






从零复现PyTorch版(与行人车辆检测实战)(3)
Yolov4网络结构和代码构建(2)
1. YOLO HEAD头部
Decode和Encode
Decode和Encode说的其实是在做目标检测时的矩形框,要描述矩形框就得知道它的中心点坐标和宽高即可记为:
(bx,by,bw,bh),我们再做模型训练和推断时不会直接用模型输出bx,by,bw,bh,为了使得模型训练时更容易收敛,做了一次模型的输出其实是Encode后的,记为(tx,ty,tw,th)
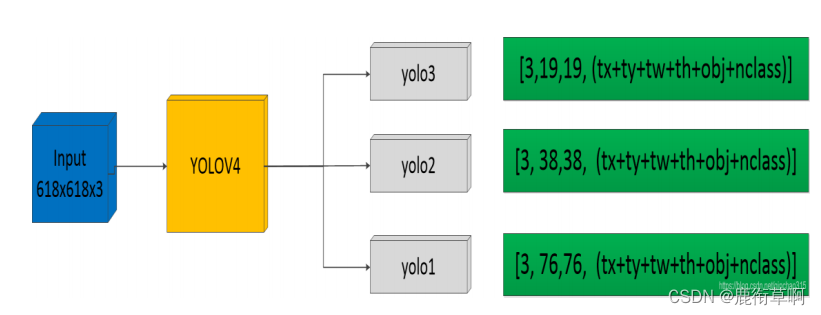
第一维度:anchors的数量(每个特征图都有3种尺度的框,3个特征图共9种尺度框)
第二维度:特征图的高
第三维度:特征图的宽
第四维度:由bx,by,bw,bh,obj,nclass在推断过程中,我们要得到真实的框的坐标,就要将tx,ty,tw,th经过Decode后得到bx,by,bw,bh,再说NMS等后处理操作。
训练过程中,我们要对比模型输出的tx,ty,tw,th和真实标注框bx,by,bw,bh之间的损失,就需要先将真实标注框encode后再跟模型输出计算,这个在训练流程里详细说,也就是我们代码里常看到的build_target流程
2. YOLO HEAD的总结
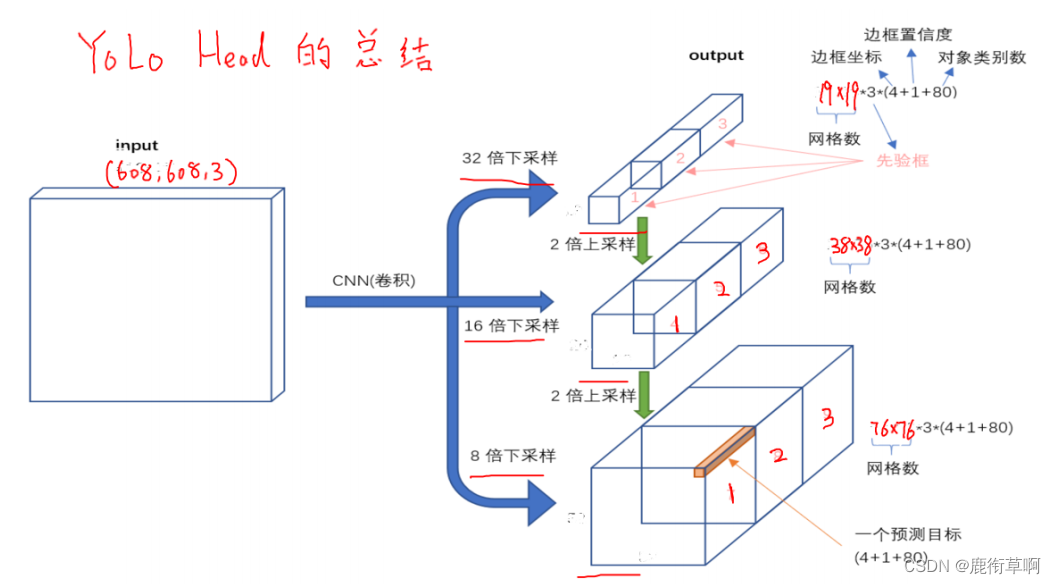
- 其中4表示tx, ty, tw, th即矩形框的位置信息,当然这个是编码后的,最终需要解码出绝对位置信息才可以用,后面YOLOV4中再说这事儿。
- obj表示物体的自信度,长度为1,如果当前对应特征图这个点位置存在一个物体,则值为1
- class表示物体的类别,使用one-hot编码,例如当前类别值为3,则具体表示法为100
- Y1直接由RES4后面经过5个DBL+DBL+Conv后得到,RES4后的尺寸是经过5次下采样,即从input缩小到了32倍得到 的特征图
- Y2分别由第二个RES8即4次下采样特征图+Y1经过上采样后再进行拼接得到的,最后再经过5个DBL+DBL+Conv得到 最终输出尺寸为26x26, 这么做的好处就是将小特征图的语义信息融合到了中等特征图中,使该特征图也具备了一些Y1的 语义信息。
