







场景:数据库已存在三张表(包含一张中间表),代码已对应建立三个实体,现通过JPA方式进行对对多联表查询
简化之后的表结构如下,表名和实体的对应关系在下面,具体的属性与实际意义见下面的tostring方法,就不赘述了
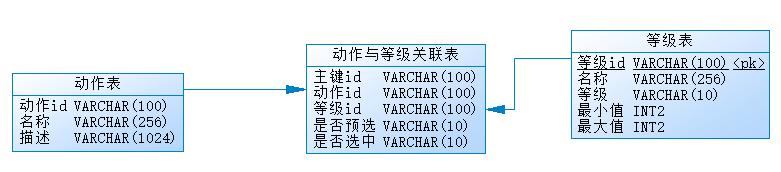
等级表实体RiskSegment(t_risk_segment)、关联表实体RiskActionSegmentMapping(t_risk_action_r_segment)、动作表实体DisposalAction(t_risk_disposal_action)。
要通过JPA实现多表查询,在不考虑自定义sql的情况下,使用Specification实现,首先在实体类上增加onetomany,manytoone的配置。
在RiskSegment上增加一对多配置
//targetEntity 指明集合类中保存的具体类型 ,mappedBy的值应该为RiskActionSegmentMapping中“一”那方的对象
//json序列化时忽略此属性,序列化和反序列化都受影响(貌似这个配置没起作用)
@OneToMany(targetEntity = RiskActionSegmentMapping.class, mappedBy = "riskSegment")
@JsonIgnore
private List<RiskActionSegmentMapping> riskActionSegmentMappings;
//重写tostring方法,去掉 List<RiskActionSegmentMapping>,避免循环调用导致栈溢出
@Override
public String toString() {
return "RiskSegment{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", level='" + level + '\'' +
", min=" + min +
", max=" + max +
'}';
}
在DisposalAction上增加一对多配置
//targetEntity 指明集合类中保存的具体类型 ,mappedBy的值应该为为RiskActionSegmentMapping中“一”那方的对象
//json序列化时忽略此属性,序列化和反序列化都受影响(貌似这个配置没起作用)
@OneToMany(targetEntity = RiskActionSegmentMapping.class, mappedBy = "disposalAction")
@JsonIgnore
private List<RiskActionSegmentMapping> riskActionSegmentMappings;
//重写tostring方法,去掉 List<RiskActionSegmentMapping>,避免循环调用导致栈溢出
@Override
public String toString() {
return "DisposalAction{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", describe='" + describe + '\'' +
'}';
}
在RiskActionSegmentMapping上增加两个多对一的配置
//targetEntity 指明保存的具体类型
//name是另一个表指向本表的外键,不设置name的值,则 name=关联表的名称+“_”+ 关联表主键的字段名
//referencedColumnName标注的是所关联表中(登记表)的字段名,若不指定则使用的所关联表的主键字段名作为外键
//notfound是联表查询时找不到引用的外键数据时忽略
@ManyToOne(targetEntity = RiskSegment.class)
@JoinColumn(name = "levelId", referencedColumnName = "id", insertable = false, updatable = false)
@JsonIgnore
@NotFound(action= NotFoundAction.IGNORE)
private RiskSegment riskSegment;
@ManyToOne(targetEntity = DisposalAction.class)
@JoinColumn(name = "actionId", referencedColumnName = "id", insertable = false, updatable = false)
@JsonIgnore
@NotFound(action=NotFoundAction.IGNORE)
private DisposalAction disposalAction;
@Override
public String toString() {
return "RiskActionSegmentMapping{" +
"id='" + id + '\'' +
", actionId='" + actionId + '\'' +
", levelId='" + levelId + '\'' +
", preliminarySelection='" + preliminarySelection + '\'' +
", selected='" + selected + '\'' +
", riskSegment=" + riskSegment +
", disposalAction=" + disposalAction +
'}';
}
在实体上的配置就完成了,现在进行多表联查,先讲涉及到两个表的查询
1.已知等级表的主键id(2),和中间表的条件(preliminary_selection=0,selected=1),查询对应的动作列表
理想的查询sql
select disposal.*
from t_risk_disposal_action disposal
inner join t_risk_action_r_segment riskaction on disposal.id=riskaction.action_id
where riskaction.level_id=? and riskaction.preliminary_selection=? and riskaction.selected=?
