






sql left join 主表限制条件写在on后面和写在where后面的区别
如题,假设有这么一道sql题
with a as (
select 1 as id , 'a' as name
union all
select 1,'b'
),
b as (
select 1 as id1, 'q' as name1
union all
select 1 , 'w'
)
select count(*) from (
select *,'a' as num
from a
left join b
on a.id = b.id1
and a.name = 'a'
问答案是几?
想必大部分人都会回答 2 ,至少我是这样的。在我原先的理解中,这个sql的执行顺序应该是这样的
- 执行关联,这是会出现四条结果,数据为 1 a 1 q; 1 a 1 w; 1 b 1 q; 1 b 1 w;
- 执行过滤,去掉a.name <>'a’的,
最后结果为 1 a 1 q; 1 a 1 w;
但这样是错的!!!
对于这道sql来说,执行顺序应该是这样的。
- 首先检测到left join ,直接返回a表全部结果,结果为 1 a ;1 b
- 拿a表符合 a.name = 'a’的,去与b表进行关联,不符合条件的,b表置为null,结果为 1 a 1 q; 1 a 1 w; 1 b null null
所以,结果为3
记录一下,总结经验
sum()over()函数技巧
-
sum()over() over里只partition 不order 为按照分组求和,没什么好说的 sum()over()
-
over里partition 且order 为按照排序字段累积求和
-
重点来了,滑动求和 ,先上sql
select t.id,t.name ,t.id*10
,sum(t.id*10)over(order by id rows between unbounded preceding and 1 preceding)
,sum(t.id*10)over(order by id )
from (select split(space(10), ' ') as x) m
lateral view posexplode(x) t as id,name
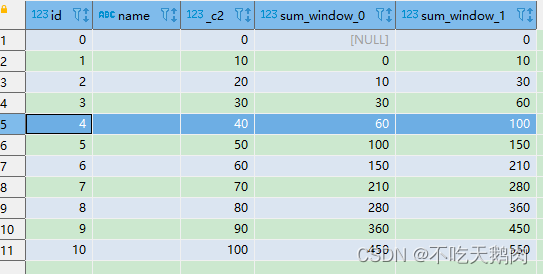
可以很轻易的看到结果,上面我写的sql为累计求和,从起始行到当前行的前一行,还有其他参数,如下
row函数:
current row:当前行
n PRECEDING:往前n行
n FOLLOWING:往后n行
UNBOUNDED:起点
UNBOUNDED PRECEDING:从前面起点
UNBOUNDED FOLLOWING:到后面终点
LAG(col,n):往前的第n行
LEAD(col,n):往后的第n行
增加字段并且修改字段位置
alter table ods.ods_bi_movie_company_da add columns( priority bigint comment '排序');
alter table ods.ods_bi_movie_company_da change priority priority bigint after post --移动到指定位置,post 字段的后面















 2073
2073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









