






一、简介
涉及三方面问题,首先是数据库驱动以及类型匹配问题,其次数据表结构初始化脚本(schem-dm.sql),最后是DM数据库模式问题,最后一个问题其实是一个共性问题,所有组件兼容达梦时都会面临此问题,后面会进行详细介绍。
二、数据库驱动以及类型匹配
适配驱动(Unable to detect database type)
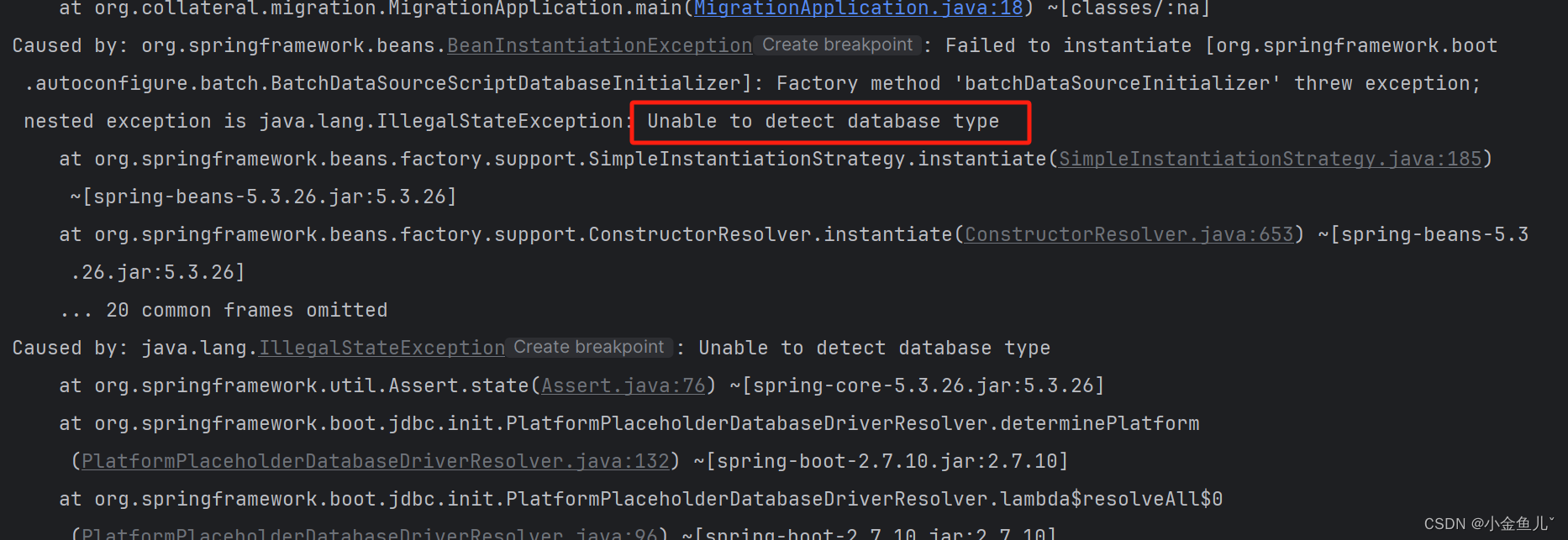
此问题产生的原理是默认的数据库驱动以及类型匹配并不兼容DM(达梦)
根据报错信息进行debug
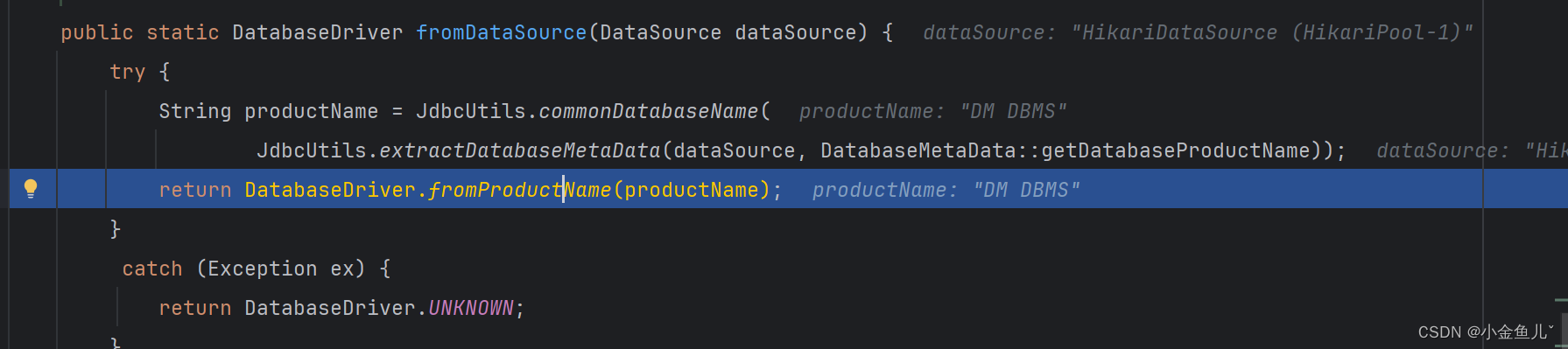
首先可以看到productName的属性值为 “DM DBMS”
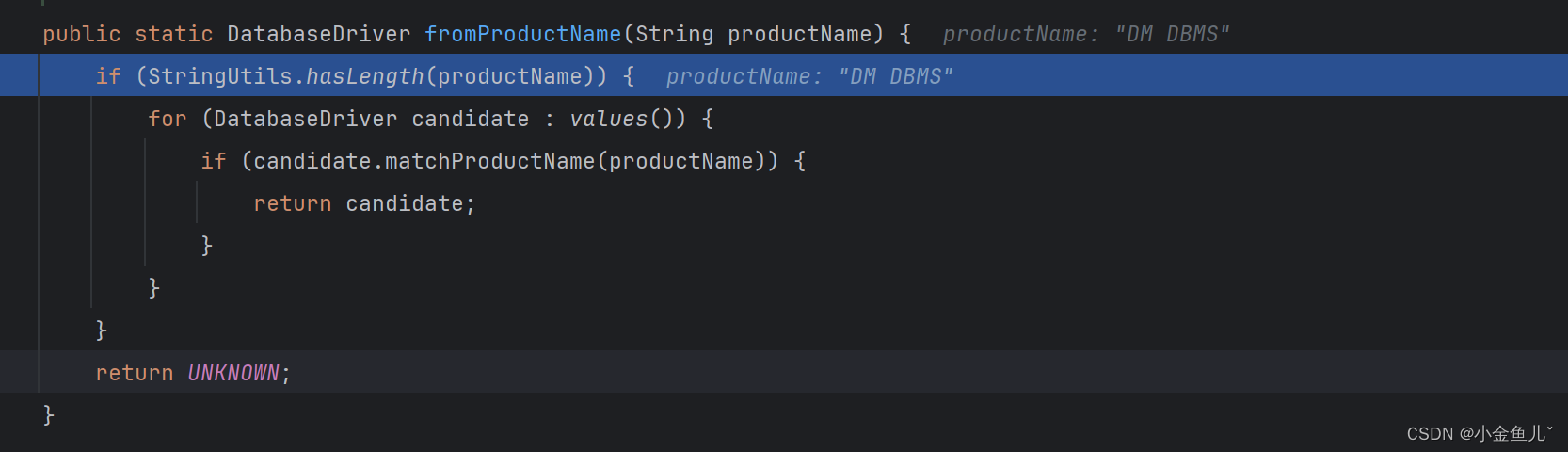
可以看到次属性值会根据DatabaseDriver枚举类中定义的常量进行匹配
原DatabaseDriver 类
public enum DatabaseDriver {
/**
* Unknown type.
