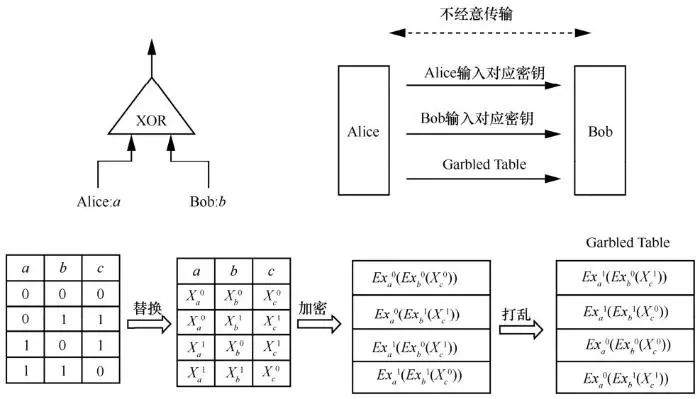
图2 混淆电路示意
基于逻辑电路的计算方法有一定可行性,文献在智能手机上成功配置了基于电路的协议,并使用了Wi-Fi通信。但该方法需要的逻辑门较多,实现复杂度较高。例如,计算编辑距离需要30 000个门电路。为了降低复杂度,Pinkas 等于 2019 年提出了具有线性渐进通信复杂度的基于电路的协议,在集合大小为220时,该协议的通信复杂度不到文献协议的十一分之一,但后者可以拓展到多方环境。
不经意传输技术保证接收者只能从发送者的多个数据中获取自己想要的数据,而发送者却不知道这个具体的数据。不经意传输的构造方法有许多,如基于RSA(Rivest, Shamir, Adleman)构造、基于椭圆曲线等。近年来,高效的 SMC 数据交互协议大部分是基于不经意传输拓展的,其性能较好,能够仅通过少数公钥操作和位操作完成大量的数据传输。例如,文献实现了在普通带宽环境中(30~100Mbit/s)最快的 SMC 协议,在半诚实对手环境和恶意对手环境中都能保证一定的安全性。它的底层协议是基于不经意拓展的轻量级多点不经意伪随机函数。由于在某些环境下,协议计算的结果可能只是一个中间结果,因此,Ciampi等基于不经意传输拓展实现能够输出“加密”的协议,类似的工作还有文献等。此外,文献利用差分隐私技术,选择性地泄露部分不重要的信息,相比于文献提出的对抗恶意对手的协议,性能提升近63%。
2.3 秘密共享
秘密共享(secret-sharing)也是SMC领域经常使用的技术,由Shamir提出。秘密共享的关键是保证数据共享过程使用的信道是安全的。传统方法采用的是加密技术,然而,密钥的分享也面临同样的问题,即如何保证密钥分享信道安全。非对称加密技术的发展在很大程度上解决了该问题,但它的安全性也依赖于信道的诚实性,存在被中间人攻击的可能。为了解决这一问题,秘密共享技术将秘密分成多份,由不同的信道传输,就算有恶意信道存在,也不能轻易还原完整的秘密。其形式化定义为
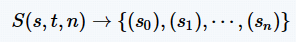
其中,s表示需要分享的秘密,t表示需要还原秘密的阈值,n 表示将秘密拆分的数目。在一组参与者中,秘密由大家共同保管,只有当超过阈值的参与者相互合作时才能恢复完整的秘密数据。
秘密共享技术在安全多方计算场景中应用广泛,数据方将数据和模型用秘密共享的方法加密拆分,发送至各参与方。在解决分布式集群一致性问题的拜占庭协议中,也采用秘密共享协议将秘密分成多份传送给各个假设的将军,并在需要的时候恢复秘密。
2.4 隐私集合交集协议
隐私集合交集协议是 MPC 领域使用较为广泛的应用层协议,旨在多个数据方间计算数据交集。其具体定义如下。
发送方S和接收方R分别持有一个私有数据集X 和 Y,协议的目标是计算它们各自隐私集合的交集,即以X和Y为输入,计算 f(X,Y)=X∩Y,而不能泄露除交集之外的数据信息。
PSI 作为具体的应用层协议,它底层的数据传输和计算功能可以由同态加密、不经意传输、秘密分享等技术实现。此外,PSI 还可以根据具体的应用要求拓展出各种各样的变体,例如,文献受可交换加密技术启发,采用布隆过滤器优化,接收者可以更轻松地计算输出,确保只有一方得知交集内容;只公布交集大小的应用场景,其中文献借助不经意评估方法实现恶意环境安全,结果表明其在云环境时的开销比半诚实协议高 25 倍,而且允许动态调节通信和计算之间的开销比;隐藏一方输入大小的应用场景,文献提出了一种适用于云计算环境的新的集合表示方法,基于加法同态公钥密码(PKC,private key cryptography)实现了2个实用的协议,即PSI和PSI-CA。
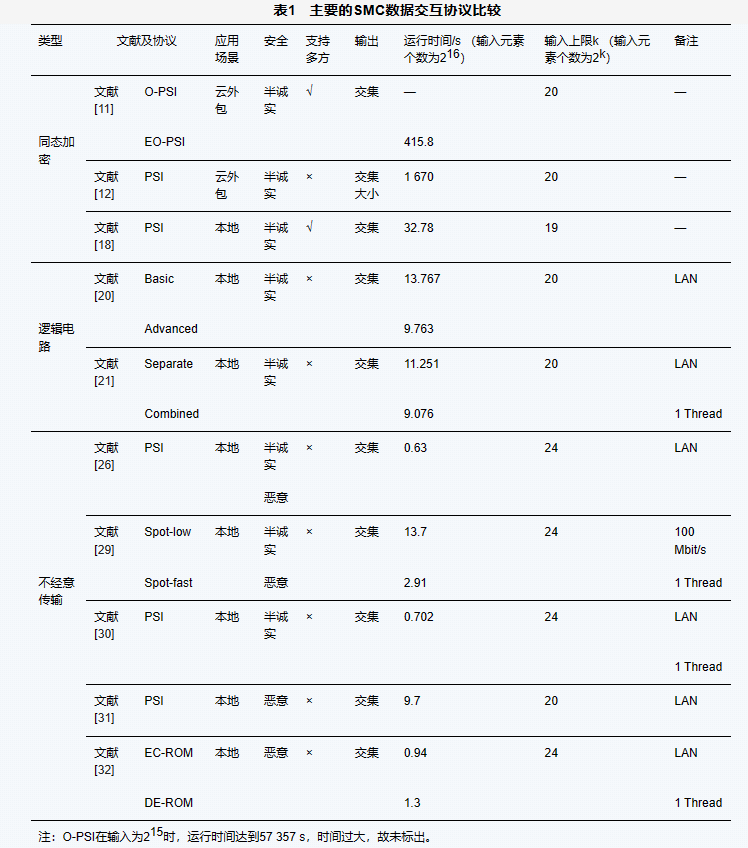
主要的SMC数据交互协议比较如表1所示。
3 联邦学习
随着云计算、人工智能、大数据等技术的发展,智能手机、可穿戴设备等产生了超大规模的数据,深度学习也随着数据量的增长而得到更好的发展。由于设备的计算能力不断增强,端设备数据与用户隐私关联度较高,非聚合式数据共享方法更受青睐,训练数据保留在本地的联邦学习算法得到广泛研究。
联邦学习是一种关注隐私保护的机器学习技术,源数据不离开本地设备,在多参与方或多计算节点之间开展高效的机器学习。联邦学习是一个统称,各数据提供方构成联邦,共同训练模型,其可使用的机器学习算法不局限于神经网络,还包括随机森林等。其框架主要由3个部分构成:提供数据的多个本地节点、负责参数调优的中心参数服务器、参数传输链路(传输本地数据训练后的模型参数至服务器,传输全局调优后的参数至各本地节点)。根据具体实现的深度学习模型和算法的不同,联邦学习框架可以适用于各类数据分散的学习场景中。
