






今天获取了下邮件中的附件。成功了…
首先,邮件不一定带附件,第二,绝大多数附件都是二进制。
先说附件吧:附件的格式如图:
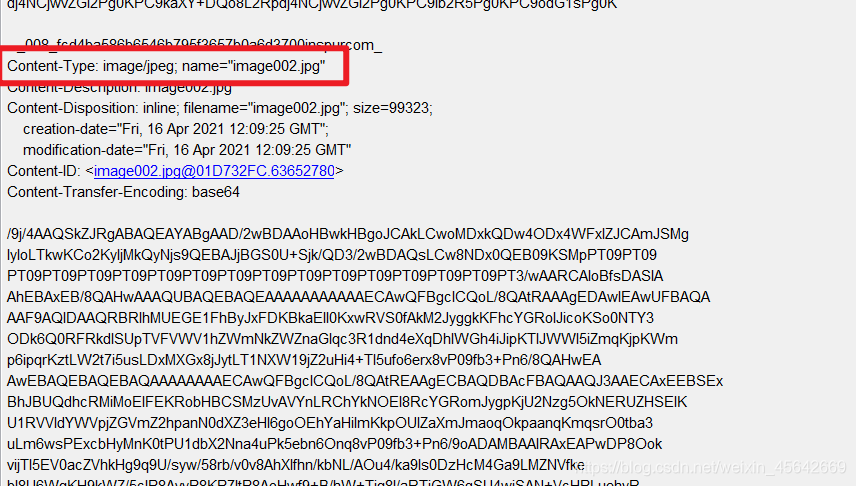
基本上所有的文件文本都是name:“XXXXXX”,所以可以直接截取NAME字段。
如果存在NAME字段,那么就是有附件。
然后,下一步,对正文储存成为二进制文件。
格式的话,选择wb。就是二进制写入。
然后把二进制代码存进去。
即可获取附件。
我自己手撕的脚本。
def get_mail_files_and_photo(msg, file_location='1'):
for part in msg.walk():
name = part.get_param('name')
file_data = b''
if name:
if name.find('=?=') != -1 and name.find('=?UTF-8?') != -1:
try:
data = name.split('?')[3]
except:
data = 'error_name'
data = bytes(data, encoding='UTF-8', errors='replace')
data = base64.b64decode(data)
data = data.decode(encoding='UTF-8', errors='replace')
if name.find('=?=') != -1 and name.find('=?GB') != -1:
try:
data = name.split('?')[3]
except:
data = 'error_name'
data = bytes(data, encoding='GBK', errors='replace')
data = base64.b64decode(data)
data = data.decode(encoding='GBK', errors='replace')
else:
data = bytes(name.replace('=', '').replace('?', ''), encoding='UTF-8', errors='replace')
data = base64.b64decode(data)
data = data.decode(encoding='UTF-8', errors='replace')
try:
file_data = part.get_payload(decode=True)
file = open('F:\\mail_log\\mail_file\\{}-{}'
.format(file_location, data[-30:-1]), 'wb')
file.write(file_data)
file.close()
except:
print('没有可获取文件')
但是:出现这么几个问题:第一个是文件名不一定能够获取成功。
能获取带乱码名的文件名,不过概率很低。
 看看我获取的文件,其中有一些乱码了……
看看我获取的文件,其中有一些乱码了……
主要原因,是因为文件名有三种码:
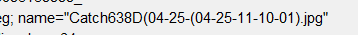
无格式纯英文转码
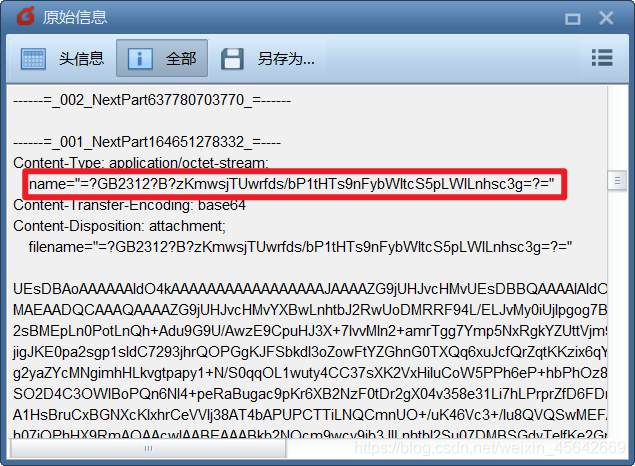
第二种:GB2312转Base64.
