






1、Java基础
自增变量
int i = 1;
i = i++;
int j = i++;
int k = i + ++i * i++;
System.out.println("i = " + i);//4
System.out.println("j = " + j);//1
System.out.println("k = " + k);//11
单例模式
/**
* 直接实例化饿汉式
*/
class Singleton1 {
public static final Singleton1 INSTANCE = new Singleton1();
private Singleton1() {
}
}
/**
* 静态代码块饿汉式(适合复杂实例化)
*/
class Singleton2 {
public static final Singleton2 INSTANCE;
static {
INSTANCE = new Singleton2();
}
private Singleton2() {
}
}
/**
* 枚举式 (最简洁)
*/
enum Singleton3 {
INSTANCE
}
/**
* 线程不安全(使用于单线程)
*/
class Singleton4 {
/**
* 1、构造器私有化
* 2、用一个静态变量保存这个唯一的实例
* 3、提供一个静态方法,获取这个实例对象
*/
public static Singleton4 instance;
private Singleton4() {
}
public static Singleton4 getInstance() {
if (instance == null) {
instance = new Singleton4();
}
return instance;
}
}
/**
* 双重检查(线程安全,适用于多线程)
*/
class Singleton5 {
// 加 volatile 作用:防止指令重排, 当实例变量有修改时,能刷到主存中去是一个原子操作,并且保证可见性。
public static volatile Singleton5 instance;
private Singleton5() {
}
public static Singleton5 getInstance() {
if (instance == null) {
synchronized (Singleton5.class) {
if (instance == null) {
instance = new Singleton5();
}
}
}
return instance;
}
}
/**
* 静态内部类模式 (适用于多线程)
*/
class Singleton6 {
/**
* 1、内部类被加载和初始化时,才创建INSTANCE实例对象
* 2、静态内部类不会自动创建, 不会随着外部类的加载初始化而初始化,他是要单独去加载和实例化的
* 3、因为是在内部类加载和初始化时,创建的,因此线程安全
*/
public static class Inner {
private static final Singleton6 INSTANCE = new Singleton6();
}
private Singleton6() {
}
public static Singleton6 getInstance() {
return Inner.INSTANCE;
}
}
类初始化实例初始化
类初始化
一个类要创建实例需要先加载并初始化该类
main方法所在的类需要先加载和初始化
一个子类要初始化需要先初始化父类
一个类初始化就是执行 clinit 方法
clinit 方法由静态类变量显示赋值代码和静态代码块组成
类变量显示赋值代码和静态代码块代码从上到下执行
clinit 方法只调用一次
实例初始化过程
实例初始化就是执行 init() 方法
init () 方法可能重载有多个,有几个构造器就有几个 init() 方法
init() 方法由非静态实例变量显示赋值代码和非静态代码块,对应构造器代码组成
非静态实例变量显示赋值代码和非静态代码块从上到下顺序执行,而对应构造器的代码最后执行
每次创建实例对象,调用对应构造器,执行的就是对应的 ini方法
init 方法的首行是super()和super(实参列表) ,即对应父类的 init 方法
class Father {
private int i = test();
private static int j = method();
static {
System.out.print("(1)");
}
Father() {
System.out.print("(2)");
}
{
System.out.print("(3)");
}
public int test() {
System.out.print("(4)");
return 1;
}
public static int method() {
System.out.print("(5)");
return 1;
}
}
class Son extends Father {
private int i = test();
private static int j = method();
static {
System.out.print("(6)");
}
Son() {
super();
System.out.print("(7)");
}
{
System.out.print("(8)");
}
public int test() {
System.out.print("(9)");
return 1;
}
public static int method() {
System.out.print("(10)");
return 1;
}
public static void main(String[] args) {
Son son = new Son();
System.out.println();
Son son1 = new Son();
//(5)(1)(10)(6)(9)(3)(2)(9)(8)(7)
//(9)(3)(2)(9)(8)(7)
}
}
局部变量与成员变量的区别
public class Main {
public static int s;
int i;
int j;
{
int i = 1;
i++;
j++;
s++;
}
public void test(int j) {
j++;
i++;
s++;
}
public static void main(String[] args) {
Main obj1 = new Main();
Main obj2 = new Main();
obj1.test(10);
obj1.test(20);
obj2.test(30);
System.out.println(obj1.i + "," + obj1.j + "," + obj1.s); // 2 1 5
System.out.println(obj2.i + "," + obj2.j + "," + obj2.s); // 1 1 5
}
}
快速失败(fail-fast) 安全失败(fail-safe)?
快速失败(fail-fast) 是 Java 集合的⼀种错误检测机制。在使⽤迭代器对集合进⾏遍历的时候,我们 在多线程下操作⾮安全失败(fail-safe)的集合类可能就会触发 fail-fast 机制,导致抛出 ConcurrentModificationException 异常。 另外,在单线程下,如果在遍历过程中对集合对象 的内容进⾏了修改的话也会触发 fail-fast 机制。
每当迭代器使⽤ hashNext() / next() 遍历下⼀个元素之前,都会检测 modCount 变量是否为 expectedModCount 值,是的话就返回遍历;否则抛出异常,终⽌遍历。 如果我们在集合被遍历期间对其进⾏修改的话,就会改变 modCount 的值,进⽽导致 modCount Ö~ expectedModCount ,进⽽抛出 ConcurrentModificationException 异常。
安全失败:
采⽤安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,⽽是先复制原有集合内容,在 拷⻉的集合上进⾏遍历。所以,在遍历过程中对原集合所作的修改并不能被迭代器检测到,故不会抛 ConcurrentModificationException 异常。
2、Java并发
volatile是什么
volatile是JVM提供的轻量级的同步机制
- 保证可见性
- 不保证原子性
- 禁止指令重排(保证有序性)
JMM内存模型之可见性
JMM(Java内存模型Java Memory Model,简称JMM)本身是一种抽象的概念并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
JMM关于同步的规定:
- 线程解锁前,必须把共享变量的值刷新回主内存
- 线程加锁前,必须读取主内存的最新值到自己的工作内存
- 加锁解锁是同一把锁
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝的自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,各个线程中的工作内存中存储着主内存中的变量副本拷贝,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,其简要访问过程如下图:
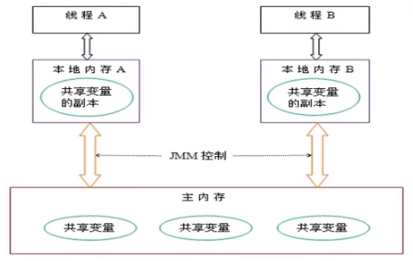
可见性
通过前面对JMM的介绍,我们知道各个线程对主内存中共享变量的操作都是各个线程各自拷贝到自己的工作内存进行操作后再写回到主内存中的。
这就可能存在一个线程AAA修改了共享变量X的值但还未写回主内存时,另外一个线程BBB又对主内存中同一个共享变量X进行操作,但此时A线程工作内存中共享变量x对线程B来说并不可见,这种工作内存与主内存同步延迟现象就造成了可见性问题
可见性代码验证:
public class Main {
public static void main(String args[]) {
// 资源类
MyData myData = new MyData();
// AAA线程 实现了Runnable接口的,lambda表达式
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t come in");
// 线程睡眠3秒,假设在进行运算
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 修改number的值
myData.addTo60();
// 输出修改后的值
System.out.println(Thread.currentThread().getName() + "\t update number value:" + myData.number);
}, "AAA").start();
// main线程就一直在这里等待循环,直到number的值不等于零
while (myData.number == 0) {
}
// 按道理这个值是不可能打印出来的,因为主线程运行的时候,number的值为0,所以一直在循环
// 如果能输出这句话,说明AAA线程在睡眠3秒后,更新的number的值,重新写入到主内存,并被main线程感知到了
System.out.println(Thread.currentThread().getName() + "\t mission is over");
}
}
class MyData {
//volatile int number = 0;
int number = 0;
public void addTo60() {
this.number = 60;
}
}
缓存一致性
为什么这里主线程中某个值被更改后,其它线程能马上知晓呢?其实这里是用到了总线嗅探技术
在说嗅探技术之前,首先谈谈缓存一致性的问题,就是当多个处理器运算任务都涉及到同一块主内存区域的时候,将可能导致各自的缓存数据不一。
为了解决缓存一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议进行操作,这类协议主要有MSI、MESI等等。
MESI
当CPU写数据时,如果发现操作的变量是共享变量,即在其它CPU中也存在该变量的副本,会发出信号通知其它CPU将该内存变量的缓存行设置为无效,因此当其它CPU读取这个变量的时,发现自己缓存该变量的缓存行是无效的,那么它就会从内存中重新读取。
总线嗅探
那么是如何发现数据是否失效呢?
这里是用到了总线嗅探技术,就是每个处理器通过嗅探在总线上传播的数据来检查自己缓存值是否过期了,当处理器发现自己的缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置为无效状态,当处理器对这个数据进行修改操作的时候,会重新从内存中把数据读取到处理器缓存中。
总线风暴
总线嗅探技术有哪些缺点?
由于Volatile的MESI缓存一致性协议,需要不断的从主内存嗅探和CAS循环,无效的交互会导致总线带宽达到峰值。因此不要大量使用volatile关键字,至于什么时候使用volatile、什么时候用锁以及Syschonized都是需要根据实际场景的。
JMM的特性
JMM的三大特性,volatile只保证了两个,即可见性和有序性,不满足原子性
- 可见性
- 原子性
- 有序性
原子性
不可分割,完整性,也就是说某个线程正在做某个具体业务时,中间不可以被加塞或者被分割,需要具体完成,要么同时成功,要么同时失败。
代码演示:
public class Main {
public static void main(String[] args) {
MyData myData = new MyData();
// 创建10个线程,线程里面进行1000次循环
for (int i = 0; i < 20; i++) {
new Thread(() -> {
// 里面
for (int j = 0; j < 1000; j++) {
myData.addPlusPlus();
}
}, String.valueOf(i)).start();
}
// 需要等待上面20个线程都计算完成后,在用main线程取得最终的结果值
// 这里判断线程数是否大于2,为什么是2?因为默认是有两个线程的,一个main线程,一个gc线程
while (Thread.activeCount() > 2) {
// yield表示不执行
Thread.yield();
}
// 查看最终的值
// 假设volatile保证原子性,那么输出的值应该为: 20 * 1000 = 20000
//解决的方式就是:
//对addPlusPlus()方法加锁。
//使用java.util.concurrent.AtomicInteger类。
System.out.println(Thread.currentThread().getName() + "\t finally number value: " + myData.number);
}
}
class MyData {
/**
* volatile 修饰的关键字,是为了增加 主线程和线程之间的可见性,只要有一个线程修改了内存中的值,其它线程也能马上感知
*/
volatile int number = 0;
public void addPlusPlus() {
number++;
}
}
number++在多线程下是非线程安全的。
我们可以将代码编译成字节码,可看出number++被编译成3条指令。
- 执行
getfield从主内存拿到原始n - 执行
iadd进行加1操作 - 执行
putfileld把累加后的值写回主内存
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ooetiqFk-1645518544304)(D:\wanghua\笔记\面试题.assets\image-20220218165830762.png)]
假设我们没有加 synchronized那么第一步就可能存在着,三个线程同时通过getfield命令,拿到主存中的 n值,然后三个线程,各自在自己的工作内存中进行加1操作,但他们并发进行 iadd 命令的时候,因为只能一个进行写,所以其它操作会被挂起,假设1线程,先进行了写操作,在写完后,volatile的可见性,应该需要告诉其它两个线程,主内存的值已经被修改了,但是因为太快了,其它两个线程,陆续执行 iadd命令,进行写入操作,这就造成了其他线程没有接受到主内存n的改变,从而覆盖了原来的值,出现写丢失,这样也就让最终的结果少于20000。
Volatile禁止指令重排
计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令重排,一般分为以下三种:
源代码 -> 编译器优化的重排 -> 指令并行的重排 -> 内存系统的重排 -> 最终执行指令
单线程环境里面确保最终执行结果和代码顺序的结果一致
处理器在进行重排序时,必须要考虑指令之间的数据依赖性
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
volatile实现禁止指令重排优化,从而避免多线程环境下程序出现乱序执行的现象
先了解一个概念,内存屏障(Memory Barrier)又称内存栅栏,是一个CPU指令,它的作用有两个:
- 保证特定操作的执行顺序,
- 保证某些变量的内存可见性(利用该特性实现volatile的内存可见性)。
由于编译器和处理器都能执行指令重排优化。如果在指令间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序,也就是说通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化。内存屏障另外一个作用是强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本。
对volatile变量进行写操作时,会在写操作后加入一条store屏障指令,将工作内存中的共享变量值刷新回到主内存。
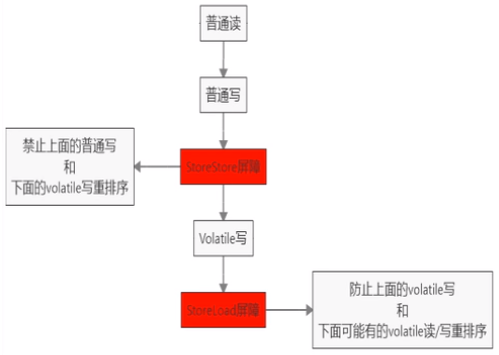
对Volatile变量进行读操作时,会在读操作前加入一条load屏障指令,从主内存中读取共享变量。
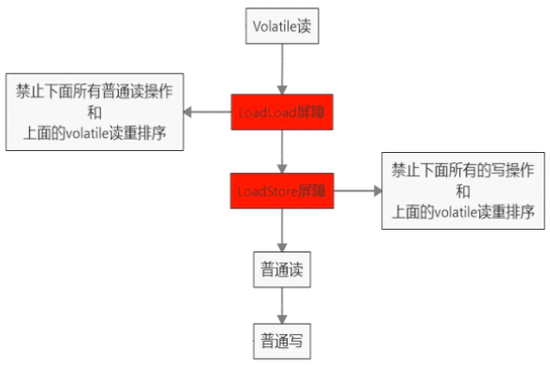
线性安全性获得保证
工作内存与主内存同步延迟现象导致的可见性问题 - 可以使用synchronized或volatile关键字解决,它们都可以使一个线程修改后的变量立即对其他线程可见。
对于指令重排导致的可见性问题和有序性问题 - 可以利用volatile关键字解决,因为volatile的另外一个作用就是禁止重排序优化。
单例模式volatile分析
DCL(双端检锁)机制不一定是线程安全的,原因是有指令重排的存在,加入volatile可以禁止指令重排
原因是在某一个线程执行到第一次检测的时候,读取到 instance 不为null,instance的引用对象可能没有完成实例化。因为 instance = new SingletonDemo();可以分为以下三步进行完成:
- memory = allocate(); // 1、分配对象内存空间
- instance(memory); // 2、初始化对象
- instance = memory; // 3、设置instance指向刚刚分配的内存地址,此时instance != null
但是我们通过上面的三个步骤,能够发现,步骤2 和 步骤3之间不存在 数据依赖关系,而且无论重排前 还是重排后,程序的执行结果在单线程中并没有改变,因此这种重排优化是允许的。
- memory = allocate(); // 1、分配对象内存空间
- instance = memory; // 3、设置instance指向刚刚分配的内存地址,此时instance != null,但是对象还没有初始化完成
- instance(memory); // 2、初始化对象
这样就会造成什么问题呢?
也就是当我们执行到重排后的步骤2,试图获取instance的时候,会得到null,因为对象的初始化还没有完成,而是在重排后的步骤3才完成,因此执行单例模式的代码时候,就会重新在创建一个instance实例
指令重排只会保证串行语义的执行一致性(单线程),但并不会关系多线程间的语义一致性
所以当一条线程访问instance不为null时,由于instance实例未必已初始化完成,这就造成了线程安全的问题
所以需要引入volatile,来保证出现指令重排的问题,从而保证单例模式的线程安全性
private static volatile SingletonDemo instance = null;
CAS
概念
CAS的全称是Compare-And-Swap,它是CPU并发原语
它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的
CAS并发原语体现在Java语言中就是sun.misc.Unsafe类的各个方法。调用UnSafe类中的CAS方法,JVM会帮我们实现出CAS汇编指令,这是一种完全依赖于硬件的功能,通过它实现了原子操作,再次强调,由于CAS是一种系统原语,原语属于操作系统用于范畴,是由若干条指令组成,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致的问题,也就是说CAS是线程安全的。
代码使用
public static void main(String[] args) {
// 创建一个原子类
AtomicInteger atomicInteger = new AtomicInteger(5);
/*
一个是期望值,一个是更新值,但期望值和原来的值相同时,才能够更改
假设三秒前,我拿的是5,也就是expect为5,然后我需要更新成 2019
*/
//true current data: 2019
//false current data: 2019
System.out.println(atomicInteger.compareAndSet(5, 2019) + "\t current data: " + atomicInteger.get());
System.out.println(atomicInteger.compareAndSet(5, 1024) + "\t current data: " + atomicInteger.get());
}
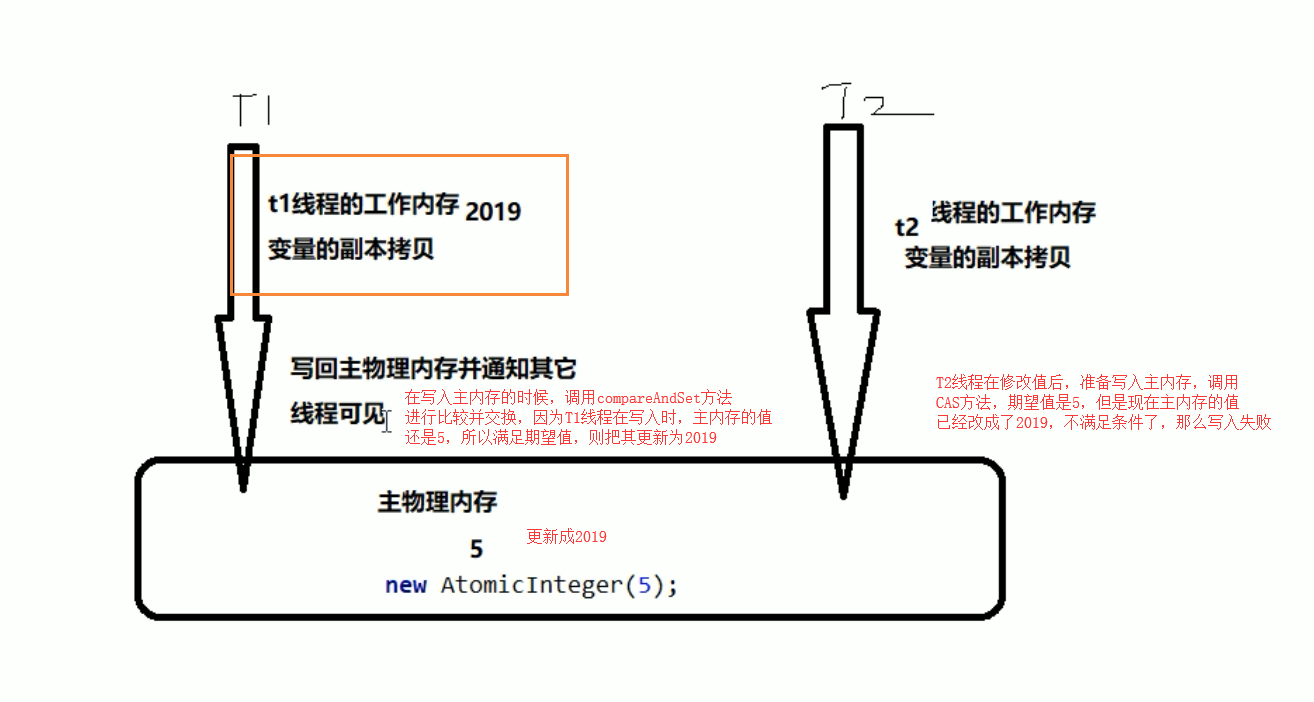
这个就类似于SVN或者Git的版本号,如果没有人更改过,就能够正常提交,否者需要先将代码pull下来,合并代码后,然后提交。
CAS底层原理
Unsafe是CAS的核心类,由于Java方法无法直接访问底层系统,需要通过本地(Native)方法来访问,Unsafe相当于一个后门,基于该类可以直接操作特定的内存数据。Unsafe类存在sun.misc包中,其内部方法操作可以像C的指针一样直接操作内存,因为Java中的CAS操作的执行依赖于Unsafe类的方法。
注意Unsafe类的所有方法都是native修饰的,也就是说unsafe类中的方法都直接调用操作系统底层资源执行相应的任务
为什么Atomic修饰的包装类,能够保证原子性,依靠的就是底层的unsafe类
//AtomicInteger.class
public final int getAndIncrement() {
//this:当前对象
//valueOffset:内存偏移地址
return unsafe.getAndAddInt(this, valueOffset, 1);
}
//UnSafe.class
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
var5:就是我们从主内存中拷贝到工作内存中的值(每次都要从主内存拿到最新的值到自己的本地内存,然后执行compareAndSwapInt()在再和主内存的值进行比较。因为线程不可以直接越过高速缓存,直接操作主内存,所以执行上述方法需要比较一次,在执行加1操作)
那么操作的时候,需要比较工作内存中的值,和主内存中的值进行比较
假设执行 compareAndSwapInt返回false,那么就一直执行 while方法,直到期望的值和真实值一样
- val1:AtomicInteger对象本身
- var2:该对象值得引用地址
- var4:需要变动的数量
- var5:用var1和var2找到的内存中的真实值
- 用该对象当前的值与var5比较
- 如果相同,更新var5 + var4 并返回true
- 如果不同,继续取值然后再比较,直到更新完成
这里没有用synchronized,而用CAS,这样提高了并发性,也能够实现一致性,是因为每个线程进来后,进入的do while循环,然后不断的获取内存中的值,判断是否为最新,然后在进行更新操作。
假设线程A和线程B同时执行getAndInt操作(分别跑在不同的CPU上)
- AtomicInteger里面的value原始值为3,即主内存中AtomicInteger的 value 为3,根据JMM模型,线程A和线程B各自持有一份价值为3的副本,分别存储在各自的工作内存
- 线程A通过getIntVolatile(var1 , var2) 拿到value值3,这是线程A被挂起(该线程失去CPU执行权)
- 线程B也通过getIntVolatile(var1, var2)方法获取到value值也是3,此时刚好线程B没有被挂起,并执行了compareAndSwapInt方法,比较内存的值也是3,成功修改内存值为4,线程B打完收工,一切OK
- 这是线程A恢复,执行CAS方法,比较发现自己手里的数字3和主内存中的数字4不一致,说明该值已经被其它线程抢先一步修改过了,那么A线程本次修改失败,只能够重新读取后在来一遍了,也就是在执行do while
- 线程A重新获取value值,因为变量value被volatile修饰,所以其它线程对它的修改,线程A总能够看到,线程A继续执行compareAndSwapInt进行比较替换,直到成功。
Unsafe类 + CAS思想: 也就是自旋,自我旋转
底层汇编
Unsafe类中的compareAndSwapInt是一个本地方法,该方法的实现位于unsafe.cpp中
- 先想办法拿到变量value在内存中的地址
- 通过Atomic::cmpxchg实现比较替换,其中参数X是即将更新的值,参数e是原内存的值
CAS缺点
CAS不加锁,保证一次性,但是需要多次比较
- 循环时间长,开销大(因为执行的是do while,如果比较不成功一直在循环,最差的情况,就是某个线程一直取到的值和预期值都不一样,这样就会无限循环)
- 只能保证一个共享变量的原子操作
- 当对一个共享变量执行操作时,我们可以通过循环CAS的方式来保证原子操作
- 但是对于多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候只能用锁来保证原子性
- 引出来ABA问题?
