







目录
4.4 处理器微架构简介
了解处理器内部硬件架构,有助于理解软件运行原理,因为这两者本身相辅相成,相互依存。
4.4.1 流水线
 表 4-13 的过程便是一个流水线的执行过程,由于砸钉子分为两个步骤,所以以上流水线称为二级流水线。
表 4-13 的过程便是一个流水线的执行过程,由于砸钉子分为两个步骤,所以以上流水线称为二级流水线。
CPU 的指令执行过程分为取指令、译码、执行三个步骤。每个步骤都是独立执行的,CPU 可以一边执行指令,一边取指令,一边译码。(CPU 在遇到无条件转移指令 jmp 时,会清空流水线。)

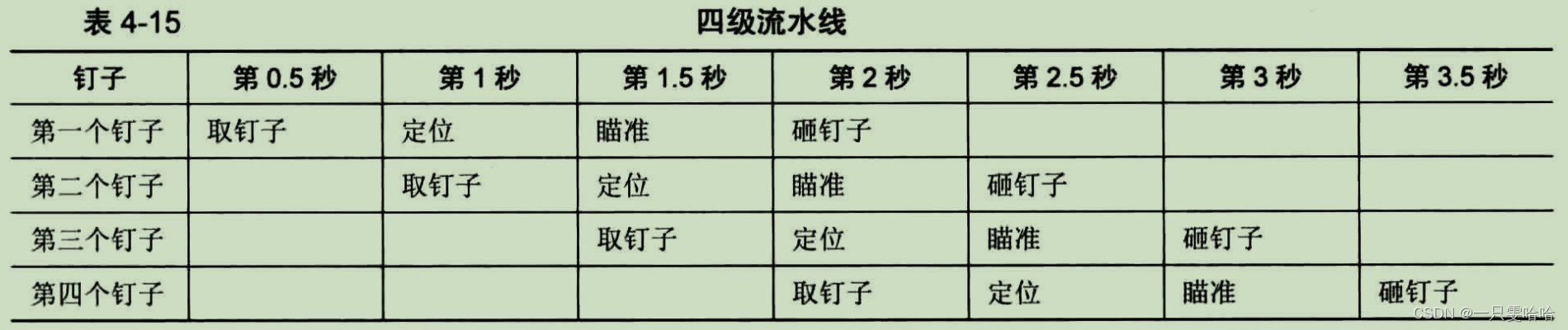 从第 2 秒后,每 0.5 秒就会有一个砸钉子的动作,所以在以后的每分钟内,都会钉入 120 个钉子,速度又提高了很多。这就是将指令拆分成多个微操作后的效率提升。(因为微操作的周期短)
从第 2 秒后,每 0.5 秒就会有一个砸钉子的动作,所以在以后的每分钟内,都会钉入 120 个钉子,速度又提高了很多。这就是将指令拆分成多个微操作后的效率提升。(因为微操作的周期短)
流水线是 CPU 提高效率的一种出路,以后介绍的各种优化方法,其实都是围绕如何让流水线更加有效而展开的。
4.4.2 乱序执行
乱序执行:是指在 CPU 中运行的指令并不按照代码中的顺序执行,而是按照一定的策略打乱顺序执行,也许后面的指令先执行,当然,得保证指令之间不具备相关性。
CISC (Complex Instruction Set Computer),意为复杂指令集计算机,不断地往 CPU 中添加各种指令,甚至在 CPU 硬件一级直接支持软件中的某些操作,以至于指令集越来越庞大笨重复杂。
RISC (Reduced Instruction Set Computer ),意为精简指令集计算机,精简保留了那些常用的指令,这些指令大多数都是不可再细分的,也就是说它们基本上都是属于微操作级别的指令。
