






我用到的资源
- 华为云轻量服务器一台

- CentOS8
- JDK1.8
- Haddop-2.7.1.tar.gz
- SecureCRT(用来远程连接)
一、准备Hadoop压缩包并安装
1、安装Hadoop
(1)准备好hadoop压缩包

(2)安装hadoop
tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local # 将hadoop安装到/usr/local目录下

(3)查看是否安装成功
/usr/local/hadoop-2.7.1/bin/hadoop version # 因为没有设置软链接,所以只能通过bin来查看
Hadoop 2.7.1
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a
Compiled by jenkins on 2015-06-29T06:04Z
Compiled with protoc 2.5.0
From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a
This command was run using /usr/local/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar

2、将hadoop添加到环境变量
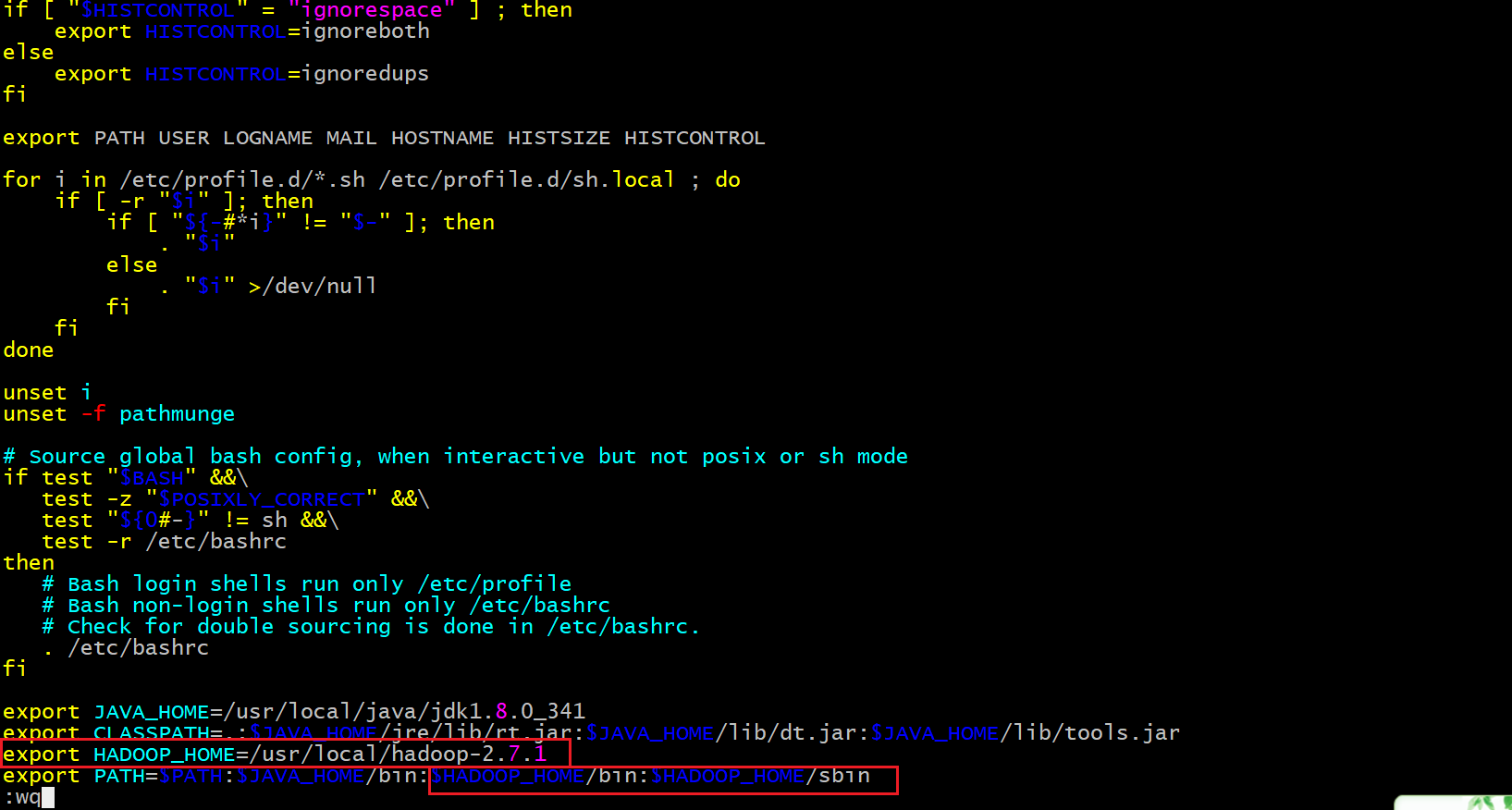
vim /etc/profile
(1)在文件末尾添加以下内容
export HADOOP_HOME=/usr/local/hadoop-2.7.1
# PATH在安装jdk时已经设置,这里需要添加上HADOOP的路径
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(2)保存文件,刷新配置
# 刷新配置文件
source /etc/profile
# 测试是否生效
hadoop version

二、伪分布式配置文件设置
先进入haoop的配置文件目录
cd /usr/local/hadoop-2.7.1/etc/hadoop/ #/usr/local/hadoop-2.7.1为我的Hadoop的安装路径

1、修改 hadoop-env.sh