本文侧重于从源数据节点和通信传输2个方面分析联邦学习的优化方法及其相关的数据隐私保护技术。
3.1 源数据节点
联邦学习中各源数据节点在本地进行训练,仅上传参数信息,避免数据隐私信息泄露。针对源数据节点的工作主要可以分为数据获取和非平衡数据优化2个方面。
3.1.1 数据获取
联邦学习拥有一定规模的本地数据节点提供源数据,但本地节点的管理较为松散,是自主构建联邦模式,可以任意加入和离开。此外,本地节点的状态是不可控的,如在线情况、诚实度、参与度、贡献程度等。如何选择适合的本地数据节点、如何激励优质的节点参与并提供高质量的数据都是数据获取阶段需要考虑的问题。
1) 参加者选择
本地数据节点的质量会影响总体的训练过程,联邦学习可通过选择部分高质量参与者,提升算法效率。例如,FedAvg从符合要求的本地节点(如在线且空闲的设备)中选取一定量的客户端进行聚合;Goetz 等提出主动联合学习框架 AFL(active federated learning),每个通信回合不是随机均匀地选择客户,而是以模型和客户数据为条件进行概率选择;FedCS根据资源的状况主动管理本地节点,使其产生更多的聚合更新。
2) 激励机制
通常的研究工作都假设设备无条件贡献资源,但实际上设备是自私的,很难组建联邦。因此,部分学者研究如何使本地数据节点积极参与到联邦系统中,并制定高效的激励机制。首先,参与的节点之间可能会存在敌对竞争关系,双方正面积极参与并均获利十分关键。其次,参与者的贡献程度不同,产生的效益也不一致,如何合理公平地分配收益也是值得研究的问题。此外,部分工作将激励机制与防御恶意参与者结合,例如,Fmore是移动边缘场景的激励机制框架,实验证明提出的激励机制能提高学习算法的性能。
3.1.2 非独立同分布及不平衡数据的优化
数据分布及其质量对模型训练有重要影响,尤其是在非聚合数据共享方法中。2017 年谷歌在FedSGD 算法的基础上提出了 FedAvg 算法,该算法对非独立和不平衡数据都具有稳健性,为后续联邦学习优化奠定了基础。
1) 数据及模型架构优化
首先,从数据入手,部分解决方案利用共享数据子集方法,在保护用户隐私的前提下,提高模型准确率。其次,从模型本身架构入手,使之更加适应联邦学习,例如,基于随机梯度下降(SGD, stochastic gradient descent)的优化算法。从本地数据节点角度考虑,优化方法包括:对数据节点的要素进行插值更新、对节点的目标函数添加一个近端项(proximal term)、局部梯度添加可控的噪声干扰并控制变量、矫正本地数据的用户漂移等。
2) 模型个性化
模型个性化的联邦学习也解决了数据非独立同分布影响模型精度的问题。传统联邦学习下,中心参数服务器提供统一的本地模型,但在某些联合学习场景下,参与方希望训练的模型对自身利益最大化,而不是为了达成全局模型的共识而进行妥协。此外,多方数据的非独立同分布特性可能会降低全局模型的精度,导致用户参与联邦学习所得的模型精度不理想。模型个性化指参与方可自定义所训练的本地联邦学习模型,在利用本地数据集训练本地私有模型的基础上,参与全局公共模型的训练,优化私有模型。
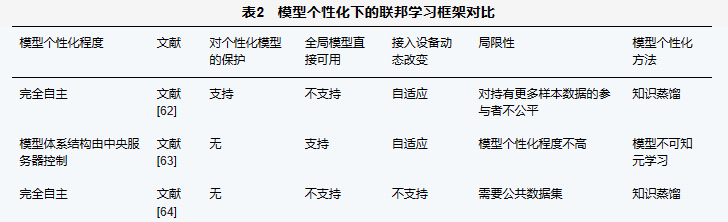
现有的模型个性化算法大多基于知识蒸馏实现,以完成不同模型间交换知识达成共识。表2展示了支持模型个性化的联邦学习框架对比分析,梳理了框架的异同点。
Liu等提出了一种允许客户独立定制模型和设计训练的联邦学习框架——联邦相互学习(FML, federated meta learning),其实现方式如图3所示。首先,训练3 个本地模型(私有模型和中间模型);其次,通过深度相互学习与中间模型交换知识(不同于师生模型,模型间不存在强弱关系,交换的方向也是双向的);随后,通过合并中间模型获取全局模型;最后,借助中间模型向私有模型传达联邦学习的知识。该方法可以让本地数据节点完全独立的设计不同于全局模型的私有模型,但同时会导致全局模型不再能开箱即用。
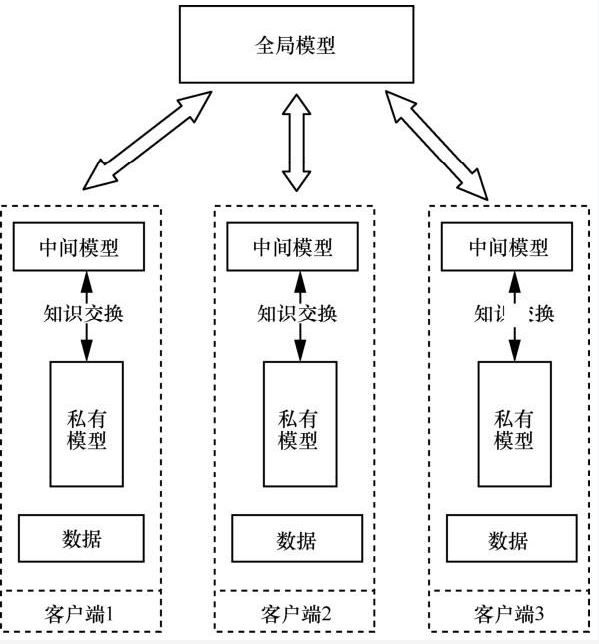
图3 FML实现方式
Ramanan 等使用迁移学习和知识蒸馏开发一个通用的支持本地节点自主设计模型的联邦学习框架。其假定参与方拥有较少的标准数据以及足量的公共数据集,借此联合学习一个分类任务,并提出 FedMD 算法:每个模型首先在公共数据方面进行充分的训练;然后,借助迁移学习,对自己少量的私有数据进行训练;随后,借助知识蒸馏将私有模型的知识转化为一个统一形式;最后,中央参数服务器收集这些转化后的知识,计算出共识。相比于传统联邦学习,不存在所谓的全局模型,只存在一个知识蒸馏结果的共识,也不支持新的参与方,因为新的参与方可能会破坏现有的模型。
