






- 注意力机制:
- 高分辨率图像聚焦某一区域, 同时降低感知周围的低分辨率图像. 聚焦点会随着时间推移而进行调整.
- 在处理数据时会更关注某些因素
- 注意力是网络架构的一个组成部分, 负责管理和量化互相依赖的关系:
- General Atteion: 在输入和输出元素之间
- Self-Attention: 在输入元素内
- 给重要和相关的元素分配更高的权重。
- 注意力一开始是被介绍为一种解决seq2seq模型主要问题的解决方案
- 标准的seq2seq模型通常不能准确地处理长的输入序列, 因为只有encoder RNN最后的hidden state被用作decoder的语境向量(Context Vectors).
- 注意力机制在解码过程中, 它保留并利用了输入序列的所有hidden state.
- 对于每个decoder生成的输出, 注意力机制都可以访问整个输入序列, 并选择性地挑选某些元素来产生输出。
- 主要有两种不同类型的注意力:两种类型的注意力的基本原理是相同的, 但它们在结构和计算上存在差别.
- bahdanau attention:加性注意力,通过对齐decoder和相关的输入序列来实现提升:
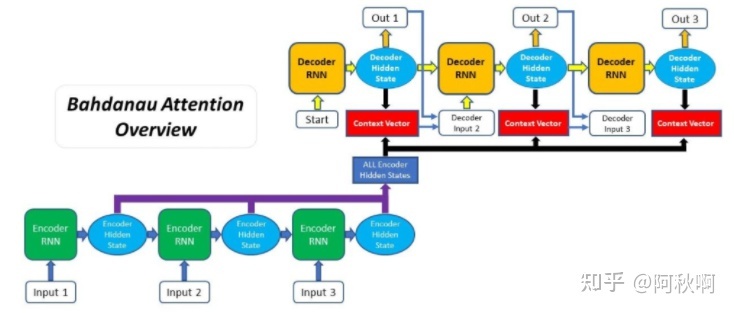
- 步骤:
- 生成encoder的hidden state,:
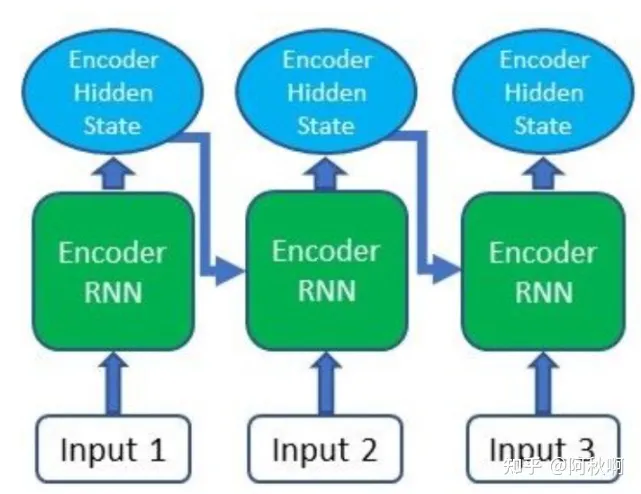
- encoder产生输入序列中每个元素的hidden state;
- 使用一个RNN(或LSTM/GRU)来编码输入序列. 在通过encoder RNN传递输入序列之后, 每个传入的输入都会产生一个hidden state或输出.
- 除了只在最终时步使用hidden state, 也会把encoder产生的所有hidden states带到下一步.
- 如图:
- 计算前一步decoder的hidden state和每个encoder的hidden state的对齐得分:
- 要注意的是, encoder最后的hidden state可以被用作decoder的第一个hidden state);
- 在获得所有encoder输出之后,可以开始使用decoder生成输出,在decoder的每时步都必须计算,对应decoder输入和hidden state的每个encoder输出的对齐分,
对齐得分是注意力机制的本质,因为其量化了,但产生下个输出时,decoder对每个encoder输出“注意”的量
使用decoder在前一步产生的hidden state和encoder的输出来计算bahdanau attention对齐分。
- 应用softmax函数到对齐得分上:
- 每个encoder的hidden state的对齐得分会被组合为一个向量, 然后softmax化;
- 由于softmax函数范围在0到1,如果某个输入元素靠近1, 则它在decoder输出的影响会被放大; 同理, 如果接近0, 则会基本被无视.
- 计算语境向量, 语境向量有encoder的hidden state和它们代表的对齐得分相乘来获得;
- 解码输出, 语境向量与前一步的decoder输出相连接, 并和前一步decoder的hidden state一起被输入到当前时步的decoder RNN来长生新的输出(看上图可能更好理解一点);
- 每时步的步骤2-5不断重复, 直到产生一个标记(token)或输出超过指定的最大长度.