总结
CAS
CAS是compareAndSwap,比较当前工作内存中的值和主物理内存中的值,如果相同则执行规定操作,否者继续比较直到主内存和工作内存的值一致为止
CAS应用
CAS有3个操作数,内存值V,旧的预期值A,要修改的更新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否者什么都不做
原子类AtomicInteger的ABA问题
连环套路
从AtomicInteger引出下面的问题
CAS -> Unsafe -> CAS底层思想 -> ABA -> 原子引用更新 -> 如何规避ABA问题
ABA问题是什么
假设现在有两个线程,分别是T1 和 T2,然后T1执行某个操作的时间为10秒,T2执行某个时间的操作是2秒,最开始AB两个线程,分别从主内存中获取A值,但是因为B的执行速度更快,他先把A的值改成B,然后在修改成A,然后执行完毕,T1线程在10秒后,执行完毕,判断内存中的值为A,并且和自己预期的值一样,它就认为没有人更改了主内存中的值,就快乐的修改成B,但是实际上 可能中间经历了 ABCDEFA 这个变换,也就是中间的值经历了狸猫换太子。
所以ABA问题就是,在进行获取主内存值的时候,该内存值在我们写入主内存的时候,已经被修改了N次,但是最终又改成原来的值了
CAS导致ABA问题
CAS算法实现了一个重要的前提,需要取出内存中某时刻的数据,并在当下时刻比较并替换,那么这个时间差会导致数据的变化。
比如说一个线程one从内存位置V中取出A,这时候另外一个线程two也从内存中取出A,并且线程two进行了一些操作将值变成了B,然后线程two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后线程one操作成功
尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的
CAS只管开头和结尾,也就是头和尾是一样,那就修改成功,中间的这个过程,可能会被人修改过
原子引用
原子引用其实和原子包装类是差不多的概念,就是将一个java类,用原子引用类进行包装起来,那么这个类就具备了原子性。
public class Main {
public static void main(String[] args) {
User user1 = new User("user1", 22);
User user2 = new User("user2", 25);
// 创建原子引用包装类,现在主物理内存的共享变量,为user1
AtomicReference<User> atomicReference = new AtomicReference<>(user1);
// 比较并交换,如果现在主物理内存的值为user1,那么交换成user2
System.out.println(atomicReference.compareAndSet(user1, user2) + "\t" + atomicReference.get());
// 比较并交换,现在主物理内存的值是user2了,但是预期为user1,因此交换失败
System.out.println(atomicReference.compareAndSet(user1, user2) + "\t" + atomicReference.get());
}
}
class User {
String userName;
int age;
public User(String userName, int age) {
this.userName = userName;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"userName='" + userName + '\'' +
", age=" + age +
'}';
}
}
解决ABA问题
新增一种机制,也就是修改版本号,类似于时间戳的概念
AtomicStampedReference
时间戳原子引用,来这里应用于版本号的更新,也就是每次更新的时候,需要比较期望值和当前值,以及期望版本号和当前版本号
// 传递两个值,一个是初始值,一个是初始版本号
static AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(100, 1);
public static void main(String[] args) {
System.out.println("============以下是ABA问题的解决==========");
new Thread(() -> {
// 获取版本号
int stamp = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + "\t 第一次版本号" + stamp);
// 暂停t3一秒钟
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 传入4个值,期望值,更新值,期望版本号,更新版本号
atomicStampedReference.compareAndSet(100, 101, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1);
System.out.println(Thread.currentThread().getName() + "\t 第二次版本号" + atomicStampedReference.getStamp());
atomicStampedReference.compareAndSet(101, 100, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1);
System.out.println(Thread.currentThread().getName() + "\t 第三次版本号" + atomicStampedReference.getStamp());
}, "t3").start();
new Thread(() -> {
// 获取版本号
int stamp = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName() + "\t 第一次版本号" + stamp);
// 暂停t4 3秒钟,保证t3线程也进行一次ABA问题
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
boolean result = atomicStampedReference.compareAndSet(100, 2019, stamp, stamp + 1);
System.out.println(Thread.currentThread().getName() + "\t 修改成功否:" + result + "\t 当前最新实际版本号:" + atomicStampedReference.getStamp());
System.out.println(Thread.currentThread().getName() + "\t 当前实际最新值" + atomicStampedReference.getReference());
}, "t4").start();
}
我们能够发现,线程t3,在进行ABA操作后,版本号变更成了3,而线程t4在进行操作的时候,就出现操作失败了,因为版本号和当初拿到的不一样
LongAdder(CAS机制优化)
LongAdder是java8为我们提供的新的类,跟AtomicLong有相同的效果。是对CAS机制的优化
Java锁
Java锁之公平锁和非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁,类似于排队买饭,先来后到,先来先服务,就是公平的,也就是队列
非公平锁是指多个线程获取锁的顺序,并不是按照申请锁的顺序,有可能申请的线程比先申请的线程优先获取锁,在高并发环境下,有可能造成优先级翻转,或者饥饿的线程(也就是某个线程一直得不到锁)
两者区别:
公平锁:就是很公平,在并发环境中,每个线程在获取锁时会先查看此锁维护的等待队列,如果为空,或者当前线程是等待队列中的第一个,就占用锁,否者就会加入到等待队列中,以后安装FIFO的规则从队列中取到自己
非公平锁: 非公平锁比较粗鲁,上来就直接尝试占有锁,如果尝试失败,就再采用类似公平锁那种方式。
可重入锁和递归锁ReentrantLock
可重入锁就是递归锁
指的是同一线程外层函数获得锁之后,内层递归函数仍然能获取到该锁的代码,在同一线程在外层方法获取锁的时候,在进入内层方法会自动获取锁
也就是说:线程可以进入任何一个它已经拥有的锁所同步的代码块
ReentrantLock / Synchronized 就是一个典型的可重入锁
可重入锁的最大作用就是避免死锁
Synchronized的重入的实现机理
每个锁对象拥有一个锁计数器和一个指向持有该锁的线程的指针。
当执行monitorenter时,如果目标锁对象的计数器为零,那么说明它没有被其他线程所持有,Java虚拟机会将该锁对象的持有线程设置为当前线程,并且将其计数器加1。
在目标锁对象的计数器不为零的情况下,如果锁对象的持有线程是当前线程,那么Java虚拟机可以将其计数器加1,否则需要等待,直至持有线程释放该锁。
当执行monitorexit时,Java虚拟机则需将锁对象的计数器减1。计数器为零代表锁已被释放。
Java锁之自旋锁
自旋锁:spinlock,是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU
原来提到的比较并交换,底层使用的就是自旋,自旋就是多次尝试,多次访问,不会阻塞的状态就是自旋。
优点:循环比较获取直到成功为止,没有类似于wait的阻塞
缺点:当不断自旋的线程越来越多的时候,会因为执行while循环不断的消耗CPU资源
手写自旋锁:
public class Main {
// 现在的泛型装的是Thread,原子引用线程
AtomicReference<Thread> atomicReference = new AtomicReference<>();
/**
* 加锁
*/
public void myLock() {
// 获取当前进来的线程
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName() + "\t come in ");
// 开始自旋,期望值是null,更新值是当前线程,如果是null,则更新为当前线程,否者自旋
while (!atomicReference.compareAndSet(null, thread)) {
}
}
/**
* 解锁
*/
public void myUnLock() {
// 获取当前进来的线程
Thread thread = Thread.currentThread();
// 自己用完了后,把atomicReference变成null
atomicReference.compareAndSet(thread, null);
System.out.println(Thread.currentThread().getName() + "\t invoked myUnlock()");
}
public static void main(String[] args) {
Main main = new Main();
// 启动t1线程,开始操作
new Thread(() -> {
// 开始占有锁
main.myLock();
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 开始释放锁
main.myUnLock();
}, "t1").start();
// 让main线程暂停1秒,使得t1线程,先执行
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 1秒后,启动t2线程,开始占用这个锁
new Thread(() -> {
// 开始占有锁
main.myLock();
// 开始释放锁
main.myUnLock();
}, "t2").start();
}
}
独占锁(写锁) / 共享锁(读锁) / 互斥锁
概念:
独占锁:指该锁一次只能被一个线程所持有。对ReentrantLock和Synchronized而言都是独占锁
共享锁:指该锁可以被多个线程锁持有
对ReentrantReadWriteLock其读锁是共享,其写锁是独占
写的时候只能一个人写,但是读的时候,可以多个人同时读
为什么会有写锁和读锁:
原来我们使用ReentrantLock创建锁的时候,是独占锁,也就是说一次只能一个线程访问,但是有一个读写分离场景,读的时候想同时进行,因此原来独占锁的并发性就没这么好了,因为读锁并不会造成数据不一致的问题,因此可以多个人共享读
多个线程 同时读一个资源类没有任何问题,所以为了满足并发量,读取共享资源应该可以同时进行,但是如果一个线程想去写共享资源,就不应该再有其它线程可以对该资源进行读或写
读-读:能共存
读-写:不能共存
写-写:不能共存
代码实现:
实现一个读写缓存的操作,假设开始没有加锁的时候,会出现什么情况
public class Main {
public static void main(String[] args) {
MyCache myCache = new MyCache();
// 线程操作资源类,5个线程写
for (int i = 0; i < 5; i++) {
// lambda表达式内部必须是final
final int tempInt = i;
new Thread(() -> {
myCache.put(tempInt + "", tempInt + "");
}, String.valueOf(i)).start();
}
// 线程操作资源类, 5个线程读
for (int i = 0; i < 5; i++) {
// lambda表达式内部必须是final
final int tempInt = i;
new Thread(() -> {
myCache.get(tempInt + "");
}, String.valueOf(i)).start();
}
}
}
/**
* 资源类
*/
class MyCache {
private final Map<String, Object> map = new HashMap<>();
// private Lock lock = null;
/**
* 定义写操作
* 满足:原子 + 独占
*/
public void put(String key, Object value) {
System.out.println(Thread.currentThread().getName() + "\t 正在写入:" + key);
try {
// 模拟网络拥堵,延迟0.3秒
TimeUnit.MILLISECONDS.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "\t 写入完成");
}
public void get(String key) {
System.out.println(Thread.currentThread().getName() + "\t 正在读取:");
try {
// 模拟网络拥堵,延迟0.3秒
TimeUnit.MILLISECONDS.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
Object value = map.get(key);
System.out.println(Thread.currentThread().getName() + "\t 读取完成:" + value);
}
}
我们可以看到,在写入的时候,写操作都没完成就被其它线程打断了,这就造成了还没写完,其它线程又开始写,这样就造成数据不一致。
解决方法:
public class Main {
public static void main(String[] args) {
MyCache myCache = new MyCache();
// 线程操作资源类,5个线程写
for (int i = 0; i < 5; i++) {
// lambda表达式内部必须是final
final int tempInt = i;
new Thread(() -> {
myCache.put(tempInt + "", tempInt + "");
}, String.valueOf(i)).start();
}
// 线程操作资源类, 5个线程读
for (int i = 0; i < 5; i++) {
// lambda表达式内部必须是final
final int tempInt = i;
new Thread(() -> {
myCache.get(tempInt + "");
}, String.valueOf(i)).start();
}
}
}
/**
* 资源类
*/
class MyCache {
/**
* 缓存中的东西,必须保持可见性,因此使用volatile修饰
*/
private volatile Map<String, Object> map = new HashMap<>();
/**
* 创建一个读写锁
* 它是一个读写融为一体的锁,在使用的时候,需要转换
*/
private ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();
/**
* 定义写操作
* 满足:原子 + 独占
*/
public void put(String key, Object value) {
// 创建一个写锁
rwLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\t 正在写入:" + key);
try {
// 模拟网络拥堵,延迟0.3秒
TimeUnit.MILLISECONDS.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "\t 写入完成");
} catch (Exception e) {
e.printStackTrace();
} finally {
// 写锁 释放
rwLock.writeLock().unlock();
}
}
/**
* 获取
*/
public void get(String key) {
// 读锁
rwLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\t 正在读取:");
try {
// 模拟网络拥堵,延迟0.3秒
TimeUnit.MILLISECONDS.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
Object value = map.get(key);
System.out.println(Thread.currentThread().getName() + "\t 读取完成:" + value);
} catch (Exception e) {
e.printStackTrace();
} finally {
// 读锁释放
rwLock.readLock().unlock();
}
}
/**
* 清空缓存
*/
public void clean() {
map.clear();
}
}
从运行结果我们可以看出,写入操作是一个一个线程进行执行的,并且中间不会被打断,而读操作的时候,是同时5个线程进入,然后并发读取操作
死锁
产生死锁的原因:
- 系统资源不足
- 进程运行推进的顺序不对
- 资源分配不当
死锁产生的四个必要条件:
- 互斥
- 解决方法:把互斥的共享资源封装成可同时访问
- 占有且等待
- 解决方法:进程请求资源时,要求它不占有任何其它资源,也就是它必须一次性申请到所有的资源,这种方式会导致资源效率低。
- 非抢占式
- 解决方法:如果进程不能立即分配资源,要求它不占有任何其他资源,也就是只能够同时获得所有需要资源时,才执行分配操作
- 循环等待
- 解决方法:对资源进行排序,要求进程按顺序请求资源。
演示:
public static void main(String[] args) {
Object o1 = new Object();
Object o2 = new Object();
new Thread(() -> {
synchronized (o1) {
try {
TimeUnit.SECONDS.sleep(2);
synchronized (o2) {
TimeUnit.SECONDS.sleep(2);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
new Thread(() -> {
synchronized (o2) {
try {
TimeUnit.SECONDS.sleep(2);
synchronized (o1) {
TimeUnit.SECONDS.sleep(2);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
查看是否死锁工具:
- jps -l命令定位进程号
- jstack 进程号 找到死锁查看
为什么Synchronized无法禁止指令重排,却能保证有序性
首先我们要分析下这道题,这简单的一个问题,其实里面还是包含了很多信息的,要想回答好这个问题,面试者至少要知道一下概念:
- Java内存模型
- 并发编程有序性问题
- 指令重排
- synchronized锁
- 可重入锁
- 排它锁
- as-if-serial语义
- 单线程&多线程
标准解答:
为了进一步提升计算机各方面能力,在硬件层面做了很多优化,如处理器优化和指令重排等,但是这些技术的引入就会导致有序性问题。
先解释什么是有序性问题,也知道是什么原因导致的有序性问题
我们也知道,最好的解决有序性问题的办法,就是禁止处理器优化和指令重排,就像volatile中使用内存屏障一样。
表明你知道啥是指令重排,也知道他的实现原理
但是,虽然很多硬件都会为了优化做一些重排,但是在Java中,不管怎么排序,都不能影响单线程程序的执行结果。这就是as-if-serial语义,所有硬件优化的前提都是必须遵守as-if-serial语义。
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial语义使单线程程序员无需担心重排序会 干扰他们,也无需担心内存可见性问题。
重点!解释下什么是as-if-serial语义,因为这是这道题的第一个关键词,答上来就对了一半了
再说下synchronized,他是Java提供的锁,可以通过他对Java中的对象加锁,并且他是一种排他的、可重入的锁。
所以,当某个线程执行到一段被synchronized修饰的代码之前,会先进行加锁,执行完之后再进行解锁。在加锁之后,解锁之前,其他线程是无法再次获得锁的,只有这条加锁线程可以重复获得该锁。
介绍synchronized的原理,这是本题的第二个关键点,到这里基本就可以拿满分了。
synchronized通过排他锁的方式就保证了同一时间内,被synchronized修饰的代码是单线程执行的。所以呢,这就满足了as-if-serial语义的一个关键前提,那就是单线程,因为有as-if-serial语义保证,单线程的有序性就天然存在了。
JUC工具类
CountDownLatch
让一些线程阻塞直到另一些线程完成一系列操作才被唤醒
CountDownLatch主要有两个方法,当一个或多个线程调用await方法时,调用线程就会被阻塞。其它线程调用CountDown方法会将计数器减1(调用CountDown方法的线程不会被阻塞),当计数器的值变成零时,因调用await方法被阻塞的线程会被唤醒,继续执行
public static void main(String[] args) throws InterruptedException {
// 计数器
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 0; i <= 6; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t 上完自习,离开教室");
countDownLatch.countDown();
}, String.valueOf(i)).start();
}
countDownLatch.await();
System.out.println(Thread.currentThread().getName() + "\t 班长最后关门");
}
CyclicBarrier
和CountDownLatch相反,需要集齐七颗龙珠,召唤神龙。也就是做加法,开始是0,加到某个值的时候就执行
CyclicBarrier的字面意思就是可循环(cyclic)使用的屏障(Barrier)。它要求做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活,线程进入屏障通过CyclicBarrier的await方法
public static void main(String[] args) {
/*
定义一个循环屏障,参数1:需要累加的值,参数2 需要执行的方法
*/
CyclicBarrier cyclicBarrier = new CyclicBarrier(7, () -> {
System.out.println("召唤神龙");
});
for (int i = 0; i < 7; i++) {
final int tempInt = i;
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t 收集到 第" + tempInt + "颗龙珠");
try {
// 先到的被阻塞,等全部线程完成后,才能执行方法
