







1.2 图
图中的度(degree):
每个节点与别的节点相连的边的条数,就是这个节点的度(每条边就是一个度)
图的分类:
无向图,有向图,权重图
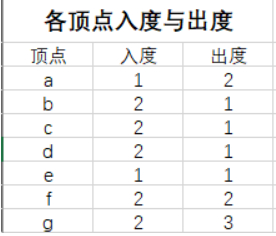
有向图中的两个概念:
入度:多少边指向该节点
出度:多少边以这个点为起点,指向别的节点
注意:一个节点的入度和出度之和等于该节点的度
图示如下:

1.3 堆(LC:215 + 692)
堆(Heap):
首先,是一种完全二叉树
然后,分为两种情况:
- 最大堆:树中每个节点的值均大于等于该节点的孩子节点
- 最小堆:树中每个节点的值均小于等于该节点的孩子节点
- 最大堆的特点:堆顶元素是所有元素中的最大值
- 最小堆的特点:堆顶元素是所有元素中的最小值
堆相关操作的时间复杂度:
访问Access:在堆中不通过索引去访问元素
搜索Search:搜索堆顶元素时的复杂度是O(1),搜索其它元素时是O(N)
添加Insert:O(logN)。假设是最大堆,将添加的元素放在堆的最后一位,然后开始与其父节点比较大小,比父节点大则和父节点交换位置,一直交换到堆顶元素或者小于等于父节点时,不再进行交换,交换的次数的最大值是堆的层数,即logN次,下图是添加节点元素值为7的过程:

删除Delete:O(logN)。假设是最小堆,将堆中最后一个元素填充到所删除的元素的位置上(为了保持完全二叉树的结构),然后将该元素和其孩子节点比较大小(可以是左孩子,可以右孩子),比该元素小,则和孩子节点交换位置,一直交换到没有孩子节点或者大于等于其孩子节点时,不再进行交换,交换的次数的最大值是堆的层数,即logN次,下图是删除节点元素值为1的过程:

堆化操作:
把一组无序的数添加到堆中去,即把一个无序数组,转化成堆
堆化操作的时间复杂度是O(n),和堆排序的时间复杂度O(nlogn)不同
将一个长度为n的数组转换成堆,需要两步:
- 将这个数组转换成完全二叉树,时间复杂度为O(n):因为只需要从头到尾遍历一遍数组即可,如下图所示:
- 将完全二叉树转换成堆,时间复杂度为O(n):假设为最小堆,需要从最下面一层开始,将每个节点和其父节点进行比较,将较小的放在父节点的位置,直到所有的父节点都比孩子节点小,这个操作也需要O(n)的时间复杂度
由于步骤1和2是级联的,所以最终总的时间复杂度为O(n)