Roy等论证了FedAvg也是一种元学习,并提出一种平均后悔上限分析框架,使联邦学习与元学习构建联系,让模型个性化成为可能。
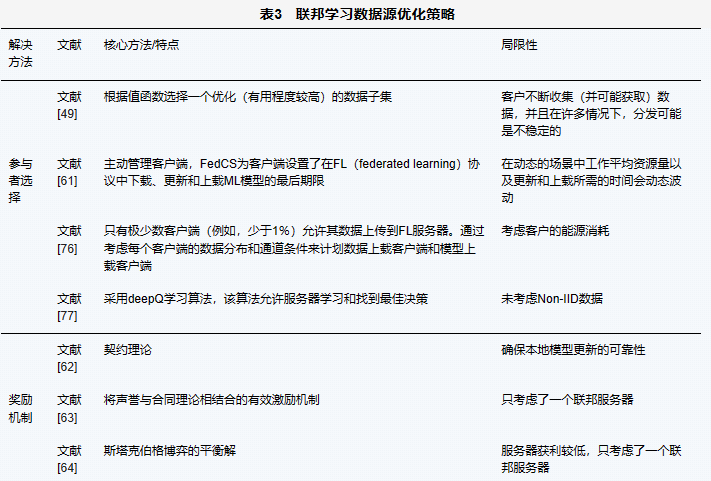
表3对现有的联邦学习数据源优化策略进行了对比总结。
3.2 通信传输优化
联邦学习中有2个必要的通信传输过程:数据节点传输本地数据训练后的模型参数至服务器,中心参数服务器传输全局调优后的参数/模型至各本地节点。在双向通信过程中,本地数据节点潜在的不可控网络状态(网络时延、通信费用等)容易导致通信成为联邦学习的瓶颈。
3.2.1 模型压缩与降低通信频次
针对通信这一任务本身,可以从降低通信频次和通信量方面进行优化。例如,AdaComm 自适应通信策略从低通信频率求平均值开始,以节省通信时延并提高收敛速度;增加通信频率以实现较低的错误率,实验证明其总体花费时间可减少到1/4。
从降低通信量考虑,可以进行通信数据压缩,包括上行压缩和下行压缩。因为上行的速率总是低于下行的速率,所以更多的研究关注上行压缩,部分研究同时压缩上行和下行。压缩可分为有损压缩和无损压缩,相较于无损压缩,有损压缩能大大提升压缩率,达到很好的压缩效果,但是有一定损耗。在保证收敛率和准确率的前提下,更多的研究偏向于有损压缩。在表4中,本文对各个压缩算法是否为有损压缩、是否有下行压缩、对非独立同分布(Non-IID, non independent and identically distributed)数据是否有稳健性以及压缩倍率等进行了分析和比较。
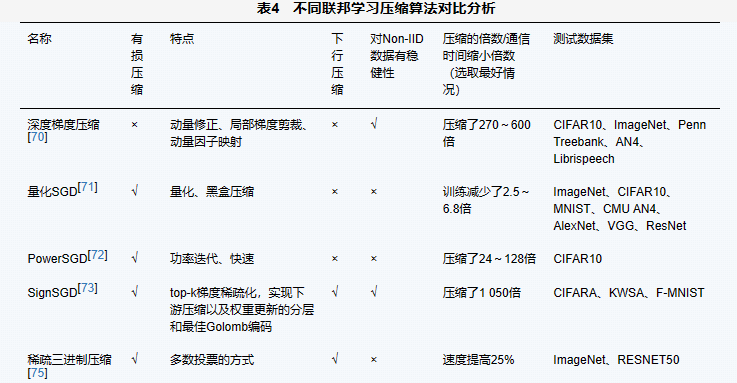
3.2.2 改变分布式体系结构
改变分布式体系结构也是优化计算节点间通信的有效方式之一。分布式体系结构包括对等、循环、服务器-客户端等。单中央服务器-多客户端的结构存在单点故障、主干网络开销过大等问题,可以利用对等架构解决。例如,对等网络结构下的联邦学习,其计算节点在有限通信的条件下,可以通过与相邻节点联合学习的方式解决通信瓶颈问题。相关研究主要集中在达成共识、协调构造全局模型、无中心模型聚合等方面。本节将去中心化的联邦学习框架根据其训练网络的结构划分为网型拓扑、树型拓扑、抽象总线拓扑,并总结讨论其模型聚合的方式及特点。
Savazzi 等为降低主干网络和中央服务器的通信开销,避免边缘设备长距离通信而导致训练时延,提出基于云边协同的联邦学习框架,其网络拓扑结构由传统的星形拓扑结构转化为树形结构,子树节点的层层聚合减少了主干网络的数据传输量。边缘云辅助的联邦学习架构如图4所示。边缘云聚合边缘网络下的本地节点的模型权重,中央云聚合边缘云的权重,其聚合函数是专门设置的HierFAVG函数。此方案仍存在中央服务器,所有边缘云聚合后才能进行云聚合,无法异步更新,降低了每轮聚合收敛的速度。
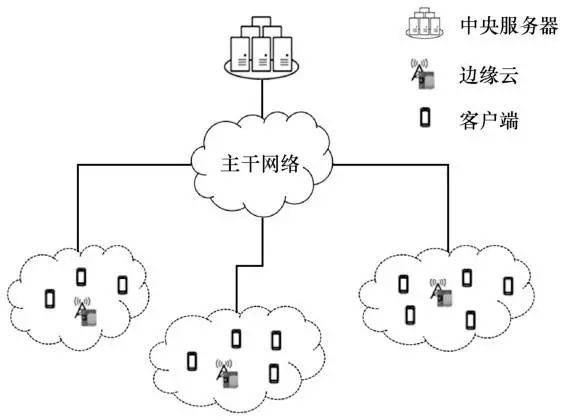
图4 边缘云辅助的联邦学习架构
Sattler等提出与区块链结合的去中心化联邦学习框架。利用抽象总线拓扑结构,各参与方构建一个区块链,基于区块链存取全局模型。区块链智能合约帮助训练网络的计算节点达成共识不借助中央服务器就完成全局模型聚合,具体包括:将全局模型权重向量划分为数个块数据,基于智能合约达成全局模型副本的共识,每个参与者投标训练区块上的块。该框架还有一个显著优势,就是借助区块链的记账特性,在区块链上推动计算,用户可以独立评估自己的成本效益比,并决定他们希望更新的块数,量化多方参与计算的绩效。但是,区块链块的数据大小限制会影响全局模型的划分,从而影响该方案性能。
Yoshida等提出了对等网络的去中心化联邦学习框架,解决参与方分担中央服务器聚合模型工作的问题。首先,随机选择一个节点开始广播,获取其他节点的权重、样本数和版本号,仅记录版本号大于自己的权重;其次,对权重进行加权平均,更新权重并增加版本号。此方案利用参与方充当某一轮的中央服务器角色,适合相互信任但又无法找出共识可靠第三方的场景。但是,该方案对节点的可靠性要求高,因为节点不仅承担一个轮次的权重更新工作,还会广播获取其他节点的样本数量和权重值,若存在恶意参与方,或者没有可靠的安全协议支撑,就会造成数据不可用甚至出现模型安全问题。