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}, String.valueOf(i)).start();
}
}
Semaphore:信号量
信号量主要用于两个目的
- 一个是用于共享资源的互斥使用
- 另一个用于并发线程数的控制
public static void main(String[] args) {
/*
初始化一个信号量为3,默认是false 非公平锁, 模拟3个停车位
*/
Semaphore semaphore = new Semaphore(3, false);
// 模拟6部车
for (int i = 0; i < 6; i++) {
new Thread(() -> {
try {
// 代表一辆车,已经占用了该车位
semaphore.acquire(); // 抢占
System.out.println(Thread.currentThread().getName() + "\t 抢到车位");
// 每个车停3秒
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "\t 离开车位");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放停车位
semaphore.release();
}
}, String.valueOf(i)).start();
}
}
阻塞队列
线程1往阻塞队列中添加元素,而线程2从阻塞队列中移除元素
当阻塞队列是空时,从队列中获取元素的操作将会被阻塞- 当蛋糕店的柜子空的时候,无法从柜子里面获取蛋糕
当阻塞队列是满时,从队列中添加元素的操作将会被阻塞- 当蛋糕店的柜子满的时候,无法继续向柜子里面添加蛋糕了
也就是说 试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其它线程往空的队列插入新的元素
同理,试图往已经满的阻塞队列中添加新元素的线程,直到其它线程往满的队列中移除一个或多个元素,或者完全清空队列后,使队列重新变得空闲起来,并后续新增
为什么需要BlockingQueue
好处是我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切BlockingQueue都帮你一手包办了
架构
BlockingQueue阻塞队列是属于一个接口,底下有七个实现类
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MmxVL5VS-1645518544306)(D:\wanghua\笔记\面试题.assets\image-20220219124554514.png)]
- ArrayBlockingQueue:由数组结构组成的有界阻塞队列
- LinkedBlockingQueue:由链表结构组成的有界(但是默认大小 Integer.MAX_VALUE)的阻塞队列
- 有界,但是界限非常大,相当于无界,可以当成无界
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列
- DelayQueue:使用优先级队列实现的延迟无界阻塞队列
- SynchronousQueue:不存储元素的阻塞队列,也即单个元素的队列
- 生产一个,消费一个,不存储元素,不消费不生产
- LinkedTransferQueue:由链表结构组成的无界阻塞队列
- LinkedBlockingDeque:由链表结构组成的双向阻塞队列
这里需要掌握的是:ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue
BlockingQueue核心方法
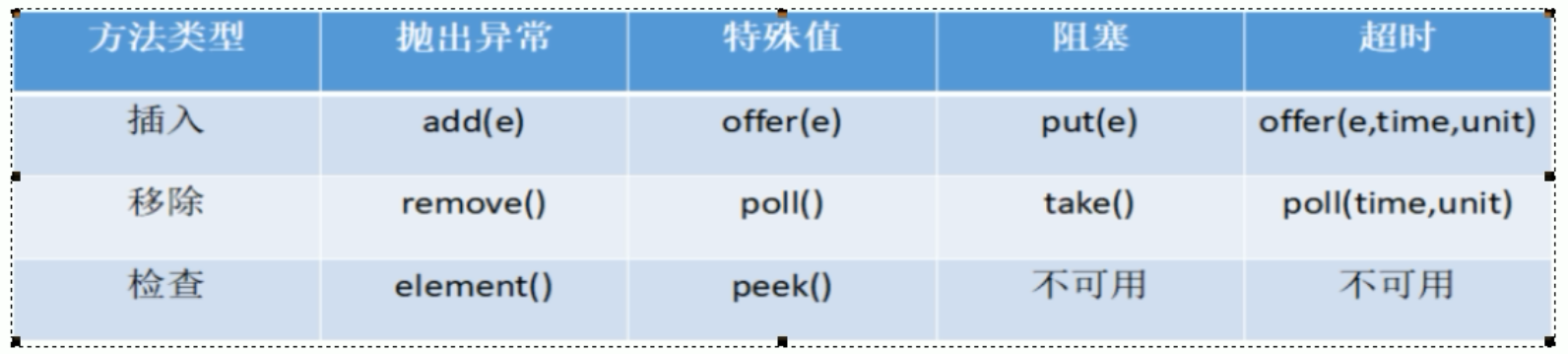
| 抛出异常 | 当阻塞队列满时:在往队列中add插入元素会抛出 IIIegalStateException:Queue full 当阻塞队列空时:再往队列中remove移除元素,会抛出NoSuchException |
|---|---|
| 特殊性 | 插入方法,成功true,失败false 移除方法:成功返回出队列元素,队列没有就返回空 |
| 一直阻塞 | 当阻塞队列满时,生产者继续往队列里put元素,队列会一直阻塞生产线程直到put数据or响应中断退出, 当阻塞队列空时,消费者线程试图从队列里take元素,队列会一直阻塞消费者线程直到队列可用。 |
| 超时退出 | 当阻塞队列满时,队里会阻塞生产者线程一定时间,超过限时后生产者线程会退出 |
SynchronousQueue
SynchronousQueue没有容量,与其他BlockingQueue不同,SynchronousQueue是一个不存储的BlockingQueue,每一个put操作必须等待一个take操作,否者不能继续添加元素
生产者消费者模式
一个初始值为0的变量,两个线程对其交替操作,一个加1,一个减1,来5轮
关于多线程的操作,我们需要记住下面几句
- 线程 操作 资源类
- 判断 干活 通知
- 防止虚假唤醒机制
传统版:
public class Main {
public static void main(String[] args) {
final int times = 10;
Data data = new Data();
new Thread(() -> {
for (int i = 0; i < times; i++) {
try {
data.increment();
} catch (Exception e) {
e.printStackTrace();
}
}
}, "T1").start();
new Thread(() -> {
for (int i = 0; i < times; i++) {
try {
data.decrement();
} catch (Exception e) {
e.printStackTrace();
}
}
}, "T2").start();
}
}
/**
* 资源类
*/
class Data {
private int number = 0;
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void increment() throws Exception {
// 同步代码块,加锁
lock.lock();
try {
// 判断
while (number != 0) {
// 等待不能生产
condition.await();
}
// 干活
number++;
System.out.println(Thread.currentThread().getName() + "\t " + number);
// 通知 唤醒
condition.signalAll();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void decrement() throws Exception {
// 同步代码块,加锁
lock.lock();
try {
// 判断
while (number == 0) {
// 等待不能消费
condition.await();
}
// 干活
number--;
System.out.println(Thread.currentThread().getName() + "\t " + number);
// 通知 唤醒
condition.signalAll();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
阻塞队列版:
使用:volatile、CAS、atomicInteger、BlockQueue、线程交互、原子引用
有点问题待解决,可能出现消费者先于生产者的情况
public class Test {
public static void main(String[] args) {
// 传入具体的实现类, ArrayBlockingQueue
MyResource myResource = new MyResource(new ArrayBlockingQueue<>(3));
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t 生产线程启动");
try {
myResource.myProduct();
} catch (Exception e) {
e.printStackTrace();
}
}, "product").start();
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t 消费线程启动");
try {
myResource.myConsumer();
} catch (Exception e) {
e.printStackTrace();
}
}, "consumer").start();
// 5秒后,停止生产和消费
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("5秒中后,生产和消费线程停止,线程结束");
myResource.stop();
}
}
class MyResource {
// 默认开启,进行生产消费
// 这里用到了volatile是为了保持数据的可见性,也就是当FLAG修改时,要马上通知其它线程进行修改
private volatile boolean FLAG = true;
// 使用原子包装类,而不用number++
private AtomicInteger atomicInteger = new AtomicInteger();
// 这里不能为了满足条件,而实例化一个具体的SynchronousBlockingQueue
BlockingQueue<String> blockingQueue;
// 而应该采用依赖注入里面的,构造注入方法传入
public MyResource(BlockingQueue<String> blockingQueue) {
this.blockingQueue = blockingQueue;
// 查询出传入的class是什么
System.out.println(blockingQueue.getClass().getName());
}
/**
* 生产
*/
public void myProduct() throws Exception {
String data;
boolean retValue;
// 多线程环境的判断,一定要使用while进行,防止出现虚假唤醒
// 当FLAG为true的时候,开始生产
while (FLAG) {
data = atomicInteger.incrementAndGet() + "";
// 2秒存入1个data
retValue = blockingQueue.offer(data, 2L, TimeUnit.SECONDS);
if (retValue) {
System.out.println(Thread.currentThread().getName() + "\t 插入队列:" + data + "成功");
} else {
System.out.println(Thread.currentThread().getName() + "\t 插入队列:" + data + "失败");
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + "\t 停止生产,表示FLAG=false,生产介绍");
}
/**
* 消费
*/
public void myConsumer() throws Exception {
String retValue;
// 多线程环境的判断,一定要使用while进行,防止出现虚假唤醒
// 当FLAG为true的时候,开始生产
while (FLAG) {
// 2秒存入1个data
retValue = blockingQueue.poll(2L, TimeUnit.SECONDS);
if (retValue != null && !retValue.equals("")) {
System.out.println(Thread.currentThread().getName() + "\t 消费队列:" + retValue + "成功");
} else {
FLAG = false;
System.out.println(Thread.currentThread().getName() + "\t 消费失败,队列中已为空,退出");
// 退出消费队列
return;
}
}
}
/**
* 停止生产的判断
*/
public void stop() {
this.FLAG = false;
}
}
Synchronized和Lock有什么区别
- synchronized属于JVM层面,属于java的关键字
monitorenter(底层是通过monitor对象来完成,其实wait/notify等方法也依赖于monitor对象 只能在同步块或者方法中才能调用 wait/ notify等方法)
Lock是具体类(java.util.concurrent.locks.Lock)是api层面的锁
- 使用方法:
synchronized:不需要用户去手动释放锁,当synchronized代码执行后,系统会自动让线程释放对锁的占用。
ReentrantLock:则需要用户去手动释放锁,若没有主动释放锁,就有可能出现死锁的现象,需要lock() 和 unlock() 配置try catch语句来完成
- 等待是否中断
synchronized:不可中断,除非抛出异常或者正常运行完成。
ReentrantLock:可中断,可以设置超时方法
设置超时方法,trylock(long timeout, TimeUnit unit)
lockInterrupible() 放代码块中,调用interrupt() 方法可以中断
- 加锁是否公平
synchronized:非公平锁
ReentrantLock:默认非公平锁,构造函数可以传递boolean值,true为公平锁,false为非公平锁
- 锁绑定多个条件Condition
synchronized:没有,要么随机,要么全部唤醒
ReentrantLock:用来实现分组唤醒需要唤醒的线程,可以精确唤醒,而不是像synchronized那样,要么随机,要么全部唤醒
例题:三个线程交替打印,A打印5次,B打印10次,C打印15次,循环10轮
public class Test {
/**
* 三个线程交替打印,A打印5次,B打印10次,C打印15次,循环10轮
*/
public static void main(String[] args) {
ShareResource shareResource = new ShareResource();
int times = 10;
new Thread(() -> {
for (int i = 0; i < times; i++) {
shareResource.print5();
}
}, "A").start();
new Thread(() -> {
for (int i = 0; i < times; i++) {
shareResource.print10();
}
}, "B").start();
new Thread(() -> {
for (int i = 0; i < times; i++) {
shareResource.print15();
}
}, "C").start();
}
}
class ShareResource {
// A 1 B 2 c 3
private int number = 1;
// 创建一个重入锁
private Lock lock = new ReentrantLock();
// 这三个相当于备用钥匙
private Condition condition1 = lock.newCondition();
private Condition condition2 = lock.newCondition();
private Condition condition3 = lock.newCondition();
public void print5() {
lock.lock();
try {
// 判断
while (number != 1) {
// 不等于1,需要等待
condition1.await();
}
// 干活
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + "\t " + number + "\t" + i);
}
// 唤醒 (干完活后,需要通知B线程执行)
number = 2;
// 通知2号去干活了
condition2.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void print10() {
lock.lock();
try {
// 判断
while (number != 2) {
// 不等于1,需要等待
condition2.await();
}
// 干活
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "\t " + number + "\t" + i);
}
// 唤醒 (干完活后,需要通知C线程执行)
number = 3;
// 通知2号去干活了
condition3.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void print15() {
lock.lock();
try {
// 判断
while (number != 3) {
// 不等于1,需要等待
condition3.await();
}
// 干活
for (int i = 0; i < 15; i++) {
System.out.println(Thread.currentThread().getName() + "\t " + number + "\t" + i);
}
// 唤醒 (干完活后,需要通知C线程执行)
number = 1;
// 通知1号去干活了
condition1.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
线程池
Callable接口
基本使用:
//FutureTask构造器传入的是Callable接口的实现类
FutureTask<String> futureTask = new FutureTask<>(() -> "AA");
new Thread(futureTask, "T1").start();
System.out.println(futureTask.get());
多个线程执行 一个FutureTask的时候,只会计算一次
线程池使用及优势
线程池做的主要工作就是控制运行的线程的数量,处理过程中,将任务放入到队列中,然后线程创建后,启动这些任务,如果线程数量超过了最大数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。
它的主要特点为:线程复用、控制最大并发数、管理线程
线程池中的任务是放入到阻塞队列中的
多核处理的好处是:省略的上下文的切换开销
原来我们实例化对象的时候,是使用 new关键字进行创建,到了Spring后,我们学了IOC依赖注入,发现Spring帮我们将对象已经加载到了Spring容器中,只需要通过@Autowrite注解,就能够自动注入,从而使用
因此使用多线程有下列的好处
- 降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就立即执行
- 提高线程的可管理性。线程是稀缺资源,如果无线创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
查看CPU核数:System.out.println(Runtime.getRuntime().availableProcessors());
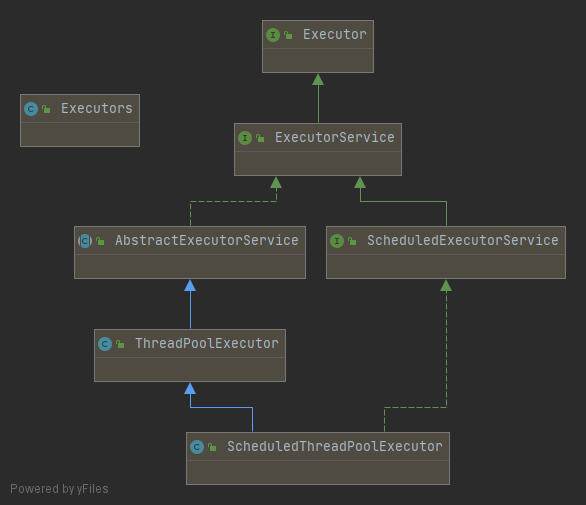
架构
Java中线程池是通过Executor框架实现的,该框架中用到了Executor,Executors(代表工具类),ExecutorService,ThreadPoolExecutor这几个类。
创建线程池
- Executors.newFixedThreadPool(int i) :创建一个拥有 i 个线程的线程池
- 执行长期的任务,性能好很多
- 创建一个定长线程池,可控制线程数最大并发数,超出的线程会在队列中等待
- Executors.newSingleThreadExecutor:创建一个只有1个线程的 单线程池
- 一个任务一个任务执行的场景
- 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行
- Executors.newCacheThreadPool(); 创建一个可扩容的线程池
- 执行很多短期异步的小程序或者负载教轻的服务器
- 创建一个可缓存线程池,如果线程长度超过处理需要,可灵活回收空闲线程,如无可回收,则新建新线程
- Executors.newScheduledThreadPool(int corePoolSize):线程池支持定时以及周期性执行任务,创建一个corePoolSize为传入参数,最大线程数为整形的最大数的线程池
public static void main(String[] args) throws Exception {
// 一池5个处理线程(用池化技术,一定要记得关闭)
ExecutorService threadPool = Executors.newFixedThreadPool(5);
// 模拟10个用户来办理业务,每个用户就是一个来自外部请求线程
try {
// 循环十次,模拟业务办理,让5个线程处理这10个请求
for (int i = 0; i < 10; i++) {
final int tempInt = i;
threadPool.execute(() -> System.out.println(Thread.currentThread().getName() + "\t 给用户:" + tempInt + " 办理业务"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
线程池7大参数
- corePoolSize:核心线程数,线程池中的常驻核心线程数
- 在创建线程池后,当有请求任务来之后,就会安排池中的线程去执行请求任务,近似理解为今日当值线程
- 当线程池中的线程数目达到corePoolSize后,就会把到达的队列放到缓存队列中
- maximumPoolSize:线程池能够容纳同时执行的最大线程数,此值必须大于等于1、
- 相当有扩容后的线程数,这个线程池能容纳的最多线程数
- keepAliveTime:多余的空闲线程存活时间
- 当线程池数量超过corePoolSize时,当空闲时间达到keepAliveTime值时,多余的空闲线程会被销毁,直到只剩下corePoolSize个线程为止
- 默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用
- unit:keepAliveTime的单位
- workQueue:任务队列,被提交的但未被执行的任务(类似于银行里面的候客区)
- LinkedBlockingQueue:链表阻塞队列
- SynchronousBlockingQueue:同步阻塞队列
- threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程池 一般用默认即可
- handler:拒绝策略,表示当队列满了并且工作线程大于线程池的最大线程数(maximumPoolSize3)时,如何来拒绝请求执行的Runnable的策略
拒绝策略
以下所有拒绝策略都实现了RejectedExecutionHandler接口
- AbortPolicy:默认,直接抛出RejectedExcutionException异常,阻止系统正常运行
- DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常,如果运行任务丢失,这是一种好方案
- CallerRunsPolicy:该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者
- DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务
线程池底层工作原理
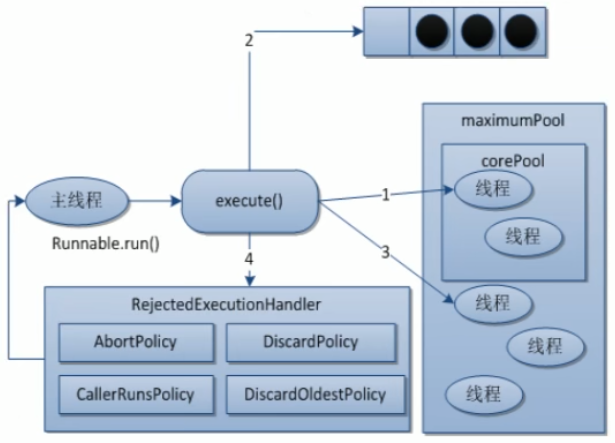
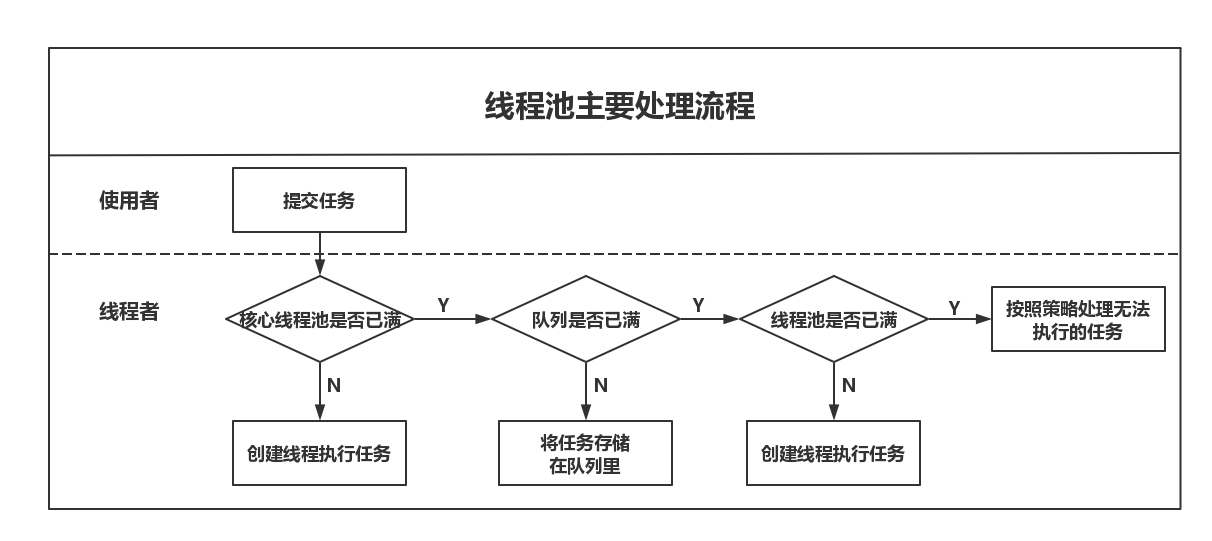
文字说明
- 在创建了线程池后,等待提交过来的任务请求
- 当调用execute()方法添加一个请求任务时,线程池会做出如下判断
- 如果正在运行的线程池数量小于corePoolSize,那么马上创建线程运行这个任务
- 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列
- 如果这时候队列满了,并且正在运行的线程数量还小于maximumPoolSize,那么还是创建非核心线程立即运行这个任务;
- 如果队列满了并且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行
- 当一个线程完成任务时,它会从队列中取下一个任务来执行
- 当一个线程无事可做操作一定的时间(keepAliveTime)时,线程池会判断:
- 如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉
- 所以线程池的所有任务完成后,它会最终收缩到corePoolSize的大小
为什么不用默认创建的线程池?