修改文件中的export JAVA_HOME=${JAVA_HOME},将JAVA_HOME设置为你JDK的路径
vim hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_341

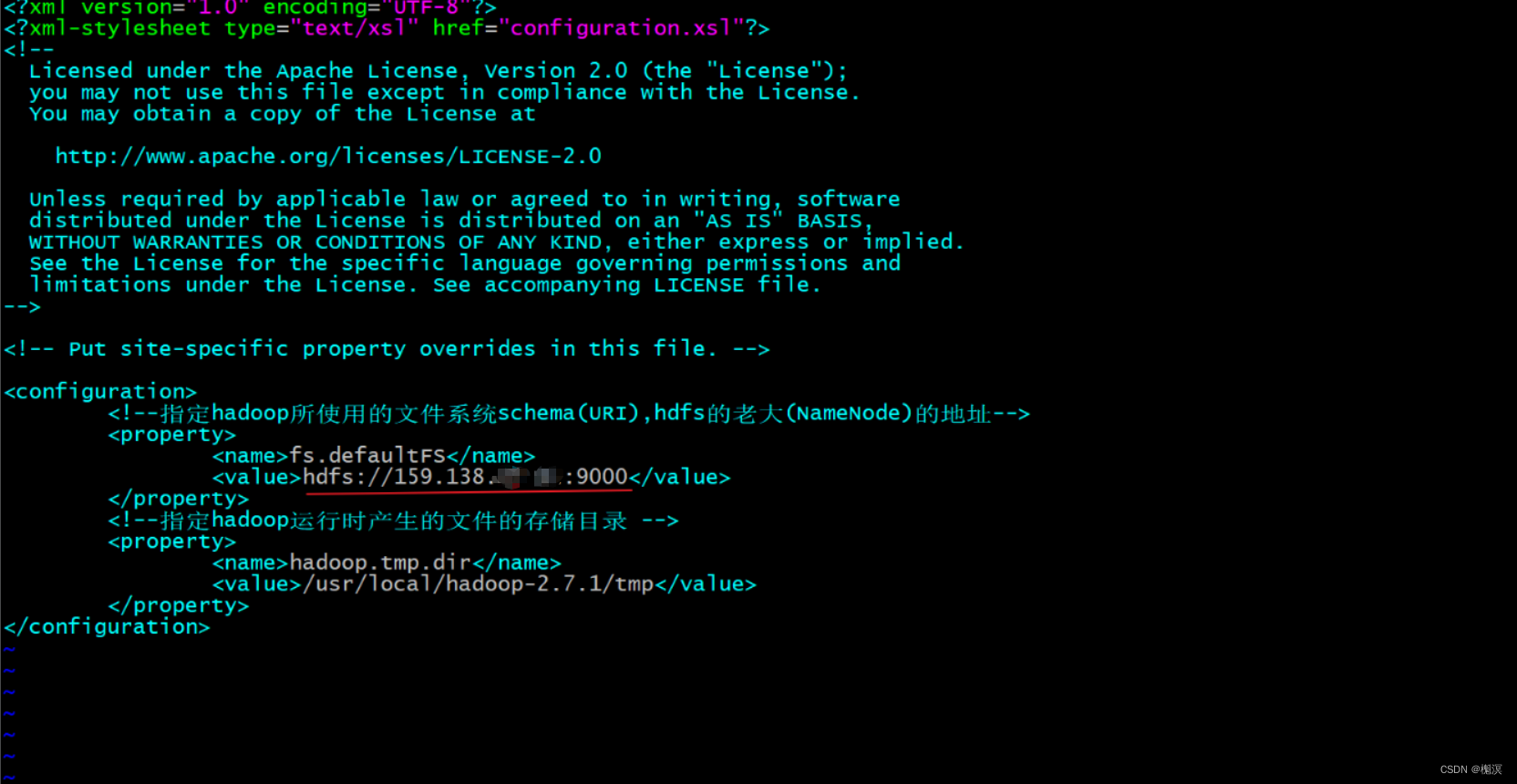
2、修改core-site.xml
vim core-site.xml
在文件末尾的<configuration></configuration>之间添加以下内容
注意:这里的地址千万别用外网地址,因为云服务器中只有一块内网网卡,外网地址是服务商分配的
<!--指定hadoop所使用的文件系统schema(URI),hdfs的老大(NameNode)的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.109:9000</value>
</property>
<!--指定hadoop运行时产生的文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.1/tmp</value>