*/
UNKNOWN(null, null),
/**
* Apache Derby.
*/
DERBY("Apache Derby", "org.apache.derby.jdbc.EmbeddedDriver", "org.apache.derby.jdbc.EmbeddedXADataSource",
"SELECT 1 FROM SYSIBM.SYSDUMMY1"),
/**
* H2.
*/
H2("H2", "org.h2.Driver", "org.h2.jdbcx.JdbcDataSource", "SELECT 1"),
/**
* HyperSQL DataBase.
*/
HSQLDB("HSQL Database Engine", "org.hsqldb.jdbc.JDBCDriver", "org.hsqldb.jdbc.pool.JDBCXADataSource",
"SELECT COUNT(*) FROM INFORMATION_SCHEMA.SYSTEM_USERS"),
/**
* SQLite.
*/
SQLITE("SQLite", "org.sqlite.JDBC"),
/**
* MySQL.
*/
MYSQL("MySQL", "com.mysql.cj.jdbc.Driver", "com.mysql.cj.jdbc.MysqlXADataSource", "/* ping */ SELECT 1"),
/**
* Maria DB.
*/
MARIADB("MariaDB", "org.mariadb.jdbc.Driver", "org.mariadb.jdbc.MariaDbDataSource", "SELECT 1"),
/**
* Google App Engine.
* @deprecated since 2.7.0 for removal in 3.0.0 without replacement following the
* removal of AppEngineDriver from version 2.0 of the AppEngine API SDK.
*/
@Deprecated
GAE(null, "com.google.appengine.api.rdbms.AppEngineDriver"),
/**
* Oracle.
*/
ORACLE("Oracle", "oracle.jdbc.OracleDriver", "oracle.jdbc.xa.client.OracleXADataSource",
"SELECT 'Hello' from DUAL"),
/**
* Postgres.
*/
POSTGRESQL("PostgreSQL", "org.postgresql.Driver", "org.postgresql.xa.PGXADataSource", "SELECT 1"),
/**
* Amazon Redshift.
* @since 2.2.0
*/
REDSHIFT("Redshift", "com.amazon.redshift.jdbc.Driver", null, "SELECT 1"),
/**
* HANA - SAP HANA Database - HDB.
* @since 2.1.0
*/
HANA("HDB", "com.sap.db.jdbc.Driver", "com.sap.db.jdbcext.XADataSourceSAP", "SELECT 1 FROM SYS.DUMMY") {
@Override
protected Collection<String> getUrlPrefixes() {
return Collections.singleton("sap");
}
},
/**
* jTDS. As it can be used for several databases, there isn't a single product name we
* could rely on.
*/
JTDS(null, "net.sourceforge.jtds.jdbc.Driver"),
/**
* SQL Server.
*/
SQLSERVER("Microsoft SQL Server", "com.microsoft.sqlserver.jdbc.SQLServerDriver",
"com.microsoft.sqlserver.jdbc.SQLServerXADataSource", "SELECT 1") {
@Override
protected boolean matchProductName(String productName) {
return super.matchProductName(productName) || "SQL SERVER".equalsIgnoreCase(productName);
}
},
/**
* Firebird.
*/
FIREBIRD("Firebird", "org.firebirdsql.jdbc.FBDriver", "org.firebirdsql.ds.FBXADataSource",
"SELECT 1 FROM RDB$DATABASE") {
@Override
protected Collection<String> getUrlPrefixes() {
return Arrays.asList("firebirdsql", "firebird");
}
@Override
protected boolean matchProductName(String productName) {
return super.matchProductName(productName)
|| productName.toLowerCase(Locale.ENGLISH).startsWith("firebird");
}
},
/**
* DB2 Server.
*/
DB2("DB2", "com.ibm.db2.jcc.DB2Driver", "com.ibm.db2.jcc.DB2XADataSource", "SELECT 1 FROM SYSIBM.SYSDUMMY1") {
@Override
protected boolean matchProductName(String productName) {
return super.matchProductName(productName) || productName.toLowerCase(Locale.ENGLISH).startsWith("db2/");
}
},
/**
* DB2 AS400 Server.
*/
DB2_AS400("DB2 UDB for AS/400", "com.ibm.as400.access.AS400JDBCDriver",
"com.ibm.as400.access.AS400JDBCXADataSource", "SELECT 1 FROM SYSIBM.SYSDUMMY1") {
@Override
public String getId() {
return "db2";
}
@Override
protected Collection<String> getUrlPrefixes() {
return Collections.singleton("as400");
}
@Override
protected boolean matchProductName(String productName) {
return super.matchProductName(productName) || productName.toLowerCase(Locale.ENGLISH).contains("as/400");
}
},
/**
* Teradata.
*/
TERADATA("Teradata", "com.teradata.jdbc.TeraDriver"),
/**
* Informix.
*/
INFORMIX("Informix Dynamic Server", "com.informix.jdbc.IfxDriver", null, "select count(*) from systables") {
@Override
protected Collection<String> getUrlPrefixes() {
return Arrays.asList("informix-sqli", "informix-direct");
}
},
/**
* Apache Phoenix.
* @since 2.5.0
*/
PHOENIX("Apache Phoenix", "org.apache.phoenix.jdbc.PhoenixDriver", null, "SELECT 1 FROM SYSTEM.CATALOG LIMIT 1"),
/**
* Testcontainers.
*/
TESTCONTAINERS(null, "org.testcontainers.jdbc.ContainerDatabaseDriver") {
@Override
protected Collection<String> getUrlPrefixes() {
return Collections.singleton("tc");
}
};
....