线程池创建的方法有:固定数的,单一的,可变的,那么在实际开发中,应该使用哪个?
我们一个都不用,在生产环境中是使用自己自定义的
为什么不用 Executors 中JDK提供的?
根据阿里巴巴手册:并发控制这章
- 线程资源必须通过线程池提供,不允许在应用中自行显式创建线程
- 使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题,如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题
- 线程池不允许使用Executors去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
- Executors返回的线程池对象弊端如下:
- FixedThreadPool和SingleThreadPool:
- 运行的请求队列长度为:Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM
- CacheThreadPool和ScheduledThreadPool
- 运行的请求队列长度为:Integer.MAX_VALUE,线程数上限太大导致oom
- FixedThreadPool和SingleThreadPool:
- Executors返回的线程池对象弊端如下:
线程池的合理参数
生产环境中如何配置 corePoolSize 和 maximumPoolSize
这个是根据具体业务来配置的,分为CPU密集型和IO密集型
- CPU密集型
CPU密集的意思是该任务需要大量的运算,而没有阻塞,CPU一直全速运行
CPU密集任务只有在真正的多核CPU上才可能得到加速(通过多线程)
而在单核CPU上,无论你开几个模拟的多线程该任务都不可能得到加速,因为CPU总的运算能力就那些
CPU密集型任务配置尽可能少的线程数量:
一般公式:CPU核数 + 1个线程数
- IO密集型
由于IO密集型任务线程并不是一直在执行任务,则可能多的线程,如 CPU核数 * 2
IO密集型,即该任务需要大量的IO操作,即大量的阻塞
在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力花费在等待上
所以IO密集型任务中使用多线程可以大大的加速程序的运行,即使在单核CPU上,这种加速主要就是利用了被浪费掉的阻塞时间。
IO密集时,大部分线程都被阻塞,故需要多配置线程数:
参考公式:CPU核数 / (1 - 阻塞系数) 阻塞系数在0.8 ~ 0.9左右
例如:8核CPU:8/ (1 - 0.9) = 80个线程数
LockSupport
LockSupport是用来创建锁和其他同步类的基本线程阻塞原语。
LockSupport中的park()和 unpark()的作用分别是阻塞线程和解除阻塞线程。
总之,比wait/notify,await/signal更强。
3种让线程等待和唤醒的方法
- 方式1:使用Object中的wait()方法让线程等待,使用object中的notify()方法唤醒线程
- 方式2:使用JUC包中Condition的await()方法让线程等待,使用signal()方法唤醒线程
- 方式3:LockSupport类可以阻塞当前线程以及唤醒指定被阻塞的线程
Object类中的wait和notify方法实现线程等待和唤醒:
static final Object lock = new Object();
public static void main(String[] args) {
new Thread(() -> {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + " come in.");
try {
lock.wait();
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + " 换醒.");
}, "Thread A").start();
new Thread(() -> {
synchronized (lock) {
lock.notify();
System.out.println(Thread.currentThread().getName() + " 通知.");
}
}, "Thread B").start();
}
Thread A come in.
Thread B 通知.
Thread A 换醒.
wait和notify方法必须要在同步块或者方法里面且成对出现使用,否则会抛出java.lang.IllegalMonitorStateException。调用顺序要先wait后notify才OK。
Condition接口中的await后signal方法实现线程的等待和唤醒:
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Condition condition = lock.newCondition();
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " come in.");
lock.lock();
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
System.out.println(Thread.currentThread().getName() + " 唤醒.");
}, "Thread A").start();
new Thread(() -> {
try {
lock.lock();
condition.signal();
System.out.println(Thread.currentThread().getName() + " 通知.");
} finally {
lock.unlock();
}
}, "Thread B").start();
}
Thread A come in.
Thread B 通知.
Thread A 唤醒.
传统的synchronized和Lock实现等待唤醒通知的约束
- 线程先要获得并持有锁,必须在锁块(synchronized或lock)中
- 必须要先等待后唤醒,线程才能够被唤醒
LockSupport类中的park等待和unpark唤醒:
LockSupport是用来创建锁和其他同步类的基本线程阻塞原语。
LockSupport类使用了一种名为Permit(许可)的概念来做到阻塞和唤醒线程的功能,每个线程都有一个许可(permit),permit只有两个值1和零,默认是零。
可以把许可看成是一种(0.1)信号量(Semaphore),但与Semaphore不同的是,许可的累加上限是1。
通过park()和unpark(thread)方法来实现阻塞和唤醒线程的操作
park()/park(Object blocker) - 阻塞当前线程阻塞传入的具体线程
public static void park() {
UNSAFE.park(false, 0L);
}
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
UNSAFE.park(false, 0L);
setBlocker(t, null);
}
permit默认是0,所以一开始调用park()方法,当前线程就会阻塞,直到别的线程将当前线程的permit设置为1时,park方法会被唤醒,然后会将permit再次设置为0并返回。
unpark(Thread thread) - 唤醒处于阻塞状态的指定线程
public static void unpark(Thread thread) {
if (thread != null)
UNSAFE.unpark(thread);
}
调用unpark(thread)方法后,就会将thread线程的许可permit设置成1(注意多次调用unpark方法,不会累加,pemit值还是1)会自动唤醒thead线程,即之前阻塞中的LockSupport.park()方法会立即返回。
public static void main(String[] args) {
Thread a = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " come in. " + System.currentTimeMillis());
LockSupport.park();
System.out.println(Thread.currentThread().getName() + " 唤醒. " + System.currentTimeMillis());
}, "Thread A");
a.start();
Thread b = new Thread(() -> {
LockSupport.unpark(a);
System.out.println(Thread.currentThread().getName() + " 通知.");
}, "Thread B");
b.start();
}
正常 + 无锁块要求。
先前错误的先唤醒后等待顺序,LockSupport可无视这顺序。
LockSupport是用来创建锁和共他同步类的基本线程阻塞原语。
LockSuport是一个线程阻塞工具类,所有的方法都是静态方法,可以让线程在任意位置阻塞,阻寨之后也有对应的唤醒方法。归根结底,LockSupport调用的Unsafe中的native代码。
LockSupport提供park()和unpark()方法实现阻塞线程和解除线程阻塞的过程
LockSupport和每个使用它的线程都有一个许可(permit)关联。permit相当于1,0的开关,默认是0,
调用一次unpark就加1变成1,
调用一次park会消费permit,也就是将1变成0,同时park立即返回。
如再次调用park会变成阻塞(因为permit为零了会阻塞在这里,一直到permit变为1),这时调用unpark会把permit置为1。每个线程都有一个相关的permit, permit最多只有一个,重复调用unpark也不会积累凭证。
AQS
AbstractQueuedSynchronizer 抽象队列同步器。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
...
}
是用来构建锁或者其它同步器组件的重量级基础框架及整个JUC体系的基石,通过内置的FIFO队列来完成资源获取线程的排队工作,并通过一个int类型变量表示持有锁的状态。
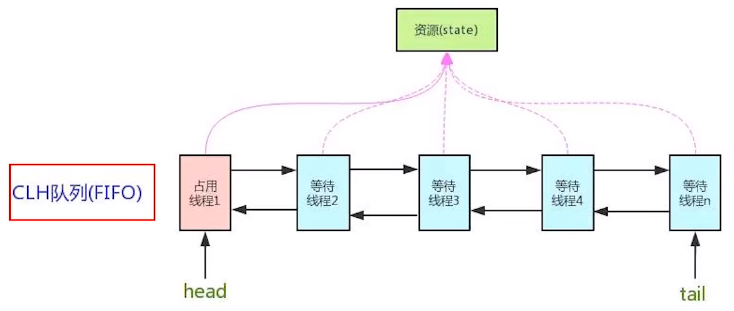
CLH:Craig、Landin and Hagersten队列,是一个单向链表,AQS中的队列是CLH变体的虚拟双向队列FIFO。
进一步理解锁和同步器的关系
- 锁,面向锁的使用者 - 定义了程序员和锁交互的使用层APl,隐藏了实现细节,你调用即可
- 同步器,面向锁的实现者 - 比如Java并发大神DougLee,提出统一规范并简化了锁的实现,屏蔽了同步状态管理、阻塞线程排队和通知、唤醒机制等。
AQS能干嘛?
加锁会导致阻塞 - 有阻塞就需要排队,实现排队必然需要有某种形式的队列来进行管理
解释说明
抢到资源的线程直接使用处理业务逻辑,抢不到资源的必然涉及一种排队等候机制。抢占资源失败的线程继续去等待(类似银行业务办理窗口都满了,暂时没有受理窗口的顾客只能去候客区排队等候),但等候线程仍然保留获取锁的可能且获取锁流程仍在继续(候客区的顾客也在等着叫号,轮到了再去受理窗口办理业务)。
既然说到了排队等候机制,那么就一定会有某种队列形成,这样的队列是什么数据结构呢?
如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中,这个队列就是AQS的抽象表现。它将请求共享资源的线程封装成队列的结点(Node),通过CAS、自旋以及LockSupportpark)的方式,维护state变量的状态,使并发达到同步的控制效果。
源码解析
AQS使用一个volatile的int类型的成员变量来表示同步状态,通过内置的FIFo队列来完成资源获取的排队工作将每条要去抢占资源的线程封装成一个Node,节点来实现锁的分配,通过CAS完成对State值的修改。
AQS的int变量 - AQS的同步状态state成员变量
private volatile int state;
state成员变量相当于银行办理业务的受理窗口状态。
- 零就是没人,自由状态可以办理
- 大于等于1,有人占用窗口,等着去
AQS的CLH队列
- CLH队列(三个大牛的名字组成),为一个双向队列
- 银行候客区的等待顾客
小总结
- 有阻塞就需要排队,实现排队必然需要队列
- state变量+CLH变种的双端队列
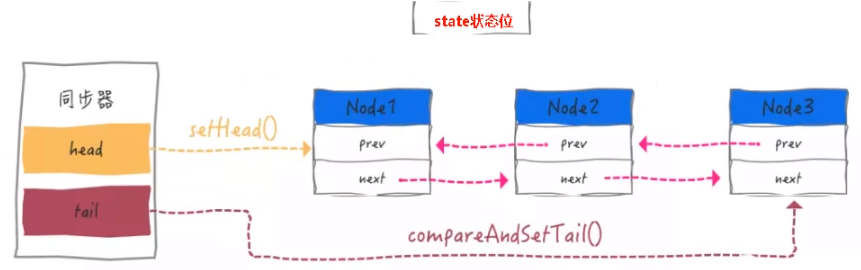
AbstractQueuedSynchronizer内部类Node源码
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
...
* Creates a new {@code AbstractQueuedSynchronizer} instance
protected AbstractQueuedSynchronizer() { }
* Wait queue node class.
static final class Node {
//表示线程以共享的模式等待锁
/** Marker to indicate a node is waiting in shared mode */
static final Node SHARED = new Node();
//表示线程正在以独占的方式等待锁
/** Marker to indicate a node is waiting in exclusive mode */
static final Node EXCLUSIVE = null;
//线程被取消了
/** waitStatus value to indicate thread has cancelled */
static final int CANCELLED = 1;
//后继线程需要唤醒
/** waitStatus value to indicate successor's thread needs unparking */
static final int SIGNAL = -1;
//等待condition唤醒
/** waitStatus value to indicate thread is waiting on condition */
static final int CONDITION = -2;
//共享式同步状态获取将会无条件地传播下去
* waitStatus value to indicate the next acquireShared should
static final int PROPAGATE = -3;
//当前节点在队列中的状态(重点)
//说人话:
//等候区其它顾客(其它线程)的等待状态
//队列中每个排队的个体就是一个Node
//初始为0,状态上面的几种
* Status field, taking on only the values:
volatile int waitStatus;
//前驱节点(重点)
* Link to predecessor node that current node/thread relies on
volatile Node prev;
//后继节点(重点)
* Link to the successor node that the current node/thread
volatile Node next;
//表示处于该节点的线程
* The thread that enqueued this node. Initialized on
volatile Thread thread;
//指向下一个处于CONDITION状态的节点
* Link to next node waiting on condition, or the special
Node nextWaiter;
* Returns true if node is waiting in shared mode.
final boolean isShared() {
//返回前驱节点,没有的话抛出npe
* Returns previous node, or throws NullPointerException if null.
final Node predecessor() throws NullPointerException {
Node() { // Used to establish initial head or SHARED marker
Node(Thread thread, Node mode) { // Used by addWaiter
Node(Thread thread, int waitStatus) { // Used by Condition
}
...