注意 堆化 和 向堆中添加元素 的区别:
堆化不是向已有的堆中添加一个一个无序数组的元素,即堆化不是前面所说的添加Insert(时间复杂度为O(logN))这个操作
堆化过程:无序数组--完全二叉树--堆,这个过程的时间复杂度为O(n)
堆相关操作的代码:
//创建堆结构
PriorityQueue<Integer> minheap = new PriorityQueue<>();
PriorityQueue<Integer> maxheap = new PriorityQueue<>(Collections.reverseOrder()); //在最小堆的基础上进行逆序排列
//添加元素,O(logN)
minheap.add(10);
minheap.add(11);
minheap.add(8);
minheap.add(9);
minheap.add(2);
minheap.add(5);
maxheap.add(10);
maxheap.add(11);
maxheap.add(8);
maxheap.add(9);
maxheap.add(2);
maxheap.add(5);
//打印
System.out.println(minheap.toString()); //[2, 8, 5, 11, 9, 10]
System.out.println(maxheap); //[11, 10, 8, 9, 2, 5]
//获取堆顶元素(不删除),O(1)
minheap.peek(); //2
maxheap.peek(); //11
//删除堆顶元素,并返回该元素,此时堆会将剩下的节点元素重新交换位置,得到最小堆或者最大堆,O(logN)
minheap.poll(); //2
maxheap.poll(); //11
//获取堆的大小,O(1)
minheap.size(); //5
maxheap.size(); //5
//遍历堆,O(N)
while(!minheap.isEmpty()){
System.out.println(minheap.poll()); //5 8 9 10 11
}
和堆有关题目的关键词:前k个/第k个 + 最大/最小 的元素
215. 数组中的第K个最大元素 - 力扣(LeetCode) (leetcode-cn.com)
难度:中等
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4说明:
你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
思路:
求第k个最大的元素,只需要将最大堆中的前k-1个堆顶元素删除,此时的堆顶元素就是第k个最大的元素
同理,求第k个最小的元素,使用最小堆即可
代码:
class Solution {
public int findKthLargest(int[] nums, int k) {
//创建最大堆
PriorityQueue<Integer> maxheap = new PriorityQueue<>(Collections.reverseOrder());
int res = 0;
for(int item : nums){
maxheap.add(item);
}
//将前k-1个大的元素删掉后,就可以得到第k个最大的元素
while(k > 1){
maxheap.poll();
k--;
}
res = maxheap.peek();
return res;
}
}复杂度分析:
时间复杂度:O(NlogN)
- 第二个while循环:删除k-1次堆顶元素,时间复杂度为O(klogN)。总的时间复杂度为两者之和,因为k
- 第一个for循环:遍历数组的时间复杂度是O(N),其中每一次循环都需要将数组中的元素添加到堆中,即堆的添加操作,该操作的时间复杂度为O(logN),因此该循环的总时间复杂度为O(NlogN)
空间复杂度:O(N),需要额外存放N个节点元素的堆空间,大小为O(N)
692. 前K个高频单词 - 力扣(LeetCode) (leetcode-cn.com)
相似题:347. 前 K 个高频元素
难度:中等
给一非空的单词列表,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。
示例 1:
输入: ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出: ["i", "love"]
解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。注意,按字母顺序 "i" 在 "love" 之前。示例 2:
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
输出: ["the", "is", "sunny", "day"]
解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,出现次数依次为 4, 3, 2 和 1 次。注意:
- 假定 k 总为有效值, 1 ≤ k ≤ 集合元素数。
- 输入的单词均由小写字母组成。
扩展练习:
- 尝试以 O(n log k) 时间复杂度和 O(n) 空间复杂度解决。
思路:
目标:求前 k 个出现次数最多的单词
- 使用最大堆求出前k个最多,也可以使用最小堆过滤去除前N-k个最少(此时最小堆中剩下的就是前k个最多)
- 使用哈希表解决出现次数的计数问题,key表示单词列表中的不同元素,value表示key对应的元素在单词列表中出现的次数
解法1:选用 最大堆 + 哈希表 的组合结构
解法1步骤:
- 遍历字符串数组,key记录数组中不同的字符串,value记录同一个字符串出现的次数
- 重写最大堆的排序方式,重写成:value从大到小排列,相同的value则将key从小到大排列
- 遍历哈希表中的key,添加到最大堆中
- 依次删除前k个堆顶元素,并同时保存这k个元素到返回值res中,最终返回res
解法2:选用 最小堆 + 哈希表 的组合结构
解法2步骤:
- 遍历字符串数组,key记录数组中不同的字符串,value记录同一个字符串出现的次数
- 重写最小堆的排序方式,重写成:value从小到大排列,相同的value则将key从大到小排列(与最大堆正好相反)
- 遍历哈希表中的key,添加到最小堆中,当最小堆中的元素个数大于k个时,说明堆顶的元素不是前k个最多的单词,此时删除堆顶元素
- 将装有k个元素的最小堆依次进行删除堆顶元素,并按顺序保存这k个元素到返回值res中,此时的res中的单词排列顺序与正确的返回值的排列顺序是相反的,所以需要反转res,最终返回res
两个细节点:
- 最大堆和最小堆重写的排序方法正好相反:
- 最大堆的容量为n,前k个堆顶元素,就是前k个出现最多的单词
- 最小堆的容量为k,前k个堆顶元素顺序的反转,就是前k个出现最多的单词
- 原因:由于最小堆重写的排序方法与题目要求的排序方法正好相反,所以排在最小堆中前面的N-k个元素,是前N-k个出现次数最少的元素,将这N-k个元素过滤删除之后,得到的就是前k个出现次数最多的元素,但是需要将这k个元素的顺序反转,才能得到正确的返回值顺序
