







目录
17. 先有的语言,还是先有的编译器,第一个编译器是怎么产生的
15. 局部变量和函数参数为什么要放在栈中
局部变量:顾名思义其作用域属于局部,并不是像 static 那样属于全局性的;
全局的变量:意味着谁都可以随时随地访问,所以其放在数据段中。
堆:是程序运行过程中用于动态内存分配的内存空间,是操作系统为每个用户进程规划的,属于软件范畴;往高地址发展;
栈:也叫堆栈,是处理器运行必备的内存空间,是硬件必需的,但又是由软件(操作系统)提供的;往低地址发展;
很多知识都是通过实践后才搞明白的(不明白的地方可以先放一放啦~)
16. 为什么说汇编语言比C语言快
汇编语言本身就是机器指令的符号化,汇编语言编译器并不会添加额外的语句,因此汇编语言写的程序会更直接;
C 编译器往往会在背后加入额外的C语言代码来支撑一些功能,因此实际的代码量就变得很大,另外在编译阶段,C代码会率先被编译成汇编代码,然后再由汇编器将汇编代码翻译成机器指令。
17. 先有的语言,还是先有的编译器,第一个编译器是怎么产生的
先是设计好语言的规则,然后编写能够识别这套规则的编译器;
编译器只要能根据规则编译出指令/输出对应要求的文件即可(迷糊?)
18. 编译型程序与解释型程序的区别
解释型语言:也称脚本语言,本身是文本文件,输入到脚本解释器中;脚本中的代码在解释器看来与字符串无异,解释器时时分析这个脚本,动态根据关键字和语法来做出相应的行为;在CPU看来,只有解释器这个进程在运行,完全不知道脚本的存在;因此哪怕脚本中有错误,前面正确的部分也会正常执行。
编译型语言:先将代码编译称指令程序(若是有误则会无法通过编译),由操作系统加载到内存后,操作系统将 CS: IP 寄存器指向这个程序的入口,使它直接上 CPU 运行,其本身就是一个进程。调度器在就绪队列中能看到此进程,而解释型程序是无法让调度器“入眼”的,调度器只会看到该脚本语言的解释器。
19. 什么是大端子节序、小端字节序
内存是以字节为单位读写的,其最小的读写单位就是字节(即内存是按字节寻址的)。
小端字节序:数值的低字节放在内存的低地址处,数值的高字节放在内存的高地址;(因为低位在低字节,强制转换数据型时不需要再调整字节了)。
大端字节序:数值的低字节放在内存的高地址处,数值的高字节放在内存的低地址;(有符号数,其字节最高位不仅表示数值本身,还起到了符号的作用(?)。符号位固定为第一字节,也就是最高位占据最低地址,符号直接可以取出来,容易判断正负)。
编译器的转换原则:强制转换到低精度类型时,会丢弃数值的高字节位,只保留数值的低字节。
20. BIOS中断、DOS中断、Linux中断的区别
BIOS,DOS都是存在于实模式下的程序,由它们建立的中断调用都是建立在中断向量表( Interrupt Vector Table, IVT )中的,它们都是通过软中断指令 int 中断号来调用的。
BIOS 中断调用的主要功能是提供了硬件访问的方法,该方法使对硬件的操作变得简单易行。
DOS 是运行在实模式下的,故其建立的中断调用也建立在中断向量表中,只不过其中断向量号和 BIOS 的不能冲突,其也可以调用 BIOS 中断。
Linux 内核是在进入保护模式后才建立中断例程的,不过在保护模式下,中断向量表己经不存在了, 取而代之的是中断描述符表( Interrupt Descriptor Table, IDT )。
21. Section和Segment的区别
section 称为节:是指在汇编源码中经由关键字 section 或 segment 修饰,逻辑划分的指令或数据区域,汇编器会将这两个关键字修饰的区域在目标文件中编译成节,也就是说“节”最初诞生于目标文件中。
segment 称为段:是链接器根据目标文件中属性相同的多个 section 合并后的 section 集合,这个集合称为 segment,也就是段,链接器把目标文件链接成可执行文件,因此段最终诞生于可执行文件中,我们平时所说的可执行程序内存空间中的代码段和数据段就是指的 segment。
(目标文件—将汇编语言编译转换成目标机器平台上的机器指令?链接—将目标文件连接成可执行文件?)