}
AQS同步队列的基本结构
AQS源码深度解读
整个ReentrantLock 的加锁过程,可以分为三个阶段:
- 尝试加锁;
- 加锁失败,线程入队列;
- 线程入队列后,进入阻赛状态。
3、JVM
字节码指令表
| 字节码 | 助记符 | 指令含义 |
|---|---|---|
| 0x00 | nop | None |
| 0x01 | aconst_null | 将null推送至栈顶 |
| 0x02 | iconst_m1 | 将int型-1推送至栈顶 |
| 0x03 | iconst_0 | 将int型0推送至栈顶 |
| 0x04 | iconst_1 | 将int型1推送至栈顶 |
| 0x05 | iconst_2 | 将int型2推送至栈顶 |
| 0x06 | iconst_3 | 将int型3推送至栈顶 |
| 0x07 | iconst_4 | 将int型4推送至栈顶 |
| 0x08 | iconst_5 | 将int型5推送至栈顶 |
| 0x09 | lconst_0 | 将long型0推送至栈顶 |
| 0x0a | lconst_1 | 将long型1推送至栈顶 |
| 0x0b | fconst_0 | 将float型0推送至栈顶 |
| 0x0c | fconst_1 | 将float型1推送至栈顶 |
| 0x0d | fconst_2 | 将float型2推送至栈顶 |
| 0x0e | dconst_0 | 将double型0推送至栈顶 |
| 0x0f | dconst_1 | 将double型1推送至栈顶 |
| 0x10 | bipush | 将单字节的常量值(-128~127)推送至栈顶 |
| 0x11 | sipush | 将一个短整型常量(-32768~32767)推送至栈顶 |
| 0x12 | ldc | 将int,float或String型常量值从常量池中推送至栈顶 |
| 0x13 | ldc_w | 将int,float或String型常量值从常量池中推送至栈顶(宽索引) |
| 0x14 | ldc2_w | 将long或double型常量值从常量池中推送至栈顶(宽索引) |
| 0x15 | iload | 将指定的int型本地变量推送至栈顶 |
| 0x16 | lload | 将指定的long型本地变量推送至栈顶 |
| 0x17 | fload | 将指定的float型本地变量推送至栈顶 |
| 0x18 | dload | 将指定的double型本地变量推送至栈顶 |
| 0x19 | aload | 将指定的引用类型本地变量推送至栈顶 |
| 0x1a | iload_0 | 将第一个int型本地变量推送至栈顶 |
| 0x1b | iload_1 | 将第二个int型本地变量推送至栈顶 |
| 0x1c | iload_2 | 将第三个int型本地变量推送至栈顶 |
| 0x1d | iload_3 | 将第四个int型本地变量推送至栈顶 |
| 0x1e | lload_0 | 将第一个long型本地变量推送至栈顶 |
| 0x1f | lload_1 | 将第二个long型本地变量推送至栈顶 |
| 0x20 | lload_2 | 将第三个long型本地变量推送至栈顶 |
| 0x21 | lload_3 | 将第四个long型本地变量推送至栈顶 |
| 0x22 | fload_0 | 将第一个float型本地变量推送至栈顶 |
| 0x23 | fload_1 | 将第二个float型本地变量推送至栈顶 |
| 0x24 | fload_2 | 将第三个float型本地变量推送至栈顶 |
| 0x25 | fload_3 | 将第四个float型本地变量推送至栈顶 |
| 0x26 | dload_0 | 将第一个double型本地变量推送至栈顶 |
| 0x27 | dload_1 | 将第二个double型本地变量推送至栈顶 |
| 0x28 | dload_2 | 将第三个double型本地变量推送至栈顶 |
| 0x29 | dload_3 | 将第四个double型本地变量推送至栈顶 |
| 0x2a | aload_0 | 将第一个引用类型本地变量推送至栈顶 |
| 0x2b | aload_1 | 将第二个引用类型本地变量推送至栈顶 |
| 0x2c | aload_2 | 将第三个引用类型本地变量推送至栈顶 |
| 0x2d | aload_3 | 将第四个引用类型本地变量推送至栈顶 |
| 0x2e | iaload | 将int型数组指定索引的值推送至栈顶 |
| 0x2f | laload | 将long型数组指定索引的值推送至栈顶 |
| 0x30 | faload | 将float型数组指定索引的值推送至栈顶 |
| 0x31 | daload | 将double型数组指定索引的值推送至栈顶 |
| 0x32 | aaload | 将引用类型数组指定索引的值推送至栈顶 |
| 0x33 | baload | 将boolean或byte型数组指定索引的值推送至栈顶 |
| 0x34 | caload | 将char型数组指定索引的值推送至栈顶 |
| 0x35 | saload | 将short型数组指定索引的值推送至栈顶 |
| 0x36 | istore | 将栈顶int型数值存入指定本地变量 |
| 0x37 | lstore | 将栈顶long型数值存入指定本地变量 |
| 0x38 | fstore | 将栈顶float型数值存入指定本地变量 |
| 0x39 | dstore | 将栈顶double型数值存入指定本地变量 |
| 0x3a | astore | 将栈顶引用类型数值存入指定本地变量 |
| 0x3b | istore_0 | 将栈顶int型数值存入第一个本地变量 |
| 0x3c | istore_1 | 将栈顶int型数值存入第二个本地变量 |
| 0x3d | istore_2 | 将栈顶int型数值存入第三个本地变量 |
| 0x3e | istore_3 | 将栈顶int型数值存入第四个本地变量 |
| 0x3f | lstore_0 | 将栈顶long型数值存入第一个本地变量 |
| 0x40 | lstore_1 | 将栈顶long型数值存入第二个本地变量 |
| 0x41 | lstore_2 | 将栈顶long型数值存入第三个本地变量 |
| 0x42 | lstore_3 | 将栈顶long型数值存入第四个本地变量 |
| 0x43 | fstore_0 | 将栈顶float型数值存入第一个本地变量 |
| 0x44 | fstore_1 | 将栈顶float型数值存入第二个本地变量 |
| 0x45 | fstore_2 | 将栈顶float型数值存入第三个本地变量 |
| 0x46 | fstore_3 | 将栈顶float型数值存入第四个本地变量 |
| 0x47 | dstore_0 | 将栈顶double型数值存入第一个本地变量 |
| 0x48 | dstore_1 | 将栈顶double型数值存入第二个本地变量 |
| 0x49 | dstore_2 | 将栈顶double型数值存入第三个本地变量 |
| 0x4a | dstore_3 | 将栈顶double型数值存入第四个本地变量 |
| 0x4b | astore_0 | 将栈顶引用型数值存入第一个本地变量 |
| 0x4c | astore_1 | 将栈顶引用型数值存入第二个本地变量 |
| 0x4d | astore_2 | 将栈顶引用型数值存入第三个本地变量 |
| 0x4e | astore_3 | 将栈顶引用型数值存入第四个本地变量 |
| 0x4f | iastore | 将栈顶int型数值存入指定数组的指定索引位置 |
| 0x50 | lastore | 将栈顶long型数值存入指定数组的指定索引位置 |
| 0x51 | fastore | 将栈顶float型数值存入指定数组的指定索引位置 |
| 0x52 | dastore | 将栈顶double型数值存入指定数组的指定索引位置 |
| 0x53 | aastore | 将栈顶引用型数值存入指定数组的指定索引位置 |
| 0x54 | bastore | 将栈顶boolean或byte型数值存入指定数组的指定索引位置 |
| 0x55 | castore | 将栈顶char型数值存入指定数组的指定索引位置 |
| 0x56 | sastore | 将栈顶short型数值存入指定数组的指定索引位置 |
| 0x57 | pop | 将栈顶数值弹出(数值不能是long或double类型的) |
| 0x58 | pop2 | 将栈顶的一个(对于非long或double类型)或两个数值(对于非long或double的其他类型)弹出 |
| 0x59 | dup | 复制栈顶数值并将复制值压入栈顶 |
| 0x5a | dup_x1 | 复制栈顶数值并将两个复制值压入栈顶 |
| 0x5b | dup_x2 | 复制栈顶数值并将三个(或两个)复制值压入栈顶 |
| 0x5c | dup2 | 复制栈顶一个(对于long或double类型)或两个(对于非long或double的其他类型)数值并将复制值压入栈顶 |
| 0x5d | dup2_x1 | dup_x1指令的双倍版本 |
| 0x5e | dup2_x2 | dup_x2指令的双倍版本 |
| 0x5f | swap | 将栈顶最顶端的两个数值互换(数值不能是long或double类型) |
| 0x60 | iadd | 将栈顶两int型数值相加并将结果压入栈顶 |
| 0x61 | ladd | 将栈顶两long型数值相加并将结果压入栈顶 |
| 0x62 | fadd | 将栈顶两float型数值相加并将结果压入栈顶 |
| 0x63 | dadd | 将栈顶两double型数值相加并将结果压入栈顶 |
| 0x64 | isub | 将栈顶两int型数值相减并将结果压入栈顶 |
| 0x65 | lsub | 将栈顶两long型数值相减并将结果压入栈顶 |
| 0x66 | fsub | 将栈顶两float型数值相减并将结果压入栈顶 |
| 0x67 | dsub | 将栈顶两double型数值相减并将结果压入栈顶 |
| 0x68 | imul | 将栈顶两int型数值相乘并将结果压入栈顶 |
| 0x69 | lmul | 将栈顶两long型数值相乘并将结果压入栈顶 |
| 0x6a | fmul | 将栈顶两float型数值相乘并将结果压入栈顶 |
| 0x6b | dmul | 将栈顶两double型数值相乘并将结果压入栈顶 |
| 0x6c | idiv | 将栈顶两int型数值相除并将结果压入栈顶 |
| 0x6d | ldiv | 将栈顶两long型数值相除并将结果压入栈顶 |
| 0x6e | fdiv | 将栈顶两float型数值相除并将结果压入栈顶 |
| 0x6f | ddiv | 将栈顶两double型数值相除并将结果压入栈顶 |
| 0x70 | irem | 将栈顶两int型数值作取模运算并将结果压入栈顶 |
| 0x71 | lrem | 将栈顶两long型数值作取模运算并将结果压入栈顶 |
| 0x72 | frem | 将栈顶两float型数值作取模运算并将结果压入栈顶 |
| 0x73 | drem | 将栈顶两double型数值作取模运算并将结果压入栈顶 |
| 0x74 | ineg | 将栈顶int型数值取负并将结果压入栈顶 |
| 0x75 | lneg | 将栈顶long型数值取负并将结果压入栈顶 |
| 0x76 | fneg | 将栈顶float型数值取负并将结果压入栈顶 |
| 0x77 | dneg | 将栈顶double型数值取负并将结果压入栈顶 |
| 0x78 | ishl | 将int型数值左移指定位数并将结果压入栈顶 |
| 0x79 | lshl | 将long型数值左移指定位数并将结果压入栈顶 |
| 0x7a | ishr | 将int型数值右(带符号)移指定位数并将结果压入栈顶 |
| 0x7b | lshr | 将long型数值右(带符号)移指定位数并将结果压入栈顶 |
| 0x7c | iushr | 将int型数值右(无符号)移指定位数并将结果压入栈顶 |
| 0x7d | lushr | 将long型数值右(无符号)移指定位数并将结果压入栈顶 |
| 0x7e | iand | 将栈顶两int型数值"按位与"并将结果压入栈顶 |
| 0x7f | land | 将栈顶两long型数值"按位与"并将结果压入栈顶 |
| 0x80 | ior | 将栈顶两int型数值"按位或"并将结果压入栈顶 |
| 0x81 | lor | 将栈顶两long型数值"按位或"并将结果压入栈顶 |
| 0x82 | ixor | 将栈顶两int型数值"按位异或"并将结果压入栈顶 |
| 0x83 | lxor | 将栈顶两long型数值"按位异或"并将结果压入栈顶 |
| 0x84 | iinc | 将指定int型变量增加指定值(如i++, i–, i+=2等) |
| 0x85 | i2l | 将栈顶int型数值强制转换为long型数值并将结果压入栈顶 |
| 0x86 | i2f | 将栈顶int型数值强制转换为float型数值并将结果压入栈顶 |
| 0x87 | i2d | 将栈顶int型数值强制转换为double型数值并将结果压入栈顶 |
| 0x88 | l2i | 将栈顶long型数值强制转换为int型数值并将结果压入栈顶 |
| 0x89 | l2f | 将栈顶long型数值强制转换为float型数值并将结果压入栈顶 |
| 0x8a | l2d | 将栈顶long型数值强制转换为double型数值并将结果压入栈顶 |
| 0x8b | f2i | 将栈顶float型数值强制转换为int型数值并将结果压入栈顶 |
| 0x8c | f2l | 将栈顶float型数值强制转换为long型数值并将结果压入栈顶 |
| 0x8d | f2d | 将栈顶float型数值强制转换为double型数值并将结果压入栈顶 |
| 0x8e | d2i | 将栈顶double型数值强制转换为int型数值并将结果压入栈顶 |
| 0x8f | d2l | 将栈顶double型数值强制转换为long型数值并将结果压入栈顶 |
| 0x90 | d2f | 将栈顶double型数值强制转换为float型数值并将结果压入栈顶 |
| 0x91 | i2b | 将栈顶int型数值强制转换为byte型数值并将结果压入栈顶 |
| 0x92 | i2c | 将栈顶int型数值强制转换为char型数值并将结果压入栈顶 |
| 0x93 | i2s | 将栈顶int型数值强制转换为short型数值并将结果压入栈顶 |
| 0x94 | lcmp | 比较栈顶两long型数值大小, 并将结果(1, 0或-1)压入栈顶 |
| 0x95 | fcmpl | 比较栈顶两float型数值大小, 并将结果(1, 0或-1)压入栈顶; 当其中一个数值为NaN时, 将-1压入栈顶 |
| 0x96 | fcmpg | 比较栈顶两float型数值大小, 并将结果(1, 0或-1)压入栈顶; 当其中一个数值为NaN时, 将1压入栈顶 |
| 0x97 | dcmpl | 比较栈顶两double型数值大小, 并将结果(1, 0或-1)压入栈顶; 当其中一个数值为NaN时, 将-1压入栈顶 |
| 0x98 | dcmpg | 比较栈顶两double型数值大小, 并将结果(1, 0或-1)压入栈顶; 当其中一个数值为NaN时, 将1压入栈顶 |
| 0x99 | ifeq | 当栈顶int型数值等于0时跳转 |
| 0x9a | ifne | 当栈顶int型数值不等于0时跳转 |
| 0x9b | iflt | 当栈顶int型数值小于0时跳转 |
| 0x9c | ifge | 当栈顶int型数值大于等于0时跳转 |
| 0x9d | ifgt | 当栈顶int型数值大于0时跳转 |
| 0x9e | ifle | 当栈顶int型数值小于等于0时跳转 |
| 0x9f | if_icmpeq | 比较栈顶两int型数值大小, 当结果等于0时跳转 |
| 0xa0 | if_icmpne | 比较栈顶两int型数值大小, 当结果不等于0时跳转 |
| 0xa1 | if_icmplt | 比较栈顶两int型数值大小, 当结果小于0时跳转 |
| 0xa2 | if_icmpge | 比较栈顶两int型数值大小, 当结果大于等于0时跳转 |
| 0xa3 | if_icmpgt | 比较栈顶两int型数值大小, 当结果大于0时跳转 |
| 0xa4 | if_icmple | 比较栈顶两int型数值大小, 当结果小于等于0时跳转 |
| 0xa5 | if_acmpeq | 比较栈顶两引用型数值, 当结果相等时跳转 |
| 0xa6 | if_acmpne | 比较栈顶两引用型数值, 当结果不相等时跳转 |
| 0xa7 | goto | 无条件跳转 |
| 0xa8 | jsr | 跳转至指定的16位offset位置, 并将jsr的下一条指令地址压入栈顶 |
| 0xa9 | ret | 返回至本地变量指定的index的指令位置(一般与jsr或jsr_w联合使用) |
| 0xaa | tableswitch | 用于switch条件跳转, case值连续(可变长度指令) |
| 0xab | lookupswitch | 用于switch条件跳转, case值不连续(可变长度指令) |
| 0xac | ireturn | 从当前方法返回int |
| 0xad | lreturn | 从当前方法返回long |
| 0xae | freturn | 从当前方法返回float |
| 0xaf | dreturn | 从当前方法返回double |
| 0xb0 | areturn | 从当前方法返回对象引用 |
| 0xb1 | return | 从当前方法返回void |
| 0xb2 | getstatic | 获取指定类的静态域, 并将其压入栈顶 |
| 0xb3 | putstatic | 为指定类的静态域赋值 |
| 0xb4 | getfield | 获取指定类的实例域, 并将其压入栈顶 |
| 0xb5 | putfield | 为指定类的实例域赋值 |
| 0xb6 | invokevirtual | 调用实例方法 |
| 0xb7 | invokespecial | 调用超类构建方法, 实例初始化方法, 私有方法 |
| 0xb8 | invokestatic | 调用静态方法 |
| 0xb9 | invokeinterface | 调用接口方法 |
| 0xba | invokedynamic | 调用动态方法 |
| 0xbb | new | 创建一个对象, 并将其引用引用值压入栈顶 |
| 0xbc | newarray | 创建一个指定的原始类型(如int, float, char等)的数组, 并将其引用值压入栈顶 |
| 0xbd | anewarray | 创建一个引用型(如类, 接口, 数组)的数组, 并将其引用值压入栈顶 |
| 0xbe | arraylength | 获取数组的长度值并压入栈顶 |
| 0xbf | athrow | 将栈顶的异常抛出 |
| 0xc0 | checkcast | 检验类型转换, 检验未通过将抛出 ClassCastException |
| 0xc1 | instanceof | 检验对象是否是指定类的实际, 如果是将1压入栈顶, 否则将0压入栈顶 |
| 0xc2 | monitorenter | 获得对象的锁, 用于同步方法或同步块 |
| 0xc3 | monitorexit | 释放对象的锁, 用于同步方法或同步块 |
| 0xc4 | wide | 扩展本地变量的宽度 |
| 0xc5 | multianewarray | 创建指定类型和指定维度的多维数组(执行该指令时, 操作栈中必须包含各维度的长度值), 并将其引用压入栈顶 |
| 0xc6 | ifnull | 为null时跳转 |
| 0xc7 | ifnonnull | 不为null时跳转 |
| 0xc8 | goto_w | 无条件跳转(宽索引) |
| 0xc9 | jsr_w | 跳转至指定的32位offset位置, 并将jsr_w的下一条指令地址压入栈顶 |
JVM体系结构
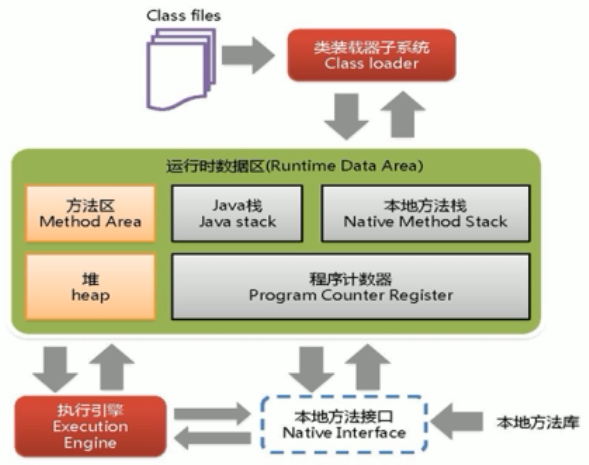
类加载器
- 类加载器是什么
- 双亲委派机制
- Java类加载的沙箱安全机制
Java中可以作为GC Roots的对象
- 虚拟机栈(栈帧中的局部变量区,也叫做局部变量表)中引用的对象。
- 方法区中的类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI(Native方法)引用的对象。
在Java8中,永久代已经被移除,被一个称为元空间的区域所取代。元空间的本质和永久代类似。
元空间(Java8)与永久代(Java7)之间最大的区别在于:永久带使用的JVM的堆内存,但是Java8以后的元空间并不在虚拟机中而是使用本机物理内存。
因此,默认情况下,元空间的大小仅受本地内存限制。类的元数据放入native memory,字符串池和类的静态变量放入java堆中,这样可以加载多少类的元数据就不再由MaxPermSize控制,而由系统的实际可用空间来控制。
// 返回Java虚拟机中内存的总量
long totalMemory = Runtime.getRuntime().totalMemory();
// 返回Java虚拟机中试图使用的最大内存量
long maxMemory = Runtime.getRuntime().maxMemory();
JVM参数
JVM的参数类型:
- 标配参数
- -version
- -help
- X参数(了解)
- -Xint:解释执行
- -Xcomp:第一次使用就编译成本地代码
- -Xmixed:混合模式
- XX参数(下一节)
JVM的XX参数之布尔类型
公式:-XX:+ 或者 - 某个属性值(+表示开启,-表示关闭)
如何查看一个正在运行中的java程序,它的某个jvm参数是否开启?具体值是多少?
- jps -l 查看一个正在运行中的java程序,得到Java程序号。
- jinfo -flag PrintGCDetails (Java程序号 )查看它的某个jvm参数(如PrintGCDetails )是否开启。
- jinfo -flags (Java程序号 )查看它的所有jvm参数
是否打印GC收集细节
- -XX:-PrintGCDetails
- -XX:+PrintGCDetails
是否使用串行垃圾回收器
- -XX:-UseSerialGC
- -XX:+UserSerialGC
D:\soft\jdk1.8.0_311\bin>jps -l
15268 com.wanghua.Test
12952 org.jetbrains.jps.cmdline.Launcher
15336 sun.tools.jps.Jps
3580
D:\soft\jdk1.8.0_311\bin>jinfo -flag PrintGCDetails 15268
-XX:+PrintGCDetails
D:\soft\jdk1.8.0_311\bin>jinfo -flags 15268
Attaching to process ID 15268, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.311-b11
Non-default VM flags: -XX:CICompilerCount=4 -XX:InitialHeapSize=335544320 -XX:MaxHeapSize=5337251840 -XX:MaxNewSize=1778909184 -XX
:MinHeapDeltaBytes=524288 -XX:NewSize=111673344 -XX:OldSize=223870976 -XX:+PrintGCDetails -XX:+UseCompressedClassPointers -XX:+Use
CompressedOops -XX:+UseFastUnorderedTimeStamps -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
Command line: -XX:+PrintGCDetails -javaagent:D:\soft\idea\IntelliJ IDEA 2021.1\lib\idea_rt.jar=53998:D:\soft\idea\IntelliJ IDEA 2
021.1\bin -Dfile.encoding=UTF-8
JVM的XX参数之设值类型
公式:-XX:属性key=属性值value
Case
- -XX:MetaspaceSize=128m
- -XX:MaxTenuringThreshold=15 //极限年龄
JVM的XX参数之XmsXmx坑题
两个经典参数:
- -Xms等价于-XX:InitialHeapSize,初始大小内存,默认物理内存1/64
- -Xmx等价于-XX:MaxHeapSize,最大分配内存,默认为物理内存1/4
JVM盘点家底查看初始默认值
查看初始默认参数值
-XX:+PrintFlagsInitial
公式:java -XX:+PrintFlagsInitial
D:\soft\jdk1.8.0_311\bin>java -XX:+PrintFlagsInitial
[Global flags]
intx ActiveProcessorCount = -1 {product}
uintx AdaptiveSizeDecrementScaleFactor = 4 {product}
uintx AdaptiveSizeMajorGCDecayTimeScale = 10 {product}
uintx AdaptiveSizePausePolicy = 0 {product}
.......
