







目录
首先回顾上节的案例:

处于举例解释方便,我们以capacity expansion problem为例,进行说明:
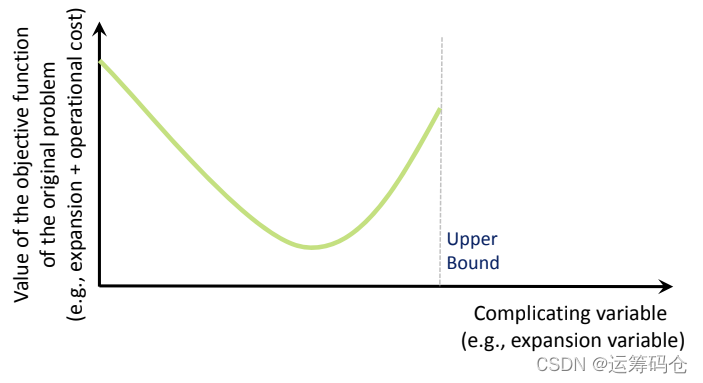
在最低点的左侧,增加投入的成本是较低的,而在最低点右侧,继续增加投入的成本是较高的。
在真实中,我们并不事先知道该曲线,我们如何得到它呢?
我们可以根据斜率来不断逼近这条曲线,过程如下:
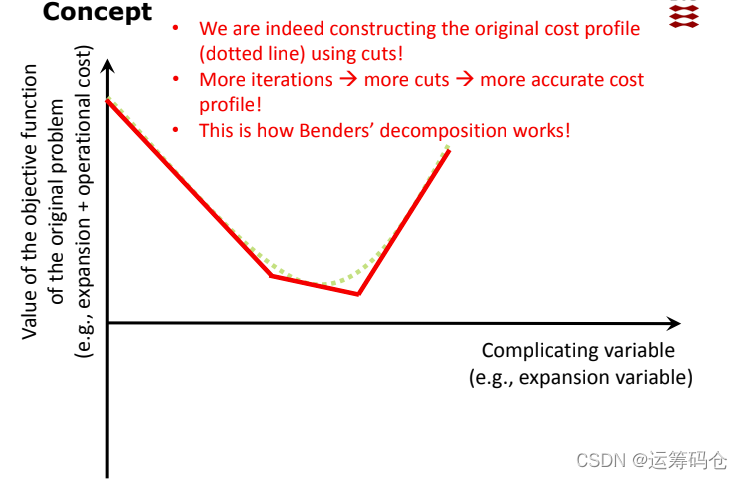
如果原始复杂变量是非凸的,那么我们只能得到它的最优解。只有凸问题,我们才能得到它的最优解。
照例先给出几个参考文献:
- Pereira, M. V., & Pinto, L. M. (1991). Multi-stage stochastic optimization applied to energy planning. Mathematical programming, 52(1), 359-375.
- Conejo, A. J., Castillo, E., Minguez, R., & Garcia-Bertrand, R. (2006). Decomposition techniques in mathematical programming: engineering and science applications. Springer Science & Business Media.
1 计算案例
给定如下问题,让我们假设 x 是复杂变量,那么有:

1.1 案例分解
问题可以分解为:

注解:
- 在主问题中,
的表示的子问题的目标函数,有多少个子问题,就对应的是多少子问题目标的和
- 固定复杂变量而删除的约束,将会出现在主问题中
是一个很大的负数,仅在第一迭代中,为
提供一个初始的下界,以避免在第一次迭代中出现无界现象。
- 最后一个约束的右侧,是子问题的对偶问题的目标函数
- 如果 i=5, 那么 k= 1, 2, 3, 4;每次迭代,我们将添加一个benders cut。也就是说,我们在第5次迭代开始时,主问题中有4个benders cut。在第一次迭代时,主问题中,是没有bender cut的
- 如果子问题不可行,我们将无法构建对偶问题,也就无法构造benders最优cut;此时我们需要想办法构建 benders 可行cut。一般的经验是,当子问题不可行时,可以添加辅助变量,并最小化辅助变量,以确保子问题始终有效。而不是使用 benders 可行cut。
1.2 算法步骤
算法的完整步骤为:

1.3 一个更紧凑的形式
如果你的约束很多,就会需要大量的对偶变量,这会导致你的benders cut会很长;此时我们采用一种更紧凑的方法:

在紧凑模型中,问题将不再需要那么多的对偶变量。 紧凑模式生成bender cut的效率更高,但并不意味着它的计算效率就更高;两者的计算效率是相等的。
通过检查两个问题的KKT条件,我们可以发现:两个问题是等价的。
2 数学推导
2.1 从确定性两阶段问题入手
给出如下两阶段确定问题:

让我们分两个阶段来求解:
在两阶段问题中, 出现在子问题中,因此,我们不能单独求解这两个问题;但是如果我们知道x,那么我们就可以用它来得到第二阶段问题的最优解。我们的处理步骤为:
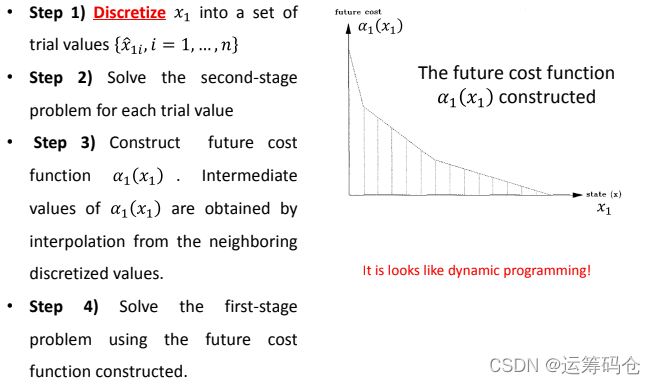
这种技术的缺点是:
- 如果 x 是连续值,我们不知道从哪里开始运算;如何进行插值,这会带来计算诅咒;例如,我们有10个决策变量,每个变量有4个离散值,将会导致
个离散值。
如何克服这个缺点呢?我们要是用对偶动态规划。
2.2 对偶动态规划
该方法使用解析函数(analytical functions),而非一组离散的值来近似未来成本函数。



注解: 表示所有不等式的最大值,最大值不等式对应的 π 也就是最优的
。
在这种情况下,我们还是需要离散化,还需要提供一系列的 π;我们对此还不满意,因为问题没有真正的被解决。
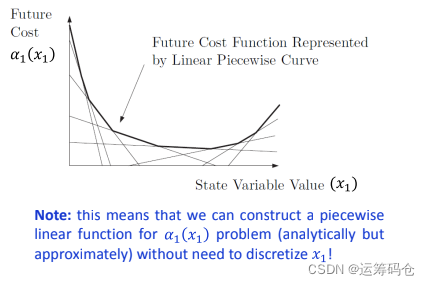
假设我们有一组π 值,我们只需要单独的解 仅包含一阶段变量x 的一阶段问题即可:


那么,如何得到一组 π 值呢?
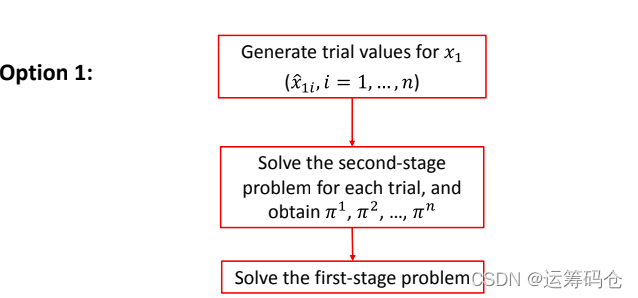
该选项需要事先给出一堆 π 值,之后一次性求解一阶段问题;但是我们通常不这么干。
选项2:我们采用迭代的方法,从一个初始值开始,生成 π 值;之后继续迭代。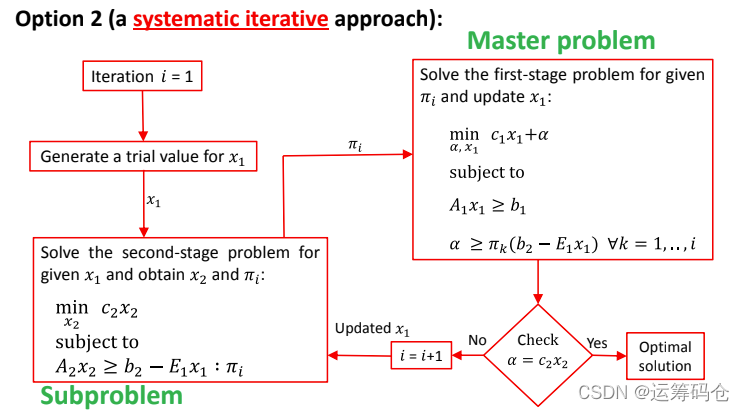
注解:
- 为什么我们要保留之前的cut? 因为你一个cut只保留未来的单词成本,拟合的结果是不精确的。(You need to add one cut for per iteration. If you eliminate the previous the cuts from the previous iterations, you are not reconstructing your future cost. Always you are representing your future cost by a single cut which is obviously not accurate so we need to keep the previous cuts too Just adding one bender cut.)
- 当我们从一个好的起点开始,会减少生成的cut的数目。那么,有没有更好的办法,为 x1 选择一个好的起点吗?答案是没有。
- 为什么我们不建议使用feasible cut ?因为加入可行cut,难以保证最终收敛;通常的做法是,加入松弛变量,让子问题始终保持可行。
- 会不会不断产生不同的π,但得到的 x1 是相同的呢?在凸优化问题中,通常是不会的。
- 在这里我们每次迭代只添加一个cut,还有些做法是一次添加很多cut。添加多个cut的方法有时候会提高效率,但也有可能很快导致你的主问题变得无法处理。
是下界,我们编程时通常写的是
- 如果原问题对应每个复杂变量都是凸的,那么benders分解方法可以确保得到全局最优解。对偶动态规划方法,也成为了Benders分解方法。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