第三种:UTF-8转BASE64.
需要写三个判断。
还有就是:PTTHON不支持超长名。
比如:
F = open(‘11111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111.txt’)
对这个文件只能后截取而不是获取前几个(因为后缀名在后面啊)不然程序会报错退出。
还有:不支持带特殊字符(问号不支持),要去除文件名中的特殊字符。
经过这几次的格式转换,就能获取文件名称了。
千万别忘了再写一个报错模块——如果实在获取不到,那么就跳过这个文件。
然后,下一个就是:通过二进制获取文件。
这个有概率失败,没有确定是什么原因。
所以还要写异常抛出模块。
整个程序逻辑是:
import email
import poplib
import pyperclip
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
from file_fun import *
import time
import re
from html import unescape
import configobj
import base64
import calendar
# 这是passwd文件的句柄,密码等都存在这个文件里面,用的时候自己配
config = configobj.ConfigObj('F:\\d1\\passwd.ini')
# 文件信息
mail_return_list = ''
def get_mail_return():
return mail_return_list
def change_mail_return(data=''):
global mail_return_list
mail_return_list = str(data)
def add_mail_return(data=''):
global mail_return_list
if data != '':
mail_return_list = str(data)+'\n'+str(mail_return_list)
else:
mail_return_list = str(data)
# 这个程序的作用是为了将html转化成txt文本,转化能力还不错……
def html_to_plain_text(html):
text = re.sub('<head.*?>.*?</head>', ' ', html, flags=re.M | re.S | re.I)
text = re.sub(r'<a\s.*?>', ' HYPERLINK ', text, flags=re.M | re.S | re.I)
text = re.sub('<.*?>', ' ', text, flags=re.M | re.S)
text = re.sub(r'(\s*\n)+', '\n', text, flags=re.M | re.S)
# text = re.sub(r'\{.*?\}', 'vue函数', '', flags=re.M | re.S)
return unescape(text)
# 获取前三行的宏,其中关于HEAD的不太清楚,但是不重要……
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
try:
value = value.decode(charset, errors="replace")
except Exception as e:
value = "无法获取标题,过"
print(str(e)+'17')
return value
def get_head(msg):
value_char = ''
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header == 'Subject':
value = decode_str(value)
else:
hdr, addr = parseaddr(value)
name = decode_str(hdr)
value = u'%s <%s>' % (name, addr)
value_char = str(value_char) + str(value) + '\n'
if len(value_char) <= 5:
value_char == '邮件无标题'
return value_char + '\n'
def add_time(mail):
try:
mail = mail.decode('UTF-8', errors='replace')
get_date = re.search(r'Date:\s([A-Za-z]{1,3}),\s([0-9]{1,2})\s([A-Za-z]{1,3})\s([0-9]{1,4})\s([0-9]{1,2}):',
mail)
except Exception as e:
print(e)
return '{}-{}-{} {}时'.format(get_date.group(4), str(list(calendar.month_abbr).index(get_date.group(3))).zfill(2),
str(get_date.group(2)).zfill(2), get_date.group(5))
def get_file(msg):
data_char = ''
for part in msg.walk():
part_charset = part.get_content_charset()
part_type = part.get_content_type()
if part_type == "text/plain" or part_type == 'text/html':
data = part.get_payload(decode=True)
try:
data = data.decode(part_charset, errors="replace")
except Exception as e:
print(str(e)+'16')
data = data.decode('gb2312', errors="replace")
data = html_to_plain_text(data)
data = data.replace('?', '')
data_char = data_char + '\n' + data
else:
if not part.is_multipart(): # 这里要判断是否是multipart,是的话,里面的数据是无用的,至于为什么可以了解mime相关知识。
name = part.get_param("name") # 如果是附件,这里就会取出附件的文件名
if name:
if name.find('=?=') != -1:
data = name.split('?')[3]
data = bytes(data, encoding='utf-8')
data = base64.b64decode(data)