22. 什么是魔数
“一种司空见惯的东西,即使不知道是怎么来的,但由于大脑经常被其训练,对其己经形成深刻的印象,似乎理所当然地接受了”
——其实遇到拦路虎的时候,真的不要太为难自己,可以不求甚解的,后面再回过头来多看看,学习本来就是需要反复理解记忆和运用的,实在理解不了,就先记忆一下,久而久之,兴许也就理解了!(这本书真的是,在传输知识的时候,还解决了我学习中的困惑,这些个情景真的都是一模一样啊🥹🥹🥹)
魔数:不明就理地出现一个数字,不知道其是什么意思,感觉看不透,猜不出,就像魔法一样很神秘;了解一定上下文的人肯定知道是什么意思,一般局外人绞尽脑汁也不解其意。
23. 操作系统是如何识别文件系统的
一个磁盘上的各分区都有位于第二个扇区的超级块,里面记录了此分区的信息,其中就有文件系统的魔数,一种文件系统对应一个魔数,比对此值便能知道文件系统类型。
24. 如何控制CPU的下一条指令
x86体系的CPU中:程序计数器 PC 并不是单一的某种寄存器,它是一种寄存器组合,指的段寄存器 cs 和指令寄存器 ip;有专门改变执行流的指令,如 jmp、call、int、ret ,这些指令可以同时修 cs 和 ip,它们在硬件级别上实现了原子操作。
ARM体系的CPU中:程序计数器有个专门的寄存器,名字就叫 PC,想要改变程序流程,直接对该寄存器赋值便可,可以用 mov 指令来修改程序流。
总结:程序计数器 PC 负责处理器的执行方向,它只是获取下一条指令的方法形式,在不同体系结构的 CPU 中有不同的实现方法。
25. 指令集、体系架构、微架构、编程语言
指令:操作码+操作数(动作+对象,操作数一般是立即数,寄存器,内存等);
指令格式:人为规定操作码和操作数的大小及位置,然后在 CPU 硬件电路中写死这些规则,让 CPU 在硬件一级上识别这些格式,从而能识别出操作码和操作数;
指令集:一套指令的集合;指令集是一套约定,里面规定的是有哪些指令,指令的二进制编码,指令格式等,如何实现这套约定,这是硬件自己的事;(CISC,RISC—两种不同的指令体系,相当于指令集中的门派,是指令的设计思想)。
微架构:指令集是具体的一套指令编码,微架构是指令集的物理实现方式。
CPU 与指令集是对应的,一种 CPU 只能识别一种指令集,所以很多 CPU 都以其支持的指令集来称呼。比如 ARM 、MIPS,它们本身是 CPU 名称,又是指令集名称。
26. 库函数是用户进程与内核的桥梁
任何操作系统都有自己的一套做事规则,在其上的所有应用程序,都按照它定下的规矩做事。
操作系统提供了一套系统调用接口,供用户进程直接调用。
库函数:有调用系统调用的代码(系统调用封装在库函数中)。
