








一、数据库定义操作
1、创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
LOCATION :设置表数据保存路径
DBPROPERTIES :设置参数
2、查询数据库
SHOW DATABASES;
SHOW DATABASES LIKE 'db_*' # 过滤查询
3、查看数据库详情
DESC DATABASES db_name;
DESC DATABASES EXTENDED db_name; # 显示数据库详细信息
4、切换当前工作数据库
USE db_name;
5、修改数据库(属性值)
ALTER DATABASES db_name SET DBPROPERTIES("key", "value");
6、删除数据库
DROP DATABASE [IF EXISTS] db_name [CASCADE];
CASCADE :如果数据库不为空,使用命令强制删除
7、创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment],
...
)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
[LIKE table_name]
[ROW FORMAT row_format]:
ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] # 字段分割符
[COLLECTION ITEMS TERMINATED BY char] # 集合字段内分隔符
[MAP KEYS TERMINATED BY char] # Map类型数据,k-v分割符
[LINES TERMINATED BY char] # 行数据分割符号
|
ROW FORMAT SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, ...)]
# 单独指定 Serialize/Deserilize (序列化/反序列化)方式
[STORED AS file_format]:数据文件存储格式:textfile、sequencefile、rcfile、orcfile
[LIKE table_name]:根据已存在的表建表,只包含结构
8、查询表类型
DESC FORMATTED table_name;
9、删除表
DROP TABLE table_name;
10、内部表&外部表(EXTERNAL) 转换
ALTER TABLE table_name1 SET TBLPROPERTIES('EXTERNAL'='TRUE');
ALTER TABLE table_name1 SET TBLPROPERTIES('EXTERNAL'='FALSE');
11、重命名表
ALTER TABLE table_name RENAME TO new_table_name;
12、增加、修改和删除表分区
详见分区表
13、增加、修改和替换列信息
ALTER TABLE table_name ADD COLUMNS ( col_name data_type [COMMENT col_comment], ... )
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
ALTER TABLE table_name REPLACE COLUMNS ( col_name data_type [COMMENT col_comment], ... )
ADD:表示新增字段
CHANGE :修改字段名称、类型、描述
[FIRST|AFTER column_name]:修改字段的位置,首置位、某字段之后
REPLACE:替换原表所有字段
二、数据操作
清除表中数据(Truncate)
truncate table table_name;
注意:Truncate只能删除管理表,不能删除外部表中数据
1、数据导入
1) 向表中装载数据(Load)
hive> load data [local] inpath '数据的path' [overwrite] into table table_name[partition (partcol1=val1,…)];
[local]:表示从本地加载数据到hive表,否则从hdfs加载数据到hive表
3) 通过查询语句向表中插入数据(Insert)
INSERT into|overwrite TABLE table_name1
SELECT col_name1,... FROM table_name2 ;
INSERT:不支持插入部分字段
into|overwrite:追加 或 覆盖
4) 多表(多分区)插入模式(根据多张表查询结果)
FROM table_name2
INSERT into|overwrite TABLE table_name1 PARTITION(partition_col = 'value1')
SELECT col_name1,... WHERE partition_col = 'value1'
INSERT into|overwrite TABLE table_name1 PARTITION(partition_col = 'value2')
SELECT col_name1,... WHERE partition_col = 'value2';
5) 查询语句中创建表并加载数据(As Select)