</property>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4Wk8xcZR-1669779228261)(../MDimages/Hadoop%E4%BC%AA%E5%88%86%E5%B8%83%E5%BC%8F%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2_images/image-20221130105228595.png)]](https://img-blog.csdnimg.cn/ce85d51f04ac43aa9c41db1e59a7f3a9.png)
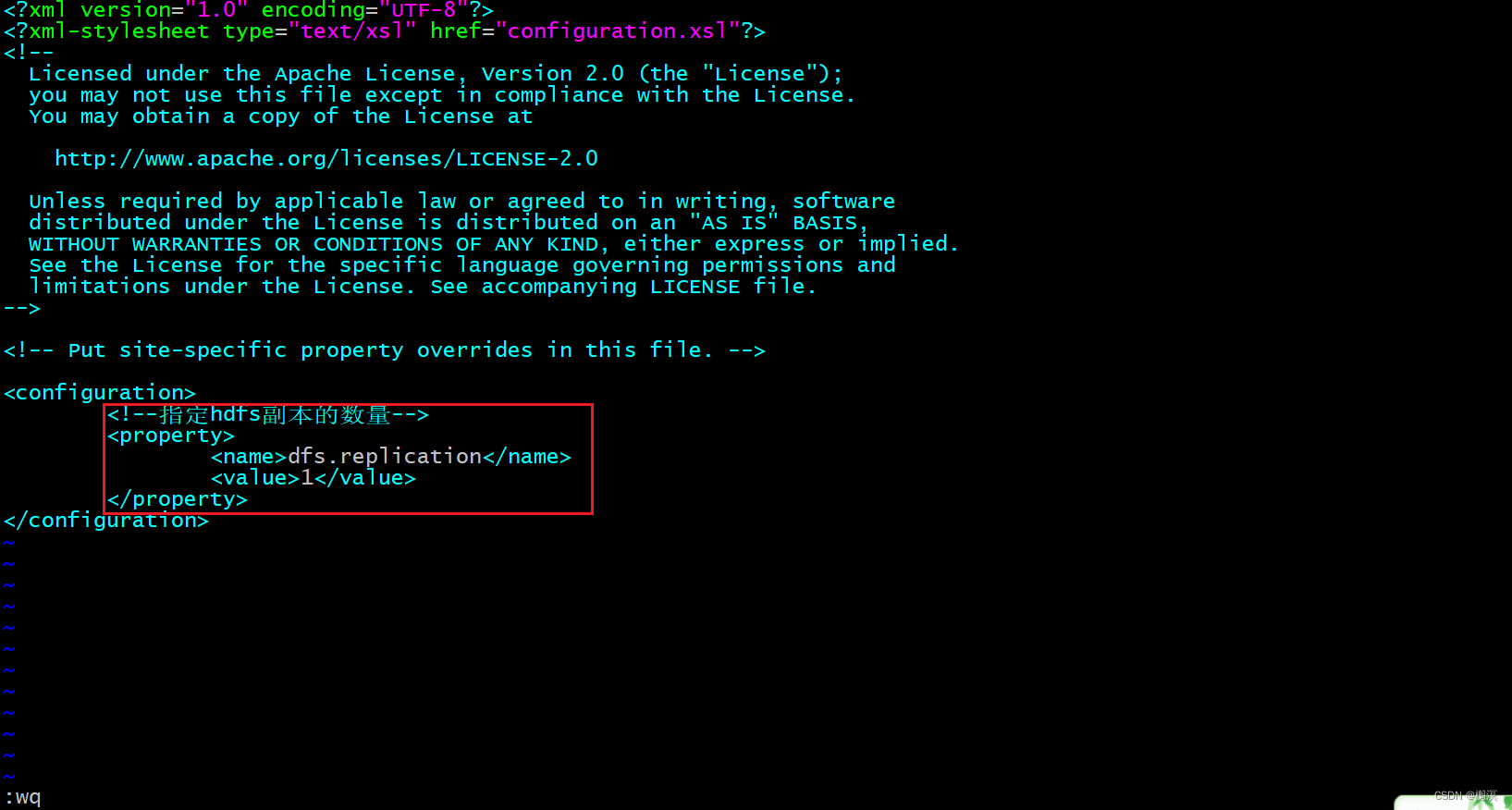
3、修改hdfs-site.xml
vim hdfs-site.xml
在文件末尾的<configuration></configuration>之间添加以下内容
<!--指定hdfs副本的数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
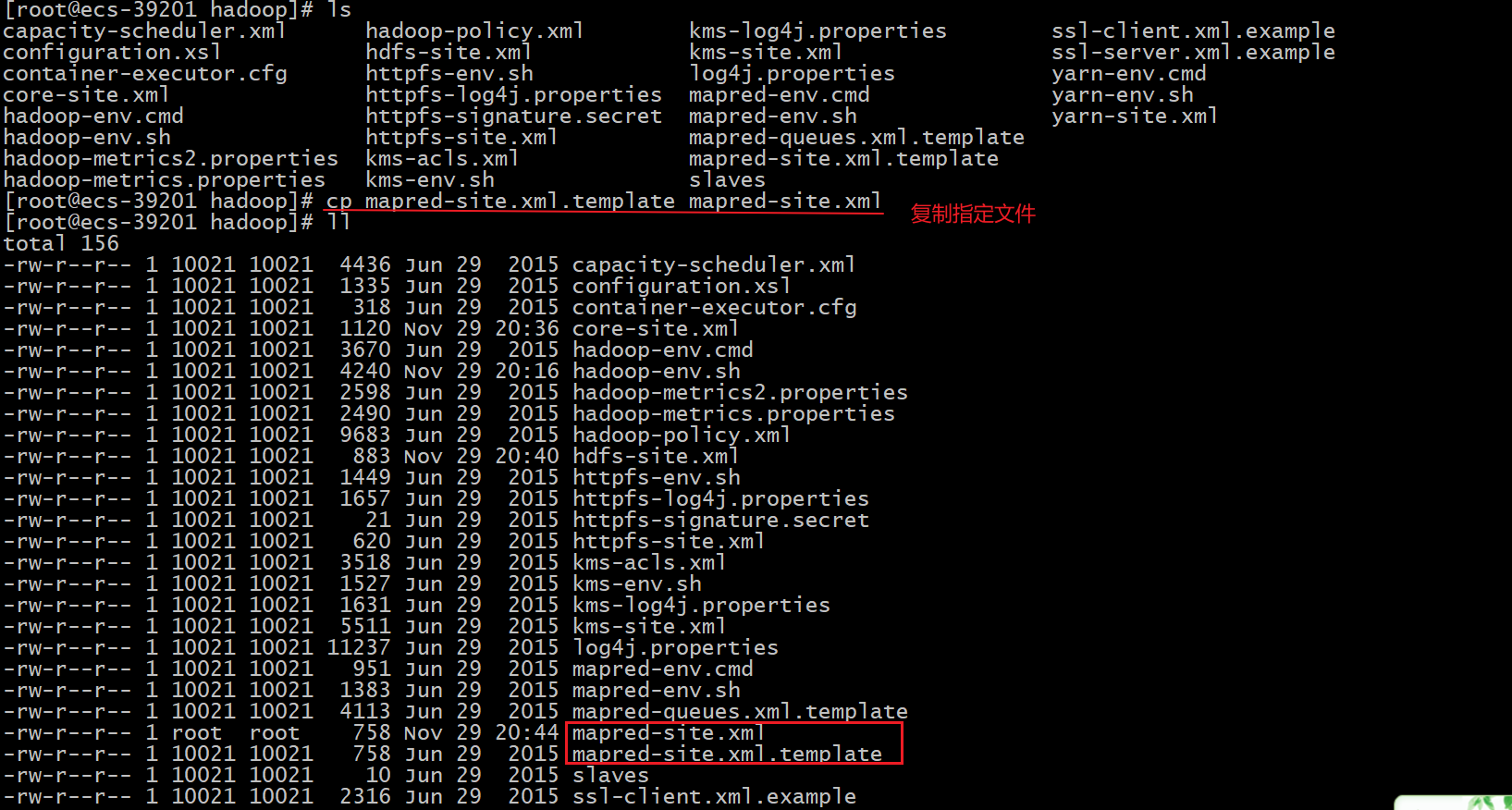