}
可以看到里面并没有定义DM常量,因此需要定义DM常量,首先由于源码不可修改,根据springboot加载规则,在我们当前项目中创建路径相同、类名相同的文件,此时项目启动会加载我们自定义的文件而不会加载源文件。
因此在我们项目中创建org.springframework.boot.jdbc.DatabaseDriver
public enum DatabaseDriver {
/**
* Unknown type.
*/
UNKNOWN(null, null),
/**
* Apache Derby.
*/
DERBY("Apache Derby", "org.apache.derby.jdbc.EmbeddedDriver", "org.apache.derby.jdbc.EmbeddedXADataSource",
"SELECT 1 FROM SYSIBM.SYSDUMMY1"),
/**
* H2.
*/
H2("H2", "org.h2.Driver", "org.h2.jdbcx.JdbcDataSource", "SELECT 1"),
/**
* HyperSQL DataBase.
*/
HSQLDB("HSQL Database Engine", "org.hsqldb.jdbc.JDBCDriver", "org.hsqldb.jdbc.pool.JDBCXADataSource",
"SELECT COUNT(*) FROM INFORMATION_SCHEMA.SYSTEM_USERS"),
/**
* SQLite.
*/
SQLITE("SQLite", "org.sqlite.JDBC"),
/**
* MySQL.
*/
MYSQL("MySQL", "com.mysql.cj.jdbc.Driver", "com.mysql.cj.jdbc.MysqlXADataSource", "/* ping */ SELECT 1"),
/**
* Maria DB.
*/
MARIADB("MariaDB", "org.mariadb.jdbc.Driver", "org.mariadb.jdbc.MariaDbDataSource", "SELECT 1"),
/**
* Google App Engine.
* @deprecated since 2.7.0 for removal in 3.0.0 without replacement following the
* removal of AppEngineDriver from version 2.0 of the AppEngine API SDK.
*/
@Deprecated
GAE(null, "com.google.appengine.api.rdbms.AppEngineDriver"),
/**
* Oracle.
*/
ORACLE("Oracle", "oracle.jdbc.OracleDriver", "oracle.jdbc.xa.client.OracleXADataSource",
"SELECT 'Hello' from DUAL"),
DM("DM DBMS", "dm.jdbc.driver.DmDriver", "dm.jdbc.driver.DmdbXADataSource",
"SELECT 'Hello' from DUAL"),
/**
* Postgres.
*/
POSTGRESQL("PostgreSQL", "org.postgresql.Driver", "org.postgresql.xa.PGXADataSource", "SELECT 1"),
/**
* Amazon Redshift.
* @since 2.2.0
*/
REDSHIFT("Redshift", "com.amazon.redshift.jdbc.Driver", null, "SELECT 1"),
/**
* HANA - SAP HANA Database - HDB.
* @since 2.1.0
*/
HANA("HDB", "com.sap.db.jdbc.Driver", "com.sap.db.jdbcext.XADataSourceSAP", "SELECT 1 FROM SYS.DUMMY") {
@Override
protected Collection<String> getUrlPrefixes() {
return Collections.singleton("sap");
}
},
/**
* jTDS. As it can be used for several databases, there isn't a single product name we
* could rely on.
*/
JTDS(null, "net.sourceforge.jtds.jdbc.Driver"),
/**
* SQL Server.
*/
SQLSERVER("Microsoft SQL Server", "com.microsoft.sqlserver.jdbc.SQLServerDriver",
"com.microsoft.sqlserver.jdbc.SQLServerXADataSource", "SELECT 1") {
@Override
protected boolean matchProductName(String productName) {
return super.matchProductName(productName) || "SQL SERVER".equalsIgnoreCase(productName);
}
},
/**
* Firebird.
*/
FIREBIRD("Firebird", "org.firebirdsql.jdbc.FBDriver", "org.firebirdsql.ds.FBXADataSource",
"SELECT 1 FROM RDB$DATABASE") {
@Override
protected Collection<String> getUrlPrefixes() {
return Arrays.asList("firebirdsql", "firebird");
}
@Override
protected boolean matchProductName(String productName) {
return super.matchProductName(productName)
|| productName.toLowerCase(Locale.ENGLISH).startsWith("firebird");
}
},
/**
* DB2 Server.
*/
DB2("DB2", "com.ibm.db2.jcc.DB2Driver", "com.ibm.db2.jcc.DB2XADataSource", "SELECT 1 FROM SYSIBM.SYSDUMMY1") {
@Override
protected boolean matchProductName(String productName) {
return super.matchProductName(productName) || productName.toLowerCase(Locale.ENGLISH).startsWith("db2/");
}
},
/**
* DB2 AS400 Server.
*/
DB2_AS400("DB2 UDB for AS/400", "com.ibm.as400.access.AS400JDBCDriver",
"com.ibm.as400.access.AS400JDBCXADataSource", "SELECT 1 FROM SYSIBM.SYSDUMMY1") {
@Override
public String getId() {
return "db2";
}
@Override
protected Collection<String> getUrlPrefixes() {
return Collections.singleton("as400");
}
@Override
protected boolean matchProductName(String productName) {
return super.matchProductName(productName) || productName.toLowerCase(Locale.ENGLISH).contains("as/400");
}
},
/**
* Teradata.
*/
TERADATA("Teradata", "com.teradata.jdbc.TeraDriver"),
/**
* Informix.
*/
INFORMIX("Informix Dynamic Server", "com.informix.jdbc.IfxDriver", null, "select count(*) from systables") {
@Override
protected Collection<String> getUrlPrefixes() {
return Arrays.asList("informix-sqli", "informix-direct");
}
},
/**
* Apache Phoenix.
* @since 2.5.0
*/
PHOENIX("Apache Phoenix", "org.apache.phoenix.jdbc.PhoenixDriver", null, "SELECT 1 FROM SYSTEM.CATALOG LIMIT 1"),
/**
* Testcontainers.