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name1
AS SELECT col_name1,... FROM table_name2
6) Import数据到指定Hive表中
hive> import table table_name from 'hdfs文件路径';
import:需要使用export导出的数据
2、数据导出
1) Insert导出
# 将查询的结果导出
hive> insert overwrite [local] directory 'local路径'
[ROW FORMAT row_format] # 数据格式化
select *|col_name,... from table_name;
[local]:将结果到处到local本地,否则导出至HDFS
[ROW FORMAT row_format]:参照创建表 格式化方式
2) Hive Shell 命令导出
[root@local hive]$ bin/hive -e 'select * from default.table_name;' >
/local/hive/datas/export/文件名.txt;
基本语法:hive -f/-e 执行语句或者脚本 > file
3) Export导出到HDFS上
hive> export table db_name.table_name to 'HDFS目录路径';
ps:export和import主要用于两个Hadoop平台集群之间Hive表迁移。
三、查询
1、基本查询
SELECT [ALL | DISTINCT] select_expr [[AS] 别名], ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list [ASC | DESC]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
[LIMIT [offset,]rows]:LIMIT子句用于限制返回的行数
注意:
(1)SQL 语言大小写不敏感。
(2)SQL 可以写在一行或者多行
(3)关键字不能被缩写也不能分行
(4)各子句一般要分行写。
(5)使用缩进提高语句的可读性。
2、算术运算符
| 运算符 | 描述 |
|---|---|
| A+B | A和B 相加 |
| A-B | A减去B |
| A*B | A和B 相乘 |
| A/B | A除以B |
| A%B | A对B取余 |
| A&B | A和B按位取与 |
| A|B | A和B按位取或 |
| A^B | A和B按位取异或 |
| ~A | A按位取反 |
示例:
select sal+1 from emp;
3、比较运算符(Between/In/ Is Null)
注意:这些操作符同样可以用于JOIN…ON和HAVING语句中
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回TRUE,反之返回FALSE |
| A<=>B | 基本数据类型 | 如果A和B都为NULL,则返回TRUE,如果一边为NULL,返回False |
| A<>B, A!=B | 基本数据类型 | A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
| A<B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
| A<=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
| A>B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
| A>=B | 基本数据类型 | A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS NULL | 所有数据类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE |
| A IS NOT NULL | 所有数据类型 | 如果A不等于NULL,则返回TRUE,反之返回FALSE |
| IN(数值1, 数值2) | 所有数据类型 | 使用 IN运算显示列表中的值 |
| A [NOT] LIKE B | STRING 类型 | B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
| A RLIKE B, A REGEXP B | STRING 类型 | B是基于java的正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
4、Like和RLike
- 使用LIKE运算选择类似的值
- 选择条件可以包含字符或数字:
% 代表零个或多个字符(任意个字符)。
_ 代表一个字符。 - RLIKE子句
RLIKE子句是Hive中这个功能的一个扩展,其可以通过Java的正则表达式这个更强大的语言来指定匹配条件。
示例:
# 查找名字中带有A-N的员工信息
select * from emp where ename RLIKE '[A-N]';
5、逻辑运算符(And/Or/Not)
| 操作符 | 含义 |
|---|---|
| AND | 逻辑并 |
| OR | 逻辑或 |
| NOT | 逻辑否 |
四、分组
1、Group By语句
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
