









1、简介
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。列表的数据项不需要具有相同的类型。
2、列表常见操作
2.1创建一个列表
list = []
list1 = ['physics', 'chemistry', 1997, 2000] #元素有字符串,数字类型
list2 = [1, 2, 3, 4, 5 ] #元素都是数字类型
list3 = ["a", "b", "c", "d"] #元素都是字符串类型
2.2往列表中添加元素
使用:list.append(obj),在列表末尾添加新的对象
>>> list=[]
>>> list.append('red')
>>> list
['red']
>>> list.append('yellow')
>>> list
['red', 'yellow']
>>> list.append('blue')
>>> list
['red', 'yellow', 'blue']
2.3访问列表中的元素
使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符
>>> list=['1','5','7','6','6','5','0','7','6','9','2']
>>> list[0]
'1'
>>> list[-1]
'2'
>>> list[0:3]
['1', '5', '7']
>>> list[:-2]
['1', '5', '7', '6', '6', '5', '0', '7', '6']
#循环遍历列表中的每一个元素
list=['1','5','7','6','6','5','0','7','6','9','2']
for x in list:
print(x,end=' ')
#结果:1 5 7 6 6 5 0 7 6 9 2
注意:使用列表截取字符串,对于下标中的元素,取前不取后。如:list[0:3],list[0]—>1,list[3]----->6,然而list[0:3]是取到下标3前面的元素,不包含下标3的元素。
2.4获取列表最大值、最小值、长度
使用python内置函数:max(list)、min(list)、len(list)
>>> list=['1','5','7','6','6','5','0','7','6','9','2']
>>> max=max(list) #获取列表中最大值
>>> max
'9'
>>> min=min(list) #获取列表中最小值
>>> min
'0'
>>> lenth=len(list) #获取列表的长度
>>> lenth
11
2.5对列表进行排序
使用列表自带的排序方法或自己写一个排序算法
>>> list=['1','5','7','6','6','5','0','7','6','9','2']
>>> list.sort() #列表自带的排序方法,默认升序
>>> list
['0', '1', '2', '5', '5', '6', '6', '6', '7', '7', '9']
>>> list.sort(reverse=True) #如果将参数reverse设置为True,则列表按降序排列
>>> list
['9', '7', '7', '6', '6', '6', '5', '5', '2', '1', '0']
思考1:如果是字符型元素,该如何比较大小呢?
如:list=[‘b’,‘c’,‘a’,‘z’,‘g’,‘k’],这个列表如何排序
原理:根据字符对应的ASCII码值比较大小,以下是26个英文字母对应的ASCII码值
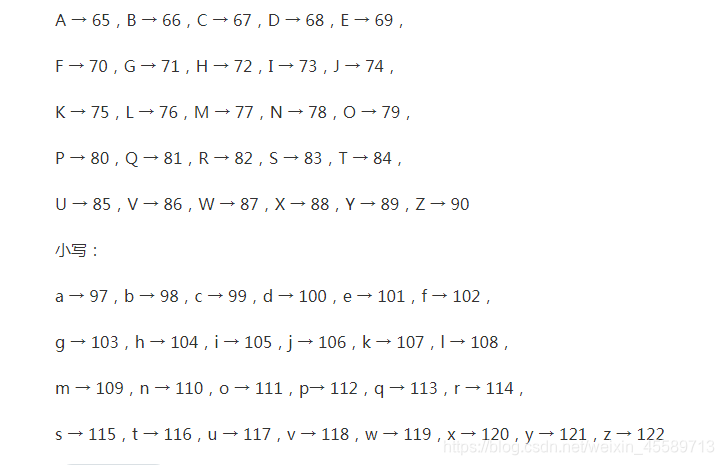
>>> list=['b','c','a','z','g','k']
>>> ord(list[2]) #字符转ascii数字
97
>>> chr(97) #数字转字符
'a'
>>> list.sort()
>>> list
['a', 'b', 'c', 'g', 'k', 'z']
思考2:如果是字符串,该如何比较大小呢?