乱序执行的好处就是后面的操作可以放到前面来做,利于装载到流水线上提高效率。
4.4.3 缓存
缓存是 20 世纪最大的发明,其原理是用一些存取速度较快的存储设备作为数据缓冲区,避免频繁访问速度较慢的低速存储设备。
SRAM,即静态随机访问存储器,是最快的存储器。寄存器和 SRAM 都是用相同的存储电路实现的,用的都是触发器,是工作速度极快的,属于纳秒级别。
局部性分为以下两个方面:(将当前用到的指令和当前位置附近的数据都加载到缓存中)
- 时间局部性:最近访问过的指令和数据,在将来一段时间内依然经常被访问。
- 空间局部性:靠近当前访问内存空间的内存地址,在将来一段时间也会被访问。
4.4.4 分支预测
CPU 中的指令是在流水线上执行的。
分支预测:是指当处理器遇到一个分支指令时,是该把分支左边的指令放到流水线上,还是把分支右边的指令放在流水线上。
如何把握好转移的方向,才是使流水线保持高效的关键。所谓的预测是针对有条件跳转来说的。
Intel的分支预测部件中用了分支目标缓冲器(Branch Target Buffer,BTB )。
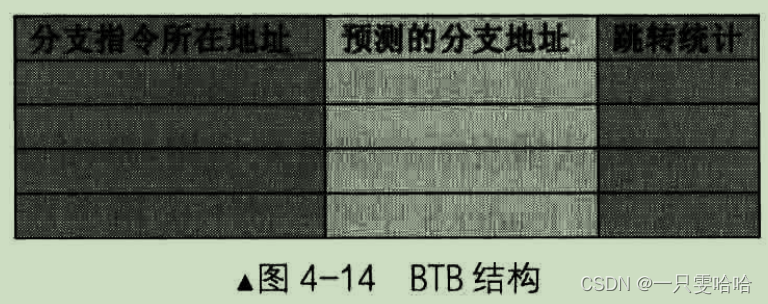
如果 BTB 中没有相同记录,这时候可以使用 Static Predictor,静态预测器。存储在里面的预测策略是固定写死的,它是由人们经过大量统计之后,根据某些特征总结出来的。如,若循环结构向上跳转则转移会发生,若向下跳转则转移不发生。

预测错了就清空流水线即可,根据实际情况更新BTB。
4.5 使用远跳转指令清空流水线,更新段描述符缓冲寄存器
代码段寄存器 cs,只有用远过程调用指令 call,远转移指令 jmp,远返回指令 retf 等指令间接改变。CPU 遇到 jmp 指令时,之前已经送上流水线上的指令只有清空,所以 jmp 指令有清空流水线的神奇功效。