*/
TESTCONTAINERS(null, "org.testcontainers.jdbc.ContainerDatabaseDriver") {
@Override
protected Collection<String> getUrlPrefixes() {
return Collections.singleton("tc");
}
};
适配类型(DatabaseType not found for product name: [DM DBMS])
继续进行项目启动
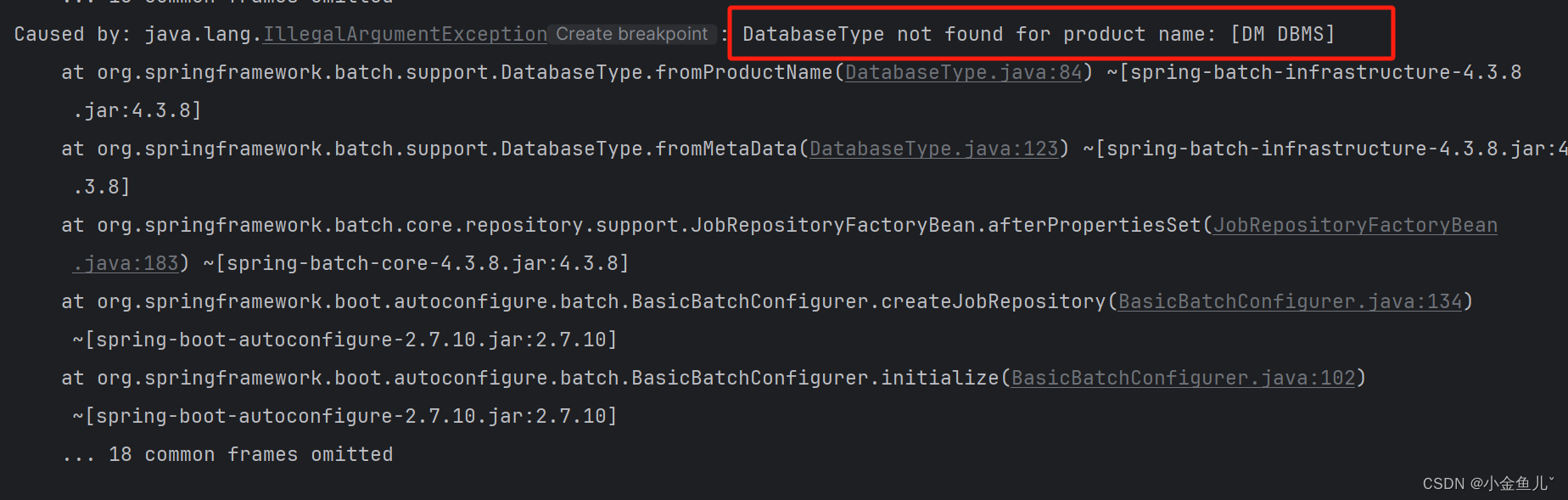
根据报错信息进行debug
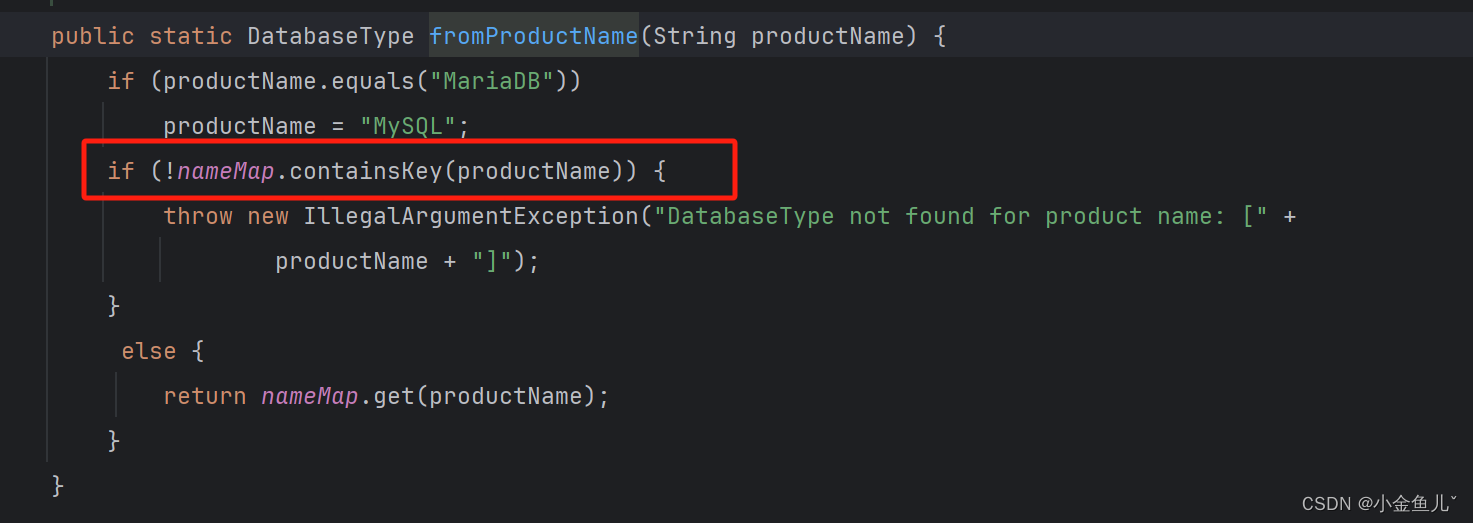
nameMap数据加载规则
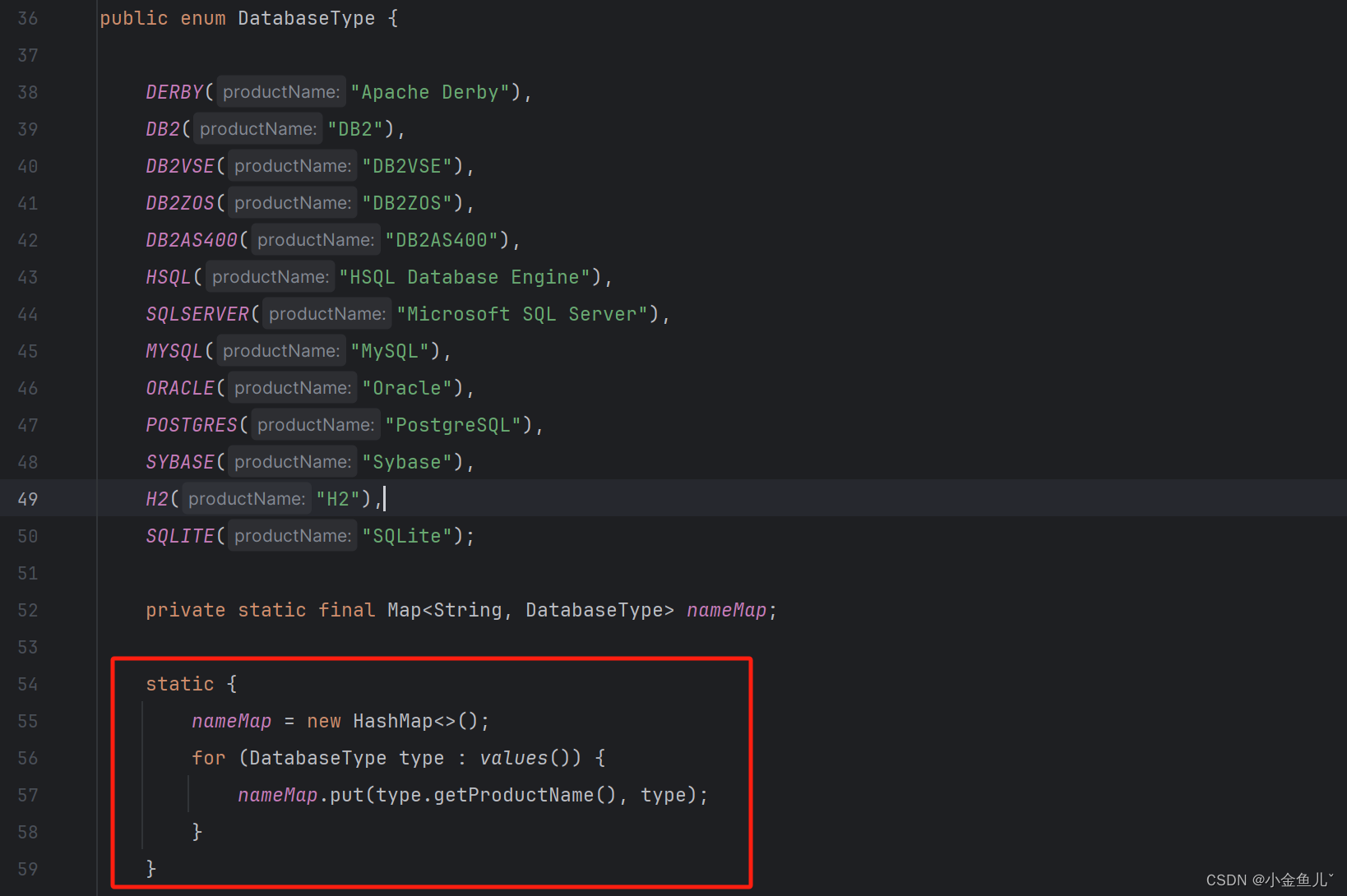
首先我们发现里面并没有DM数据库类型的定义,因此我们要在这里加DM数据库类型的定义,该操作与适配驱动方法一直。
public enum DatabaseType {
DERBY("Apache Derby"),
DB2("DB2"),
DB2VSE("DB2VSE"),
DB2ZOS("DB2ZOS"),
DB2AS400("DB2AS400"),
HSQL("HSQL Database Engine"),
SQLSERVER("Microsoft SQL Server"),
MYSQL("MySQL"),
ORACLE("Oracle"),
POSTGRES("PostgreSQL"),
SYBASE("Sybase"),
H2("H2"),
SQLITE("SQLite"),
DM("DM DBMS");
...
}
DefaultDataFieldMaxValueIncrementerFactory
继续进行项目启动
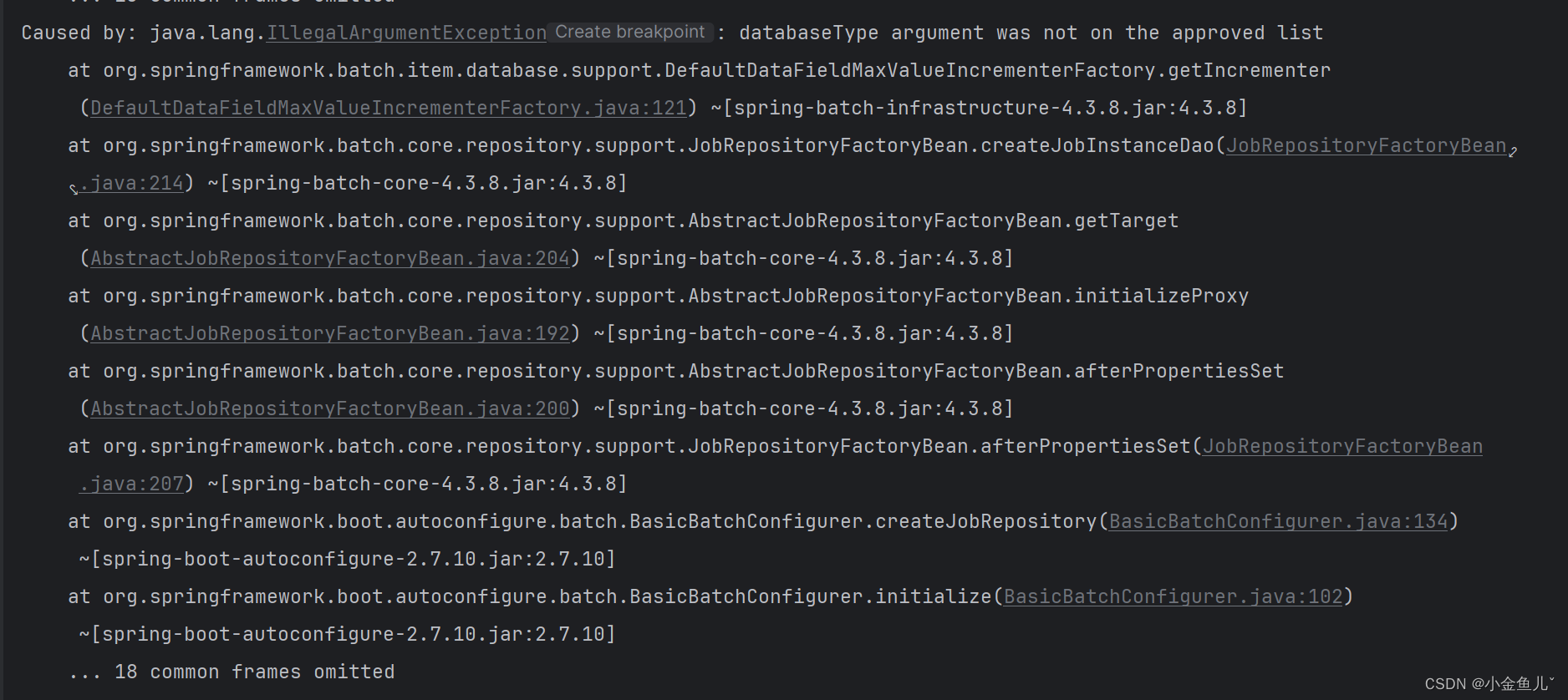
根据报错信息进行debug
public class DefaultDataFieldMaxValueIncrementerFactory implements DataFieldMaxValueIncrementerFactory{
@Override
public DataFieldMaxValueIncrementer getIncrementer(String incrementerType, String incrementerName) {
DatabaseType databaseType = DatabaseType.valueOf(incrementerType.toUpperCase());
if (databaseType == DB2 || databaseType == DB2AS400) {
return new Db2LuwMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == DB2ZOS) {
return new Db2MainframeMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == DERBY) {
return new DerbyMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
else if (databaseType == HSQL) {
return new HsqlMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
else if (databaseType == H2) {
return new H2SequenceMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == MYSQL) {
MySQLMaxValueIncrementer mySQLMaxValueIncrementer = new MySQLMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
mySQLMaxValueIncrementer.setUseNewConnection(true);
return mySQLMaxValueIncrementer;
}
else if (databaseType == ORACLE) {
return new OracleSequenceMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == POSTGRES) {
return new PostgresSequenceMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == SQLITE) {
return new SqliteMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
else if (databaseType == SQLSERVER) {
return new SqlServerMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
else if (databaseType == SYBASE) {
return new SybaseMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
throw new IllegalArgumentException("databaseType argument was not on the approved list");
}
...
