







第五章课后习题答案
文章目录
- 第五章课后习题答案
- 一、试述将线性函数f(x) = wTx用作神经元激活函数的缺陷?
- 二、试述使用图5.2(b)激活函数的神经元与对率回归的联系
- 三、对于图5.7中的Vih,试推导出BP算法中的更新公式(5.13).
- 四、试述式(5.6)中学习率的取值对神经网络训练的影响.
- 五、试编程实现标准BP算法和累积BP算法,在西瓜数据集3.0上分别用这两个算法训练一一个 单隐层网络,并进行比较.
- 六、试设计一个BP改进算法,能通过动态调整学习率显著提升收敛速度.编程实现该算法,并选择两个UCI数据集与标准BP算法进行实验比较.
- 七、根据式(5.18)和(5.19),试构造一个能解决异或问题的单层RBF神经网络.
一、试述将线性函数f(x) = wTx用作神经元激活函数的缺陷?
使用线性函数作为激活函数时,因为在单元层和隐藏层,其单元值仍是输入值X的线性组合。
若输出层也用线性函数作为激活函数,达不到“激活”与“筛选”的目的,这样相当于整个的线性回归。

二、试述使用图5.2(b)激活函数的神经元与对率回归的联系
对率回归,是使用Sigmoid函数作为联系函数时的广义线性模型。
对于单位阶跃函数(如左图所示):
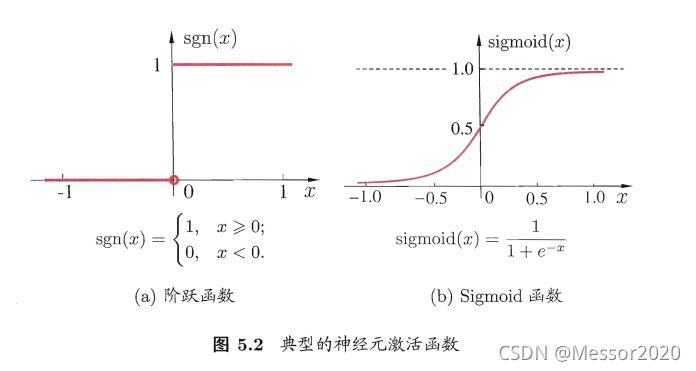
单位阶跃函数不连续,难以求导,所以用对数几率函数代替。
对于对率函数(如以上右图所示):

使用Sigmoid激活函数,每个神经元几乎和对率回归相同,只不过对率回归在 [sigmoid(x)>0.5] 时输出为1,而神经元直接输出 [sigmoid(x)] 。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1993
1993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