Kang 等提出了基于支持设备到设备(D2D,device-to-device)通信的 5G 网络进行去中心化联邦学习的框架及去中心化的模型聚合算法CFA-GE(consensus based federated averaging with gradients exchange)。利用5G网络环境,该方法更适合大规模密集和完全分散的网络,与以Mcmanhan等所提方法为代表的集中式深度学习方法形成鲜明对比。
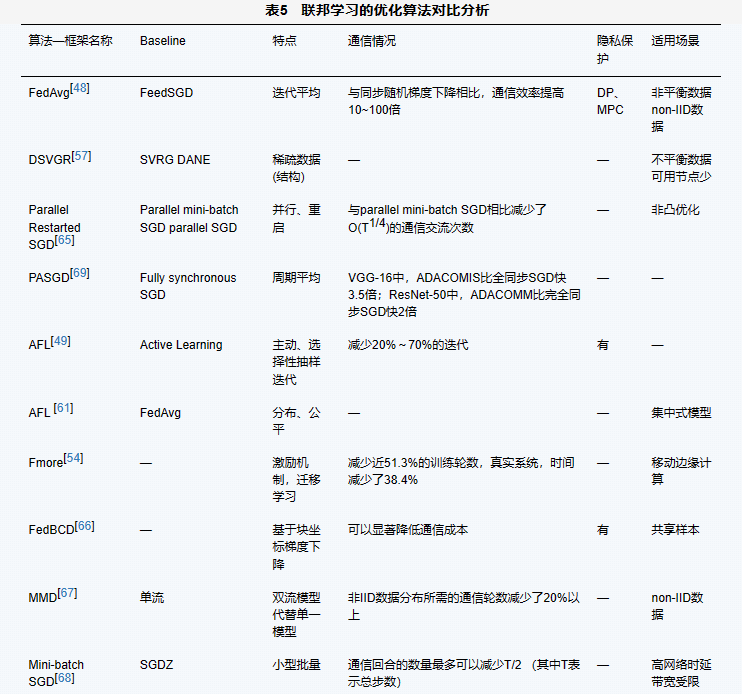
表5从算法的特点、隐私保护情况、适用场景等方面对部分联邦学习优化算法进行了对比分析。
4 面向隐私保护的非聚合式数据共享框架
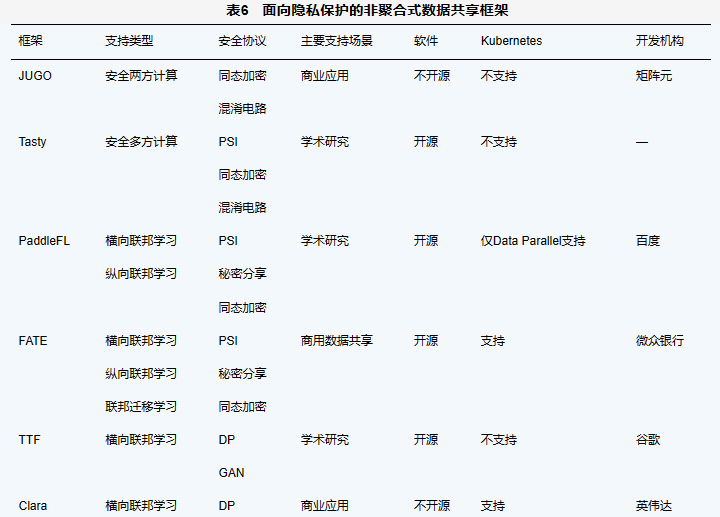
本节主要介绍支持隐私保护的非聚合式数据共享框架,包括安全多方计算平台 JUGO 及编译器Tasty、百度共享数据框架PaddleFL、微众银行FATE (federated AI technology enabler)、谷歌的 TFF (TensorFlow federated)以及英伟达Clara。表6对这些框架进行了总结对比,分析了其各自特性及适用的场景。
4.1 安全多方计算平台
2018 年计算架构服务提供商矩阵元发布了通用的安全多方计算平台JUGO,帮助用户快速开发通用半诚实的两方安全计算算法。JUGO架构如图5所示,算法模块主要集成了混淆电路、同态加密等底层协议,供MPC-SDK模块调用。当参与方间协同商定计算逻辑后,借助矩阵元开发的Frutta高级编程语言在MPC-IDE集成开发环境上编写实现,为上层的应用提供安全多方计算服务。最后,电路编译器把电路逻辑编译成电路文件。这些操作都可在 GPU、FPGA 等硬件加速下实现,使协同计算过程更快地完成。
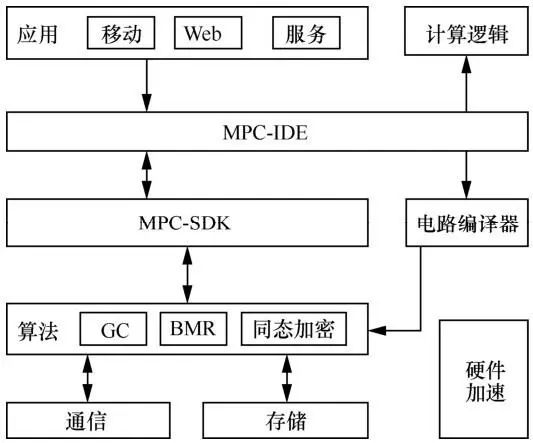
图5 矩阵元JUGO架构
此外,编译器 Tasty能自动生成高效的基于同态加密和混淆电路技术的组合协议,用户可以使用高级语言方便快速地描述该协议。Tasty 用于许多隐私保护协议,如PSI相关应用、人脸识别等。图6展示了其主要工作流程,包括:1) 分析阶段,运行时环境首先检查协议描述是否存在语法错误,协议两方是否在执行同一个协议,通过分析该协议自动确定哪方可以进行预计算;2) 设置阶段,可预计算的参与方提前计算协议中独立于它们输入的部分,如混淆电路的生成和发送等;3) 在线/执行阶段,各参与方提供自己的输入,协议的在线部分(加密、解密、电路评估等)开始执行,直到计算出各参与方相应的输出为止。
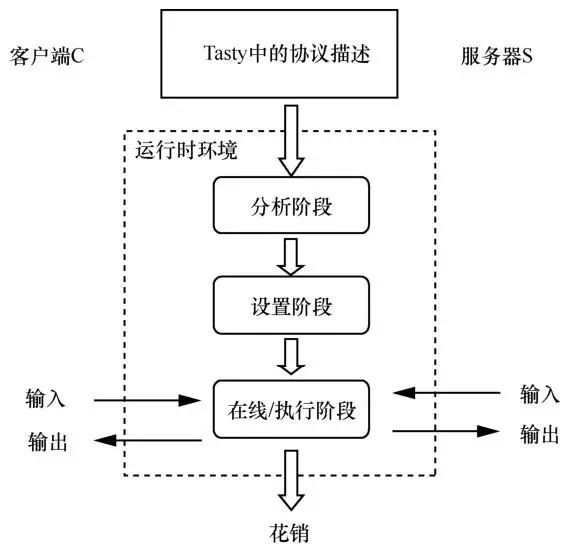
图6 Tasty工作流程
4.2 百度数据共享框架
PaddleFL是百度于2019年开源的联邦学习框架,主要提供2种联邦学习解决方案:Data Parallel和PFM(parallel federated learning with MPC)。
4.2.1 数据并行化
各数据方通过Data Parallel可以基于经典的横向联邦学习算法 FedAvg、DPSGD等完成模型训练。其服务架构如图7所示,分为编译阶段和运行阶段。
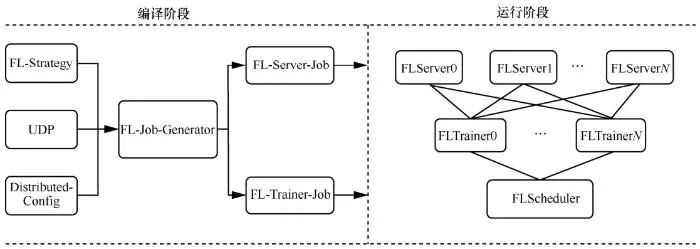
图7 数据并行化下的横向联邦学习服务架构
编译阶段包含以下4个主要部分。1) FL-Strategy。用户可以使用 FL-Strategy 定义联邦学习策略,如Fed-Avg。2) UDP(user-defined-program),为PaddleFL 程序,定义机器学习模型结构和训练策略,如多任务学习。3) Distributed-Config。联邦学习系统会部署在分布式环境中,需要对分布式训练进行配置并定义分布式节点信息。4) FL-Job-Generator。给定 FL-Strategy、UDP 和Distributed Training Config,生成联邦参数的服务器端和客户端的FL-Job。
运行阶段包含以下3个组件。1) FL-Server,在云或第三方集群中运行的联邦参数服务器。2) FL-Trainer,参与联邦学习的每个组织都将有一个或多个与参数服务器通信的客户端。3) FL-Scheduler,训练过程中调度客户端,在每个更新周期前,决定哪些客户端可以参与训练。
4.2.2 基于安全多方计算的联邦学习
作为PaddleFL的一个重要组成部分,PFM是基于多方安全计算实现的联邦学习方案。PFM可以很好地支持横向、纵向及联邦迁移学习等多个场景,既可提供可靠的安全性,也具有可观的性能。