}
发现此时并没有关于DM的定义。首先我们先关注该方法返回值类型DataFieldMaxValueIncrementer,次类是用来做什么,我们找一个Mysql的实现看一下他要达到什么样的效果
public class MySQLMaxValueIncrementer extends AbstractColumnMaxValueIncrementer {
/** The SQL string for retrieving the new sequence value. */
private static final String VALUE_SQL = "select last_insert_id()";
/** The next id to serve. */
private long nextId = 0;
/** The max id to serve. */
private long maxId = 0;
/** Whether to use a new connection for the incrementer. */
private boolean useNewConnection = true;
/**
* Default constructor for bean property style usage.
* @see #setDataSource
* @see #setIncrementerName
* @see #setColumnName
*/
public MySQLMaxValueIncrementer() {
}
/**
* Convenience constructor.
* @param dataSource the DataSource to use
* @param incrementerName the name of the sequence table to use
* @param columnName the name of the column in the sequence table to use
*/
public MySQLMaxValueIncrementer(DataSource dataSource, String incrementerName, String columnName) {
super(dataSource, incrementerName, columnName);
}
/**
* Set whether to use a new connection for the incrementer.
* <p>{@code true} is necessary to support transactional storage engines,
* using an isolated separate transaction for the increment operation.
* {@code false} is sufficient if the storage engine of the sequence table
* is non-transactional (like MYISAM), avoiding the effort of acquiring an
* extra {@code Connection} for the increment operation.
* <p>Default is {@code true} since Spring Framework 5.0.
* @since 4.3.6
* @see DataSource#getConnection()
*/
public void setUseNewConnection(boolean useNewConnection) {
this.useNewConnection = useNewConnection;
}
@Override
protected synchronized long getNextKey() throws DataAccessException {
if (this.maxId == this.nextId) {
/*
* If useNewConnection is true, then we obtain a non-managed connection so our modifications
* are handled in a separate transaction. If it is false, then we use the current transaction's
* connection relying on the use of a non-transactional storage engine like MYISAM for the
* incrementer table. We also use straight JDBC code because we need to make sure that the insert
* and select are performed on the same connection (otherwise we can't be sure that last_insert_id()
* returned the correct value).
*/
Connection con = null;
Statement stmt = null;
boolean mustRestoreAutoCommit = false;
try {
if (this.useNewConnection) {
con = getDataSource().getConnection();
if (con.getAutoCommit()) {
mustRestoreAutoCommit = true;
con.setAutoCommit(false);
}
}
else {
con = DataSourceUtils.getConnection(getDataSource());
}
stmt = con.createStatement();
if (!this.useNewConnection) {
DataSourceUtils.applyTransactionTimeout(stmt, getDataSource());
}
// Increment the sequence column...
String columnName = getColumnName();
try {
stmt.executeUpdate("update " + getIncrementerName() + " set " + columnName +
" = last_insert_id(" + columnName + " + " + getCacheSize() + ") limit 1");
}
catch (SQLException ex) {
throw new DataAccessResourceFailureException("Could not increment " + columnName + " for " +
getIncrementerName() + " sequence table", ex);
}
// Retrieve the new max of the sequence column...
ResultSet rs = stmt.executeQuery(VALUE_SQL);
try {
if (!rs.next()) {
throw new DataAccessResourceFailureException("last_insert_id() failed after executing an update");
}
this.maxId = rs.getLong(1);
}
finally {
JdbcUtils.closeResultSet(rs);
}
this.nextId = this.maxId - getCacheSize() + 1;
}
catch (SQLException ex) {
throw new DataAccessResourceFailureException("Could not obtain last_insert_id()", ex);
}
finally {
JdbcUtils.closeStatement(stmt);
if (con != null) {
if (this.useNewConnection) {
try {
con.commit();
if (mustRestoreAutoCommit) {
con.setAutoCommit(true);
}
}
catch (SQLException ignore) {
throw new DataAccessResourceFailureException(
"Unable to commit new sequence value changes for " + getIncrementerName());
}
JdbcUtils.closeConnection(con);
}
else {
DataSourceUtils.releaseConnection(con, getDataSource());
}
}
}
}
else {
this.nextId++;
}
return this.nextId;
}
}
里面只有一个核心方法,针对于SpringBatch通俗来讲该方法主要是用来获取下一次的唯一标记,因此可以仿照mysql的逻辑。
编写DMMaxValueIncrementer
public class DMMaxValueIncrementer extends AbstractColumnMaxValueIncrementer {
/** The next id to serve. */
private long nextId = 0;
/** The max id to serve. */
private long maxId = 0;
/** Whether to use a new connection for the incrementer. */
private boolean useNewConnection = true;
public DMMaxValueIncrementer() {
}
public void setUseNewConnection(boolean useNewConnection) {
this.useNewConnection = useNewConnection;
}
public DMMaxValueIncrementer(DataSource dataSource, String incrementerName, String columnName) {
super(dataSource, incrementerName, columnName);
}
@Override
protected synchronized long getNextKey() {
if (this.maxId == this.nextId) {
/*
* If useNewConnection is true, then we obtain a non-managed connection so our modifications
* are handled in a separate transaction. If it is false, then we use the current transaction's
* connection relying on the use of a non-transactional storage engine like MYISAM for the
* incrementer table. We also use straight JDBC code because we need to make sure that the insert
* and select are performed on the same connection (otherwise we can't be sure that last_insert_id()
* returned the correct value).
*/
Connection con = null;
Statement stmt = null;
boolean mustRestoreAutoCommit = false;
try {
if (this.useNewConnection) {
con = getDataSource().getConnection();
if (con.getAutoCommit()) {
mustRestoreAutoCommit = true;
con.setAutoCommit(false);
}
}
else {
con = DataSourceUtils.getConnection(getDataSource());
}
stmt = con.createStatement();
if (!this.useNewConnection) {
DataSourceUtils.applyTransactionTimeout(stmt, getDataSource());
}
// Increment the sequence column...