4.6 保护模式之内存段的保护
保护模式中的保护二字主要体现在段描述符的属性字段中,每个字段都不是多余的。这些属性只是用来描述一块内存的性质,是用来给 CPU 做参考的,当有实际动作在这片内存上发生时,CPU用这些属性来检查动作的合法性,从而起到了保护的作用。
4.6.1 向段寄存器加载选择子时的保护
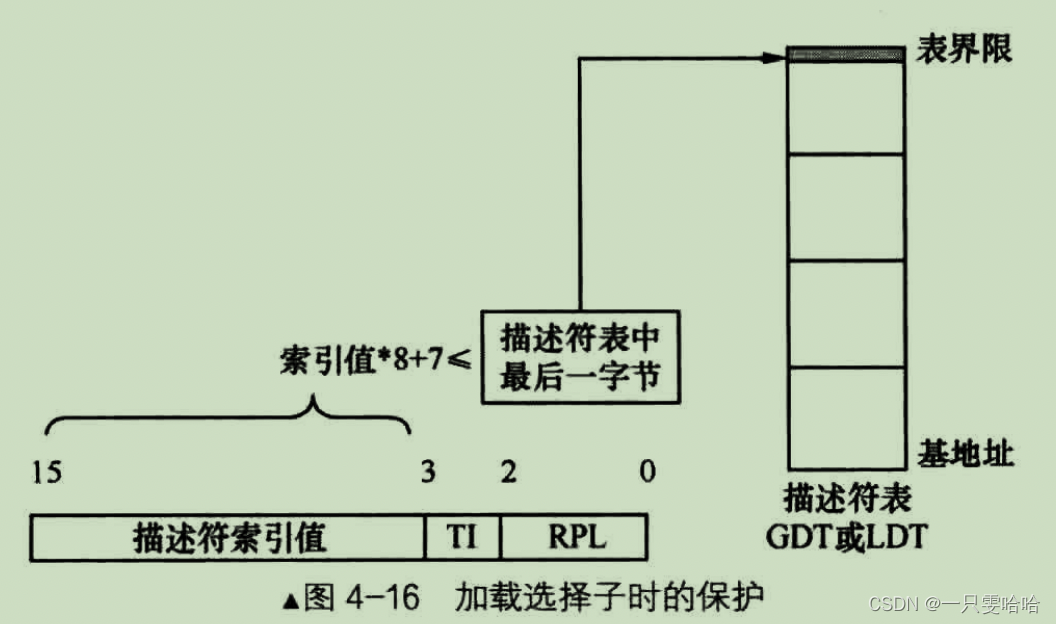
当引用一个内存段时,实际上就是往段寄存器中加载个选择子,为了避免出现非法引用内存段的情况,在这时候,处理器会在以下几方面做出检查:
处理器先检查 TI 的值,如果 TI 是 0,则从全局描述符表寄存器 gdtr 中拿到 GDT 基地址和 GDT 界限值。如果 TI 是 1,则从局部描述符表寄存器 Idtr 中拿到 LDT 基地址和 LDT 界限 值。有了描述符表基地址和描述符表界限值后,把选择子的高 13 位代入上面的表达式,若不成立,处理器则抛出异常。
- 只有具备可执行属性的段(代码段),才能加载到 cs 段寄存器中。
- 只具备执行属性的段(代码段),不允许加载到除 cs 外的段寄存器中。
- 只有具备可写属性的段(数据段),才能加载到 SS 栈段寄存器中。
- 至少具备可读属性的段才能加载到 DS ES FS GS 段寄存器中。
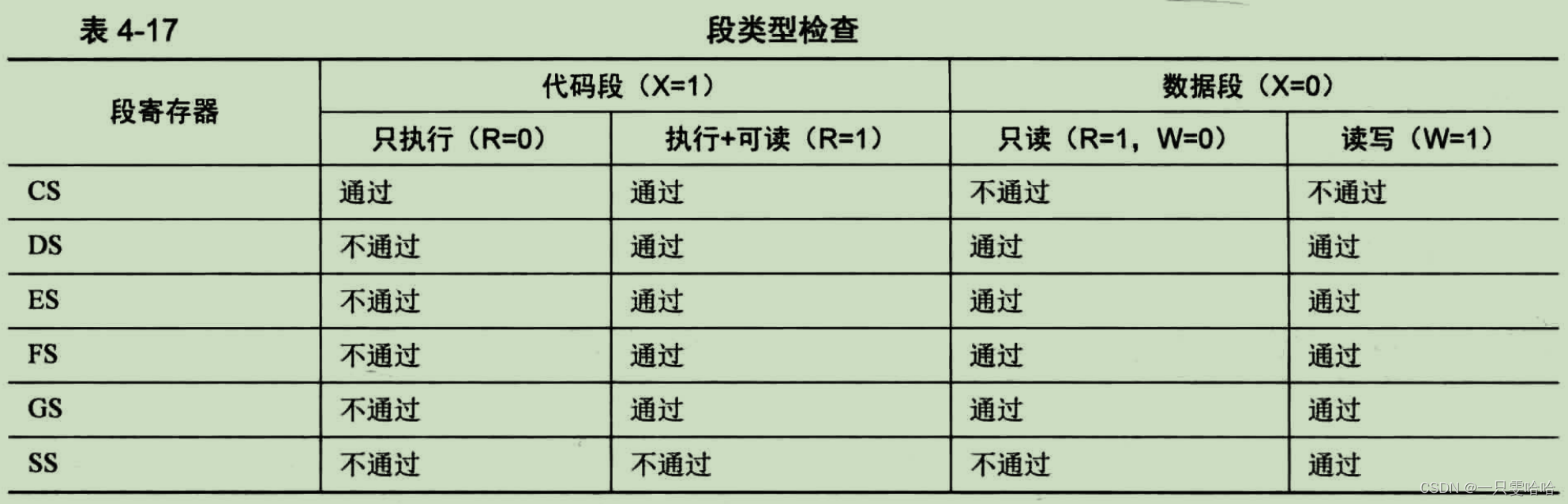
以上所涉及到的 P 位,其值由软件(通常是操作系统)来设置,由 CPU 来检查。A 位由 CPU 来设置。
4.6.2 代码段和数据段的保护
对于代码段和数据段来说,CPU 每访问一个地址,都要确认该地址不能超过其所在内存段的范围。
若 G 为 0,表示段界限的单位是 1 字节;若 G 为 1,表示段界限的单位是 4KB。
段界限就是以 0 为起始的段偏移量???