- Y3分别由第一个RES8即3次下采样特征图+Y2经过上采样后再进行拼接得到,最后也同样经过5个DBL+DBL+Conv得 到最终输出尺寸为52x52,那么Y3同时融合了自己的空间和表征信息,以及上面2个特征图的语义信息,这样子的特征融合的方式,也叫做FPN,即特征金字塔融合策略,可以使模型输出最终提高精度。
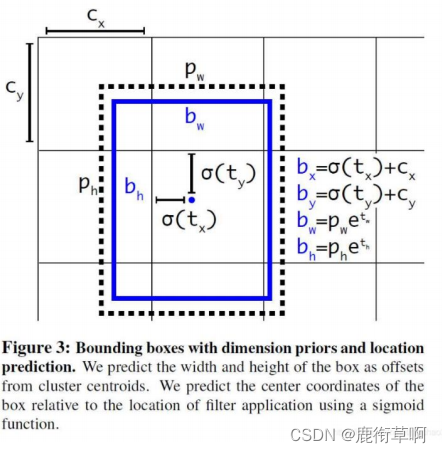
3. Decode过程如下(Encode就是根据公式反向求解即可)
bx=sigmod(tx) + cx
by=sigmod(ty) + cy
bw = pwexp(tw)
bh = phexp(th)
其中pw和ph是该特征图的先验框(即anchors)的尺寸,因此可以理解为模型推断出的tw和th其实是一个相对于先验框的W,H的变化量,而tx,ty则可以理解为相对于当前网格(注意不是整张图,网格单位为1)的坐标位置,那么cx,cy自然就是当前网格的一个序号了,例如对于19x19尺寸特征图对应到原图19*19网格,例如cx=4,cy=0就表示当前网格为第0行第4列的
网格
4. 先验框anchors
就是我们常说的anchors,先验指的就是图片预先设定好的框,然后再以这些框来做训练和推断的基础,上面已经说过一张608的RGB图片经过了YOLO的整体网络后输出了3个不同尺寸的特征图,分别1919,3838,7676。那么就可以认为将原
尺寸图画成了1919,3838,7676的网格,每个网格都有3个不同尺寸大小的先验框负责对目标进行检测,这个尺寸是我们人为定好的,比如原论文的先验框:
anchors = [[(12, 16), (19, 36), (40, 28)], [(36, 75), (76, 55), (72, 146)], [(142, 110), (192, 243), (459, 401)]]
数值对应图像像素值。
我们再做训练和推断时,会把anchors转成网格为单位的数, 例如[(12, 16), (19, 36), (40, 28)]对应于76*76特征图,那么每个网格的像素大小为 608/76=8, 转换成网格单位后的anchors值为:[(12/8, 16/8), (19/8, 36/8), (40/8, 28/8)]。
训练时,物体真实中心点落在哪个网格里,就会用那个网格的anchors进行计算和匹配。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