String columnName = getColumnName();
String VALUE_SQL = "select " + columnName + " from " + getIncrementerName() + " order by " + columnName + " desc limit 1";
// Retrieve the new max of the sequence column...
ResultSet rs = stmt.executeQuery(VALUE_SQL);
try {
if (!rs.next()) {
throw new DataAccessResourceFailureException("failed after executing an query");
}
this.maxId = rs.getLong(1) + getCacheSize();
}
finally {
JdbcUtils.closeResultSet(rs);
}
try {
stmt.executeUpdate("update " + getIncrementerName() + " set " + columnName +
" = " + this.maxId);
}
catch (SQLException ex) {
throw new DataAccessResourceFailureException("Could not increment " + columnName + " for " +
getIncrementerName() + " sequence table", ex);
}
this.nextId = this.maxId - getCacheSize() + 1;
}
catch (SQLException ex) {
throw new DataAccessResourceFailureException("Could not update", ex);
}
finally {
JdbcUtils.closeStatement(stmt);
if (con != null) {
if (this.useNewConnection) {
try {
con.commit();
if (mustRestoreAutoCommit) {
con.setAutoCommit(true);
}
}
catch (SQLException ignore) {
throw new DataAccessResourceFailureException(
"Unable to commit new sequence value changes for " + getIncrementerName());
}
JdbcUtils.closeConnection(con);
}
else {
DataSourceUtils.releaseConnection(con, getDataSource());
}
}
}
}
else {
this.nextId++;
}
return this.nextId;
}
}
在DefaultDataFieldMaxValueIncrementerFactory类中增加DM类型定义并创建DMMaxValueIncrementer,改操作方法于适配驱动一直
public class DefaultDataFieldMaxValueIncrementerFactory implements DataFieldMaxValueIncrementerFactory{
@Override
public DataFieldMaxValueIncrementer getIncrementer(String incrementerType, String incrementerName) {
DatabaseType databaseType = DatabaseType.valueOf(incrementerType.toUpperCase());
if (databaseType == DB2 || databaseType == DB2AS400) {
return new Db2LuwMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == DB2ZOS) {
return new Db2MainframeMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == DERBY) {
return new DerbyMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
else if (databaseType == HSQL) {
return new HsqlMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
else if (databaseType == H2) {
return new H2SequenceMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == MYSQL) {
MySQLMaxValueIncrementer mySQLMaxValueIncrementer = new MySQLMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
mySQLMaxValueIncrementer.setUseNewConnection(true);
return mySQLMaxValueIncrementer;
}
else if (databaseType == ORACLE) {
return new OracleSequenceMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == POSTGRES) {
return new PostgresSequenceMaxValueIncrementer(dataSource, incrementerName);
}
else if (databaseType == SQLITE) {
return new SqliteMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
else if (databaseType == SQLSERVER) {
return new SqlServerMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
else if (databaseType == SYBASE) {
return new SybaseMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
}
else if (databaseType == DM){
DMMaxValueIncrementer dmMaxValueIncrementer = new DMMaxValueIncrementer(dataSource, incrementerName, incrementerColumnName);
dmMaxValueIncrementer.setUseNewConnection(true);
return dmMaxValueIncrementer;
}
throw new IllegalArgumentException("databaseType argument was not on the approved list");
}
...
}
三、schem-dm.sql
我们知道在配置文件中指定spring.batch.jdbc.initialize-schema=always时,项目启动时会初始化springbatch运行过程中所需的表结构,以mysql为例,项目启动会下载schem-mysql.sql文件执行表结构初始化操作,由于我们使用的是DM(达梦数据库)因此我们要创建一个schem-dm.sql文件进行数据表的初始化。并将该文件放在org/springframework/batch/core目录下。
-- BATCH_JOB_INSTANCE definition
CREATE TABLE BATCH_JOB_INSTANCE
(
JOB_INSTANCE_ID BIGINT NOT NULL,
VERSION BIGINT NULL,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
CONSTRAINT PK_BATCH_JOB_INSTANCE_JID PRIMARY KEY (JOB_INSTANCE_ID)
);
CREATE UNIQUE INDEX UIDX_BATCH_JOB_INSTANCE_JID ON BATCH_JOB_INSTANCE (JOB_INSTANCE_ID);
CREATE UNIQUE INDEX UIDX_BATCH_JOB_INSTANCE_JN_JK ON BATCH_JOB_INSTANCE (JOB_NAME, JOB_KEY);
-- BATCH_JOB_EXECUTION definition
CREATE TABLE BATCH_JOB_EXECUTION
(
JOB_EXECUTION_ID BIGINT NOT NULL,
VERSION BIGINT NULL,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP NULL,
END_TIME TIMESTAMP NULL,
STATUS VARCHAR(10) NULL,
EXIT_CODE VARCHAR(2500) NULL,
EXIT_MESSAGE VARCHAR(2500) NULL,
LAST_UPDATED TIMESTAMP NULL,
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
CONSTRAINT PK_BATCH_JOB_EXECUTION_JID PRIMARY KEY (JOB_EXECUTION_ID)
);
CREATE UNIQUE INDEX UIDX_BATCH_JOB_EXECUTION_JID ON BATCH_JOB_EXECUTION (JOB_EXECUTION_ID);
CREATE INDEX IDX_BATCH_JOB_EXECUTION_JID ON BATCH_JOB_EXECUTION (JOB_INSTANCE_ID);
-- BATCH_JOB_EXECUTION foreign keys
ALTER TABLE BATCH_JOB_EXECUTION
ADD CONSTRAINT JOB_INST_EXEC_FK FOREIGN KEY (JOB_INSTANCE_ID) REFERENCES BATCH_JOB_INSTANCE (JOB_INSTANCE_ID);
-- BATCH_STEP_EXECUTION definition