示例:
# 计算雇员表每个部门的平均工资
select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
2、Having 语句
having与where不同点:
(1)where后面不能写分组函数,而having后面可以使用分组函数(可以使用分组聚合后的字段进行过滤)。
(2)having只用于group by分组统计语句。
示例:
# 每个部门的平均薪水大于2000的部门
select deptno, avg(sal) avg_sal from emp group by deptno having
avg_sal > 2000;
五、Join语句
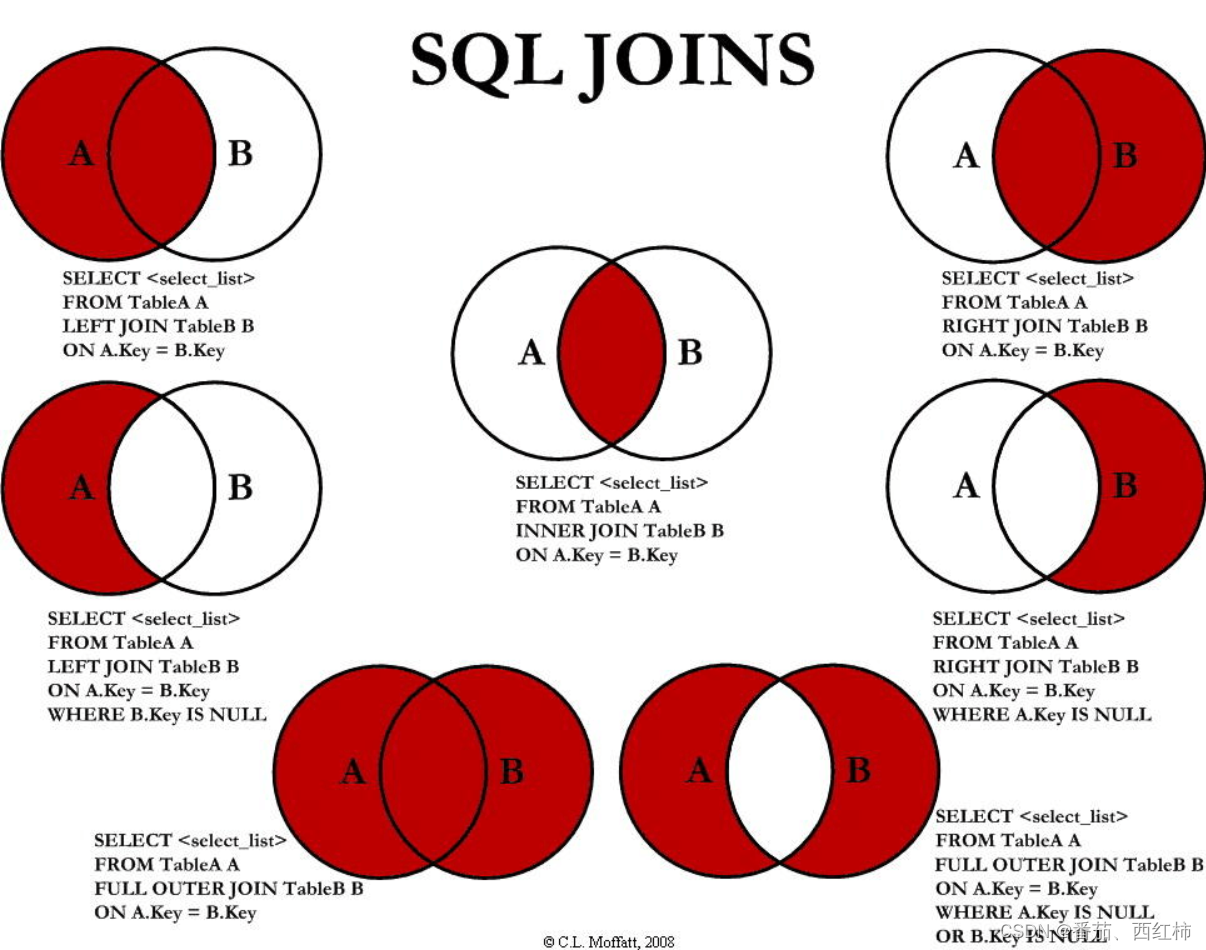
笛卡尔积:产生条件:
(1)省略连接条件
(2)连接条件无效
(3)所有表中的所有行互相连接
ps:连接查询时表别名的好处:
(1)使用别名可以简化查询。
(2)使用表名前缀可以提高执行效率。
六、排序
1、全局排序(Order By)
注意:Order By 全局排序,只有一个Reducer
ASC(ascend): 升序(默认)
DESC(descend): 降序
2、每个Reduce内部排序(Sort By)
Sort By:对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用sort by。
Sort by为每个reducer产生一个排序文件。每个Reducer内部进行排序,对全局结果集来说不是排序。
示例:
# 根据部门编号降序查看员工信息
select * from emp sort by deptno desc;
ps:
1)设置reduce个数
hive (default)> set mapreduce.job.reduces=3;
2)查看设置reduce个数
hive (default)> set mapreduce.job.reduces;
3)将查询结果导入到文件中(按照部门编号降序排序)
hive (default)> insert overwrite local directory
'/local/datas/sortby-result'
select * from emp sort by deptno desc;
3、分区(Distribute By)
Distribute By: 在有些情况下,需要控制某个特定行应该到哪个reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by类似MR中partition(自定义分区),进行分区,结合sort by使用。
注意:
- distribute by的分区规则是对每条数据根据分区字段值的hash码与reduce的个数进行模除后,余数相同的分到一个区。
- Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
示例:
hive (default)> set mapreduce.job.reduces=3;
hive (default)> insert overwrite local directory '/local/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
ps:对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
4、Cluster By
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
select * from emp cluster by deptno;
select * from emp distribute by deptno sort by deptno;
七、分区表和分桶表
1、分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
# 创建分区表语法
create table partition_table(
col_name data_type [COMMENT col_comment],...
)
partitioned by (partition_col_name data_type );
注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列,可通过伪列查询。并且分区表加载数据时(load…),必须指定分区。
1) 增加分区
ALTER TABLE partition_table add partition(partition_col_name1="分区") [partition(partition_col_name2="分区")]...;
2) 删除分区
ALTER TABLE partition_table drop partition(partition_col_name1="分区") [partition(partition_col_name2="分区")]...;
3) 查看表分区
show partitions partition_table;
4) 查看分区表结构
desc formatted partition_table;
2、二级分区
create table partition_table(
col_name data_type [COMMENT col_comment],...