查看修改更新参数值
-XX:+PrintFlagsFinal
公式:java -XX:+PrintFlagsFinal
D:\soft\jdk1.8.0_311\bin>java -XX:+PrintFlagsFinal
[Global flags]
intx ActiveProcessorCount = -1 {product}
uintx AdaptiveSizeDecrementScaleFactor = 4 {product}
uintx AdaptiveSizeMajorGCDecayTimeScale = 10 {product}
uintx AdaptiveSizePausePolicy = 0 {product}
........
=表示默认,:=表示修改过的。
运行java命令的同时打印出参数
java -XX:+PrintFlagsFinal -XX:MetaspaceSize=512m HelloWorld
打印命令行参数
-XX:+PrintCommandLineFlags
常用基础参数
-Xss设置单个线程栈的大小,一般默认为512k~1024K,等价于-XX:ThreadStackSize
-Xmn:设置年轻代大小
-XX:MetaspaceSize 设置元空间大小
-XX:+PrintGCDetails 输出详细GC收集日志信息
-XX:SurvivorRatio
调节新生代中 eden 和 S0、S1的空间比例,默认为 -XX:SuriviorRatio=8,Eden:S0:S1 = 8:1:1
假如设置成 -XX:SurvivorRatio=4,则为 Eden:S0:S1 = 4:1:1
SurvivorRatio值就是设置eden区的比例占多少,S0和S1相同
NewRatio
配置年轻代new 和老年代old 在堆结构的占比
默认:-XX:NewRatio=2 新生代占1,老年代2,年轻代占整个堆的1/3
-XX:NewRatio=4:新生代占1,老年代占4,年轻代占整个堆的1/5,
NewRadio值就是设置老年代的占比,剩下的1个新生代。
新生代特别小,会造成频繁的进行GC收集。
MaxTenuringThreshold
晋升到老年代的对象年龄。
SurvivorTo和SurvivorFrom互换,原SurvivorTo成为下一次GC时的SurvivorFrom区,部分对象会在From和To区域中复制来复制去,如此交换15次(由JVM参数MaxTenuringThreshold决定,这个参数默认为15),最终如果还是存活,就存入老年代。
这里就是调整这个次数的,默认是15,并且设置的值 在 0~15之间。
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻对象不经过Survivor区,直接进入老年代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大的值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概念。
四大引用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jp62bcYS-1645518544310)(D:\wanghua\笔记\面试题.assets\image-20220220134649394.png)]
软引用和弱引用的适用场景
场景:假如有一个应用需要读取大量的本地图片
- 如果每次读取图片都从硬盘读取则会严重影响性能
- 如果一次性全部加载到内存中,又可能造成内存溢出
此时使用软引用可以解决这个问题。
设计思路:使用HashMap来保存图片的路径和相应图片对象关联的软引用之间的映射关系,在内存不足时,JVM会自动回收这些缓存图片对象所占的空间,从而有效地避免了OOM的问题
Map<String, SoftReference<String>> imageCache = new HashMap<>();
虚引用
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收,它不能单独使用也不能通过它访问对象,虚引用必须和引用队列(ReferenceQueue)联合使用。
虚引用的主要作用是跟踪对象被垃圾回收的状态。仅仅是提供了一种确保对象被finalize以后,做某些事情的机制。
PhantomReference的gei方法总是返回null,因此无法访问对应的引用对象。其意义在于说明一个对象已经进入finalization阶段,可以被gc回收,用来实现比fihalization机制更灵活的回收操作。
换句话说,设置虚引用关联的唯一目的,就是在这个对象被收集器回收的时候收到一个系统通知或者后续添加进一步的处理。Java技术允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。
ReferenceQueue引用队列
回收前需要被引用的,用队列保存下。
OOM
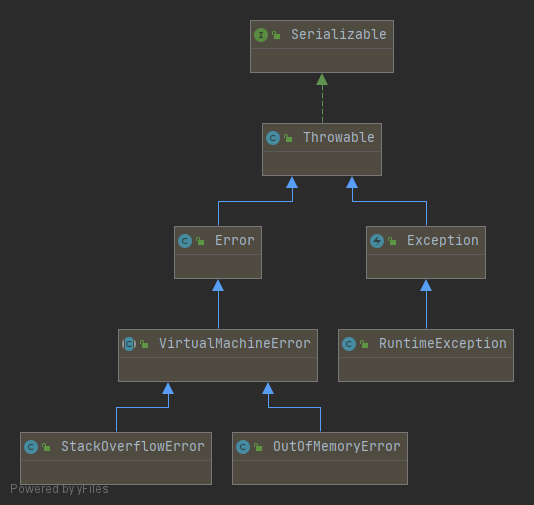
JVM中常见的两种错误
StackoverFlowError
- java.lang.StackOverflowError
OutofMemoryError
- java.lang.OutOfMemoryError:java heap space
- java.lang.OutOfMemoryError:GC overhead limit exceeeded
- java.lang.OutOfMemoryError:Direct buffer memory
- java.lang.OutOfMemoryError:unable to create new native thread
- java.lang.OutOfMemoryError:Metaspace
OOM之Java heap space
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7ETR7Hhi-1645518544311)(D:\wanghua\笔记\面试题.assets\image-20220220150614639.png)]
OOM之GC overhead limit exceeded
超出GC开销限制
GC回收时间过长时会抛出OutOfMemroyError。过长的定义是,超过98%的时间用来做GC并且回收了不到2%的堆内存,连续多次GC 都只回收了不到2%的极端情况下才会抛出。
假如不抛出GC overhead limit错误会发生什么情况呢?那就是GC清理的这么点内存很快会再次填满,迫使cc再次执行。这样就形成恶性循环,CPU使用率一直是100%,而Gc却没有任何成果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-olwtSfWc-1645518544312)(D:\wanghua\笔记\面试题.assets\image-20220220151048815.png)]
OOM之Direct buffer memory
导致原因:
写NIO程序经常使用ByteBuffer来读取或者写入数据,这是一种基于通道(Channel)与缓冲区(Buffer)的IO方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避兔了在Java堆和Native堆中来回复制数据。
- ByteBuffer.allocate(capability) 第一种方式是分配VM堆内存,属于GC管辖范围,由于需要拷贝所以速度相对较慢。
- ByteBuffer.allocateDirect(capability) 第二种方式是分配OS本地内存,不属于GC管辖范围,由于不需要内存拷贝所以速度相对较快。
但如果不断分配本地内存,堆内存很少使用,那么JVM就不需要执行GC,DirectByteBuffer对象们就不会被回收,这时候堆内存充足,但本地内存可能已经使用光了,再次尝试分配本地内存就会出现OutOfMemoryError,那程序就直接崩溃了。
/**
* -Xms5m -Xmx5m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
*/
public static void main(String[] args) throws InterruptedException {
System.out.printf("配置的maxDirectMemory: %.2f MB%n",
sun.misc.VM.maxDirectMemory() / 1024.0 / 1024);
TimeUnit.SECONDS.sleep(3);
ByteBuffer bb = ByteBuffer.allocateDirect(6 * 1024 * 1024);
}
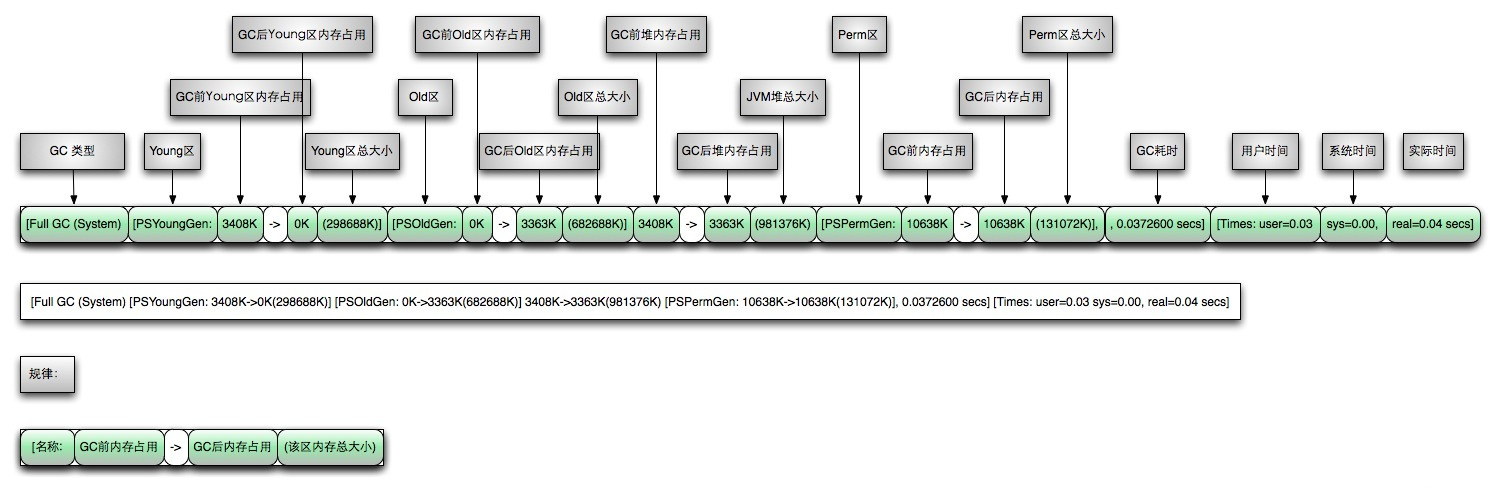
[GC (Allocation Failure) [PSYoungGen: 1024K->504K(1536K)] 1024K->616K(5632K), 0.1017799 secs] [Times: user=0.00 sys=0.00, real=0.10 secs]
[GC (Allocation Failure) [PSYoungGen: 1527K->504K(1536K)] 1639K->736K(5632K), 0.0006777 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
配置的maxDirectMemory: 5.00 MB
[GC (Allocation Failure) [PSYoungGen: 1528K->488K(1536K)] 1760K->1228K(5632K), 0.0007729 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (System.gc()) [PSYoungGen: 525K->488K(1536K)] 1265K->1276K(5632K), 0.0028258 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 488K->0K(1536K)] [ParOldGen: 788K->1109K(4096K)] 1276K->1109K(5632K), [Metaspace: 4166K->4166K(1056768K)], 0.0275874 secs] [Times: user=0.20 sys=0.02, real=0.03 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:695)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311)
at com.wanghua.Test.main(Test.java:52)
Heap
PSYoungGen total 1536K, used 42K [0x00000000ffe00000, 0x0000000100000000, 0x0000000100000000)
eden space 1024K, 4% used [0x00000000ffe00000,0x00000000ffe0a970,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
ParOldGen total 4096K, used 1109K [0x00000000ffa00000, 0x00000000ffe00000, 0x00000000ffe00000)
object space 4096K, 27% used [0x00000000ffa00000,0x00000000ffb15440,0x00000000ffe00000)
Metaspace used 4197K, capacity 4678K, committed 4864K, reserved 1056768K
class space used 462K, capacity 494K, committed 512K, reserved 1048576K
OOM之unable to create new native thread
不能够创建更多的新的线程了,也就是说创建线程的上限达到了
高并发请求服务器时,经常会出现异常java.lang.OutOfMemoryError:unable to create new native thread,准确说该native thread异常与对应的平台有关
导致原因:
- 应用创建了太多线程,一个应用进程创建多个线程,超过系统承载极限
- 服务器并不允许你的应用程序创建这么多线程,linux系统默认运行单个进程可以创建的线程为1024个,如果应用创建超过这个数量,就会报 java.lang.OutOfMemoryError:unable to create new native thread
解决方法:
- 想办法降低你应用程序创建线程的数量,分析应用是否真的需要创建这么多线程,如果不是,改代码将线程数降到最低
- 对于有的应用,确实需要创建很多线程,远超过linux系统默认1024个线程限制,可以通过修改Linux服务器配置,扩大linux默认限制
OOM之Metaspace
使用java -XX:+PrintFlagsInitial命令查看本机的初始化参数,-XX:MetaspaceSize为21810376B(大约20.8M)
Java 8及之后的版本使用Metaspace来替代永久代。
Metaspace是方法区在Hotspot 中的实现,它与持久代最大的区别在于:Metaspace并不在虚拟机内存中而是使用本地内存也即在Java8中, classe metadata(the virtual machines internal presentation of Java class),被存储在叫做Metaspace native memory。
永久代(Java8后被原空向Metaspace取代了)存放了以下信息:
- 虚拟机加载的类信息
- 常量池
- 静态变量
- 即时编译后的代码
模拟Metaspace空间溢出,我们借助CGLib直接操作字节码运行时不断生成类往元空间灌,类占据的空间总是会超过Metaspace指定的空间大小的。
垃圾收集器
GC算法(引用计数/复制/标清/标整)是内存回收的方法论,垃圾收集器就是算法落地实现。
4种主要垃圾收集器
-
Serial
-
Parallel
-
CMS
-
G1
-
串行垃级回收器(Serial) - 它为单线程环境设计且值使用一个线程进行垃圾收集,会暂停所有的用户线程,只有当垃圾回收完成时,才会重新唤醒主线程继续执行。所以不适合服务器环境。
-
并行垃圾回收器(Parallel) - 多个垃圾收集线程并行工作,此时用户线程也是阻塞的,适用于科学计算 / 大数据处理等弱交互场景,也就是说Serial 和 Parallel其实是类似的,不过是多了几个线程进行垃圾收集,但是主线程都会被暂停,但是并行垃圾收集器处理时间,肯定比串行的垃圾收集器要更短。
-
并发垃圾回收器(CMS) - 用户线程和垃圾收集线程同时执行(不一定是并行,可能是交替执行),不需要停顿用户线程,互联网公司都在使用,适用于响应时间有要求的场景。
-
G1垃圾回收器 - G1垃圾回收器将堆内存分割成不同的区域然后并发的对其进行垃圾回收。
查看默认的垃圾收集器:java -XX:+PrintCommandLineFlags -version
或者
jps -l
得出Java程序号
jinfo -flags (Java程序号)
Java中一共有7大垃圾收集器
年轻代GC
- UserSerialGC:串行垃圾收集器
- UserParallelGC:并行垃圾收集器
- UseParNewGC:年轻代的并行垃圾回收器
老年代GC
- UserSerialOldGC:串行老年代垃圾收集器(已经被移除)
- UseParallelOldGC:老年代的并行垃圾回收器
- UseConcMarkSweepGC:(CMS)并发标记清除
老嫩通吃
- UseG1GC:G1垃圾收集器
GC之约定参数说明
- DefNew:Default New Generation
- Tenured:Old
- ParNew:Parallel New Generation
- PSYoungGen:Parallel Scavenge
- ParOldGen:Parallel Old Generation
Server/Client模式分别是什么意思?