PFM 中的安全训练和推理任务是基于高效的多方计算协议,如三方安全计算协议 ABY3 (three-party arithmetic-binary-Yao)。在ABY3中,参与方可分为输入方、计算方和结果方。输入方为训练数据及模型的持有方,负责加密数据和模型,并将其发送到计算方。计算方为训练的执行方,基于特定的多方安全计算协议完成训练任务,只能得到加密后的数据及模型。计算结束后,结果方会拿到计算结果并恢复出明文数据。每个参与方可充当多个角色,如一个数据拥有方也可以作为计算方参与训练。PFM的整个训练及推理过程如图8所示。其主要由 3个阶段组成:数据准备、安全训练/推理、结果解析。数据准备阶段包括私有数据对齐和数据加密及分发。首先,PFM通过PSI协议允许数据拥有方在不泄露自己数据的情况下,找出多方共有的样本集合。此功能主要支持纵向联邦学习,因为其要求多个数据方在训练前进行数据对齐,同时保护用户的数据隐私。其次,数据方将数据和模型用秘密共享的方法加密,然后用直接传输或者数据库存储的方式传到计算方。每个计算方只会拿到数据的一部分,因此计算方无法还原真实数据。
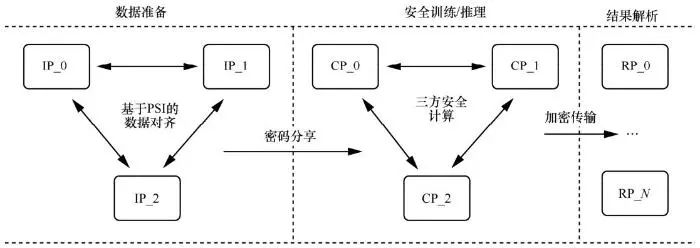
图8 PFM训练及推理过程(IP_i、CP_i以及RP_i分别表示数据或模型的拥有方、计算方以及结果获取方)
安全训练/推理阶段。PFM拥有与PaddleFL相同的运行模式。在训练前,用户需要定义 SMC 协议、训练模型以及训练策略。PaddleFL的多方安全计算模块提供了可以操作加密数据的算子,在运行时算子的实例会被创建并被执行器依次运行。
结果解析阶段。安全训练和推理工作完成后,模型(或预测结果)将由计算方以加密形式输出。结果方可以收集加密的结果,使用 PFM 中的工具对其进行解密,并将明文结果传递给用户。
4.3 微众银行数据共享框架
4.3.1 概述
FATE 是由微众银行开源的一款工业级的联邦学习框架,为用户提供保护隐私的分布式机器学习服务。FATE 涵盖联邦特征工程、联邦机器学习模型训练(FATE FederatedML)、联邦模型评估、联邦在线推理等。其中,FATE FederatedML是联邦学习算法功能组件,提供许多常见机器学习算法联邦化实现。其主要功能如图9所示,具体如下:联邦样本对齐,包括纵向样本 ID 对齐、基于 RSA+哈希等对齐方式;联邦特征工程,包括联邦采样、联邦特征分箱、联邦特征选择、联邦相关性、联邦统计等;联邦机器学习,包括联邦逻辑回归、线性回归、泊松回归、联邦 SecureBost、联邦 DN、联邦迁移学习等;多方安全计算协议,包括同态加密、秘密分享、RSA、Diffie-Hellman交换算法等。
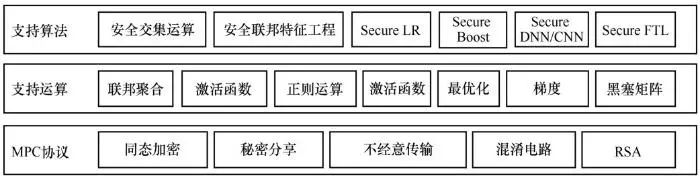
图9 FATE FederatedML主要功能
4.3.2 无损隐私保护系统
FATE 在实现纵向联邦学习时,为联邦学习环境下的模型训练提供一种称为 SecureBoost 的无损隐私保护 tree-boosting 系统。如图10 所示, SecureBoost在隐私约束下对数据进行对齐,协同学习共享gradient-tree boosting模型,同时对多个私有方的所有训练数据保密。FATE 利用基于隐私保护的样本 ID 匹配进行数据对齐。当数据垂直划分在多个参与方上时,不同的参与方持有不同但部分重叠的用户,这些用户可以通过其唯一的用户 ID来识别。为了在没有仲裁的情况下兼顾隐私并找到各方的共享用户或数据样本用户集的非共享部分, FATE 使用文献所提的隐私保护协议,在加密方案下寻找数据样本的用户交集。
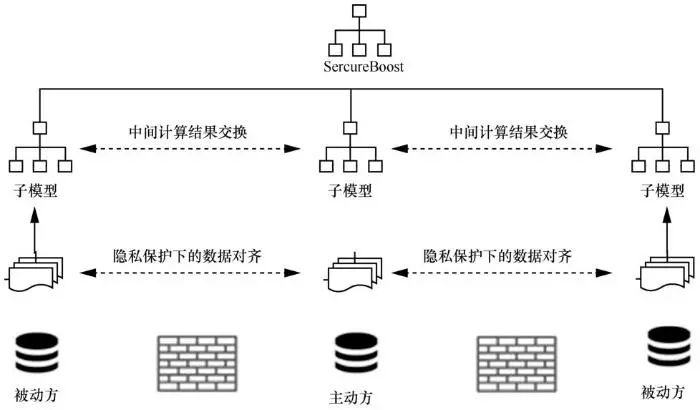
图10 SecureBoost框架
图11 描述了在纵向联邦学习时,隐私保护约束下的数据对齐流程,具体如下。
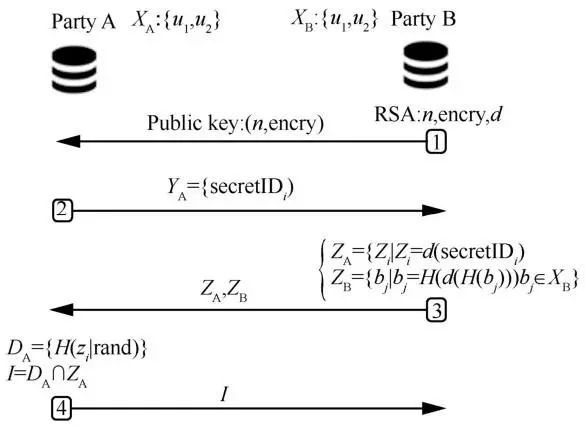
图11 FATE纵向联邦学习的数据对齐实现流程
1) B将公钥(n, encry)加密后传给A,建立加密通道。其中,n是公有密钥,encry是加密算法。
2) A通过哈希函数H逐个映射ui,并乘以加密后的随机噪声,然后将结果YA回传给B。
3) B解密后得到ZA,计算ZB,并将ZA和ZB回传给A。
4) A消除ZA中的随机噪声,然后进行一次哈希运算生成DA,再求ZA与DA的交集,最后A回传交集结果给B。