答:字符串的比较是比较ASCII码值。从字符串的第一个字符开始比较,谁的ASCII码大谁就大。如果第一个相同,则比较第二个。以此类推。如果都相同则相等。
解析:第一步比较:b<r<y;第二步比较:a<e
>>> list=['red', 'yellow', 'blue','yallow']
>>> list.sort()
>>> list
['blue', 'red', 'yallow', 'yellow']
#参考例子
print(max(['1', '2', '3'])) # 3
print(max(['31', '2', '3'])) # 31
print(max(['13', '2', '3'])) # 3
2.6对列表中的字典元素进行排序
如:rows=[{‘日期’: ‘2018-09-04’, ‘测试1’: ‘50.00 %’, ‘测试2’: ‘100.00%’},
{‘日期’: ‘2018-09-05’, ‘测试1’: ‘100.00%’, ‘测试2’: ‘无执行’},
{‘日期’: ‘2018-09-06’, ‘测试1’: ‘100.00%’, ‘测试2’: ‘100.00%’},
{‘日期’: ‘2018-08-31’, ‘测试1’: ‘无执行’, ‘测试2’: ‘无执行’},
{‘日期’: ‘2018-09-01’, ‘测试1’: ‘无执行’, ‘测试2’: ‘无执行’},
{‘日期’: ‘2018-09-02’, ‘测试1’: ‘无执行’, ‘测试2’: ‘无执行’},
{‘日期’: ‘2018-09-03’, ‘测试1’: ‘无执行’, ‘测试2’: ‘无执行’}]
方式1:使用list.sort()方式
rows=[{'日期': '2018-09-04', '测试1': '50.00 %', '测试2': '100.00%'},
{'日期': '2018-09-05', '测试1': '100.00%', '测试2': '无执行'},
{'日期': '2018-09-06', '测试1': '100.00%', '测试2': '100.00%'},
{'日期': '2018-08-31', '测试1': '无执行', '测试2': '无执行'},
{'日期': '2018-09-01', '测试1': '无执行', '测试2': '无执行'},
{'日期': '2018-09-02', '测试1': '无执行', '测试2': '无执行'},
{'日期': '2018-09-03', '测试1': '无执行', '测试2': '无执行'}]
def function(date):
print(date['日期'],end=' ')
return date['日期']
rows.sort(key=function)
print(" ")
print(rows)
#结果:
2018-09-04 2018-09-05 2018-09-06 2018-08-31 2018-09-01 2018-09-02 2018-09-03
[{'日期': '2018-08-31', '测试1': '无执行', '测试2': '无执行'}, {'日期': '2018-09-01', '测试1': '无执行', '测试2': '无执行'}, {'日期': '2018-09-02', '测试1': '无执行', '测试2': '无执行'}, {'日期': '2018-09-03', '测试1': '无执行', '测试2': '无执行'}, {'日期': '2018-09-04', '测试1': '50.00 %', '测试2': '100.00%'}, {'日期': '2018-09-05', '测试1': '100.00%', '测试2': '无执行'}, {'日期': '2018-09-06', '测试1': '100.00%', '测试2': '100.00%'}]
方式2:使用sorted方式
rows=[{'日期': '2018-09-04', '测试1': '50.00 %', '测试2': '100.00%'},
{'日期': '2018-09-05', '测试1': '100.00%', '测试2': '无执行'},
{'日期': '2018-09-06', '测试1': '100.00%', '测试2': '100.00%'},
{'日期': '2018-08-31', '测试1': '无执行', '测试2': '无执行'},
{'日期': '2018-09-01', '测试1': '无执行', '测试2': '无执行'},
{'日期': '2018-09-02', '测试1': '无执行', '测试2': '无执行'},
{'日期': '2018-09-03', '测试1': '无执行', '测试2': '无执行'}]
rows=sorted(rows,key=lambda keys:keys['日期'])
print(rows)
#结果:[{'日期': '2018-08-31', '测试1': '无执行', '测试2': '无执行'}, {'日期': '2018-09-01', '测试1': '无执行', '测试2': '无执行'}, {'日期': '2018-09-02', '测试1': '无执行', '测试2': '无执行'}, {'日期': '2018-09-03', '测试1': '无执行', '测试2': '无执行'}, {'日期': '2018-09-04', '测试1': '50.00 %', '测试2': '100.00%'}, {'日期': '2018-09-05', '测试1': '100.00%', '测试2': '无执行'}, {'日期': '2018-09-06', '测试1': '100.00%', '测试2': '100.00%'}]
3、案例实战
描述:统计文本test-data.txt中分词出现频次前三的分词
test-data.txt文件见附件
#导入需要的包
import jieba
import os
filetext=open('test-data.txt','r',encoding='GBK').read()
#使用精简模式进行文本分词
word_lists=jieba.lcut(filetext)
#将分词与频次存入字典中
word_dict={}
for word in word_lists:
if len(word)==1: #一个字的不统计
continue
else:
word_dict[word]=word_dict.get(word,0)+1
print(word_dict)
#按频次对字典进行排序{'大家': 3, '带来': 1, '价值': 1, '第四': 1}
toplist=sorted(word_dict.items(),key=lambda x:x[1],reverse=True)
print(toplist)
#取频次前3,将字典存储在列表中
for i in range(3):
word,count=toplist[i]
print(word,'--->',count)
#结果如下:
{'大家': 3, '带来': 1, '价值': 1, '第四': 1, '希望': 2, '得到': 1, '什么样': 1, '支持': 1, 'eg': 1, '贫僧': 1, '玄奘': 1, '东土': 1, '大唐': 1, '去往': 1, '西天': 1, '取经': 1, '以求': 1, '普度众生': 1, '早日': 1, '发放': 1, '通关': 1, '文牒': 1, '2019': 4, '12': 1, '刘步蟾': 1 ...}
[('2019', 4), ('大家', 3), ('最好', 3), ('什么', 2), ('希望', 2), ('学习', 2), ('框架', 2), ('英语', 2), ('沙龙', 2), ('人生', 2), ('太闲', 2), ('太忙', 2), ('一个', 2), ('不是', 2), ('永远', 2), ('10.3', 1), ('如何', 1), ('做好', 1)...]
2019 ---> 4
大家 ---> 3
最好 ---> 3














 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