- 生成encoder的hidden state,:
- 流程图:
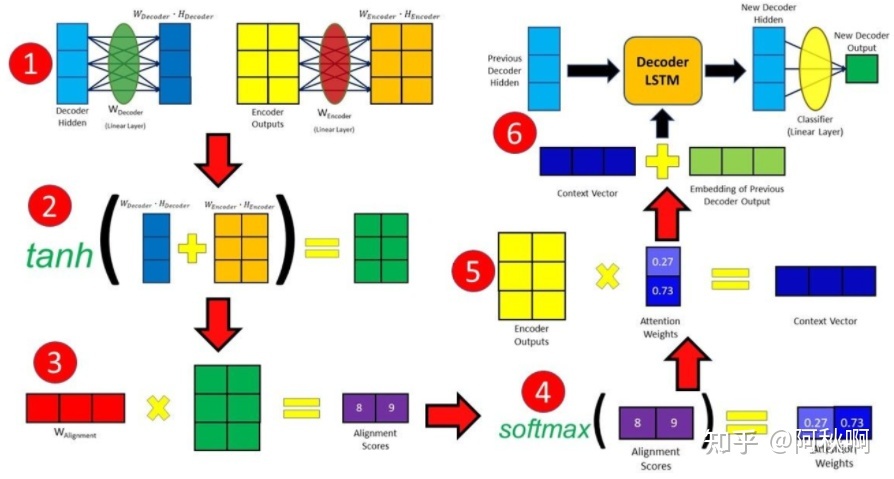
- 图中的步骤:
- decoder hidden经过一层全连接得到一个输出dh,encoder output经过一层全连接得到一个输出eo
- 将dh和eo进行加性组合并通过tanh激活,得到一个输出tan_dh_eo
- 使用对齐权重和tan_dh_eo相乘得到对齐得分
- 将对齐得分再经过softmax 得到as
- 将 encoder outputs与as相乘得到cv(content vector)
- 使用cv和embedding
- 图中的步骤:
- 步骤:
- luong attention:
-
经常被称为点乘(或者乘法)注意力. 和加性注意力相比, 两者最大的区别在于:
-
计算对齐得分的方式不同
-
注意力机制在decoder中被引入的位置不同
-
- 在Luong Attention中, 有三种不同的对齐得分函数: dot, general和concat:
- Dot - 要阐释对齐得分, 只需要将encoder的hidden states乘以decoder的hidden state
- General - 和dot函数相似, 但需要另外乘以一个权重矩阵:
- Concat - 有点像Bahdanau Attention中计算对齐分的方式, 不过把encoder和decoder的hidden state相加. 但是这样的方式会导致encoder和decoder的hidden state没有它们自己的权重矩阵(而转为共享权重), 这一点与Bahdanau Attention不同
- 步骤:
- 产生encoder的hidden state - encoder产生输入序列中每个元素的hidden state;
- Decoder RNN :
- 通过decoder RNN, 前一步的decoder hidden state和decoder输出被传递来生成新的hidden state;
- 与加性attention对比:在解码过程的第一步使用RNN(而非最后一步). RNN使用前一步产生的hidden state和前一步最终输出的词嵌入(word embedding)来产生一个新的hidden state.
- 计算对齐得分 - 使用新的decoder hidden state和encoder hidden state来计算对齐分;
- Softmax对齐分 - 每个encoder hidden state的对齐分被组合成一个向量, 然后softmax;
- 计算语境向量 - Encoder的hidden state和它们对应的对齐分相乘, 得到语境向量;
- 产生最终输出 - 语境向量与步骤2处生成的decoder hidden state相连接, 再通过一个全连接层来产生新的输出;
- 对于每时步的decoder, 重复步骤2到6直到产生一个停止标记或输出长度超出预设最大长度.
-
- bahdanau attention:加性注意力,通过对齐decoder和相关的输入序列来实现提升:
- 注意力的代价:
- 对于每个输入和输出的字组合, 都需要计算一个注意力值. 如果进行字符级计算, 并处理数百个标记组成的序列, 那么注意力机制的代价就可能比较高了.
- 一种替代解决方案, 可以使用强化学习来预测一个要集中注意的大概位置. 这听起来才更像是人类的注意力, 视觉注意的循环模型就是这么做的。
注意力机制--学习笔记



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