4、拷贝mapred-site.xml.template文件内容并命名为mapred-site.xml
# 拷贝
cp mapred-site.xml.template mapred-site.xml
5、修改mapred-site.xml
vim mapred-site.xml
在文件末尾的<configuration></configuration>之间添加以下内容
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

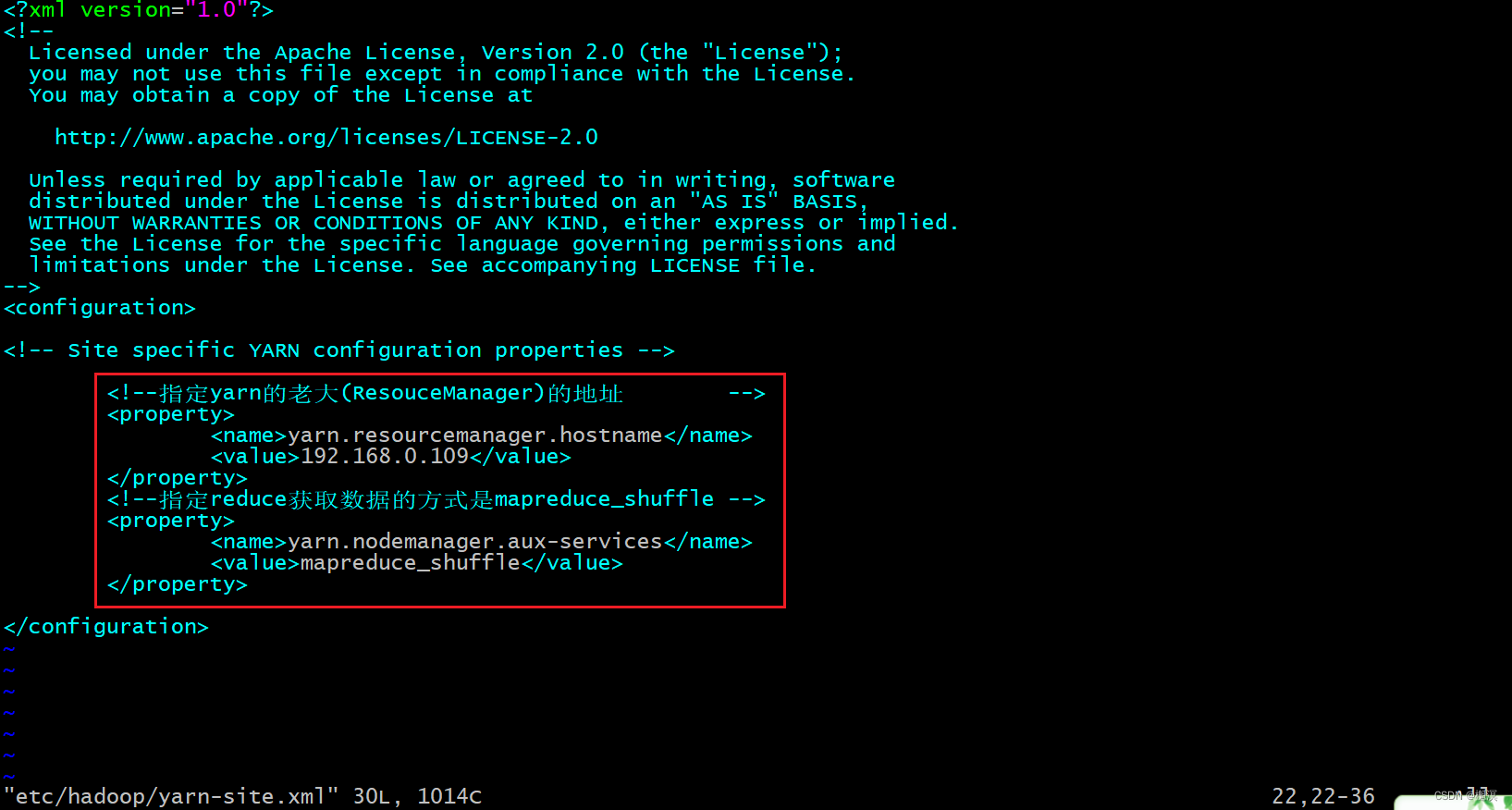
6、修改 yarn-site.xml
vim yarn-site.xml
在文件末尾的<configuration></configuration>之间添加以下内容
<!--指定yarn的老大(ResouceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.109</value>
</property>
<!--指定reduce获取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