通过root.join的方式创建连接
@Test
public void test1() {
Specification<DisposalAction> specification2 = (Specification<DisposalAction>) (root, query, cb) -> {
List<Predicate> predicates = new ArrayList<>();
//root.join第一个参数是连接的属性名称,从DisposalAction对象里面找到riskActionSegmentMappings,第二个属性是连接方式,包括左连接
//Join<T,T>第一个泛型是源类型,第二个泛型是连接目标的类型,joinRiskActionSegmentMapping 实体(可以理解为何root相似)
Join<DisposalAction, RiskActionSegmentMapping> joinRiskActionSegmentMapping = root.join("riskActionSegmentMappings", JoinType.INNER);
//构建查询条件,levelId是中间表中等级表的外键,另外两个条件是中间表的其他条件(这个看不懂建议先查看Specification的基础用法)
predicates.add(cb.equal(joinRiskActionSegmentMapping.get("levelId"), "2"));
predicates.add(cb.equal(joinRiskActionSegmentMapping.get("preliminarySelection"), "0"));
predicates.add(cb.equal(joinRiskActionSegmentMapping.get("selected"), "1"));
return cb.and(predicates.toArray(new Predicate[predicates.size()]));
};
log.info(disposalActionRepository.findAll(specification2).toString());
}
生成的sql和目标sql一致,实际上相当于查询了一次一对多的联查
Hibernate:
select disposalac0_.id as id1_8_, disposalac0_.cnname as cnname2_8_, disposalac0_.describe as describe3_8_,
disposalac0_.label as label4_8_,disposalac0_.n1 as n5_8_, disposalac0_.n2 as n6_8_, disposalac0_.n3 as n7_8_,
disposalac0_.n4 as n8_8_, disposalac0_.n5 as n9_8_,disposalac0_.n6 as n10_8_, disposalac0_.n7 as n11_8_,
disposalac0_.name as name12_8_, disposalac0_.status as status13_8_, disposalac0_.type as type14_8_
from t_risk_disposal_action disposalac0_
inner join t_risk_action_r_segment riskaction1_ on disposalac0_.id=riskaction1_.action_id
where riskaction1_.level_id=? and riskaction1_.preliminary_selection=? and riskaction1_.selected=?
2.三个表的查询,查询(73)在的等级表的等级,并通过中间表查询到动作列表,中间表条件依旧是(preliminary_selection=0,selected=1)
第一种查询方式,通过query拼接sql
@Test
public void test() {
Specification<DisposalAction> specification = (Specification<DisposalAction>) (root, query, cb) -> {
List<Predicate> predicates = new ArrayList<>();
//通过query拼接sql的方式查询,比较好理解,缺点是只能生成笛卡尔积
//riskActionSegmentMappingRoot 实体
Root<RiskActionSegmentMapping> riskActionSegmentMappingRoot = query.from(RiskActionSegmentMapping.class);
Root<RiskSegment> riskSegmentRoot = query.from(RiskSegment.class);
//构建查询条件
// AB两表的关联条件,就是sql join 中的on条件
predicates.add(cb.equal(riskActionSegmentMappingRoot.get("actionId"), root.get("id")));
// AB两表的关联条件,就是sql join 中的on条件
predicates.add(cb.equal(riskActionSegmentMappingRoot.get("levelId"), riskSegmentRoot.get("id")));
predicates.add(cb.equal(riskActionSegmentMappingRoot.get("preliminarySelection"), "0"));
predicates.add(cb.equal(riskActionSegmentMappingRoot.get("selected"), "1"));
predicates.add(cb.greaterThan(riskSegmentRoot.get("max"), "73"));
predicates.add(cb.lessThan(riskSegmentRoot.get("min"), "73"));
return cb.and(predicates.toArray(new Predicate[predicates.size()]));
};
List<DisposalAction> all = disposalActionRepository.findAll(specification);
log.info(all.toString());
}
这种方式得到的sql联表查询的结果是笛卡尔积,用得还算比较少
Hibernate:
select disposalac0_.id as id1_8_, disposalac0_.cnname as cnname2_8_, disposalac0_.describe as describe3_8_,
disposalac0_.label as label4_8_, disposalac0_.n1 as n5_8_, disposalac0_.n2 as n6_8_, disposalac0_.n3 as n7_8_,
disposalac0_.n4 as n8_8_, disposalac0_.n5 as n9_8_,disposalac0_.n6 as n10_8_, disposalac0_.n7 as n11_8_,
disposalac0_.name as name12_8_, disposalac0_.status as status13_8_, disposalac0_.type as type14_8_
from t_risk_disposal_action disposalac0_
cross join t_risk_action_r_segment riskaction1_
cross join t_risk_segment risksegmen2_
where riskaction1_.action_id=disposalac0_.id and riskaction1_.level_id=risksegmen2_.id
and riskaction1_.preliminary_selection=? and riskaction1_.selected=?
