









今天思考的时候突然想到一个问题。正常情况下,我们都知道一个partition只能被同一个消费组中的一个consumer消费,而且实际场景中,一般我们都是consumer多于partition或者等于partition,也就是,一个consumer只会从一个partition里pull消息。
但是如果consumer比partition数量要少时,一个consumer就会对应多个partition,这个时候它会怎么拉消息呢?你的配置文件max.poll.records到底是从一个partition拉取的消息最大数量还是所有partition呢?
带着这个疑问,我在网上搜了一下kafka的消费原理,源码解析
这篇博客讲得很好,可以看出来每个consumer会一对一对应一个blockingQueue,这样在consumer分配完要消费的partition后,其实这个阻塞队列和partition的关系就确定了。在这个地方,我猜测,阻塞队列的大小就和你的这个配置参数有关。然后博客里讲,每个broker会有一个fetchThread,负责把消息放到阻塞队列里边。在放的时候,会根据partition和队列的对应关系,把消息放到不同的队列里边。
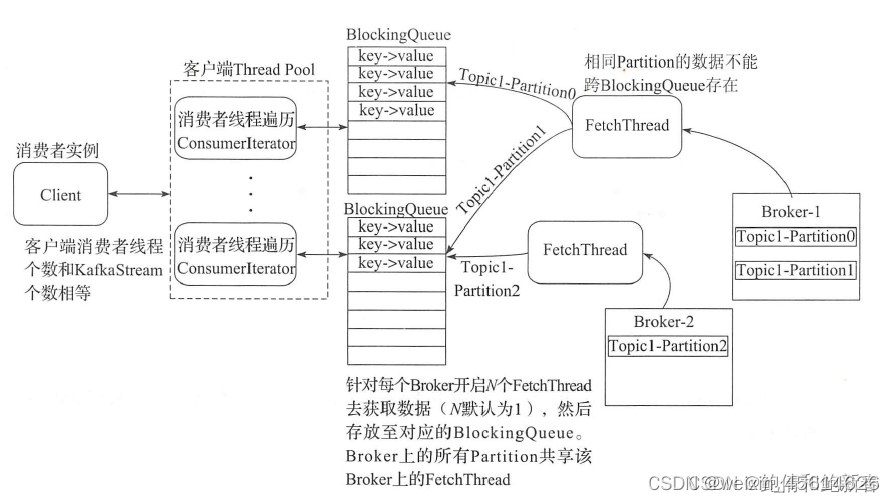
这样就明白了,这个max.poll.records参数指定的是从所有消费的partition拉取消息的最大数量(应该是blockingqueue里边每次poll,)。如果是多个partiton的话,一次拉取的消息中每个partition的占比是不确定的,有可能10个都是partition0的消息,也有可能5个是partition0,5个是partition1,也有可能是1:9,人为无法控制。这也是为什么一个consumer对应多个partition时无法保证消费顺序,而只能保证单个partition中消息的顺序性~
上边这些都是看了这篇源码分析后的猜测,受限于身边物理硬件的问题,没办法测试,希望有朋友可以试验一下对不对。看来以后还是要多看源码,不然理解的原理还是比较浅显~~~
之后会出一个面试的博客,以及对kafka原理讲解的博客,暂时手头上有不少事情,等忙完了就写,先把flag立下了。。。。。
PS:每个consumer group都会有一个metadata来存储相关信息,比如offset,在这个metadata中,每个consumer都有一个对应的offset来记录消费的位置,为了consumer重连或者重新分配时不会重复消费。同时这个metadata中也会存储每个consumer和partition的对应关系。














 1179
1179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