使用范围:一般使用Server模式,Client模式基本不会使用
操作系统
-
32位的Window操作系统,不论硬件如何都默认使用Client的JVM模式
-
32位的其它操作系统,2G内存同时有2个cpu以上用Server模式,低于该配置还是Client模式
-
64位只有Server模式
GC之Serial收集器
一句话:一个单线程的收集器,在进行垃圾收集时候,必须暂停其他所有的工作线程直到它收集结束。
串行收集器是最古老,最稳定以及效率高的收集器,只使用一个线程去回收但其在进行垃圾收集过程中可能会产生较长的停顿(Stop-The-World”状态)。虽然在收集垃圾过程中需要暂停所有其他的工作线程,但是它简单高效,对于限定单个CPU环境来说,没有线程交互的开销可以获得最高的单线程垃圾收集效率,因此Serial垃圾收集器依然是java虚拟机运行在Client模式下默认的新生代垃圾收集器。
对应JVM参数是:-XX:+UseSerialGC
开启后会使用:Serial(Young区用) + Serial Old(Old区用)的收集器组合
表示:新生代、老年代都会使用串行回收收集器,新生代使用复制算法,老年代使用标记-整理算法
GC之ParNew收集器
一句话:使用多线程进行垃圾回收,在垃圾收集时,会Stop-The-World暂停其他所有的工作线程直到它收集结束。
ParNew收集器其实就是Serial收集器新生代的并行多线程版本,最常见的应用场景是配合老年代的CMS GC工作,其余的行为和Seria收集器完全一样,ParNew垃圾收集器在垃圾收集过程中同样也要暂停所有其他的工作线程。它是很多Java虚拟机运行在Server模式下新生代的默认垃圾收集器。
常用对应JVM参数:-XX:+UseParNewGC启用ParNew收集器,只影响新生代的收集,不影响老年代。
开启上述参数后,会使用:ParNew(Young区)+ Serial Old的收集器组合,新生代使用复制算法,老年代采用标记-整理算法
但是,ParNew+Tenured这样的搭配,Java8已经不再被推荐
备注:-XX:ParallelGCThreads限制线程数量,默认开启和CPU数目相同的线程数。
GC之Parallel收集器
Parallel / Parallel Scavenge
Parallel Scavenge收集器类似ParNew也是一个新生代垃圾收集器,使用复制算法,也是一个并行的多线程的垃圾收集器,俗称吞吐量优先收集器。一句话:串行收集器在新生代和老年代的并行化。
它重点关注的是:
可控制的吞吐量(Thoughput=运行用户代码时间/(运行用户代码时间+垃圾收集时间),也即比如程序运行100分钟,垃圾收集时间1分钟,吞吐量就是99% )。高吞吐量意味着高效利用CPU的时间,它多用于在后台运算而不需要太多交互的任务。
自适应调节策略也是ParallelScavenge收集器与ParNew收集器的一个重要区别。(自适应调节策略:虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间(-XX:MaxGCPauseMillis)或最大的吞吐量。
常用JVM参数:-XX:+UseParallelGC或-XX:+UseParallelOldGC(可互相激活)使用Parallel Scanvenge收集器。
开启该参数后:新生代使用复制算法,老年代使用标记-整理算法。
多说一句:-XX:ParallelGCThreads=数字N 表示启动多少个GC线程
-
cpu>8 N= 5/8
-
cpu<8 N=实际个数
GC之ParallelOld收集器
Parallel Old收集器是Parallel Scavenge的老年代版本,使用多线程的标记-整理算法,Parallel Old收集器在JDK1.6才开始提供。
在JDK1.6之前,新生代使用ParallelScavenge收集器只能搭配年老代的Serial Old收集器,只能保证新生代的吞吐量优先,无法保证整体的吞吐量。在JDK1.6之前(Parallel Scavenge + Serial Old )
Parallel Old 正是为了在年老代同样提供吞吐量优先的垃圾收集器,如果系统对吞吐量要求比较高,JDK1.8后可以优先考虑新生代Parallel Scavenge和年老代Parallel Old收集器的搭配策略。在JDK1.8及后〈Parallel Scavenge + Parallel Old )
JVM常用参数:-XX:+UseParallelOldGC使用Parallel Old收集器,设置该参数后,新生代Parallel+老年代Parallel Old。
GC之CMS收集器
CMS收集器(Concurrent Mark Sweep:并发标记清除)是一种以获取最短回收停顿时间为目标的收集器。
适合应用在互联网站或者B/S系统的服务器上,这类应用尤其重视服务器的响应速度,希望系统停顿时间最短。
CMS非常适合地内存大、CPU核数多的服务器端应用,也是G1出现之前大型应用的首选收集器。
Concurrent Mark Sweep并发标记清除,并发收集低停顿,并发指的是与用户线程一起执行
开启该收集器的JVM参数:-XX:+UseConcMarkSweepGC开启该参数后会自动将-XX:+UseParNewGC打开。
开启该参数后,使用ParNew(Young区用)+ CMS(Old区用)+ Serial Old的收集器组合,Serial Old将作为CMS出错的后备收集器。

4步过程:
-
初始标记(CMS initial mark) - 只是标记一下GC Roots能直接关联的对象,速度很快,仍然需要暂停所有的工作线程。
-
并发标记(CMS concurrent mark)和用户线程一起 - 进行GC Roots跟踪的过程,和用户线程一起工作,不需要暂停工作线程。主要标记过程,标记全部对象。
-
重新标记(CMS remark)- 为了修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,仍然需要暂停所有的工作线程。由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正。
-
并发清除(CMS concurrent sweep) - 清除GCRoots不可达对象,和用户线程一起工作,不需要暂停工作线程。基于标记结果,直接清理对象,由于耗时最长的并发标记和并发清除过程中,垃圾收集线程可以和用户现在一起并发工作,所以总体上来看CMS 收集器的内存回收和用户线程是一起并发地执行。
优点:并发收集低停顿。
缺点:并发执行,对CPU资源压力大,采用的标记清除算法会导致大量碎片。
由于并发进行,CMS在收集与应用线程会同时会增加对堆内存的占用,也就是说,CMS必须要在老年代堆内存用尽之前完成垃圾回收,否则CMS回收失败时,将触发担保机制,串行老年代收集器将会以STW的方式进行一次GC,从而造成较大停顿时间。
标记清除算法无法整理空间碎片,老年代空间会随着应用时长被逐步耗尽,最后将不得不通过担保机制对堆内存进行压缩。CMS也提供了参数-XX:CMSFullGCsBeForeCompaction(默认O,即每次都进行内存整理)来指定多少次CMS收集之后,进行一次压缩的Full GC。
GC之SerialOld收集器
Serial Old是Serial垃圾收集器老年代版本,它同样是个单线程的收集器,使用标记-整理算法,这个收集器也主要是运行在 Client默认的java虚拟机默认的年老代垃圾收集器。
在Server模式下,主要有两个用途(了解,版本已经到8及以后):
- 在JDK1.5之前版本中与新生代的Parallel Scavenge 收集器搭配使用。(Parallel Scavenge + Serial Old )
- 作为老年代版中使用CMS收集器的后备垃圾收集方案。
GC之如何选择垃圾收集器
组合的选择
-
单CPU或者小内存,单机程序
-XX:+UseSerialGC
-
多CPU,需要最大的吞吐量,如后台计算型应用
-XX:+UseParallelGC(这两个相互激活)
-XX:+UseParallelOldGC
-
多CPU,追求低停顿时间,需要快速响应如互联网应用
-XX:+UseConcMarkSweepGC
-XX:+ParNewGC
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uWZpXHHg-1645518544312)(D:\wanghua\笔记\面试题.assets\image-20220220182826510.png)]
GC之G1收集器
以前收集器特点:
- 年轻代和老年代是各自独立且连续的内存块;
- 年轻代收集使用单eden+s0+s1进行复机算法;
- 老年代收集必须扫描整个老年代区域;
- 都是以尽可能少而快速地执行GC为设计原则。
从官网的描述中,我们知道G1是一种服务器端的垃圾收集器,应用在多处理器和大容量内存环境中,在实现高吞吐量的同时,尽可能的满足垃圾收集暂停时间的要求。另外,它还具有以下特性:
-
像CMS收集器一样,能与应用程序线程并发执行。
-
整理空闲空间更快。
-
需要更多的时间来预测GC停顿时间。
-
不希望牺牲大量的吞吐性能。
-
不需要更大的Java Heap。
G1收集器的设计目标是取代CMS收集器,它同CMS相比,在以下方面表现的更出色:
-
G1是一个有整理内存过程的垃圾收集器,不会产生很多内存碎片。
-
G1的Stop The World(STW)更可控,G1在停顿时间上添加了预测机制,用户可以指定期望停顿时间。
-
CMS垃圾收集器虽然减少了暂停应用程序的运行时间,但是它还是存在着内存碎片问题。于是,为了去除内存碎片问题,同时又保留CMS垃圾收集器低暂停时间的优点,JAVA7发布了一个新的垃圾收集器-G1垃圾收集器。
-
G1是在2012年才在jdk1.7u4中可用。oracle官方计划在JDK9中将G1变成默认的垃圾收集器以替代CMS。它是一款面向服务端应用的收集器,主要应用在多CPU和大内存服务器环境下,极大的减少垃圾收集的停顿时间,全面提升服务器的性能,逐步替换java8以前的CMS收集器。
主要改变是Eden,Survivor和Tenured等内存区域不再是连续的了,而是变成了一个个大小一样的region ,每个region从1M到32M不等。一个region有可能属于Eden,Survivor或者Tenured内存区域。
特点:
-
G1能充分利用多CPU、多核环境硬件优势,尽量缩短STW。
-
G1整体上采用标记-整理算法,局部是通过复制算法,不会产生内存碎片。
-
宏观上看G1之中不再区分年轻代和老年代。把内存划分成多个独立的子区域(Region),可以近似理解为一个围棋的棋盘。
-
G1收集器里面讲整个的内存区都混合在一起了,但其本身依然在小范围内要进行年轻代和老年代的区分,保留了新生代和老年代,但它们不再是物理隔离的,而是一部分Region的集合且不需要Region是连续的,也就是说依然会采用不同的GC方式来处理不同的区域。
-
G1虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的survivor(to space)堆做复制准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换。
GC之G1底层原理
Region区域化垃圾收集器 - 最大好处是化整为零,避免全内存扫描,只需要按照区域来进行扫描即可。
区域化内存划片Region,整体编为了一些列不连续的内存区域,避免了全内存区的GC操作。
核心思想是将整个堆内存区域分成大小相同的子区域(Region),在JVM启动时会自动设置这些子区域的大小,在堆的使用上,G1并不要求对象的存储一定是物理上连续的只要逻辑上连续即可,每个分区也不会固定地为某个代服务,可以按需在年轻代和老年代之间切换。启动时可以通过参数-XX:G1HeapRegionSize=n可指定分区大小(1MB~32MB,且必须是2的幂),默认将整堆划分为2048个分区。
大小范围在1MB~32MB,最多能设置2048个区域,也即能够支持的最大内存为:32 M B ∗ 2048 = 65536 M B = 64 G
G1算法将堆划分为若干个区域(Region),它仍然属于分代收集器。
这些Region的一部分包含新生代,新生代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者Survivor空间。
这些Region的一部分包含老年代,G1收集器通过将对象从一个区域复制到另外一个区域,完成了清理工作。这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有CMS内存碎片问题的存在了。
在G1中,还有一种特殊的区域,叫Humongous区域。
如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象。这些巨型对象默认直接会被分配在年老代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。
为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
回收步骤
G1收集器下的Young GC
针对Eden区进行收集,Eden区耗尽后会被触发,主要是小区域收集+形成连续的内存块,避免内存碎片
-
Eden区的数据移动到Survivor区,假如出现Survivor区空间不够,Eden区数据会部分晋升到Old区。
-
Survivor区的数据移动到新的Survivor区,部分数据晋升到Old区。
-
最后Eden区收拾干净了,GC结束,用户的应用程序继续执行。
4步过程:
- 初始标记:只标记GC Roots能直接关联到的对象
- 并发标记:进行GC Roots Tracing的过程
- 最终标记:修正并发标记期间,因程序运行导致标记发生变化的那一部分对象
- 筛选回收:根据时间来进行价值最大化的回收
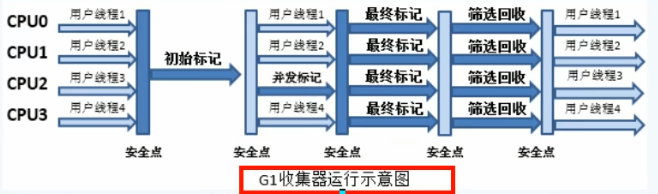
GC之G1参数配置及和CMS的比较
-
-XX:+UseG1GC
-
-XX:G1HeapRegionSize=n:设置的G1区域的大小。值是2的幂,范围是1MB到32MB。目标是根据最小的Java堆大小划分出约2048个区域。
-
-XX:MaxGCPauseMillis=n:最大GC停顿时间,这是个软目标,JVM将尽可能(但不保证)停顿小于这个时间。
-
-XX:InitiatingHeapOccupancyPercent=n:堆占用了多少的时候就触发GC,默认为45。
-
-XX:ConcGCThreads=n:并发GC使用的线程数。
-
-XX:G1ReservePercent=n:设置作为空闲空间的预留内存百分比,以降低目标空间溢出的风险,默认值是10%。
开发人员仅仅需要声明以下参数即可:
三步归纳:开始G1+设置最大内存+设置最大停顿时间
- -XX:+UseG1GC
- -Xmx32g
- -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=n:最大GC停顿时间单位毫秒,这是个软目标,JVM将尽可能(但不保证)停顿小于这个时间
G1和CMS比较
-
G1不会产生内碎片
-
是可以精准控制停顿。该收集器是把整个堆(新生代、老年代)划分成多个固定大小的区域,每次根据允许停顿的时间去收集垃圾最多的区域。
JVMGC结合SpringBoot微服务优化简介
- IDEA开发微服务工程。
- Maven进行clean package。
- 要求微服务启动的时候,同时配置我们的JVM/GC的调优参数。
- 公式:
java -server jvm的各种参数 -jar 第1步上面的jar/war包名。
字符串常量池
String:intern()是一个本地方法,它的作用是如果字符串常量池中已经包含一个等于此String对象的字符串,则返回代表池中这个字符串的String对象的引用;否则,会将此String对象包含的字符串添加到常量池中,并且返回此String对象的引用。在JDK 6或更早之前的HotSpot虚拟机中,常量池都是分配在永久代中,我们可以通过-XX:PermSize和-XX:MaxPermSize限制永久代的大小,即可间接限制其中常量池的容量。
public static void main(String[] args) {
String str1 = new StringBuilder("58").append("tongcheng").toString();
System.out.println(str1);
System.out.println(str1.intern());
System.out.println(str1 == str1.intern());//true,所有字符串都为true,除了"java"
System.out.println();
String str2 = new StringBuilder("ja").append("va").toString();
System.out.println(str2);
System.out.println(str2.intern());
System.out.println(str2 == str2.intern());//false
}
按照代码结果,Java字符串答案为false必然是两个不同的java,那另外一个java字符串如何加载进来的?
有一个初始化的Java字符串(JDK出娘胎自带的),在加载sun.misc.Version这个类的时候进入常量池。
递推步骤
-
System代码解析 System -> initializeSystemClass() -> Version
-
类加载器和rt.jar - 根加载器提前部署加载rt.jar
-
OpenJDK8源码
-
http://openjdk.java.net/
-
openjdk8\jdk\src\share\classes\sun\misc
-
考查点 - intern()方法,判断true/false?- 《深入理解java虚拟机》书原题是否读过经典JVM书籍
这段代码在JDK 6中运行,会得到两个false,而在JDK 7中运行,会得到一个true和一个false。产生差异的原因是,在JDK 6中,intern()方法会把首次遇到的字符串实例复制到永久代的字符串常量池中存储,返回的也是永久代里面这个字符串实例的引用,而由StringBuilder创建的字符串对象实例在Java堆上,所以必然不可能是同一个引用,结果将返回false。
而JDK 7(以及部分其他虚拟机,例如JRockit)的intern()方法实现就不需要再拷贝字符串的实例到永久代了,既然字符串常量池已经移到Java堆中,那只需要在常量池里记录一下首次出现的实例引用即可,因此intern()返回的引用和由StringBuilder创建的那个字符串实例就是同一个。而对str2比较返回false,这是因为“java”这个字符串在执行StringBuilder.toString()之前就已经出现过了,字符串常量池中已经有它的引用,不符合intern()方法要求“首次遇到"”的原则,“计算机软件"这个字符串则是首次出现的,因此结果返回true
sun.misc.Version类会在JDK类库的初始化过程中被加载并初始化,而在初始化时它需要对静态常量字段根据指定的常量值(ConstantValue〉做默认初始化,此时被sun.misc.Version.launcher静态常量字段所引用的"java"字符串字面量就被intern到HotSpot VM的字符串常量池——StringTable里了。
4、MySQL
MySQL 什么时候适合创建索引,什么时候不适合创建索引?
什么时候适合创建索引
1)主键自动建立唯 一 索引
2)频繁作为查询条件的字段应该创建索引
3)查询中与其它表关联的字段,外键关系建立索引
4)频繁更新的字段不适合创建索引,因为每次更新不单是更新了记录还会更新索引
5)单键组索引的选择问题,who? 在高并发下领向创建组合索引
6)意询中排序的字段,排序字段若通过索引法访问将大大提高排序速度
7)查询中统计或者分组字段
什么时候不适合创建索引
1)表记录太少
2)经常增删改的表
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引。
3)注意,如果某个数据列包含许多重复的内容,为它建立索弓|就没有太大的实际效果。
5、Redis
Redis 持久化有几种类型,它们的区别是?
Redis 提供了两种不同形式的持久化的方式。
RDB(Redis DataBase)
1)什么是 RDB 呢?
指定时间间隔从内存中的数据集快照写入磁盘,也就是行话讲的 Snapshot 快照,它的恢复是将快照文件读取到内存中。
2)RDB 备份是如何执行的?
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
3)什么是 fork ?
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”,一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
4)RDB 保存的文件
在 redis.conf 的配置文件中,默认保存文件的名称叫 dump.rdb
rdb文件的保存路径,也可以修改。默认为Redis启动时命令行所在的目录下
5)RDB 保存的策略
15 分钟 1 次添加 key 的操作,5 分钟 10 次添加 key 的操作,1 分钟 10000 次添加 key 的操作都会触发保存策略。
6)RDB 的备份
先通过 config get dir 查询 rdb文件的目录
将 *.rdb 的文件拷贝到别的地方
7)RDB 的恢复
关闭 Redis
先把备份文件拷贝到拷贝到工作目录下
启动 Redis,备份数据会直接加载
8)RDB 的优点
- 节省磁盘空间
- 恢复速度快
9)RDB 的缺点
虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
在备份周期在一定间隔时间做一次备份, 所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
AOF(Append Only File)
1)什么是 AOF 呢?
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
2)AOF 默认不开启,需要手动在配置文件中配置
3)可以在redis.conf中配置文件名称,默认为 appendonly.aof
4)AOF 和 RDB 同时开启,redis 听谁的
系统默认取AOF的数据。
5)AOF 文件故障备份
AOF的备份机制和性能虽然和RDB不同, 但是备份和恢复的操作同RDB一样,都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载。
6)AOF 文件故障恢复
如遇到AOF文件损坏,可通过
redis-check-aof --fix appendonly.aof 进行恢复
7)AOF 同步频率设置
始终同步,每次Redis的写入都会立刻记入日志。
每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
把不主动进行同步,把同步时机交给操作系统。
8)Rewrite
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof。
9)Redis如何实现重写?
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
10)何时重写?
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。
系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
11)AOF 优点
备份机制更稳健,丢失数据概率更低。
可读的日志文本,通过操作AOF稳健,可以处理误操作。
12)AOF 缺点
比起RDB占用更多的磁盘空间。
恢复备份速度要慢。
每次读写都同步的话,有一定的性能压力。
存在个别Bug,造成恢复不能。
Redis 在项目中的使用场景?
| 数据类型 | 使用场景 |
|---|---|
| String | 比如:我想知道什么时候封锁一个IP(某一个IP地址在某一段时间内访问的特别频繁,那有可能这个IP可能存在风险,所以对它进行封锁),使用Incrby命令记录当前IP访问次数 存储用户信息【id,name,age】 存储方式:set(userKey,用户信息字符串) |
| List | 实现最新消息的排行,还可以利用List的push命令,将任务存在list集合中,同时使用另一个pop命令将任务从集合中取出 Redis——list数据类型来模拟消息队列。 比如:电商中的秒杀就可以采用这种方式来完成一个秒杀活动 |
| Set | 特殊之处:可以自动排重。 比如微博中将每个人的好友存在集合(Set)中 如果求两个人的共同好友的操作,我们只需要求交集即可。(交/并集命令) |
| Hash | 存储用户信息【id,name,age】 存储方式:Hset(key,filed,value) hset(userKey,id,101) hset(userKey,name,“admin”) hset(userKey,age,23) 这样存储的好处:当修改用户信息某一项属性值时,直接通过filed取值,并修改值 -----修改案例------ hget(userKey,id) hset(userKey,id,102) ------------------------------ 为什么不使用String存储? 获取方式:get(userKey) 会把参数为userKey对应的用户信息字符串全部进行反序列号,而用户信息字符串包含了用户所有的信息 如果我只修改用户的ID,那反序列化的其他信息其实是没有任何意义的 序列化与反序列化是由IO进行操作的,使用String类型存储增加了IO的使用次数,降低了程序的性能 对值为某类信息时不建议使用String类型存储 |
| ZSet | 有序集合(sorted set),以某一个条件为权重,进行排序。 比如:京东看商品详情时,都会有一个综合排名,还有可以安装价格、销量进行排名 |
其他redis的类型
- bitmap
- HyperLogLogs
- GEO
- Stream
备注
- 命令不区分大小写,而key是区分大小写的
- help @类型名词
string
APPEND key value
summary: Append a value to a key
since: 2.0.0
BITCOUNT key [start end]
summary: Count set bits in a string
since: 2.6.0
BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]
summary: Perform arbitrary bitfield integer operations on strings
since: 3.2.0
BITOP operation destkey key [key ...]
summary: Perform bitwise operations between strings
since: 2.6.0
BITPOS key bit [start] [end]
summary: Find first bit set or clear in a string
since: 2.8.7
DECR key
summary: Decrement the integer value of a key by one
since: 1.0.0
DECRBY key decrement
summary: Decrement the integer value of a key by the given number
since: 1.0.0
GET key
summary: Get the value of a key
since: 1.0.0
GETBIT key offset
summary: Returns the bit value at offset in the string value stored at key
since: 2.2.0
GETDEL key
summary: Get the value of a key and delete the key
since: 6.2.0
GETEX key [EX seconds|PX milliseconds|EXAT timestamp|PXAT milliseconds-timestamp|PERSIST]
summary: Get the value of a key and optionally set its expiration
since: 6.2.0
GETRANGE key start end
summary: Get a substring of the string stored at a key
since: 2.4.0
GETSET key value
summary: Set the string value of a key and return its old value
since: 1.0.0
INCR key
summary: Increment the integer value of a key by one
since: 1.0.0
INCRBY key increment
summary: Increment the integer value of a key by the given amount
since: 1.0.0
INCRBYFLOAT key increment
summary: Increment the float value of a key by the given amount
since: 2.6.0
MGET key [key ...]
summary: Get the values of all the given keys
since: 1.0.0
MSET key value [key value ...]
summary: Set multiple keys to multiple values
since: 1.0.1
MSETNX key value [key value ...]
summary: Set multiple keys to multiple values, only if none of the keys exist
since: 1.0.1
PSETEX key milliseconds value
summary: Set the value and expiration in milliseconds of a key
since: 2.6.0
SET key value [EX seconds|PX milliseconds|EXAT timestamp|PXAT milliseconds-timestamp|KEEPTTL] [NX|XX] [GET]
summary: Set the string value of a key
since: 1.0.0
SETBIT key offset value
summary: Sets or clears the bit at offset in the string value stored at key
since: 2.2.0
SETEX key seconds value
summary: Set the value and expiration of a key
since: 2.0.0
SETNX key value
summary: Set the value of a key, only if the key does not exist
since: 1.0.0
SETRANGE key offset value
summary: Overwrite part of a string at key starting at the specified offset
since: 2.2.0
STRALGO LCS algo-specific-argument [algo-specific-argument ...]
summary: Run algorithms (currently LCS) against strings
since: 6.0.0
STRLEN key
summary: Get the length of the value stored in a key
since: 2.2.0
分布式锁
-
SETNX key value
-
SET key value [EX seconds] [PX milliseconds] [NX|XX]
-
EX:key在多少秒之后过期
-
PX:key在多少毫秒之后过期
-
NX:当key不存在的时候,才创建key,效果等同于setnx
-
XX:当key存在的时候,覆盖key
-
应用场景
- 商品编号、订单号采用INCR命令生成
- 是否喜欢的文章
hash
HDEL key field [field ...]