实际的段界限大小,是段内最后一个可访问的有效地址。
实际段界限的值为: (描述符中段界限+1) * (段界限的粒度大小: 4k 或者 1) -1。(规定就是这么算的吧🤔️)
对于 G 位为 4k 粒度大小的段来说:实际段界限大小 = (描述符中段界限+1) *4k-1=描述符中段界限*4k+4k-1=描述符中段界限*0x1000+0xFFF。
在 IA32 体系结构中,访问内存就要用分段策略。
- EIP 中的偏移地址+指令长度 <= 实际段界限大小。
- 数据段的偏移地址+数据长度 <= 实际段界限大小。
段界限大小规定的好像就是段内最后一个可访问的有效地址,和段基址一起规定了段的大小范围🤔️,这里的有效地址是指偏移地址吗???
4.6.3 栈段的保护
栈顶指针[e]sp 的值逐渐降低,这是 push 指令的作用,与描述符是否向下扩展无关,也就是说,是数据段就可以用作栈。
CPU 对数据段的检查,其中一项就是看地址是否超越段界限。如果将向上扩展的数据段用作栈,那 CPU 将按照之前提到的数据段的方式检查该段。如果用向下扩展的段做栈的话,情况有点复杂,这体现在段界限的意义上。
- 对于向上扩展的段,实际的段界限是段内可以访问的最后一字节。
- 对于向下扩展的段,实际的段界限是段内不可以访问的第一个字节。
地址本身由低地址向高地址发展。
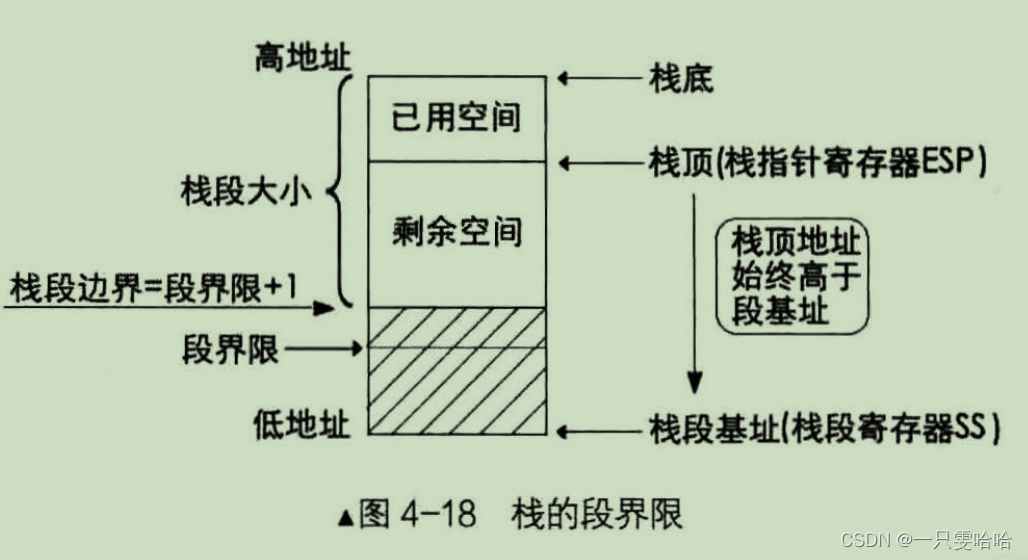
这里有点懵🤔️















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