三、启动Hadoop集群
1、关闭防火墙
# Hadoop启动需要使用很多端口,如果不关闭防火墙会出现无法连接的问题
systemctl stop firewalld
注意:需要root权限才能关闭

2、格式化HDFS(namenode)第一次使用时要格式化
hadoop namenode -format

3、启动HDFS
# 启动hdfs
start-dfs.sh
#注意在启动过程要多次输入yes和root的密码
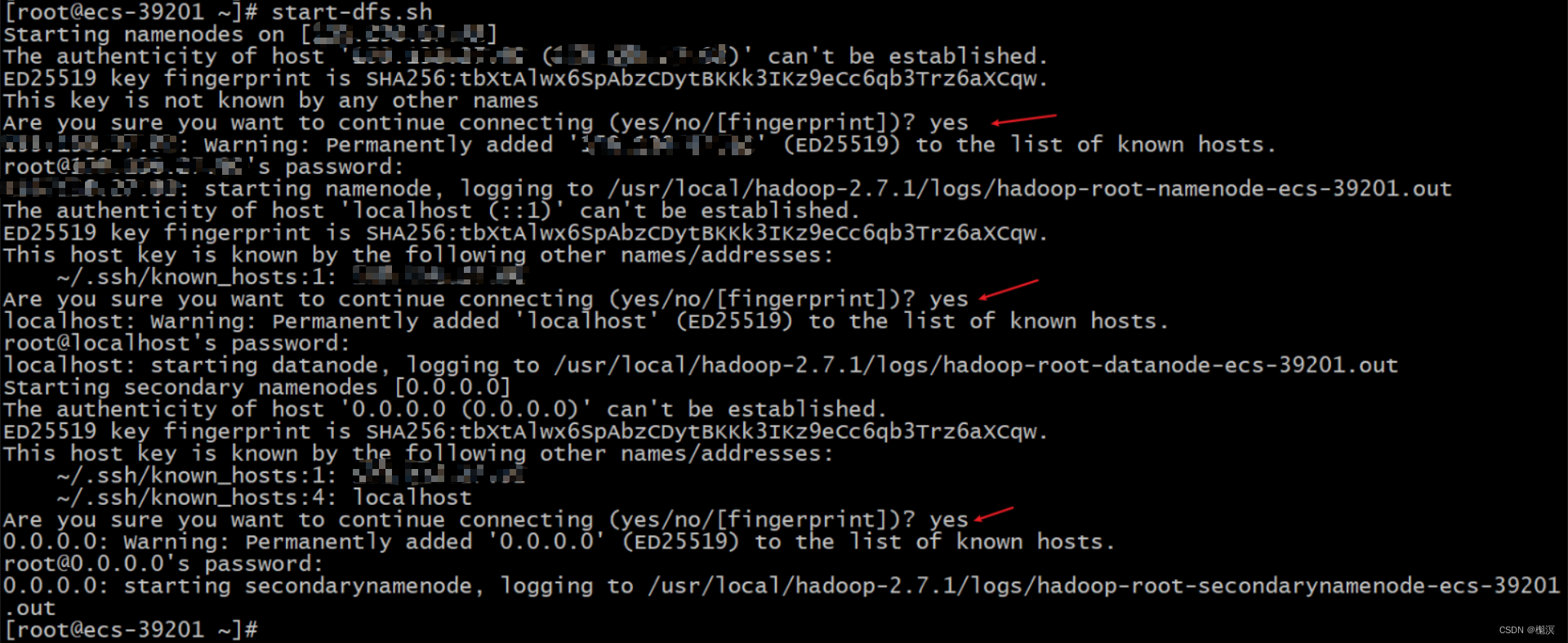
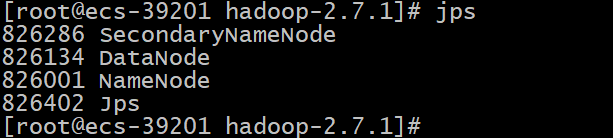
# 查看当前进程
jps
4、启动YARN
# 启动YARN
start-yarn.sh

# 查看当前进程
jps

当DFS和YARN的进程都启动时,应存在5个进程
ResourceManager
SecondaryNameNode
DataNode
NodeManager
NameNode
5、访问HDFS的WEB管理页面
启动Hadoop后,通过访问50070端口可以进入HDFS的管理页面