- 由于最大堆和最小堆的容量不同:
- 使用最大堆,每次插入元素的时间复杂度为O(logn)
- 使用最小堆,每次插入元素的时间复杂度为O(logk)
因此:使用最小堆的时间复杂度低于最大堆
代码:
解法1:最大堆 + 哈希表
class Solution {
public List<String> topKFrequent(String[] words, int k) {
HashMap<String, Integer> map = new HashMap<>();
//难点:创建最大堆时,还需要同时重写最大堆的排序方法,重写成:value从大到小排列,相同的value则将key从小到大排列
PriorityQueue<String> maxheap = new PriorityQueue<>(Collections.reverseOrder(new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
//注意!!
//return s1.compareTo(s2)这种写法的排序结果是由小到大的,这是默认的排序方式
//return s2.compareTo(s1) 或者 return -s1.compareTo(s2)这种写法的排序结果是由大到小的
return map.get(s1).equals(map.get(s2)) ? -(s1.compareTo(s2)) : (map.get(s1) - map.get(s2));
//这里的返回值表明:如果value相等,按照key从大到小排列,如果value不相等,则按照value从小到大排列,正好和需要重写的排序要求相反
//但是,外面还有一层reversOrder,将里面的排序结果作了翻转,就满足了需要重写的排序要求
}
}));
//根据输出要求是List<String>类型,初始化输出
List<String> res = new ArrayList<>();
for(String item : words){
map.put(item, map.getOrDefault(item, 0) + 1); //这样写省去了map.containsKey(item)的判断,代码简洁,但是要注意将defaultValue设置为0
}
//直接遍历map中的key,使用String类型来接收
for(String word : map.keySet()){
maxheap.add(word);
}
while(k > 0){
res.add(maxheap.poll());
k--;
}
return res;
}
}解法2:最小堆 + 哈希表
class Solution {
public List<String> topKFrequent(String[] words, int k) {
HashMap<String, Integer> map = new HashMap<>();
//难点:创建最小堆时,还需要同时重写最小堆的排序方法,最小堆的重写方法和最大堆的重写方法正好相反!
//即:value从小到大排列,相同的value则将key从大到小排列
PriorityQueue<String> minheap = new PriorityQueue<>((new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
//return s1.compareTo(s2)这种写法的排序结果是由小到大的,这是默认的排序方式
//return s2.compareTo(s1) 或者 return -s1.compareTo(s2)这种写法的排序结果是由大到小的
return map.get(s1).equals(map.get(s2)) ? -(s1.compareTo(s2)) : (map.get(s1) - map.get(s2));
//这里的返回值表明:如果value相等,按照key从大到小排列,如果value不相等,按照value从小到大排列
}
}));
//根据输出要求是List<String>类型,初始化输出
List<String> res = new ArrayList<>();
for(String item : words){
map.put(item, map.getOrDefault(item, 0) + 1); //这样写省去了map.containsKey(item)的判断,代码简洁,但是要注意将defaultValue设置为0
}
//直接遍历map中的key,使用String类型来接收
for(String word : map.keySet()){
minheap.add(word);
//注意:最小堆的大小为k,即最小堆中只会存放k个元素
if(minheap.size() > k){
minheap.poll();
}
}
while(k > 0){
res.add(minheap.poll());
k--;
}
//res中的元素是按照:出现的次数从小到大排列,相同的出现次数则按字母顺序从大到小排列
//因此res中的元素顺序与正确的元素顺序正好相反,所以需要将res反转
Collections.reverse(res); //本方法没有返回值,不要写成 res=Collections.reverse(res)
return res;
}
}复杂度分析:
解法1:
时间复杂度:O(nlogn),n为字符串数组的长度
- 第一个for循环,遍历一遍字符数组并向map中不断添加,时间复杂度为O(n)与O(1)的乘积,为O(n);
- 第二个for循环,向最大堆中添加元素的时间复杂度为O(logn),总的时间复杂度是O(n)与O(logn)的乘积,为O(nlogn);
- 第三个while循环,从最大堆中删除堆顶元素的时间复杂度为O(1),总的时间复杂度为为O(k);
- 因此三次循环的时间复杂度相加,得到的总时间复杂度为O(nlogn)
空间复杂度:O(n),使用哈希表和最大堆的空间复杂度均为O(n),因此总的空间复杂度为O(n)
解法2:
时间复杂度:O(nlogk),n为字符串数组的长度
- 第一个for循环,遍历一遍字符数组并向map中不断添加,时间复杂度为O(n)与O(1)的乘积,为O(n);
- 第二个for循环,向最小堆中添加元素的时间复杂度为O(logk),总的时间复杂度是O(n)与O(logk)的乘积,为O(nlogk);
- 第三个while循环,从最小堆中删除堆顶元素的时间复杂度为O(1),总的时间复杂度为为O(k);
- 因此三次循环的时间复杂度相加,得到的总时间复杂度为O(nlogk)
空间复杂度:O(n),使用哈希表堆的空间复杂度为O(n),最小堆的空间复杂度为O(k),因此总的空间复杂度为O(n)














 1222
1222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