summary: Delete one or more hash fields
since: 2.0.0
HEXISTS key field
summary: Determine if a hash field exists
since: 2.0.0
HGET key field
summary: Get the value of a hash field
since: 2.0.0
HGETALL key
summary: Get all the fields and values in a hash
since: 2.0.0
HINCRBY key field increment
summary: Increment the integer value of a hash field by the given number
since: 2.0.0
HINCRBYFLOAT key field increment
summary: Increment the float value of a hash field by the given amount
since: 2.6.0
HKEYS key
summary: Get all the fields in a hash
since: 2.0.0
HLEN key
summary: Get the number of fields in a hash
since: 2.0.0
HMGET key field [field ...]
summary: Get the values of all the given hash fields
since: 2.0.0
HMSET key field value [field value ...]
summary: Set multiple hash fields to multiple values
since: 2.0.0
HRANDFIELD key [count [WITHVALUES]]
summary: Get one or multiple random fields from a hash
since: 6.2.0
HSCAN key cursor [MATCH pattern] [COUNT count]
summary: Incrementally iterate hash fields and associated values
since: 2.8.0
HSET key field value [field value ...]
summary: Set the string value of a hash field
since: 2.0.0
HSETNX key field value
summary: Set the value of a hash field, only if the field does not exist
since: 2.0.0
HSTRLEN key field
summary: Get the length of the value of a hash field
since: 3.2.0
HVALS key
summary: Get all the values in a hash
since: 2.0.0
list
BLMOVE source destination LEFT|RIGHT LEFT|RIGHT timeout
summary: Pop an element from a list, push it to another list and return it; or block until one is available
since: 6.2.0
BLPOP key [key ...] timeout
summary: Remove and get the first element in a list, or block until one is available
since: 2.0.0
BRPOP key [key ...] timeout
summary: Remove and get the last element in a list, or block until one is available
since: 2.0.0
BRPOPLPUSH source destination timeout
summary: Pop an element from a list, push it to another list and return it; or block until one is available
since: 2.2.0
LINDEX key index
summary: Get an element from a list by its index
since: 1.0.0
LINSERT key BEFORE|AFTER pivot element
summary: Insert an element before or after another element in a list
since: 2.2.0
LLEN key
summary: Get the length of a list
since: 1.0.0
LMOVE source destination LEFT|RIGHT LEFT|RIGHT
summary: Pop an element from a list, push it to another list and return it
since: 6.2.0
LPOP key [count]
summary: Remove and get the first elements in a list
since: 1.0.0
LPOS key element [RANK rank] [COUNT num-matches] [MAXLEN len]
summary: Return the index of matching elements on a list
since: 6.0.6
LPUSH key element [element ...]
summary: Prepend one or multiple elements to a list
since: 1.0.0
LPUSHX key element [element ...]
summary: Prepend an element to a list, only if the list exists
since: 2.2.0
LRANGE key start stop
summary: Get a range of elements from a list
since: 1.0.0
LREM key count element
summary: Remove elements from a list
since: 1.0.0
LSET key index element
summary: Set the value of an element in a list by its index
since: 1.0.0
LTRIM key start stop
summary: Trim a list to the specified range
since: 1.0.0
RPOP key [count]
summary: Remove and get the last elements in a list
since: 1.0.0
RPOPLPUSH source destination
summary: Remove the last element in a list, prepend it to another list and return it
since: 1.2.0
RPUSH key element [element ...]
summary: Append one or multiple elements to a list
since: 1.0.0
RPUSHX key element [element ...]
summary: Append an element to a list, only if the list exists
since: 2.2.0
set
SADD key member [member ...]
summary: Add one or more members to a set
since: 1.0.0
SCARD key
summary: Get the number of members in a set
since: 1.0.0
SDIFF key [key ...]
summary: Subtract multiple sets
since: 1.0.0
SDIFFSTORE destination key [key ...]
summary: Subtract multiple sets and store the resulting set in a key
since: 1.0.0
SINTER key [key ...]
summary: Intersect multiple sets
since: 1.0.0
SINTERSTORE destination key [key ...]
summary: Intersect multiple sets and store the resulting set in a key
since: 1.0.0
SISMEMBER key member
summary: Determine if a given value is a member of a set
since: 1.0.0
SMEMBERS key
summary: Get all the members in a set
since: 1.0.0
SMISMEMBER key member [member ...]
summary: Returns the membership associated with the given elements for a set
since: 6.2.0
SMOVE source destination member
summary: Move a member from one set to another
since: 1.0.0
SPOP key [count]
summary: Remove and return one or multiple random members from a set
since: 1.0.0
SRANDMEMBER key [count]
summary: Get one or multiple random members from a set
since: 1.0.0
SREM key member [member ...]
summary: Remove one or more members from a set
since: 1.0.0
SSCAN key cursor [MATCH pattern] [COUNT count]
summary: Incrementally iterate Set elements
since: 2.8.0
SUNION key [key ...]
summary: Add multiple sets
since: 1.0.0
SUNIONSTORE destination key [key ...]
summary: Add multiple sets and store the resulting set in a key
since: 1.0.0
集合运算
集合的差集运算A - B
- 属于A但不属于B的元素构成的集合
- SDIFF key [key …]
集合的交集运算A ∩ B
- 属于A同时也属于B的共同拥有的元素构成的集合
- SINTER key [key …]
集合的并集运算A U B
-
属于A或者属于B的元素合并后的集合
-
SUNION key [key …]
应用场景
- 微信抽奖小程序
- 用户ID,立即参与按钮
- SADD key 用户ID
- 显示已经有多少人参与了、上图23208人参加
- SCARD key
- 抽奖(从set中任意选取N个中奖人)
- SRANDMEMBER key 2(随机抽奖2个人,元素不删除)
- SPOP key 3(随机抽奖3个人,元素会删除)
微信朋友圈点赞
- 新增点赞
- sadd pub:msglD 点赞用户ID1 点赞用户ID2
- 取消点赞
- srem pub:msglD 点赞用户ID
- 展现所有点赞过的用户
- SMEMBERS pub:msglD
- 点赞用户数统计,就是常见的点赞红色数字
- scard pub:msgID
- 判断某个朋友是否对楼主点赞过
- SISMEMBER pub:msglD用户ID
微博好友关注社交关系
- 共同关注:我去到局座张召忠的微博,马上获得我和局座共同关注的人
- sadd s1 1 2 3 4 5
- sadd s2 3 4 5 6 7
- SINTER s1 s2
- 我关注的人也关注他(大家爱好相同)
QQ内推可能认识的人
- sadd s1 1 2 3 4 5
- sadd s2 3 4 5 6 7
- SINTER s1 s2
- SDIFF s1 s2
- SDIFF s2 s1
zset
向有序集合中加入一个元素和该元素的分数
添加元素 ZADD key score member [score member …]
按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素 ZRANGE key start stop [WITHSCORES]
获取元素的分数 ZSCORE key member
删除元素 ZREM key member [member …]
获取指定分数范围的元素 ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
增加某个元素的分数 ZINCRBY key increment member
获取集合中元素的数量 ZCARD key
获得指定分数范围内的元素个数 ZCOUNT key min max
按照排名范围删除元素 ZREMRANGEBYRANK key start stop
获取元素的排名
从小到大 ZRANK key member
从大到小 ZREVRANK key member
应用场景
-
根据商品销售对商品进行排序显示
-
定义商品销售排行榜(sorted set集合),key为goods:sellsort,分数为商品销售数量。
-
商品编号1001的销量是9,商品编号1002的销量是15 - zadd goods:sellsort 9 1001 15 1002
-
有一个客户又买了2件商品1001,商品编号1001销量加2 - zincrby goods:sellsort 2 1001
-
求商品销量前10名 - ZRANGE goods:sellsort 0 10 withscores
-
抖音热搜
- 点击视频
- ZINCRBY hotvcr:20200919 1 八佰
- ZINCRBY hotvcr:20200919 15 八佰 2 花木兰
- 展示当日排行前10条
- ZREVRANGE hotvcr:20200919 0 9 withscores
- 点击视频
分布式锁
常见的面试题:
-
Redis除了拿来做缓存,你还见过基于Redis的什么用法?
-
Redis做分布式锁的时候有需要注意的问题?
-
如果是Redis是单点部署的,会带来什么问题?那你准备怎么解决单点问题呢?
-
集群模式下,比如主从模式,有没有什么问题呢?
-
那你简单的介绍一下Redlock吧?你简历上写redisson,你谈谈。
-
Redis分布式锁如何续期?看门狗知道吗?
SpringBoot整合redis搭建超卖程序
使用场景:多个服务间 + 保证同一时刻内 + 同一用户只能有一个请求(防止关键业务出现数据冲突和并发错误)
建两个Module:boot_redis01,boot_redis02
Redis内存淘汰策略
三种不同的删除策略
- 定时删除 - 总结:对CPU不友好,用处理器性能换取存储空间(拿时间换空间)
- 惰性删除 - 总结:对memory不友好,用存储空间换取处理器性能(拿空间换时间)
- 上面两种方案都走极端 - 定期删除 - 定期抽样key,判断是否过期(存在漏网之鱼)
定时删除
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。
立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力,让CPU心累,时时需要删除,忙死。
这会产生大量的性能消耗,同时也会影响数据的读取操作。
惰性删除
数据到达过期时间,不做处理。等下次访问该数据时,
如果未过期,返回数据;
发现已过期,删除,返回不存在。
惰性删除策略的缺点是,它对内存是最不友好的。
如果一个键已经过期,而这个键又仍然保留在数据库中,那么只要这个过期键不被删除,它所占用的内存就不会释放。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏 – 无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息。
定期删除
定期删除策略是前两种策略的折中:
定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
周期性轮询Redis库中的时效性数据,来用随机抽取的策略,利用过期数据占比的方式控制删除频度
特点1:CPU性能占用设置有峰值,检测频度可自定义设置
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
总结:周期性抽查存储空间(随机抽查,重点抽查)
举例:
redis默认每个100ms检查,是否有过期的key,有过期key则删除。注意:redis不是每隔100ms将所有的key检查一次而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis直接进去ICU)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
定期删除策略的难点是确定删除操作执行的时长和频率:如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将CPU时间过多地消耗在删除过期键上面。如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除束略一样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
内存淘汰策略登场
-
noeviction:不会驱逐任何key
-
volatile-lfu:对所有设置了过期时间的key使用LFU算法进行删除
-
volatile-Iru:对所有设置了过期时间的key使用LRU算法进行删除
-
volatile-random:对所有设置了过期时间的key随机删除
-
volatile-ttl:删除马上要过期的key
-
allkeys-lfu:对所有key使用LFU算法进行删除
-
allkeys-Iru:对所有key使用LRU算法进行删除
-
allkeys-random:对所有key随机删除
上面总结
- 2*4得8
- 2个维度
- 过期键中筛选
- 所有键中筛选
- 4个方面
- LRU
- LFU
- random
- ttl(Time To Live)
- 8个选项
如何配置,修改
- 命令
- config set maxmemory-policy noeviction
- config get maxmemory
- 配置文件 - 配置文件redis.conf的maxmemory-policy参数
6、Linux
Linux 常用服务类相关命令?
Linux 系统有 7 种运行级别 (runlevel) : 常用的是级别 3 和 5 。
- 运行级别0: 系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
- 运行级别1: 单用户工作状态,root权限,用于系统维护,禁止远程登陆
- 运行级别2: 多用户状态(没有NFS),不支持网络
- 运行级别3: 完全的多用户状态(有NFS),登陆后进入控制台命令行模式
- 运行级别4: 系统未使用,保留
- 运行级别5: X11控制台,登陆后进入图形GUI模式
- 运行级别6: 系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动.
centos 7
systemctl start 服务名(xxx.service)
systemct restart 服务名(xxxx.service)
systemctl stop 服务名(xxxx.service)
systemctl reload 服务名(xxxx.service)
systemctl status 服务名(xxxx.service)
#查看服务的方法 /usr/lib/systemd/system
#查看服务的命令
systemctl list-unit-files
systemctl --type service
#通过systemctl命令设置自启动
自启动 systemctl enable service_name
不自启动 systemctl disable service_name
7、Git
1、创建分支
git branch <分支名>
git branch -v 查看分支
2、切换分支
git checkout <分支名>
一步完成: git checkout -b <分支名>
3、合并分支
先切换到主干 git checkout master
git merge <分支名>
4、删除分支
先切换到主干 git checkout master
git branch -D <分支名>
8、ElasticSearch
Elasticsearch 与 solr 的区别?
1)背景
他们都是基于 Lucene 搜索服务器基础上开发,一款优秀的,高性能的企业级搜索服务器,【是因为他们都是基于分词技术构建的倒排索引的方式进行查询】
2)开发语言
Java
3)诞生时间
Solr:2004年诞生
ES:2010年诞生
4)主要区别
- 当实时建立索引的时候,solr 会产生 io 阻塞,而 es 不会,es 查询性能要高于 solr
- 在不断动态添加数据的时候,solr 的检索效率会变得低下,而 es 没有什么变化
- Solr 利用 zookeeper 进行分布式管理,而 es 自带有分布式系统的管理功能,Solr 一般都要部署到 web 服务器上,比如 tomcat,启动 tomcat 的时候需要配置 tomcat 和 solr 的 关联 【 Solr 的本质,是一个动态的 web项目】
- Solr支持更多格式的数据 【xml、json、csv 】等,而 es 仅仅支持 json 文件格式
- Solr 是传统搜索应用的有利解决方案,但是 es 更加适用于新兴的是是搜索应用
- 单纯的对已有的数据进行检索, solr 效率更好,高于 es
- Solr 官网提供的功能更多哦,而 es 本身更加注重于核心功能,高级功能都有第三方插件完成
7、SSM
Spring Bean 的作用域之间有什么区别?
在 Spring 的配置文件中,给 bean 加上 scope 属性来指定 bean 的作用域如下:
- singleton:唯一 bean 实例,Spring 中的 bean 默认都是单例的。
- prototype:每次请求都会创建一个新的 bean 实例。
- request: 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
- session:每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
- global-session:全局session作用域,仅仅在基于portlet的web应用中才有意义,Spring5已经没有了。Portlet是能够生成语义代码(例如:HTML)片段的小型Java Web插件。它们基于portlet容器,可以像servlet一样处理HTTP请求。但是,与 servlet 不同,每个 portlet 都有不同的会话。
Spring 支持的常用数据库事务传播行为和事务的隔离级别?
事务的隔离级别
TransactionDefinition 接口中定义了五个表示隔离级别的常量:
- TransactionDefinition.ISOLATION_DEFAULT: 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.
- TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
- TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
- TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
事务的传播行为
支持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
不支持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况:
- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
Spring MVC 如果解决 POST 请求中文乱码问题?
解决 POST 请求中文乱码问题
修改项目中web.xml文件
<filter>
<filter-name>CharacterEncodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>CharacterEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
解决 Get 请求中文乱码问题
修改tomcat中server.xml文件
<Connector URIEncoding="UTF-8" port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
Spring MVC 的工作流程?
流程说明(重要):
1、客户端(浏览器)发送请求,直接请求到 DispatcherServlet。
2、DispatcherServlet 根据请求信息调用 HandlerMapping,解析请求对应的 Handler。
3、解析到对应的 Handler(也就是我们平常说的 Controller 控制器)后,开始由 HandlerAdapter 适配器处理。
4、HandlerAdapter 会根据 Handler 来调用真正的处理器来处理请求,并处理相应的业务逻辑。
5、处理器处理完业务后,会返回一个 ModelAndView 对象,Model 是返回的数据对象,View 是个逻辑上的 View。
6、ViewResolver 会根据逻辑 View 查找实际的 View。
7、DispaterServlet 把返回的 Model 传给 View(视图渲染)。
8、把 View 返回给请求者(浏览器)
Mybatis 中当实体类中的属性名和表中的字段不一样,怎么解决?
解决方案有三种如下:
1、写 SQL 语句的时候 写别名
2、在MyBatis的全局配置文件中开启驼峰命名规则,前提是符合驼峰命名规则
<!-- 开启驼峰命名规则,可以将数据库中下划线映射为驼峰命名
列如 last_name 可以映射为 lastName
-->
<setting name="mapUnderscoreToCameLCase" value="true" />
3、在Mapper映射文件中使用 resultMap 自定义映射
<!--
自定义映射
-->
<resultMap type="com.atguigu.pojo.Employee" id="myMap">
<!-- 映射主键 -->
<id cloumn="id" property="id"/>
<!-- 映射其他列 -->
<result column="last_name" property="lastName" />
<result column="email" property="email" />
<result column="salary" property="salary" />
<result column="dept_id" property="deptId" />
</resultMap>
10、分布式
单点登录
单点登录: 一处登录多处使用!
前提:单点登录多使用在分布式系统中
购物车实现过程

消息队列在项目中的使用

消息队列的弊端
播行为和事务的隔离级别?
事务的隔离级别
TransactionDefinition 接口中定义了五个表示隔离级别的常量:
- TransactionDefinition.ISOLATION_DEFAULT: 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.
- TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
- TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
- TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
事务的传播行为
支持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
不支持当前事务的情况:
- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况:
- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
Spring MVC 如果解决 POST 请求中文乱码问题?
解决 POST 请求中文乱码问题
修改项目中web.xml文件
<filter>
<filter-name>CharacterEncodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>CharacterEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
解决 Get 请求中文乱码问题
修改tomcat中server.xml文件
<Connector URIEncoding="UTF-8" port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
Spring MVC 的工作流程?
流程说明(重要):
1、客户端(浏览器)发送请求,直接请求到 DispatcherServlet。
2、DispatcherServlet 根据请求信息调用 HandlerMapping,解析请求对应的 Handler。
3、解析到对应的 Handler(也就是我们平常说的 Controller 控制器)后,开始由 HandlerAdapter 适配器处理。
4、HandlerAdapter 会根据 Handler 来调用真正的处理器来处理请求,并处理相应的业务逻辑。
5、处理器处理完业务后,会返回一个 ModelAndView 对象,Model 是返回的数据对象,View 是个逻辑上的 View。
6、ViewResolver 会根据逻辑 View 查找实际的 View。
7、DispaterServlet 把返回的 Model 传给 View(视图渲染)。
8、把 View 返回给请求者(浏览器)
Mybatis 中当实体类中的属性名和表中的字段不一样,怎么解决?
解决方案有三种如下:
1、写 SQL 语句的时候 写别名
2、在MyBatis的全局配置文件中开启驼峰命名规则,前提是符合驼峰命名规则
<!-- 开启驼峰命名规则,可以将数据库中下划线映射为驼峰命名
列如 last_name 可以映射为 lastName
-->
<setting name="mapUnderscoreToCameLCase" value="true" />
3、在Mapper映射文件中使用 resultMap 自定义映射
<!--
自定义映射
-->
<resultMap type="com.atguigu.pojo.Employee" id="myMap">
<!-- 映射主键 -->
<id cloumn="id" property="id"/>
<!-- 映射其他列 -->
<result column="last_name" property="lastName" />
<result column="email" property="email" />
<result column="salary" property="salary" />
<result column="dept_id" property="deptId" />
</resultMap>
10、分布式
单点登录
单点登录: 一处登录多处使用!
前提:单点登录多使用在分布式系统中
购物车实现过程
消息队列在项目中的使用
消息队列的弊端
消息的不确定性: 延迟队列 和 轮询技术来解决问题即可!














 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