)
partitioned by (partition_col_name1 data_type, partition_col_name1 data_type);
3、动态分区
关系型数据库中,对分区表Insert数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive中也提供了类似的机制,即动态分区(Dynamic Partition),只不过,使用Hive的动态分区,需要进行相应的配置。
开启动态分区参数设置
(1)开启动态分区功能(默认true,开启)
hive.exec.dynamic.partition=true
(2)设置为非严格模式(动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。)
hive.exec.dynamic.partition.mode=nonstrict
(3)在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认1000
hive.exec.max.dynamic.partitions=1000
(4)在每个执行MR的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
hive.exec.max.dynamic.partitions.pernode=100
(5)整个MR Job中,最大可以创建多少个HDFS文件。默认100000
hive.exec.max.created.files=100000
(6)当有空分区生成时,是否抛出异常。一般不需要设置。默认false
hive.error.on.empty.partition=false
# 示例
# partition(loc) 标识动态分区的字段 loc
insert into table dept_table partition(loc) select deptno, dname, loc from dept;
4、把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
1) 方式一:上传数据后修复
示例:
# 上传数据
hive > dfs -mkdir -p
/user/hive/mydb/dept_table/day=20200401/hour=13;
hive > dfs -put /local/datas/dept_20200401.log /user/hive/mydb/dept_table/day=20200401/hour=13;
#(查询不到刚上传的数据)执行修复命令
hive > msck repair table dept_table;
# 查询数据
hive > select * from dept_table where day='20200401' and hour='13';
- 方式二:上传数据后添加分区
# 上传数据
hive > dfs -mkdir -p
/user/hive/mydb/dept_table/day=20200402/hour=14;
hive > dfs -put /local/datas/dept_20200402.log /user/hive/mydb/dept_table/day=20200402/hour=14;
# 执行添加分区
hive > alter table dept_table add partition(day='20200402',hour='14');
# 查询数据
hive > select * from dept_table where day='20200402' and hour='14';
3) 方式三:创建文件夹后load数据到分区
# 创建目录
hive > dfs -mkdir -p
/user/hive/mydb/dept_table/day=20200403/hour=15;
# 上传数据
hive > load data local inpath '/local/datas/dept_20200403.log' into table
dept_table partition(day='20200403',hour='12');
# 查询数据
hive > select * from dept_table where day='20200403' and hour='15';
5、分桶表
对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径;分桶针对的是数据文件。
# 创建分桶表(通过id字段分桶,共分 4 buckets)
create table bucket_table(id int, name string)
clustered by(id)
into 4 buckets
分桶规则:Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方 式决定该条记录存放在哪个桶当中
注意事项:
(1)reduce的个数设置为-1,让Job自行决定需要用多少个reduce或者将reduce的个数设置为大于等于分桶表的桶数
(2)从hdfs中load数据到分桶表中,避免本地文件找不到问题
(3)不要使用本地模式(考虑到资源问题,防止MR执行失败)
6、抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行抽样来满足这个需求。
# 查询时使用 TABLESAMPLE(BUCKET x OUT OF y ON 分桶字段)
select * from bucket_table tablesample(bucket 1 out of 4 on id);
注意:x的值必须小于等于y的值,否则报错!!!
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
八、函数
1、系统内置函数
# 查看系统自带的函数
show functions;
# 显示自带的函数的用法
desc function upper;
# 详细显示自带的函数的用法
desc function extended upper;
2、常用内置函数
1) 空字段赋值
NVL( value,default_value)
2) CASE WHEN 选择分支
CASE
WHEN 条件表达式1 THEN 为True时返回
[WHEN 条件表达式2 THEN 为True时返回 ...]
[ELSE 为False时返回]
END
3) 行转列
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
注意: CONCAT_WS must be "string or array
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
4) 列转行
将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW udtf(expression) tableAlias AS columnAlias
# 用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
# SPLIT(col,""):将一个字段值按照指定字符进行拆分,返回array
# EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
示例:
# 示例数据
# movie category
# 《Lie to me》 悬疑,警匪,动作,心理,剧情
# 执行查询
SELECT movie,category_name
FROM movie_info
LATERAL VIEW explode(split(category,",")) movie_info_tmp AS category_name ;
# 查询结果
# movie category_name
# 《Lie to me》 悬疑
# 《Lie to me》 警匪
# 《Lie to me》 动作
# 《Lie to me》 心理
# 《Lie to me》 剧情
5) 窗口函数(开窗函数)
窗口函数(个人理解):在不影响整体查询结果的情况下,单独开辟一个窗口用于计算,并将计算结果作为一个字段添加到每一条记录中。
在计算过程中可以选择对于每一条记录用于计算的窗口范围。窗口内可进行分区或排序。
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的改变而变化。
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING表示到后面的终点
LAG(col,n,default_val):往前第n行数据
LEAD(col,n, default_val):往后第n行数据
NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
6)Rank
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