CREATE TABLE BATCH_STEP_EXECUTION
(
STEP_EXECUTION_ID BIGINT NOT NULL,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME TIMESTAMP NOT NULL,
END_TIME TIMESTAMP NULL,
STATUS VARCHAR(10) NULL,
COMMIT_COUNT BIGINT NULL,
READ_COUNT BIGINT NULL,
FILTER_COUNT BIGINT NULL,
WRITE_COUNT BIGINT NULL,
READ_SKIP_COUNT BIGINT NULL,
WRITE_SKIP_COUNT BIGINT NULL,
PROCESS_SKIP_COUNT BIGINT NULL,
ROLLBACK_COUNT BIGINT NULL,
EXIT_CODE VARCHAR(2500) NULL,
EXIT_MESSAGE VARCHAR(2500) NULL,
LAST_UPDATED TIMESTAMP NULL,
CONSTRAINT PK_BATCH_STEP_EXECUTION_SID PRIMARY KEY (STEP_EXECUTION_ID)
);
CREATE UNIQUE INDEX UIDX_BATCH_STEP_EXECUTION_SID ON BATCH_STEP_EXECUTION (STEP_EXECUTION_ID);
CREATE INDEX IDX_BATCH_STEP_EXECUTION_JID ON BATCH_STEP_EXECUTION (JOB_EXECUTION_ID);
-- BATCH_STEP_EXECUTION foreign keys
ALTER TABLE BATCH_STEP_EXECUTION
ADD CONSTRAINT JOB_EXEC_STEP_FK FOREIGN KEY (JOB_EXECUTION_ID) REFERENCES BATCH_JOB_EXECUTION (JOB_EXECUTION_ID);
-- BATCH_JOB_EXECUTION_CONTEXT definition
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT
(
JOB_EXECUTION_ID BIGINT NOT NULL,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT NULL,
CONSTRAINT PK_BATCH_JOB_EXECUTION_CONTEXT_JID PRIMARY KEY (JOB_EXECUTION_ID)
);
CREATE UNIQUE INDEX UIDX_BATCH_JOB_EXECUTION_CONTEXT_JID ON BATCH_JOB_EXECUTION_CONTEXT (JOB_EXECUTION_ID);
CREATE INDEX IDX_BATCH_JOB_EXECUTION_CONTEXT_JID ON BATCH_JOB_EXECUTION_CONTEXT (JOB_EXECUTION_ID);
-- BATCH_JOB_EXECUTION_CONTEXT foreign keys
ALTER TABLE BATCH_JOB_EXECUTION_CONTEXT
ADD CONSTRAINT JOB_EXEC_CTX_FK FOREIGN KEY (JOB_EXECUTION_ID) REFERENCES BATCH_JOB_EXECUTION (JOB_EXECUTION_ID);
-- BATCH_JOB_EXECUTION_PARAMS definition
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS
(
JOB_EXECUTION_ID BIGINT NOT NULL,
TYPE_CD VARCHAR(6) NOT NULL,
KEY_NAME VARCHAR(100) NOT NULL,
STRING_VAL VARCHAR(250) NULL,
DATE_VAL TIMESTAMP NULL,
LONG_VAL BIGINT NULL,
DOUBLE_VAL NUMBER(22,0) NULL,
IDENTIFYING CHAR(1) NOT NULL
);
CREATE INDEX IDX_BATCH_JOB_EXECUTION_PARAMS_JID ON BATCH_JOB_EXECUTION_PARAMS (JOB_EXECUTION_ID);
-- BATCH_JOB_EXECUTION_PARAMS foreign keys
ALTER TABLE BATCH_JOB_EXECUTION_PARAMS
ADD CONSTRAINT JOB_EXEC_PARAMS_FK FOREIGN KEY (JOB_EXECUTION_ID) REFERENCES BATCH_JOB_EXECUTION (JOB_EXECUTION_ID);
-- BATCH_JOB_EXECUTION_SEQ definition
CREATE TABLE BATCH_JOB_EXECUTION_SEQ
(
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL
);
CREATE UNIQUE INDEX UIDX_BATCH_JOB_EXECUTION_SEQ_UKEY ON BATCH_JOB_EXECUTION_SEQ (UNIQUE_KEY);
-- BATCH_JOB_SEQ definition
CREATE TABLE BATCH_JOB_SEQ
(
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL
);
CREATE UNIQUE INDEX UIDX_BATCH_JOB_SEQ_UKEY ON BATCH_JOB_SEQ (UNIQUE_KEY);
-- BATCH_STEP_EXECUTION_CONTEXT definition
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT
(
STEP_EXECUTION_ID BIGINT NOT NULL,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT NULL,
CONSTRAINT PK_BATCH_STEP_EXECUTION_CONTEXT_SID PRIMARY KEY (STEP_EXECUTION_ID)
);
CREATE UNIQUE INDEX UIDX_BATCH_STEP_EXECUTION_CONTEXT_SID ON BATCH_STEP_EXECUTION_CONTEXT (STEP_EXECUTION_ID);
CREATE INDEX IDX_BATCH_STEP_EXECUTION_CONTEXT_SID ON BATCH_STEP_EXECUTION_CONTEXT (STEP_EXECUTION_ID);
-- BATCH_STEP_EXECUTION_CONTEXT foreign keys
ALTER TABLE BATCH_STEP_EXECUTION_CONTEXT
ADD CONSTRAINT STEP_EXEC_CTX_FK FOREIGN KEY (STEP_EXECUTION_ID) REFERENCES BATCH_STEP_EXECUTION (STEP_EXECUTION_ID);
-- BATCH_STEP_EXECUTION_SEQ definition
CREATE TABLE BATCH_STEP_EXECUTION_SEQ
(
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL
);
CREATE UNIQUE INDEX UIDX_BATCH_STEP_EXECUTION_SEQ_UKEY ON BATCH_STEP_EXECUTION_SEQ (UNIQUE_KEY);
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);
四、DM数据模式问题
数据库连接配置
spring:
batch:
job:
enabled: false
jdbc:
initialize-schema: always
datasource:
# username: root
# password: root
# url: jdbc:mysql://192.168.72.100:13306/cmp_migration_db?serverTimezone=GMT%2B8
# driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:dm://192.168.72.100:30236/?cmp_migration_db&zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=utf-8
username: SYSDBA
password: SYSDBA001
driver-class-name: dm.jdbc.driver.DmDriver
首先我们可以看到我使用的SYSDBA用户操作cmp_migration_db库,我们启动项目会发现数据表并没有创建到cmp_migration_db库中,而是创建到了SYSDBA数据库中。对于此问题DM官方的解释为达梦默认会根据用户名去找对应的数据库,如果想要操作指定数据库需要在url上指定schem=数据库名称,如果达梦数据库配置的大小写敏感需要再数据库名称上加上引号schem="数据库名称”。
修改后的配置文件
spring:
batch:
job:
enabled: false
jdbc:
initialize-schema: always
datasource:
# username: root
# password: root
# url: jdbc:mysql://192.168.72.100:13306/cmp_migration_db?serverTimezone=GMT%2B8
# driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:dm://192.168.72.100:30236/?schema="cmp_migration_db"&zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=utf-8
username: SYSDBA
password: SYSDBA001
driver-class-name: dm.jdbc.driver.DmDriver

















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