在多方安全训练阶段,FATE利用SecureBoost的模型,实质上是将梯度提升树学习算法XGBoost进行转换,使其适应联邦学习环境。分裂节点的选择和叶的最优权重计算仅取决于叶的g和h。其中, g和h分别是XGBoost损失函数的一阶导数和二阶导数。而 g、h 与分类标签存在关联,攻击方在一定条件下可以通过g和h恢复分类标签。由XGBoost特点可知,每个被动方(无标签数据的参与方)一旦获得g和h,仅用其本地数据就能够独立地确定局部最优分裂。因此,非联邦学习下活动方将g和h发送到每个被动方是可行的。但由于g和h可以用来获取分类标签信息,为了确保安全,联邦学习要求各被动方无法直接访问g和h,主动方(有标签数据的参与方)在将g和h发送给被动方之前要进行加密。随后,每个被动方使用加密的g和h确定局部最优分裂。被动方A使用由主动方B加密的g和h进行计算。其中,g和h在主动方B侧本地计算,B侧没有泄露样本分类标签;被动方A本地计算经加法同态加密后的梯度直方图,B解密梯度直方图,但是不知道具体对应的ID集合,保护了A侧ID集合隐私信息。
4.4 谷歌数据共享框架
4.4.1 概述
TFE是由谷歌开源的联邦学习框架,可用于对分散式数据进行机器学习和计算[91]。开发者可基于其模型和数据来模拟联邦学习算法并实验新算法。TFF提供的构建块也可用于实现非学习计算,例如对分散式数据进行聚合分析。TFF的接口可以分成两层:1) FL API,提供了一组高阶接口,开发者能够利用其联合训练和评估实现TensorFlow模型。2) FC(federated core)API,可以通过在强类型函数式编程环境中结合使用 TensorFlow 与分布式通信运算符,简洁地表达新的联合算法。这一层也是构建联合学习的基础。
TFF可用于模拟对联合学习系统的目标攻击和基于隐私的差异防御,使用潜在的恶意客户端构建一个迭代进程。同时,TFF还支持自定义的攻击方式,通过编写一个客户端更新函数来实现新的攻击算法。此外,新的防御方案可以通过定制状态聚合函数及聚合客户端输出以获得自定义安全全局更新策略。
4.4.2 隐私保护库
谷歌开源的TensorFlow Privacy是将差分隐私技术集成到诸如随机梯度下降的迭代训练过程中,提供了隐私保护Python库,以训练具有差异隐私的机器学习模型。引入模块化方法最大限度地减少对训练算法的更改,为隐私机制提供各种配置策略;隔离和简化关键逻辑解决了在隐私敏感数据集上训练机器学习模型的实际挑战。而TFF与TensorFlow Privacy隐私库是互操作的,可以支撑联邦训练算法的不同隐私模型,例如,支持基础的DP-FedAvg算法进行差分隐私训练。此外,TFF 还提供可扩展的隐私保护接口,可以实现自定义差分隐私算法并将其应用于联邦平均的参数更新。
TFF实现本地数据隐私保护的另一个重要方式是与生成式对抗网络(GAN, generative adversarial network)结合,如DP-FedAvg-GAN算法。Rangan等展示了DP-FedAvg-GAN算法下联邦学习、生成模型和差分隐私相结合的有效性。
4.5 英伟达医疗数据共享框架
NVIDIA Clara是一个医疗保健应用框架,用于人工智能成像、基因组学以及智能传感器的开发和部署。以服务器-客户端结构的联邦学习为特色,各数据持有方和中央服务器通过边缘 AI 计算平台NVIDIA EGX构建训练网络,实现支持隐私保护的智能计算。NVIDIA Clara作为一个商业应用产品,需基于英伟达的GPU硬件来获取服务。
联邦学习的中央服务器虽然通过适当地聚合客户端本地模型更新可以获得一个高精度的全局模型,但是共享的模型可能间接地泄露本地的训练示例。NVIDIA Clara云边协同的架构,可以通过控制站点的全局模型只共享部分模型权重,从而保护隐私,并且数据较少暴露在模型反转中。Paillier 等探讨了在联邦学习系统中应用差分隐私技术来保护病人资料的可行性。其实验结果表明,模型性能与隐私保护代价之间存在折中关系。
此外,为确保在客户机-服务器通信时数据和模型的安全性,Clara使用联合学习令牌来建立客户端和服务器之间的信任。联邦学习令牌会在整个联邦训练会话生命周期中使用。客户端需要验证服务器标识,服务器也需要验证客户端。客户端-服务器数据交换基于HTTPS协议进行安全通信。
5 挑战与展望
随着海量异构数据的日益增长,数据隐私保护问题迫在眉睫。非聚合式数据共享方法在数据分享模式基础上增强了隐私保护,降低数据泄露的风险。通过总结分析安全多方计算、联邦学习及非聚合式数据共享框架的发展,本文进一步提出了非聚合式数据共享领域在未来更为复杂的信息世界中面临的挑战和机遇。
5.1 复杂的多参与方场景
随着物联网和边缘计算的发展,智能设备能力不断提升,数据往往分布在多个节点上。而且,节点动态性强,可以自由加入和离开,导致多参与方情况更加复杂和不稳定。