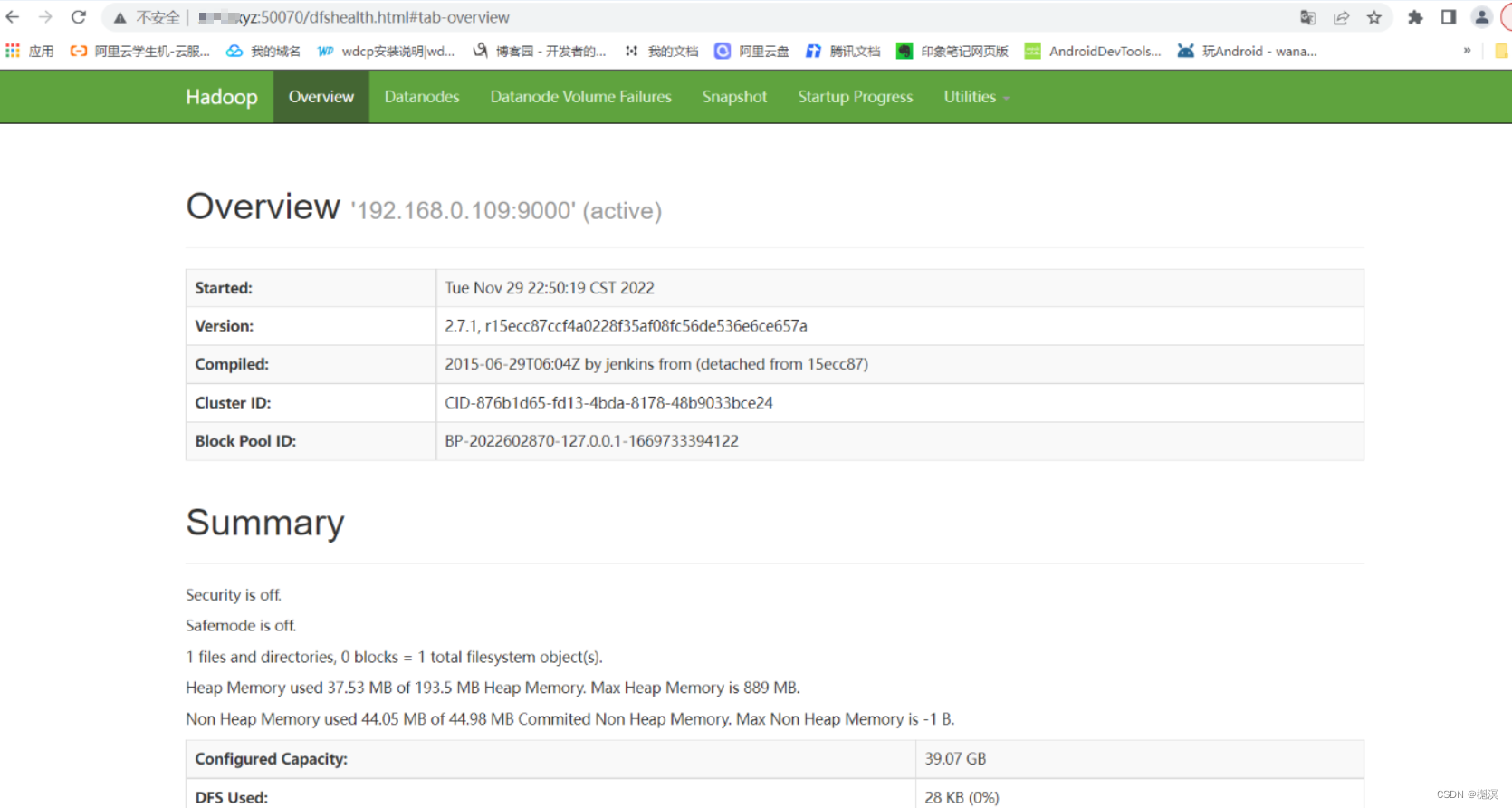
6、访问YARN的WEB管理页面
启动Hadoop后,通过访问8088端口可以进入YARN的管理页面
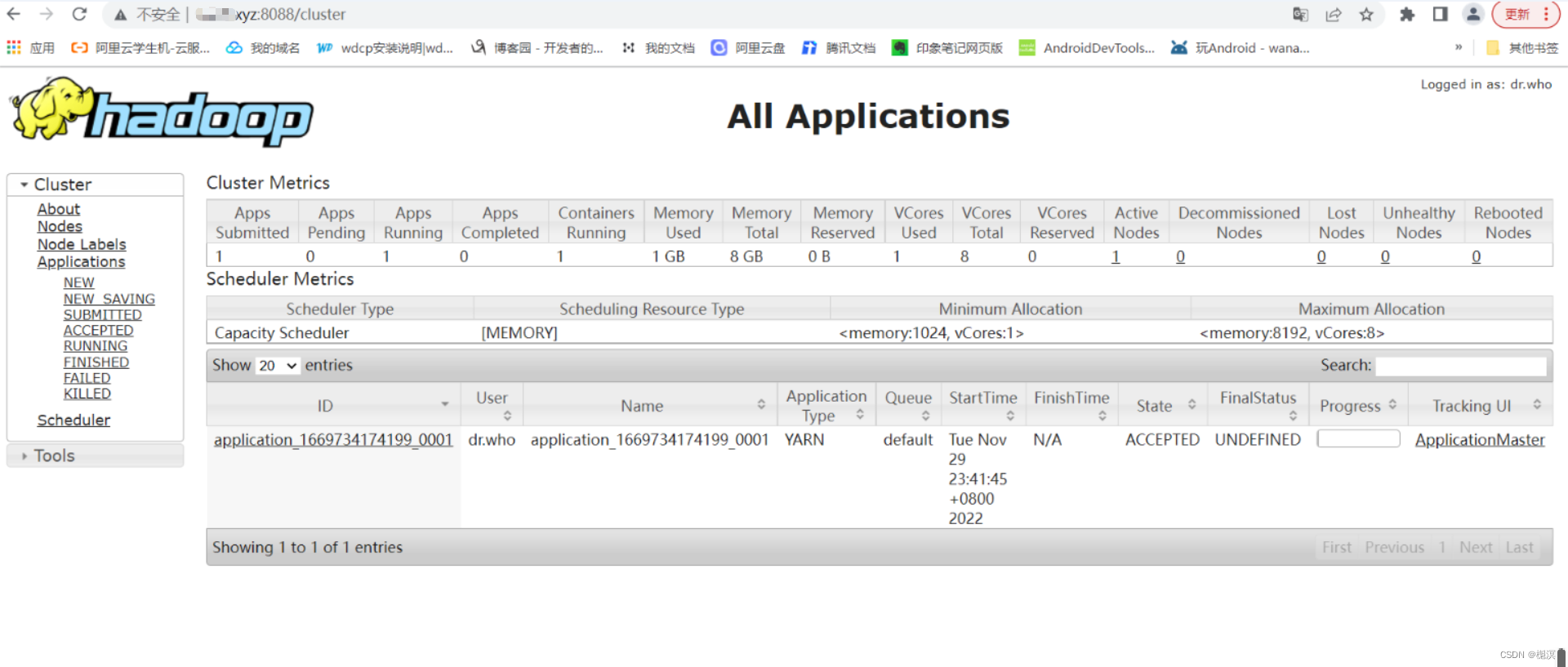
7、停止HDFS和YARN服务
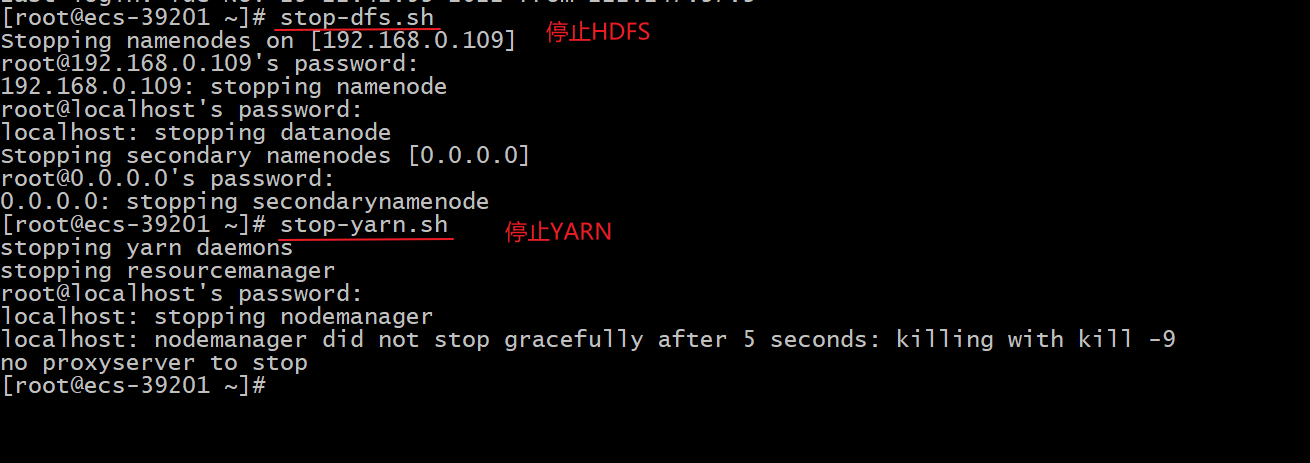
四、遇到问题
NameNode启动报错:Cannot assign requested address
当我启动HDFS服务后发现少了一个NameNode进程,于是查看日志文件发现报BindException ,通过百度发现,原来是因为我在core-site.xml文件中设置的defaultFS值是外网IP,而云服务器只有一块内网网卡,外网IP是设置在云服务提供商的公网网关的,通过NAT技术映射到内网网卡上,所以NameNode无法访问该地址。
解决办法:
将defaultFS值设置为服务器的内网IP
重新格式化HDFS
NameNode在第一次格式化失败后,需要删除格式化失败残留文件,才能重新进行格式化
(1)删除残留文件
rm -rf /usr/local/hadoop-2.7.1/tmp # 删除hdfs缓存文件
rm -rf /usr/local/hadoop-2.7.1/dfs/name # 删除NameNode缓存目录
rm -rf /usr/local/hadoop-2.7.1/dfs/data # 删除DataNode婚车目录
rm -rf /usr/local/hadoop-2.7.1/logs # 删除日志文件
(2)手动创建配置文件
mkdir -p /usr/local/hadoop-2.7.1/tmp # 创建hdfs缓存文件
mkdir -p /usr/local/hadoop-2.7.1/dfs/name # 创建NameNode缓存目录
mkdir -p /usr/local/hadoop-2.7.1/dfs/data # 创建DataNode婚车目录
mkdir -p /usr/local/hadoop-2.7.1/logs # 创建日志目录
(3)重新格式化
hadoop namenode -format















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