eg:我们在 C 程序中简单地 include 〈标准头文件〉之所以有效,是因为编译器提供的运行库中已经为我们准备好了这些标准函数的函数体所在的目标文件,在链接时默默帮我们链接上了。
27. 转义字符与ASCII码
字符编码就是用唯一的一个二进制串表示唯一的-个字符,其中最著名的字符编码就是 ASCII 码。
在写字符串时,如何在其中加入不可见的控制符?需要编译器或解释器的支持了。
编译器在给我们做支持,它将“转义字符 '\'+可见字符” 这种形式的不可见字符转换成了该不可见字符的 ASCII 码。
28. MBR、EBR、DBR 和 OBR 各是什么
计算机在接电之后运行的是基本输入输出系统 BIOS,BIOS 是位于主板上的一个小程序,它只完成一些简单的检测或初始化工作,然后找机会把处理器使用权交出去给MBR;
MBR 是主引导记录, Master 或 Main Boot Record ,它存在于整个硬盘最开始的那个扇区,这个扇区便称为 MBR 引导扇区。BIOS 将 MBR 引导程序加载到物理地址 0x7c00 ,然后跳过去执行,这样 BIOS 就把处理器使用权移交给 MBR 了。
MBR 引导扇区中除了引导程序外,还有 64 字节大小的分区表,里面是分区信息,分区表中每个分区表项占 16 字节,因此 MBR 分区表中可容纳 4 个分区,这个分区就是“次引导程序”的候选人群,MBR 引导程序开始遍历这 4 个分区,想找到合适的人选并把系统控制权交给他(找活动分区,0x80标记)。通常情况下这个“次引导程序”就是操作系统提供的加载器,因此 MBR 引导程序的任务就是把控制权交给操作系统加载器,由该加载器完成操作系统的自举,最终使控制权交付给操作系统内核。
为了 MBR 方便找到活动分区上的内核加载器,内核加载器的入口地址也固定在各分区最开始的扇区,因此该扇区称为操作系统引导扇区。其中的引导程序(内核加载器)称为操作系统引导记录OBR,即 OS Boot Record,所以此扇区也称为 OBR 引导扇区。
OBR 引导扇区起始处的跳转指令会马上将处理器带入操作系统引导程序,从此 MBR 完成交接工作,以后便是内核的天下了。
BIOS ➡️ 整个硬盘最开始的那个扇区,MBR(0x7c00) ➡️ 找活动分区,到分区最开始的OBR扇区,跳转指令 ➡️ 加载 OS 内核
DBR 是 DOS Boot Record,也就是DOS操作系统的引导记录(程序),
EBR 位于各子扩展分区中最开始的扇区,解决分区数量限制的问题。
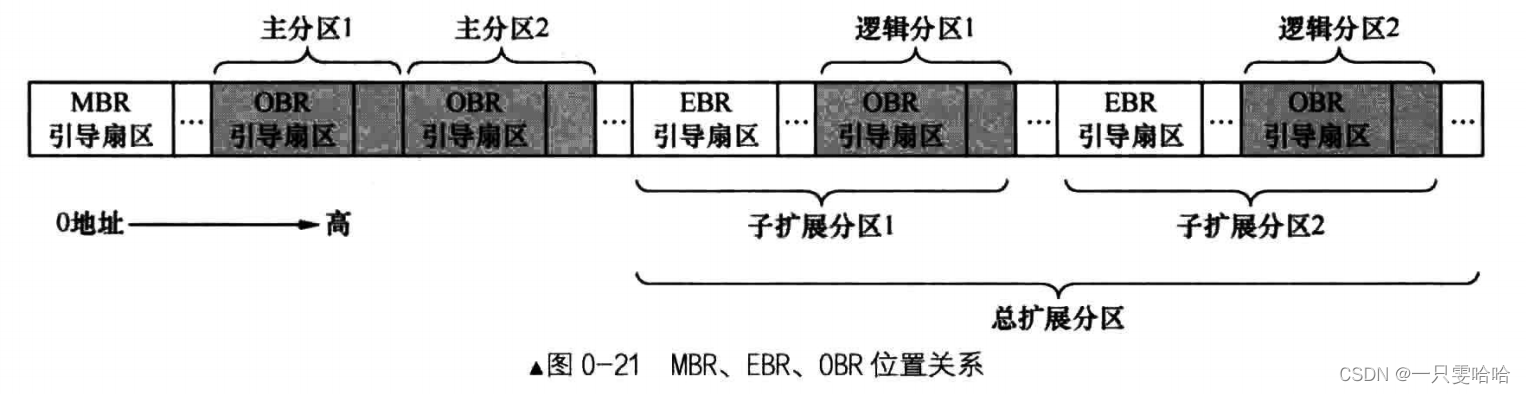
【这里EBR有点迷糊😵💫】















 1317
1317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