and risksegmen2_.max>73 and risksegmen2_.min<73
第二种查询方式,还是通过root.join方式查询,可以看得到第一次连接是内连接,第二次连接是左连接
@Test
public void test3() {
Specification<DisposalAction> specification2 = (Specification<DisposalAction>) (root, query, cb) -> {
List<Predicate> predicates = new ArrayList<>();
//root.join第一个参数是连接的属性名称,从DisposalAction对象里面找到riskActionSegmentMappings,第二个属性是连接方式
//Join<T,T>第一个泛型是源类型,第二个泛型是连接目标的类型,joinRiskActionSegmentMapping 实体(可以理解为何root相似)
Join<DisposalAction, RiskActionSegmentMapping> joinRiskActionSegmentMapping = root.join("riskActionSegmentMappings", JoinType.INNER);
//joinRiskActionSegmentMapping.join第一个参数是连接的属性名称,从RiskActionSegmentMapping对象里面找到riskSegment
//Join<T,T>第一个泛型是源类型,第二个泛型是连接目标的类型,segmentMappingRiskSegmentJoin 实体(可以理解为何root相似)
Join<RiskActionSegmentMapping, RiskSegment> segmentMappingRiskSegmentJoin = joinRiskActionSegmentMapping.join("riskSegment", JoinType.LEFT);
//构建查询条件
predicates.add(cb.equal(joinRiskActionSegmentMapping.get("preliminarySelection"), "0"));
predicates.add(cb.equal(joinRiskActionSegmentMapping.get("selected"), "1"));
predicates.add(cb.greaterThan(segmentMappingRiskSegmentJoin.get("max"), "73"));
predicates.add(cb.lessThan(segmentMappingRiskSegmentJoin.get("min"), "73"));
return cb.and(predicates.toArray(new Predicate[predicates.size()]));
};
List<DisposalAction> all2 = disposalActionRepository.findAll(specification2);
log.info(all2.toString());
}
而得到的sql也是第一次是内连接,第二次是左连接,满足三表联查的需要,其实多表查询,就是从上一个表找连接的下一个表的拼接sql的过程,找到了表,就可以引用表中的字段作为查询条件,而这里转换成了实体而已,从上一个实体找连接的下一个实体,找到了实体,就可以引用实体中的属性作为查询条件。
Hibernate:
select disposalac0_.id as id1_8_, disposalac0_.cnname as cnname2_8_, disposalac0_.describe as describe3_8_,
disposalac0_.label as label4_8_, disposalac0_.n1 as n5_8_, disposalac0_.n2 as n6_8_, disposalac0_.n3 as n7_8_,
disposalac0_.n4 as n8_8_, disposalac0_.n5 as n9_8_, disposalac0_.n6 as n10_8_, disposalac0_.n7 as n11_8_,
disposalac0_.name as name12_8_, disposalac0_.status as status13_8_, disposalac0_.type as type14_8_
from t_risk_disposal_action disposalac0_
inner join t_risk_action_r_segment riskaction1_ on disposalac0_.id=riskaction1_.action_id
left outer join t_risk_segment risksegmen2_ on riskaction1_.level_id=risksegmen2_.id
where riskaction1_.preliminary_selection=? and riskaction1_.selected=?
and risksegmen2_.max>73 and risksegmen2_.min<73
因为这里是简化了很多表属性,原本的查询结果很多,所以就没有展示出来,但是查询出来的结果都是一致的,验证过了。














 1103
1103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