由于安全多方计算协议复杂度高,传统的方法侧重研究两方参与场景,无法很好地拓展到多方环境。不能简单地将两方协议执行多次来达到多方计算,因为在简单重复两方协议的过程中,参与方会得到一些中间结果,而它本身是不能获知这些中间结果的。虽然有部分研究者针对这一问题展开研究,但还未能完全解决。例如,Wang 等提出让某参与方充当领导者,组织协议在多方之间执行,但无法很好地应对领导者是恶意节点的情况,而且领导者的选择也影响协议效率;Kolesnikov等借助不经意可编程的伪随机函数(OPPRF, oblivious evaluation of a programmable pseudorandom func-tion)的特性来完成多方计算,5个各有220个元素的参与者执行协议仅需72 s,但其实验选取的是较小数字或较短字符串等简单元素,不能很好地应对复杂场景。云计算给多参与方场景的安全计算带来了机遇,其强大的计算和存储能力可以用于支撑复杂的协议,但也存在一定挑战。首先,传统方法是针对数据存储在本地、计算执行在本地的特点而设计的,不能照搬到云环境中。其次,云中心节点一般被认为是半诚实的,需要对传输数据进行加密,而这个操作会导致数据拥有方难以在协议执行过程中对外包的数据集进行访问控制。因此,需要研究适应动态多参与方的安全计算协议,可以利用现有的一些高级密码学成果和边缘计算环境中的智能节点等,达到高效合理计算的目标。
参与方的增多也会影响联邦学习算法的准确性和性能。首先,管理和筛选合格的参与方需要额外的开销;其次,本地数据节点增多,其不同的数据分布会影响全局优化模型的效果。在最坏的情况下生成的联合模型并不比在单个节点上训练生成的模型好,在非独立同分布的数据情况下, FedAvg训练卷积神经网络的准确率会显著下降。改进的潜在方法包括增加并行性、增加本地节点的计算量、参与方聚类择优、模型自适应调整等。针对参与方的动态变化及应对短时间内参与方数量弹性增加/降低等情况,如何设计一个快速收敛且保证准确率的算法模型还需要进一步的研究。
5.2 性能优化与开销代价的平衡
为了增强数据隐私保护,需要复杂的协议和算法保证最低程度的数据泄露,但在实现过程中,则会造成系统开销增大。因此,如何平衡所需的优化性能和执行开销是十分重要的问题,关系到方案的实际应用拓展情况。
在安全多方计算领域,Pinkas等提出货币成本衡量标准,其表示PSI协议在云计算平台执行所带来的计算和通信开销,并根据该标准设计了2个半诚实对手安全协议,其中一个具有非常低的通信开销,另一个则在计算开销上表现出色,然而这 2种特性并未出现在同一个协议上。如何权衡计算和通信开销,在满足应用场景和用户隐私需求的情况下达到平衡,能否借助货币成本标准设计出更加折中的方案等,都是亟待解决的问题。
在联邦学习领域,其分布式架构存在多节点的数据交换过程,需要较好的通信带宽,多节点训练的拓展性也与其正相关。然而,在大型异构环境分布式训练中,本地数据节点常常会受到可用通信带宽和资源的限制。梯度压缩是解决这类问题的一种潜在的有效方法,但大多压缩算法采用近似编码表示内容,存在一定的信息损失,无法被广泛采用。其次,运行速度会受到影响,而且可能造成优化后的所有梯度聚集或无法达到相同的测试性能。因此,如何在保证算法准确度的前提下减少通信成本仍然需要进一步研究。
5.3 潜在安全问题
非聚合式数据共享虽然能保证源数据不在单点聚合,但仍面临一些潜在的安全问题。
虚假数据。攻击者可以冒充虚假参与方,提交模拟的数据,造成数据中毒的情况。在安全多方计算场景中,此方案可以用来攻击外包计算节点,消耗其资源,使真正参与方得不到公平的资源使用机会。在联邦学习场景中,虚假数据会严重影响全局优化模型的准确性,造成严重后果。针对这一问题,可以尝试从参与方认证、可靠性激励等方面提出解决方案。
架构安全性。安全多方计算中,由于加密后的数据需要传输交互,若一个参与方被攻破,则信息可能被泄露。如果攻击者获悉加密方法及部分真实数据信息,就能在一定程度上破解密文。安全多方计算的数据安全性取决于使用的加密方法和数据传输通道的安全性。联邦学习中参数服务器对本地数据及其训练过程是不可见的,攻击者可利用缺乏透明性对系统进行攻击。通过有目的或无目的的模型攻击,使训练过程中数据样本偏差不可察觉,影响全局模型的性能或操控模型偏向。如何确保本地数据节点提供诚实可信的训练,保证整个联邦学习流程的安全性仍然是一个难点。
5.4 隐私保护技术结合
随着学术界和工业界对数据隐私保护问题的重视,研究者致力于开发各种增强数据隐私保护的技术,如何结合现有的技术,针对不同的应用场景,提升整体系统的数据隐私保护能力,也是未来值得研究的方向。