data = data.decode(encoding='gbk', errors='replace')
data_char = data_char + '\n' + str(data) + '\n'
return data_char
def get_mail_files_and_photo(msg, file_location='1'):
for part in msg.walk():
name = part.get_param('name')
file_data = b''
if name:
try:
if name.find('=?=') != -1 and name.find('=?UTF-8?') != -1:
data = name.split('?')[3]
data = bytes(data, encoding='UTF-8', errors='replace')
data = base64.b64decode(data)
data = data.decode(encoding='UTF-8', errors='replace')
file_data = part.get_payload(decode=True)
elif name.find('=?=') != -1 and name.find('=?GB') != -1:
data = name.split('?')[3]
data = bytes(data, encoding='GBK', errors='replace')
data = base64.b64decode(data)
data = data.decode(encoding='GBK', errors='replace')
file_data = part.get_payload(decode=True)
else:
data = name.replace('=', '').replace('?', '')
file_data = part.get_payload(decode=True)
file = open('F:\\mail_log\\mail_file\\{}-{}'.format(file_location, data[-30:]), 'wb')
file.write(file_data)
file.close()
except Exception as e:
print(e)
# 这是生成邮件文本的主程序
def mail_input(start_row=90, end_row=100):
global mail_return_list
print('正在获取邮件正文')
add_mail_return('正在获取邮件正文')
password = config['passwd']['password']
user = config['passwd']['user']
pop3server = config['passwd']['pop3server']
root = config['root']['mail_root']
p = poplib.POP3_SSL(pop3server)
p.user(user)
p.pass_(password)
print('邮件处理起点'+str(start_row))
print('处理到:'+str(end_row+1))
for i in range(start_row, end_row + 1):
print('获取邮件{}中'.format(i))
add_mail_return('获取邮件{}中 '.format(i)+time.strftime("%d %H:%M:%S", time.localtime()))
mail = p.retr(i)[1]
mail = b'\n'.join(mail)
msg = email.message_from_bytes(mail)
file = open(root + str(i) + ".txt", 'w+', encoding="gb2312", errors="replace")
file.write(get_head(msg))
file.write(add_time(mail))
file.write(get_file(msg) + '\n')
get_mail_files_and_photo(msg, str(i))
file.close()
mail_flash(i)
p.close()
print('邮件全部获取,关闭连接')
add_mail_return('邮件全部获取,关闭连接')
time.sleep(1)
mail_flash(end_row)
def get_mail_len():
try:
mail = mail_read()
except Exception as e:
print(str(e)+'15')
password = config['passwd']['password']
user = config['passwd']['user']
pop3server = config['passwd']['pop3server']
p = poplib.POP3_SSL(pop3server)
p.user(user)
p.pass_(password)
mail = len(p.list()[1]) - 100
mail_flash(mail)
return mail
# 获取邮件到最新,并刷新日志到log
def mail_new():
password = config['passwd']['password']
user = config['passwd']['user']
pop3server = config['passwd']['pop3server']
p = poplib.POP3_SSL(pop3server)
p.user(user)
p.pass_(password)
start_row = int(get_mail_len()) + 1
end_row = len(p.list()[1])
# 当有人删除邮件以后,会发现开始行大于当前行,那么就获取现在最大封数-200,获取最近200行
if start_row > end_row + 50:
add_key = config['mail']['when_delete_then_add']
add_mail_return('发现邮件删除,需要获取最新{}封'.format(add_key))
start_row = len(p.list()[1]) - int(add_key)
end_row = len(p.list()[1])
change_error_count(0)
mail_input(start_row, end_row)
p.close()
return int(get_mail_len()) + 1














 2052
2052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