生成对抗网络是一种深度神经网络结构,由Goodfellow等在2014年提出,它可以学习数据集分布,生成与数据集相似的逼真数据。利用GAN可以把同等特征的模拟数据发送给对方,而不泄露真实数据内容,保护源数据隐私。非聚合式数据共享方法主要强调数据共享的作用及其目标,若数据特征保留,则同样可以训练准确的模型。但现有的GAN相关研究缺乏对GAN模型的性能、可用性、生成样本的质量等方面的客观评价,导致模型的判定受一定主观因素的影响。其次,仍然存在训练过程不稳定、训练结果难以收敛、模式崩溃等问题, PPGAN、DPGAN虽在一定程度上有所改善,但仍有很大的优化空间。
本地差分隐私(LDP, local differential privacy)技术让数据所有者在发布数据之前对数据进行扰动,避免需要信任的第三方进行数据收集和处理,保护源数据隐私。该技术能够消除所增加的正、负噪声,并且基于预定义的查询来设计扰动机制,对指定的查询能得到准确的估计。但目前的查询类型比较单一,包括离散型数据的计数查询和连续型数据的均值查询,不支持其他类型的查询,如范围查询、最值查询等。其次,本地差分隐私对复杂数据类型研究的工作还不足,目前仅有文献等对图等复杂数据进行了研究,不能很好地处理具有边权或边属性的图,以及特定图的挖掘任务研究,如三角形计数和频繁的子图结构挖掘等。
联邦学习框架需要上传本地训练模型的参数至中央参数服务器,中央服务器结合全局信息进行调优操作后,再把优化后的参数信息返回给各本地节点。参数数据传输链路及中央参数调优计算可结合安全多方计算技术,保证参数信息交互过程中的隐私安全性。具体的技术选型、计算操作实现还需要结合联邦学习实际应用场景进行进一步的分析和优化。
6 结束语
随着数据量的迅速增多以及用户隐私保护需求的提高,传统的集中式获取全部数据的方式已不能很好地应对多方数据共享的场景,非聚合式数据共享有望成为主流。非聚合式数据共享在有效降低源数据隐私泄露风险的情况下,完成数据处理和挖掘的目标。本文简要介绍了主要的非聚合式数据共享方法的研究现状,首先,阐述早期非聚合式数据共享方法安全多方计算的相关技术,包括同态加密、不经意传输、秘密共享、隐私集合交集协议等。其次,从源数据节点和通信传输优化2个方面介绍近期的非聚合式数据共享研究热点联邦学习技术。此外,本文还对比分析了非聚合式数据共享框架,如百度PaddleFL、微众银行FATE、谷歌TFF等,给未来研究方案的实际构建和运行提供支撑。最后,本文提出了4个非聚合式数据共享领域面临的挑战和潜在研究方向。期望本文可以为研究人员快速全面地了解和掌握非聚合式数据共享领域的基本现状和研究发展提供参考和帮助。
作者简介
李尤慧子(1989−),女,河南新蔡人,博士,杭州电子科技大学副教授,主要研究方向为边缘计算、隐私安全、移动互联网计算、高能效系统 。
殷昱煜(1980−),男,重庆人,博士,杭州电子科技大学教授,主要研究方向为边缘计算、服务计算、大数据分析、软件形式化方法等 。
高洪皓(1985−),男,浙江临海人,博士,上海大学副教授、韩国嘉泉大学教授,主要研究方向为软件形式化验证、服务协同计算、无线网络和工业物联网、智能医学影像处理等 。
金一(1982−),女,河北石家庄人,博士,北京交通大学教授、博士生导师,主要研究方向为机器学习与认知计算、人工智能及应用、图像感知与识别 。
王新珩(1968−),男,山东平度人,博士,西交利物浦智能工程学院教授、博士生导师,主要研究方向为物联网、室内定位、智能化服务和智慧城市 。
联系我们:
Tel:010-81055448
010-81055490
010-81055534
E-mail:bdr@bjxintong.com.cn
http://www.infocomm-journal.com/bdr
http://www.j-bigdataresearch.com.cn/
转载、合作:010-81055307
大数据期刊
《大数据(Big Data Research,BDR)》双月刊是由中华人民共和国工业和信息化部主管,人民邮电出版社主办,中国计算机学会大数据专家委员会学术指导,北京信通传媒有限责任公司出版的期刊,已成功入选中文科技核心期刊、中国计算机学会会刊、中国计算机学会推荐中文科技期刊,以及信息通信领域高质量科技期刊分级目录、计算领域高质量科技期刊分级目录,并多次被评为国家哲学社会科学文献中心学术期刊数据库“综合性人文社会科学”学科最受欢迎期刊。

关注《大数据》期刊微信公众号,获取更多内容


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









